Навигация
Кластеризация групп входящих пакетов с помощью нейронных сетей конкурирующего типа
63100
знаков
1
таблица
8
изображений
Содержание
Введение
1. Описание способа решения задачи
2. Теоретическая часть
2.1 Что такое Data mining и KDD?
2.2 Описание рассматриваемых хакерских атак
2.2.1 Подмена одного из субъектов TCP-соединения в сети Internet
2.2.2 Нарушение работоспособности хоста в сети Internet при использовании направленного “шторма” ложных TCP-запросов на создание соединения либо при переполнении очереди запросов
2.2.3 Другие виды атак
2.3 Сеть с самоорганизацией на основе конкуренции
2.3.1 Состав сети Кохонена
2.3.2 Меры расстояния между векторами
2.3.3 Способы нормализации входных данных
2.3.4 Алгоритм обучения карты Кохонена
2.3.5 Механизм утомления
2.3.6 Алгоритм нейронного газа
3. Формализация задачи
4. Эксперимент
5. Результаты работы модели
Заключение
Список используемой литературы
Листинг программ
Введение
Наряду с развитием средств электронной связи происходило развитие средств нарушения работоспособности информационных каналов. В настоящее время усиливается оснащение вычислительной техники механизмами защиты от несанкционированного доступа, вирусов, спама, хакерских атак и т.д. Это так называемые брандмауэры, файрволлы, фильтры пакетов. Операционные системы также усиливают свой боевой арсенал. Несмотря на это ежедневно продолжается нарушаться работа различных компьютеров: от головных серверов до рабочих станций от действия вредоносных программ. В данной работе автор хотел расклассифицировать группы входящих пакетов, поступающих на одну из рабочих станций в ЛВС, методами интеллектуального анализа данных. Впоследствии, зная принадлежность той или иной группы к классу хакерских атак, по заданному количеству поступивших пакетов можно определить грядущую угрозу рабочей станции.
1. Описание способа решения задачи
Во-первых, следует выбрать параметры, позволяющие оценить текущее состояние входящего трафика. Из-за того, что по одному пакету нельзя определить начало атаки, то параметры должны быть интегральными по некоторой группе пакетов. Это можно сделать путём оценивания n-подряд идущих пакетов, причём чем больше n, тем более точным должен быть результат классификации.
Во вторых, необходимо создать интеллектуальную базу данных для построения интеллектуальной модели системы, это можно сделать путём проведения серии экспериментов, чередуя посылку пакетов, вызванных злонамеренными действиями, и обычных пакетов между компьютерами.
Третьим шагом, служит создание интеллектуальной системы оценивания входящих пакетов, причём обучающей базой для построения модели служит база созданная на шаге 2.
Наконец, после обучения интеллектуальной системы требуется объяснить результаты моделирования и проверить работу модели в реальных условиях.
2. Теоретическая часть
2.1. Что такое Data mining и KDD?
“Большинство исследователей и экспертов накапливают за время своей деятельности большие, а организации – просто гигантские объемы данных. Но единственное что люди могут, а в большинстве случаев и хотят получить от них – это быстрое извлечение требуемой информации. Фактически базы данных выполняют функцию памяти, или сложной записной книжки; доступ пользователя к хранилищу данных обеспечивает только извлечение небольшой части из хранимой информации в ответ на четко задаваемые вопросы. Когда мы имеем огромный поток информации, огромные залежи накопленной информации, встает задача максимально целесообразно использовать эту информацию, чтобы извлечь спрятанное в данных знание с целью оптимизировать управление какими-либо процессами, улучшить деятельность организации, более точно узнать свойства и законы функционирования, присущие очень сложным объектам, таким, скажем, как медицинские организации, биологические системы или организм человека.
