Навигация
Необходимо, чтобы возникновение некоторой ситуации в БД четко и оперативно влияло на ход выполнения прикладной задачи
56602
знака
1
таблица
0
изображений
4. Необходимо, чтобы возникновение некоторой ситуации в БД четко и оперативно влияло на ход выполнения прикладной задачи.
5. Одной из важнейших проблем СУБД является контроль типов данных. В настоящий момент СУБД контролирует синтаксически только стандартно-допустимые типы данных, то есть такие, которые определены в DDL (data definition language) — языке описания данных, который является частью SQL. Однако в реальных предметных областях у нас действуют данные, которые несут в себе еще и семантическую составляющую, например, это координаты объектов или единицы различных метрик, например рабочая неделя в отличие от реальной имеет сразу после пятницы понедельник.
Данную модель поддерживают большинство современных СУБД: Informix, Ingres, Sybase, Oracle, MS SQL Server. Основу данной модели составляет механизм хранимых процедур как средство программирования SQL-сервера, механизм триггеров как механизм отслеживания текущего состояния информационного хранилища и механизм ограничений на пользовательские типы данных, который иногда называется механизмом поддержки доменной структуры.
В этой модели бизнес-логика разделена между клиентом и сервером. На сервере бизнес-логика реализована в виде хранимых процедур — специальных программных модулей, которые хранятся в БД и управляются непосредственно СУБД. Клиентское приложение обращается к серверу с командой запуска хранимой процедуры, а сервер выполняет эту процедуру и регистрирует все изменения в БД, которые в ней предусмотрены. Сервер возвращает клиенту данные, релевантные его запросу, которые требуются клиенту либо для вывода на экран, либо для выполнения части бизнес-логики, которая расположена на клиенте. Трафик обмена информацией между клиентом и сервером резко уменьшается.
Централизованный контроль в модели сервера баз данных выполняется с использованием механизма триггеров. Триггеры также являются частью БД.
Термин «триггер» взят из электроники и семантически очень точно характеризует механизм отслеживания специальных событий, которые связаны с состоянием БД. Триггер в БД является как бы некоторым тумблером, который срабатывает при возникновении определенного события в БД. Ядро СУБД проводит мониторинг всех событий, которые вызывают созданные и описанные триггеры в БД, и при возникновении соответствующего события сервер запускает соответствующий триггер. Каждый триггер представляет собой также некоторую программу, которая выполняется над базой данных. Триггеры могут вызывать хранимые процедуры.
Механизм использования триггеров предполагает, что при срабатывании одного триггера могут возникнуть события, которые вызовут срабатывание других триггеров. Этот мощный инструмент требует тонкого и согласованного применения, чтобы не получился бесконечный цикл срабатывания триггеров.
В данной модели сервер является активным, потому что не только клиент, но и сам сервер, используя механизм триггеров, может быть инициатором обработки данных в БД.
И хранимые процедуры, и триггеры хранятся в словаре БД, они могут быть использованы несколькими клиентами, что. существенно уменьшает дублирование алгоритмов обработки данных в разных клиентских приложениях.
Для написания хранимых процедур и триггеров используется расширение стандартного языка SQL, так называемый встроенный SQL.
Недостатком данной модели является очень большая загрузка сервера. Действительно, сервер обслуживает множество клиентов и выполняет следующие функции:
· осуществляет мониторинг событий, связанных с описанными триггерами;
· обеспечивает автоматическое срабатывание триггеров при возникновении связанных с ними событий;
· обеспечивает исполнение внутренней программы каждого триггера;
· запускает хранимые процедуры по запросам пользователей;
· запускает хранимые процедуры из триггеров;
· возвращает требуемые данные клиенту;
· обеспечивает все функции СУБД: доступ к данным, контроль и поддержку целостности данных в БД, контроль доступа, обеспечение корректной параллельной работы всех пользователей с единой БД.
Если мы переложили на сервер большую часть бизнес-логики приложений, то требования к клиентам в этой модели резко уменьшаются. Иногда такую модель называют моделью с «тонким клиентом», в отличие от предыдущих моделей, где на клиента возлагались гораздо более серьезные задачи. Эти модели называются моделями с «толстым клиентом».
Для разгрузки сервера была предложена трехуровневая модель.
