Навигация
Взаимосвязь между дискриминантными переменными и дискриминантными функциями
21725
знаков
3
таблицы
8
изображений
5. Взаимосвязь между дискриминантными переменными и дискриминантными функциями
Для оценки вклада отдельной переменной в значение дискриминантной функции целесообразно пользоваться стандартизованными коэффициентами дискриминантной функции. Стандартизованные коэффициенты можно рассчитать двумя путями:
·стандартизовать значения исходных переменных таким образом, чтобы их средние значения были равны нулю, а' дисперсии - единице;
·вычислить стандартизованные коэффициенты исходя из значений коэффициентов в нестандартной форме:
·
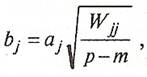 (28)
(28)
где р - общее число исходных переменных, т - число групп, ![]() - элементы матрицы ковариаций:
- элементы матрицы ковариаций:
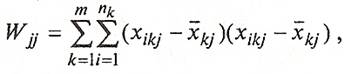 (29)
(29)
где i - номер наблюдения, j - номер переменной, k - номер класса, ![]() - количество объектов в k-м классе.
- количество объектов в k-м классе.
Стандартизованные коэффициенты применяют в тех случаях, когда нужно определить, какая из используемых переменных вносит наибольший вклад в величину дискриминантной функции. В примере с двумя классами, рассмотренном выше, дискриминантная функция имела вид:
f= -185,03Х1 + 1,84Х2 + 4,92Хз .
Следовательно, наибольший вклад в величину дискриминантной функции вносит переменная X1.
Определим значения стандартизованных коэффициентов и запишем новое значение дискриминантной функции:
![]() (30)
(30)
где ![]() =
=![]()
Стандартизованные коэффициенты дискриминантной функции тоже показывают определяющее влияние первой переменной на величину дискриминантной функции.
Помимо определения вклада каждой исходной переменной в дискриминантную функцию, можно проанализировать и степень корреляционной зависимости между ними.
Для оценки тесноты связи между отдельными переменными и дискриминантными функциями служат коэффициенты корреляции, которые называются структурными коэффициентами. По величине структурных коэффициентов судят о связи между переменными и дискриминантными функциями. Структурные коэффициенты позволяют также в случае необходимости присвоить имя каждой функции. Они могут быть рассчитаны в целом по всей совокупности объектов (R) и для каждого класса отдельно (R![]() ).
).
Покажем на примере 1 расчет структурных коэффициентов в целом для трех классов. Исходные данные для расчета коэффициентов представлены в табл. 3. Вычисленные структурные коэффициенты (R![]() f) имеют следующие значения:
f) имеют следующие значения:
Rx1f= 0,650 RX2f = -0,576 RХЗf = -0,506 Rx4f = -0,951
Rx1jl = -0,036 Rx2j1 = 0,486 RхЗjl = -0,211 Rx4j1 = 0,217
Rx1f2 = -0,728 Rx2f2 = 0,878 RХЗf2 = 0,511 Rx4f2 = -0,998
Rx1fJ = -0,713 Rх1JЗ = 0,258 RхЗfJ = -0,122 Rx4fJ = -0,998.
Таблица 3 – Исходные данные
| Номер | Х1 | Х2 | ХЗ | Х4 |
|
| наблюдения | |||||
| 1 | 0,50 | 94,0 | 8,50 | 6707 | -31973,089 |
| 2 | 0,67 | 75,4 | 8,79 | 5037 | -18122,238 |
| 3 | 0,68 | 85,2 | 9,10 | 3695 | -6930,930 |
| 4 | 0,55 | 98,8 | 8,47 | 6815 | -32812,109 |
| 5 | 1,52 | 81,5 | 4,95 | 3211 | -13434,229 |
| 6 | 1,20 | 93,8 | 6,95 | 2890 | -10812,723 |
| 7 | 1,46 | 86,5 | 4,70 | 2935 | -11139,514 |
| 8 | 1,70 | 80,0 | 4,50 | 3510 | -14272,295 |
| 9 | 1,65 | 85,0 | 4,80 | 2900 | -9573,076 |
| 10 | 1,49 | 78,5 | 4,10 | 2850 | -9348,104 |
Если рассматривать абсолютные значения структурных коэффициентов, видно, например, что наибольшая зависимость функций ![]() наблюдается от переменной
наблюдается от переменной ![]() , а функций
, а функций ![]() и
и ![]() - от переменной
- от переменной ![]() .
.
