А. Г. Глазунов
В статье перечислены и кратко описаны основные типы технологий перевода. Изложены принципы организации систем памяти переводов, и охарактеризована сфера их применимости. Предложена новая модель памяти переводов, подразумевающая привлечение технологии машинного перевода. Кратко описан универсальный сетевой язык UNL, и обоснована целесообразность его использования для реализации предложенной модели.
Введение
Отвлекшись на секунду от всех тонкостей существующих ныне способов перевести текст с одного языка на другой, можно с уверенностью утверждать, что есть лишь три типа перевода: человеческий, машинный и человеко-машинный. Первый тип, вне всяких сомнений, является самым трудоемким, однако, на первый взгляд, он кажется наиболее надежным, поскольку кто, если не человек, способен адекватно передать смысл, заключенный в тексте? Тем не менее, более внимательный взгляд на проблему позволяет обнаружить, что человеческий перевод по-настоящему ценен или, если хотите, бесценен только в художественной литературе и, отчасти, в публицистике, где важными факторами являются разнообразие и творческий подход. В то же время, научные и технические тексты требуют строгих формулировок и точного следования терминологии, что, согласитесь, временами представляет для человека проблему. Идеальным средством для технического перевода мог бы оказаться компьютер, но в ближайшие годы чисто машинный перевод едва ли найдет серьезное практическое применение в силу сложности, многообразия и недостаточной "формализуемости" естественных языков. Выходом из положения является комбинированный, человеко-машинный перевод, выполняемый при доминирующей роли человека, но с привлечением возможностей вычислительной техники.
Полагаясь на справедливость вышесказанного, сконцентрируем свое внимание на задаче оптимального комбинирования процессов человеческого и компьютерного переводов технического текста. Дабы с первых же строк не отклоняться от пресловутого принципа точности терминологии, для начала введем ряд определений, заранее отметив, что все они даются исключительно в контексте поставленной задачи.
Основные определенияКонцепт- не зависящее от конкретного языка понятие, соответствующее реальной или абстрактной сущности, свойству, действию, либо иному элементу, отражающему связь между другими понятиями.
Термин- слово или словосочетание на заданном языке, обозначающее в этом языке конкретный концепт.
Терминология- множество обозначающих один и тот же концепт терминов из различных языков.
Сегмент- непрерывный фрагмент текста, состоящего из терминов одного языка, обозначающих связанную по некоторому критерию группу концептов.
Вариант сегмента- сегмент, похожий на исходный по некоторому критерию.
Исходный язык- язык, с которого осуществляется перевод.
Целевой язык- язык, на который осуществляется перевод.
Языковая пара- упорядоченная пара сегментов, объявленных переводчиком эквивалентными по смыслу, первый из которых содержит термины на исходном языке, а второй- на целевом.
Восемь типов технологии переводаВ современных профессиональных средах перевода возможности вычислительной техники используются на различных этапах и уровнях. Всего можно выделить восемь способов применения компьютера при переводе (таблица 1).
Таблица 1
| Уровень терминов | Уровень сегментов | |
| До перевода | Выделение терминов Анализ терминологии | Сегментация текста |
| Во время перевода | Автоматический поиск терминологии | Поиск языковых пар в памяти переводов Машинный перевод |
| После перевода | Проверка соответствия терминологии | Проверка целостности сегментов, формата и грамматики |
Выделение терминов и анализ терминологии
На этом этапе производится исследование текста с целью выяснения, какие слова или словосочетания могут быть взяты в качестве терминов. После того, как определен термин на исходном языке, осуществляется анализ терминологии на предмет того, какой термин на целевом языке следует выбрать для обозначения нужного концепта. Например, если в исходном тексте встретилось словосочетание "операционная система" то программа должна проанализировать его в качестве возможного термина, даже если в системе уже определены термины "операционный" и "система".
Автоматический поиск терминологииДанный процесс может быть сравнен с машинным переводом на уровне отдельных терминов. Суть его заключается в том, что в процессе работы над текстом переводчик имеет возможность видеть варианты перевода для каждого термина, и быстро вставлять нужный перевод в текст на целевом языке, не рискуя допустить опечатку.
Проверка соответствия терминологииПосле того, как перевод выполнен, компьютер осуществляет проверку того, что все вхождения каждого из терминов были переведены одинаково. Например, если термин "операционная система" был заменен при своем первом вхождении на "operatingsystem", а при втором вхождении на "operationalsystem", то должно быть выдано соответствующее предупреждении о нарушении единства терминологии.
Сегментация текстаРазбиение текста на сегменты является важным подготовительным этапом для полной или частичной автоматизации перевода. Сегменты должны по возможности содержать фрагменты текста, грамматически независимые друг от друга. Иными словами, должна быть обеспечена возможность корректного перевода каждого сегмента независимо от других. Обычно разбиение на сегменты выполняется по знакам пунктуации.
