Навигация
![]()
 1. Понятие информационной технологии.
1. Понятие информационной технологии.
ИТ – средства, методы и системы сбора, передачи, обработки и представления информации пользователю.
Существуют 4 этапа эволюции:
Появление речи;
Появление письменности;
Появление средств ВТ (Современные и тд.).
В современном ИТ выделяют 3 составляющие:
Аппаратное обеспечение (средства ВТ и оргтехники – hardware);
Программное обеспечение (прикладное и системное ПО, методическое и информационное обеспечение – software);
Организационное обеспечение (включая человека в системы ИТ, взаимодействие человека с этими системами, системное использование технических и программных средств – orgware)
ИТ = новые ИТ = современные ИТ.
Новые ИТ – современная ИТ технология, использующая развитый (интеллектуальный) интерфейс с конечным пользователем.
ИТ как прикладная наука, изучает фундаментальные соотношения в больших информационных системах.
ИТ как практика – интеллектуальная деятельность по проектированию и созданию конкретных технологий обработки данных.
В ИТ выделяют 3 составляющие:
Базовые ИТ. Обеспечивают решение отдельных компонентов в той или иной задаче, служат для создания прикладных ИТ. Например: технологии программирования, СУБД, системы распознавания изображения и тд.
Прикладные ИТ. Формируются на основе базовых ИТ, предназначены для полной информатизации объекта. Например: САПРы, АСУП, геоинформационные системы.
Обеспечивающие ИТ. Обеспечивают реализацию базовых и прикладных ИТ. На рынке представлены их отдельные компоненты. Например: современная микроэлектронная база средств ВТ, перспективные системы и комплексы (оптические и нейрокомпьютеры, транспьютеры).
3.Основные методы организации текстовых файлов.
Цепочечные файлы.
К самой БД добавляется справочник, который имеет следующую структуру:
Ключ – значимое слово, характеризующее тот или иной документ. Рядом пишется адресная ссылка на тот текстовый файл, который имеет данный ключ в качестве значимого термина. И к этой подстроке добавляются собственно текстовые файлы.
Цепочечная модель: сколько индексных терминов в тексте выделено столько и должно быть ссылок.
Преимущества:
Максимальная длина поиска определяется самой длинной цепочкой;
Новые записи (тексты) можно ставить в начало цепи, что упрощает её корректировку.
Недостатки:
Цепи могут быть длинными, если некоторые ключи используются довольно часто;
Необходимость выделения памяти для хранения адресных ссылок в самих текстах;
Если справочник очень велик, он значительно усложняет работу с текстами и требует организации дополнительного доступа к себе самому.
Вопрос 5(окончание).
термину k. Если Sk уменьшается, то k либо вообще не рассматривается как возможный индекс, либо ему присваивается отрицательный вес.
1.Параметры, основанные на динамической эффективности. Всем терминам первоначально присваиваются одинаковый вес, затем пользователь формирует запрос, и выдаются документы и пользователь определяет релевантность, система сама уменьшает или увеличивает вес документа, в соответствии с потребностями пользователя, т.е. предусматривается некоторая программа обучения системы.
Мы рассмотрели статистические подходы (СП). Помимо СП используются такие подходы, которые предусматривают местоположение термина в тексте.
Подходы:
1. В индексационные термины включаются те, которые встречаются в названиях документов, названиях глав, разделов и т.д.
2. Составляются списки значимых для некоторой предметной области слов. Т.е. составляется глоссарий по некоторой предметной области.
Методы увеличения полноты. Часто бывает необходимо выдать наибольшее число релевантных документов из массива. В этом случае необходимо к используемым индексационным терминам добавить дополнительные, чтобы расширить область поиска.
1-й подход к решению этой задачи: использование терминов заместителей из словаря синонимов, который называют тезариусом, в котором термины сгруппированы в классы.
2) Метод ассоциативного индексирования. Основан на использовании матрицы ассоциируемости терминов, которая задаёт для каждой пары терминов показатель ассоциируемости. Абсолютная запись этого ПА между терминами j и k:
f ( j ; k ) = сумм ( i=1 – n ) fij * fjk – частота совместного использования f ( j ; k ) = сумм ( i=1 – n ) fij * fjk / (сумм ( i=1 – n ) fij ^ 2+ сумм ( i=1 – n ) fjk ^ 2 – сумм ( i=1 – n ) fij * fjk - для расчёта относительного значения этого показателя. fij,k – частота появления термина j или k в i – м документе. 0 <= f ( j ; k ) <= 1. Если f ( j ; k ) = 0, то термины совсем не ассоциируются, если f ( j ; k ) = 1, то полностью ассоциируемы.
