ОБЗОР ОБЪЕКТА ОБРАБОТКИ ИНФОРМАЦИОННО-СПРАВОЧНОЙ ПОДСИСТЕМЫ
Коаксиальные коннекторы
Возможности соединения оптического волокна
Малогабаритные оптические соединители
ПРОЕКТИРОВАНИЕ ИНФОРМАЦИОННО-СПРАВОЧНОЙ ПОДСИСТЕМЫ САПР КОНСТРУКТОРСКО-ТЕХНОЛОГИЧЕСКОГО НАЗНАЧЕНИЯ
Уникальность: в произвольный заданный момент времени никакие два различных кортежа R не имеют одного и того же значения для Ai, Aj, ..., Ak
Навигация
ПРОЕКТИРОВАНИЕ ИНФОРМАЦИОННО-СПРАВОЧНОЙ ПОДСИСТЕМЫ САПР КОНСТРУКТОРСКО-ТЕХНОЛОГИЧЕСКОГО НАЗНАЧЕНИЯ
Создание информационно-справочной подсистемы САПР конструкторско-технологического назначения. Внешние соединители
68123
знака
8
таблиц
53
изображения
3. ПРОЕКТИРОВАНИЕ ИНФОРМАЦИОННО-СПРАВОЧНОЙ ПОДСИСТЕМЫ САПР КОНСТРУКТОРСКО-ТЕХНОЛОГИЧЕСКОГО НАЗНАЧЕНИЯ
3.1 Проектирование хранилища данных
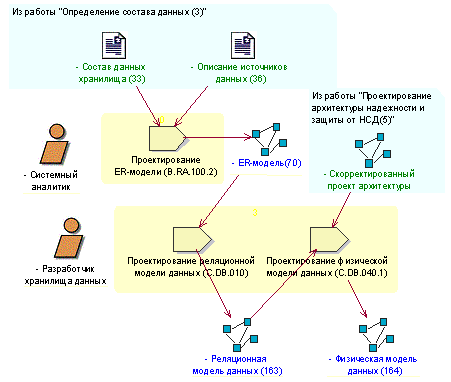
Рисунок 3.1- Состав и взаимосвязь задач работы «Проектирование данных хранилища»
При разработке ER-модели необходимо помнить, что это наиболее общий вид модели, с которым имеет дело разработчик – в том смысле, что модели этого вида практически не привязаны к компьютерным реалиям (абстрагированы от них). Это «понятийная модель», модель понятий предметной области. Таким образом, при разработке ER-модели проектируется схема понятий прикладной области в их взаимосвязи.
Основными понятиями ER-модели являются сущность, связь и атрибут.
Сущность - это реальный или представляемый объект, информация о котором должна сохраняться и быть доступна. Имя сущности - это имя класса, а не некоторого конкретного экземпляра этого класса. Для большей выразительности и лучшего понимания имя сущности может сопровождаться примерами конкретных объектов этого типа. Каждый экземпляр сущности должен быть отличим от любого другого экземпляра той же сущности.
Связь - это графически изображаемая ассоциация, устанавливаемая между двумя сущностями. Эта ассоциация всегда является бинарной и может существовать между двумя разными сущностями или между сущностью и ей же самой (рекурсивная связь).
Атрибутом сущности является любая деталь, которая служит для уточнения, идентификации, классификации, числовой характеристики или выражения состояния сущности.
Уникальным идентификатором сущности является атрибут, комбинация атрибутов, комбинация связей или комбинация связей и атрибутов, уникально отличающая любой экземпляр сущности от других экземпляров сущности того же типа.
Сущность может быть расщеплена на два или более взаимно исключающих подтипа, каждый из которых включает общие атрибуты и/или связи. Эти общие атрибуты и/или связи явно определяются один раз на более высоком уровне. В подтипах могут определяться собственные атрибуты и/или связи. В принципе подтипизация может продолжаться на более низких уровнях, но опыт показывает, что в большинстве случаев оказывается достаточно двух-трех уровней.
Сущность, на основе которой определяются подтипы, называется супертипом. Подтипы должны образовывать полное множество, т.е. любой экземпляр супертипа должен относиться к некоторому подтипу.
ER-модель - это модель понятий предметной области в их взаимосвязи, и иерархии среди этих объектов.
