Навигация
Основные понятия статистики
73481
знак
1
таблица
3
изображения
Введение
1. Абсолютные и относительные статистические величины 1.1 Понятие абсолютных величин
2. Средние величины и показатели вариации 2.1 Понятие и общие принципы применения средних величин
2.2 Виды степенных средних величин
2.9 Свойства средней арифметической и дисперсии
3. Выборочное наблюдение 3.1 Понятие и отбор единиц
3.2 Средняя ошибка выборки
4. Ряды динамики 4.1 Понятие и классификация рядов динамики
Слово «статистика» имеет латинское происхождение (от status – состояние). В средние века оно означало политическое состояние государства. В науку этот термин введен в XVIII в. немецким ученым Готфридом Ахенвалем.
В настоящее время термин «статистика» употребляется в трех значениях:
1) под статистикой понимают отрасль практической деятельности, которая имеет своей целью сбор, обработку, анализ и публикацию массовых данных о самых различных явлениях общественной жизни (в этом смысле «статистика» выступает как синоним словосочетания «статистический учет»);
2) статистикой называют цифровой материал, служащий для характеристики какой-либо области общественных явлений или территориального распределения какого-то показателя;
3) статистикой называется отрасль знания, особая научная дисциплина и соответственно учебный предмет в высших и средних специальных учебных заведениях.
Как и всякая наука, статистика имеет свой предмет изучения. Статистика изучает количественную и качественную сторону массовых общественных явлений, исследует количественное выражение закономерностей общественного развития в конкретных условиях места и времени.
Свой предмет статистика изучает при помощи: определенных категорий (т.е. понятий, которые отражают наиболее общие и существенные свойства, признаки, связи и отношения предметов и явлений объективного мира, к ним относятся: статистическая совокупность, единица совокупности, признак единицы, статистический показатель и их система) и специфического метода. Метод статистики – это целая совокупность приемов, пользуясь которыми статистика исследует свой предмет. Она включает в себя три группы собственно методов (этапов любого статистического исследования):
1) метод массовых наблюдений (сбор первичного статистического материала, научно организованная регистрация всех существенных фактов, относящихся к рассматриваемому объекту);
2) метод группировок (дает возможность все собранные в результате массового статистического наблюдения факты подвергать систематизации и классификации);
3) метод обобщающих показателей (позволяет характеризовать изучаемые явления и процессы при помощи статистических величин – абсолютных, относительных и средних, выявляются взаимосвязи и масштабы явлений, определяются закономерности их развития, даются прогнозные оценки).
Основными задачами статистики являются:
1) сбор, обработка, анализ и хранение информации;
2) доведение обработанной информации до органов управления всех уровней;
3) ознакомление широкой общественности и населения с динамикой и дислокацией социально-экономических явлений в стране путем издания статистических сборников, справочников, обзоров, публикаций в печатных и электронных СМИ (например, сайт www.gks.ru);
4) международное сопоставление уровня социально-экономического развития разных стран.
1. Абсолютные и относительные статистические величины 1.1 Понятие абсолютных величин
Результаты статистических наблюдений регистрируются сначала в виде абсолютных величин, отражающих уровень развития явления или процесса. В статистике в отличие от математики все абсолютные величины именованные, обладают конкретной размерностью, а также могут быть положительными и отрицательными.
Единицы измерения абсолютных величин отражают технические или потребительские свойства и являются простыми, отражая одно свойство (например, масса груза в т.), а также сложными, отражая несколько свойств в их взаимосвязи (например, тонно-километр или киловатт-час).
Единицы измерения могут быть натуральными, условно-натуральными и стоимостными. Первые применяются для исчисления величин с однородными свойствами (например, штуки, тонны, погонные метры, квадратные метры и т.д.). Недостаток в том, что они не позволяют суммировать разнородные величины.
Условно-натуральные единицы измерения применяются к абсолютным величинам с однородными свойствами, но проявляющим их по-разному. Например, общая масса энергоносителей (дрова, торф, каменный уголь, нефтепродукты, природный газ) измеряется в т.у.т. — тонны условного топлива, поскольку каждый его вид имеет разную теплотворную способность, а за стандарт принято 29,3 МДж/кГ. Аналогично общее количество школьных тетрадей измеряется в у.ш.т. — условные школьные тетради размером 12 листов. Аналогично продукция консервного производства измеряется в у.к.б. — условные консервные банки емкостью 1/3 литра. Аналогично продукция моющих средств приводится к условной жирности 40%.
Стоимостные единицы измерения выражаются в рублях или в иной валюте, представляя собой меру стоимости каждой абсолютной величины. Они позволяют суммировать даже разнородные величины, но недостаток в том, что при этом часто не учитывается негативное изменение экономических условий в виде инфляции. Поэтому статистика стоимостные величины всегда пересчитывает в сопоставимых ценах.
Смысловой набор абсолютных величин называется статистической совокупностью, в которой их можно группировать по характерным признакам: количественным и словесным.
Количественные признаки выражаются числами и могут быть дискретными и интервальными. Так, возраст человека по паспорту — признак дискретный, а возраст группы людей (от и до) — признак интервальный.
Словесные признаки выражаются словами и, если слов только два, признак называется альтернативным. Например, пол человека: мужской или женский. Если выражающих слов больше двух, то признак называется атрибутивным. Например, национальность, профессия и т.п.
Следует различать моментные и периодные абсолютные величины. Первые показывают фактическое наличие или количественный уровень явления на определенный момент времени или дату (например, наличие оборотных средств, количество денег в кармане и т.п.). Вторые - это итоговый накопленный результат за определенный период времени (например, выпуск продукции за месяц, квартал, год или заработная плата за месяц, квартал, год и т.д.). В отличие от моментных, периодные абсолютные величины допускают последующее суммирование.
Абсолютная статистическая величина обозначается X, а их общее количество в совокупности обозначается N. Количество величин с одинаковым значением признака обозначается f и называется повторяемость, встречаемость, частота. Естественно, Σf = N. Отношение f / N = f / Σf = d называется доля, удельный вес, частость.