6. Использование частотных мер в индексировании.Частотный метод – по каждому термину, входящему в документ подсчитывается частота вхождения терминов в документ fik, i – номер документа, k – термин. Эта частота абсолютная. Затем документы упорядочиваются в соответствии с возрастанием или убыванием частоты.
Если термин имеет большую частоту, то это, скорее всего общеупотребительный термин, не раскрывающий конкретную предметную область (будет много документов).
Если термин имеет малую частоту, то он существенно отражает содержание, даже если его включить в дескрипторы (ключевые слова), то он , скорее всего будет использоваться в холостую. Поэтому эти 2 простейших документа исключают из списка.
Терминам с большей частотой присваивают меньший вес, с меньшей частотой – больший вес.
Инвертированные файлы.
Получаются из цепочечных файлов, когда в справочник включаются адресные ссылки на все тексты, имеющие соответствующий ключ в качестве индексационного термина.
Недостаток: переменное число адресов в справочнике.
Достоинство: быстрый поиск релевантных документов, так как их адреса находятся сразу в справочнике, обработку которого можно организовать в оперативной памяти.
Рассредоточенные файлы.
Весь массив документов разбивается на группы файлов, ключевые термины которых связаны некоторым математическим соотношением. Тогда поиск в справочнике заменяется вычислительной процедурой, которая называется хешированием, рандомизацией или перемешиванием. Здесь нет справочника, а существует вычислительная процедура, т.е. блок, называемый блоком рандомизации, который по ключу (поисковому термину) на основании вычислительной процедуры определяет адрес, по которому находится текст.
Ключ адрес этот участок
{ключ} памяти
называется
бакетом
В этой области памяти находится несколько текстов, каждый из которых характеризуется по своему в векторе документов. Т.е. адрес получается по вычислительной процедуре.
Преимущества:
Быстрый вычисляемый доступ;
Из-за отсутствия справочника экономится память.
Недостатки:
Сложность при выборе метода хеширования;
Применяется для коротких векторов запросов, когда в поиске участвует немного слов;
Изменения векторов документов порождает сложность в ведении файлов.
Кластерные файлы.
Документы разбиваются на родственные группы, которые называют кластерами или классами. Каждый класс описывается центроидом (профилем) и вектор запроса прежде всего сравнивается с центроидами класса.
Преимущества:
Возможен быстрый поиск, т.к. число классов, как правило, невелико;
Возможно интерактивное сужение (расширение) поиска за счёт исключения или добавления дополнительных кластеров.
Недостатки:
Необходимость формировать кластеры;
Необходимость введения файла центроидов;
Дополнительный расход памяти для файла центроидов или профилей.
4. Понятие центроида кластера.Множество терминов составляющих векторов кластера называются центроидом или репрезентативным кластерным профилем. Т.о. каждый кластер характеризуется центроидным вектором, который представляет собой множество пар: {(tik , wik)}, где tik – множество терминов описывающих i-й кластер, wik – множество весов.
Вес – число, определяющее значимость данного термина для раскрытия содержимого документа.
7. Расчет соотношения “сигнал-шум” при индексировании.Использование соотношения “ сигнал – шум “. Здесь исключается ещё одна частота: суммарная или общая частота появления термина k в наборе из n документов и рассчитывается:
Fk = сумма (i=1 – n) fik
Шум k –го символа рассчитывается:
Nk = сумма(i=1 – n) fik / Fk * log (Fk / fik)
Сигнал k – го символа:
Sk = log Fk – Nk
Шум является максимальным, если термин имеет равномерное распределение в n документах. Шум является минимальным и равномерным, когда термин имеет неравномерное распределение, например, когда он встречается только в одном документе, с частотой Fk, тогда:
Nk = сумма (i=1 – n) fik / Fk * log Fk / fik = 0, в этом случае сигнал имеет максимальное значение:
Sk = log Fk – Nk = log Fk
С учётом этих параметров, для определения веса используется отношение сигнала к шуму k –го термина: Sk / Nk. Чем больше это отношение, тем больший вес назначается. Строится однозначная таблица.
8.Использование распределения частоты термина при индексировании.Использование распределения частоты термина (уклонения).