1.6 Модель сервера приложенийЭта модель является расширением двухуровневой модели и в ней вводится дополнительный промежуточный уровень между клиентом и сервером.
В этой модели компоненты приложения делятся между тремя исполнителями:
· Клиент обеспечивает логику представления, включая графический пользовательский интерфейс, локальные редакторы; клиент может запускать ло-кальный код приложения клиента, который может содержать обращения к локальной БД, расположенной на компьютере-клиенте. Клиент исполняет коммуникационные функции front-end части приложения, которые обеспечивают доступ клиенту в локальную или глобальную сеть. Дополнительно реализация взаимодействия между клиентом и сервером может включать в себя управление распределенными транзакциями, что соответствует тем случаям, когда клиент также является клиентом менеджера распределенных транзакций.
· Серверы приложений составляют новый промежуточный уровень архитектуры. Они спроектированы как исполнения общих незагружаемых функций для клиентов. Серверы приложений поддерживают функции клиентов как частей взаимодействующих рабочих групп, поддерживают сетевую доменную операционную среду, хранят и исполняют наиболее общие правила бизнес-логики, поддерживают каталоги с данными, обеспечивают обмен сообщениями и поддержку запросов, особенно в распределенных транзакциях.
· Серверы баз данных в этой модели занимаются исключительно функциями СУБД: обеспечивают функции создания и ведения БД, поддерживают целостность реляционной БД, обеспечивают функции хранилищ данных (warehouse services). Кроме того, на них возлагаются функции создания резервных копий БД и восстановления БД после сбоев, управления выполнением транзакций и поддержки устаревших (унаследованных) приложений (legacy application).
Отметим, что эта модель обладает большей гибкостью, чем двухуровневые модели. Наиболее заметны преимущества модели сервера приложений в тех случаях, когда клиенты выполняют сложные аналитические расчеты над базой данных, которые относятся к области OLAP-прнложений. (On-line analytical processing.) В этой модели большая часть бизнес-логики клиента изолирована от возможностей встроенного SQL, реализованного в конкретной СУБД, и может быть выполнена на стандартных языках программирования, таких как С, C++, SmallTalk, Cobol. Это повышает переносимость системы, ее масштабируемость.
Функции промежуточных серверов могут быть в этой модели распределены в рамках глобальных транзакций путем поддержки ХА-протокола (X/Open transaction interface protocol), который поддерживается большинством поставщиков СУБД.
1.7 Модели серверов баз данныхВ период создания первых СУБД технология «клиент-сервер» только зарождалась. Поэтому изначально в архитектуре систем не было адекватного механизма организации взаимодействия процессов типа «клиент» и процессов типа «сервер». В современных же СУБД он является фактически основополагающим и от эффективности его реализации зависит эффективность работы системы в целом.
Рассмотрим эволюцию типов организации подобных механизмов. В основном этот механизм определяется структурой реализации серверных процессов, и часто он называется архитектурой сервера баз данных.
Первоначально, как мы уже отмечали, существовала модель, когда управление данными (функция сервера) и взаимодействие с пользователем были совмещены в одной программе. Это можно назвать нулевым этапом развития серверов БД.
Затем функции управления данными были выделены в самостоятельную группу — сервер, однако модель взаимодействия пользователя с сервером соответствовала парадигме «один-к-одному», то есть сервер обслуживал запросы только одного пользователя (клиента), и для обслуживания нескольких клиентов нужно было запустить эквивалентное число серверов.
Выделение сервера в отдельную программу было революционным шагом, который позволил, в частности, поместить сервер на одну машину, а программный интерфейс с пользователем — на другую, осуществляя взаимодействие между ними по сети. Однако необходимость запуска большого числа серверов для обслуживания множества пользователей сильно ограничивала возможности такой системы.
Для обслуживания большого числа клиентов на сервере должно быть запущено большое количество одновременно работающих серверных процессов, а это резко повышало требования к ресурсам ЭВМ, на которой запускались все серверные процессы. Кроме того, каждый серверный процесс в этой модели запускался как независимый, поэтому если один клиент сформировал запрос, который был только, что выполнен другим серверным процессом для другого клиента, то запрос, тем не менее, выполнялся повторно. В такой модели весьма сложно обеспечить взаимодействие серверных процессов. Эта модель самая простая, и исторически она появилась первой.
