Содержание
1. Виды и формы связей, различаемые в статистике. 3
2. Оценка достоверности коэффициента корреляции. 6
3. Доверительные интервалы для оценки. 16
Список литературы.. 24
1. Виды и формы связей, различаемые в статистике
Современная наука об обществе объясняет суть явлений через изучение взаимосвязей явлений. Объем продукции предприятия связан с численностью работников, стоимостью основных фондов и т.д.
Различают два типа взаимосвязей между различными явлениями и их признаками: функциональную или жестко детерминированную и статистическую или стохастически детерминированную.
Функциональная связь – это вид причинной зависимости, при которой определенному значению факторного признака соответствует одно или несколько точно заданных значений результативного признака. Например, при у = Öx – связь между у и х является строго функциональной, но значению х = 4 соответствует не одно, а два значения y1 = +2; y2= -2.
Стохастическая связь – это вид причинной зависимости, проявляющейся не в каждом отдельном случае, а в общем, в среднем, при большом числе наблюдений. Например, изучается зависимость роста детей от роста родителей. В семьях, где родители более высокого роста, дети в среднем ниже, чем родители. И, наоборот, в семьях, где родители ниже ростом, дети в среднем выше, чем родители. Еще один пример: потребление продуктов питания пенсионеров зависит от душевого дохода: чем выше доход, тем больше потребление. Однако такого рода зависимости проявляются лишь при большом числе наблюдений.
Корреляционная связь – это зависимость среднего значения результативного признака от изменения факторного признака; в то время как каждому отдельному значению факторного признака Х может соответствовать множество различных значений результативного (Y).
Задачами корреляционного анализа являются:
1) изучение степени тесноты связи 2 и более явлений;
2) отбор факторов, оказывающих наиболее существенное влияние на результативный признак;
3) выявление неизвестных причинных связей. Исследование корреляционных зависимостей включает ряд этапов:
1) предварительный анализ свойств совокупности;
2) установление факта наличия связи, определение ее направления и формы;
3) измерение степени тесноты связи между признаками;
4) построение регрессионной модели, т.е. нахождение аналитического выражения связи;
5) оценку адекватности модели, ее экономическую интерпретацию и практическое использование.
Корреляционная связь между признаками может возникать различными путями. Важнейший путь - причинная зависимость результативного признака (его вариации) от вариации факторного признака. Например, Х – балл оценки плодородия почв, Y – урожайность сельскохозяйственной культуры. Здесь ясно, какой признак выступает как независимая переменная (фактор), а какой как зависимая переменная (результат).
Очень важно понимать суть изучаемой связи, поскольку корреляционная связь может возникнуть между двумя следствиями общей причины. Здесь можно привести множество примеров. Так, классическим является пример, приведенный известным статистиком начала XX в. А.А. Чупровым. Если в качестве признака Х взять число пожарных команд в городе, а за признак Y – сумму убытков в городе от пожаров, то между признаками Х и Y в городах обнаружится значительная прямая корреляция. В среднем, чем больше пожарников в городе, тем больше убытков от пожаров. В чем же дело? Данную корреляцию нельзя интерпретировать как связь причины и следствия, оба признака – следствия общей причины – размера города. В крупных городах больше пожарных частей, но больше и пожаров, и убытков от них за год, чем в мелких.
Современный пример. Сразу после 17 августа 1998 г. резко возросли цена валюты и объем покупки валюты частными лицами. Здесь также нельзя рассматривать эти два явления как причину и следствие. Общая причина – обострение финансового кризиса, приведшее к росту курсовой стоимости валюты и стремлению населения сохранить свои накопления в твердой валюте. Такого рода корреляцию называют ложной корреляцией.
Корреляция возникает и в случае, когда каждый из признаков и причина, и следствие. Например, при сдельной оплате труда существует корреляция между производительностью труда и заработком. С одной стороны, чем выше производительность труда, тем выше заработок. С другой – высокий заработок сам по себе является стимулирующим фактором, заставляющим работника трудиться более интенсивно.
По направлению выделяют связь прямую и обратную, по аналитическому выражению – прямолинейную и нелинейную.
В начальной стадии анализа статистических данных не всегда требуются количественные оценки, достаточно лишь определить направление и характер связи, выявить форму воздействия одних факторов на другие. Для этих целей применяются методы приведения параллельных данных, аналитических группировок и графический.
