Навигация
Бита – diagnostics, 1 бит – modify
61662
знака
29
таблиц
63
изображения
2 бита – diagnostics, 1 бит – modify
Если испорчен один бит, код Хэмминга поможет его восстановить, если два – устранить ошибку.
Контроль паритета [выявит] только одну ошибку. Биты дополняются еще одним – четность/нечетность.
Если к устройству пришел неверный адрес, оно выставляет на шину сигнал ошибки. На высокочастотных шинах появляются:
- Фаза ожидания ошибки адреса
- Фаза ожидания данных
Т.к. ошибки появляются [редко], в эти фазы все просто чего-то ждут, обмена по шине нет.
Разделение шины между несколькими ЦПЭффективность шины очень мала:
1) Большую часть времени на шине ничего не происходит.
2) Даже во время активности шины не все провода используются одновременно.
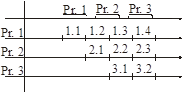
Надо совместить разные фазы шины разных ЦП, так, чтобы ЦП друг другу не мешали и использовали шину параллельно.
Предыдущий ЦП освободил шину – следующий ее занимает. Такие шины называются транзакционными.
В настоящее время в […] системах, т.к. алгоритмы анализа очень сложны (ко всему прочему, фазы могут быть разной длины).
Используется арбитр шин – устройство, которое управляет разделением шины между разными ЦП.

П просит АШ выдать ему шину. Если несколько запросов, АШ по какому-то алгоритму выделяет шину конкретному ЦП.
ЦП тогда начинает анализировать сигнал Busy.
Использование кэшКогда мы общаемся с ВУ, должны на шину выставить адрес.
В некоторых системах:
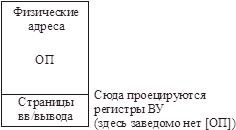
Старшие разряды шины служат для адресации регистров ВУ.
Когда мы даем команду «писать в регистр», данные оседают в кэш. Если после этого будет дана команда «читать кэш», прочитаны данные будут прочитаны из кэша! Что неверно!
КЭШ предназначен для устройств, обладающих только свойством хранения (например, ОП). А любое ВУ обладает еще какой-нибудь функцией (при этом совсем не обязательно ему обладать функцией хранения). Например, видеопамять – хранение и отображение.
Кэш не может отличить память ВУ от ОП. От нас потребуется соответствующее управление. Надо обращение к регистрам делать отличным от обращения к ОП.
- Шина адресов
- Шина ВУстройств
То есть, делаем логическую шину, отличную от адресной.
В Intel ввели специальные инструкции – in и out. ЦП четко различает (по коду) команда работы с памятью и с портами. Обращения к ВУ не кэшируются.
Есть еще одна проблема: в случае большой памяти ВУ.
По байтам брать нельзя, т.к. на каждый байт нужно прерывание, а это накладно (на весь пакет нужно одно прерывание).
1-е решение: сигнал кэшу сбросить всю свою память перед выполнением обмена с памятью. Но сбросятся все таблицы страниц! В ЦП УПА управляет адресацией с помощью таблицы страничных преобразований.
2-е решение: для каждой страницы 2 бита: «запрет кэширования» и «кэширование только при чтении»
Способы подключения ВУ к ВС. Использование контроллера ввода/вывода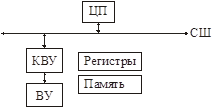
КВУ знает протокол СШ и подключается к ней. С другой стороны он подключается к ВУ, т.е. должен знать интерфейс ВУ.
Управляющими объектами (ВУ-ва) являются регистры и память. ВУ отображает их на виртуальное АП.
Если устройство быстрое и большие объемы передаваемых данных – используется резидентная память (существует два механизма – прямой доступ к памяти и отображение памяти).
Если медленное устройство и малые объемы передачи данных – используются регистры ВУ.
Как же КВУ интерпретирует адрес, выставленный на шину?..
Используются регистры:

К такому регистру (например, к RD) можно обращаться по одному адресу, но физически это два разных регистра. В один – отправляются данные, а из другого получаются.
