Навигация
Распределённые базы данных
59434
знака
0
таблиц
14
изображений
Распределённые базы данных
Введение
1 История вопроса
Введение
В условиях современного динамического развития общества и усложнения технической и социальной инфраструктуры информация становится таким же стратегическим ресурсом, как традиционные материальные и энергетические ресурсы [1]. Современные информационные технологии, позволяющие создавать, хранить, перерабатывать и обеспечивать эффективные способы представления информационных ресурсов потребителю, стали важным фактором жизни общества и средством повышения эффективности управления всеми сферами общественной деятельности. Уровень использования информации становится одним из существенных факторов успешного экономического развития и конкурентоспособности региона как на внутреннем, так и на внешнем рынке.
Осознание мировым сообществом роли информации как стратегического ресурса стимулировало разработки новых информационных технологий для получения и переработки больших объемов информации и ее хранения и предоставления пользователям. Первое место среди новых технологий занимают сетевые информационные технологии.
Информация является важнейшим стратегическим ресурсом, и наибольший экономический и социальный успех сегодня сопутствует тем странам, которые активно используют современные средства компьютерных коммуникаций и сетей, информационных технологий и систем управления информационными ресурсами. Перенесенные на электронные носители информационные ресурсы приобретают качественно новое состояние и становятся активными. Доступная для оперативного воспроизводства средствами компьютерной обработки информация является важнейшим фактором социального развития общества.
В настоящее время наиболее развитые страны мира находятся на завершающей стадии индустриального этапа развития общества и перехода к следующему, информационному, этапу развития и построения "Информационного общества" (ИО). Широкое использование информационных технологий и современных средств доступа к информации открыло принципиально иные возможности построения более сбалансированного общества, с существенно большей реализацией индивидуальных возможностей его членов. "Информационное общество" несет в себе огромный потенциал для улучшения жизни граждан и повышения эффективности социального и экономического устройства государства. Стоящий перед Россией как и перед всем миром выбор прост: либо использовать преимущества зарождающегося ИО, сводя при этом к минимуму возможные потери, либо отдаться во власть революционной стихии, вызванной информационным кризисом.
Использование Internet/Intranet технологий при создании информационных ресурсов и построении информационных систем различного назначения в последнее время стало доминирующим в мировом информационном пространстве по следующим причинам [2]. Эти технологии:
· Позволяют организовать с достаточной простотой для пользователя системы поиска нужной информации.
· Предъявляют минимальные требования как с технической стороны так и со стороны программного обеспечения к рабочему месту клиента (клиент работает со стандартным программным обеспечением и единственным требованием является поддержка работы WWW просмотрщика -- браузера одной из последних версий1).
· Поддерживают распределенные системы хранения информации и множественные методы ее хранения.
· Поддерживают работу с практически неограниченным объемом разноплановых данных (текст, графика, изображение, звук, видео, векторные карты и др.).
· Предоставляют технологически простой способ администрирования информационных систем с одного рабочего места.
· Поддерживают удаленные методы редактирования и пополнения информации.
1 История вопроса
История создания компьютерных информационных систем насчитывает несколько десятилетий. За это время были созданы системы по автоматизации деятельности банков, статистических бюро, промышленных предприятий, контор, агентств по бронированию и продаже билетов и т.д. Однако бурная деятельность по созданию новых систем автоматизации не только не утихает, но и переживает в последнее время заметное оживление. Эта ситуация связана с все возрастающим значением систем обработки информации для выживания компаний в условиях высокой конкуренции, уменьшением удельной стоимости таких систем, с развитием технологий обработки и хранения информации, а также качественным изменением ситуации с развитием технологий передачи данных, в частности Internet.
Первые ИС создавались для больших ЭВМ и имели унитарную структуру, т.е. представляли собой по сути одну программу, включающую в себя все функции по хранению данных, их обработке и представлению, а также по контролю доступа к данным со стороны пользователей системы. Такая организация ИС имеет ряд достоинств. Это, в частности, централизованное хранение и обработка информации, простота администрирования системы, а также очень эффективное использование вычислительных ресурсов - для выполнения важных задач может быть выделена вся мощь вычислительной системы.
Однако обработка информации может быть осуществлена и на другой машине. Такой подход позволил создать на базе ПК и рабочих станций системы распределенной обработки информации. Первыми из этого класса систем стали системы, построенные по архитектуре файл-сервер. Основной особенностью этой архитектуры явился полный отказ от централизованных вычислений. Файл-сервер выполнял лишь функции хранения данных и не принимал участия в их обработке - эта работа была возложена на клиентские машины.