Поиск языковых пар в памяти переводовАвтоматическая память переводов, или просто память переводов (TranslationMemory), подразумевает, в первую очередь, просмотр ранее переведенных текстов. Она сравнивает переводимый в текущий момент текст с тем, что хранится в базе, "вспоминает" сегменты, которые изменились незначительно, и предлагает использовать их перевод повторно. Разумеется, критерии сходства сегментов могут быть различны, и они играют очень важную роль в расширении возможностей памяти переводов.
Машинный переводДанный способ перевода заключается в алгоритмической обработке исходного текста, в ходе которой происходит разбор сегментов, выделяются отдельные термины и отношения между ними, после чего осуществляется замена всех терминов на соответствующие термины целевого языка в нужной форме и взаиморасположении. Машинный перевод (MachineTranslation) применим только в очень узком контексте и требует значительного постредактирования переведенного текста.
Проверка целостности сегментов, формата и грамматикиДанные действия выполняются по окончании перевода и имеют своей целью проверить, все ли сегменты остались на своих местах, сохранилась ли форматирующая информация, и корректен ли результирующий текст с точки зрения грамматики целевого языка.
Среди перечисленных технологий наибольший интерес представляют терминологические словари и память переводов, поскольку именно от их эффективности зависит скорость и качество перевода. Технология построения терминологических словарей достаточно хорошо проработана и основана на принципах, аналогичных тем, что применяются в обычных двуязычных словарях. Разбиение текста на термины обычно осуществляется по пробелам с дополнительным привлечением некоторого морфологического анализа.
Сложнее обстоит дело с организацией памяти переводов. Наряду с тривиальной задачей поиска языковой пары, включающей сегмент, идентичный заданному, память переводов должна обеспечивать возможность поиска сегментов, похожих на данный по некоторому критерию. Таким образом, центральной проблемой классической памяти переводов является построение анализатора таких "нечетких совпадений" (fuzzymatches), характеристики которого и определяют преимущества и недостатки каждой конкретной системы профессионального перевода.
Аспекты использования памяти переводовСфера применимости
Как следует из вышеизложенного, основой функционирования любой системы памяти переводов являются ранее переведенные тексты. Множество этих текстов постоянно пополняется новыми переводами, вследствие чего, процент автоматически переводимых сегментов, постепенно растет. Это означает, что для наиболее эффективного использования памяти переводов, все тексты должны содержать достаточное количество похожих фраз. Такое положение вещей имеет место в документации на различного рода продукты. Это обусловлено двумя факторами. Во-первых, документацию принято составлять максимально простым языком, лаконично и в строгих терминах. Во-вторых, с появлением новых версий и модификаций поставляемого потребителям продукта содержание документации меняется лишь в незначительной степени. Память переводов, в подобных случаях, избавляет переводчика от необходимости по несколько раз переводить идентичные фрагменты текста, входящие в разные документы.
В то же время, использование памяти переводов требует от переводчика специальной подготовки, а также наличия соответствующего аппаратного и программного обеспечения. Другим негативным фактором является то, что для обеспечения ожидаемого эффекта все переводы должны быть сделаны в одной и той же среде, либо в средах, совместимых по формату представления данных. Наконец, полезный эффект памяти переводов проявляется с заметной отсрочкой во времени, требуя поначалу дополнительных капиталовложений.
Резюмируя вышесказанное, можно выделить три условия применимости рассматриваемой технологии:
большой объем перевода;
однотипность переводимых текстов;
готовность к отсроченному возврату капиталовложений.
Основные принципы работы
Память переводов представляет собой базу данных, хранящую языковые пары, и определенный механизм поиска. Несмотря на то, что различные профессиональные среды перевода, такие как "Translator'sWorkbench" фирмы Trados, "Transit" фирмы Star, "DejaVu" фирмы Atril, имеют, по-видимому, различную реализацию этого механизма ("по-видимому", поскольку алгоритмы не придаются огласке), общая идея становится ясной после изучения примеров. Поэтому с примеров и начнем.
Пусть в исходном тексте встречаются следующие фразы:
"Температура регулируется поворотом ручки." "Температура регулируется поворотом ручки по часовой стрелке." "Напор воды регулируется поворотом ручки по часовой стрелке."
Если сегментация выполняется по предложениям, то каждая из приведенных фраз попадет в отдельный сегмент. Пусть первый сегмент был переведен человеком следующим образом:
"The temperature can be adjusted by turning the knob."
Языковая пара, состоящая из исходного и переведенного сегментов, заносится в память переводов. Когда переводчик доходит до второй фразы примера, система определяет сходство и выводит на экран следующую информацию: таблица 2.