Метод приведения параллельных данных основан на сопоставлении 2 или нескольких рядов статистических величин. Такое сопоставление позволяет установить наличие связи и получить представление о ее характере. Сравним изменения двух величин (табл. 1).
Таблица 1
| Х | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Y | 5 | 9 | 6 | 10 | 12 | 17 | 15 | 20 | 23 |
С увеличением Х возрастает и Y, поэтому связь между ними можно описать уравнением прямой.
Метод аналитических группировок характеризует влияние качественного признака на относительные средние величины, на показатели вариации количественных признаков. В качестве группировочного признака выбирается факторный. В таблице размещают средние значения одного или нескольких результативных признаков. Изменения факторного признака при переходе от одной группы к другой вызывают соответствующие изменения результативного признака (табл. 2).
Оборачиваемость в днях – факторный признак, обозначаемый обычно X, а прибыль – результативный – Y. Табл. 9.2 ясно демонстрирует присутствие связи между признаками, это – отрицательная связь. Судить о том, линейная она или нет, по этим данным сложно.
Таблица 2. Характеристика зависимости прибыли малых предприятий от оборачиваемости оборотных средств на 1998 г.
| Продолжительность оборота средств, дн. (Х) | Число малых предприятий | Средняя прибыль, млн. руб. (Y) |
| 40–50 | 6 | 14,57 |
| 51–70 | 8 | 12,95 |
| 71–101 | 6 | 7,40 |
| Итого | 20 | 11,77 |
Коэффициент парной корреляции, исчисленный по выборочным данным, является случайной величиной. С уменьшением числа наблюдений надежность коэффициента корреляции падает. С увеличением числа наблюдений (свыше 500) распределение коэффициента корреляции r (не превышающее 0,9) стремится к нормальному.
Полученный из выборки коэффициент корреляции r является оценкой коэффициента корреляции ρ в генеральной совокупности.
По общему правилу проверки статистических гипотез:
– если tнабл £ tкр, нулевую гипотезу о том, что между Х и Y отсутствует корреляционная связь (Н0: r = 0), нельзя отклонить на заданном уровне значимости а;
– если tнабл< tкр, нулевая гипотеза отклоняется в пользу альтернативной о том, что коэффициент корреляции значимо отличается от нуля (Н1: r¹0), т.е. о наличии линейной корреляционной зависимости между Х и Y.
Критерий tрасч подчиняется закону распределения Стьюдента с п – 2 степенями свободы.
При малом числе наблюдений в выборке и высоком коэффициенте корреляции (распределение r отличается от нормального) для проверки гипотезы о наличии корреляционной связи, а также при построения доверительного интервала применяется z-преобразование Фишера.
При выявлении статистической зависимости по данным аналитической группировки в качестве меры степени тесноты связи может быть использовано эмпирическое корреляционное отношение (hэмп)
Чем ближе hэмп к 1, тем теснее связь между переменными Х и Y, тем больше колеблемость Y объясняется колеблемостью X.
Квадрат эмпирического корреляционного отношения (h2эмп) называют коэффициентом детерминации. Он показывает, какая часть Y колеблемости объясняется колеблемостью X.
В случае линейной регрессионной зависимости r = hтеор. Если связь – нелинейная, h < hтеор. Это позволяет использовать hтеор в качестве меры линейности связи между переменными X и Y. Если линейный коэффициент корреляции Пирсона (r) мало отличается от теоретического корреляционного отношения (hтеор), т.е. r» hтеор, то зависимость между переменными близка к линейной. В противном случае имеет, место нелинейная зависимость между X и Y.
В уравнении парной регрессии – 2 параметра: b0 и b1, т.е. т = 2.
Критическое значение F определяется по таблицам распределения Фишера по уровню значимости α и числу степеней свободы.
Наблюдаемое значение (Fнабл) необходимо сравнить с критическим (Fкр). По общему правилу проверки статистических гипотез:
– если Fнабл £ Fкр, нулевую гипотезу (H1:h = 0) о том, что h незначим, нельзя отклонить;
– если Fнабл > Fкр нулевая гипотеза отклоняется в пользу альтернативной (H1:h ¹ 0) о том, что h значимо отличается от нуля.