Однако очень скоро стало ясно, что полный отказ от централизованного контроля данных таит в себе ряд серьезных проблем. Проблемы эти состоят уже не в отказе отдельных компонентов системы, а в логике их совместной работы. Каждое из приложений, работающее с общими данными должно придерживаться ряда весьма жестких ограничений и соглашений, обеспечивающих целостность информации при ее модификации различными модулями системы. На контроль целостности данных приходилось весьма существенная доля программного кода системы, вычислительного ресурса клиентских машин и сетевого трафика, и, тем не менее, оставались проблемы, например сбой на клиентской машине в середине выполнения операции мог привести к рассогласованию данных.
Выходом из создавшейся ситуации стала разработка концепции клиент-серверных вычислений, сочетающей в себе преимущества централизованной обработки данных унитарных систем с преимуществами распределенных вычислений систем типа файл-сервер. Ключевым отличием архитектуры клиент-сервер от архитектуры файл-сервер является абстрагирование от внутреннего представления данных (физической схемы данных). Теперь клиентские программы манипулируют данными на уровне логической схемы. Они уже не заботятся о построении индексов для ускорения выборки данных, о распределении данных по файлам, выставлении семафоров на обрабатываемые записи и т.д.
Все рутинные функции по хранению, обработке и защите данных на так называемом физическом уровне берет на себя система управления базой данных (СУБД). Со времени своего появления СУБД также активно эволюционировали, предлагая различные модели логического представления данных (иерархические, сетевые, реляционные, объектно- ориентированные). Но суть дела от этого не меняется - программе, выполняющей бизнес-функции ИС, уже не надо заботится о том, как и где хранятся данные, следить за их достаточностью и непротиворечивостью, обеспечивать условия по безопасному совместному пользованию данными несколькими пользователями. Она лишь запрашивает СУБД о предоставлении требуемых данных.
Еще одним преимуществом использования СУБД и архитектуры клиент-сервер по сравнению с файл-серверным подходом явилась возможность использовать транзакционный механизм манипулирования данными. Этот сервис, предоставляемый сервером данных, позволяет объединять несколько действий по изменению данных в одну неделимую операцию (транзакцию). Использование транзакций обеспечивает надежную защиту информации от программно-аппаратных сбоев как на клиентской, так и на серверной части ИС.
Помимо улучшения работоспособности уже готовых программ, архитектура клиент-сервер существенно облегчает и процесс создания ИС. Как уже было отмечено, прикладному программисту теперь не надо отвлекаться от описания логики работы системы на проблемы хранения данных, индексации таблиц и т.п. Транзакционный механизм позволяет не заботится о порядке модификации данных внутри одной транзакции и о способах восстановления их первоначального состояния при обнаружении исключительных ситуаций. А это в свою очередь сильно расширяет возможности командной иерархической разработки проекта - программисту уже не нужно знать внутреннее устройство функций написанных другими людьми - он может просто пользоваться ими без риска отказа работоспособности уже отлаженных модулей. Кроме того, использование в прикладных программах логического уровня представления данных и использование стандартизованных механизмов запроса к СУБД позволило писать платформо-независимые программы клиентской части ИС.
Итак, использование архитектуры клиент-сервер позволило создавать надежные (в смысле целостности данных) многопользовательские ИС с распределенной базой данных (РБД), поддерживающие графический интерфейс пользователя (ГИП) на клиентских станциях, связанных коммуникационной сетью. Основной составной единицей таких систем стали РБД.
2 Основные принципы, правила построения и функционирования РБДРБД состоит из набора узлов, связанных коммуникационной сетью, основной задачей которой является передача данных без ошибок и искажения. Коммуникационная сеть является ядром информационной сети, обеспечивающим передачу и некоторые виды обработки данных.
Коммуникационной сети присущи следующие свойства:
· каждый узел — это полноценная СУБД сама по себе;
· узлы взаимодействуют между собой таким образом, что пользователь любого из них может получить доступ к любым данным в сети так, как будто они находятся на его собственном узле.
Каждый узел сам по себе является СУБД. Любой пользователь может выполнить операции над данными на своём локальном узле точно так же, как если бы этот узел вовсе не входил в распределённую систему. Распределённую систему баз данных можно рассматривать как партнёрство между отдельными локальными СУБД на отдельных локальных узлах.
Дадим следующее определение: распределенная база данных — это набор файлов (отношений), хранящихся в разных узлах информационной сети и логически связанных таким образом, чтобы составлять единую совокупность данных (связь может быть функциональной или через копии одного и того же файла) [3].