Таблица 2
| Текущий сегмент | Температура регулируется поворотом ручки по часовой стрелке |
| Найденный сегмент | Температура регулируется поворотом ручки |
| Перевод | The temperature can be adjusted by turning the knob |
| Степень сходства | ~70% |
Теперь переводчик имеет возможность частично воспользоваться уже сделанным переводом, учтя различия:
"The temperature can be adjusted by turning the knob clockwise."
После того, как сегмент, соответствующий второй фразе примера помечается как переведенный, в памяти переводов появляется еще одна языковая пара. Тем самым, когда дело доходит по третьей фразы, система уже имеет возможность показать переводчику два похожих варианта: таблица 3.
Таблица 3
| Текущий сегмент | Напор воды регулируется поворотом ручки по часовой стрелке |
| Найденная языковая пара 1 | Температура регулируется поворотом ручки по часовой стрелке |
| The temperature can be adjusted by turning the knob clockwise | |
| Степень сходства | ~65% |
| Текущий сегмент | Напор воды регулируется поворотом ручки по часовой стрелке |
| Найденная языковая пара 2 | Температура регулируется поворотом ручки |
| The temperature can be adjusted by turning the knob | |
| Степень сходства | ~40% |
Воспользовавшись, к примеру, первым из предложенных вариантов, переводчик быстро расправляется с оставшейся частью фразы:
"The water head can be adjusted by turning the knob clockwise."
Эффективность работы памяти переводов во многом определяется тем, насколько удачно решены следующие задачи:
сегментация;
обработка специальных символов и форматирующей информации.
Очевидно, что с увеличением размера сегментов будет уменьшаться число полных совпадений (и увеличиваться число частичных), что сильно повысит ресурсоемкость процедур поиска и потребует от переводчика значительных усилий в изучение предоставленных ему в качестве вариантов перевода языковых пар. С другой стороны, уменьшение размера сегментов сделает их малопригодными для повторного использования, поскольку сильно возрастет влияние контекста на перевод. Оптимальной единицей сегментации чаще всего оказывается фрагмент предложения, ограниченный знаками препинания. Во избежание ошибочной сегментации по точкам внутри аббревиатур и других подобных случаев используют регулярные выражения и списки исключений.
Вторая проблема обусловлена тем, что в тексте кроме букв зачастую присутствуют иные символы, как то: маркеры внедренных в документ объектов, закладки, перекрестные ссылки, переключатели свойств шрифта. Все эти инородные элементы в ряде случаев могут повлиять на перевод. Например, выделенное курсивом слово может при переводе быть взято в кавычки и попасть в результирующий текст в неизменном виде. Для управления поведением анализатора в таких ситуациях во многих программных продуктах предусмотрены специальные настройки, в том числе, основанные на применении регулярных выражений.
Пути расширения возможностей
Поскольку функцией памяти переводов является поиск в базе данных переведенных фрагментов заданного сегмента, то пределом ее возможностей является, очевидно, выборка, максимально покрывающая исходный сегмент и не содержащая никакой избыточной (лишней) информации.
Попытаемся выделить возможные варианты повышения качества памяти переводов, воспользовавшись приведенным ранее примером. Выберем и рассмотрим две языковые пары: таблица 4.
Таблица 4
| Языковая пара 1 | Температура регулируется поворотом ручки по часовой стрелке |
| The temperature can be adjusted by turning the knob clockwise | |
| Языковая пара 2 | Напор воды регулируется поворотом ручки по часовой стрелке |
| The water head can be adjusted by turning the knob clockwise |
Сходство сегментов на исходном языке позволяет сделать предположение, что их переводы, то есть сегменты на целевом языке также должны быть похожи. Коль скоро это так, что возникает резонное желание выделить из двух приведенных языковых пар общую часть и представить ее в виде новой языковой пары. Выполнив несложную операцию пересечения строк, получаем следующий результат: таблица 5.
Таблица 5
| Языковая пара 3 | Регулируется поворотом ручки по часовой стрелке |
| can be adjusted by turning the knob clockwise |
Теперь для любого сегмента, включающего фрагмент " регулируется поворотом ручки по часовой стрелке", может быть выбрана языковая пара номер 3, содержащая только необходимый перевод для фрагмента.
Однако, не всегда все так хорошо. Чуть более внимательный взгляд на этот пример сразу же заставит нас признать, что создание таких "укороченных" языковых пар эквивалентно уменьшению размера сегмента, а мы помним, чем это грозит. Маленький фрагмент текста, в особенности, если он не ограничен никакими знаками препинания, едва ли может быть правильно переведен без учета контекста. Следовательно, при выделении общих частей в двух используемых уже языковых парах необходимо руководствоваться теми же принципами, что и при начальной сегментации исходного текста.