Если п объектов какой-либо совокупности N пронумерованы в соответствии с возрастанием или убыванием какого-либо признака X, то говорят, что объекты ранжированы по этому признаку. Ранг xi, указывает место, которое занимает i-й объект среди других n объектов, расположенных в соответствии с признаком Х (i= 1,2,…. п). Например, при исследовании рынка мы можем задать вопрос с целью выяснения предпочтений потребителей при выборе товара (при покупке акций, мороженого, водки и т.п.) таким образом, чтобы они распределили товар в порядке возрастания (или убывания) своих потребительских предпочтений. Если мы имеем 2 набора ранжированных данных, то можно попытаться установить степень линейной зависимости между ними. Предположим, имеется 5 продуктов, расположенных по порядку предпочтений от 1 до 5 в соответствии с двумя характеристиками А и В (табл. 3).
Таблица 3
| Характеристики для ранжирования | Продукт | ||||
| V | W | X | Y | Z | |
| А | 2 | 5 | 1 | 3 | 4 |
| B | 1 | 3 | 2 | 4 | 5 |
Для определения наличия взаимосвязи между ранговыми оценками используется коэффициент ранговой корреляции Спирмена. Его расчет основан на различии между рангами:
D = Ранг А – Ранг В.
Альтернативные признаки – это признаки, принимающие только два возможных значения. Исследование их корреляции основано на показателях, построенных на четырехклеточных таблицах, в которых сводятся значения признаков:
| а | в |
| с | d |
Например, требуется измерить связь между прививками от гриппа и пониженной заболеваемостью от гриппа в группе случайно отобранных студентов (табл. 4).
Таблица 4
| Заболели | Не заболели | Итого | |
| Привитые | 30 | 20 | 50 |
| Непривитые | 15 | 5 | 20 |
| Всего | 45 | 25 | 70 |
Изучение степени тесноты взаимосвязи между признаками было проведено с помощью корреляционного анализа (расчета различных мер связи).
Уточнение формы связи, нахождение ее аналитического выражения производится путем построения уравнения связи (уравнения регрессии).
Регрессия – это односторонняя статистическая зависимость.
Уравнение регрессии позволяет определить, каким в среднем будет значение результативного признака (Y) при том или ином значении факторного признака (X), если остальные факторы, влияющие на Y и не связанные с X, рассматривались неизменными (т.е. мы абстрагировались от них).
К задачам регрессионного анализа относятся:
1) установление формы зависимости;
2) определение функции регрессии;
3) оценка неизвестных значений зависимой переменной.
По аналитическому выражению различают прямолинейную и криволинейную связи.
Прямолинейная связь имеет место, когда с возрастанием (или убыванием) значений Х значения Y увеличиваются (или уменьшаются) более или менее равномерно.
В этом случае уравнение связи записывается так:
`yх = b0 + b1х.
Криволинейная форма связи может выражаться различными кривыми, из которых простейшими являются:
1) парабола второго порядка
`yх = b0 + b1х +b2х2;
2) гипербола
`yx =b0+b1 /x;
3) показательная
`yx = b0b1x;
либо в логарифмическом виде
ln`yx = lnb0 + xlnb1.
После определения формы связи, т.е. вида уравнения регрессии, по эмпирическим данным определяют параметры искомого уравнения.
При этом отыскиваемые параметры должны быть такими, чтобы рассчитанные по уравнению теоретические значения результативного признака максимально приближались к эмпирическим данным.
Чаще всего определение параметров уравнения регрессии осуществляется с помощью метода наименьших квадратов, в котором предполагается, что сумма квадратов отклонений теоретических значений от эмпирических должна быть минимальной,
В зависимости от формы связи в каждом конкретном случае определяется своя система уравнений, удовлетворяющая принципу минимизации.
Предположение о парной линейной зависимости между Х и Y можно описать функцией
Y = b0 + b1Х + и,
где b0, b1 – истинные значения параметров уравнения регрессии в генеральной совокупности; и – случайная составляющая.
Существует несколько причин возникновения случайной составляющей:
1) невключение объясняющих переменных в уравнение регрессии;
2) агрегирование объясняющих переменных, включенных в уравнение регрессии;
3) неправильное описание структуры модели, т.е. неверный выбор объясняющих переменных;
4) неправильная функциональная спецификация модели. Например, для моделирования использована линейная функция, в то время как зависимость между переменными – нелинейная;
5) ошибки наблюдения (ошибки данных).
