Навигация
По форме представления — ряды абсолютных, относительных и средних величин
73481
знак
1
таблица
3
изображения
2. По форме представления — ряды абсолютных, относительных и средних величин.
3. По интервалам времени — ряды равномерные и неравномерные (полные и неполные), первые из которых имеют равные интервалы, а у вторых равенство интервалов не соблюдается.
4. По числу смысловых статистических величин — ряды изолированные и комплексные (одномерные и многомерные). Первые представляют собой ряд динамики одной статистической величины (например, индекс инфляции), а вторые — нескольких (например, потребление основных продуктов питания).
4.2 Абсолютное и относительное изменение уровней ряда
Система уровней ряда аналогична системе дискретных статистических величин X. По-прежнему вычисляются абсолютное, относительное изменения, среднее значение, а также соответствующие индексы и темпы изменения по единичным и средним значениям. Используются те же формулы средних величин от простой арифметической до геометрической.
Любое изменение уровней ряда определяется базисным и цепным способами.
Базисное абсолютное изменение представляет собой разность конкретного и первого уровней ряда, определяясь по формуле
![]() (1.43)
(1.43)
Цепное абсолютное изменение представляет собой разность конкретного и предыдущего уровней ряда, определяясь по формуле
![]() (1.44)
(1.44)
По знаку абсолютного изменения делается вывод о характере развития явления: при ![]() > 0 — рост, при
> 0 — рост, при ![]() < 0 — спад, при
< 0 — спад, при ![]() = 0 — стабильность.
= 0 — стабильность.
Для проверки правильности расчетов применяется правило, согласно которому сумма цепных абсолютных изменений равняется последнему базисному. То есть
![]() (1.45)
(1.45)
где к = n-1 — количество изменений уровней ряда (r = 1 ...к).
Базисное относительное изменение представляет собой соотношение конкретного и первого уровней ряда, определяясь по формуле
![]() (1.46)
(1.46)
Цепное относительное изменение представляет собой соотношение конкретного и предыдущего уровней ряда, определяясь по формуле
![]() (1.47)
(1.47)
Относительные изменения уровней — это по существу индексы динамики, критериальным значением которых служит 1. Если они больше ее, имеет место рост явления, меньше ее — спад, а при равенстве единице наблюдается стабильность явления.
Вычитая единицу из относительных изменений, получают темп изменения уровней, критериальным значением которого служит 0. При положительном темпе изменения имеет место рост явления, при отрицательном — спад, а при нулевом темпе изменения наблюдается стабильность явления.
Для проверки правильности расчетов применяется правило, согласно которому произведение цепных относительных изменений равняется последнему базисному.
То есть
![]() (1.48)
(1.48)
4.3 Средний уровень ряда и средние изменения
Способ расчета среднего уровня зависит от того, моментный ряд или интервальный. При моментном ряде применяется формула средней хронологической величины (1.17), но при соответствующих обозначениях имеющая вид
![]() =
= 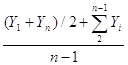 , (1.49)
, (1.49)
где Y1 и Yn — первый и последний уровни ряда; Yi — промежуточные уровни.
В случае интервального ряда его средний уровень определяется по формуле простой средней арифметической величины как
![]() =
=![]() (1.50)
(1.50)
Среднее изменение уровней ряда определяется также базисным и цепным способами.
Базисное среднее абсолютное изменение представляет собой частное от деления последнего базисного абсолютного изменения на количество изменений. То есть
![]() Б =
Б =![]() (1.51)
(1.51)
Цепное среднее абсолютное изменение уровней ряда представляет собой частное от деления суммы всех цепных абсолютных изменений на количество изменений.
То есть
![]() Ц =
Ц =![]() (1.52)
(1.52)
По знаку средних абсолютных изменений также судят о характере изменения явления в среднем: рост, спад или стабильность.
Из правила контроля базисных и цепных абсолютных изменений согласно формуле (1.45) следует, что базисное и цепное среднее изменение должны быть равными.
Наряду со средними абсолютным изменением рассчитывается и среднее относительное тоже базисным и цепным способами.
Базисное среднее относительное изменение определяется по формуле
![]() Б=
Б=![]() =
= ![]() (1.53)
(1.53)
Цепное среднее относительное изменение определяется по формуле
![]() Ц=
Ц=![]() (1.54)
(1.54)
Естественно, базисное и цепное среднее относительное изменения должны быть одинаковыми и сравнением их с критериальным значением 1 делается вывод о характере изменения явления в среднем: рост, спад или стабильность.
Вычитанием 1 из базисного или цепного среднего относительного изменения образуется соответствующий средний темп изменения, по знаку которого также можно судить о характере изменения изучаемого явления, отраженного данным рядом динамики.
4.4 Проверка ряда на наличие тренда
Всякий ряд динамики теоретически может быть представлен в виде составляющих:
Ø тренд – основная тенденция развития ряда, обусловливающая увеличение или снижение его уровней;
Ø циклические (периодические) колебания (в том числе сезонные);
Ø случайные колебания.
Проверка ряда динамики на наличие в нем тренда возможна несколькими способами (в порядке усложнения):
1. Графический метод, когда на графике по оси абсцисс откладывается время, а по оси ординат – уровни ряда. Соединив полученные точки линиями, в большинстве случаев можно выявить тренд визуально.