К тому же, не стоит забывать, что пересечение сегментов на исходном языке не обязательно изоморфно пересечению сегментов на целевом языке. Это связано с различиями правил грамматики в разных языках, порядка слов, соответствия слов понятиям. Поэтому осмысленное значение целевого сегмента языковой пары, образованной пересечением, можно ожидать только при:
значительном размере обоих сегментов вновь образованной языковой пары;
эвристически определенном изоморфизме пересечения сегментов на исходном и целевом языке (например, если пересечение осуществлено по знакам пунктуации);
морфологическом и синтаксическом анализе результата пересечения с привлечением технологии машинного перевода.
Еще одной немаловажной задачей при реализации механизма описанных манипуляций с языковыми парами является создание некоторого формализма, позволяющего однозначно определить, какие именно пары должны подвергаться обработке, как именно должен формироваться результат, как должен осуществляться поиск сегмента и каковы критерии сравнения сегментов при поиске. Этим мы теперь и займемся.
Многоуровневая модель памяти переводов
Представление данных
Структура реально используемых ныне реализаций памяти перевода является одноуровневой и подразумевает наличие упорядоченного списка языковых пар. С введением механизма выделения в парах общих частей подобная организация данных окажется неудобной. Действительно, для любых двух пересекающихся языковых пар в базе будет создаваться дополнительный элемент, содержание которого будет полностью дублироваться в обеих языковых парах. От избыточности удастся избавиться, если удалить вынесенную общую часть из обеих пар, а на ее место поставить ссылку на вновь созданную языковую пару (рис. 1).
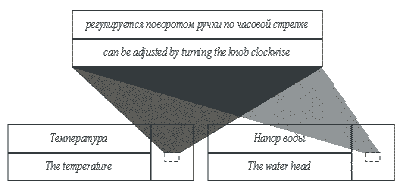
Рис. 1
Повторяя данную процедуру каждый раз, когда обнаруживается очередное пересечение, мы, в конечном счете, получим направленный граф, узлами которого являются языковые пары, а дугами- отношения включения.
Еще одной оптимизацией является разделение исходного и целевого сегментов каждой языковой пары. Это имеет смысл, поскольку не так уж редки случаи, когда одна и та же исходная фраза переводится на целевой язык по-разному, что порождает две языковые пары с одинаковым первым элементом. Помимо этого, пересечения исходных и целевых сегментов не всегда изоморфны, и их результаты не обязательно образуют языковую пару.
Поэтому разделим языковые пары, и получим два ориентированных графа, "синхронизированных" друг относительно друга (рис. 2). При этом отношения, связывающие вершины разных графов, могут быть различной местности, но обязательно обладают свойством симметричности.
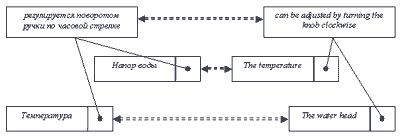
Рис. 2
Развивая идею дальше, вспомним, что в нашем распоряжении уже имеется аппарат, позволяющий формализовать представленную схему. Это- объектно-ориентированный подход. В самом деле, каждому сегменту в базе может быть сопоставлен отдельный класс, отношение включения по своим свойствам идентично отношению наследования, а горизонтальные связи, формирующие языковые пары могут быть заданы механизмом ассоциирования, либо введением в класс метода Translate ("перевести").
Тем не менее, предложенная модель пока что не описывает внутреннюю структуру сегментов, которую необходимо анализировать при создании новой языковой пары на основе пересечения существующих. Для решения этой задачи разобьем все сегменты на отдельные слова (по пробелам). Теперь каждый сегмент может быть представлен классом, являющимся производным от всех слов, образующих текст сегмента. При этом совершенно необязательно иметь перевод для каждого слова, поскольку это будет отражено лишь отсутствием соответствующей связи между узлами графов, а метод Translate будет возвращать "нулевое" значение.
Памятуя о том, что в состав среды перевода помимо памяти переводов входит также терминологический словарь, деление сегментов можно осуществлять не по словам, а по терминам. Наличие терминологического словаря дает и еще одну возможность. Для каждого вхождения термина в сегмент можно определить его начальную форму, то есть ту, в которой он входит в базу словаря. Эта начальная форма послужит как бы абстрактным базовым классом для каждого вхождения термина, а конкретное вхождение будет содержать определение значений заданных в базовом классе атрибутов: род, число, падеж и т. п.
Последнее нововведение подталкивает нас к мысли о том, терминологический словарь можно слить воедино с памятью переводов, представив, тем самым, все ресурсы переводчика в виде универсальной модели (рис. 3).