Проблемы, возникающие в модели «один-к-одному», решаются в архитектуре «систем с выделенным сервером», который способен обрабатывать запросы от многих клиентов. Сервер единственный обладает монополией на управление данными и взаимодействует одновременно со многими клиентами. Логически каждый клиент связан с сервером отдельной нитью («thread»), или потоком, по которому пересылаются запросы. Такая архитектура получила название многопотоковой односерверной («multi-threaded»).
Она позволяет значительно уменьшить нагрузку на операционную систему, возникающую при работе большого числа пользователей («trashing»).
Кроме того, возможность взаимодействия с одним сервером многих клиентов позволяет в полной мере использовать разделяемые объекты (начиная с открытых файлов и кончая данными из системных каталогов), что значительно уменьшает потребности в памяти и общее число процессов операционной системы. Например, системой с архитектурой «один-к-одному» будет создано 100 копий процессов СУБД для 100 пользователей, тогда как системе с многопотоковой архитектурой для этого понадобится только один серверный процесс.
Однако такое решение имеет свои недостатки. Так как сервер может выполняться только на одном процессоре, возникает естественное ограничение на применение СУБД для мультипроцессорных платформ. Если компьютер имеет, например, четыре процессора, то СУБД с одним сервером используют только один из них, не загружая оставшиеся три.
В некоторых системах эта проблема решается вводом промежуточного диспетчера. Подобная архитектура называется архитектурой виртуального сервера («virtual server»).
В этой архитектуре клиенты подключаются не к реальному серверу, а к промежуточному звену, называемому диспетчером, который выполняет только функции диспетчеризации запросов к актуальным серверам. В этом случае нет ограничений на использование многопроцессорных платформ. Количество актуальных серверов может быть согласовано с количеством процессоров в системе.
Однако и эта архитектура не лишена недостатков, потому что здесь в систему добавляется новый слой, который размещается между клиентом и сервером, что увеличивает трату ресурсов на поддержку баланса загрузки актуальных серверов («load balancing») и ограничивает возможности управления взаимодействием «клиент—сервер». Во-первых, становится невозможным направить запрос от конкретного клиента конкретному серверу, во-вторых, серверы становятся равноправными — нет возможности устанавливать приоритеты для обслуживания запросов.
Подобная организация взаимодействия клиент-сервер может рассматриваться как аналог банка, где имеется несколько окон кассиров, и специальный банковский служащий — администратор зала (диспетчер) направляет каждого вновь пришедшего посетителя (клиента) к свободному кассиру (актуальному серверу). Система работает нормально, пока все посетители равноправны (имеют равные приоритеты), однако стоит лишь появиться посетителям с высшим приоритетом, которые должны обслуживаться в специальном окне, как возникают проблемы. Учет приоритета клиентов особенно важен в системах оперативной обработки транзакций, однако именно эту возможность не может предоставить архитектура систем с диспетчеризацией.
Современное решение проблемы СУБД для мультипроцессорных платформ заключается в возможности запуска нескольких серверов базы данных, в том числе и на различных процессорах. При этом каждый из серверов должен быть многопотоковым. Если эти два условия выполнены, то есть основания говорить о многопотоковой архитектуре с несколькими серверами.
Она также может быть названа многонитевой мультисерверной архитектурой. Эта архитектура связана с вопросами распараллеливания выполнения одного пользовательского запроса несколькими серверными процессами.
Существует несколько возможностей распараллеливания выполнения запроса. В этом случае пользовательский запрос разбивается на ряд подзапросов, которые могут выполняться параллельно, а результаты их выполнения потом объединяются в общий результат выполнения запроса. Тогда для обеспечения оперативности выполнения запросов их подзапросы могут быть направлены отдельным серверным процессам, а потом полученные результаты объединены в общий результат. В данном случае серверные процессы не являются независимыми процессами, такими, как рассматривались ранее. Эти серверные процессы принято называть нитями (treads), и управление нитями множества запросов пользователей требует дополнительных расходов от СУБД, однако при оперативной обработке информации в хранилищах данных такой подход наиболее перспективен.
1.8 Типы параллелизмаРассматривают несколько путей распараллеливания запросов.