Распределенная база данных предполагает хранение и выполнение функций управления данными в нескольких узлах и передачу данных между этими узлами в процессе выполнения запросов. Разбиение данных в распределенной базе данных может достигаться путем хранения различных таблиц на разных компьютерах или даже хранения разных частей и фрагментов одной таблицы на разных компьютерах. Для пользователя (или прикладной программы) не должно иметь значения, каким образом распределены данные между компьютерами. Работать с распределенной базой данных, если она действительно распределенная, следует так же, как и с централизованной, т. е. размещение базы данных должно быть прозрачно.
Несмотря на то, что распределенная база данных состоит из нескольких локальных баз данных, у пользователя должна сохраняться иллюзия работы с централизованной базой данных, что вызывает потребность в использовании некоторого общего представления о данных — глобальной концептуальной схемы. Определение данных в такой концептуальной схеме должно быть аналогичным определению в централизованной базе данных.
Отличия начинаются, когда требуется хранить данные в нескольких узлах. Чтобы произвести разбиение данных, нужно секционировать таблицы глобальной схемы на фрагменты. Существует два типа секционирования: горизонтальное и вертикальное. При секционировании таблицы по строкам выполняется горизонтальное секционирование, при разбиении по столбцам — вертикальное.
Таким образом, архитектура распределенной СУБД должна содержать информацию о секционировании исходных таблиц базы данных, что предполагает создание дополнительного уровня — фрагментного.
Самый высший уровень архитектуры распределенной СУБД — это интерфейс прикладной программы и интерфейс процессора запросов.
Взгляд на базу данных отдельных пользователей представлен в архитектуре отдельным 1-м уровнем, что аналогично внешнему уровню в классической архитектуре СУБД.
Для реализации и объяснения распределенной природы базы данных выделяются два уровня: фрагментный (см. выше) и уровень распределенного представления. Последний показывает географическое распределение данных по рабочим станциям, расположение экземпляра каждого фрагмента.
1—4 уровни архитектуры распределенной СУБД относятся к сетевой СУБД.
Однако выделяют еще локальные СУБД, где определяют представление данных на каждой рабочей станции.
Каждый уровень поддерживает различные представления базы данных; каждый уровень взаимодействует только со смежными уровнями представления.
Для управления распределенной базой данных создается программный комплекс – система управления распределенной базой данных (СУРБД).
C. J. Date в 1987 году сформулировал один основной принцип и двенадцать правил, которым, по его мнению, должны следовать распределенные базы данных [4].
Основной принцип заключается в "прозрачности распределенности". С точки зрения пользователя информации распределенная БД не должна отличаться от локальной БД. Здесь имеется в виду пользователь, формулирующий запросы к базе данных и получающий результаты на своем экране (или принтере). Технология его работы не должна зависеть от того, в какой конкретной базе находятся нужные ему данные: в его локальной базе, в удаленной базе, все необходимые данные в одной и той же базе или в различных базах данных.
Фундаментальный принцип имеет следствием определённые дополнительные правила или цели. Таких целей всего двенадцать:
1. Локальная независимость. Узлы в распределённой системе должны быть независимы, или автономны. Локальная независимость означает, что все операции на узле контролируются этим узлом.
2. Отсутствие опоры на центральный узел. Локальная независимость предполагает, что все узлы в распределённой системе должны рассматриваться как равные. Поэтому не должно быть никаких обращений к «центральному» или «главному» узлу с целью получения некоторого централизованного сервиса.
Похожие работы
... баз данных других приложений (таких как xBase и Paradox), баз данных архитектуры клиент-сервер (таких как Microsoft SQL Server) или из электронных таблиц (например, Microsoft Excel или Lotus 1-2-3). Базы данных Access можно связывать с таблицами баз данных других типов (dBase, FoxPro, Paradox) форматированными файлами (такими, как текстовые файлы в формате ASCII и рабочие листы Excel) и с другими ...
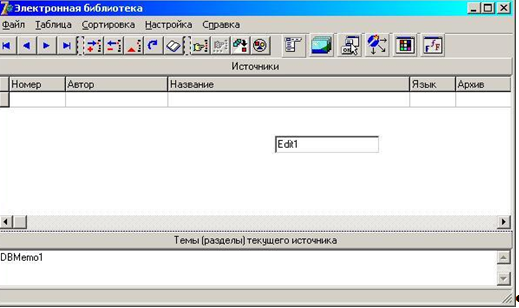
... , и на практике 5NF не используется. Заметим, что зависимость соединения является обобщением как многозначной зависимости, так и функциональной зависимости. 4. РАЗРАБОТКА БАЗЫ ДАННЫХ 4.1 Предметная область базы данных База данных предназначена для хранения информации об электронных источниках литературы в виде файлов, упакованных в архивы. Файлы архивов физически располагаются на сервере ...
