Навигация
Распознавание графических символов
32565
знаков
0
таблиц
15
изображений
СОДЕРЖАНИЕ
ВВЕДЕНИЕ
1. ПОСТАНОВКА ЗАДАЧИ
2. ОПИСАНИЕ ИСПОЛЬЗОВАННЫХ АЛГОРИТМОВ
2.1 Алгоритм сегментации текста
2.2 Алгоритм распознавания слова. Персептрон
3. РАЗРАБОТКА И РЕАЛИЗАЦИЯ ПО
3.1 Архитектура программы
3.2 Интерфейс программы
3.3 Описание разработанных классов
4. ТЕСТИРОВАНИЕ ПО
4.1 Запуск приложения
ВЫВОДЫ
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
ПРИЛОЖЕНИЕ A ЛИСТИНГ ПРОГРАММЫ
ОПИСЬ ЛИСТОВ ГРАФИЧЕСКОЙ ЧАСТИ
ВВЕДЕНИЕ
В последние годы распознавание образов находит все большее применение в повседневной жизни. Распознавание речи и рукописного текста значительно упрощает взаимодействие человека с компьютером, распознавание печатного текста используется для перевода документов в электронную форму.
Реализация методов распознавания необходима в автоматизированных системах, предназначенных для использования в криминалистике, медицине, военном деле.
Особо следует отметить распознавание полноценных изображений. Область применения данного раздела многогранна. Например, на современных заводах контроль качества производимой продукции зачастую производят с использованием систем распознавания, которые отсеивают брак. Распознавание полноценных изображений применяется также на дорогах, для определения и распознавания номеров автомобилей, контроль их скорости. Обработка изображений актуальна и при анализе снимков из космоса и с самолётов. Таким образом, видно, что область применения распознавания изображений широка и многогранна и позволяет намного сократить и упростить рабочий процесс и вместе с тем повысить его качество. Однако, возможности интеллектуального анализа изображений с помощью компьютеров оставляют желать лучшего. Можно с уверенностью отметить лишь успехи в распознавании букв и цифр в документах и текстах, а также анализе изображений специального вида. Такая область как распознавание текстур, исследование в которой проводятся не одно десятилетие, пока не имеет универсальных методов.
Задачей распознавания изображений является применение методов, позволяющих либо получить некоторое описание изображения, поданного на вход системы, либо отнести это изображение к некоторому определенному классу. Процедура распознавания применяется к некоторому изображению и обеспечивает преобразование его в некоторое абстрактное описание: набор чисел, цепочку символов или граф. Последующая обработка такого описания позволяет отнести исходное изображение к одному из нескольких классов.
Но возникает ряд трудностей и проблем. Чаще всего это связано с тем, что изображения предъявляются на сложном фоне или изображения эталона и входные изображения отличаются положением в поле зрения, или входные изображения не совпадают с эталонами за счет случайных помех.
В данном курсовом проекте разработано приложение, позволяющие на изображении какого либо документа, либо просто текста находить слово "Указ". Входное изображение может быть любого размера, ориентация текста должна быть горизонтальной.
Приложение реализовано в среде программирования MS Visual Studio 2008 на языке C#. Платформа .Net дает широкий набор классов для работы с изображениями и обработки результатов.
1. ПОСТАНОВКА ЗАДАЧИ
Согласно заданию к курсовому проекту необходимо спроектировать приложение, реализованное на языке C# в среде разработки Microsoft Visual Studio 2008, реализующее распознавание слова "Указ" на изображении документа.
Исходные данные:
1. Растровое изображение документа.
2. Текст документа должен быть написан на белом фоне, черным шрифтом.
3. Шрифт текста не должен быть курсивным либо полужирным.
4. Размер изображения может быть любым.
5. Положение текста на изображении горизонтальное.
Приложение должно выполнять следующие задачи:
1. Загрузка изображения в приложение.
2. Сегментация текста на слова.
3. Распознавание среди слов слово "Указ".
Выходные данные:
1. Таблица найденных слов "Указ".
2. ОПИСАНИЕ ИСПОЛЬЗОВАННЫХ АЛГОРИТМОВ 2.1 Алгоритм сегментации текста
Процесс сегментации текста состоит из двух этапов: выделение строк текста и выделение слов в строках.
Поиск строк осуществляется путем просмотра пикселей изображения сверху вниз. При проходе запоминаются вертикальные координаты всех полностью белых полос на изображении (рисунок 2.1).

Рисунок 2.1 – Разбиение текста на строки
После нахождения всех белых горизонтальных полос анализируются их индексы. Для исключения соседних линий, строкой текста считается растр находящийся между двумя последовательными в списке, но не соседними белыми полосками.
Процесс поиска слов в строке заключается в анализировании вертикальных полос на изображении строки. При нахождении первой не полностью бело линии координата запоминается и считается начальной координатой слова, затем анализируются расстояния между буквами. При превышении некоторого порога слово "вырезается" из строки. Процесс продолжается до конца строки.
Алгоритм сегментации текста представлен в графической части
2.2 Алгоритм распознавания слова. ПерсептронРаспознавание слова "Указ" в разработанном приложении, реализовано на базе персептрона. Алгоритм обучения персептрона – без учета правильности ответа. Персептрон построен по схеме "Несколько сумматоров". Общая схема персептрона представлена на рисунке 2.2
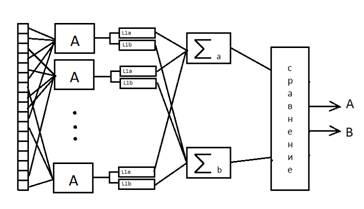
Рисунок 2.2 – Схема персептрона с несколькими сумматорами
Каждый А-элемент имеет несколько входов и один выход.