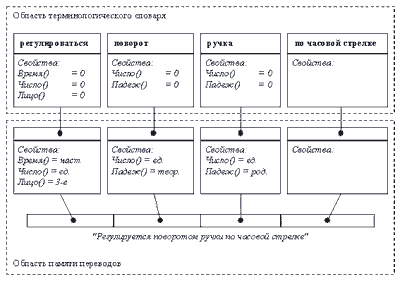
Рис. 3
Поиск и добавление
До тех пор, пока память переводов была линейной, сегменты неделимыми, а сравнение строгим, решение задачи поиска сводилось к введению отношения строгого лексикографического порядка над множеством сегментов на исходном языке. Иными словами, определялся оператор "меньше", на основе которого можно было осуществить обыкновенный двоичный поиск, и проверку на равенство. С введением оператора "нечеткого совпадения", который позволял оценить степень сходства для любых двух сегментов, решение проблемы поиска резко усложнилось и, без дополнительных ухищрений с различного рода индексацией, стало эквивалентно задаче полного перебора. Предложенная многоуровневая модель памяти переводов, собственно, и предоставляет некоторый механизм неявной индексации: каждое входящее в сегмент слово, по сути, идентифицирует некоторое подмножество ориентированного графа памяти переводов, состоящее из узлов, которые можно достичь, начав обход от узла, соответствующего выбранному слову.
Используя особенности выбранной структуры памяти переводов, задачу поиска сегментов, похожих на заданный, можно решить путем выполнения следующих действий (рис. 4):
разбить заданный сегмент на слова;
найти в памяти переводов все узлы, соответствующие этим словам;
спускаясь по графу отношений наследования, помещать в список найденных сегментов все встречаемые узлы.
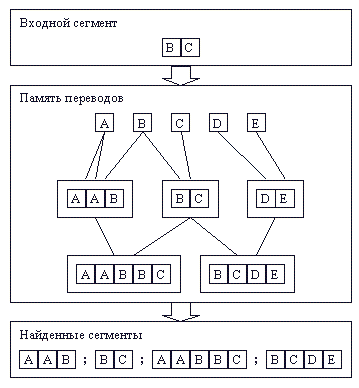
Рис. 4
Резонным представляется вопрос о том, в каком порядке следует предоставлять найденные сегменты переводчику: ведь приведенная процедура поиска выберет из памяти все сегменты, пересекающиеся с заданным по крайней мере по одному слову. Каковы правила фильтрации и сортировки найденных сегментов?
Ответ на этот вопрос лежит за пределами выбранного формализма, однако в этом нет ничего страшного. Дело в том, что результат поиска представляет собой классический вариант одноуровневой памяти переводов, анализ которого может быть произведена методами, формализованными в рамках существующих сред перевода. Для обеспечения эффективности поиска целесообразно осуществлять оценку "пригодности" сегментов по мере их нахождения. Например, если некоторый сегмент полностью совпадает с эталоном, то все его потомки в графе могут быть автоматически исключены из поиска.
Теперь поговорим о задаче добавления нового сегмента в память переводов. Очевидным условием корректности процедуры добавления является обеспечение успешного поиска. Стало быть, добавляемый сегмент должен иметь в числе своих предков (не обязательно прямых) все составляющие его слова. Следуя целям оптимальности, можно заключить, что среди предков должны присутствовать также узлы графа, содержащие фрагменты данного сегмента. Иными словами, если в памяти переводов присутствуют сегменты "AB" и "CD", то сегмент "ABCD" должен стать наследником этих двух сегментов. Аналогично, если в памяти присутствует сегмент "ABCD", то добавляемый сегмент "AB" должен стать его предком. В общем случае при добавлении сегмента в граф памяти переводов могут существовать альтернативные варианты наследования. В такой ситуации схема добавления заметно усложнится. В любом случае, проблема построения оптимальной иерархии классов решается в рамках объектно-ориентированного подхода, поэтому мы не будем заострять здесь на ней внимание.
Вычисление пересечения языковых парПоскольку выделение общей части двух сегментов- важный этап предлагаемой технологии перевода, изучим этот вопрос более детально. При этом, помня о том, что сегмент в памяти перевода выступает, чаще всего, не отдельно, а как элемент языковой пары, будем рассматривать именно пересечение пар.
Для начала дадим определения пересечения сегментов. Итак, пересечение сегментов A и B- это множество сегментов Ci, таких что:
каждый из Ci содержится и в A, и в B;
никакие два Ci не содержат одинаковых фрагментов;
не существует такого сегмента D, что и A, и B содержат D, и D содержит один из сегментов Ci.
Приведенное определение не подразумевает выделения из сегментов A и B всех общих фрагментов. Это сделано для того, чтобы можно было использовать алгоритмы различной сложности реализации пересечения.
Теперь перейдем к пересечению языковых пар. Как уже было упомянуто выше, очень важно определить, является ли пересечение изоморфным, иными словами, можно ли считать результаты пересечения исходных и целевых сегментов языковой парой. Два примера иллюстрируют это (рис. 5). В первом случае пару сегментов "достаточно высока" и "ishighenough" имеет смысл поместить в память переводов, поскольку она действительно представляет собой вариант перевода, который может быть повторно использован переводчиком. Во втором случае- это совершенно очевидно- сегменту "достаточно" не следует сопоставлять сегмент "ishighenough", поскольку данная языковая пара будет некорректной.