КВУ дешевы и достаточно универсальны.
Недостаток: они реализованы в виде фиксированной логики. Логику работы изменить нельзя!
Если нужно подключать программируемые устройства, контроллеры не годятся, нужно применять механизм сопроцессора.
Механизм сопроцессора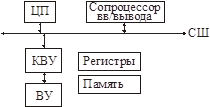
Сопроцессор не обладает полной вычислительной самостоятельностью. Он не может самостоятельно обмениваться данными по шине, принимать решения об обмене.
Сопроцессор имеет собственную систему команд, ему требуется помощь ЦП для организации работы.
1) Сопроцессор должен отличать циклы шины ЦП от своих циклов шины.
2) ЦП также должен отличать циклы шины сопроцессора от своих.
Escape-признак – это префикс команды.
Если команда, встречаемая ЦП имеет такой префикс, ЦП ее пропускает. Сопроцессор выполняет команды, следующие за признаком Escape.
Недостаток: нельзя изолировать поток команд сопроцессора от потока команд ЦП (в поток команд ЦП входят команды сопроцессора).
Тогда применяются процессоры ввода/вывода (ПВВ).
Они также имеют собственную систему команд, но могут управлять системной шиной. Следовательно, в памяти можно изолировать команды ЦП и ПВВ.
Отличие ПВВ от ЦП: ЦП никогда не останавливается. ПВВ останавливается по завершению операции.
ПВВ часто называют канальным процессором, а его программу – канальной программой.
Применяются для управления [произвольным] оборудованием (нужно только загрузить нужную программу) (например, в Mainframe’ах IBM).
Механизмы управления ВУ-ми через контроллеры. Управление через отображение регистров и адресов памяти на СШ
Самый простой способ.
Драйвер ВУ должен знать, какой регистр за что отвечает. Драйвер может в любой момент времени обратиться к любому регистру.
Преимущества:
- разработчик драйвера наиболее свободен в выборе – когда и что делать;
- за 1 цикл шины позволяет обращаться к запрошенному регистру (нет задержки).
Недостаток: если устройство сложное, нужно много регистров, а разрядность шины регистров ограничена.
Следовательно, нужно экономить регистры! (см. след. тему).
Механизм косвенной адресации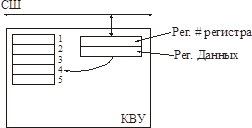
Число регистров в КВУ уменьшить невозможно (сколько есть, столько есть). Регистры эти имеют некоторые адреса внутри КВУ и не отображаются на шину.
На шину отображаются два регистра – регистр номера регистра и регистр данных.
Алгоритм работы:
Надо сгенерировать два цикла шины:
Цикл 1: число, обозначающее номер регистра в рег. # регистра.
Цикл 2: данные передаются из регистра данных во внутренний регистр с этим номером, либо коммутируются внутри регистра на шину (прямо так, без пересылки данных из него в регистр данных).
Драйвер может опять в любой момент обращаться к любому регистру, но существует задержка, т.к. требуется два цикла шины.
Примечание: для ВУ с большим числом регистров, доступ к которым осуществляется редко (пример: часы реального времени (70h и 71h – регистры номера и данных) и CMOS-память – используются только в момент загрузки компьютера).
Если надо гонять часто большие объемы данных, механизм косвенной адресации неприменяем!
В случае быстрых устройств и больших объемов данных необходимо выставить мало регистров на шину, но чтобы не тратилось два цикла шины.
Конвейерная схема загрузки регистров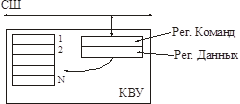
Смысл: любое устройство, работающее с таким КВУ имеет фиксированный набор команд и строго определенный порядок загрузки регистров для каждой команды.
Регистры уже не доступны драйверу по номеру, Номер регистра, в который будет помещена информация, определяется самой командой, а не драйвером.
Надо выполнить транзакцию и передачу КВУ данных, необходимых для данной операции. А КВУ сам распихает их по своим регистрам и запустит операцию.