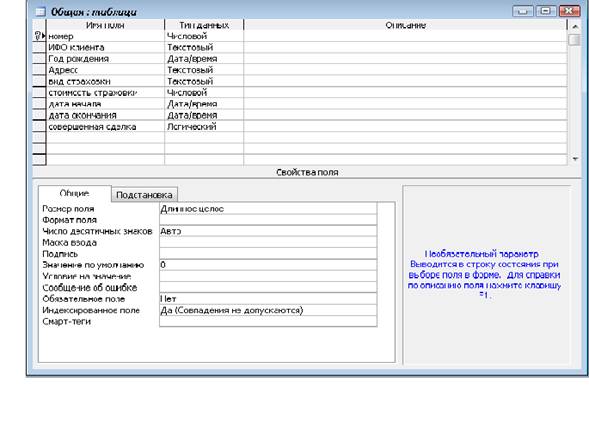
... проектирования БД. Основные понятия. Поскольку рассматриваемый подход к разработке реляционной модели базируется на формальной логике, то в его основе должны лежать некоторые фундаментальные формализации. В теории реляционных баз данных к ним относятся понятия атрибута, отношения, ключа и функциональной зависимости. Атрибутом будем называть поименованное свойство объекта и обозначать Аi , где ...
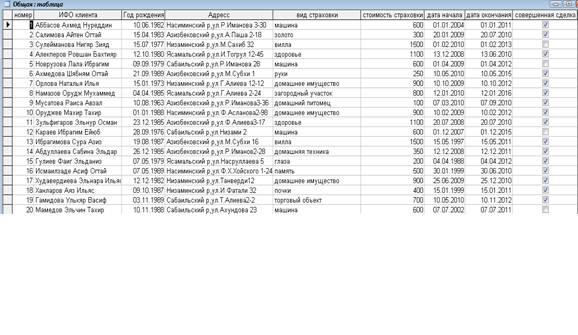
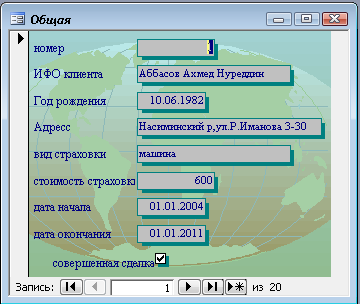
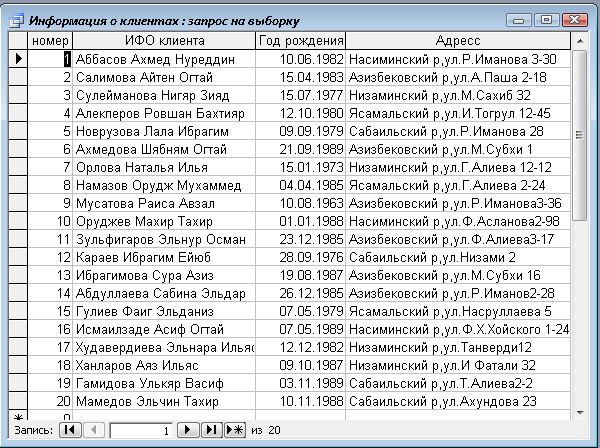
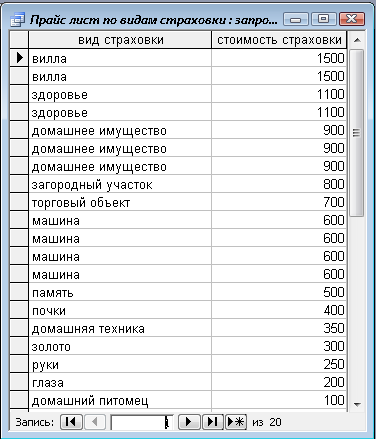
... экономии объёма используемой памяти. Нормализация – это разделение таблицы на две и более обладающие лучшими свойствами при включении изменений и удаление данных. страхование база данный ПРАКТИЧЕСКАЯ ЧАСТЬ Рассмотрим данные для создания базы данных на тему «Страхование населения». Создаем базу в реляционной модели базы данных. Описание данной задачи: «Руководство страховой компании заказало ...
0 комментариев