После того, как будет сформирована ER-модель, разработчик хранилища данных разрабатывает реляционную и физическую модели данных.
Реляционная модель данных представляет собой трансформацию ER-модели и описывает следующие элементы проектирования:
![]() описание таблиц, столбцов и представлений,
описание таблиц, столбцов и представлений,
![]() описания первичных, уникальных и внешних ключей,
описания первичных, уникальных и внешних ключей,
![]() правила по уровням валидации столбцов и строк (ограничения проверок),
правила по уровням валидации столбцов и строк (ограничения проверок),
![]() правила заполнения отдельных столбцов (последовательность, источники).
правила заполнения отдельных столбцов (последовательность, источники).
Разработка реляционной модели ведется на основе ER-модели с учетом особенностей выбранного типа базы данных. В отличие от построения ER-модели, построение реляционной модели несет в себе сравнительно малую семантическую нагрузку, и часто понимается уже как «логическое моделирование базы данных» (а не прикладной области). В таком понимании цель его состоит в том, чтобы описать базу данных безотносительно к конкретной СУБД (считается, что проектируется как бы «логически одна» база данных для всего хранилища данных ИАС). Основная цель разработки реляционной модели - сформировать домены, их атрибуты и взаимосвязи с учетом требований постановки задачи и независимости данных (а они могут противоречить друг другу).
Физическая модель данных описывает структуры хранения данных с использованием всех особенностей конкретной СУБД. Она непосредственно учитывает такие аспекты, как архитектуру, безопасность, эффективность доступа и другие.
Результат выполнения работы «Проектирование данных хранилища»В результате выполнения этой работы формируется модель хранилища данных, включающая в себя следующие артефакты, «ER-модель», «Реляционная модель данных», «Физическая модель данных».
ER-модель - это модель объектов предметной области в их взаимосвязи, и иерархии среди этих объектов.
Реляционная модель данных описывает следующие элементы проектирования хранилища данных:
![]() таблицы, столбцы и представления,
таблицы, столбцы и представления,
![]() первичные, уникальные и внешние ключи,
первичные, уникальные и внешние ключи,
![]() правила по уровням валидации столбцов и строк (ограничения проверок),
правила по уровням валидации столбцов и строк (ограничения проверок),
![]() правила заполнения отдельных столбцов (последовательность, источники).
правила заполнения отдельных столбцов (последовательность, источники).
Физическая модель представляет собой SQL скрипт, позволяющий создать реальную базу данных. В ряде случаев может потребоваться также включить в физическую модель описание дополнительных настроек СУБД, необходимых для реализации БД.
Физическая модель данных содержит следующую информацию:
![]() описание базы данных, сегментов отката и табличных областей,
описание базы данных, сегментов отката и табличных областей,
![]() описания файлов и структуры памяти,
описания файлов и структуры памяти,
![]() типы индексов,
типы индексов,
![]() описания объектов, связанных с хранилищем данных (физическое размещение, включая сегментацию).
описания объектов, связанных с хранилищем данных (физическое размещение, включая сегментацию).
Современные объемы хранимых данных, обязательные требования к их доступности и скорости обработки, динамика развития систем обуславливают важность исследования факторов, влияющих на качество баз данных (БД), лежащих в основе современных информационных систем.
Обычно жизненный цикл БД включает в себя этапы концептуального и логического проектирования, разработки, сопровождения и развития. Рассмотрим каждый этап.
На этапе концептуального проектирования анализируются свойства и характеристики исследуемой предметной области и формируются канонические структуры баз данных, обычно представляемые в виде графов, узлами которых являются объекты предметной области, а дугами - отношения между ними. Для описания канонической структуры базы данных используются разные технологии и инструментальные средства, например Rational Rose и реализованная в нем нотация UML (Unified Modeling Language - унифицированный язык моделирования). UML обеспечивает описание предметной области на наиболее естественном языке: как классы, объекты и отношения между ними. Язык описания предметной области на данном этапе крайне важен: проектировщик анализирует и моделирует ее в обязательном контакте с пользователями, большинство из которых не являются техническими специалистами, поэтому для корректной интерпретации моделей язык их описания должен быть простым и понятным. На данном этапе моделирование осуществляется без привязки к конкретной СУБД.