Горизонтальный параллелизм. Этот параллелизм возникает тогда, когда хранимая в БД информация распределяется по нескольким физическим устройствам хранения — нескольким дискам. При этом информация из одного отношения разбивается на части по горизонтали. Этот вид параллелизма иногда называют распараллеливанием или сегментацией данных. И параллельность здесь достигается путем выполнения одинаковых операций, например фильтрации, над разными физическими хранимыми данными. Эти операции могут выполняться параллельно разными процессами, они независимы. Результат: выполнения целого запроса складывается из результатов выполнения отдельных операций.
Время выполнения такого запроса при соответствующем сегментировании данных существенно меньше, чем время выполнения этого же запроса традиционными способами одним процессом.
Вертикальный параллелизм. Этот параллелизм достигается конвейерным выполнением операций, составляющих запрос пользователя. Этот подход требует серьезного усложнения в модели выполнения реляционных операций ядром СУБД. Он предполагает, что ядро СУБД может произвести декомпозицию запроса, базируясь на его функциональных компонентах, и при этом ряд подзапросов может выполняться параллельно, с минимальной связью между отдельными шагами выполнения запроса.
Действительно, если мы рассмотрим, например, последовательность операций реляционной алгебры:
R5=R1 [А, С]
R6=R2 [A.B.D]
R7 = R5[A > 128]
R8 =R5 [A] R6
то операции первую и третью можно объединить и выполнить параллельно с операцией два, а затем выполнить над результатами последнюю четвертую операцию.
Общее время выполнения подобного запроса, конечно, будет существенно меньше, чем при традиционном способе выполнения последовательности из четырех операций.
И третий вид параллелизма является гибридом двух ранее рассмотренных.
Наиболее активно применяются все виды параллелизма в OLAP-приложениях, где эти методы позволяют существенно сократить время выполнения сложных запросов над очень большими объемами данных.
2. Общая характеристика программных средств подготовки табличных документов
Электронная таблица (табличные процессоры) – пакеты программ, предназначенные для обработки табличным образом организованных данных. Пользователь имеет возможность с помощью средств пакета осуществлять разнообразные вычисления, строить графики, управлять форматом ввода-вывода данных, компоновать данные, проводить аналитические исследования и т.п.
В настоящие время наиболее популярными и эффективными пакетами данного класса является: Excel, Improv, Quattro Pro, Lotus 1-2-3.
2.1 Lotus 1-2-3Появившейся в 1982 г. на рынке программирования средств Lotus 1-2-3 был первым табличным процессором, интегрировавшим в своем составе, помимо обычных инструментов, графику и возможность работы с системами управления базами данных. Поскольку Lotus был разработан для компьютеров типа IBM, он сделал для этой фирмы то же, что VisiCalc в свое время сделал для фирмы Apple. Дальше на рынке вышли новые электронные таблицы, такие как VP Planner компании Paperback Software и Quattro Pro компании Borland International, которые предложили пользователю практически тот же набор инструментария, но по значительно более низким ценам.
2.2 QUATTRO PROПроцессор QUATTRO PRO почти всех версий обладает такими достоинствами, как:
- чрезвычайно удобный пользовательский интерфейс, дающий возможность представления данных в самой разнообразной и нестандартной форме и обеспечивающий широкие возможности по обработке данных;
- многооконный режим работы, позволяющий организовать на экране удобную рабочую среду и создавать системы связанных электронных таблиц (ЭТ)
- доступ к любым, неограниченным по размерам внешним базам данных, созданным на основе наиболее популярных систем управления базой данных (СУБД);
- высокое качество печати выходных документов; возможность построения разнообразных графиков, диаграмм, рисунков, а также возможность создания слайд-фильмов для презентации готовых результатов и приложений;
- легкость создания программ автоматической обработки информации в таблицах и удобные средства отладки и редактирования созданных программ.
Основное внимание в данной работе будет уделено следующим вопросам:
- оформление для вывода на принтер выходных документов с высоким качеством печати;
- графическое представление полученных результатов и вывод их на принтер в составе выходных документов;
- способы графического анализа результатов.
2.3 ExcelОдним из наиболее распространенных средств работы с документами, имеющими табличную структуру, является Microsoft Excel.
Эта программа предназначена для работы с таблицами данных, преимущественно числовых. При формировании таблицы выполняют ввод, редактирование и форматирование текстовых и числовых данных, а так же формул. Наличие средств автоматизации облегчает эти операции. Созданная таблица может быть выведена на печать.
