Навигация
1.3 Диаграмма запроса
Можно представить два стиля диаграмм запросов — полные и упрощенные. Полные диаграммы включают все данные, которые потенциально могут относиться к проблеме настройки. Упрощенные диаграммы более качественные и не содержат данных, которые обычно не требуются [Дэн Тоу].
Ниже показан простой запрос с одним соединением, иллюстрирующий все значимые элементы диаграммы запроса.
SELECT D.DepartmentJIame. E.LastJIame. E.Firstjlame FROM Employees E. Departments 0 WHERE E.Department_Id=D.Departmentjd
AND E.Exempt_Flag='Y'
AND D.US_Based_Flag='Y';
В математических терминах то, что показано на рис. 1.Х, является направленным графом. Это набор узлов и связей, причем связей часто обозначаются стрелками, указывающие направление. Узлы на этой диаграмме представлены буквами Е и D. Рядом с узлами и обоими концами каждой связи есть числа, которые указывают дополнительные свойства узлов и связей. В терминах запроса можно интерпретировать эти элементы диаграммы следующим образом.
Узлы
Узлы представляют таблицы или псевдонимы таблиц в разделе FROM — в примере это псевдонимы Е и D. Для удобства можно сокращать названия таблиц или псевдонимов, если это не вызывает двусмысленности или недопонимания.
Связи
Связи представляют соединения между таблицами, а направленная связь обозначает, что соединение гарантированно получит уникальные значения в той таблице, на которую указывает связь. В данном случае DepartmentId — первичный (уникальный) ключ в таблице Departments, поэтому у связи есть стрелка на конце, указывающем на узел D. Так как Departments не уникален в таблице Employees, на другом конце связи стрелки нет. Хотя вы можете догадаться, что DepartmentId — это первичный ключ для Departments, SQL не объявляет явно, какая сторона соединения является первичным ключом, а какая — внешним. Необходимо проверить индексы или объявленные ключи, чтобы удостовериться, что Departments гарантированно уникален в таблице Departments.
Подчеркнутые числа
Подчеркнутые числа рядом с узлами обозначают долю строк каждой таблицы, удовлетворяющих условиям фильтрации для этой таблицы. Здесь под условиями понимаются не условия соединения, а условия, относящиеся только к конкретной таблице на диаграмме SQL. На рис. 1.X 10 % строк таблицы Employees удовлетворяют условию Exempt_Flag='Y', и 50 % строк таблицы Departments удовлетворяют условию US_Based_Flag='Y'. Эти доли называются коэффициентами фильтрации.
Часто для одной или нескольких таблиц вообще не указаны условия фильтрации. В этом случае для коэффициента фильтрации (К) используется значение 1,0, так как 100 % строк удовлетворяют (несуществующим) условиям фильтрации для этой таблицы. В подобных случаях обычно вообще не указываются коэффициенты фильтрации на диаграмме. Отсутствие этого числа обозначает К = 1,0 для данной таблицы. Коэффициент фильтрации не может быть больше 1,0. Зачастую можно приблизительно угадать значение коэффициентов фильтрации, зная, что представляют таблицы и столбцы. Если доступны распределения реальных данных, можно найти точные значения коэффициентов фильтрации, просто получив и проанализировав эти данные. Необходимо рассматривать каждую фильтрованную таблицу с операторами фильтрации, относящимися только к этой таблице, как однотабличный запрос, и искать селективность условий фильтров.
Во время фазы разработки приложения не всегда можно точно знать, какие коэффициентов фильтрации следует ожидать во время работы приложения на реальных объемах данных. В этом случае нужно производить оценку, основываясь на знании работающего приложения, а не на малых искусственных объемах данных в тестовых базах данных.
Неподчеркнутые числа рядом с обоими концами связи представляют среднее количество строк, найденных в таблице на этом конце соединения для соответствующей строки на другом конце соединения. Они называются коэффициентами соединения. Коэффициент соединения в начале соединения — это детальный коэффициент соединения, а на конце соединения (со стрелкой) — главный коэффициент соединения.
Главные коэффициенты соединения всегда меньше или равны 1,0, так как уникальный ключ гарантирует обнаружение нескольких главных строк для одной детальной. Часто встречается случай, когда в детальной таблице внешний ключ обязателен и ссылочная целостность данных идеальна (что гарантирует существование подходящей главной строки), тогда главный коэффициент соединения равен в точности 1,0.
