Навигация
1. Нечеткие знания
Обширной областью эффективного применения интеллектуальных систем как средства построения информационных систем нового поколения является область нечетких знаний. Это связано с тем, что во всех предметных областях существенное место занимают некорректные, нечетко формулируемые задачи и реальный человеческий способ рассуждения (опирающийся на естественный язык) не может быть описан в рамках традиционных математических формализмов, предполагающих однозначность интерпретации. Другими словами, знания чаще всего нечетки. «Для того, чтобы ИС вышли за рамки простых символьных выводов и приблизились к мышлению человека, необходимы методы представления нечетких знаний и механизмы выводов, работающие в их среде.» Исии. Возникла необходимость создания теории, позволяющей формально описывать нестрогие, нечеткие понятия и моделировать рассуждения, содержащие такие понятия.
Все недоопределённости в знаниях можно классифицировать следующим образом:
1) недетерминированность выводов,
2) многозначность,
3) ненадежность,
4) неполнота,
5) нечеткость или неточность. Именно этому классу уделяется внимание ниже.
1.1 Определение. Причины нечеткости знаний
Нечеткими называются такие знания, которые допускают суждения об относительной степени истинности или ложности.
Типы, источники, причины нечеткости знаний:
- присутствие неопределенности в фактическом знании,
- неточность языка представления знаний,
- знания, основанные на неполной информации,
- неопределенность, появляющаяся при агрегации (объединении в одну систему) знаний, полученных из разных источников и пр.
В последнее десятилетие всё больше внимания уделяется подходу, основанному на теории нечетких множеств. Эту теорию предложил ам. ученый Лофти Заде в 1965 году. Главная идея подхода Заде заключается в использовании для моделирования рассуждений нечеткой логики. Заде ввел одно из главных понятий в нечеткой логике – понятие лингвистической переменной.
Использование этого подхода позволяет построить «нечёткие» аналоги основных математических понятий и создать формальный аппарат для моделирования человеческого способа решения задач.
1.2 Нечёткая логика
Лингвистическая переменная (ЛП) – это переменная, значение которой определяется набором вербальных (словесных) характеристик некоторого свойства. Например, ЛП «рост» определяется набором {карликовый, низкий, средний…}.
В нечёткой логике степень истинности или степень ложности каждого нечеткого высказывания (или ЛП) принимает значения из отрезка от 0 до 1, причем 0 и 1 совпадают с понятиями ложь и истина для чётких высказываний. Степень истинности 0,7, например, это не вероятность в статистическом смысле, а некоторое произвольное субъективное значение.
Составные высказывания (как и в обычной логике высказываний) образуются из простых с помощью логических операций отрицания (не), конъюнкции (и), дизъюнкции (или), импликации /замещения/ ( ), эквиваленции ( ). Так степень истинности комбинации высказываний s1 и s2, имеющих соответственно степени истинности p1 и p2, в нечеткой логике может быть определена следующим образом.
Конъюнкция: высказывание s1 «И» s2 имеет истинность слайд
p = min (p1, p2).
Дизъюнкция: высказывание s1 «ИЛИ» s2 имеет истинность
p = max (p1, p2).
Отрицание: высказывание «НЕ» s1 имеет истинность
p = 1 - p1.
Импликация: s1 s2 можно представить логической формулой
(«НЕ» s1) “ИЛИ” s2,
то истинность импликации нечётких высказываний может быть определена как
p = max (1 - p1, p2).
Эквивалентность: s1 s2 можно представить логической формулой (s1 s2) “И” (s2 s1) или при нечётких высказываниях
p = min (max (1 - p1, p2), max (p1, 1 - p2)).
Здесь истина эквиваленции р = 1 при р1 = р2 = 0 и р1 =р2 = 1,
р = 0,5 при р1 = р2 = 0,5.
Л8.ПРИМЕР – нечеткая логика.
s1: Иванов – успешный студент, степень истинности р1 = 0,7,
s2: Петров – успешный студент, степень истинности р2 = 0,4.
1. Оба успешные студенты
И – конъюнкция р = мин (0.7, 0.4) = 0.4 – истинность решения.
2. s1 ИЛИ s2- дизъюнкция (кто-то из них успешный)
степень истинности р = мах (0.7, 0.4) = 0.7.
3. НЕ - s1 – отрицание (не Иванов)
степень истинности р = 1 – р1 = 1 – 0.7 = 0.3.
4. s1 s2 - Замещение – импликация
степень истинности р = мах (1 – 0.7, 0.4) = 0.4 или если р1 = 0,5, а р2 = 0.4, то
р = мах (1 – 0.5, 0.4) = 0.5.