2. Метод средних, согласно которому изучаемый ряд динамики делится на два равных подряда, для каждого из которых определяется средняя величина ![]() и
и ![]() . И если они различаются существенно (более 10%), то признается наличие тренда.
. И если они различаются существенно (более 10%), то признается наличие тренда.
3. Метод Кокса и Стюарта, согласно которому ряд динамики делится на три равные по числу уровней группы и существенное различие выявляется между средними уровнями первой и третьей групп. Если общее число уровней не делится на три, то надо добавить недостающий уровень или исключить излишний.
4. Метод Валлиса и Мура, согласно которому наличие тренда признается в том случае, если ряд не содержит либо содержит в приемлемом количестве фазы, т.е. перемену знака при определении абсолютного изменения цепным способом.
5. Метод серий, согласно которому каждый уровень ряда считается принадлежащим к одному из двух типов, например типу А – меньше медианного или среднего значения или типу В – больше его. Затем в образовавшейся последовательности типов устанавливается число серий R. Они называются последовательностью уровней одинакового типа, которая граничит с уровнями другого типа. Если в ряду динамики общая тенденция к росту или снижению уровней отсутствует, то число серий является случайной величиной, распределенной приближенно по нормальному закону (при n>30) или по распределению Стьюдента (при n<30). Следовательно, если закономерности в изменениях уровней нет, то случайная величина R оказывается в доверительном интервале
![]()
где t – коэффициент доверия для принятого уровня вероятности при нормальном законе или со степенью свободы k = (n - 1) при распределении Стьюдента;
![]() – среднее число серий в ряду, определяемое по формуле:
– среднее число серий в ряду, определяемое по формуле:
![]() ;
;
![]() – среднее квадратическое отклонение числа серий в ряду, определяемое по формуле
– среднее квадратическое отклонение числа серий в ряду, определяемое по формуле
![]() .
.
Подставляя среднее число серий и его среднее квадратическое отклонение в доверительный интервал, получим его развернутое значение в виде
![]() .
.
Значит, с заданной вероятностью тренд имеет место, если установленное число серий ряда не входит в доверительный интервал, и тренд отсутствует, если установленное число серий находится в этом интервале.
4.5 Непосредственное выделение трендаЭтот процесс можно осуществлять тремя способами.
1. Укрупнение интервалов, когда ряд динамики делят на некоторое достаточно большое число равных интервалов. Если интервальные средние уровни не позволяют увидеть тенденцию, то увеличивают размах интервалов, уменьшая одновременно их число.
2. Методом скользящей средней, когда уровни ряда заменяются средними величинами, получаемыми из данного уровня и нескольких симметрично его окружающих уровней. Такие средние называются интервалом сглаживания. Он может быть нечетным (3, 5, 7 и т.д. уровней) или четным (2, 4, 6 и т.д. уровней). Чаще применяется нечетный интервал, потому что сглаживание идет проще. При этом формулы для расчета скользящей средней величины имеют вид
![]() ;
;
![]() .
.
Недостаток метода скользящей средней заключается в условности определения сглаженных значений для уровней в начале и в конце ряда. Получают их по специальным формулам. Так, при сглаживании по трем уровням условное значение первого уровня нового ряда рассчитывается по формуле
![]() .
.
Для уровня в конце нового ряда при таком сглаживании формула аналогична:
![]() .
.
При сглаживании по пяти уровням условными оказываются по два уровня в начале и в конце нового ряда. Первое условное значение определяется по формуле
![]() ,
,
а второе – по формуле
![]() .
.
Для двух уровней в конце нового ряда при таком сглаживании формулы аналогичны. Так, последнее расчетное значение определяется по формуле
![]() ,
,
а предпоследнее значение по формуле
![]() .
.
3. Метод аналитического выравнивания, под которым понимается формализация основной, проявляющейся во времени тенденции развития изучаемого явления. В итоге получают наиболее общий результат действия всех причинных факторов, а отклонение конкретных уровней ряда от формализованных значений объясняют действием фактов, проявляющихся случайно или циклически. В результате приходят к трендовой модели вида
![]() , (1.55)
, (1.55)
где ![]() – математическая функция развития;
– математическая функция развития; ![]() – случайное или циклическое отклонение от функции; t – время в виде номера периода (уровня ряда). Цель такого метода – выбор теоретической зависимости
– случайное или циклическое отклонение от функции; t – время в виде номера периода (уровня ряда). Цель такого метода – выбор теоретической зависимости ![]() в качестве одной из функций:
в качестве одной из функций:
![]() – прямая линия;
– прямая линия;
![]() – гипербола;
– гипербола;
![]() – парабола;
– парабола;
![]() – степенная;
– степенная;
![]() – ряд Фурье.
– ряд Фурье.
Определение параметров ![]() в этих функциях может вестись несколькими способами, но самые незначительные отклонения аналитических (теоретических) уровней (
в этих функциях может вестись несколькими способами, но самые незначительные отклонения аналитических (теоретических) уровней (![]() – читается как «игрек, выравненный по t») от фактических (
– читается как «игрек, выравненный по t») от фактических (![]() ) дает метод наименьших квадратов – МНК (т.е.