Естественно, Σd = 1. В статистике, в отличие от математики, пределы суммирования не ставятся, а подразумеваются, т.к. абсолютные величины здесь не абстрактные, а смысловые.
Однако сами по себе абсолютные статистические величины не дают полного представления об изучаемом явлении, т.к. не показывают его структуру, соотношение между частями, взаимосвязь с другими абсолютными величинами, развитие во времени. Для этих целей служат относительные статистические величины.
1.2 Понятие относительных величинОтносительная статистическая величина представляет собой соотношение двух абсолютных величин и, если последние однородны, имея одинаковую размерность, то относительная величина получается безразмерной, принимая статус коэффициента. Например, фондоотдача (оборачиваемость) как отношение стоимости выпущенной продукции к стоимости основных фондов является коэффициентом.
Часто применяется искусственная размерность коэффициентов путем их умножения или на 100 (получают проценты), или на 1000 (получают промилле), или на 10000 (получают деципромилле). Две последние размерности используются в статистике населения, где коэффициенты и проценты выражаются очень малыми величинами. Наиболее употребимы проценты.
Однако искусственная размерность коэффициентов удобна лишь в разговорной речи и в отчетах, а в расчетах она только мешает, т.к. сотни и тысячи «путаются под пером» и в конце концов сокращаются. Поэтому существует «золотое» правило финансистов: «Говорим и учитываем процентом — считаем коэффициентом».
Если относительная статистическая величина - результат соотношения двух абсолютных величин с разной размерностью, то она приобретает дробную размерность, принимая статус показателя. Например, это всем известные: себестоимость продукции в руб./ед., ее цена в руб./ед,, производительность рабочей силы в руб./чел., энергоотдача производства в руб./кВт ч и другие показатели.
Относительные величины применяются для качественного статистического анализа динамики, структуры, координации, сравнения и интенсивности изучаемых явлений. При этом безразмерные относительные величины наряду с именованием коэффициентами часто именуются индексами.
1.3 Виды относительных величинНаиболее распространенной является относительная величина, коэффициент или индекс динамики, который характеризует изменение какого-либо явления во времени, представляя собой отношение значений одной и той же абсолютной величины в разные периоды времени. То есть
![]() . (1.1)
. (1.1)
Здесь и далее подиндексы означают: 1 — отчетный или анализируемый период, 0 — прошлый или базисный период.
Критериальным значением индекса динамики служит единица. Если он больше ее, имеет место рост явления; равен единице — стабильность; если меньше единицы, наблюдается спад явления.
Еще одно название индекса динамики — индекс изменения, вычитая из которого единицу получают темп изменения с критериальным значением нуль. Если он больше нуля, имеет место рост явления; равен нулю — стабильность; если меньше нуля, наблюдается спад явления.
![]() . (1.2)
. (1.2)
В некоторых учебниках по Статистике индекс изменения назван темпом роста, а темп изменения — темпом прироста, независимо от получаемого результата, который может показать стабильность или спад.
Если анализируемый и базисный периоды не являются соседними во временном ряду (например, год, предшествующий пятилетке и ее последний год), то найденный по формуле (1.1) индекс динамики или изменения будет общим, поэтому дополнительно определяется средний индекс по формуле
![]() , (1.3)
, (1.3)
где t — количество периодов во временном ряду (например, в пятилетке t = 5).
Как и у общего, у среднего индекса критериальным значением служит единица с теми же выводами о характере изменения. Вычитанием из среднего индекса единицы получают средний темп изменения с критериальным значением нуль и аналогичными выводами о характере изменения явления.
На производстве применяются относительные величины, коэффициенты или индексы планового задания и выполнения плана. Первый определяется как отношение значений одной и той же абсолютной величины по плану анализируемого периода и по факту базисного. То есть
![]() , (1.4)
, (1.4)
![]() где X’1 — план анализируемого периода; X0 — факт базисного периода.
где X’1 — план анализируемого периода; X0 — факт базисного периода.
Индекс выполнения плана представляет собой отношение значений одной и той же абсолютной величины по факту и по плану анализируемого периода, определяясь по формуле
![]() (1.5)
(1.5)
Перемножая индексы планового задания и выполнения плана, получаем индекс динамики. То есть
![]() (1.6)
(1.6)
Широко применяется также относительная величина, коэффициент или индекс структуры в виде отношения какой-либо части абсолютной величины ко всему ее значению. По существу это упоминавшаяся выше доля, удельный вес, частость, определяемая по формуле
![]() . (1.7)
. (1.7)
Например, если количество лиц женского пола (лжп) в группе студентов поделить на численность всей группы, то получится индекс структуры лжп.
Похожей является относительная величина, коэффициент или индекс координации как отношение какой-либо части абсолютной величины к другой ее части, принятой за основу. Определяется по формуле
![]() . (1.8)
. (1.8)
Например, если за основу принять количество лжп в группе студентов и на это число поделить количество лиц мужского пола (лмп) в ней, то получится индекс координации лмп относительно лжп.
Следующей является относительная величина, коэффициент или индекс сравнения в виде отношения значений одной и той же абсолютной величины в одном периоде или моменте времени, но для разных объектов или территорий. Определяется по формуле
![]() , (1.9)
, (1.9)
где А, Б — признаки сравниваемых объектов или территорий.
Еще один вид относительных величин сравнения получают путем сопоставления индексов динамики разных явлений. В результате образуются индексы опережения или отставания в развитии одного явления по сравнению с другим. Так, если на предприятии производительность труда увеличилась на 12 %, а средняя зарплата только на 7,5 %, то рост производительности труда опережает рост зарплаты по индексу изменения на 112/107,5=1,042 или на 4,2 %, а по темпу изменения на 12/7,5=1,6 или на 60 %. Это и есть соответствующие индексы опережения. Индекс отставания роста зарплаты от роста производительности труда будет обратной величиной.