5. s1 s2 - Эквиваленция - они равноценны степень истинности р = мин( мах( 1 – р1, р2), мах (р1, 1 – р2)) = мин( мах (1-0.7, 0.4), мах(0.7, 1-0.4)) = мин(0.4, 0.7) = 0.4.
1.3 Нечёткие множества
Нечёткое множество отличается от обычного множества тем, что относительно любых его элементов можно сделать не два, а три вывода:
1) элемент принадлежит данному множеству;
2) элемент не принадлежит данному множеству;
3) элемент принадлежит данному множеству со степенью уверенности ![]() (далее
(далее ![]() будем называть коэффициентом достоверности или принадлежности);
будем называть коэффициентом достоверности или принадлежности);
Очевидно, первые два случая соответствуют третьему при значениях коэффициента достоверности ![]() = 1 и
= 1 и ![]() = 0 соответственно. Таким образом, нечёткое множество определяется путем введения обобщенного понятия принадлежности.
= 0 соответственно. Таким образом, нечёткое множество определяется путем введения обобщенного понятия принадлежности.
Как определить и смоделировать следующее множество? «Когда мы говорим «старик», то не ясно, что мы имеем в виду: больше 50? больше 60? больше 70?». Подход, сформированный Заде, основывается на нижеприведённом представлении.
Пусть U полное множество, охватывающее всю проблемную область. Нечёткое (под) множество F множества U определяется через функцию принадлежности ![]() F(u) (u - элемент множества U). Эта функция отображает элементы u множества на множество чисел в отрезке
F(u) (u - элемент множества U). Эта функция отображает элементы u множества на множество чисел в отрезке ![]() , которые указывают степень принадлежности каждого элемента нечеткому множеству F.
, которые указывают степень принадлежности каждого элемента нечеткому множеству F.
Если полное множество U состоит из конечного числа множеств u1, u2, …, un, то нечёткое множество F можно представить в следующем виде:
F = ![]() F(u1)/u1 +
F(u1)/u1 + ![]() F(u2)/u2 + … +
F(u2)/u2 + … +![]() F(un)/un =
F(un)/un = ![]() F(ui)/ ui.
F(ui)/ ui.
*Знак + не есть сложение, а скорее обозначает совокупность элементов множества (знаменатель) с их принадлежностью (числитель). Знаки ![]() и
и ![]() имеют поэтому несколько отличный от традиционного смысл.
имеют поэтому несколько отличный от традиционного смысл.
Например, если полное множество – это множество людей в возрасте от 0 до 100 лет, то функция принадлежности нечётких множеств, означающих возраст «молодой», «средний», «старый» можно определить так, как на рис. 10.1.
При записи через 10 лет получим приблизительно следующее:
*Молодой = ![]() м (u) = 1/0 + 1/10 + 0,8/20 + 0,3/30.
м (u) = 1/0 + 1/10 + 0,8/20 + 0,3/30.
Средний = ![]() ср (u) = 0,5/30 + 1/40 +0,5/50.
ср (u) = 0,5/30 + 1/40 +0,5/50.
Старый = ![]() ст (u) = 0,4/50 + 0,8/60 + 1/70 + 1/80 + 1/90.
ст (u) = 0,4/50 + 0,8/60 + 1/70 + 1/80 + 1/90.
*Члены с коэффициентом принадлежности 0 не записываются.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() Понятия дополнение, объединение и пересечение множеств (по рис.).
Понятия дополнение, объединение и пересечение множеств (по рис.).
![]() м (u)
м (u) ![]() ср (u)
ср (u) ![]() ст (u)
ст (u)
![]()

![]()
![]()
![]()
![]()
![]() 1
1
![]() Молодой Средний Старый
Молодой Средний Старый
 | |||
![]() 0
0
0 10 20 30 40 50 60 70 80 90 u (возраст)
Рис. 10.1. Нечёткие множества и функции принадлежности категорий возраста.
Фаззификация (переход к нечеткости)Точные значения входных переменных преобразуются в значения лингвистических переменных посредством применения некоторых положений теории нечетких множеств, а именно - при помощи определенных функций принадлежности.
Рассмотрим этот этап подробнее. Прежде всего, введем понятие «лингвистической переменной» и «функции принадлежности».
Лингвистические переменныеВ нечеткой логике значения любой величины представляются не числами, а словами естественного языка и называются ТЕРМАМИ. Так, значением лингвистической переменной ДИСТАНЦИЯ являются термы ДАЛЕКО, БЛИЗКО и т. д.