Документ Excel называется рабочей книгой. Рабочая книга представляет собой набор рабочих листов, каждый из которых имеет табличную структуру и может содержать одну или несколько таблиц. В окне документа в программе Excel отображается только текущий рабочий лист, с которым и ведется работа. Каждый рабочий лист имеет названия, которое отображается на ярлычке листа, отображаемом в его нижней части. С помощью ярлычков можно переключиться к другим рабочим листам, входящим в ту же самую рабочую книгу. Чтобы переименовать рабочий лист, надо дважды щелкнуть на его ярлычке.
Рабочий лист состоит из строк и столбцов. Столбцы озаглавлены прописными латинскими буквами и, далее, двухбуквенными комбинациями. Всего рабочий лист может содержать до 256 столбцов, пронумерованных от A до ΙV. Строки последовательно нумеруются цифрами, от 1 до 65 536 (максимально допустимый номер строки).
На пересечении столбцов и строк образуется ячейки таблицы. Они являются минимальными элементами для хранения данных. Обозначение отдельной ячейки сочетает в себе номера столбца и строки (в этом порядке), на пересечении которых она расположена, например: A1 или DE234. Обозначение ячейки (ее номер) выполняет функции ее адреса. Адреса ячеек используются при записи формул, определяющих взаимосвязь между значениями, расположенными в разных ячейках.
Одна из ячеек всегда является активной и выделяется рамкой активной ячейки. Эта рамка в программе играет роль курсора. Операции ввода и редактирования всегда производятся в активной ячейке. Переместить рамку активной ячейки можно с помощью курсорных клавиш или указателя мыши.
На данные, расположенные в соседних ячейках, можно ссылаться в формулах как единое целое. Такую группу ячеек называют диапазоном.
Отдельная ячейка может содержать данные, относящиеся к одному из трех типов: текста, число или формула, - а так же оставаться пустой. Программа при сохранение рабочей книги записывает в файл только прямоугольную область рабочих листов, примыкающих к левому верхнему углу (ячейка A1) и содержать все заполненные ячейки.
Тип данных, размещаемых в ячейке, определяется автоматически при вводе. Если эти данные можно интерпретировать как число, программа так и делает. В противном случае данные рассматриваются как текст. Ввод формулы всегда начинается с символа знака равенства.
Содержание электронной таблицы: формулы, ссылки и ячейки, абсолютные и относительные ссылки, автоматизация ввода (автозавершение, автозаполнение), надстройки, построение диаграмм и графиков, и многое другое.
3. Задание Word
Создание многоуровневого списка и работа с ним.
Порядок работы:
1.Создание таблицы – Таблица→Вставить→Таблица→Число столбцов – 4; Число строк – 2;
В первой и во второй строке таблицы введены заголовки: «Классификация прикладного программного обеспечения, Начальный вид списка, Измененный вид списка».
2.Самый быстрый способ создания многоуровневого списка – ввести текст, а затем преобразовать его в многоуровневый список с помощью команды меню Формат→Список→Многоуровневый.
3. Чтобы изменить вид списка, копируется начальный вид списка в соответствующую ячейку таблицы справа, и выполняются действия:
а) выбираем команду меню Формат→Список;
б) в диалоговом окне Список вкладку соответствующего типа списка - Многоуровневый;
в) щелчком на кнопке Изменить открываем диалоговое окно Изменение Многоуровневого списка и в нем устанавливаем необходимые параметры для изменяемого списка.
4. При изменение маркера для маркированного списка, в окне изменение щелкаем Знак, и в раскрывающимся списке Шрифт выбираем новый вид маркера.
5. Перед тем, как внести изменения в многоуровневый список, устанавливаем курсор перед текстом списка в правой ячейке и выполняем команду Вставка→Разрыв→Новый раздел→на текущей странице, а затем приступаем к преобразованию списка.
6. При изменение оформления уровня Многоуровневого списка выбираем номер этого уровня в раскрывающимся списке Уровень диалогового окна Изменение многоуровневого списка и устанавливаем требуемые параметры (раскрывающиеся списки: нумерация:, начать с :, предыдущий уровень:, положение номера на:, положение текста – отступ).