По выборочным данным определяются оценки истинных (в случае правильной спецификации модели) параметров уравнения регрессии и случайной составляющей
`yx=b0+b1х+e
где b0, b1, е – оценки неизвестных b0, b1, и. В случае парной линейной зависимости вида
`yx=b0+b1х
В настоящее время необходимость в ручных расчетах отпала, так как существует множество компьютерных программ, реализующих методы регрессионного анализа. Важно понимать смысл параметров и уметь их адекватно интерпретировать.
На основе уравнений регрессии часто рассчитывают коэффициенты эластичности результативного признака относительно факторного.
Коэффициент эластичности (Э) показывает, на сколько процентов в среднем изменится результативный признак Y при изменении факторного признака Х на 1%.
Рассмотрим методы регрессионного и корреляционного анализов. Предположим, что нас интересует выручка от продажи баночного пива в магазинах города в течение дня. Мы провели исследование в 20 случайно выбранных магазинах и получили следующие данные (табл. 6):
Таблица 6. Данные исследования
| Номер магазина | Число посетителей | Выручка, у.е. |
| 1 | 907 | 11,20 |
| 2 | 926 | 11,05 |
| 3 | 506 | 6,84 |
| 4 | 741 | 9,21 |
| 5 | 789 | 9,42 |
| 6 | 889 | 10,08 |
| 7 | 874 | 9,45 |
| 8 | 510 | 6,73 |
| 9 | 529 | 7,24 |
| 10 | 420 | 6,12 |
| 11 | 679 | 7,63 |
| 12 | 872 | 9,43 |
| 13 | 924 | 9,46 |
| 14 | 607 | 7,64 |
| 15 | 452 | 6,92 |
| 16 | 729 | 8,95 |
| 17 | 794 | 9,33 |
| 18 | 844 | 10,23 |
| 19 | 1010 | 11,77 |
| 20 | 621 | 7,41 |
| Итого | 14,623 | 176,11 |
Для прогноза объемов продаж применим простую модель парной регрессии, в которой используется только одна факторная переменная – Х (число посетителей магазина). С увеличением числа посетителей растет выручка от продажи. Рассчитаем параметры уравнения регрессии:
`yx =b0+b1x
Для облегчения расчетов воспользуемся табл. 7.
Таблица 7
| Магазин | Число покупателей X | Выручка Y | X2 | Y2 | XY |
| 1 | 907 | 11,20 | 822 649 | 125,4400 | 10 158,40 |
| 2 | 926 | 11,05 | 857 476 | 122,1025 | 10 232,30 |
| 3 | 506 | 6,84 | 256,036 | 46,7856 | 3461,04 |
| 4 | 741 | 9,21 | 549 081 | 84,8241 | 6 824,61 |
| 5 | 789 | 9,42 | 622 521 | 88,7364 | 7 432,38 |
| 6 | 889 | 10,08 | 790 321 | 101,6064 | 8961,12 |
| 7 | 874 | 9,45 | 763 876 | 89,3025 | 8 259,30 |
| 8 | 510 | 6,73 | 260 100 | 45,2929 | 3 432,30 |
| 9 | 529 | 7,24 | 279 841 | 52,4176 | 3 829,96 |
| 10 | 420 | 6,12 | 176 400 | 37,4544 | 2 570,40 |
| 11 | 679 | 7,63 | 461 041 | 58,2169 | 5 180,77 |
| 12 | 872 | 9,43 | 760 384 | 88,9249 | 8 222,96 |
| 13 | 924 | 9,46 | 853 776 | 89,4916 | 8 741,04 |
| 14 | 607 | 7,64 | 368 449 | 58,3696 | 4 637,48 |
| 15 | 452 | 6,92 | 204304 | 47,8864 | 3 127,84 |
| 16 | 729 | 8,95 | 531 441 | 80,1025 | 6 254,55 |
| 17 | 794 | 9,33 | 630 436 | 87,0489 | 7 408,02 |
| 18 | 844 | 10,23 | 712 336 | 104,6529 | 8634,12 |
| 19 | 1010 | 11,77 | 1 020 100 | 138,5329 | 11 887,70 |
| 20 | 621 | 7,41 | 385 641 | 54,9081 | 4 601,61 |
| Итого | 14623 | 176,11 | 11 306 209 | 1 602,0971 | 134 127,90 |
Коэффициент b1 характеризует наклон линии регрессии. b1 = 0,00873. Это означает, что при увеличении Х на единицу ожидаемое значение Y возрастет на 0,00873. То есть регрессионная модель указывает на то, что каждый новый посетитель магазина в среднем увеличивает недельную выручку магазина на 0,00873 у.е. (или можно сказать, что ожидаемый прирост ежедневной выручки составит 8,73 у.е. при привлечении в магазин 100 дополнительных посетителей). Отсюда b1 может быть интерпретирован как прирост ежедневной выручки, который варьирует в зависимости от числа посетителей магазина.