) дает метод наименьших квадратов – МНК (т.е. ![]() минимально). При этом методе учитываются все эмпирические уровни и должна обеспечиваться минимальная сумма квадратов отклонений эмпирических значений уровней
минимально). При этом методе учитываются все эмпирические уровни и должна обеспечиваться минимальная сумма квадратов отклонений эмпирических значений уровней ![]() от теоретических
от теоретических ![]() :
:
![]() . (1.56)
. (1.56)
В частности, при выравнивании по прямой вида ![]() , параметры
, параметры ![]() и
и ![]() отыскиваются по МНК следующим образом. В формуле (1.56) вместо
отыскиваются по МНК следующим образом. В формуле (1.56) вместо ![]() записываем его конкретное выражение
записываем его конкретное выражение ![]() . Тогда
. Тогда
![]() .
.
Дальнейшее решение сводится к задаче на экстремум, т.е. к определению того, при каком значении ![]() и
и ![]() функция двух переменных S может достигнуть минимума. Как известно, для этого надо найти частные производные S по
функция двух переменных S может достигнуть минимума. Как известно, для этого надо найти частные производные S по ![]() и
и ![]() , приравнять их к нулю и после элементарных преобразований решить систему двух уравнений с двумя неизвестными.
, приравнять их к нулю и после элементарных преобразований решить систему двух уравнений с двумя неизвестными.
В соответствии с вышеизложенным найдем частные производные

Сократив каждое уравнение на 2, раскрыв скобки и перенеся члены с y в правую сторону, а остальные – оставив в левой, получим систему нормальных уравнений
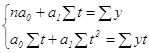
где n – количество уровней ряда; t – порядковый номер в условном обозначении периода или момента времени; y – уровни эмпирического ряда.
Эта система и, соответственно, расчет параметров ![]() и
и ![]() упрощаются, если отсчет времени ведется от середины ряда. Например, при нечетном числе уровней серединная точка (год, месяц) принимается за нуль. Тогда предшествующие периоды обозначаются соответственно –1, –2, –3 и т.д., а следующие за средним (центральным) – соответственно 1, 2, 3 и т.д. При четном числе уровней два серединных момента (периода) времени обозначают –1 и +1, а все последующие и предыдущие, соответственно, через два интервала:
упрощаются, если отсчет времени ведется от середины ряда. Например, при нечетном числе уровней серединная точка (год, месяц) принимается за нуль. Тогда предшествующие периоды обозначаются соответственно –1, –2, –3 и т.д., а следующие за средним (центральным) – соответственно 1, 2, 3 и т.д. При четном числе уровней два серединных момента (периода) времени обозначают –1 и +1, а все последующие и предыдущие, соответственно, через два интервала: ![]() ,
, ![]() ,
, ![]() и т.д.
и т.д.
При таком порядке отсчета времени (от середины ряда) ![]() = 0, поэтому система нормальных уравнений упрощается до следующих двух уравнений, каждое из которых решается самостоятельно:
= 0, поэтому система нормальных уравнений упрощается до следующих двух уравнений, каждое из которых решается самостоятельно:
 (1.57)
(1.57)
Как видим, при такой нумерации периодов параметр ![]() представляет собой среднее значение уровней ряда. К данному виду можно свести гиперболу, если ввести замену
представляет собой среднее значение уровней ряда. К данному виду можно свести гиперболу, если ввести замену ![]() , тогда к ней полностью применима система уравнений (1.57).
, тогда к ней полностью применима система уравнений (1.57).
По полученной модели для каждого периода (каждой даты) определяются теоретические уровни тренда (![]() ) и оценивается надежность (адекватность) выбранной модели тренда.
) и оценивается надежность (адекватность) выбранной модели тренда.
4.6 Оценка надежности уравнения тренда
Выбрав и составив уравнение, проводят оценку его надежности с помощью критерия Фишера, сравнивая его расчетное значение Fр с теоретическими значениями FТ, приведенными в специальных таблицах любого справочника по высшей математике. При этом расчетный критерий Фишера определяется по формуле
![]() , (1.58)
, (1.58)
где k – число параметров (членов) выбранного уравнения тренда; ДА – дисперсия аналитическая; До – дисперсия остаточная в виде разности фактической ДФ и аналитической дисперсий.
В свою очередь, фактическая и аналитическая дисперсии отклонений уровней ряда определяются по формулам
![]() ; (1.59)
; (1.59)
![]() . (1.60)
. (1.60)
![]()
Сравнение расчетного и теоретического значений критерия Фишера ведется обычно при уровне значимости 0,05 с учетом степеней свободы ![]() и
и ![]() . При условии Fр> FТ считается, что выбранная математическая модель ряда динамики адекватно отражает обнаруженный в нем тренд.
. При условии Fр> FТ считается, что выбранная математическая модель ряда динамики адекватно отражает обнаруженный в нем тренд.
4.7 Гармонический анализ сезонных колебаний[1]*
Особое место при анализе сезонных колебаний занимает выравнивание с помощью ряда Фурье, в котором уровни можно выразить как функцию времени следующим уравнением:
![]() .
.
То есть сезонные колебания уровней динамического ряда можно представить в виде синусоидальных колебаний. Поскольку последние представляют собой гармонические колебания, то синусоиды, полученные при выравнивании по ряду Фурье, называют гармониками различных порядков (показатель k в этом уравнении определяет число гармоник). Обычно при выравнивании по ряду Фурье рассчитывают несколько гармоник (чаще не более 4) и затем уже определяют, с каким числом гармоник ряд Фурье наилучшим образом отражает изменения уровней ряда.