Конечно, для реализации лингвистической переменной необходимо определить точные физические значения ее термов. Пусть, например, переменная ДИСТАНЦИЯ может принимать любое значение из диапазона от 0 до 60 метров. Как же нам поступить? Согласно положениям теории нечетких множеств, каждому значению расстояния из диапазона в 60 метров может быть поставлено в соответствие некоторое число, от нуля до единицы, которое определяет СТЕПЕНЬ ПРИНАДЛЕЖНОСТИ данного физического значения расстояния (допустим, 10 метров) к тому или иному терму лингвистической переменной ДИСТАНЦИЯ. В нашем случае расстоянию в 50 метров можно задать степень принадлежности к терму ДАЛЕКО, равную 0,85, а к терму БЛИЗКО - 0,15. Конкретное определение степени принадлежности возможно только при работе с экспертами. При обсуждении вопроса о термах лингвистической переменной интересно прикинуть, сколько всего термов в переменной необходимо для достаточно точного представления физической величины. В настоящее время сложилось мнение, что для большинства приложений достаточно 3-7 термов на каждую переменную. Минимальное значение числа термов вполне оправданно. Такое определение содержит два экстремальных значения (минимальное и максимальное) и среднее. Для большинства применений этого вполне достаточно. Что касается максимального количества термов, то оно не ограничено и зависит целиком от приложения и требуемой точности описания системы. Число же 7 обусловлено емкостью кратковременной памяти человека, в которой, по современным представлениям, может храниться до семи единиц информации.
В заключение дадим два совета, которые помогут в определении числа термов:
А) исходите из стоящей перед вами задачи и необходимой точности описания, помните, что для большинства приложений вполне достаточно трех термов в переменной;
Б) составляемые нечеткие правила функционирования системы должны быть понятны, вы не должны испытывать существенных трудностей при их разработке; в противном случае, если не хватает словарного запаса в термах, следует увеличить их число.
Фаззификация (переход к нечеткости)Точные значения входных переменных преобразуются в значения лингвистических переменных посредством применения некоторых положений теории нечетких множеств, а именно - при помощи определенных функций принадлежности.
Рассмотрим этот этап подробнее. Прежде всего, введем понятие «лингвистической переменной» и «функции принадлежности».
Лингвистические переменныеВ нечеткой логике значения любой величины представляются не числами, а словами естественного языка и называются ТЕРМАМИ. Так, значением лингвистической переменной ДИСТАНЦИЯ являются термы ДАЛЕКО, БЛИЗКО и т. д.
Конечно, для реализации лингвистической переменной необходимо определить точные физические значения ее термов. Пусть, например, переменная ДИСТАНЦИЯ может принимать любое значение из диапазона от 0 до 60 метров. Как же нам поступить? Согласно положениям теории нечетких множеств, каждому значению расстояния из диапазона в 60 метров может быть поставлено в соответствие некоторое число, от нуля до единицы, которое определяет СТЕПЕНЬ ПРИНАДЛЕЖНОСТИ данного физического значения расстояния (допустим, 10 метров) к тому или иному терму лингвистической переменной ДИСТАНЦИЯ. В нашем случае расстоянию в 50 метров можно задать степень принадлежности к терму ДАЛЕКО, равную 0,85, а к терму БЛИЗКО - 0,15. Конкретное определение степени принадлежности возможно только при работе с экспертами. При обсуждении вопроса о термах лингвистической переменной интересно прикинуть, сколько всего термов в переменной необходимо для достаточно точного представления физической величины. В настоящее время сложилось мнение, что для большинства приложений достаточно 3-7 термов на каждую переменную. Минимальное значение числа термов вполне оправданно. Такое определение содержит два экстремальных значения (минимальное и максимальное) и среднее. Для большинства применений этого вполне достаточно. Что касается максимального количества термов, то оно не ограничено и зависит целиком от приложения и требуемой точности описания системы. Число же 7 обусловлено емкостью кратковременной памяти человека, в которой, по современным представлениям, может храниться до семи единиц информации.
В заключение дадим два совета, которые помогут в определении числа термов:
n исходите из стоящей перед вами задачи и необходимой точности описания, помните, что для большинства приложений вполне достаточно трех термов в переменной;
n составляемые нечеткие правила функционирования системы должны быть понятны, вы не должны испытывать существенных трудностей при их разработке; в противном случае, если не хватает словарного запаса в термах, следует увеличить их число.
Функции принадлежностиКак уже говорилось, принадлежность каждого точного значения к одному из термов лингвистической переменной определяется посредством функции принадлежности. Ее вид может быть абсолютно произвольным. Сейчас сформировалось понятие о так называемых стандартных функциях принадлежности (см. рис. 3).
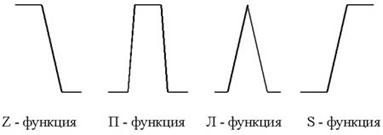
Стандартные функции принадлежности легко применимы к решению большинства задач. Однако если предстоит решать специфическую задачу, можно выбрать и более подходящую форму функции принадлежности, при этом можно добиться лучших результатов работы системы, чем при использовании функций стандартного вида.