Свободный член уравнения b0 = +2,423 у.е., это – эначение Y при X, равном нулю. Поскольку маловероятно число посетителей магазина, равное нулю, то можно интерпретировать b0 как меру влияния на величину ежедневной выручки других факторов, не включенных в уравнение регрессии.
Регрессионная модель может быть использована для прогноза объема ежедневной выручки. Например, мы хотим использовать модель для предсказания средней ежедневной выручки магазина, который посетят 600 покупателей.
Когда мы используем регрессионные модели для прогноза, важно помнить, что обсуждаются только значения независимых переменных, находящиеся в пределах от наименьшего до наибольшего значений факторного признака, используемые при создании модели. Отсюда, когда мы предсказываем Y по заданным значениям X, мы можем интерполировать значения в пределах заданных рангов Х, но мы не можем экстраполировать вне рангов X. Например, когда используется число посетителей для прогноза дневной выручки магазина, то мы знаем из данных примера, что их число находится в пределах от 420 до 1010. Следовательно, предсказание недельной выручки может быть сделано только для магазинов с числом покупателей от 420 до 1010 чел.
Хотя метод наименьших квадратов дает нам линию регрессии, которая обеспечивает минимум вариации, регрессионное уравнение не является идеальным в смысле предсказания, поскольку не все значения зависимого признака Y удовлетворяют уравнению регрессии. Нам необходима статистическая мера вариации фактических значений Y от предсказанных значений Y. Эта мера в то же время является средней вариацией каждого значения относительно среднего значения Y. Мера вариации относительно линии регрессии называется стандартной ошибкой оценки.
Для проверки того, насколько хорошо независимая переменная предсказывает зависимую переменную в нашей модели, необходим расчет ряда мер вариации. Первая из них – общая (полная) сумма квадратов отклонений результативного признака от средней – есть мера вариации значений Y относительно их среднего `Y. В регрессионном анализе общая сумма квадратов может быть разложена на объясняемую вариацию или сумму квадратов отклонений за счет регрессии и необъясняемую вариацию или остаточную сумму квадратов отклонений.
Сумма квадратов отклонений вследствие регрессии это – сумма квадратов разностей между `y (средним значением Y) и `yx (значением Y, предсказанным по уравнению регрессии). Сумма квадратов отклонений, не объясняемая регрессией (остаточная сумма квадратов), – это сумма квадратов разностей y и `yx. Эти меры вариации могут быть представлены следующим образом (табл. 8):
Таблица 8
| Общая сумма квадратов (ST) | = | Сумма квадратов за счет регрессии (SR) | + | Остаточная сумма квадратов (SE) |
Следовательно, 91,3% вариации еженедельной выручки магазинов могут быть объяснены числом покупателей, варьирующим от магазина к магазину. Только 8,7% вариации можно объяснить иными факторами, не включенными в уравнение регрессии.
В простой линейной регрессии г имеет тот же знак, что и b1, Если b1 > 0, то r > 0; если b1 < 0, то r < 0, если b1 = 0, то r = 0.
В нашем примере r2 = 0,913 и b1 > 0, коэффициент корреляции r = 0,956. Близость коэффициента корреляции к 1 свидетельствует о тесной положительной связи между выручкой магазина от продажи пива и числом посетителей.
Мы интерпретировали коэффициент корреляции в терминах регрессии, однако корреляция и регрессия – две различные техники. Корреляция устанавливает силу связи между признаками, а регрессия – форму этой связи. В ряде случаев для анализа достаточно найти меру связи между признаками, без использования одного из них в качестве факторного признака для другого.
3. Доверительные интервалы для оценкиДоверительные интервалы для оценки неизвестного генерального значения `yген(myх) и индивидуального значения `yi.
Поскольку в основном для построения регрессионных моделей используются данные выборок, то зачастую интерпретация взаимоотношений между переменными в генеральной совокупности базируется на выборочных результатах.
