Навигация
Меры расстояния между векторами
63100
знаков
1
таблица
8
изображений
2.3.2 Меры расстояния между векторами.
Процесс самоорганизации предполагает определение победителя каждого этапа. В этой ситуации важной проблемой становится выбор метрики, в которой будет измеряться расстояние между векторами x и w.
Чаще всего в качестве меры расстояния используются:
эвклидова мера 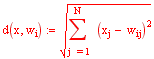
скалярное произведение ![]()
мера относительно нормы L1 
мера относительно нормы L∞ ![]()
Для успешного обучения и функционирования нейронной сети Кохонена желательно, чтобы диапазоны изменения наблюдаемых величин не отличались друг от друга или отличались незначительно. Это требуется для того чтобы предотвратить чрезмерный вклад компонента исходных данных с широким диапазоном в модификацию весов.
Наиболее распространенным способы нормализации является масштабирование исходных данных в некоторый диапазон:
![]() ,
,
![]() ,
,
Формула (4.1) осуществляет масштабирование в диапазон [0;1]. Формула (4.2) – в диапазон [-1;1].
Расчетные значения параметра, полученные в результате функционирования нейросети, масштабируются в диапазон [min(p); max(p)] при помощи обратных формул.
2.3.4 Механизм утомления
При инициализации весов сети случайным образом часть нейронов может оказаться в области пространства, в которой отсутствуют данные или их количество ничтожно мало. Эти нейроны имеют мало шансов на победу и адаптацию своих весов, поэтому они остаются мёртвыми. Таким образом, входные данные будут интерпретироваться меньшим количеством нейронов (мёртвые нейроны не принимают участие в анализе), а погрешность интерпретации данных, иначе называемая погрешностью квантования, увеличится. Поэтому важной проблемой становиться активация всех нейронв сети.
Такую активацию можно осуществить, если в алгоритме обучения предусмотреть учёт количества побед каждого нейрона, а процесс обучения организовать так, чтобы дать шанс победить и менее активным нейронам. Такой способ учёта активности нейронов будет называться в дальнейшем механизмом утомления.
Существуют различные механизмы учёта активности нейронов в процессе обучения. Часто используется метод подсчёта потенциала pi каждого нейрона, значение которого модифицируется всякий раз после представления очередной реализации входного вектора x в соответствии со следующей формулой (в ней предполагается, что победителем стал w-й нейрон):

Значение коэффициента pmin определяет минимальный потенциал, разрешающий участие в конкурентной борьбе. Если фактическое значение потенциала pi падает ниже pmin, i-й нейрон “отдыхает”, а победитель ищется среди нейоронов, для которых выполняется отношение
![]()
для 1<=i<=N и pi>=pmin. Максимальное значение потенциала ограничивается на уровне, равном 1. Выбор конкретного pmin позволяет установить порог готовности нейрона к конкурентной борьбе. При pmin=0 утомляемость нейронов не возникает, и каждый из них сразу после победы будет готов к продолжению соперничества. При Pmin=1 возникает другая крайность, вследствие которой нейроны побеждают по очереди, так как в каждый момент времени только один из них оказывается готовым к соперничеству. На практике хорошие результаты достигаются, когда pmin=0.75.
2.3.5 Алгоритм обучения карты КохоненаОсновным отличием данной технологии от наиболее распространенного обучения методом обратного распространения, является то, что обучение проходит без учителя, то есть результат обучения зависит только от структуры входных данных.
Алгоритм функционирования самообучающихся карт Алгоритм SOM подразумевает использование упорядоченной структуры нейронов. Обычно используются одно и двумерные сетки. При этом каждый нейрон представляет собой n-мерный вектор-столбец своих весовых коэффициентов:
![]() ,
,
где n определяется размерностью исходного пространства (размерностью входных векторов). Применение одно и двумерных сеток связано с тем, что возникают проблемы при отображении пространственных структур большей размерности.
Обычно нейроны располагаются в узлах двумерной сетки с прямоугольными или шестиугольными ячейками. При этом, нейроны также взаимодействуют друг с другом. Величина этого взаимодействия определяется расстоянием между нейронами на карте. На рисунке даны примеры расстояний для шестиугольной и четырехугольной сеток.
При этом легко заметить, что для шестиугольной сетки расстояние между нейронами больше совпадает с евклидовым расстоянием, чем для четырехугольной сетки. Количество нейронов в сетке определяет степень детализации результата работы алгоритма, и, в конечном счете, от этого зависит точность обобщающей способности карты.