Подведем некоторый итог этапа фаззификации и дадим некое подобие алгоритма по формализации задачи в терминах нечеткой логики.
Шаг 1. Для каждого терма взятой лингвистической переменной найти числовое значение или диапазон значений, наилучшим образом характеризующих данный терм. Так как это значение или значения являются «прототипом» нашего терма, то для них выбирается единичное значение функции принадлежности.
Шаг 2. После определения значений с единичной принадлежностью необходимо определить значение параметра с принадлежностью «0» к данному терму. Это значение может быть выбрано как значение с принадлежностью «1» к другому терму из числа определенных ранее.
Шаг 3. После определения экстремальных значений нужно определить промежуточные значения. Для них выбираются П- или Л-функции из числа стандартных функций принадлежности.
Шаг 4. Для значений, соответствующих экстремальным значениям параметра, выбираются S- или Z-функции принадлежности.
Если удалось подобным образом описать стоящую перед вами задачу, вы уже целиком погрузились в мир нечеткости. Теперь необходимо что-то, что поможет найти верный путь в этом лабиринте. Таким путеводителем вполне может стать база нечетких правил. О методах их составления мы поговорим ниже.
Разработка нечетких правилНа этом этапе определяются продукционные правила, связывающие лингвистические переменные. Совокупность таких правил описывает стратегию управления, применяемую в данной задаче.
Большинство нечетких систем используют продукционные правила для описания зависимостей между лингвистическими переменными. Типичное продукционное правило состоит из антецедента (часть ЕСЛИ …) и консеквента (часть ТО …). Антецедент может содержать более одной посылки. В этом случае они объединяются посредством логических связок И или ИЛИ.
Процесс вычисления нечеткого правила называется нечетким логическим выводом и подразделяется на два этапа: обобщение и заключение.
Пусть мы имеем следующее правило:
ЕСЛИ ДИСТАНЦИЯ=средняя И
УГОЛ=малый, ТО МОЩНОСТЬ=средняя.
Обратимся к примеру с контейнерным краном и рассмотрим ситуацию, когда расстояние до платформы равно 20 метрам, а угол отклонения контейнера на тросе крана равен четырем градусам. После фаззификации исходных данных получим, что степень принадлежности расстояния в 20 метров к терму СРЕДНЯЯ лингвистической переменной ДИСТАНЦИЯ равна 0,9, а степень принадлежности угла в 4 градуса к терму МАЛЫЙ лингвистической переменной УГОЛ равна 0,8.
На первом шаге логического вывода необходимо определить степень принадлежности всего антецедента правила. Для этого в нечеткой логике существуют два оператора: MIN(…) и MAX(…). Первый вычисляет минимальное значение степени принадлежности, а второй - максимальное значение. Когда применять тот или иной оператор, зависит от того, какой связкой соединены посылки в правиле. Если использована связка И, применяется оператор MIN(…). Если же посылки объединены связкой ИЛИ, необходимо применить оператор MAX(…). Ну а если в правиле всего одна посылка, операторы вовсе не нужны. Для нашего примера применим оператор MIN(…), так как использована связка И. Получим следующее:
MIN(0,9;0,8)=0,8.
Следовательно, степень принадлежности антецедента такого правила равна 0,8. Операция, описанная выше, отрабатывается для каждого правила в базе нечетких правил.
Следующим шагом является собственно вывод или заключение. Подобным же образом посредством операторов MIN/MAX вычисляется значение консеквента. Исходными данными служат вычисленные на предыдущем шаге значения степеней принадлежности антецедентов правил.
После выполнения всех шагов нечеткого вывода мы находим нечеткое значение управляющей переменной. Чтобы исполнительное устройство смогло отработать полученную команду, необходим этап управления, на котором мы избавляемся от нечеткости и который называется дефаззификацией.
Дефаззификация (устранение нечеткости)На этом этапе осуществляется переход от нечетких значений величин к определенным физическим параметрам, которые могут служить командами исполнительному устройству.
Результат нечеткого вывода, конечно же, будет нечетким. В примере с краном команда для электромотора крана будет представлена термом СРЕДНЯЯ (мощность), но для исполнительного устройства это ровно ничего не значит.
Для устранения нечеткости окончательного результата существует несколько методов. Рассмотрим некоторые из них. Аббревиатура, стоящая после названия метода, происходит от сокращения его английского эквивалента.
Метод центра максимума (СоМ)Так как результатом нечеткого логического вывода может быть несколько термов выходной переменной, то правило дефаззификации должно определить, какой из термов выбрать. Работа правила СоМ показана на рис. 4.