В регистр команд загружаем команду (например, «читать сектор»). После этого последовательно помещаем все необходимые данные для этой команды в рег. данных.
После получения всего блока данных транзакция управления завершена, КВУ получает результат.
Чтобы не было бесконечного ожидания, считается, что любая операция записи в регистр команд сбрасывает предыдущую команду, если только она еще не выполняется.
Недостаток: в драйверах уже нельзя просто так использовать многопоточность, т.к. регистры должны запоминаться в нужном порядке.
Как еще можно снизить диапазон адресов? (см. след. тему).
Схема прямого доступа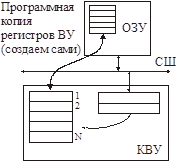
Можно организовать так называемый канал управления (для обмена командами с КВУ).
ПДП (DMA) может использоваться как для обмена данными, так и для обмена командами.
Заполняем программную копию регистров ВУ в ОЗУ требуемыми значениями и толкаем операцию ПДП.
Контроллер ПДП копирует блок из ОЗУ в регистры ВУ. Затем, КВУ автоматически начинает производить операцию.
Также в любой момент мы можем скопировать регистры ВУ в ОЗУ.
Недостаток: для организации обмена требуется ПДП.
КВУ должно поддерживать механизм ПДП. Ему нужно два канала: для данных и для управления. В Intel количество каналов ПДП ограничено, поэтому отказались от этого механизма.
В ВС с большими диапазонами АП актуальность сужения диапазона адресов уменьшается (для 32, 64 бит). Так что используют простое отображение регистров ВУ на шину.
Управление по опросу (polling)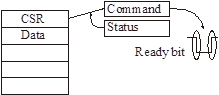
В
Status-регистре любого устройства всегда есть бит Ready (чаще всего он в знаковом разряде).
При поступлении команды в регистр команд аппаратура сбрасывает этот бит. При завершении команды бит снова устанавливается.
Ready bit можно проверять в цикле или по таймауту.
Для большого числа устройств работа в режиме polling’а неприемлема. Для асинхронных устройств этот режим вообще неприемлем.
Появился режим прерываний (см. след. тему).
Организация механизма прерыванийЗадачи:
1) Проинформировать ЦП о завершении операции ввода/вывода.
2) Найти ту программу, которая может обработать это прерывание.
Была разработана схема, названная «векторной таблицей».
Все события пронумерованы.

Дескрипторы описывают программы обработки прерывания.
Дескрипторы аппаратно (процессорно) зависимы.
ЦП должен сохранять тот контекст, который нельзя сохранить другими средствами. Если работаем с виртуальной памятью, надо аппаратно сохранять тот контекст, который меняется автоматически аппаратно во время перехода (таблица страниц, стек и т.д.).
Чтобы выполнить процедуру аппаратного прерывания достаточно сказать о факте происхождения события и передать номер сообщения (сигнализация и передача номера).
Система прерываний – специальный набор действий (какой номер выставлять на шину, что делать, если несколько и т.д.).
Система прерываний радиального типа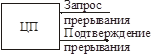
Ножка запроса прерываний всегда опрашивается центральным процессором между выполнением машинных инструкций.
Аппаратно в ЦП можно блокировать опрос этого бита (CLI).
Если этот бит устанавливается в 1, начинается обработка прерываний:
1) ЦП должен спасти свой контекст.
2) ЦП должен получить номер дескриптора таблицы (для этого сгенерировать цикл шины – подтверждение прерывания).

Контроллер прерываний – программируемое через СШ устройство.
Необходимо указать контроллеру, какой номер события связан с каким ВУ.
Система прерываний радиального типа: каждое прерывание ассоциирует с каждым устройством специальный единичный запрос.
Для каждой линии IRQx – одно событие. Устройства подключаются к таким линиям.
Приоритет предоставления прерываний – алгоритм, по которому контроллер прерываний определяет приоритеты ВУ, подключаемых к одной линии IRQx (?).
В MS-DOS и Windows используется линейная приоритетная схема: устройства имеют статические приоритеты, которые определяются номером линии IRQx.