Перечисленные индексы являются безразмерными относительными величинами, а показателем, имеющим размерность, служит относительная величина интенсивности в виде отношения значений двух разнородных абсолютных величин для одного периода времени и одной территории или объекта. Для ее определения используется формула
![]() . (1.10)
. (1.10)
К показателям интенсивности относятся упомянутые выше себе стоимость, цена, энергоемкость продукции и другие относительные величины с дробной размерностью.
2. Средние величины и показатели вариации 2.1 Понятие и общие принципы применения средних величин
Статистическая совокупность содержит некоторое количество статистических величин, имеющих, как правило, разные значения и признаки, что делает невозможным сравнение нескольких совокупностей в целом. Для этой цели применяется средняя величина, как обобщающий показатель совокупности, характеризующий уровень изучаемого явления или процесса.
Средняя величина всегда обобщает количественное выражение признака и погашает индивидуальные различия статистических величин совокупности, вызванные случайными обстоятельствами. Но по значению средней величины нельзя делать принципиальные выводы.
Так, если один ученик имеет тетрадь в 48 листов, а другой - ни одной, то в среднем получается по 2 у.ш.т. на ученика. Но из этого нельзя заключать, что все ученики школьными тетрадями обеспечены.
В статистике соблюдаются следующие принципы применения средних величин.
1. Необходим обоснованный выбор статистической совокупности, для которой определяется средняя величина.
2. При определении средней величины исходят из качественного содержания статистических величин, учитывая возможную взаимосвязь изучаемых признаков.
3. Средняя величина должна рассчитываться по однородной совокупности, которая позволяет применять метод группировки, предполагающий расчет системы обобщающих показателей.
4. Общая средняя величина должна подкрепляться и поясняться групповыми средними величинами.
2.2 Виды степенных средних величин
Средние величины делятся на два больших класса: степенные и структурные. К последним относятся мода и медиана, но наиболее часто применяются степенные различных видов.
Степенные средние, в зависимости от представления отдельных величин, могут быть простыми и взвешенными. Простая средняя рассчитывается при наличии двух и более статистических величин, расположенных в произвольном порядке. Общая формула простой средней величины имеет вид
![]() =
=![]() . (1.11)
. (1.11)
Взвешенная средняя величина рассчитывается по сгруппированным статистическим величинам с использованием следующей общей формулы
![]() =
=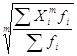 (1.12)
(1.12)
При этом обозначено:
Xi – значения отдельных статистических величин или середин группировочных интервалов;
m - показатель степени, от значения которого зависят следующие виды степенных средних величин:
при m = -1 средняя гармоническая;
при m = 0 средняя геометрическая;
при m = 1 средняя арифметическая;
при m = 2 средняя квадратическая;
при m = 3 средняя кубическая и так далее.
Используя общие формулы простой и взвешенной средних при разных показателях степени m, получаем частные формулы каждого вида. Так, приняв m = 1, находим, что простая средняя арифметическая величина определяется по формуле
![]() =
=![]() . (1.13)
. (1.13)
Аналогично для взвешенной средней арифметической величины получаем формулу через частоты или через доли (так как ![]() )
)
![]() =
=![]() . (1.14)
. (1.14)
Не представляет трудностей и вывод формул для простых и взвешенных средних квадратических и кубических величин. Несколько сложнее вывод средней гармонической при m = –1. Так, используя формулу (1.11), имеем вначале
![]() гм =
гм = 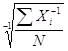 =
= ![]() ,
,
а окончательно получим, что простая средняя гармоническая величина определяется по формуле
![]() ГМ =
ГМ = ![]() , (1.15)
, (1.15)
Аналогично выводится формула взвешенной средней гармонической величины, которая имеет следующий окончательный вид через частоты или через доли
![]() ГМ =
ГМ = 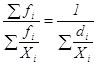 , (1.16)
, (1.16)
Наиболее часто употребляются формулы средних арифметических и гармонических величин.
2.3 Правила применения средней арифметической и гармонической взвешенныхОни часто применяются для осреднения относительных величин интенсивности, т.е. показателей, имеющих дробную размерность. При этом соблюдаются следующие правила.
1. Если имеются дополнительные данные по числителю дробной размерности, то применяется средняя гармоническая.
2. Если имеются дополнительные данные по знаменателю дробной размерности, то применяется средняя арифметическая.
3. Если неясно, к числителю или знаменателю относятся дополнительные данные, то поочередно применяются средняя гармоническая и арифметическая, а затем определяется средняя между ними величина.
Для иллюстрации правил решим задачу: 4 фирмы выпускают одинаковую продукцию при себестоимостях в руб/ед.: Si = 5, 3, 4, 6, а доли фирм равны соответственно di = 0,3; 0,2; 0,4; 0,1. Определить среднюю себестоимость продукции.
Для решения примера используем вышеизложенные правила.
1. Если доли фирм относятся к текущим затратам (числитель показателя себестоимости), то ее среднее значение определяем по формуле (1.16) как среднюю гармоническую величину
![]() = 1/ (0,3/5 + 0,2/3 + 0,4/4 + 0,1/6) = 4,1 (руб./ед.)
= 1/ (0,3/5 + 0,2/3 + 0,4/4 + 0,1/6) = 4,1 (руб./ед.)
2. Если доли фирм относятся к количеству выпущенной продукции (знаменатель показателя себестоимости), то ее среднее значение находим по формуле (1.14) как среднюю арифметическую величину
![]() = 5*0,3 + 3*0,2 + 4*0,4 + 6*0,1 = 4,3 (руб./ед.)
= 5*0,3 + 3*0,2 + 4*0,4 + 6*0,1 = 4,3 (руб./ед.)
3. Если не сказано, к чему относятся доли фирм, то в дополнение к выполненным расчетам определяем среднюю себестоимость как простую среднюю величину из полученных результатов. То есть ![]() = (Sгм + Sар)/2 = 4,2 (руб./ед.)
= (Sгм + Sар)/2 = 4,2 (руб./ед.)
Таким путем рассчитываются средние значения и других показателей с дробной размерностью.