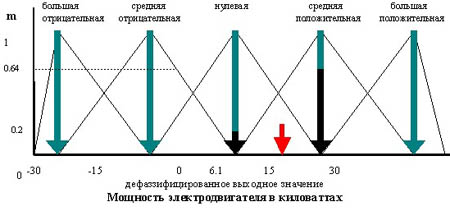
При использовании этого метода правило дефаззификации выбирает максимальное из полученных значений выходной переменной. Работа метода ясна из рис. 5.
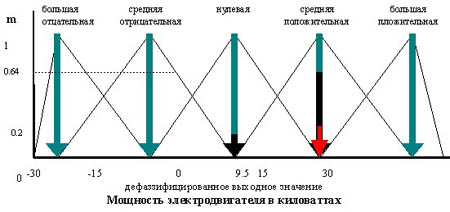
В этом методе окончательное значение определяется как проекция центра тяжести фигуры, ограниченной функциями принадлежности выходной переменной с допустимыми значениями. Работу правила можно видеть на рис. 6.
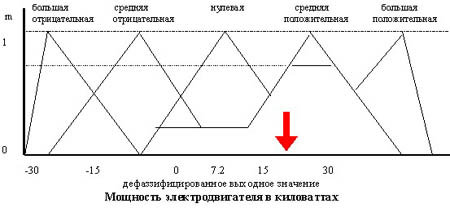
Применение: MYCIN, Fuzzy CLIPS, AM, HEARSAY-11, PROSPECTOR. «Экспертные системы»
В современном обществе при решении задач управления сложными многопараметрическими и сильно связанными системами, объектами и производственными и технологическими процессами приходится сталкиваться с решением неформализуемых и трудноформализуемых задач. Такие задачи часто возникают в следующих областях: авиация, космос и оборона, нефтеперерабатывающая промышленность и транспортировка нефтепродуктов, энергетика, металлургия, машиностроительная промышленность, медицина, прогнозирование и мониторинг и другие.
В начале 60-х годов в рамках исследований по искусственному интеллекту (ИИ) сформировалось самостоятельное направление - экспертные системы (ЭС). В задачу этого направления входит исследование и разработка программ (устройств), использующих знания и процедуры вывода для решения задач, ранее решавшихся только человеком-экспертом. Области применения ЭС включают широкий проблемный спектр от медицинской диагностики и определения курса лечения до систем управления различного рода, планирования и контроля процесса производства.
Экспертная система — система, объединяющая возможности компьютера со знаниями и опытом эксперта в такой форме, что система способна предложить разумный совет или осуществить разумное решение. Дополнительно желаемой характеристикой такой системы является способность пояснять ход своих рассуждений в понятной для человека форме.
Данное определение ЭС одобрено комитетом группы специалистов по экспертным системам Британского компьютерного общества.
Под экспертной системой понимают программу, которая, используя знания специалистов (экспертов) о некоторой конкретной узко специализированной предметной области и в пределах этой области, способна принять решение на уровне эксперта-профессионала.
Можно отметить двойственность толкования названия ЭС, т.к. во-первых, в них используется знания экспертов, а во-вторых, ЭС сами могут выступать в качестве экспертов.
Огромный интерес к экспертным системам со стороны пользователя вызван следующими причинами:
1. Специалисты, не знающие программирования, с помощью экспертных систем могут самостоятельно разрабатывать интересующие их приложения, что позволяет резко расширить сферу использования вычислительной техники.
2. Экспертные системы при решении практических задач достигают результатов, не уступающих, а иногда и превосходящих возможности людей экспертов, не оснащенных ЭС.
3. Решаемые экспертными системами задачи являются неформализованными и используют эвристические, экспериментальные, субъективные знания экспертов в определенной предметной области.
4. В экспертных системах знания отделены от данных, и мощность ЭС обусловлена в первую очередь мощностью базы знаний и только во вторую очередь используемыми методами решения задач.
Обычно к экспертным системам относят системы, основанные на знаниях, т.е. системы, функциональные возможности которых являются в первую очередь следствием их наращиваемой базы знаний (БЗ) и только во вторую очередь определяется используемыми методами принятия решения.
Правильное функционирование ЭС, как систем основанных на знаниях, зависит от качества и количества знаний, хранимых в их БЗ. Поэтому приобретение знаний для ЭС является очень важным процессом.
Приобретение (извлечение) знаний — получение информации о проблемной области различными способами, в том числе от специалистов, и выражение её на языке представления знаний с целью построения БЗ. Необходимо умело «скопировать» образ мышления эксперта.