При выравнивании по ряду Фурье периодические колебания уровней динамического ряда представлены в виде суммы нескольких синусоид (гармоник), наложенных друг на друга.
Так, при k=1 ряд Фурье будет иметь вид
![]() ,
,
а при k=2, соответственно,
![]()
и так далее.
Параметры уравнения теоретических уровней, определяемого рядом Фурье, находят, как и в других случаях, методом наименьших квадратов. Приведем без вывода формулы, используемые для исчисления параметров ряда Фурье:
![]() ;
; ![]() ;
; ![]() .
.
Последовательные значения t обычно определяются от 0 с увеличением (приростом), равным ![]() , где n – число уровней эмпирического ряда.
, где n – число уровней эмпирического ряда.
Например, при n=10 временнЫе точки t можно записать следующим образом:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() ,
,
или (после сокращения)
![]()
![]() ;
; ![]() ;
; ![]() ;
; ![]() ;
; ![]() ;
; ![]() ;
; ![]() ;
; ![]() ;
; ![]() .
.
При n=12 значения t, соответственно будут
![]()
![]()
![]()
![]()
![]()
![]()
![]() ;
; ![]()
![]()
![]()
![]()
![]() .
.
Значения ![]() и
и ![]() удобно расположить в таблице (для двух гармоник):
удобно расположить в таблице (для двух гармоник):
В следующей таблице приведены исходные данные (графы 1 и 2) и расчет показателей, необходимых для получения уравнений первой и второй гармоники (k=1 и k=2).
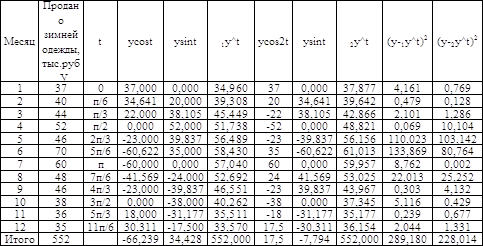
Искомое уравнение первой гармоники имеет вид
![]() .
.
В шестой графе получены теоретические значения объема продажи зимней одежды по месяцам. Очевидно, что они значительно отличаются от эмпирических. Поэтому определим уравнение второй гармоники, т.е.
![]() .
.
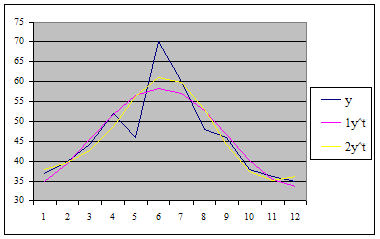
В девятой графе получены теоретические значения ![]() , которые более близки к эмпирическим уровням, чем
, которые более близки к эмпирическим уровням, чем ![]() . Об этом свидетельствует и сумма квадратов отклонений теоретических значений от эмпирических (итого двух последних столбцов). После выбора оптимального уравнения, естественно, что его нужно проверить на адекватность с помощью критерия Фишера (параграф 4.6). В нашем примере FР1=14,45>FТ=4,26, FР2=7,60>FТ=4,12 значит обе модели адекватны и их можно использовать для прогнозирования. Графическое отображение на следующей диаграмме свидетельствует о более точном представлении во второй гармонике.
. Об этом свидетельствует и сумма квадратов отклонений теоретических значений от эмпирических (итого двух последних столбцов). После выбора оптимального уравнения, естественно, что его нужно проверить на адекватность с помощью критерия Фишера (параграф 4.6). В нашем примере FР1=14,45>FТ=4,26, FР2=7,60>FТ=4,12 значит обе модели адекватны и их можно использовать для прогнозирования. Графическое отображение на следующей диаграмме свидетельствует о более точном представлении во второй гармонике.
Аналогично рассчитываются параметры уравнения с применением третьей и четвертой гармоник и проверяют близость теоретических значений к эмпирическим.
4.8 Прогнозирование при помощи трендаНахождение по имеющимся данным за определенный период времени некоторых недостающих значений признака внутри этого периода называется интерполяцией. Нахождение значений признака за пределами анализируемого периода называется экстраполяцией.
Применение экстраполяции для прогнозирования должно основываться на предположении, что найденная закономерность развития внутри динамического ряда сохраняется и вне этого ряда. Это означает, что основные факторы, сформировавшие выявленную закономерность изменений уровней ряда во времени, сохранится в будущем.
При составлении прогнозов уровней социально-экономических явлений обычно оперируют не точечной, а интервальной оценкой, рассчитывая так называемые доверительные интервалы прогноза. Границы интервалов определяются по формуле
![]() , (1.61)
, (1.61)
где ![]() – точечный прогноз, рассчитанный по модели тренда;
– точечный прогноз, рассчитанный по модели тренда;
![]() – коэффициент доверия по распределению Стьюдента при уровне значимости
– коэффициент доверия по распределению Стьюдента при уровне значимости ![]() и числе степеней свободы
и числе степеней свободы ![]() =n-1;
=n-1;
![]() – ошибка аппроксимации.
– ошибка аппроксимации.
Уровень значимости ![]() связан с вероятностью
связан с вероятностью ![]() следующей формулой
следующей формулой
![]() . (1.62)
. (1.62)
Ошибка аппроксимации (среднее квадратическое отклонение тренда) определяется по следующей формуле
![]() , (1.63)
, (1.63)
где ![]() и
и ![]() – соответственно фактические и теоретические (расчетные) значения уровней ряда динамики;
– соответственно фактические и теоретические (расчетные) значения уровней ряда динамики;
n – число уровней ряда;
k – число параметров (членов) в уравнении тренда.