2.4 Особые виды степенных средних величинРазновидностью простой средней арифметической служит средняя хронологическая величина, когда имеются моментные статистические величины на определенную одинаковую дату, например, на 1-е число каждого месяца в году. Формула средней хронологической теоретическому выводу не поддается и записывается приближенно в виде
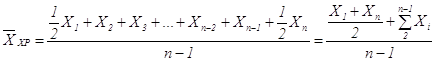 . (1.17)
. (1.17)
где Х1 и Xn — первое и последнее значения статистической величины; Xi — промежуточные значения; n — общее число значений.
По такой формуле бухгалтерия определяет среднегодовую стоимость основных фондов, учитывая ее значения на 1-е число каждого месяца. При этом n = 13, т. к. 1-е января фиксируется дважды: у отчетного и следующего за отчетным года. Аналогично коммерческие банки определяют среднегодовую сумму вкладов и выданных кредитов. Если учет квартальный, то n = 5.
Средняя геометрическая величина получается при подстановке в формулу (1.11) m=0:
![]() =
=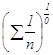 =
=![]()
Для раскрытия неопределенностей этого вида прологарифмируем обе части формулы (1.11):
![]() .
.
Подставляя в правую часть равенства m=0, получаем неопределенность вида ![]() . Используя правило Лопиталя и дифференцируя отдельно числитель и знаменатель по переменной m, получаем
. Используя правило Лопиталя и дифференцируя отдельно числитель и знаменатель по переменной m, получаем
![]() .
.
Следовательно, при m=0
![]() .
.
Потенцируя, находим
![]() . (1.18)
. (1.18)
Формула (1.18) является формулой средней геометрической простой, а если использовать частоты f, получим формулу средней геометрической взвешенной:
![]() =
= ![]() – взвешенная, (1.19)
– взвешенная, (1.19)
где П—символ произведения.
Средняя геометрическая величина применяется, если задана последовательность индексов динамики, указывающих, например, на изменение уровня производства каждого последующего года по сравнению с предыдущим.
Рассчитанные для одних и тех же данных различные средние величины оказываются неодинаковыми. Здесь действует правило мажорантности средних величин (впервые сформулировал профессор А. Я. Боярский), согласно которому с ростом показателя степени m в общих формулах увеличивается и средняя величина. То есть
![]() <
<![]() <
< ![]() <
< ![]() <
< ![]()
Это правило частично подтвердилось расчетом средней себестоимости продукции, где средняя гармоническая получилась равной 4,1 руб./ед., а средняя арифметическая 4,3 руб./ед. Если рассчитать еще и среднюю геометрическую взвешенную, то она будет равной 4,2 руб./ед.
2.5 Структурные средниеОсобый вид средних величин – структурные средние – применяется для изучения внутреннего строения рядов распределения значений признака, а также для оценки средней величины (степенного типа), если по имеющимся статистическим данным ее расчет не может быть выполнен.
В качестве структурных средних чаще всего используют показатели моды – наиболее часто повторяющегося значения признака – и медианы – величины признака, которая делит упорядоченную последовательность его значений на две равные по численности части. В итоге у одной половины единиц совокупности значение признака больше медианного уровня, а у другой – меньше его.
Если изучаемый признак имеет дискретные значения, то особых сложностей при расчете моды и медианы не бывает. Если же данные о значениях признака Х представлены в виде упорядоченных интервалов его изменения (интервальных рядов), расчет моды и медианы несколько усложняется. Поскольку медианное значение делит всю совокупность на две равные по численности части, оно оказывается в каком-то из интервалов признака X. С помощью интерполяции в этом медианном интервале находят значение медианы:
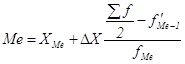 , (1.20)
, (1.20)
где XMe – нижняя граница медианного интервала;
∆X – его величина (размах);
∑f/2 – половина от общего числа величин;
![]() – сумма наблюдений (или объема взвешивающего признака), накопленная до начала медианного интервала;
– сумма наблюдений (или объема взвешивающего признака), накопленная до начала медианного интервала;
fMe – число наблюдений или объем взвешивающего признака в медианном интервале.
При расчете модального значения признака по данным интервального ряда надо обращать внимание на то, чтобы интервалы были одинаковыми, поскольку от этого зависит показатель повторяемости значений признака X. Для интервального ряда с равными интервалами величина моды определяется как
![]() , (1.21)
, (1.21)
где ХMo – нижнее значение модального интервала;
fMo – число наблюдений или объем взвешивающего признака в модальном интервале;
fMo-1 – то же для интервала, предшествующего модальному;
fMo+1 – то же для интервала, следующего за модальным;
∆X – величина интервала изменения признака в группах.
Очевидно, что в формуле (1.20) и (1.21) можно заменить частоты f на доли d, так как ![]() , а
, а ![]() можно вынести за скобки как в числителе, так и в знаменателе и сократить.
можно вынести за скобки как в числителе, так и в знаменателе и сократить.
Показателями типа медианы, характеризующими структуру рядов распределения признака, являются квартили (делят ряд на 4 равные части), квинтили (на 5), децили (на 10), перцентили (на 100).
2.6 Средние отклонения от средних величинКаждая статистическая величина от среднего значения отличается (отклоняется) по-разному и в любую сторону: со знаком плюс или минус. Поэтому для оценки типичности полученной средней величины надо знать величину среднего отклонения совокупности от нее. Поскольку неизбежны и отрицательные отдельные отклонения, необходима нейтрализация знака минус, иначе среднего отклонения не получится. Этого можно достичь двумя способами: принять отрицательные отклонения по модулю или возвести их во вторую степень (в квадрат).
При первом способе образуется среднее линейное отклонение, а при втором — среднее квадратическое. В связи с тем, что средние величины могут быть простыми и взвешенными, аналогичными могут быть и средние отклонения. Поэтому среднее линейное отклонение определяется по формулам
![]()
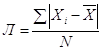 – простое; (1.22)
– простое; (1.22)
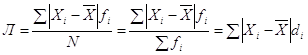 – взвешенное. (1.23)
– взвешенное. (1.23)
В этих формулах прямые скобки означают, что разности или отклонения берутся по модулю, то есть без учета знака. Если ошибочно вместо прямых скобок принять обычные круглые, то получится Л=0.