На следующем этапе каноническая структура преобразуется в логическую структуру баз данных, которая учитывает ограничения выбранной СУБД. Рассмотрим особенности построения логических структур для объектно-ориентированных и реляционных СУБД.
Известно, что реляционные базы данных представляют собой множество двумерных таблиц и отношений между ними, задаваемых структурой внешних ключей. Каноническая структура часто содержит сложные объекты и связи - как межобъектные, так и внутриобъектные (сложные типы данных). Поэтому процесс проектирования логических структур баз данных реляционного типа сводится к следующей последовательности операций: анализ предметной области и выделение базовых типов сущностей, нормализация типов сущностей и формирование логических записей, установление связей между записями.
Несмотря на формальную строгость методов проектирования реляционных баз данных, им присущ ряд недостатков. При построении информационных систем, использующих большое число информационных элементов, логические структуры БД для данных систем ввиду многочисленных многозначных зависимостей между данными могут состоять из десятков и даже сотен таблиц, что делает такие БД плохо обозримыми и управляемыми. Более того, за счет разбиения объектов предметной области на плоские нормализованные отношения теряется семантика исследуемой предметной области, что усложняет сопровождение и модернизацию систем. Данные методы не позволяют также адекватно моделировать отдельные свойства данных.
Для адекватного моделирования сложных структур данных проектировщик должен иметь возможность определять свои типы данных, не ограничиваясь теми данными, которые предоставляются определенной реляционной СУБД. Реляционная модель не позволяет также определить набор операций, связанных с данными определенного типа, что часто является естественным требованием при моделировании объектов предметной области. Операции приходится задавать в конкретном приложении. Поэтому использование таких методов проектирования требует высокой квалификации проектировщиков.
В основе объектно-ориентированного подхода к моделированию предметных областей лежат такие понятия, как объект и свойства инкапсуляции, наследования и полиморфизма.
· Свойство инкапсуляции означает, что объекты имеют некоторую структуру и определенный набор операций, т.е. поведение. Внутренняя структура объекта скрыта от пользователя. Манипулирование объектом, изменение его состояния возможны лишь с помощью специальных методов, определяемых заданным набором операций.
· Свойство наследования позволяет создавать из объектов новые объекты. Они наследуют структуру и поведение своих предшественников, к которым добавляются характеристики, отражающие их индивидуальность.
· Свойство полиморфизма означает, что различные объекты могут получать одинаковые сообщения, но реагировать на них по-разному - в зависимости от того, каким образом в них реализованы методы реакции на сообщения.
Объектно-ориентированные технологии обеспечивают естественный переход от концептуальной структуры БД к логической структуре БД. В отличие от реляционных БД при проектировании объектно-ориентированных БД (ООБД) не требуется декомпозиция и нормализация объектов, выделенных на этапе концептуального проектирования. Объекты представляются в том же виде, что наделяет объектно-ориентированные структуры наглядностью и прозрачностью и позволяет значительно сократить время на их разработку и повысить степень преемственности. ООБД определяют возможность создания и использования сложных типов данных. При этом не требуется модификации ядра ООБД и для создания нового типа необходимо унаследовать характеристики любого имеющегося типа, наиболее подходящего по своему поведению и состоянию, расширить недостающие операции и атрибуты и переопределить уже имеющиеся. Полученные объектно-ориентированные структуры обладают высокой степенью модульности, что позволяет вносить в них изменения наиболее простым и безболезненным способом. При этом изменения влияют на один класс (или связанную подсистему классов) и могут эффективно управляться и проверяться. Развитые объектно-ориентированные СУБД содержат эффективные интерфейсы интеграции с известными инструментальными средствами проектирования, обеспечивающие автоматическую генерацию логической структуры и ее загрузку в ООБД. Например, СУБД Cache от компании InterSystems содержит интерфейс RoseLink, обеспечивающий тесную интеграцию с продуктом Rational Rose.