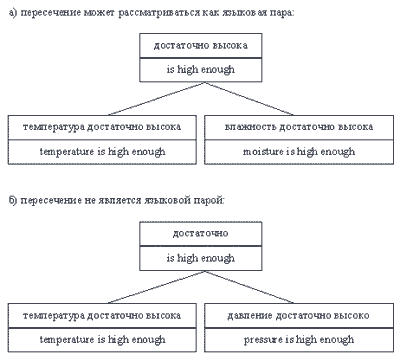
Рис. 5
Для проверки изоморфизма пересечений можно использовать подход, основанный на технологии машинного перевода. Его суть в сопоставлении терминов, образующих исходный и целевой сегменты. Для этого необходимо произвести грамматический разбор сегментов с целью выделения терминов и синтаксических связей между ними. После этого можно воспользоваться терминологическим словарем для определения того, какому термину в целевом сегменте соответствует заданный термин в исходном сегменте. Иными словами, изоморфизм можно определить по следующему критерию (рис. 6):
пересечение является изоморфным, если всем терминам его исходного сегмента, сопоставлены термины его целевого сегмента, и синтаксические связи между ними идентичны тем, которые присутствуют в сегментах, из которых было получено пересечение.
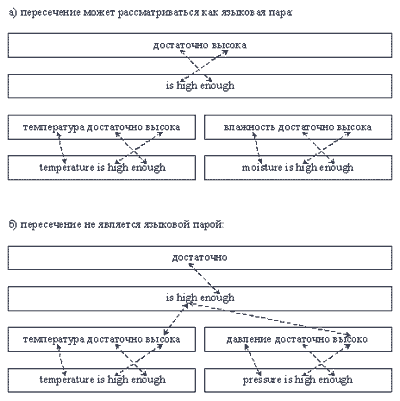
Рис. 6
В общем случае, для оценки изоморфизма можно проверять не только отдельные термины (суть корневые узлы графа памяти переводов), но и родительские сегменты всех уровней. Это повысит надежность оценки, снизив риск неправильного определения синтаксических связей.
Следует обратить внимание на тот факт, что в предлагаемой модели машинный перевод используется только для грамматического анализа текста, образующего сегмент. Слабым местом систем машинного перевода является выбор перевода для терминов сегмента, и именно эта задача решается более надежным способом- с помощью памяти переводов.
От языковых пар к языковым звездам
Нередкой является ситуация, когда перевод приходится осуществлять не только с языка A на язык B, но и, наоборот, с языка B на язык A. Одна и та же память переводов будет одинаково полезна в обоих случаях, поскольку содержит максимально синхронизированные графы сегментов на языке A и на языке B. Однако стоит нам усложнить задачу и предположить необходимость перевода между несколькими языками, как полезность единой памяти переводов заметно падает. Действительно, если перевод осуществлялся с языка A на языки B и C, то в памяти не будет храниться соответствия между сегментами на языках B и C. Как же обеспечить подобную возможность?
Разумным решением могло бы явиться использование некоторого промежуточного языка X, на который осуществлялся бы перевод, а затем, вторым этапом, выполнялся бы перевод с языка X на целевой язык. В подобном случае все языковые пары в памяти переводов состояли бы из сегмента языка X и сегмента одного из целевых (либо исходных) языков. Тут имеются, однако, подводные камни. Во-первых, как мы уже убедились, пересечение языковых пар не всегда бывает изоморфным, следовательно, не все языковые пары в памяти переводов будут содержать перевод на язык X. Очевидно, такие пары будут бесполезны. Во-вторых, при переводе всегда имеется опасность потери смысла: двойной перевод значительно увеличивает эту опасность.
Каким же должен быть этот гипотетический промежуточный язык X, чтобы им было целесообразно воспользоваться? Его свойства вытекают из двух названных проблем. Во-первых, этот язык должен обеспечивать изоморфное пересечение для любого другого языка. Нарушение изоморфизма (по крайней мере, в родственных языках) обусловлено в значительной степени различием синтаксических правил, приводящим к разному порядку членов предложения, а также к различию форм одного и того же слова. Отсюда следует, что язык X должен быть инвариантен к порядку слов и как-то учитывать их формы в исходном языке. Во-вторых, он должен быть в состоянии передать смысл фразы на любом языке, следовательно- включать в себя специфические понятия всех существующих человеческих языков.