Возможны и другие алгоритмы.
Например, циклическая схема: после завершения обработки прерываний устройство становится самым низкоприоритетным.
Наивысший приоритет предоставляется асинхронным устройствам, а также системным событиям. Низший – синхронным устройствам.
Главный недостаток – ограничено число линий запроса, а следовательно и устройств.
Можно построить иерархическую схему (расширяем вторым контроллером):

Третий контроллер подключить нельзя, т.к. не хватит линий прерываний. Шина тоже может накладывать ограничение на число прерываний (ISA – 15).
Если количество устройств очень большое, нельзя использовать эту схему!
Чтобы не потерять короткие прерывания используется маска запомненных прерываний.
End of Interrupt – команда сброса масок блокировок и запомненных прерываний.
Нужно отправить ее контроллеру!
Нужно, чтобы на одну линию можно было подключить сколько угодно устройств – в этом случае нельзя использовать контроллер!
Приоритетная (параллельная) схема обработки прерываний
Производится программная или аппаратная привязка.
Устройство выставляет номер вектора на шину.
Но в цикле прерывания только одно устройство должно выставлять номер на шину.
Для этого вводится сигнал ответа устройству данного приоритета. ЦП должен иметь столько линий подтверждения прерываний, сколько у него линий запроса.
ACK должен попасть только к одному устройству данного приоритета!
Устройства с одинаковым приоритетом имеют «внутренний приоритет», определяемый их близостью к ЦП.
В этой схеме есть проблема, связанная с блокировкой запросов (в прошлой схеме проблем не было, блокировкой занимался контроллер).
С запросами связывается битовая маска, которая транслируется в слово состояния процессора. Т.е. ответственность за блокировку/разрешение прерываний возлагается на программиста (системного, конечно ;) )!
Действия, выполняемые в обработчике прерыванияintx: push ax
push si
 push ds
push ds
in ax, #port
mov ds:[si], ax
inc si
dec cx
pop
...
iret
Если темп поступления прерывания высок, не успеем все обработать.
Механизм прямого доступа к памятиЦП не участвует в обмене.
Аппаратуре нужно знать: номер порта и адрес буфера. Контроллер прямого доступа (КПДП) и есть та самая железяка!
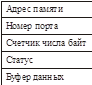
Это минимальный набор регистров
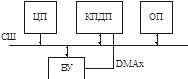
Как подключить это устройство.
По завершении операции КПДП генерирует прерывание.
Схемы организации прямого доступа:
1) Радиальная:
Канал прямого доступа резервируется для каждого устройства. ВУ выставляет к КПДП запрос DMAx с номером этого канала.
Недостаток: ограничиваем количество физических устройств, которые могут работать ПДП посредством каналов к КПДП.
2) Динамическая
Конкретное физическое устройство не привязывается к номеру канала.
Канал ПД выдается устройству при необходимости в прямом доступе и освобождается по завершению операции.
КПДП выполняет обмен между ОП и ВУ, генерируя цикл шины. В цикле шины могут присутствовать только физические адреса. Необходимо добавить (к регистрам выше) набор регистров адресации памяти, например, таблицу страниц.
Кроме того, буфер должен быть физически непрерывным.
Вопрос с кэшированием!
Параллельные вычисленияОбщие понятия.
Сильно и слабо связанные:
- Сильно связанные – общая память для всех ЦП;
- Слабо связанные – у каждого ЦП своя память.
Однородные и неоднородные:
- Однородные – все ЦП одинаковые;
- Неоднородные – разные ЦП.
Архитектуры:
- Симметричная (SMP) – сильно связанная система с однородными процессорами;
- Массово-параллельные системы (MPP) – неоднородные слабо связанные системы.
 |
Параллельность команд и параллельность данных.
1. Уровень процессов (изолированных задач)
2. Второй уровень параллельности – общие коды (процесс), общие данные, много потоков – многопоточная обработка.
3. Алгоритмическая параллельность – параллельностью обладает сам алгоритм. Например, умножение матрицы на вектор, можно считать компоненты результирующего вектора одновременно (параллельно).