Рассмотрим этап разработки. Все множество запросов пользователей к БД можно разделить на два класса - множество запросов на модификацию данных и множество запросов на выборку данных. На этом этапе сложно сказать, какая структура - объектная или реляционная - наиболее предпочтительна. Простой, в то же время крайне эффективный и стандартизированный язык SQL обеспечивает наиболее удобные на данный момент механизмы для выборки и анализа данных и значительно превосходит по возможностям и удобству использования другие языки выборки и анализа данных. С другой стороны, объектно-ориентированные БД за счет поддержки сложных типов данных и отношений, механизмов свизлинга и двухэтапной фиксации данных предоставляют более развитые в сравнении с реляционными БД средства для работы с отдельными записями в БД. В отдельный класс запросов пользователей следует вынести задачи, связанные с массовой загрузкой, выгрузкой и обработкой данных. Данные задачи обычно выполняются в эксклюзивном режиме и часто требуют максимальной скорости выполнения. Известно, что максимальную скорость при работе с большими объемами данных обеспечивают иерархические базы данных. Таким образом, можно сделать вывод, что на этапе разработки выгодно использовать сразу три способа работы с данными. Что же делать? Создавать различные БД под управлением различных СУБД и регулярно их синхронизировать? Дорогое и очень сомнительное решение...
Последний этап - это этап развития системы. Безусловным лидером по удобству и скорости является объектный подход, который за счет реализации принципов наследования и полиморфизма обеспечивает наиболее простой и эффективный способ адаптации схемы БД в условиях изменяющихся требований пользователей.
Приведенный анализ наглядно демонстрирует неэффективность "чистых" СУБД (будь то реляционные или объектно-ориентированные СУБД) для построения БД, входящих в состав современных информационных систем. Так, на этапах проектирования (концептуального и логического), сопровождения и развития целесообразно использовать объектно-ориентированные технологии. На этапе разработки для реализации задач выборки и анализа данных - SQL, для работы с отдельными записями в БД - объекты, для массовой обработки данных - иерархические массивы.
В этой связи все большую популярность приобретают гибридные или постреляционные СУБД, которые реализуют сразу несколько моделей данных в рамках единого хранилища данных, а наиболее развитые - и в рамках единого хранилища метаданных.
На рынке представлено несколько гибридных СУБД от разных поставщиков. Условно их можно разделить на два класса. К первому относятся реляционно-объектные (объектно-реляционные) СУБД, в которых имеется объектная или реляционная надстройка над соответственно реляционной или объектной моделью данных. Эту модель активно продвигают традиционные поставщики реляционных СУБД.
Второй класс - постреляционные СУБД. Они не строятся ни на реляционной, ни на объектной модели, однако также позволяют представлять хранимые данные в виде как реляционных таблиц, так и классов объектов. К этому классу СУБД относится и СУБД Cache от компании InterSystems.
Обоим типам гибридных систем свойственны ненормализованная модель данных, инкапсулированная семантика приложений и множество внешних интерфейсов - как объектных, так и реляционных. Рассмотрим их особенности.
Объектная или реляционная надстройка над существующим ядром системы позволяет обойти часть ограничений, присущих ядру. Однако в этом случае складывается многоуровневая архитектура (рис.), что отрицательно влияет на производительность надстроек и утяжеляет само ядро системы. Кроме того, такая надстройка в большинстве случаев ограничена и не соответствует стандартам на реализацию модели (SQL92, SQL99) или рекомендациям комитетов по стандартизации (ODMG).
Сравнение Сache и реляционно-объектных архитектур
Ядро постреляционных СУБД не использует ни реляционную, ни объектную схему - обычно оно построено на базе сетевой или иерархической модели. Зачем это делается? Известно, что реализации сетевой и в особенности иерархической модели БД отличаются высокой скоростью работы с данными и простотой масштабируемости. При этом гибкость языковой среды иерархических БД позволяет весьма эффективно воплощать ту или иную модель данных. Именно поэтому многие специалисты рекомендуют использовать иерархическую СУБД в качестве основы даже для "чистых" реляционных и объектных СУБД. Для работы с данными в постреляционных СУБД применяются механизмы, которые представляют массивы данных иерархического или сетевого ядра системы в виде классов объектов и реляционных таблиц и обеспечивают необходимые механизмы (например, встроенные языки третьего поколения или интерфейсы к внешним инструментариям) для работы с ними.