Знания для ЭС могут быть получены из различных источников: книг, отчетов, баз данных, эмпирических правил, персонального опыта эксперта и т. п. Возможны 3 способа получения знаний от эксперта: протокольный анализ, интервью и игровая имитация профессиональной деятельности
Классификация экспертных систем
По назначению: экспертные системы общего назначения; специализированные: а) проблемно-ориентированные для задач диагностики, проектирования, прогнозирования; б) предметно-ориентированные для решения специфических задач, например, контроль ситуации на АЭС.
По степени зависимости от внешней среды:
-статические экспертные системы, не зависящие от внешней среды;
- динамические, учитывающие динамику внешней среды и предназначенные для решения задач в реальном времени.
По типу использования:
- изолированные экспертные системы;
- экспертные системы на входе/выходе других систем;
- гибридные экспертные системы, интегрированные с базами данных и другими программными средствами.
По сложности решаемых задач:
- простые экспертные системы, имеющие до 1000 простых правил;
- средние системы, имеющие от 1000 до 10000 правил;
- сложные, имеющие более 10000 правил.
По стадии создания:
- исследовательский образец, разработанный за 1-2 месяца с минимальной базой знаний;
- демонстрационный образец, разработанный за 3-4 месяца на языках LISP, PROLOG и др.;
- промышленный образец, разработанный за 4-8 месяцев с полной базой знаний на языках типа CLIPS;
- коммерческий образец, разработанный за 1,5 – 2 года на современных языках с полной базой знаний.
Области применения ЭС
В настоящее время ЭС используются при решении задач следующих типов:
· принятие решений в условиях неопределенности (неполноты) информации о внешнем мире,
· интерпретация символов и сигналов (например, системы оптического распознавания),
· прогнозирование (погоды, месторождений полезных ископаемых),
· диагностика (заболеваний, состояния технических устройств),
· конструирование (например, технических устройств), планирование (например, банковских операций),
· обучение,
· управление, контроль и др.
Функциональная структура экс пертной системы
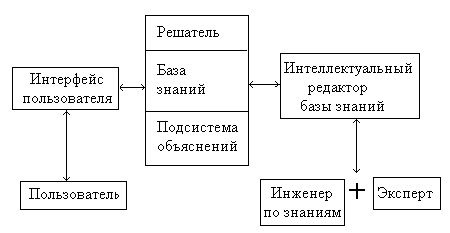
Рис. 13.1.Структура ЭС
*Типичная экспертная система состоит из следующих основных компонентов: модуля принятия решения (интерпретатора), БД, БЗ, пользовательского интерфейса.
Ввод входных данных и информации о текущей задаче – через пользователя.
База данных предназначена для хранения исходных и промежуточных данных, необходимых для решения текущей задачи. Термин база данных совпадает по названию, но не по значению с термином, используемым в информационно-поисковых системах и системах управления БД, где он обозначает список однотипных единиц информации.
Пример содержимого базы данных ЭС обработки детали на станке.
База знаний (БЗ) — совокупность описывающих предметную область правил и фактов, позволяющих с помощью механизма вывода выводить суждения в рамках этой предметной области, которые в явном виде в базе не присутствуют.
Решатель, используя информацию из БД и знания из БЗ, формирует такую последовательность правил, которые, будучи примененными к данным из БД, приводят к решению задачи. Этот модуль используется и на этапе обучения системы и на этапе проведения экспертизы. В начале обучения база знаний системы пуста. Используя данные из БД, решатель пытается выработать какое-то суждение. Поскольку в БЗ отсутствуют какие-либо правила, требуемые для решения задачи, суждение будет неверным, на что системе будет указано человеком-экспертом, а так же будет введен правильный ответ. Используя полученную от человека информацию (правильное суждение), решатель дополнит БЗ соответствующими правилами. Затем модуль принятия решений попытается вывести новое суждение. Если ответ, полученный системой в результате ее работы, является верным, модуль принятия решений еще раз подтвердит правила, участвовавшие в принятии ответа. Такой процесс обучения продолжается до тех пор, пока ЭС не начнет выводить только правильные суждения. К моменту проведения экспертизы база знаний уже заполнена при помощи модуля принятия решений необходимыми для решения поставленной задачи правилами. Применяя проверенные правила к данным из БД, модуль принятия решения выведет требуемое суждение.
Интерфейс пользователя предназначен для осуществления процесса взаимодействия между человеком-экспертом и экспертной системой. Он обеспечивает возможность высокоуровневого общения с ЭС, преобразуя входные данные, представленные на естественном языке, во внутреннее представление ЭС, а сообщения ЭС — в обратном направлении.
Таким образом, данные определяют объекты, их характеристики и значения, существующие в области экспертизы. Правила определяют способы преобразования данных, характерные для рассматриваемой проблемной области. Эксперт, используя интерфейс пользователя, наполняет систему знаниями, которые позволяют ЭС в режиме решения самостоятельно (без эксперта) решать задачи из проблемной области.