Если такой универсальный язык будет найден, то память переводов можно будет организовать не на основе языковых пар, а на основе языковых звезд, где в центре находится сегмент на языке X, на лучах- варианты переводов его на другие языки. При значительном объеме перевода между большим количеством языков дополнительные затраты на удвоенную работу переводчика с лихвой окупятся гибким механизмом памяти переводов, значительно упрощающим многоязычный перевод.
Осталось только найти язык X. И такой язык существует! Это универсальный сетевой язык UNL (UniversalNetworkingLanguage), предложенный Институтом Развития Обучения (InstituteofAdvancedStudies- IAS) при Университете Объединенных Наций (UnitedNationsUniversity- UNU). Им мы и воспользуемся для дальнейшего развития модели памяти переводов.
Язык UNL и концептно-ориентированная парадигма
Краткое описание языка UNL
Язык UNL представляет высказывания в виде множества так называемых универсальных слов, связанных определенного типа бинарными отношениями. Универсальное слово представляет собой обозначение некоторого понятия и задается именем соответствующего понятия (обычно на английском языке), группой вспомогательных атрибутов (число, время, наклонение и т. п.) и некоторыми ограничениями семантики, представленными с помощью других универсальных слов и отношений. Вот примеры универсальных слов:
"человек" - man(icl>person)
"люди" - man(icl>person).@plural
"шляпа" - hat(icl>thing)
Бинарные отношения задают тип взаимосвязи между понятиями. Например, в словосочетании "человек идет" используется отношение "agt" (agent), обозначающее связь между субъектом действия и самим действием. В словосочетании "нести флаг" используется отношение "obj" (object), обозначающее направленность действия на объект. В синтаксисе UNL эти примеры запишутся так:
"человекидет" - agt(walk(icl>do), man(icl>person))
"нестифлаг" - obj(carry(icl>do), flag(icl>thing))
Любое множество таких пар может быть объединено в одно составное универсальное слово при помощи специальных меток. Например, словосочетание "человек, несущий флаг" представится следующим образом:
agt:01(carry(icl>do):02, man(icl>person))
obj:01(carry(icl>do):02, flag(icl>thing))
Чтобы отразить тот факт, что несколько вхождений одного и того же универсального слова обозначают один объект, все вхождения маркируются одной и той же меткой, как это сделано в случае слова "carry".
Составное слово, так же как и простое универсальное слово, может быть элементом бинарного отношения. Фраза "я вижу человека, несущего флаг" запишется так:
agt:01(carry(icl>do):02, man(icl>person))
obj:01(carry(icl>do):02, flag(icl>thing))
agt(see(icl>do):03, I)
obj(see(icl>do):03, :01)
Как видно из примеров, каждое слово, простое и составное, в языке обозначает определенное понятие, или "концепт". Следовательно, UNL оперирует не словами, а именно концептами. С другой стороны, предложение на языке UNL представляет собой неупорядоченное множество связанных бинарными отношениями концептов. Отсюда следует, что при переводе на UNL исключено нарушение изоморфизма, вызванное различным порядком слов.
Проблема изоморфизма пересечения языковых пар
Итак, мы определили, что представление на языке UNL позволяет полностью сохранить смысл (поскольку лексическими единицами являются однозначные обозначения понятий) и обеспечивает независимость изоморфизма пересечения языковых пар от порядка слов в предложениях. Тем не менее, осталась и усугубилась проблема нарушения изоморфизма, вызванного различием форм одного и того же слова в разных предложениях. Действительно, концепт в языке UNL, не меняет своей формы, с каким бы другим концептом он ни был связан. В то же время, одно и то же слово на естественном человеческом языке может видоизменяться.
Анализируя эту проблему, задумаемся: а действительно ли нам нужно вычислять пересечение исходных сегментов? Нельзя ли, вычислив пересечение целевых сегментов (то есть UNL-предложений), сформировать для него перевод обратно на исходный язык автоматически? Положительный ответ на эти вопросы можно дать, если снова воспользоваться технологией машинного перевода. Действительно, для всех концептов имеется их перевод на исходный язык, следовательно, слабое место машинного перевода- выбор лексики- удастся избежать. Все, что будет требоваться от компьютера- это выделить в исходном сегменте те слова и синтаксические связи, которые вошли в состав пересечения UNL-предложений, и сформировать новое словосочетание, нужным образом изменив формы слов (рис. 7).
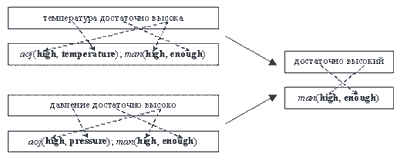
Рис. 7
Коль скоро мы доверили системе машинного перевода синтаксический и морфологический разбор исходного сегмента, когда оценивали изоморфизм пересечения языковых пар без привлечения UNL, доверим ей сделать то же самое для организации поиска сегмента в памяти переводов. В самом деле, почему бы не преобразовать исходный сегмент в UNL-предложение и не осуществить поиск в графе сегментов, хранящих текст на языке UNL? Поступив подобным образом, мы полностью избавимся от необходимости осуществлять операции поиска и добавления над графом сегментов, хранящих текст на естественном языке. Все операции будут производиться над графом UNL-предложений. Теперь вместо нескольких графов (по одному на каждый язык) память переводов будет использовать один единственный граф, каждый узел которого будет представлять собой языковую звезду с UNL-предложением в центре и вариантами перевода на лучах.