Основное отличие и преимущество постреляционных СУБД в сравнении с реляционно-объектными СУБД состоит в том, что в постреляционных СУБД механизмы работы с объектами и реляционными таблицами находятся на одном логическом уровне, что обеспечивает более высокую скорость доступа и работы с данными, функциональную полноту, в т.ч. соответствие определенным стандартам и спецификациям.
3.3 Реляционная структура данныхВ конце 60-х годов появились работы, в которых обсуждались возможности применения различных табличных даталогических моделей данных, т.е. возможности использования привычных и естественных способов представления данных. Наиболее значительной из них была статья сотрудника фирмы IBM д-ра Э.Кодда (Codd E.F., A Relational Model of Data for Large Shared Data Banks. CACM 13: 6, June 1970), где, вероятно, впервые был применен термин "реляционная модель данных".
Будучи математиком по образованию Э.Кодд предложил использовать для обработки данных аппарат теории множеств (объединение, пересечение, разность, декартово произведение). Он показал, что любое представление данных сводится к совокупности двумерных таблиц особого вида, известного в математике как отношение – relation (англ.)
Наименьшая единица данных реляционной модели – это отдельное атомарное (неразложимое) для данной модели значение данных. Так, в одной предметной области фамилия, имя и отчество могут рассматриваться как единое значение, а в другой – как три различных значения.
Доменом называется множество атомарных значений одного и того же типа. Так домен пунктов отправления (назначения) – множество названий населенных пунктов, а домен номеров рейса – множество целых положительных чисел.
Смысл доменов состоит в следующем. Если значения двух атрибутов берутся из одного и того же домена, то, вероятно, имеют смысл сравнения, использующие эти два атрибута (например, для организации транзитного рейса можно дать запрос "Выдать рейсы, в которых время вылета из Москвы в Сочи больше времени прибытия из Архангельска в Москву"). Если же значения двух атрибутов берутся из различных доменов, то их сравнение, вероятно, лишено смысла: стоит ли сравнивать номер рейса со стоимостью билета?
Отношение на доменах D1, D2, ..., Dn (не обязательно, чтобы все они были различны) состоит из заголовка и тела. На рис. 3.2 приведен пример отношения для расписания движения самолетов
Заголовок состоит из такого фиксированного множества атрибутов A1, A2, ..., An, что существует взаимно однозначное соответствие между этими атрибутами Ai и определяющими их доменами Di (i=1,2,...,n).
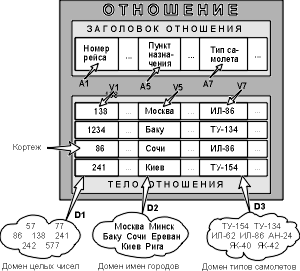
Рис. 3.2. Отношение с математической точки зрения (Ai - атрибуты, Vi - значения атрибутов)
Тело состоит из меняющегося во времени множества кортежей, где каждый кортеж состоит в свою очередь из множества пар атрибут-значение (Ai:Vi), (i=1,2,...,n), по одной такой паре для каждого атрибута Ai в заголовке. Для любой заданной пары атрибут-значение (Ai:Vi) Vi является значением из единственного домена Di, который связан с атрибутом Ai.
Степень отношения – это число его атрибутов. Отношение степени один называют унарным, степени два – бинарным, степени три – тернарным, ..., а степени n – n-арным. Степень отношения "Рейс" – 8.
Кардинальное число или мощность отношения – это число его кортежей. Мощность отношения "Рейс" равна 10. Кардинальное число отношения изменяется во времени в отличие от его степени.
Поскольку отношение – это множество, а множества по определению не содержат совпадающих элементов, то никакие два кортежа отношения не могут быть дубликатами друг друга в любой произвольно-заданный момент времени. Пусть R – отношение с атрибутами A1, A2, ..., An. Говорят, что множество атрибутов K=(Ai, Aj, ..., Ak) отношения R является возможным ключом R тогда и только тогда, когда удовлетворяются два независимых от времени условия:
Похожие работы
... . Предполагается снижение уровня дефектов, выявленных на этапах сборки, приемки и инспекционного контроля на 25%, уменьшение количества рекламаций на 30%. Для определения экономической эффективности предложенных мероприятий по повышению конкурентоспособности и качества продукции необходимо рассчитать затраты, которые понесет предприятие и результаты, которые будут получены при их реализации. ...
0 комментариев