Как было сказано выше, регрессионное уравнение используется для прогноза значений Y по заданному значению X. В нашем примере показано, что при 600 посетителях магазина сумма выручки могла бы быть 7,661 у. е. Однако это значение – только точечная оценка истинного среднего значения. Мы знаем, что для оценки истинного значения генерального параметра возможна интервальная оценка.
Доверительный интервал для оценки неизвестного генерального значения `yген(myх) имеет вид
![]()
где
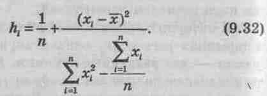
Здесь `yx – предсказанное значение Y
(`yx==b0+b1yi);
Syx – стандартная ошибка оценки;
п – объем выборки;
хi – заданное значение X.
Легко видеть, что длина доверительного интервала зависит от нескольких факторов. Для заданного уровня значимости a увеличение вариации вокруг линии регрессии, измеряемой стандартной ошибкой оценки, увеличивает длину интервала. Увеличение объема выборки уменьшит длину интервала. Более того, ширина интервала также варьирует с различными значениями X. Когда оценивается `yx по значениям X, близким к `x, то интервал тем уже, чем меньше абсолютное отклонение хi от `x (рис. 9.5).
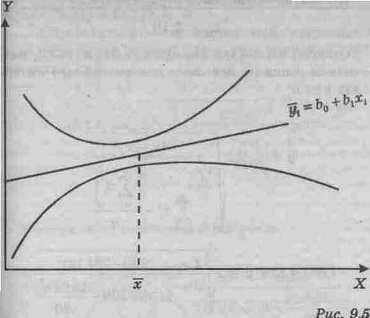
Когда оценка осуществляется по значениям X, удаленным от среднего `x, то длина интервала возрастает.
Рассчитаем 95%-й доверительный интервал для среднего значения выручки во всех магазинах с числом посетителей, равным 600. По данным нашего примера уравнение регрессии имеет вид
`yx = 2,423 + 0,00873x:
и для `xi = 600 получим `yi; =7,661, а также
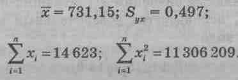
По таблице Стьюдента t18 = 2,10.
Отсюда, используя формулы (9.31) и (9.32), рассчитаем границы искомого доверительного интервала для myx
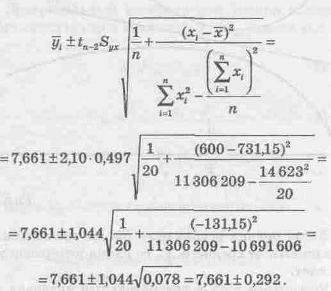
Итак, 7,369 £ myx £7,953.
Следовательно, наша оценка состоит в том, что средняя дневная выручка находится между 7,369 и 7,953 у.е. для всех магазинов с 600 посетителями.
Для построения доверительного интервала для индивидуальных значений Yx, лежащих на линии регрессии, используется доверительный интервал регрессии вида
![]()
где hi,`yi, Syx, п и хi – определяются, как и в формулах (9.31) и (9.32).
Определим 95% – и доверительный интервал для оценки дневных продаж отдельного магазина с 600 посетителями
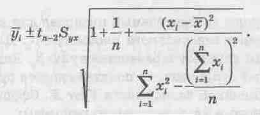
В результате вычислений получим

Итак, 6,577 £ `yi £ 8,745.
Следовательно, с 95%-й уверенностью можно утверждать, что ежедневная выручка отдельного магазина, который посетили 600 покупателей, находится в пределах от 6,577 до 8,745 у. е. Длина этого интервала больше чем длина интервала, полученного ранее для оценки среднего значения Y.
Доверительные интервалы для оценки истинных значений неизвестного параметра уравнения регрессии b1 и коэффициента регрессии р в генеральной совокупности.
Построим доверительный интервал для истинного значения генерального параметра b1. Для этого проверим гипотезу о равенстве нулю b1. Если гипотеза будет отклонена, то подтверждается существование линейной зависимости Y от X. Сформулируем нулевую и альтернативную гипотезы:
Н0: b1 = 0 (линейной зависимости нет);
Н1: b1¹ 0 (линейная зависимость есть).