Похожие работы
... платежей в бюджет и внебюджетные фонды, проведению комплексного оперативного анализа материалов по налогообложению, обеспечению органов управления и соответствующих уровней налоговых служб достоверной информацией. Автоматизированная информационная технология (АИТ) в налоговой системе – это совокупность методов, информационных процессов и программно-технических средств, объединенных в ...

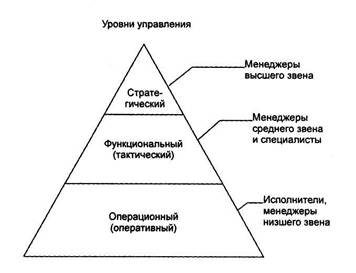
... управления хозяйственной деятельностью в постоянно действующий фактор повышения эффективности производства за счет актуализации всего информационного фонда предприятия. Методика финансового анализа, ориентированная на использование информационных технологий, должна удовлетворять требованиям системности, комплексности, оперативности, точности, прогрессивности, динамичности. Только на основе ...
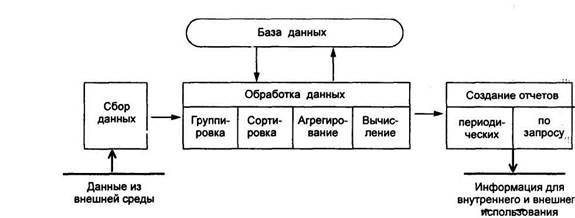
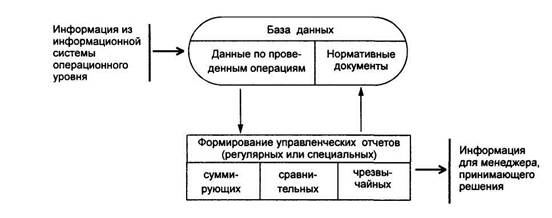
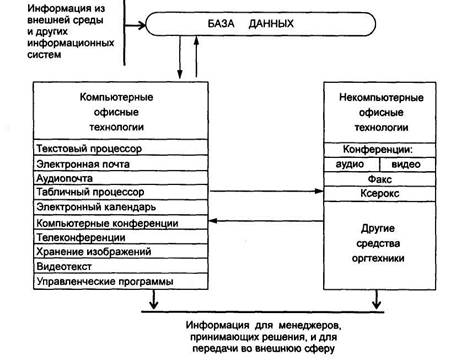
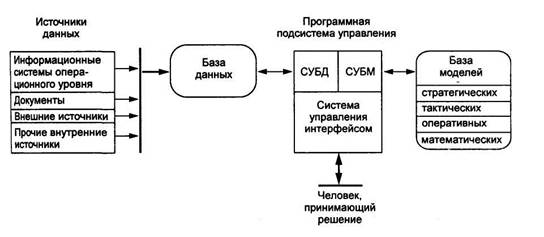
... методическое обеспечение - это совокупность средств и методов организации производства и управления им в условиях внедрения информационной системы. Оно включает в себя методики проведения работ, требования к оформлению документов, должностные инструкции и т.д. 2. Автоматизированные информационные технологии в офисе Любой офис имеет следующую структуру представленную: секретарем (осуществляет ...
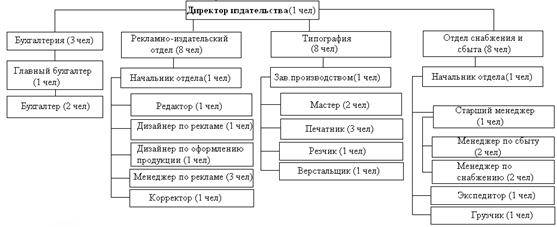
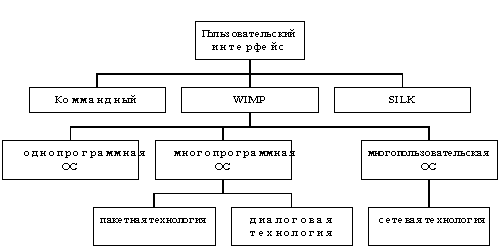
... группой, так как это повышает эффективность рабочих групп и способствует лучшему информационному обмену. Заключение В ходе данной курсовой работы были изучены информационные технологии обеспечения управленческой деятельности, на примере типографии «Мистер Принт» рассмотрены основные наиболее значимые достижения информационной технологии в сфере управления организацией. В первой главе были ...
0 комментариев