Можно было бы действовать старым проверенным способом, то есть посадить огромную армию аналитиков, статистиков, которые бы с этими данными разбирались, используя традиционные средства анализа данных. Но, очевидно, что уже сейчас эта задача не может быть решена только силами человека просто в силу гигантского объема данных. Можно сказать, что экстенсивный путь использования интеллекта человека в принципе не позволяет решить эту задачу, и для ее решения требуется качественно иной подход. С другой стороны такое решение просто дорого и экономически неэффективно. Кроме того, не всегда получаемые аналитиками результаты являются объективными, поскольку обычно люди руководствуются, явно или неявно, теми или иными соображениями, некоторыми априорными представлениями об изучаемом предмете, что не может не отразиться на объективности получаемых ими результатов.
А можно ли узнать из данных о том, какое решение наиболее предпочтительно для конкретной задачи, как организовать ресурсы бизнеса наиболее эффективным образом или как минимизировать издержки и при этом переложить значительную часть аналитической работы на плечи Машины? Хотелось бы автоматизировать процесс анализа и сделать его более объективным, а именно: получить некоторую технологию, которая бы автоматически извлекала из данных новые нетривиальные знания в форме моделей, зависимостей, законов и т.д., гарантируя при этом их статистическую значимость. Новейшая технология,
Knowledge discovery in databases (дословно, «обнаружение знаний в базах данных») – аналитический процесс исследования человеком большого объема информации с привлечением средств автоматизированного исследования данных с целью обнаружения скрытых в данных структур или зависимостей. Предполагается полное или частичное отсутствие априорных представлений о характере скрытых структур и зависимостей. KDD включает предварительное осмысление и неполную формулировку задачи (в терминах целевых переменных), преобразование данных к доступному для автоматизированного анализа формату и их предварительную обработку, обнаружение средствами автоматического исследования данных (data mining) скрытых структур или зависимостей, апробация обнаруженных моделей на новых, не использовавшихся для построения моделей данных и интерпретация человеком обнаруженных моделей.
Data mining (дословно, «разработка данных») – исследование и обнаружение “машиной” (алгоритмами, средствами искусственного интеллекта) в сырых данных скрытых структур или зависимостей, которые
– ранее не были известны,
– нетривиальны,
– практически полезны,
– доступны для интерпретации человеком.
Направленная на решение этих проблем – это технология knowledge discovery in databases (KDD). KDD – это синтетическая область, впитавшая в себя последние достижения искусственного интеллекта, численных математических методов, статистики и эвристических подходов. Цель технологии – нахождение моделей и отношений, скрытых в базе данных, таких моделей, которые не могут быть найдены обычными методами. Следует отметить, что на плечи Машины перекладываются не только “рутинные” операции (скажем, проверка статистической значимости гипотезы), но и операции, которые ранее было отнюдь не принято называть рутинными (выработка новой гипотезы). KDD позволяет увидеть такие взаимоотношения между данными, которые прежде даже не приходили в голову исследователю, а применение которых может способствовать увеличению эффективности работы и исследований, а в нашем конкретном случае позволит выявлять пакеты, являющиеся прямым следствием посягательством на вычислительные ресурсы.
Похожие работы
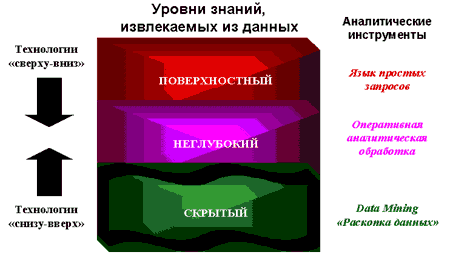

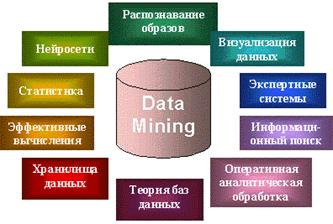

... ? Сфера применения Data Mining ничем не ограничена - она везде, где имеются какие-либо данные. Но в первую очередь методы Data Mining сегодня, мягко говоря, заинтриговали коммерческие предприятия, развертывающие проекты на основе информационных хранилищ данных (Data Warehousing). Опыт многих таких предприятий показывает, что отдача от использования Data Mining может достигать 1000%. Например, ...
0 комментариев