5. Индексы 5.1 Индивидуальные индексы
Индекс — относительная величина, показывающая, во сколько раз уровень изучаемого явления в данных условиях отличается от уровня того же явления в других условиях. В статистическом анализе индексы используются не только для сопоставления уровней явлений, но и для установления значимости причин, вызывающих их изменение.
Если анализируются простые явления или не имеет значения структура сложных явлений, то применяются индивидуальные индексы. Например, такие простые явления как количество проданного товара q и его цена р своим произведением образуют такое сложное явление, как выручка от продаж Q=qp. Сравнение их значений по отдельности для конкретного товара в отчетном периоде времени относительно какого-либо базисного периода и дает индивидуальные индексы:
—количества товара iq = q1 /q0 ;
—его цены ip = p1/p0 ;
—выручки от продаж iQ = Q1 /Q0 .
Очевидно, что индивидуальный индекс сложного явления формируется из таких индексов простых его составляющих по типологической формуле его определения. То есть
iQ=iqip (1.64)
Подставив сюда индивидуальный индекс выручки, записываем:
Q1/Q0= iqip
откуда получаем, что
Q1= iqipQ0 (1.65)
Формула (1.65) представляет собой двухфакторную мультипликативную модель сложного явления, позволяющую находить его изменение под влиянием каждого фактора в отдельности.
Мультипликативной она называется потому, что содержит только действие умножения. Если в формуле только сложение, или вычитание, или оба этих действия, то она называется аддитивной моделью. Если в формуле только деление, то она называется кратной моделью. Если в формуле сложение и вычитание с умножением и делением в любом сочетании, то она называется смешанной моделью.
Общее изменение выручки равняется ![]() =Q1-Q0, а ее изменение от каждого фактора определяется следующим образом. От изменения количества товара при постоянной цене (ip = 1) оно равно
=Q1-Q0, а ее изменение от каждого фактора определяется следующим образом. От изменения количества товара при постоянной цене (ip = 1) оно равно
![]() q= iqQ0 - Q0 = (iq–1) Q0, (1.66)
q= iqQ0 - Q0 = (iq–1) Q0, (1.66)
а при изменении еще и цены оно будет равным
![]() p= Q1 - Q0 -
p= Q1 - Q0 -![]() q= iqipQ0 - Q0 - (iq–1) Q0= iq(ip–1) Q0, (1.67)
q= iqipQ0 - Q0 - (iq–1) Q0= iq(ip–1) Q0, (1.67)
Так, если выручка от продаж возросла с Q0 = 8 млн. руб. в предыдущем периоде до Q1 =12,18 млн. руб. в последующем при увеличении количества проданного товара на 5% (iq =1,05) и повышении цены на 45% (ip =1,45), то можно по формуле (1.54) записать, что
Q1 = 1,05*1,45*8 = 12,18 млн. руб.
При этом весь прирост выручки в сумме ![]() = 12,18-8=4,18 млн. руб. вызван увеличением обоих факторов. За счет изменения количества проданного товара он по формуле (1.66) составил
= 12,18-8=4,18 млн. руб. вызван увеличением обоих факторов. За счет изменения количества проданного товара он по формуле (1.66) составил ![]() q =(1,05-1)8=0,4 млн. руб., а за счет изменения цены по формуле (1.67) равняется
q =(1,05-1)8=0,4 млн. руб., а за счет изменения цены по формуле (1.67) равняется ![]() p =1,05(1,45-1)8 =3,78 млн. руб. Для контроля отмечаем, что сумма факторных изменений выручки равна общему: 0,4+3,78=4,18 млн. руб.
p =1,05(1,45-1)8 =3,78 млн. руб. Для контроля отмечаем, что сумма факторных изменений выручки равна общему: 0,4+3,78=4,18 млн. руб.
Формулы (1.66) и (1.67) получены исходя из того, что в основной формуле выручки количество товара - первый фактор, а цена - второй. Если эти факторы поменять местами, то выручка и ее общее изменение останутся прежними, но изменения от каждого фактора будут другими.
Так, если основываться на формуле выручки вида Q = pq, то ее изменение за счет цены, как первого фактора, по аналогии с формулой (1.66) будет равняться
![]() p= (ip–1) Q0 , (1.68)
p= (ip–1) Q0 , (1.68)
Изменение выручки за счет количества товара, как второго фактора, по аналогии с формулой (1.67) определится по выражению
![]() q= ip(iq–1) Q0. (1.69)
q= ip(iq–1) Q0. (1.69)
Суммарное по факторам изменение выручки по-прежнему равняется ее общему изменению.
В рассмотренном примере, считая цену первым фактором и применяя формулу (1.68), определяем, что изменение выручки за счет повышения цены равняется
![]() p = (1,45-1)8 = 3,6 млн. руб.
p = (1,45-1)8 = 3,6 млн. руб.
Изменение выручки за счет увеличения количества проданного товара, как второго фактора, по формуле (1.69) равно
![]() q = 1,45(1,05-1)8 = 0,58 млн. руб.
q = 1,45(1,05-1)8 = 0,58 млн. руб.
Общее изменение выручки осталось прежним: 3,6+0,58=4,18 млн. руб.
