Постановка задачи и определение цели работы
Анализ вариантов реализации системы
Инфологическая модель базы данных
Выбор серверного ЯП и клиентского фреймворка
Описание интерфейсов системы
Интерфейс администратора
Работа с пользователями системы
Оценка затрат на специальное оборудование
Оценка прочих расходов
Анализ и выявление потенциально опасных и вредных факторов
Меры безопасности, для предотвращения возможности поражения электрическим током
Навигация
Инфологическая модель базы данных
Разработка веб-приложения для информационного обеспечения учебного процесса (видеокасты)
70706
знаков
4
таблицы
32
изображения
4.4 Инфологическая модель базы данных
На рисунке 13 представлена инфологическая модель базы данных системы. Подробное описание проиллюстрированной модели представлено в приложении A. Инфологическая модель ядра системы представлена на рисунке 12.
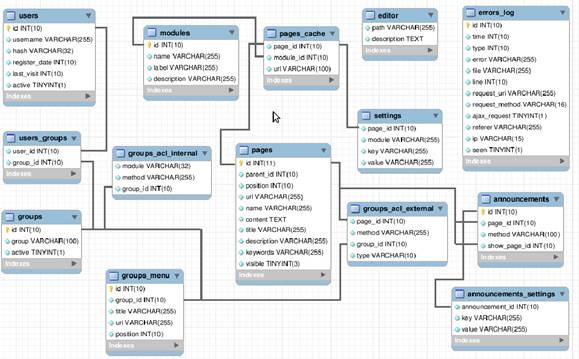
Рисунок 12 – Инфологическая модель ядра системы
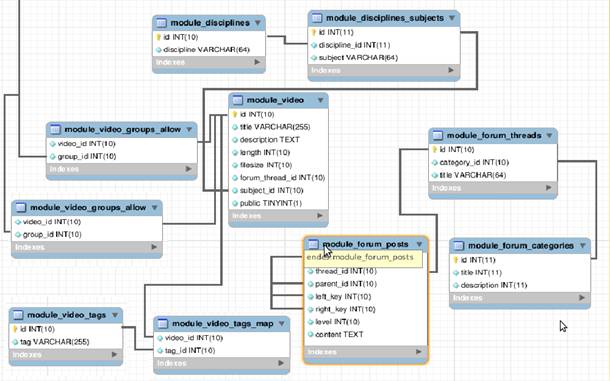 Рисунок 13 – Инфологическая модель системы
Рисунок 13 – Инфологическая модель системы
4.5 Выбор технологии реализации
После рассмотрения возможных аналогов данного проекта было выявлено, что для отдачи мультимедиа контента (в том числе видео- и аудиоконтента) используются веб-сервера nginx и lighttpd. Серверные скрипты в основном используют возможности php, python и bash. В качестве сервера баз данных используются в большинстве случаев MySQL и PostgreSQL. На рисунке 14 представлена стандартная схема работы большинства динамических сайтов в сети Интернет.
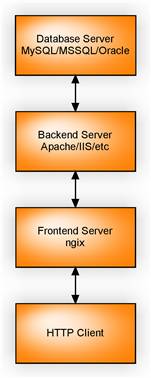
Рисунок 14 – Стандартная схема работы динамических сайтов, использующих БД
Как видно из рисунка, запрос пользователя поступает на фронтовый веб-сервер, который слушает 80 порт (стандартный HTTP-порт). Далее фронтовый веб-сервер в зависимости от запроса или проксирует его далее на бэкенд (более тяжеловесный сервер, умеющий обрабатывать динамические запросы, например Apache), или же отдает контент, запрошенный пользователем. В случае проксирования запроса на бэкенд мы можем взаимодействовать с БД посредством какого-либо языка программирования [14].
4.5.1 Выбор веб-сервера
Данная схема работы сайтов является на данный момент стандартной в сети Интернет. В качестве фронтовых веб-серверов в большинстве случае используются nginx и lighttpd. В качестве бэкенда самым известным веб-сервером является Apache. Также возможен вариант работы нескольких веб-серверов Apache (или вобще – нескольких физических серверов) вместе с балансировщиком нагрузки [12]. Вообще, главная причина использование схемы фронтенд-бэкенд – эффективное использование ресурсов. Если клиентов пускать напрямую к бэкенду (например apache+mod_perl) без фронтенда, то серверов под бэкенды потребуется в несколько раз больше [12].
В nginx рабочие процессы обслуживают одновременно множество соединений, мультиплексируя их вызовами операционной системы select (Windows), epoll (Linux), kqueue (FreeBSD) и eventport (Solaris). Рабочие процессы выполняют цикл обработки событий от дескрипторов. Полученные от клиента данные разбираются с помощью конечного автомата. Разобранный запрос последовательно обрабатывается цепочкой модулей, задаваемой конфигурацией. Ответ клиенту формируется в буферах, которые хранят данные либо в памяти, либо указывают на отрезок файла. Буферы объединяются в цепочки, определяющие последовательность, в которой данные будут переданы клиенту. Если операционная система поддерживает эффективные операции ввода-вывода, такие как writev и sendfile, то nginx применяет их по возможности [10].