Детальные коэффициенты соединения могут быть равны любому неотрицательному числу. Они могут быть меньше 1,0, так как некоторые отношения главной и детальной таблиц разрешают существование нуля, одной или многих детальных строк, причем чаще всего встречается случай «один к нулю». В примере для средней строки Employees есть соответствующая строка (с которой она связана) в Departments в 98 % случаев, тогда как средняя строка Departments соответствует (связывается с) 20 строкам Employees. Нужно по возможности получать эти значения из полных, реальных распределений данных. Так же, как и с коэффициентами фильтрации, может потребоваться вычисление коэффициентов соединения во время фазы разработки приложения.
Диаграммы запросов полностью исключают любые упоминания списков столбцов и выражений, которые выбирает запрос (то есть все, что находится между SELECT и FROM). Производительность запроса практически полностью определяется тем, какие строки выбираются из базы данных, и каким образом они получаются. Что делается с этими строками, какие столбцы возвращаются, и какие выражения подсчитываются — это практически несущественно для производительности. Главное, но редкое исключение из этого правила — когда выбираются так мало столбцов из таблицы, что база данных может выполнить запрос, используя только данные из индекса, совершенно не обращаясь к основной таблице. Иногда доступ только к индексу может существенно сэкономить ресурсы, но он мало влияет на решения, которые принимаются относительно оставшейся части плана исполнения. Решать, нужно ли попробовать только индексный доступ, следует в последний момент процесса настройки и только если наилучший план без применения этой стратегии оказывается слишком медленным.
В диаграмме отсутствуют любые указания на сортировку (ORDER BY), группировку (GROUP BY) и фильтрацию после группировки (HAVING). Эти операции практически никогда не имеют большого значения для производительности запроса. Шаг сортировки, который они обычно включают, может влиять на скорость выполнения, но для изменения его стоимости мало что можно сделать, и эта стоимость обычно не так велика по сравнению с производительностью плохо выполняющегося запроса.
В диаграммах запроса имена таблиц обычно заменяются псевдонимами. Не имеет значения, из какой таблицы запрос считывает данные или какие сущности хранятся в таблицах. Нужно уметь преобразовывать результат обратно в действия в исходном SQL и в базе данных (такие действия, как создание нового индекса, например). Однако при решении абстрактной проблемы настройки, то чем более абстрактными будут названия узлов, тем лучше.
Детали условий соединения теряются, когда представляются соединения как простые стрелки с парой чисел, полученных откуда-то за пределами SQL. Если известна статистика соединения, то подробности (например, столбцы соединения и как они между собой связаны) не играют роли.
Диаграмма не указывает размеры таблиц. Однако можно сделать предположение о размерах таблиц, исходя из детального коэффициента соединения, который находится у верхнего конца связи. Имея диаграмму запроса, необходимо знать общие размеры таблиц, чтобы установить, сколько будет возвращено строк, и сколько времени займет выполнение запроса. Но оказывается, что эта информация не нужна для выяснения относительного времени выполнения различных вариантов, и, следовательно, для поиска лучшего. Это полезный результат, поскольку зачастую необходимо добиться хорошего выполнения запроса не только на единственном экземпляре базы данных, но на целом диапазоне экземпляров для множества пользователей. Для различных пользователей могут существовать таблицы различных абсолютных размеров, но относительные размеры обычно изменяются несущественно, а коэффициенты соединения и фильтрации и того меньше. В действительности они изменяются настолько мало, что различия можно игнорировать.
Подробности условий фильтрации теряются, когда они абстрагируются до обыкновенных чисел. Можно выбрать оптимальный путь к данным, ничего не зная о том, как, или по каким столбцам база данных исключает строки из результата выполнения запроса. Необходимо только знать, насколько эффективен в числовом отношении каждый фильтр для достижения поставленных целей исключения строк. Как только будет обнаружен абстрактный оптимальный план, потребуется вернуться к подробным условиям фильтрации, чтобы понять, что нужно изменить. Можно изменить индексы для достижения оптимального пути, или изменить SQL-код, чтобы заставить базу данных использовать уже существующие индексы, но, в любом случае, этот финальный шаг прост, если известно, каков оптимальный абстрактный план.
Похожие работы

... Сэл.эн.каб.=n*b*Pлам*Сквт/ч, где Сэл.эн.каб. - затраты на электроэнергию для освещения кабинета (руб.) n - количество часов, необходимых для разработки одной программы = 98 b - количество ламп в кабинете= 24 Рлам - мощность, потребляемая 1 лампочкой за 1 час. При разработке программы составила 0,04 квт Сквт/ч - стоимость 1 квт/ч, равна 1,45 руб. Подставив значения в формулу, получим: Сэл ...
