Навигация
Расчет коэффициентов дискриминантной функции
21725
знаков
3
таблицы
8
изображений
2. Расчет коэффициентов дискриминантной функции
Коэффициенты дискриминантной функции ![]() определяются таким образом, чтобы
определяются таким образом, чтобы ![]() (x) и
(x) и ![]() (x) как можно больше различались между собой, т.е. чтобы для двух множеств (классов) было максимальным выражение
(x) как можно больше различались между собой, т.е. чтобы для двух множеств (классов) было максимальным выражение
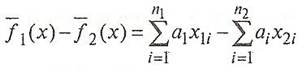
(4)
Тогда можно записать следующее:
![]() (5)
(5)
где k- номер группы; p – число переменных, характеризующих каждое наблюдение.
Обозначим дискриминантную функцию ![]() (x) как
(x) как ![]() (k - номер группы, t - номер наблюдения в группе). Внутригрупповая вариация может быть измерена суммой квадратов отклонений:
(k - номер группы, t - номер наблюдения в группе). Внутригрупповая вариация может быть измерена суммой квадратов отклонений:
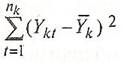 (6)
(6)
По обеим группам это будет выглядеть следующим образом:
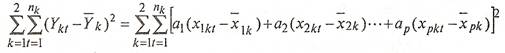 (7)
(7)
В матричной форме это выражение может быть записано так:
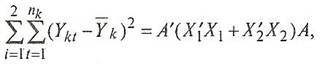 (8)
(8)
где А - вектор коэффициентов дискриминантной функции;
![]() - транспонированная матрица отклонений наблюдаемых значений исходных переменных от их средних величин в первой группе
- транспонированная матрица отклонений наблюдаемых значений исходных переменных от их средних величин в первой группе
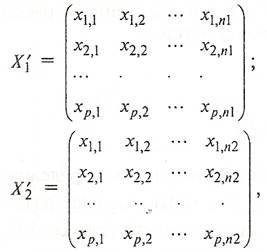 (9)
(9)
![]() - аналогичная матрица для второй группы.
- аналогичная матрица для второй группы.
Объединенная ковариационная матрица ![]() определяется так:
определяется так:
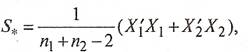 (10)
(10)
Следовательно выражение (8) дает оценку внутригрупповой вариации и его можно записать в виде:
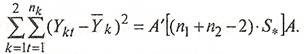 (11)
(11)
Межгрупповая вариация может быть измерена как
![]() (12)
(12)
При нахождении коэффициентов дискриминантной функции ![]() следует исходить из того, что для рассматриваемых объектов внутригрупповая вариация должна быть минимальной, а межгрупповая вариация - максимальной. В этом случае мы достигнем наилучшего разделения двух групп, т.е. необходимо, чтобы величина F была максимальной:
следует исходить из того, что для рассматриваемых объектов внутригрупповая вариация должна быть минимальной, а межгрупповая вариация - максимальной. В этом случае мы достигнем наилучшего разделения двух групп, т.е. необходимо, чтобы величина F была максимальной:
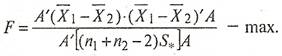 (13)
(13)
В точке, где функция F достигает максимума, частные производные по ![]() будут равны нулю. Если вычислить частные производные
будут равны нулю. Если вычислить частные производные
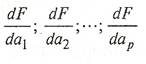 (14)
(14)
и приравнять их нулю, то после преобразований получим выражение:
![]() (15)
(15)
Из этой формулы и определяется вектор коэффициентов дискриминантной функции (А)
Полученные значения коэффициентов подставляют в формулу (1) и для каждого объекта в обеих группах (множествах) вычисляют дискриминантные функции, затем находят среднее значение для каждой группы. Таким образом, каждое i-е наблюдение, которое первоначально описывалось m переменными, будет как бы перемещено в одномерное пространство, т.е. ему будет соответствовать одно значение дискриминантной функции, следовательно, размерность признакового пространства снижается.
3. Классификация при наличии двух обучающих выборок
Перед тем как приступить непосредственно к процедуре классификации, нужно определить границу, разделяющую в частном случае две рассматриваемые группы. Такой величиной может быть значение функции, равноудаленное от ![]() и
и ![]() , т.е.
, т.е.
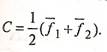 (16)
(16)
Величина С называется константой дискриминации.