Различные знаки у структурных коэффициентов можно интерпретировать следующим образом. Исходные переменные, имеющие различное направление связи с дискриминантной функцией, т.е. положительные или отрицательные структурные коэффициенты, будут ориентировать объекты в различных направлениях, удаляя или приближая их к центрам соответствующих классов. Из данного примера видно, что переменная X1 и функция ![]() имеют коэффициент -0,036. Это значит, что при увеличении значений
имеют коэффициент -0,036. Это значит, что при увеличении значений ![]() функция
функция ![]() уменьшается. Допустим, все разности (
уменьшается. Допустим, все разности (![]() -
-![]() ) > о ( l= 2, ... , k) для i-го наблюдения, значит его следует отнести к первому классу. Если у классифицируемых объектов значения переменной
) > о ( l= 2, ... , k) для i-го наблюдения, значит его следует отнести к первому классу. Если у классифицируемых объектов значения переменной ![]() будут возрастать, то значения функции
будут возрастать, то значения функции ![]() для этих объектов будут уменьшаться, что приведет к отдалению их от центра первого класса. В конце концов
для этих объектов будут уменьшаться, что приведет к отдалению их от центра первого класса. В конце концов ![]() достигнет у p-го объекта «критического» значения, которому будет соответствовать неравенство (
достигнет у p-го объекта «критического» значения, которому будет соответствовать неравенство (![]() -
-![]() ) < 0, т.е. i-й объект уже не попадет в первый класс. Аналогичные рассуждения проводятся и для положительных структурных коэффициентов.
) < 0, т.е. i-й объект уже не попадет в первый класс. Аналогичные рассуждения проводятся и для положительных структурных коэффициентов.
Заключение
Дискриминантный анализ так же, как и кластерный анализ, относится к методам многомерной классификации, но при этом базируется на иных предпосылках. Основное отличие заключается в том, что в ходе дискриминантного анализа новые кластеры не образуются, а формулируется правило, по которому новые единицы совокупности относятся к одному из уже существующих множеств (классов). Основанием для отнесения каждой единицы совокупности к определенному множеству служит величина дискриминантной функции, рассчитанная по соответствующим значениям дискриминантных переменных.
Основными проблемами дискриминантного анализа являются, во-первых, определение набора дискриминантных переменных, Bo-вторых, выбор вида дискриминантной функции. Существуют различные критерии последовательного отбора переменных, позволяющих получить наилучшее различение множеств. Можно также воспользоваться алгоритмом пошагового дискриминантного анализа, который в литературе подробно описан. После уточнения оптимального набора дискриминантных переменных исследователю предстоит решить вопрос о выборе вида дискриминантной функции, Т.е. выбрать вид разделяющей поверхности. Чаще всего на практике применяют линейный дискриминантный анализ. В этом случае дискриминантная функция представляет собой либо прямую, либо плоскость (гиперплоскость).
Линейная дискриминантная функция не всегда подходит в качестве описания разделяющей поверхности между множествами. Например, в тех случаях, когда различаемые множества не являются выпуклыми, правомерно предположить, что дискриминантная функция, приводящая к наименьшим ошибкам классификации, не может быть линейной.
Если множества, используемые в качестве обучающих выборок, близко расположены друг к другу, то возрастает вероятность ошибочной классификации новых объектов, особенно в тех случаях, когда классифицируемый объект сильно удален от центров обоих множеств. Складывается ситуация, при которой распознавание объекта затруднено. Одним из возможных выходов в таком случае является пересмотр набора дискриминантных переменных.
Дискриминантный анализ можно использовать как метод прогнозирования (предсказания) поведения наблюдаемых единиц статистической совокупности на основе имеющихся стереотипов поведения аналогичных объектов, входящих в состав объективно существующих или сформированных по определенному принципу множеств (обучающих выборок).
Список использованной литературы
1. Многомерный статистический анализ в экономике. Под редакцией В.Н. Тамашевича. Москва.1999г.
2. Эконометрика и эконометрическое прогнозирование. Мухамедиев Б.М. Алматы. 2007г.
3. Многомерные статистические методы. Дубров А.М., Мхитарян В.С., Трошин Л.И. Москва. 2003г.
4. Эконометрика. Под редакцией Елисеевой И.И. Москва. 2005г.
5. Эконометрика. Балдин С.В., Быстров О.Ф., Соколов М.М. Москва. 2004г.
Похожие работы
... , национальные и иные особенности при выходе на зарубежные рынки. При проведении вторичных исследований значимость внутренней или внешней информации определяется в зависимости от целей исследования и объекта исследования. 1.2 Методы обработки маркетинговой информации После того как маркетолог собрал информацию, наступает этап оценки и анализа данных. Прежде чем задействовать сложные методы ...
... экспертами, но, как отмечают авторы, для уточнения значений требуется ее дальнейшая производственная проверка. Экспертные системы При наличии разнообразных методов окончательное определение формулировки прогноза лавинной опасности остается за специалистом. Образование, опыт, интуиция, способность оценить неучтенные прогностическими технологиями факторы, выявить ведущий из них на текущий момент ...


... практический характер. Результаты, полученные в работе, могут быть использованы в дальнейших исследованиях по управлению риском и могут быть применены в банках. Глава 1. Обзор моделей оценки кредитного риска 1.1. Понятие качества и прозрачности методик Проблема количественной оценки и анализа кредитных рисков и рейтингов заемщиков и создания резервов на случай дефолта является ...
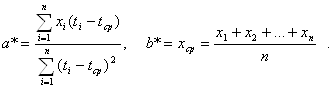

... исходить из вида обрабатываемых данных. В соответствии с современными воззрениями делим эконометрику и прикладную статистику на четыре области: - статистика случайных величин (одномерная статистика); - многомерный статистический анализ; - статистика временных рядов и случайных величин; - статистика объектов нечисловой природы. В первой области элемент выборки - число, во второй - вектор, в ...
0 комментариев