В связи с различными факторными изменениями выручки в зависимости от места фактора в ее основной формуле, встает вопрос, какую же формулу выручки применять для анализа. Это зависит от конкретной экономической ситуации. Если увеличение выручки обеспечивается главным образом за счет роста количества проданного товара при более или менее стабильной цене, то товар считается первым фактором, а цена — вторым. Если же увеличение выручки достигается в основном повышением цен без увеличения и даже при снижении количества проданного товара, то цена считается первым фактором, а товар — вторым.
Значит, очередность анализа по факторам вытекает из вида формулы сложного явления. Так, если материальные затраты М на выпуск продукции определяются как произведение ее количества q, удельного расхода материала т и его цены р, то типологическая формула имеет вид
М = qmp, (1.70)
а трехфакторная мультипликативная модель запишется как
M1=iqimipM0. (1.71)
Следовательно, можно записать следующие формулы факторных изменений материальных затрат
![]()
![]()
![]()
Меняя факторы местами в основной формуле (1.70), можно получать другие факторные формулы. Но всегда общее изменение материальных затрат, равное сумме факторных изменений, будет одинаковым.
Подобные мультипликативные модели можно формировать для неограниченного числа факторов.
5.2 Простые общие индексыИндекс становится общим, когда в основной формуле показывается неоднородность изучаемого явления. Например, анализируется изменение выручки от продаж не одного, а всех или нескольких видов товаров. Тогда общий индекс количества проданных товаров будет равен
![]() =
= ![]() (1.72)
(1.72)
Аналогично по ценам
![]() =
=![]() (1.73)
(1.73)
Аналогично по выручке
![]() =
=![]() =
=![]() (1.74)
(1.74)
Однако здесь двухфакторная мультипликативная модель не может выглядеть как в случае индивидуальных индексов, потому что произведение простых общих индексов количества товаров и цен не равно общему индексу выручки. То есть ![]()
![]()
![]()
![]() и убеждаемся в этом неравенстве, подставив значения общих индексов из формул (1.72)—(1.74).
и убеждаемся в этом неравенстве, подставив значения общих индексов из формул (1.72)—(1.74).
В самом деле:

Как видим, в числителе и знаменателе левой части произведения сумм, а в числителе и знаменателе правой части сумма произведений и они, конечно, не адекватны.
Это вызвано тем, что записанные выше общие индексы простых явлений не отражают взаимосвязи между собой в сложном явлении и потому считаются не объективными. Поэтому они помечены штрихом и названы простыми общими индексами.
5.3 Агрегатные общие индексыОбъективность общим индексам придает их запись в агрегатном виде, предложенная испанцем Ласпейресом и немцем Пааше.
Агрегатный общий индекс Ласпейреса для количества товаров как первого фактора выручки определяется по формуле
![]() =
=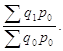 (1.75)
(1.75)
Аналогично можно записать агрегатный общий индекс Ласпейреса для цен как первого фактора выручки, то есть
![]() =
=![]() (1.76)
(1.76)
В формулах Ласпейреса знаменатели по существу одинаковые, представляя собой выручку базисного периода, а числители разные. В формуле (1.75) это отчетная выручка в базисных ценах (количесгво товаров отчетное, а цены — базисные), в формуле (1.76) наоборот — базисная выручка в отчетных ценах (цены отчетные, а количество товаров — базисное).
Агрегатные общие индексы Пааше применяются ко вторым факторам мультипликативных моделей. Поэтому такой индекс для цен как второго фактора выручки определяется по формуле
![]() =
=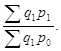 (1.77)
(1.77)
Аналогично можно записать агрегатный общий индекс Пааше для количества товаров как второго фактора выручки, то есть
![]() =
= (1.78)
(1.78)
В формулах Пааше числители по существу одинаковые, представляя собой выручку отчетного периода, а знаменатели аналогичны числителям формул Ласпейреса.
Для облегчения запоминания студентами формул Ласпейреса и Пааше предлагаю обратить внимание на букву «ш» в слове «Пааше», которая напоминает «111» - так обозначены отчетные периоды в общей формуле (две единицы – в числителе, а одна – в знаменателе). В формуле же Ласпейреса – три нуля (наоборот к формуле Пааше).
Произведения количественного индекса Ласпейреса и ценового индекса Пааше, а также ценового индекса Ласпейреса и количественного индекса Пааше дают общий индекс выручки.
Однако вид этих формул показывает, что однофакторные индексы Ласпейреса и Пааше не равны между собой. То есть не равными являются количественные индексы Ласпейреса и Пааше и ценовые. Американский экономист Гершенкрон обширными расчетами установил, что по одному и тому же фактору индекс Ласпейреса всегда больше индекса Пааше и это открытие названо эффектом Гершенкрона.
Но в статистике должно быть одно значение индекса, поэтому американский экономист Фишер предложил применять среднюю геометрическую величину из индексов Ласпейреса и Пааше, определяя ее по формулам:
для количества товаров
![]() =
=![]() (1.79)
(1.79)
для цен
![]() =
=![]() (1.80)
(1.80)
Вместе с тем, проведенные Ворониным В.Ф. многочисленные расчеты показали, что для целей статистики вполне можно применять не среднюю геометрическую, а простую среднюю арифметическую величину из индексов Ласпейреса и Пааше, определяя ее по формулам:
для количества товаров
![]() =
=![]() (1.81)
(1.81)
для цен
![]() =
=![]() (1.82)
(1.82)
Например, если индекс Ласпейреса 1,8 и индекс Пааше 1,4 , то средний геометрический индекс по предложению Фишера равняется
IФ=![]() =1,59,
=1,59,
а средний арифметический индекс по нашему предложению составит
IВ=(1,8+1,4)/2 = 1,60.
