Навигация
Системное программное обеспечение
22151
знак
0
таблиц
0
изображений
Разработка интерпретатора
1. Общее описание.
Данный интерпретатор реализует основных арифметических действия в виде инфиксных операций над числами с плавающей точкой. Например входной поток имеет вид:
r=2.5
area=pi*r*r
(здесь pi имеет предопределенное значение). Тогда программа калькулятора выдаст:
2.5
19.635
Результат вычислений для первой входной строки равен 2.5, а результат для второй строки - это 19.635. Программа интерпретатора состоит из четырех основных частей: анализатора, функции ввода, таблицы имен и драйвера.
Анализатор проводит синтаксический анализ, функция ввода обрабатывает входные данные и проводит лексический анализ, таблица имен хранит постоянную информацию, нужную для работы, а драйвер выполняет инициализацию, вывод результатов и обработку ошибок.
2. Анализатор.
Грамматика языка калькулятора определяется следующими правилами:
программа:
END // END - это конец ввода
список-выражений END
список-выражений:
выражение PRINT // PRINT - это 'n' или ';'
выражение PRINT список-выражений
выражение:
выражение + терм
выражение - терм
терм
терм:
терм / первичное
терм * первичное
первичное
первичное:
NUMBER // число с плавающей запятой в С++
NAME // имя в языке С++ за исключением '_'
NAME = выражение
- первичное
( выражение )
Иными словами, программа есть последовательность строк, а каждая строка содержит одно или несколько выражений, разделенных точкой с запятой. Основные элементы выражения - это числа, имена и операции *, /, +, - (унарный и бинарный минус) и =. Имена необязательно описывать до использования.
Для синтаксического анализа используется метод, обычно называемый рекурсивным спуском. Это распространенный и достаточно очевидный метод. В таких языках как С++, то есть в которых операция вызова не сопряжена с большими накладными расходами, это метод эффективен. Для каждого правила грамматики имеется своя функция, которая вызывает другие функции. Терминальные символы (например, END, NUMBER, + и -) распознаются лексическим анализатором get_token(). Нетерминальные символы распознаются функциями синтаксического анализатора expr(), term() и prim(). Как только оба операнда выражения или подвыражения стали известны, оно вычисляется. В настоящем трансляторе в этот момент создаются команды, вычисляющие выражение.
Анализатор использует для ввода функцию get_token(). Значение последнего вызова get_token() хранится в глобальной переменной curr_tok. Переменная curr_tok принимает значения элементов перечисления token_value:
enum token_value {
NAME, NUMBER, END,
PLUS='+', MINUS='-', MUL='*', DIV='/',
PRINT=';', ASSIGN='=', LP='(', RP=')'
};
token_value curr_tok;
Для всех функций анализатора предполагается, что get_token() уже была вызвана, и поэтому в curr_tok хранится следующая лексема, подлежащая анализу. Это позволяет анализатору заглядывать на одну лексему вперед. Каждая функция анализатора всегда читает на одну лексему больше, чем нужно для распознавания того правила, для которого она вызывалась. Каждая функция анализатора вычисляет "свое" выражение и возвращает его результат. Функция expr() обрабатывает сложение и вычитание. Она состоит из одного цикла, в котором распознанные термы складываются или вычитаются:
double expr() // складывает и вычитает
{
double left = term();
for(;;) // ``вечно''
switch(curr_tok) {
case PLUS:
get_token(); // случай '+'
left += term();
break;
case MINUS:
get_token(); // случай '-'
left -= term();
break;
default:
return left;
}
}
Отметим, что выражения вида 2-3+4 вычисляются как (2-3)+4, что предопределяется правилами грамматики.
Функция term() справляется с умножением и делением аналогично тому, как функция expr() со сложением и вычитанием:
double term() // умножает и складывает
{
double left = prim();
for(;;)
switch(curr_tok) {
case MUL:
get_token(); // случай '*'
left *= prim();
break;
case DIV:
get_token(); // случай '/'
double d = prim();
if (d == 0) return error("деление на 0");
left /= d;
break;
default:
return left;
}
}
Проверка отсутствия деления на нуль необходима, поскольку результат деления на нуль неопределен и, как правило, приводит к катастрофе.
Функция error() будет рассмотрена позже. Переменная d появляется в программе там, где она действительно нужна, и сразу же инициализируется.