Весь процесс работы переводчика с предлагаемой системой описывается схемой, изображенной на рис. 8.
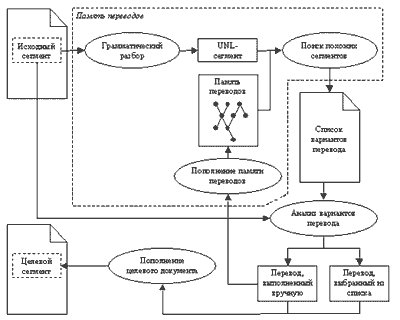
Рис. 8
Важным фактором является то, что работа классической памяти переводов описывается такой же схемой. Это означает, что реализация предлагаемой модели может быть легко встроена в существующие системы.
Концептно-ориентированная сущность памяти переводов
В результате всех нововведений мы построили модель памяти переводов, в основе которой лежит ориентированный граф отношений наследования, в узлах которого находятся понятия (концепты) различной степени конкретности. При этом в корневых (не имеющих предков) узлах графа находятся наиболее общие абстрактные концепты, соответствующие элементам терминологического словаря. Путем множественного наследования от них порождаются составные концепты, соответствующие более конкретным понятиям. С каждым концептом графа связаны варианты его перевода на различные языки. Не для каждого концепта может существовать перевод на заданный язык. С другой стороны, для некоторого концепта может быть определено несколько вариантов перевода на один и тот же язык.
Это было краткое резюме технической стороны предлагаемого подхода. Но более важным является технологический аспект. Долгое время системы машинного перевода и памяти переводов представляли два конкурирующих направления и никогда не рассматривались вместе кроме как в противопоставлении. На сегодняшний день взгляды меняются, и хотя фирмы не придают своим ноу-хау широкой огласки, заметна тенденция к совместному использованию в некоторых системах обеих технологий. Предлагаемая модель демонстрирует один из возможных вариантов такой интеграции. Более того, она представляет собой попытку показать, что под машинный перевод и память переводов можно подвести общую основу, и создать такую систему профессионального перевода, в которой оба механизма действуют как единое целое.
Список литературы
Alan K. Melby,Eight Types of Translation Technology // ATA, Hilton Head, November 1998
Олег Сонин, MT или TM// Компьютерная неделя N26-27(200-201).- М., 1999
Martin Volk: The Automatic Translation of Idioms. Machine Translation vs. Translation Memory Systems. In: Nico Weber (ed.): Machine Translation: Theory, Applications, and Evaluation. An assessment of the state of the art. St. Augustin: gardez-Verlag. 1998.
The Universal Networking Language (UNL) Specifications Version 3.0// UNU/IAS/UNL Center, August 2000. http://www.unl.ias.unu.edu/unlsys/unl/UNL%20Specifications.htm
Для подготовки данной работы были использованы материалы с сайта http://www.citforum.ru/
Похожие работы
... адекватности отечественных версий исходным не может даже идти и речи. Порой приходится иметь дело фактически с самостоятельным понятием. Так, нация и национальность упрямо связываются в отечественном политическом дискурсе с кровно-родственным происхождением, тогда как исходная версия концептуализирует «порождение» как связь с территорией. Поэтому одним из важнейших критериев принадлежности к нации ...
... , призванная связать воедино научные изыскания в области культуры, сознания и языка, т.к. он принадлежит сознанию, детерминируется культурой и опредмечивается в языке». 2. Формирование системы культурных концептов в рамках когнитивных возможностей личности Концепт, как отмечалось выше, представляет собой такую когнитивную единицу, которая является частью «всей картины мира, отраженной в ...
... жизни как ценности в трудах философов включает, наряду с индивидуально-авторским пониманием ценности бытия, и заданные языком (и шире – лингвокультурой) ценностные ориентиры. Глава 2. Способы языкового выражения лингвокультурного концепта savoir vivre во французской лингвокультуре и его соответствия в русском языковом сознании 2.1 Отношение к жизни как концепт-антиномия Для анализа ...
... языковой картине мира. Для решения указанных задач в диссертации использовались комплексные методы: описательный метод с применением приемов наблюдения, концептуальный метод анализа вербализации концептов «Истина», «Правда» и «Ложь» в русской и английской языковых картинах мира. В работе применялись также дополнительные методы изучения материала: изучение литературы по теме исследования, метод ...
0 комментариев