При использовании второго способа вначале определяется дисперсия отклонений по формулам
![]() – простая; (1.24)
– простая; (1.24)
![]()
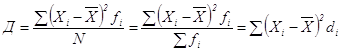 – взвешенная. (1.25)
– взвешенная. (1.25)
Дисперсия альтернативного признака (т.е. имеющего две взаимоисключающие разновидности, например, пол человека – мужской или женский, качество продукции – годная или бракованная) определяется по формуле 1.25, если вместо Xi подставить 1 и 0 (так как признак может принимать только 2 значения). Зная, что:
p + q = 1,
где p – доля единиц, обладающих признаком, q – доля единиц не обладающих им.
Среднее значение можно найти по формуле (1.14):
![]() .
.
Таким образом получим формулу дисперсии альтернативного признака, применив формулу (1.25):
![]() .
.
Таким образом, дисперсия альтернативного признака равна
![]() . (1.26)
. (1.26)
Предельное значение дисперсии альтернативного признака равно 0,25; оно получается при p = q = 0,5.
В отличие от математики статистика оперирует не абстрактными, а смысловыми величинами, имеющими размерность. Поэтому и дисперсия здесь не безразмерная, как в математике, а сопровождается квадратической размерностью. Например, если статистическая величина измеряется в годах, или рублях, то дисперсия отклонений получится в «квадратных» годах или в «квадратных» рублях.
Для получения обычной размерности находится среднее квадратическое отклонение («сигма») как корень квадратный из дисперсии. То есть
![]() =
= ![]() . (1.27)
. (1.27)
Однако значения средних отклонений, как любой абсолютной величины, служат лишь количественной мерой анализа статистической совокупности. Для качественного анализа применяются относительные критерии, называемые коэффициентами вариации.
2.7 Коэффициенты вариации
Вариация — это несовпадение значений одной и той же статистической величины у разных объектов в силу особенностей их собственного развития, а также различия условий, в которых они находятся. Вариация имеет объективный характер и помогает познать сущность изучаемого явления. Если средняя величина сглаживает индивидуальные различия, то вариация, наоборот, их подчеркивает, устанавливая типичность или не типичность найденной средней величины для конкретной статистической совокупности. Тем самым можно делать вывод о качественности подобранных статистических данных.
Вариация измеряется с помощью относительных величин, называемых коэффициентами вариации и определяемых в виде отношения среднего отклонения к средней величине.
Поскольку среднее отклонение может определяться линейным и квадратическим способами, то соответствующими могут быть и коэффициенты вариации. Следовательно, коэффициенты вариации надо определять по формулам
![]() – линейный; (1.28)
– линейный; (1.28)
![]() – квадратический. (1.29)
– квадратический. (1.29)
Значения коэффициента вариации изменяются от 0 до 1 и чем ближе он к нулю, тем типичнее найденная средняя величина для изучаемой статистической совокупности, а значит и качественнее подобраны статистические данные. При этом критериальным значением коэффициента вариации служит 1/3.
То есть средняя величина считается типичной для данной совокупности при λ ![]() 0,333 или при ν
0,333 или при ν ![]() 0,333. В ином случае средняя величина не типична и требуется пересмотреть статистическую совокупность с целью включения в нее более объективных статистических величин.
0,333. В ином случае средняя величина не типична и требуется пересмотреть статистическую совокупность с целью включения в нее более объективных статистических величин.
Обычно квадратический коэффициент вариации несколько (примерно на 25%) больше линейного, рассчитанные по одним и тем же данным. А значит возможен случай, когда λ ![]() 0,333 и ν
0,333 и ν ![]() 0,333, тогда необходимо взять среднюю из этих коэффициентов и по ее значению сделать окончательный вывод о не/типичности найденной средней величины.
0,333, тогда необходимо взять среднюю из этих коэффициентов и по ее значению сделать окончательный вывод о не/типичности найденной средней величины.
С помощью линейного коэффициента вариации принципиальный вывод о типичности или не типичности средней величины можно получить проще и быстрее, чем с помощью квадратического. Однако квадратический коэффициент применяется чаще, так как существует несколько способов для вычисления дисперсии.
У такого способа оценки вариации есть и существенный недостаток. Действительно, пусть, например, исходная совокупность рабочих, имеющих средний стаж 15 лет, со стандартным отклонением σ = 10 лет, «состарилась» еще на 15 лет. Теперь![]() = 30 лет, а стандартное отклонение по-прежнему равно 10. Совокупность, ранее бывшая неоднородной (10/15*100 = 66,7%), со временем оказывается, таким образом, вполне однородной (10/30*100 = 33,3 %).
= 30 лет, а стандартное отклонение по-прежнему равно 10. Совокупность, ранее бывшая неоднородной (10/15*100 = 66,7%), со временем оказывается, таким образом, вполне однородной (10/30*100 = 33,3 %).
Поэтому возможен дополнительный анализ статистической совокупности с помощью коэффициента осцилляции, определяемого по формуле
![]() , (1.30)
, (1.30)
где R — размах вариации в виде разности наибольшего и наименьшего значений в совокупности статистических величин. То есть
R = Хмах –Хmin, (1.31)
где Xмax и Xmin — максимальное и минимальное значения в совокупности.
При упорядочении статистических величин в совокупности образуются группировочные интервалы. Тогда под обозначением ∆Х понимается размах интервала, а среднее интервальное значение обозначается ХИ.
В случае ориентировки только на квадратический коэффициент вариации могут применяться разные методы определения дисперсии.
2.8 Определение дисперсии методом моментовПреобразованием приведенных выше логических формул определения дисперсии могут быть получены ее новые формулы для расчета, например, методом моментов, которым иногда значение дисперсии получается быстрее.
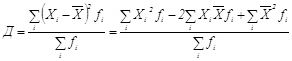 =
=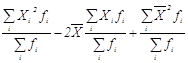 =
=![]() =
=![]()
Окончательно записываем, что дисперсия методом моментов определяется по формуле
Д = ![]() , (1.32)
, (1.32)
где ![]() – средняя квадратов статистических величин;
– средняя квадратов статистических величин; ![]() – квадрат их средней величины.
