Навигация
Объяснить, что такое уровень статистической значимости
14268
знаков
13
таблиц
2
изображения
4. Объяснить, что такое уровень статистической значимости.
Уровень значимости – это вероятность того, что мы сочли различия существенными, а они на самом деле случайны.
Когда мы указываем, что различия достоверны на 5%-ом уровне значимости, или при p≤0,05. то мы имеем виду, что вероятность того, что они все-таки недостоверны, составляет 0,05. Когда мы указываем, что различия достоверны на 1%-ом уровне значимости, или при p≤0,01, то мы имеем в виду, что вероятность того, что они все-таки недостоверны, составляет 0,01.
Если перевести все это на более формализованный язык, то уровень значимости - это вероятность отклонения нулевой гипотезы, в то время как она верна.
В статистике величину называют статисти́чески зна́чимой, если мала вероятность чисто случайного возникновения её или ещё более крайних величин. Здесь под крайностью понимается степень отклонения от нуль-гипотезы. Разница называется «статистически значимой», если имеются данные, появление которых было бы маловероятно, если предположить, что эта разница отсутствует; это выражение не означает, что данная разница должна быть велика, важна, или значима в общем смысле этого слова.
Уровень значимости обыкновенно обозначают греческой буквой α (альфа). Популярными уровнями значимости являются 5%, 1%, и 0.1%. Если тест выдаёт p-величину меньше α-уровня, то нуль-гипотеза отклоняется. Такие результаты неформально называют «статистически значимыми». Например, если кто-то говорит что «шансы того, что случившееся является совпадением, равны одному из тысячи», то имеется в виду 0.1 % уровень значимости.
5. Как интерпретировать моду, медиану и среднее?
Мода — точка, в которой плотность распределения имеет локальный максимум. Распределение может иметь несколько мод.
МЕДИАНА - один из показателей центра распределения для порядковых и количественных переменных; обозначается Ме. Представляет собой значение переменной, которое делит выборку пополам таким образом, чтобы для 50% объектов из выборки значения переменной не превосходили Ме, а для других 50% объектов - были не меньше, чем Ме.
Математи́ческое ожида́ние — понятие среднего значения случайной величины в теории вероятностей. Все рассмотренные характеристики: мода, медиана, средняя арифметическая, среднее взвешенное ѕ являются средними. Они характеризуют центральные тенденции одномерного распределения.
6. Квантильная шкала – это шкала, условием для построения которой является возможность ранжирования испытуемых по величине у.
Квантильные ранги имеют прямоугольное распределение, то есть в каждом интервале квантильнои шкалы содержится одинаковая доля обследованных лиц. Стандартизация тестовых оценок путем их перевода в квантильную шкалу стирает различия в особенностях распределения психодиагностических показателей, так как сводит любое распределение к прямоугольному. Поэтому с позиции теории измерений квантильные шкалы относятся к шкалам порядка: они дают информацию, у кого из испытуемых сильнее выражено тестируемое свойство, но ничего не позволяют сказать о том, насколько или во сколько раз сильнее.
7. Если коэффициент корреляции по модулю оказывается близким к единице, то исследуемые величины линейно зависимы.
8. Решить задачу, используя критерий Фридмана.
Шести респондентам предъявлялся тест Равенна. Фиксируется время решения каждого задания. Экспериментатор предполагает, что будут найдены статистически значимые различия между временем решения первых трёх заданий. Результаты замеров представлены в таблице.
| № п/п | Время решения 1-ого задания теста, сек. | Время решения второго задания теста, в сек. | Время решения третьего задания теста в сек. |
| 1 | 8 | 3 | 5 |
| 2 | 4 | 15 | 12 |
| 3 | 6 | 23 | 15 |
| 4 | 3 | 6 | 6 |
| 5 | 7 | 12 | 3 |
| 6 | 15 | 24 | 12 |
| Суммы | 43 | 83 | 53 |
| Средние | 7,2 | 13,8 | 8,8 |
Решение
Критерий χ2r Фридмана
Назначение критерия
Критерий χ2r применяется для сопоставления показателей, измеренных в трех или более условиях на одной и той же выборке испытуемых.
Критерий позволяет установить, что величины показателей от условия к условию изменяются, но при этом не указывает на направленность изменений.
Гипотезы
H0: Между показателями, полученными (измеренными) в разных условиях, существуют лишь случайные различия.
H1: Между показателями, полученными в разных условиях, существуют неслучайные различия.
Проранжируем значения, полученные по трем тестам каждым испытуемым.
Сумма рангов по каждому испытуемому должна составлять 6. Расчетная общая сумма рангов в критерии определяется по формуле:
![]()
где n - количество испытуемых
с - количество условий измерения (замеров).