На рис.1 видно, что объекты, расположенные над прямой f(x)=![]() +
+![]() +…+
+…+ ![]() =C , находятся ближе к центру множества
=C , находятся ближе к центру множества ![]() и, следовательно, могут быть отнесены к первой группе, а объекты, расположенные ниже этой прямой, ближе к центру второго множества, т.е. относятся ко второй группе. Если граница между группами выбрана так, как сказано выше, то суммарная вероятность ошибочной классификации минимальная.
и, следовательно, могут быть отнесены к первой группе, а объекты, расположенные ниже этой прямой, ближе к центру второго множества, т.е. относятся ко второй группе. Если граница между группами выбрана так, как сказано выше, то суммарная вероятность ошибочной классификации минимальная.
Рассмотрим пример использования дискриминантного анализа для проведения многомерной классификации объектов. При этом в качестве обучающих будем использовать сначала две выборки, принадлежащие двум классам, а затем обобщим алгоритм классификации на случай k классов.
Пример 1. Имеются данные по двум группам промышленных предприятий машиностроительного комплекса:
![]() -фондоотдача основных производственных фондов, руб.;
-фондоотдача основных производственных фондов, руб.;
![]() -затраты на рубль произведенной продукции, коп.;
-затраты на рубль произведенной продукции, коп.;
![]() -затраты на сырье и материалов на один рубль продукции, коп.
-затраты на сырье и материалов на один рубль продукции, коп.
| Номер | Х1 | Х2 | ХЗ | |
| предприятия | ||||
| 1 | 0,50 | 94,0 | 8,50 | |
| l-я группа | 2 | 0,67 | 75,4 | 8,79 |
| 3 | 0,68 | 85,2 | 9,10 | |
| 4 | 0,55 | 98,8 | 8,47 | |
| 5 | 1,52 | 81,5 | 4,95 | |
| 2-я группа | 6 | 1,20 | 93,8 | 6,95 |
| 7 | 1,46 | 86,5 | 4,70 |
Необходимо провести классификацию четырех новых предприятий, имеющих следующие значения исходных переменных:
l-е предприятие: ![]() = 1,07,
= 1,07, ![]() =93,5,
=93,5, ![]() =5,30,
=5,30,
2-е предприятие: ![]() = 0,99,
= 0,99, ![]() =84,0,
=84,0, ![]() =4,85,
=4,85,
3-е предприятие: ![]() = 0,70,
= 0,70, ![]() =76,8,
=76,8, ![]() =3,50,
=3,50,
4-е предприятие: ![]() = 1,24,
= 1,24, ![]() =88,0,
=88,0, ![]() =4,95.
=4,95.
Для удобства запишем значения исходных переменных для каждой группы предприятий в виде матриц ![]() и
и ![]() :
:
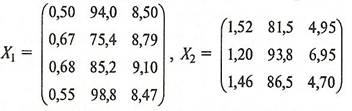 (17)
(17)
Рассчитаем среднее значение каждой переменной в отдельных группах для определения положения центров этих групп:
I гр. ![]() =0,60,
=0,60, ![]() =88,4,
=88,4, ![]() =8,72
=8,72
II гр. ![]() =1,39,
=1,39, ![]() =87,3,
=87,3, ![]() =5,53.
=5,53.
Дискриминантная функция f(x) в данном случае имеет вид:
f(х) = ![]() +
+![]() +
+![]() (18)
(18)
Коэффициенты ![]() ,
, ![]() и
и ![]() вычисляются по формуле:
вычисляются по формуле:
A=![]() (
(![]() -
-![]() ), (19)
), (19)
где ![]() и
и ![]() - векторы средних в первой и второй группах; А - вектор коэффициентов;
- векторы средних в первой и второй группах; А - вектор коэффициентов; ![]() - матрица, обратная совместной ковариационной матрице.
- матрица, обратная совместной ковариационной матрице.
Для определения совместной ковариационной матрицы ![]() нужно рассчитать матрицы
нужно рассчитать матрицы ![]() и
и ![]() . Каждый элемент этих матриц представляет собой разность между соответствующим значением исходной переменной
. Каждый элемент этих матриц представляет собой разность между соответствующим значением исходной переменной ![]() и средним значением этой переменной в данной группе
и средним значением этой переменной в данной группе ![]() (k - номер группы):
(k - номер группы):
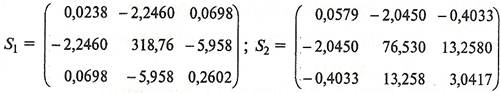
Тогда совместная ковариационная матрица ![]() будет равна:
будет равна:
![]() , (20)
, (20)
где ![]() ,
, ![]() - число объектов l-й и 2-й группы;
- число объектов l-й и 2-й группы;
 (21)
(21)
Обратная матрица ![]() будет равна:
будет равна:
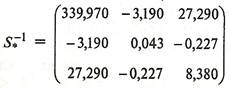 .(22)
.(22)
Отcюда находим вектор коэффициентов дискриминантной функции по формуле:
 (23)
(23)
т.е. ![]() =-185,03,
=-185,03, ![]() =1,84,
=1,84, ![]() =4,92.