4. Формами параллельности обладает и самый обычный код (параллельность на уровне машинных команд, независимые операции).
При увеличении числа процессоров скорость системы увеличивается не линейно. Это объясняется тем, что передача информации будет занимать все большую часть времени.
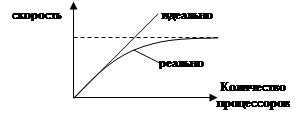 |
Перед обработкой данные надо сначала распределить между узлами, а потом передать результаты обратно.
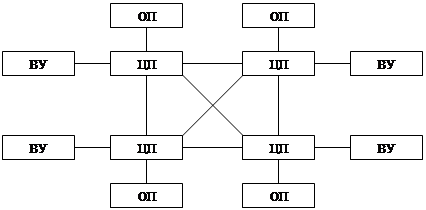
Топологии массово-параллельных систем:
Похожие работы
... различными пользователями. Наличие выделенных устройств создает для операционной системы некоторые проблемы. Для решения поставленных проблем целесообразно разделить программное обеспечение ввода-вывода на четыре слоя (рисунок 2.30): Обработка прерываний, Драйверы устройств, Независимый от устройств слой операционной системы, Пользовательский слой программного обеспечения. Рис ...
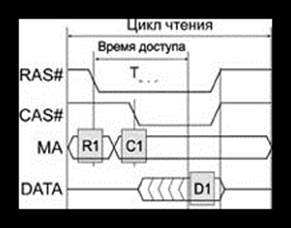
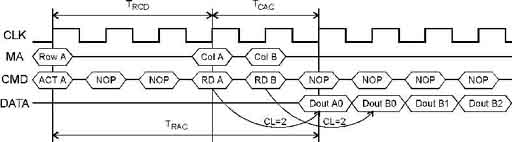
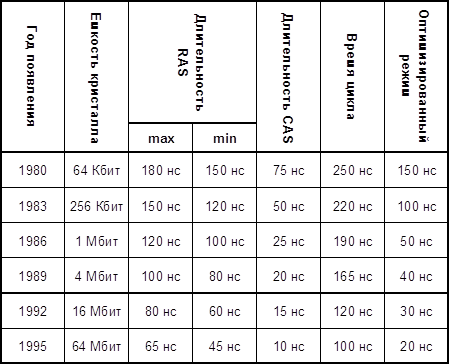
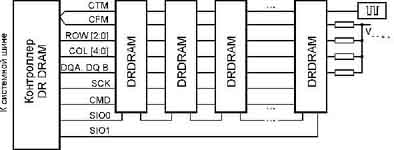
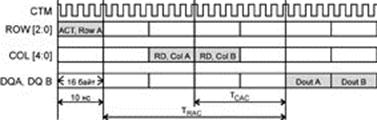
... производительность 1600 Мбайт/с на двухбайтной шине данных при частоте 400 МГц. Стандарт DRDRAM поддержан множеством производителей микросхем и модулей памяти, он претендует на роль основного высокопроизводительного стандарта для памяти компьютеров любого размера. Подсистема памяти (ОЗУ) DRDRAM состоит из контроллера памяти, канала и собственно микросхем памяти. По сравнению с DDR SDRAM при той ...

... времени суток и дням недели для различных пользователей; блокировка ПЭВМ на время отсутствия пользователя на рабочем месте; контроль и тестирование средств защиты; По требованию Заказчика БАЗОВАЯ СИСТЕМА ВВОДА-ВЫВОДА может быть дополнена программами обслуживания специальных устройств, а также введена поддержка национальных таблиц маркировки клавиатур и кодовых таблиц знакогенератора адаптера ...

... также невысока и обычно составляет около 100 кбайт/с. НКМЛ могут использовать локальные интерфейсы SCSI. Лекция 3. Программное обеспечение ПЭВМ 3.1 Общая характеристика и состав программного обеспечения 3.1.1 Состав и назначение программного обеспечения Процесс взаимодействия человека с компьютером организуется устройством управления в соответствии с той программой, которую пользователь ...
0 комментариев