В данном случае,
6*3*(3+1)/2 = 36
Показатели времени решения тестов 1, 2, 3 и их ранги (n=6)
| № п/п | Тест 1 | Тест 2 | Тест 3 | |||
| Время решения 1-ого задания теста, сек. | Ранг | Время решения 2-ого задания теста, в сек. | Ранг | Время решения 3-его задания теста в сек. | Ранг | |
| 1 | 8 | 3 | 3 | 1 | 5 | 2 |
| 2 | 4 | 1 | 15 | 3 | 12 | 2 |
| 3 | 6 | 1 | 23 | 3 | 15 | 2 |
| 4 | 3 | 1 | 6 | 3 | 6 | 2 |
| 5 | 7 | 2 | 12 | 3 | 3 | 1 |
| 6 | 15 | 2 | 24 | 3 | 12 | 1 |
| Суммы | 43 | 10 | 83 | 16 | 53 | 10 |
| Средние | 7,2 | 13,8 | 8,8 | |||
Общая сумма рангов составляет: 10+16+10=36, что совпадает с расчетной величиной.
Сформулируем гипотезы.
Н0: Различия во времени, которое испытуемые проводят над решением трех различных тестов, являются случайными.
H1: Различия во времени, которое испытуемые проводят над решением трех различных тестов, не являются случайными.
Теперь нам нужно определить эмпирическое значение χ2r, по формуле:
![]()
где с - количество условий;
n - Количество испытуемых;
T2j - суммы рангов по каждому из условий.
Определим χ2r для данного случая:
χ2r= ((12/6*3*(3+1))*(100 +256 + 100)) – 3*6*(3+1) = 4
Поскольку в данном примере рассматриваются три задачи, то есть 3 условия, с=3. Количество испытуемых n=6. Это позволяет нам воспользоваться специальной таблицей χ2r, а именно табл. VII-A Приложения I. Эмпирическое значение χ2r=4 при с=3, n=6 точно соответствует уровню значимости р=0,184.
Ответ: Н0 отклоняется. Принимается Н1. Различия во времени, которое испытуемые проводят над решением трех различных тестов, неслучайны (р=0,184).
Похожие работы

... , и , то можно предположить о правильном распределении объектов и уже существующих двух классах и верно выполненной классификации объектов подмножества М0. 3.2 Пример решения задачи дискриминантным анализом в системе STATISTICA Исходя из данных по 10 странам (рис. 3.1), которые были выбраны и отнесены к соответствующим группам экспертным методом (по уровню медицинского обслуживания), ...

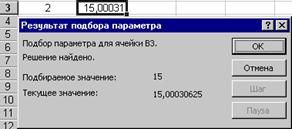
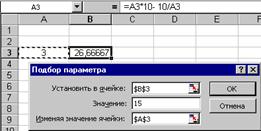
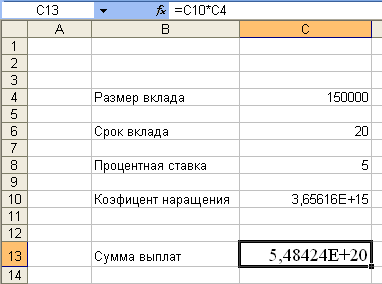
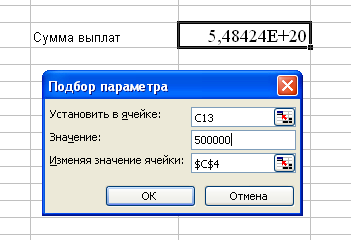
... ) или неположительным (второе решение). Задачу поиска параметра при налагаемых граничных условиях поможет решить специальная надстройка Microsoft Excel Поиск решения. 2 Практическая часть 2.1 Пример решения задач с использованием функции “подбор параметра” Как известно, формулы в Microsoft Excel позволяют определить значение функции по ее аргументам. Однако может возникнуть ситуация, ...
... его увеличением для целей информационного обеспечения исполнительных местных органов [7,8]. 3 ОПЫТ УПРАВЛЕНИЯ И ОБОЩЕНИЕ ДАННЫХ НА ПРИМЕРЕ АЛМАТИНСКОГО ОБЛАСТНОГО УПРАВЛЕНИЯ СТАТИСТИКИ3.1 Алматинское областное управление статистики как субъект сбора и обобщения статистической информации В своей деятельности Алматинское областное управление статистики (АОУС) руководствуется ...
... проверить знания студента из первой части курса, которая излагается в первых четырёх модулях. Во вторых вопросах билета проверяются знания классической предельной проблемы теории вероятностей и математической статистики, которые излагаются в следующих пяти модулях. 1. Вероятностная модель с не более чем счётным числом элементарных исходов. Пример: испытания с равновозможными исходами. 2. ...
0 комментариев