Для эффективного управления памятью nginx использует пулы. Пул — это последовательность предварительно выделенных блоков динамической памяти. Длина блока варируется от 1 до 16 килобайт. Изначально под пул выделяется только один блок. Блок разделяется на занятую область и незанятую. Выделение мелких объектов выполняется путем продвижения указателя на незанятую область с учетом выравнивания. Если незанятой области во всех блоках нехватает для выделения нового объекта, то выделяется новый блок. Если размер выделяемого объекта превышает значение константы NGX_MAX_ALLOC_FROM_POOL, либо длину блока, то он полностью выделяется из кучи. Таким образом, мелкие объекты выделяются очень быстро и имеют накладные расходы только на выравнивание [15].
4.5.2 Выбор СУБД
Самыми известными СУБД при работе с сайтами являются MySQL, PostgreSQL. Также используются MSSQL, Oracle, Firebird и некоторые другие. Большая популярность MySQL и PostgreSQL по сравнению с проприетарными СУБД обусловлена большим сообществом разработчиков, открытостью продуктов и огромными возможностями по настройке быстродействия баз данных.
Если сравнивать конкретно MySQL и PostgreSQL, то можно выявить следующие преимущества MySQL:
- соответствие стандартам SQL – начиная с пятой версии MySQL большое внимание разработчиками удалялось соответствию стандартам SQL. В MySQL запросы максимально соответствют стандартам SQL'99;
- большее количество платформ – MySQL изначально разрабатывался как кроссплатформенная СУБД. В Windows MySQL работает как служба, в *nix – как демон. PostgreSQL изначально разрабатывался как СУБД, работающая в *nix-системах;
- скорость работы на простых запросах – огромное преимущество MySQL заключается именно в скорости работы простых запросов. Благодаря тому, что в MySQL используются различные типы таблицам, а типом таблиц по умолчанию является MyISAM, реализуется огромная скорость при работе с простыми запросами. В то же время, тип тпблиц InnoDB позволяет осуществлять транзакции, следить за целостностью данных, но в данной случае уже не будет выигрыша в скорости запросов;
- стабильность работы – исторически сложилось, что MySQL довольно стабильная СУБД. PostgreSQL – более молодая, в то время как из-за более раннего начала разработки у MySQL сложилось большее сообщество разработчиков;
- безопасность, связанная со стабильностью – сообщество разработчиков MySQL за все эти годы нашли и устранили огромное количество уязвимостей, что позволяет считать MySQL одной из самых защищенных СУБД;
- работа с большими объектами – в MySQL реализована поддержка бинарных объектов практически неограниченных размеров в полях типа BLOB, что отсутствует у PostgreSQL;
- возможности для легкого изменения таблиц – в MySQL реализованы возможности легкого изменения таблиц, что отсутствует в PostgreSQL.
В то же время у PostgreSQL есть свои преимущества:
- стабильность – несмотря на то, что сообщество разработчиков MySQL больше, сама PostgreSQL изначально проектировалась как более стабильная СУБД. Плюс в этом свою роль сыграло то, что MySQL долго избавлялся от наследия своих третьей и четвертой сравнительно нестабильных версий;
- скорость работы (процедуры) – PostgreSQL выигрывает в производительности на сложных запросах, логически построенных процедурах;
- целостность данных – PostgreSQL позволяет оперировать с данными, не перекладывая логику на ЯП. При разработке кода программисту не придется думать о целостности данных в БД;
- специальные вещи (триггеры, процедуры, функции...) - многие вещи, которые реализуются в MySQL только в последних релизах.
Как можно увидеть, главным преимуществом MySQL являются скорость работы на простых запросах (логика БД довольно простая и не требует процедур для реализации). Это преимуществом было выбрано в качестве основного при выборе СУБД.
В то же время было необходимо выбрать тип таблиц MySQL. Исторически сложилось, что типом таблиц по умолчанию в MySQL является MyISAM. Вторым по популярности типом таблиц является InnoDB. В настоящее время разрабатывается альтернатива InnoDB – Falcon, однако использование его на production-серверах не рекомендуется. В то же время существуют и другие типы таблиц, например:
- HEAP (все хранится в памяти)
- MERGE (совокупность таблиц MyISAM)
- Maria (обновленный MyISAM с возможностями транзакций)
При анализе преимущества и недостатков стандартного типа таблиц MySQL были выявлены следующие его преимущества:
- полнотекстовый поиск
- преимущество в скорости на простых выборках
- работа “из коробки”
Анализ преимуществ InnoDB выявил следующие пункты:
- поддержка транзакций
- целостность/внешние ключи
- преимущество в скорости на сложных выборках
- более полное соответствие стандартам
Как можно увидеть, InnoDB позволяет переложить логику на СУБД, в то время как стандартный тип таблиц позволяет использовать преимущество простых выборок (а их будет гораздо больше чем сложных). Также в MyISAM реализована возможность полнотекстового поиска (хотя она довольно требовательна к наличию индексов). И что немаловажно – возможность работы с типом “из коробки” [13]. Трудно сказать, преимущество это или недостаток, однако при развертывании каких-либо систем преимущество отдается проверенным продуктам. Настройка движка InnoDB до сих пор является довольно объемной темой, проработка которой не относится к написанию дипломной работы. Поэтому было отдано предпочтение типу таблиц MyISAM [11].
0 комментариев