Уклонение рассчитывается:
U = (сумм (fik – fk)) / (n-1)
fk – средняя частота термина k в наборе из n документов.
fk = Fk / n
Для оценки веса термина используется не уклонение, а формула Fk* U/ fk
Чем больше это отношение, тем больший вес назначается термину.
9.Использование при индексировании параметров, основанных на способности термина различать документы набора.Исходные данные – набор из n документов и множество S коэффициентов подобия всех пар документов из множества n: { S ( Di , Dj ) }. Эти коэффициенты подобия рассчитываются на основании векторов документов. Способ расчета разный, а принцип: S ( Di , Dj ) = 1, если вектора идентичны.
S ( Di , Dj ) = 0 , если в векторах нет ни одного общего документа.
По S рассчитывают средний коэффициент подобия: S = C * сумм (i= 1 – n) S ( Di , Dj ), С – коэффициент усреднения, может быть любым, в частности C = 1 / n.
Далее из векторов документов удаляют некоторый k – й термин и рассчитывают средний коэффициент по парного подобия, но с удалённым k –м термином: Sk( т.е. в векторах документа не участвуют веса k –го термина). Если Sk возрастает относительно S, то термину k присваивается положительный вес. Чем больше эта разница, тем больший вес присваивается термину k. Если Sk уменьшается, то k либо вообще не рассматривается как возможный индекс, либо ему присваивается отрицательный вес.
10.Динамическая информативность как метод индексирования.Всем терминам первоначально присваиваются одинаковый вес, затем пользователь формирует запрос, и выдаются документы и пользователь определяет релевантность, система сама уменьшает или увеличивает вес документа, в соответствии с потребностями пользователя, т.е. предусматривается некоторая программа обучения системы.
Похожие работы
... = πR2, L = 2πR). 28) Критерии выбора конфигурации персонального компьютера. Зав. кафедрой -------------------------------------------------- Экзаменационный билет по предмету ИНФОРМАТИКА. РАСШИРЕННЫЙ КУРС Билет № 9 29) Что называется связью «один к одному»? Определите тип связи между объектами предметной области Институт: ...
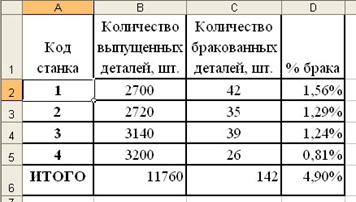
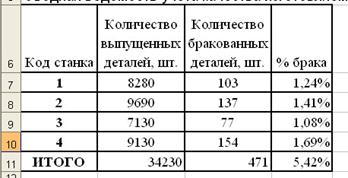
... рост производительности труда в других отраслях народного хозяйства. В настоящее время около 50% всех рабочих мест в мире поддерживается средствами обработки информации. Информатика как фундаментальная наука занимается разработкой методологии создания информационного обеспечения процессов управления любыми объектами на базе компьютерных информационных систем. В Европе можно выделить следующие ...
... корпуса молодых специалистов по новой юридической специальности- «правовая информатика». В настоящее время правовую информатику можно рассматривать как перспективное и быстро прогрессирующее направление научных исследований , которое имеет собственный предмет , задачи и методы исследований . Восприятие юристами положений и выводов информатики должно происходить через призму юридических ...
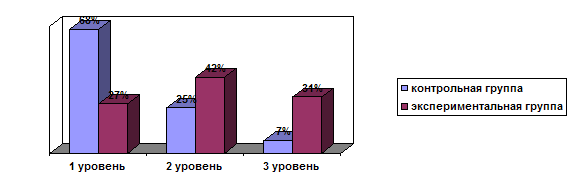
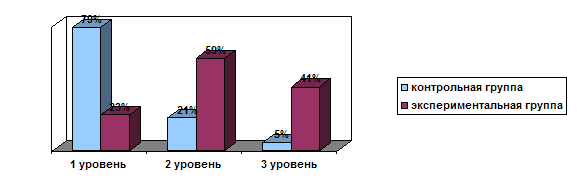
... учебного процесса методической подготовки будущего учителя. Основное содержание исследования отражено в следующих публикациях автора: I. Монографии: 1. Абдуразаков М.М. Совершенствования содержания подготовки будущего учителя информатики в условиях информатизации образования. –Махачкала: ДГПУ, 2006. –190 с. 12 п.л. 2. Гаджиев Г.М., Абдуразаков М.М. Технология преподавания информатики. – ...
0 комментариев