– квадрат их средней величины.
Эти параметры нередко имеют и другие названия. Вычитаемое называют начальным моментом первого порядка, уменьшаемое – начальным моментом второго порядка, а сама дисперсия при этом называется центральным моментом второго порядка.
Для иллюстрации пользования формулами дисперсии рассмотрим простейший пример, приняв абстрактно Х1 = 2, Х2 = 4, Х3 = 6, для которых среднее значение, очевидно, равняется ![]() = 4. Тогда дисперсия простая по логической формуле (1.24) будет равна
= 4. Тогда дисперсия простая по логической формуле (1.24) будет равна
Д3 = ((2-4)2 + (4-4)2 + (6-4)2)/3 = 8/3 = 2,67
Применив формулу моментов (1.32), получим тот же результат
Д3 =(22 + 42 + 6 2 )/3 – 42 = 56/3 – 16 = 2,67
В данном примере быстрота определения дисперсии методом моментов не достаточно ощутима, но она проявляется очень заметно при большом количестве статистических данных.
2.9 Свойства средней арифметической и дисперсии
В статистических расчетах эти характеристики статистической совокупности зачастую применяются во взаимодействии. При этом с целью приведения их к удобному для анализа виду при громоздких значениях статистических величин используют следующие свойства.
1. Если каждую статистическую величину изменить на одно число (прибавить или отнять), то средняя арифметическая изменится на это число, а дисперсия при этом не изменится.
2. Если каждую статистическую величину изменить в одинаковое число раз (умножить или разделить), то средняя арифметическая изменится во столько же раз, а дисперсия изменится в квадрат таких раз.
Доказать эти свойства можно путем математических преобразований соответствующих формул, но гораздо проще доказательство получается с помощью следующего численного примера.
Принимая предыдущие три статистические величины с их значениями 2, 4, и 6, сначала прибавим к каждой из них 5, а потом умножим каждую из них на 5. Тогда получим измененные значения статистических величин, представленные матрицей
X1=2; X1’=2+5=7; X1’’=2*5=10.
X2=4; X2’=4+5=9; X2’’=4*5=10.
X3=6; X3’=6+5=11; X3’’=6*5=30.
![]() = 4;
= 4; ![]() ’=9;
’=9; ![]() ’’=20.
’’=20.
Д=2,67; Д’=2,67; Д’’=66,67.
В этой матрице значения средних арифметических очевидны, а первоначальное значение дисперсии было найдено в предыдущем примере. Расчет других ее значений приведен ниже по логической формуле (1.24)
Д’= ((7-9)2 + (9-9)2 + (11-9)2)/3 = 2,67
Д’’= ((10-20)2 + (20-20)2 + (30-20)2)/3 = 66,67
Отмечаем, что отношение 66,67/2,67 дает ровно 25 или 52. То есть при увеличении каждой статистической величины в 5 раз дисперсия увеличилась в 25 раз. Аналогичные численные доказательства можно выполнить и в случаях противоположного изменения статистических величин.
3. Выборочное наблюдение 3.1 Понятие и отбор единиц
Выборочный метод используется, когда применение сплошного наблюдения физически невозможно из-за огромного массива данных или экономически нецелесообразно. Физическая невозможность имеет место, например, при изучении пассажиропотоков, рыночных цен, семейных бюджетов. Экономическая нецелесообразность имеет место при оценке качества товаров, связанной с их уничтожением. Например, дегустация, испытание кирпичей на прочность и т.п. Выборочное наблюдение используется также для проверки результатов сплошного.
Статистические величины, отобранные для наблюдения, составляют выборочную совокупность или выборку, а весь их массив - генеральную совокупность. При этом число величин в выборке обозначают п, во всей генеральной совокупности — как обычно N. Отношение n/N называется относительный размер или частость выборки, измеряемая в процентах.
Качество результатов выборочного наблюдения зависит от репрезентативности выборки, т.е. от того, насколько она представительна в генеральной совокупности. Для обеспечения репрезентативности выборки надо соблюдать принцип случайности отбора статистических величин, который реализуется разными способами.
1. Собственно случайный отбор или «метод лото», когда статистическим величинам присваиваются порядковые номера, заносимые на определенные предметы (бумажки, фишки, кубики, бочонки, шары), которые затем перемешиваются в некоторой емкости (шапка, мешок, ящик, барабан) и выбираются наугад. Этот способ можно осуществить также с помощью математических таблиц случайных чисел.
2. Механический отбор, согласно которому отбирается каждая (N/п)-я величина генеральной совокупности. Так, если она содержит 100000 величин, а требуется выбрать 1000, то в выборку попадет каждая 100000 / 1000 = 100-я величина. Причем, если они не ранжированы, то первая выбирается наугад из первой сотни, а номера других будут на сотню больше. Например, если первой оказалась статистическая величина № 19, то следующей должна быть № 119, затем № 219, затем № 319 и т. д. Если статистические величины ранжированы, то первой выбирается № 50, затем № 150, затем № 250 и так далее.
3. Отбор величин из неоднородного массива данных ведется стратифицированным (расслоенным) способом, когда генеральная совокупность предварительно разбивается на однородные группы, к которым применяется случайный или механический отбор.
4. Особый способ составления выборки представляет собой серийный или гнездовой отбор, при котором случайно или механически выбирают не отдельные величины, а их серии или гнезда, внутри которых ведут сплошное наблюдение.
Качество выборочных наблюдений зависит и от типа выборки: повторная или бесповторная. В первом случае попавшие в выборку статистические величины или их серии после использования возвращаются в генеральную совокупность, имея шанс попасть в новую выборку. При .этом у всех величин генеральной совокупности одинаковая вероятность включения в выборочную совокупность.
Бесповторный отбор означает, что попавшие в выборку статистические величины или их серии после использования не возвращаются в генеральную совокупность, а потому для остальных величин последней повышается вероятность попадания в следующую выборку.