=4,92.
Подставим полученные значения коэффициентов в формулу (18) и рассчитаем значения дискриминантной функции для каждого объекта:
 (24)
(24)
Тогда константа дискриминации С будет равна:
С =![]() (94,4238-70,0138) = 12,205.
(94,4238-70,0138) = 12,205.
После получения константы дискриминации можно проверить правильность распределения объектов в уже существующих двух классах, а также провести классификацию новых объектов.
Рассмотрим, например, объекты с номерами 1, 2, З, 4. Для того чтобы отнести эти объекты к одному из двух множеств, рассчитаем для них значения дискриминантных функций (по трем переменным):
![]() = -185,03 х 1,07 + 1,84 х 93,5 + 4,92 х 5,30 = 0,1339,
= -185,03 х 1,07 + 1,84 х 93,5 + 4,92 х 5,30 = 0,1339,
![]() = -185,03 х 0,99 + 1,84 х 84,0 + 4,92 х 4,85 = -4,7577,
= -185,03 х 0,99 + 1,84 х 84,0 + 4,92 х 4,85 = -4,7577,
![]() = -185,03 х 0,70 + 1,84 х 76,8 + 4,92 х 3,50 = 29,0110,
= -185,03 х 0,70 + 1,84 х 76,8 + 4,92 х 3,50 = 29,0110,
![]() = -185,03 х 1,24 + 1,84 х 88,0 + 4,92 х 4,95 = -43,1632.
= -185,03 х 1,24 + 1,84 х 88,0 + 4,92 х 4,95 = -43,1632.
Таким образом, объекты 1, 2 и 4 относятся ко второму классу, а объект 3 относится к первому классу, так как ![]() < с,
< с, ![]() < с,
< с, ![]() > с,
> с, ![]() < с.
< с.
Похожие работы
... , национальные и иные особенности при выходе на зарубежные рынки. При проведении вторичных исследований значимость внутренней или внешней информации определяется в зависимости от целей исследования и объекта исследования. 1.2 Методы обработки маркетинговой информации После того как маркетолог собрал информацию, наступает этап оценки и анализа данных. Прежде чем задействовать сложные методы ...
... экспертами, но, как отмечают авторы, для уточнения значений требуется ее дальнейшая производственная проверка. Экспертные системы При наличии разнообразных методов окончательное определение формулировки прогноза лавинной опасности остается за специалистом. Образование, опыт, интуиция, способность оценить неучтенные прогностическими технологиями факторы, выявить ведущий из них на текущий момент ...


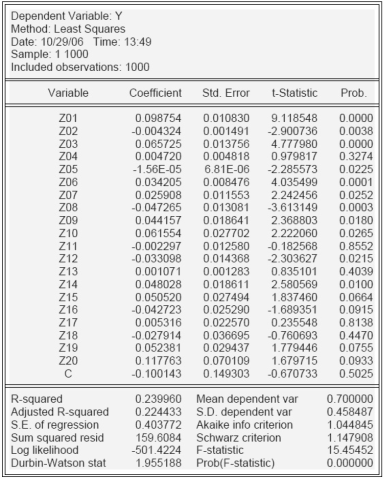
... практический характер. Результаты, полученные в работе, могут быть использованы в дальнейших исследованиях по управлению риском и могут быть применены в банках. Глава 1. Обзор моделей оценки кредитного риска 1.1. Понятие качества и прозрачности методик Проблема количественной оценки и анализа кредитных рисков и рейтингов заемщиков и создания резервов на случай дефолта является ...
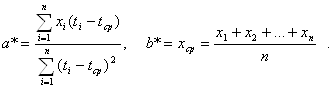
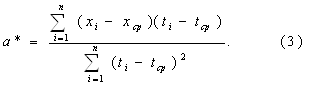

... исходить из вида обрабатываемых данных. В соответствии с современными воззрениями делим эконометрику и прикладную статистику на четыре области: - статистика случайных величин (одномерная статистика); - многомерный статистический анализ; - статистика временных рядов и случайных величин; - статистика объектов нечисловой природы. В первой области элемент выборки - число, во второй - вектор, в ...
0 комментариев