Режимы работы ЭС
Существует 2 режима работы ЭС: режим приобретения знаний и режим решения задач. В режиме приобретения знаний ЭС заполняется знаниями при помощи инженера по знаниям и эксперта в какой-то проблемной области. Эксперт описывает проблемную область в виде совокупности данных и правил, которые инженер по знаниям заносит в том или ином виде в базу знаний.
В режиме решения задач необходимо посредством интерфейса пользователя заполнить БД данными о задаче. При этом данные пользователя о задаче, представленные на привычном для пользователя языке, преобразуются во внутренний язык системы.
Итак, на основе входных данных из БД и данных и правил о проблемной области из БЗ модуль принятия решения выводит суждение, являющееся решением поставленной перед ЭС задачи. Если ответ ЭС не понятен пользователю, то он может потребовать объяснения, как этот ответ получен.
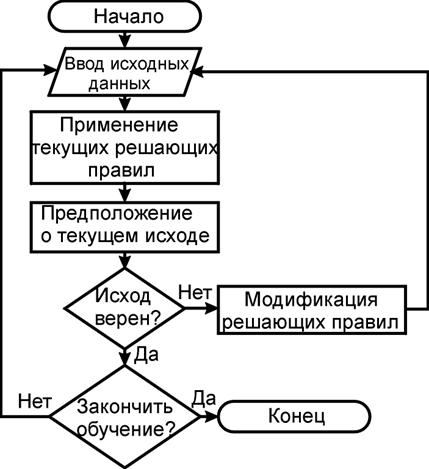
Рис. 13.2. Алгоритм работы ЭС в режиме обучения
Технология проектирования и разработки ЭС
Разработка ЭС имеет существенные отличия от разработки обычного программного продукта. Опыт создания ЭС показал, что использование при их разработке методологии, принятой в традиционном программировании, либо чрезмерно затягивает процесс создания ЭС, либо вообще приводит к отрицательному результату.
Создавать ЭС следует только тогда, когда разработка ЭС возможна, оправдана и методы инженерии знаний соответствуют решаемой задаче.
Чтобы разработка ЭС была возможной для данной проблемной области, необходимо одновременное выполнение, по крайней мере следующих требований:
1. К экспертам:
1. существуют эксперты в данной области, которые решают задачу значительно лучше, чем начинающие специалисты;
2. эксперты сходятся в оценке предлагаемого решения, иначе нельзя будет оценить качество разработанной ЭС;
3. эксперты способны вербализовать (выразить на естественном языке) и объяснить используемые ими методы, в противном случае трудно рассчитывать на то, что знания экспертов будут "извлечены" и вложены в ЭС;
4. решение задачи требует только рассуждений, а не действий;
5. Задача не должна быть слишком трудной (т.е. ее решение должно занимать у эксперта несколько часов или дней, а не недель);
6. Задача хотя и не должна быть выражена в формальном виде, но все же должна относиться к достаточно "понятной" и структурированной области, т.е. должны быть выделены основные понятия, отношения между ними и известные (хотя бы эксперту) способы получения решения задачи.
7. решение задачи не должно в значительной степени использовать «здравый смысл» (т.е.широкий спектр общих сведений о мире и о способе его функционирования, которые знает и умеет использовать любой нормальный человек), т.к. подобные знания пока не удается (в достаточном количестве) вложить в системы искусственного интеллекта.
Использование ЭС в данном приложении может быть возможно, но не оправдано. Применение ЭС может быть оправдано одним из следующих факторов:
1. решение задачи принесет значительный эффект, например экономический;
2. использование человека-эксперта невозможно либо из-за недостаточного количества экспертов, либо из-за необходимости выполнять экспертизу одновременно в различных местах;
3. использование ЭС целесообразно в тех случаях, когда при передаче информации эксперту происходит недопустимая потеря времени или информации;
4. использование ЭС целесообразно при необходимости решать задачу в окружении, враждебном для человека.
Приложение соответствует методам инженерии знаний, если решаемая задача обладает совокупностью следующих характеристик:
1) задача может быть решена посредством манипуляции с символами (т.е. с помощью символических рассуждений), а не манипуляций с числами, как принято в математических методах и в традиционном программировании;
2) задача должна иметь эвристическую, а не алгоритмическую природу, т.е. ее решение должно требовать применения эвристических правил. Задачи, которые могут быть гарантированно решены (с соблюдением заданных ограничений) с помощью некоторых формальных процедур, не подходят для применения ЭС;
3) задача должна быть достаточно сложна, чтобы оправдать затраты на разработку ЭС. Однако она не должна быть чрезмерно сложной (решение занимает у эксперта часы, а не недели), чтобы ЭС могла ее решать;
4) задача должна быть достаточно узкой, чтобы решаться методами ЭС, и практически значимой.