Бесповторный отбор дает более точные результаты, поэтому применяется чаще. Но есть ситуации, когда его применить нельзя (изучение пассажиропотоков, потребительского спроса и т.п.) и тогда ведется повторный отбор.
3.2 Средняя ошибка выборки
Выборочную совокупность можно сформировать по количественному признаку статистических величин, а также по альтернативному или атрибутивному. В первом случае обобщающей характеристикой выборки служит выборочная средняя величина, обозначаемая ![]() , а во втором — выборочная доля величин, обозначаемая w. В генеральной совокупности соответственно: генеральная средняя
, а во втором — выборочная доля величин, обозначаемая w. В генеральной совокупности соответственно: генеральная средняя ![]() и генеральная доля р .
и генеральная доля р .
Разности ![]() —
— ![]() и W — р называются ошибкой выборки, которая делится на ошибку регистрации и ошибку репрезентативности. Первая часть ошибки выборки возникает из-за неправильных или неточных сведений по причинам непонимания существа вопроса, невнимательности регистратора при заполнении анкет, формуляров и т.п. Она достаточно легко обнаруживается и устраняется. Вторая часть ошибки возникает из-за постоянного или спонтанного несоблюдения принципа случайности отбора. Ее трудно обнаружить и устранить, она гораздо больше первой и потому ей уделяется основное внимание.
и W — р называются ошибкой выборки, которая делится на ошибку регистрации и ошибку репрезентативности. Первая часть ошибки выборки возникает из-за неправильных или неточных сведений по причинам непонимания существа вопроса, невнимательности регистратора при заполнении анкет, формуляров и т.п. Она достаточно легко обнаруживается и устраняется. Вторая часть ошибки возникает из-за постоянного или спонтанного несоблюдения принципа случайности отбора. Ее трудно обнаружить и устранить, она гораздо больше первой и потому ей уделяется основное внимание.
Величина ошибки выборки зависит от структуры последней. Например, если при определении среднего балла успеваемости студентов факультета в одну выборку включить больше отличников, а в другую - больше неудачников, то выборочные средние баллы и ошибки выборки будут разными.
Поэтому в статистике определяется средняя ошибка повторной и бесповторной выборки в виде ее удельного среднего квадратического отклонения по формулам
![]() =
= ![]() - повторная; (1.35)
- повторная; (1.35)
![]() =
= ![]() - бесповторная; (1.36)
- бесповторная; (1.36)
где Дв — выборочная дисперсия, определяемая при количественном признаке статистических величин по обычным формулам из гл.2.
При альтернативном или атрибутивном признаке выборочная дисперсия определяется по формуле
Дв = w(1-w). (1.37)
Из формул (1.35) и (1.36) видно, что средняя ошибка меньше у бесповторной выборки, что и обусловливает ее более широкое применение.
3.3 Предельная ошибка выборкиУчитывая, что на основе выборочного обследования нельзя точно оценить изучаемый параметр (например, среднее значение) генеральной совокупности, необходимо найти пределы, в которых он находится. В конкретной выборке разность![]() может быть больше, меньше или равна
может быть больше, меньше или равна ![]() . Каждое из отклонений
. Каждое из отклонений ![]() от
от ![]() имеет определенную вероятность. При выборочном обследовании реальное значение
имеет определенную вероятность. При выборочном обследовании реальное значение ![]() в генеральной совокупности неизвестно. Зная среднюю ошибку выборки, с определенной вероятностью можно оценить отклонение выборочной средней от генеральной и установить пределы, в которых находится изучаемый параметр (в данном случае среднее значение) в генеральной совокупности. Отклонение выборочной характеристики от генеральной называется предельной ошибкой выборки
в генеральной совокупности неизвестно. Зная среднюю ошибку выборки, с определенной вероятностью можно оценить отклонение выборочной средней от генеральной и установить пределы, в которых находится изучаемый параметр (в данном случае среднее значение) в генеральной совокупности. Отклонение выборочной характеристики от генеральной называется предельной ошибкой выборки ![]() . Она определяется в долях средней ошибки с заданной вероятностью, т.е.
. Она определяется в долях средней ошибки с заданной вероятностью, т.е.
![]() = t
= t![]() , (1.38)
, (1.38)
где t – коэффициент доверия, зависящий от вероятности, с которой определяется предельная ошибка выборки.
Вероятность появления определенной ошибки выборки находят с помощью теорем теории вероятностей. Согласно теореме П. Л. Чебышёва, при достаточно большом объеме выборки и ограниченной дисперсии генеральной совокупности вероятность того, что разность между выборочной средней и генеральной средней будет сколь угодно мала, близка к единице:
![]() при
при ![]() .
.
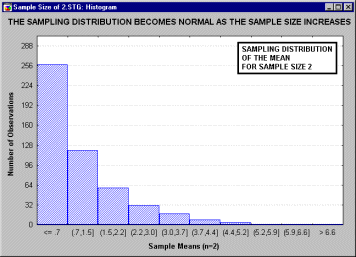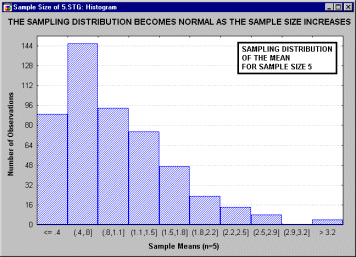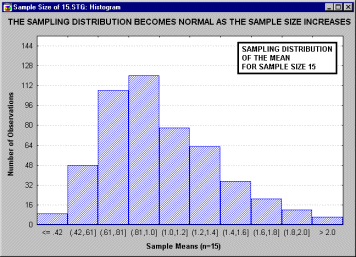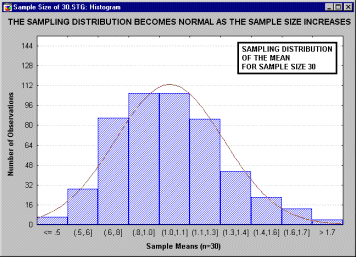
А. М. Ляпунов доказал, что независимо от характера распределения генеральной совокупности при увеличении объема выборки распределение вероятностей появления того или иного значения выборочной средней приближается к нормальному распределению. Это так называемая центральная предельная теорема. Следовательно, вероятность отклонения выборочной средней от генеральной средней, т.е. вероятность появления заданной предельной ошибки, также подчиняется указанному закону и может быть найдена как функция от t с помощью интеграла вероятностей Лапласа:
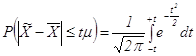 ,
,
где ![]() – нормированное отклонение выборочной средней от генеральной средней.