Для проверки гипотезы Н0 используется t-критерий (случайная величина t, имеющая распределение Стьюдента с п – 2 степенями свободы):
Где
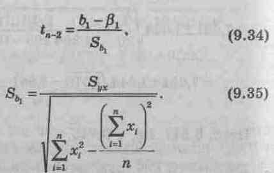
Убедимся, что полученный выборочный результат является достаточным для заключения о том, что зависимость объема выручки от числа посетителей магазина статистически существенна на 5%-м уровне значимости.
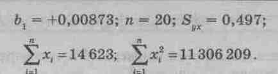
Следовательно,
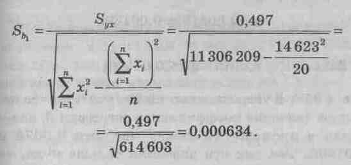
Найдем наблюдаемое значение критерия t
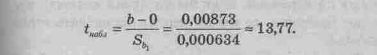
tкрит(a=0,05;k=18)= 2,1 (по таблице распределения Стьюдента).
Так как 13,77>2,10, то нулевая гипотеза Н0 отвергается в пользу альтернативной гипотезы Н1, и можно говорить о наличии существенной линейной зависимости ежедневной выручки от числа посетителей магазина.
Второй, эквивалентный первому, метод для проверки наличия или отсутствия линейной зависимости переменной Y от Х состоит в построении доверительного интервала для оценки b1 и определении того, принадлежит ли значение b1 этому интервалу. Доверительный интервал для оценки b1 получают по формуле
![]()
Найдем для нашего примера 95%‑й. доверительный интервал для оценки b1:

Итак, 0,0074 £ b1 £ 0,01006, т.е. с 95%-й уверенностью можно считать, что истинное значение коэффициента регрессии b1 находится в промежутке между числами 0,0074 и 0,01006. Так как эти значения больше нуля, то можно сделать вывод, что существует статистически значимая линейная зависимость выручки от числа посетителей. Если бы интервал включал нулевое значение, то мы не смогли бы сделать этого вывода.
Третий метод проверки существования линейной связи между двумя переменными состоит в проверке выборочного коэффициента корреляции r.
Для этого выдвигается нулевая гипотеза Н0: ρ=0 (нет корреляции).
Альтернативная гипотеза Н1: ρ ¹0 (корреляция существует).
Для проверки нулевой гипотезы Н0 используем t‑критерий (случайную величину t, имеющую распределение Стьюдента с п – 2 степенями свободы) (9.11).
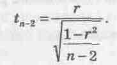
Наблюдаемое значение t составит
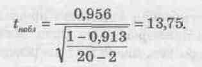
Полученный результат практически совпадает со значением, полученным по формуле (9.35). Следовательно, мы вновь подтверждаем наличие линейной связи между двумя переменными Y и X.
Список литературы
1. Апатенок Р.Ф. Математика для экономистов. М, Просвещение, 1998.
2. Красс М. Математика для экономических специальностей. Учебник. 3-е изд., перераб и доп. М, Экономист, 1999.
3. Роббинс С.В. Математика в статистике. М., Наука, 1967.
Похожие работы
... опираться на теорию множеств, математическую логику, теорию алгоритмов. На основе применения «неколичественного» математического аппарата в теоретическом языкознании сформировалось направление, условно называемое комбинаторной лингвистикой – в ней используются методы математической статистики теории вероятностей, теории информации, математического анализа Современные инструментальные методы ...
... монету второй раз не бросают), в четвертом — второму. Шансы игроков на выигрыш относятся как 3 к 1. В этом отношении и надо разделить ставку. Глава II. Элементы теории вероятностей и статистики на уроках математики в начальной школе (методика работы) Первый шаг на пути ознакомления младших школьников с миром вероятности состоит в длительном экспериментировании. Эксперимент повторяют много раз при ...

... -иллюстративного и репродуктивного метолов, а экономический профиль ориентирован на формирование прикладного стиля мышления. 2. Методика проведения элективных курсов по математике в профильной школе 2.1 Цели организации элективных курсов по математике Принципиальным положением организации школьного математического образования в настоящее время является дифференциация обучения ...
... наука находила всё новое практическое значение с развитием вычислительной техники. Этот процесс продолжается и сегодня. Немыслимый раньше «тандем» «физиков» и «лириков» стал реальностью. Для полноценного взаимодействия математики и информатики с гуманитарными науками потребовались квалифицированные специалисты как с той, так и с другой стороны. В то время как специалистам-компьютерщикам всё более ...
0 комментариев