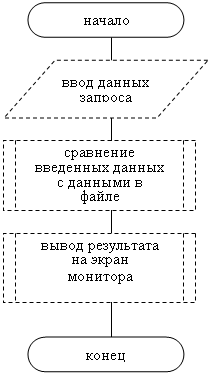
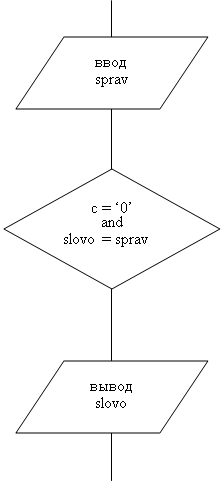
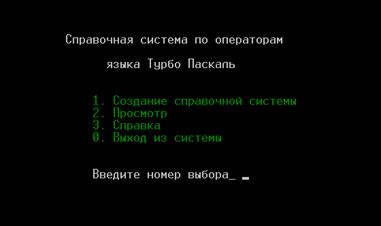
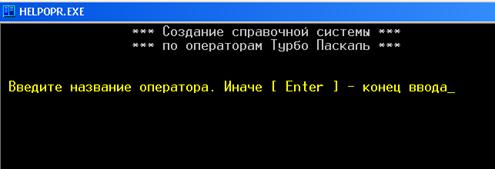
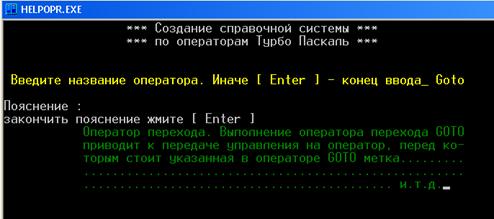
... свободного пространства Видео: Любое ОC: Windows'95 – XP SP2 Дополнительных средств (принтер, сканер, дополнительные дисководы и т.д.) не требуется. 2. Разработка рабочего проекта 2.1 Разработка программы Для разработки приложения «Helpopr» используется среда программирования Turbo Pascal 7.0. Проект программы содержит основное окно выбора «Меню»[8]; Список глобальных переменных ...
... ) ФАКУЛЬТЕТ ЭЛЕКТРОНИКИ И ПРИБОРОСТРОЕНИЯ КАФЕДРА КЭС группа Э-92 ДАТА ЗАЩИТЫ апреля 1997 г. Отзыв на дипломную работу студента гр.Э-92 Сорокина Ю.В. “Разработка программы контроллера автоматически связываемых объектов для управления конструкторской документацией в среде Windows 95/NT”. Широкое использование вычислительной техники в народном хозяйстве требует увеличения производства и ...