– нормированное отклонение выборочной средней от генеральной средней.
Значения интеграла Лапласа для разных t рассчитаны и имеются в специальных таблицах, из которых в статистике широко применяется сочетание:
Вероятность | 0,683 | 0,866 | 0,950 | 0,954 | 0,988 | 0,990 | 0,997 | 0,999 |
| t | 1 | 1,5 | 1,96 | 2 | 2,5 | 2,58 | 3 | 3,5 |
Задавшись конкретным уровнем вероятности, выбирают величину нормированного отклонения t и определяют предельную ошибку выборки по формуле (1.38)
При этом чаще всего применяют ![]() = 0,95 и t = 1,96, т.е. считают, что с вероятностью 95% предельная ошибка выборки вдвое больше средней. Поэтому в статистике величина t иногда именуется коэффициентом кратности предельной ошибки относительно средней.
= 0,95 и t = 1,96, т.е. считают, что с вероятностью 95% предельная ошибка выборки вдвое больше средней. Поэтому в статистике величина t иногда именуется коэффициентом кратности предельной ошибки относительно средней.
После исчисления предельной ошибки находят доверительный интервал обобщающей характеристики генеральной совокупности. Такой интервал для генеральной средней величины имеет вид
(![]() -
-![]() )
)![]()
![]()
![]() (
(![]() +
+![]() ), (1.39)
), (1.39)
а для генеральной доли аналогично
(w-![]() )
)![]() p
p ![]() (w +
(w +![]() ). (1.40)
). (1.40)
Следовательно, при выборочном наблюдении определяется не одно, точное значение обобщающей характеристики генеральной совокупности, а лишь ее доверительный интервал с заданным уровнем вероятности. И это серьезный недостаток выборочного метода статистики.
3.4 Определение численности выборкиРазрабатывая программу выборочного наблюдения, иногда задаются конкретным значением предельной ошибки с уровнем вероятности. Неизвестной остается минимальная численность выборки, обеспечивающая заданную точность. Ее можно получить из формул средней и предельной ошибок в зависимости от типа выборки. Так, подставляя формулы сначала (1.35) и затем (1.36) в формулу (1.38) и решая ее относительно численности выборки, получим следующие формулы
для повторной выборки
n = ![]() ; (1.41)
; (1.41)
для бесповторной выборки
n = ![]() . (1.42)
. (1.42)
Кроме того, при статистических величинах с количественными признаками надо знать и выборочную дисперсию, но к началу расчетов и она не известна. Поэтому она принимается приближенно одним из следующих способов:
—берется из предыдущих выборочных наблюдений;
—по правилу, согласно которому в размахе вариации укладывается примерно шесть стандартных отклонений (R/![]() = 6 или R/
= 6 или R/ ![]() = 6; отсюда Д = R2 /36);
= 6; отсюда Д = R2 /36);
— по правилу «трех сигм», согласно которому в средней величине укладывается примерно три стандартных отклонения (![]() /
/![]() =3; отсюда
=3; отсюда ![]() =
= ![]() /3 или Д =
/3 или Д =![]() 2/9).
2/9).
При изучении не численных признаков, если даже нет приблизительных сведений о выборочной доле, принимается w = 0,5, что по формуле (1.37) соответствует выборочной дисперсии в размере Дв = 0,5(1-0,5) = 0,25.
4. Ряды динамики 4.1 Понятие и классификация рядов динамики
Ряд динамики — это последовательность упорядоченных во времени количественных статистических величин, характеризующих развитие изучаемого явления или процесса. Конкретное значение величины называется уровнем ряда и обозначается Y, а их число в ряду обозначается n. Ряды динамики классифицируются по следующим признакам.
1. По времени — ряды моментные и интервальные (периодные) которые показывают уровень явления на конкретный момент времени или на определенный его период. Сумма уровней интервального ряда дает вполне реальную статистическую величину за несколько периодов времени, например, общий выпуск продукции, общее количество проданных акций и т.п. Уровни моментного ряда, хотя и можно суммировать, но эта сумма реального содержания, как правило, не имеет. Так, если сложить величины запасов на начало каждого месяца квартала, то полученная сумма не означает квартальную величину запасов.
Похожие работы
... , что все это рассуждение основано на предположении о нормальности распределения этих повторных выборок (т.е. нормальности выборочного распределения). Это предположение обсуждается в следующем разделе. Все ли статистики критериев нормально распределены? Не все, но большинство из них либо имеют нормальное распределение, либо имеют распределение, связанное с нормальным и вычисляемое на основе ...
... признак. Классификация. Для изучения общей теории статистики необходимо рассмотреть основные понятия на которых будет основываться все дальнейшее изложение материала. Т.к. статистика имеет дело с массовыми явлениями, то основным понятием является статистическая совокупность. Статистическая совокупность – это множество объектов или явлений изучаемых статистикой, которые имеют один или несколько ...
... пер- вичных статистических материалов, и вторичные, характеризуемые в процессе обработки и анализа данных. ПОКАЗАТЕЛЬ - одно из основных понятий статистики, под которым имеется в виду обобщенная колличественная характеристика социально-экономических явлений и процессов в их качественной определенности в условиях конкрет- ного места и времени. Примерами конкретных социально-экономических показате ...
... . Совокупность заведений, занимающихся однородным видом деятельности, представляет собой отрасль. Для количественного описания состояния и функционирования экономики в системе национальных счетов используются понятия запасов и потоков. Запасы отражают все виды активов и пассивов в экономике и отражаются в учете на определенную дату. Потоки отражают любые действия по созданию, преобразованию, ...
0 комментариев