Как видим, разница очень незначительная. Но при этом важно во всех периодах времени постоянно пользоваться одной и той же средней величиной: или геометрической, или арифметической.
5.4 Общие индексы как средние из индивидуальныхПомимо записи общих индексов в агрегатном виде, на практике часто используют формулы их расчета как величин, средних из соответствующих индивидуальных индексов.
Используя их формулы, можем записывать, что q1 = q0iq и p1 = p0ip, а также, что q0 =q1/iq и р0=р1/ip. Подставив отчетные значения количества товара и цены в формулу общего индекса выручки, получим
IQ= =
= =
=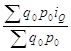 . (1.83)
. (1.83)
Значит, общий индекс выручки можно определять только через ее базисные значения с умножением в числителе на индивидуальный индекс выручки по конкретному товару.
Теперь подставим базисные значения количества товара и цены в формулу общего индекса выручки. Тогда получим
IQ=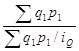 . (1.84)
. (1.84)
Значит, общий индекс выручки можно определять только через ее отчетные значения с делением в знаменателе на индивидуальный индекс выручки по конкретному товару.
Аналогично через индивидуальные индексы количества товара и цены можно выразить агрегатные общие индексы Ласпейреса и Пааше.
5.5 Индекс структурных сдвиговВыше изложенные общие индексы применимы к изучению явлений, образованных как разными, так и однородными процессами. В последнем случае динамику итога можно показать через простые общие индексы отдельных факторов.
Для доказательства в формуле количественного индекса Ласпейреса числитель умножим и разделим на ![]() , а знаменатель – на
, а знаменатель – на ![]() . Тогда будем иметь
. Тогда будем иметь
![]() =
=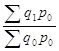 =
=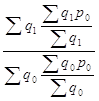 =
=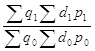 ,
,
где![]() =
=![]() - простой общий индекс количества товаров;
- простой общий индекс количества товаров;
![]() =
=![]() – доля или удельный вес конкретного товара в общем количестве;
– доля или удельный вес конкретного товара в общем количестве;
 =
=![]() - агрегатный общий индекс структуры, доли или удельного веса, часто называемый индексом структурных сдвигов.
- агрегатный общий индекс структуры, доли или удельного веса, часто называемый индексом структурных сдвигов.
Следовательно, количественный индекс Ласпейреса равняется произведению простого общего индекса количества товаров и индекса структурных сдвигов. То есть
![]() =
=![]()
![]() , (1.85)
, (1.85)
откуда для определения индекса структурных сдвигов получается довольно простая формула
![]() =
=![]() /
/![]() . (1.86)
. (1.86)
Используя формулу (1.83) в двухфакторной модели общего индекса выручки, получим его трехфакторную мультипликативную модель вида
IQ=![]()
![]() =
=![]()
![]()
![]() . (1.87)
. (1.87)
Трехфакторная модель возможна к широкому применению в экономическом анализе для установления количественного влияния каждого фактора на вариацию сложного явления.
5.6 Факторный анализ общей и частной выручки
Приравнивая правую часть полученной трехфакторной модели и среднюю часть формулы (1.72), записываем выражение
![]() =
=![]()
![]()
![]() ,
,
из которого заключаем, что общую выручку отчетного периода можно определить через общую выручку базисного периода и общие индексы по мультипликативной формуле
![]() =
=![]()
![]()
![]()
![]() . (1.88)
. (1.88)
Эта формула в точности соответствует мультипликативной модели (1.71), что позволяет применять соответствующие формулы факторных изменений. Так, изменение общей выручки за счет изменения общего количества товаров определится по формуле
![]() =
=![]()
![]() . (1.89)
. (1.89)
Изменение общей выручки за счет изменения долей конкретных товаров (структурных сдвигов) определяется по формуле
![]() =
=![]()
![]()
![]() . (1.90)
. (1.90)
И наконец изменение общей выручки за счет изменения цен определяется по формуле
![]() =
=![]()
![]()
![]()
![]() . (1.91)
. (1.91)
Естественно, сумма факторных изменений должна равняться общему итоговому изменению. То есть для контроля правильности анализа проверяется выполнение условия
![]() =
=![]() -
-![]() =
=![]() +
+![]() +
+![]() . (1.92)
. (1.92)
Факторный анализ изменения выручки по отдельному товару в составе общего товарооборота ведется на основе следующей трехфакторной мультипликативной модели
![]() =
=![]()
![]()
![]()
![]() , (1.93)
, (1.93)
где ![]() =
= ![]() — индивидуальный индекс доли конкретного товара.
— индивидуальный индекс доли конкретного товара.