Функция prim, обрабатывающая первичное, во многом похожа на функции expr и erm().
double number_value;
char name_string[256];
double prim() // обрабатывает первичное
{
switch (curr_tok) {
case NUMBER: // константа с плавающей точкой
get_token();
return number_value;
case NAME:
if (get_token() == ASSIGN) {
name* n = insert(name_string);
get_token();
n->value = expr();
return n->value;
}
return look(name_string)->value;
case MINUS: // унарный минус
get_token();
return -prim();
case LP:
get_token();
double e = expr();
if (curr_tok != RP) return error("требуется )");
get_token();
return e;
case END:
return 1;
default:
return error("требуется первичное");
}
}
Когда появляется NUMBER (то есть константа с плавающей точкой), возвращается ее значение. Функция ввода get_token() помещает значение константы в глобальную переменную number_value. Если в программе используются глобальные переменные, то часто это указывает на то, что структура не до конца проработана, и поэтому требуется некоторая оптимизация. Именно так обстоит дело в данном случае. В идеале лексема должна состоять из двух частей: значения, определяющего вид лексемы (в данной программе это token_value), и (если необходимо) собственно значения лексемы. Здесь же имеется только одна простая переменная curr_tok, поэтому для хранения последнего прочитанного значения NUMBER требуется глобальная переменная number_value. Такое решение проходит потому, что калькулятор во всех вычислениях вначале выбирает одно число, а затем считывает другое из входного потока.
Если последнее значение NUMBER хранится в глобальной переменной number_value, то строковое представление последнего значения NAME хранится в name_string. Перед тем, как что-либо делать с именем, интерпретатор должен заглянуть вперед, чтобы выяснить, будет ли ему присваиваться значение, или же будет только использоваться существующее его значение. В обоих случаях надо обратиться к таблице имен. Эта таблица состоит из записей, имеющих вид:
struct name {
char* string;
name* next;
double value;
};
Член next используется только служебными функциями, работающими с таблицей:
name* look(const char*);
name* insert(const char*);
Обе функции возвращают указатель на ту запись name, которая соответствует их параметру-строке. Функция look() "ругается", если имя не было занесено в таблицу. Это означает, что в калькуляторе можно использовать имя без предварительного описания, но в первый раз оно может появиться только в левой части присваивания.
Похожие работы
... . Объясните, для чего служат разрешения и привилегии в Windows NT. Зав. кафедрой -------------------------------------------------- Экзаменационный билет по предмету СИСТЕМНОЕ ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ Билет № 22 Перечислите возможности и инструменты системы программирования Microsoft Developer Studio. Укажите для чего предназначается буфер в системах ввода-вывода, ...
... доступа к информации, ее целостности и другие возможности использования сетевых ресурсов. 3. Сервисное ПО: краткая характеристика Сервисное программное обеспечение - программы и программные комплексы, которые расширяют возможности базового программного обеспечения и организуют более удобную среду работы пользователя. Это набор сервисных, дополнительно устанавливаемых программ, которые ...
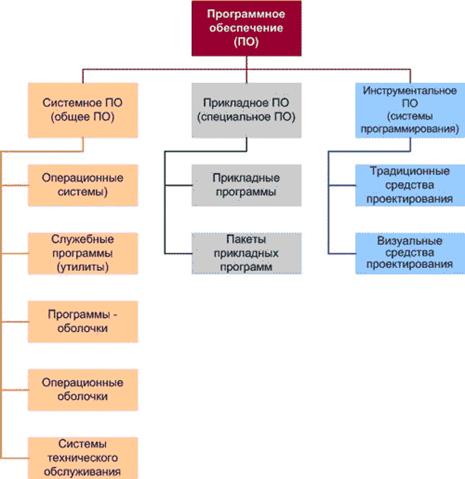
... . John W. Tukey) в 1958 году.[1] Совокупность программ, предназначенная для решения задач на ПК, называется программным обеспечением. Состав программного обеспечения ПК называют программной конфигурацией. Программное обеспечение, можно условно разделить на три категории: · системное ПО (программы общего пользования), выполняющие различные вспомогательные функции, например создание копий ...
я правилами вывода, а лишь служат для отражения семантической и синтаксической стороны грамматики. Для наглядного изображения работы программы представлено дерево функционального вызова (рис 1). На нём можно проследить принцип рекурсивного спуска -основной принцип, заложенный в обработку. Он заключается в прохождении дерева от крайней левой до крайней правой вершины дерева. Кроме того, для ...
0 комментариев