Рис.4 – Расстояние между нейронами на шестиугольной (а) и четырехугольной (б) сетках
Перед началом обучения карты необходимо проинициализировать весовые коэффициенты нейронов. Удачно выбранный способ инициализации может существенно ускорить обучение, и привести к получению более качественных результатов. Существуют два основных способа инициирования начальных весов:
· Инициализация случайными значениями - всем весам даются малые случайные величины.
· Инициализация примерами – всем весам в качестве начальных значений задаются значения случайно выбранных примеров из обучающей выборки.
Обучение состоит из последовательности коррекций векторов, представляющих собой нейроны. На каждом шаге обучения из исходного набора данным случайно выбирается один из векторов (обозначим его х), а затем производится поиск наиболее схожего с ним вектора коэффициентов нейронов. При этом выбирается нейрон-победитель, который наиболее схожий с вектором входов. Под «схожестью» в данной задаче понимается некоторая метрика, заданная в пространстве входных векторов. В качестве метрики обычно используется расстояние в евклидовом пространстве. Узел нейрона-победителя для входного вектора после обучения нейросети называется «наиболее подходящим узлом» (Best Matching Unit – BMU).
Таким образом, если обозначить нейрон-победитель номером c, то:
![]() ,
,
После того, как найден нейрон-победитель, производится корректировка весов нейросети. При этом вектор, описывающий нейрон-победитель и вектора, описывающие его соседей в сетке, перемещаются в направлении входного вектора. Это проиллюстрировано на рисунке для двумерного вектора.
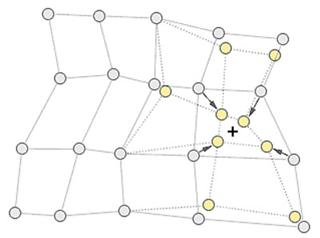
Рис.5 – Подстройка весов нейрона победителя и его соседей
При этом для модификации весовых коэффициентов используется формула:
![]() ,
,
где t обозначает номер эпохи (номер итерации обучения).
Функция h(t) называется функцией соседства нейронов. Эта функция представляет собой невозрастающую функцию от времени и расстояния между нейроном-победителем и соседними нейронами в сетке. Эта функция разбивается на две части: собственно функцию расстояния и функции скорости обучения от времени:
![]() ,
,
где r – координаты нейрона в сетке.
Обычно применяется одна из двух функций от расстояния: простая константа:
 ,
,
или Гауссова функция:
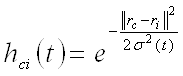 ,
,
При этом ![]() является убывающей функцией от времени. Эту величину называют радиусом обучения. Он выбирается достаточно большим на начальном этапе обучения и постепенно уменьшается так, что в конечном итоге обучается один нейрон-победитель. Наиболее часто используется функция, линейно убывающая от времени.
является убывающей функцией от времени. Эту величину называют радиусом обучения. Он выбирается достаточно большим на начальном этапе обучения и постепенно уменьшается так, что в конечном итоге обучается один нейрон-победитель. Наиболее часто используется функция, линейно убывающая от времени.
Функция скорости обучения ![]() также представляет собой функцию, убывающую от времени. Наиболее часто используются два варианта этой функции: линейная и обратно пропорциональная времени вида:
также представляет собой функцию, убывающую от времени. Наиболее часто используются два варианта этой функции: линейная и обратно пропорциональная времени вида:
![]() ,
,
где A и B это константы. Применение этой функции приводит к тому, что все вектора из обучающей выборки вносят примерно равный вклад в результат обучения.
Обучение состоит из двух основных фаз: на первоначальном этапе выбирается достаточно большое значение скорости обучения и радиуса обучение, что позволяет расположить вектора нейронов в соответствии с распределением примеров в выборке, а затем производится точная подстройка весов, когда значения параметров скорости обучения много меньше начальных.
Похожие работы


... ? Сфера применения Data Mining ничем не ограничена - она везде, где имеются какие-либо данные. Но в первую очередь методы Data Mining сегодня, мягко говоря, заинтриговали коммерческие предприятия, развертывающие проекты на основе информационных хранилищ данных (Data Warehousing). Опыт многих таких предприятий показывает, что отдача от использования Data Mining может достигать 1000%. Например, ...
0 комментариев