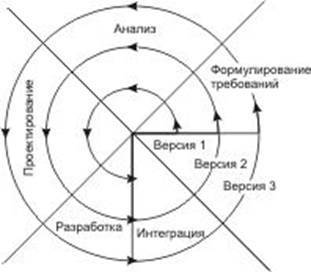
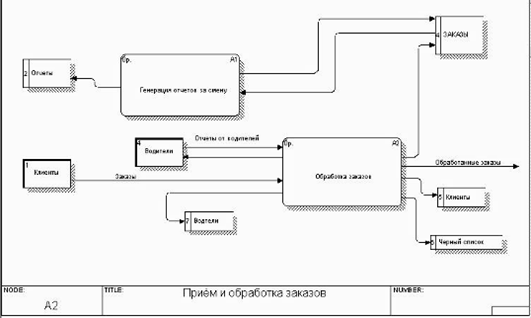
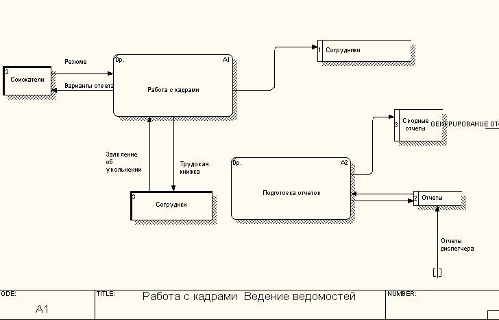
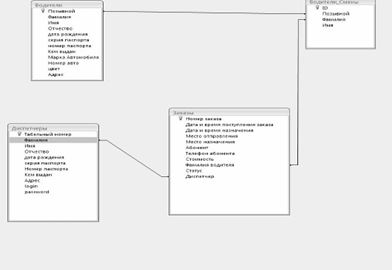
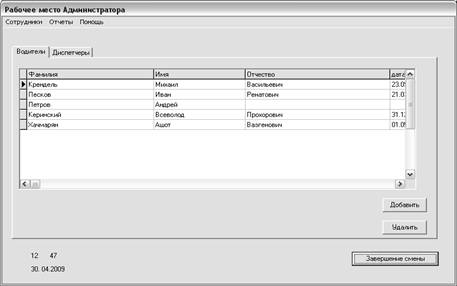
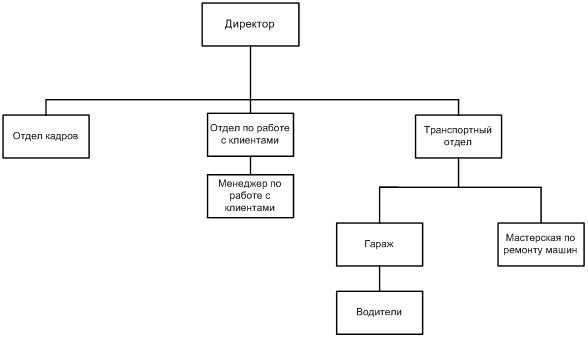
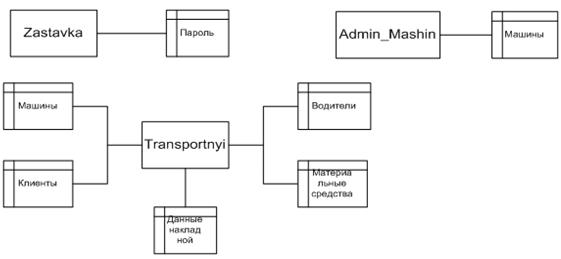
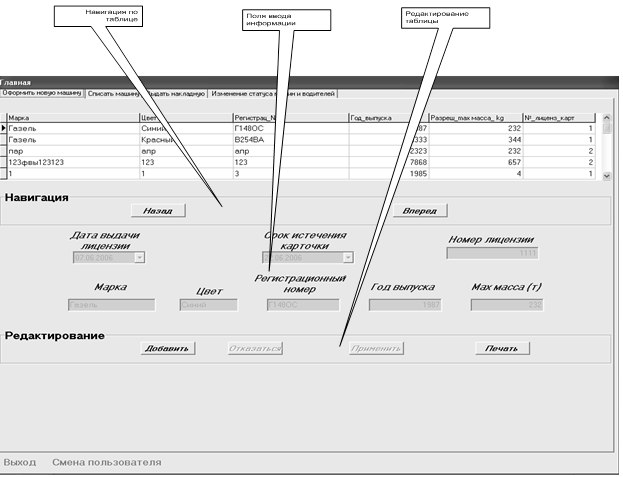
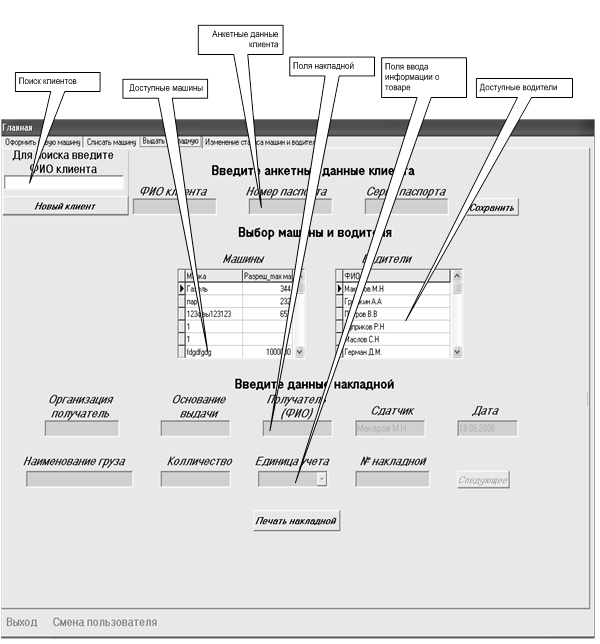
... продукта и создание удобных карточек заполнения атрибутов БД: простота создания связей и их модернизация. Глава II. Разработка программы для автоматизации деятельности таксопарка 2.1 Анализ требований заказчика Программа Автоматизированное рабочее место диспетчера такси разработана по спиральной модели жизненного цикла автоматизированных информационных систем. На каждом этапе создания ...
0 комментариев