Следовательно, изменения выручки по конкретному товару за счет изменения каждого фактора могут определяться по формулам:
за счет изменения общего количества товаров (товарооборота)
![]() =
=![]() ; (1.94)
; (1.94)
за счет изменения доли конкретного товара
![]() =
=![]() ; (1.95)
; (1.95)
за счет изменения цены конкретного товара
![]() =
=![]() . (1.96)
. (1.96)
Естественно, факторные изменения выручки по конкретному товару в сумме должны равняться полному изменению выручки по этому товару. То есть для контроля правильности анализа проверяется выполнение условия
![]() =
=![]() -
-![]() =
=![]() +
+![]() +
+![]() . (1.97)
. (1.97)
где j — признак конкретного товара.
Кроме того, полные изменения выручки по каждому товару в сумме должны равняться общему изменению выручки по всему товарообороту. То есть для контроля правильности анализа дополнительно проверяется выполнение условия ![]() =
=![]() . При этом для облегчения необходимого контроля результаты факторного анализа представляются в виде факторной таблицы, рассмотренной ниже в методических указаниях по теме.
. При этом для облегчения необходимого контроля результаты факторного анализа представляются в виде факторной таблицы, рассмотренной ниже в методических указаниях по теме.
В полученной трехфакторной модели (1.87) второй и третий индексы запишем подробно по формулам их определения, а третий еще и сократим на ![]() . Тогда сначала будем иметь
. Тогда сначала будем иметь
IQ=![]()
![]()
![]() =
=![]()
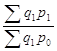 =
=![]()
 =
=![]()
![]() =
=![]() ,
,
а, произведя очевидное сокращение и обозначив
![]() =
=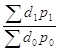 - индекс переменного состава, (1.98)
- индекс переменного состава, (1.98)
получим общий индекс выручки в виде формулы
IQ=![]()
![]() . (1.99)
. (1.99)
![]() =
=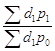 называется индексом фиксированного (постоянного) состава. (1.100)
называется индексом фиксированного (постоянного) состава. (1.100)
Следовательно, общий индекс выручки есть произведение простого общего индекса количества товаров и индекса переменного состава. Последний часто путают с ценовым индексом Пааше, хотя формулы их определения совершенно разные.
Из формулы (1.99) можно заключить, что индекс переменного состава есть частное от деления общего индекса выручки на простой общий индекс количества товаров, тогда как ценовый индекс Пааше наравне с формулой (1.77) возможно определять как отношение общего индекса выручки и количественного индекса Ласпейреса.
Изложенные математические выкладки позволяют общий индекс выручки определять следующими семью способами
![]() ==
==![]()
![]() =
=![]()
![]() ===
===![]()
![]()
![]() =
=![]()
![]() .
.
Результат расчета любым способом должен быть одинаковым и это яркий пример того, что истина всегда одна, хотя пути ее достижения могут быть разными.
[1] Тема повышенной сложности
Похожие работы
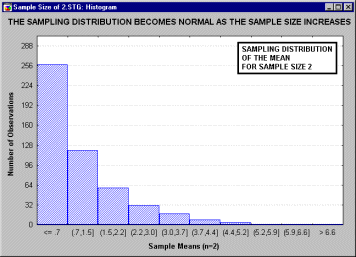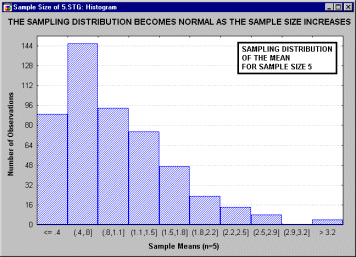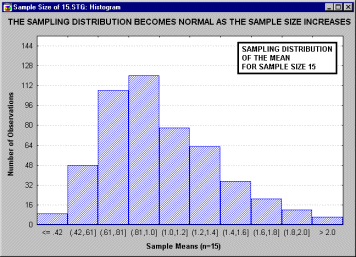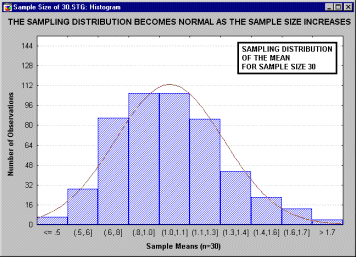
... , что все это рассуждение основано на предположении о нормальности распределения этих повторных выборок (т.е. нормальности выборочного распределения). Это предположение обсуждается в следующем разделе. Все ли статистики критериев нормально распределены? Не все, но большинство из них либо имеют нормальное распределение, либо имеют распределение, связанное с нормальным и вычисляемое на основе ...
... признак. Классификация. Для изучения общей теории статистики необходимо рассмотреть основные понятия на которых будет основываться все дальнейшее изложение материала. Т.к. статистика имеет дело с массовыми явлениями, то основным понятием является статистическая совокупность. Статистическая совокупность – это множество объектов или явлений изучаемых статистикой, которые имеют один или несколько ...
... пер- вичных статистических материалов, и вторичные, характеризуемые в процессе обработки и анализа данных. ПОКАЗАТЕЛЬ - одно из основных понятий статистики, под которым имеется в виду обобщенная колличественная характеристика социально-экономических явлений и процессов в их качественной определенности в условиях конкрет- ного места и времени. Примерами конкретных социально-экономических показате ...
... . Совокупность заведений, занимающихся однородным видом деятельности, представляет собой отрасль. Для количественного описания состояния и функционирования экономики в системе национальных счетов используются понятия запасов и потоков. Запасы отражают все виды активов и пассивов в экономике и отражаются в учете на определенную дату. Потоки отражают любые действия по созданию, преобразованию, ...
0 комментариев