А-элементы производят алгебраическое суммирование сигналов, поступивших на их входы, и полученную сумму сравнивают с одинаковой для всех А-элементов величиной ϑ. Если сумма больше ϑ, А-элемент возбуждается и выдает на выходе сигнал, равный единице. Если сумма меньше ϑ, А-элемент остается невозбужденным и выходной его сигнал равен нулю. Таким образом, выходной сигнал j-го Α-элемента:
yj= ![]()

где величина rij принимает значение +1, если i -й рецептор подключен ко входу j-го Α-элемента со знаком плюс; и значение -1, если рецептор подключен со знаком минус, и значение 0, если i-ый рецептор к j-му Α-элементу не подключается (j = 1, 2, …, m, где m – число Α-элементов).
Выходные сигналы Α-элементов умножаются на переменные коэффициенты λj.
После умножения на λ выходные сигналы поступают на сумматоры Σ, количество которых также равно числу различаемых образов.
σ = ![]()
Предъявленный объект относится к тому образу, сумматор которого имеет наибольший сигнал.
В данной работе есть два распознаваемых класса условно из можно обозначить "Указ" и "Не указ". При обучении класса "Указ" на вход персептрона поступают изображения слова "Указ" написанное разными шрифтами. При обучении класса "Не указ", для повышения надежности работы персептрона, поступают те же изображения с текстом "Указ", но с инвертированными цветом.
В каждом такте персептрон отвечает на предъявленный ему объект возбуждением некоторых А-элементов. Обучение состоит в том, что коэффициенты λj возбужденных в данном такте А-элементов увеличиваются на некоторую величину (например на единицу), если в этом такте был предъявлен объект образа А, и уменьшается на эту же величину, если был предъявлен объект образа В.
3. РАЗРАБОТКА И РЕАЛИЗАЦИЯ ПО 3.1 Архитектура программы
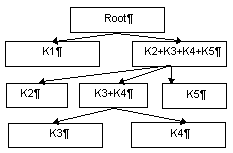
Программа написана как проект Windows Forms Application, т.е. windows-приложение, графический интерфейс которого представлен формами и диалоговыми окнами. Структура разработанного проекта представлена на рисунке 3.1.
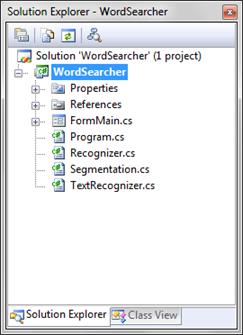
Рисунок 3.1 – Структура проекта
Приложение разработано на принципах ООП. Диаграмма разработанных классов представлена на рисунке 3.2
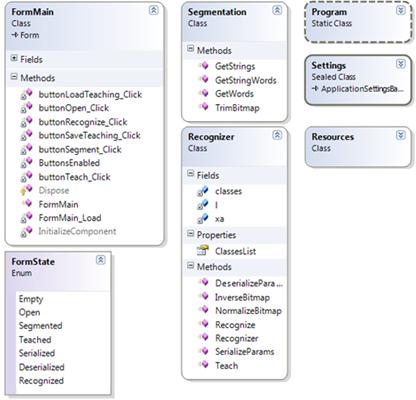
Рисунок 3.2 – Диаграмма классов приложения
Общая схема приложения в натации IDEF0 приведена на рисунке 3.3.
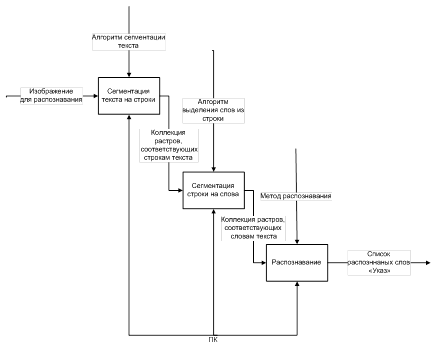
Рисунок 3.3 – Общая схема IDEF0 приложения
Похожие работы
... 0.98; gotoxy(10,24); writeln('Press any key to continue...'); readkey; graphiki; readkey; closegraph; End. ПРИЛОЖЕНИЕ Б Текст программы распознавания символов Program Final_of_work; uses graph; const BiH=50; {-------высота картинки в пикселях------} BiW=160; {-------ширина картинки в ...
... Правильное понимание таблицы читателем невозможно без учета информации о взаимном расположении строк, колонок и ячеек таблицы. Поэтому при автоматизированном распознавании табличных форм необходимо в выходном документе сохранить то же взаимное расположение этих структурных табличных элементов, что и в исходной таблице. Строки и колонки таблиц могут иметь иерархическую структуру (рис. 3), причем ...
... случае присоединения к компьютерной системе сканера, в окне папки «Панель управления» появляется соответствующий значок, позволяющий производить настройку. Таким образом, в большинстве программ работа со сканером производится при посредстве специального диалогового окна, обеспечивающего непосредственное взаимодействие со сканером. После того как пользователь дает команду на сканирование документа ...
... с приглашением по запросу (в машинной графике)required parameter обязательный параметрrequired space обязательный пробел (в системах подготовки текстов)requirements specification 1. техническое задание 2. описание требований к программному средствуrerun перезапуск, повторный запускreschedule переупорядочивать очередь (о диспетчере операционной системы)reschedule interval период переупорядочения ...
0 комментариев