При разработке ЭС, как правило, используется концепция "быстрого прототипа". Смысл ее состоит в том, что разработчики не пытаются сразу построить конечный продукт. На начальном этапе они создают прототип (прототипы) ЭС. Прототипы должны удовлетворять двум противоречивым требованиям: с одной стороны, они должны решать типичные задачи конкретного приложения, а с другой - время и трудоемкость их разработки должны быть весьма незначительны, чтобы можно было максимально запараллелить процесс накопления и отладки знаний (осуществляемый экспертом) с процессом выбора (разработки) программных средств (осуществляемым инженером по знаниям и программистом). Для удовлетворения указанным требованиям, как правило, при создании прототипа используются разнообразные средства, ускоряющие процесс проектирования.
Прототип должен продемонстрировать пригодность методов инженерии знаний для данного приложения. В случае успеха эксперт с помощью инженера по знаниям расширяет знания прототипа о проблемной области. При неудаче может потребоваться разработка нового прототипа или разработчики могут прийти к выводу о непригодности методов ЭС для данного приложения. По мере увеличения знаний прототип может достигнуть такого состояния, когда он успешно решает все задачи данного приложения. Преобразование прототипа ЭС в конечный продукт обычно приводит к перепрограммированию ЭС на языках низкого уровня, обеспечивающих как увеличение быстродействия ЭС, так и уменьшение требуемой памяти. Трудоемкость и время создания ЭС в значительной степени зависят от типа используемого инструментария.
В ходе работ по созданию ЭС сложилась технология их разработки, включающая шесть следующих этапов (рис. 1.4):
идентификацию, концептуализацию, формализацию, выполнение, тестирование, опытную эксплуатацию. На этапе идентификации определяются задачи, которые подлежат решению, выявляются цели разработки, определяются эксперты и типы пользователей.
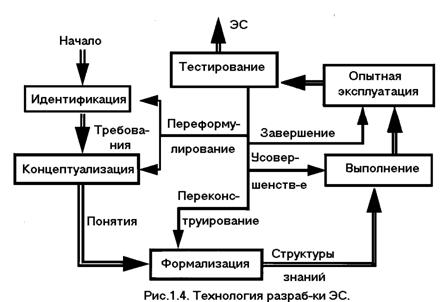
На этапе концептуализации проводится содержательный анализ проблемной области, выявляются используемые понятия и их взаимосвязи, определяются методы решения задач.
На этапе формализации выбираются ИС и определяются способы представления всех видов знаний, формализуются основные понятия, определяются способы интерпретации знаний, моделируется работа системы, оценивается адекватность целям системы зафиксированных понятий, методов решений, средств представления и манипулирования знаниями.
На этапе выполнения осуществляется наполнение экспертом базы знаний. В связи с тем, что основой ЭС являются знания, данный этап является наиболее важным и наиболее трудоемким этапом разработки ЭС. Процесс приобретения знаний разделяют на извлечение знаний из эксперта, организацию знаний, обеспечивающую эффективную работу системы, и представление знаний в виде, понятном ЭС. Процесс приобретения знаний осуществляется инженером по знаниям на основе анализа деятельности эксперта по решению реальных задач.
Трудности при разработке экспертных систем
Разработка ЭС связана с определенными трудностями, к числу которых можно отнести следующие:
1. Проблема извлечения знаний экспертов.Ни один специалист никогда просто так не откроет секреты своего профессионального мастерства, свои сокровенные знания в профессиональной области. Он должен быть заинтересован материально или морально. Часто такой специалист опасается, что раскрыв свои секреты, он будет не нужен компании. Вместо него будет работать экспертная система. Необходимо выбирать высококвалифицированного специалиста, заинтересованного в сотрудничестве.
2. Проблема формализации знаний экспертов. Эксперты-специалисты в определенной области, как правило, не в состоянии формализовать свои знания. Часто они принимают правильные решения на интуитивном уровне и не могут аргументировано объяснить, почему принято то или иное решение. Иногда эксперты не могут прийти к взаимопониманию. В таких ситуациях поможет выбор эксперта, умеющего ясно формулировать свои мысли и легко объяснять другим свои идеи.
3. Проблема нехватки времени у экспертов. Выбранный для разработки эксперт не может найти достаточно времени для выполнения проекта. Чтобы избежать такой ситуации, необходимо получить от эксперта, прежде чем начнется проект, согласие тратить на проект время в определенном фиксированном объеме.
4. Правила, формализованные экспертом, не дают требуемой точности. Проблему можно избежать, если решать вместе с экспертом реальные задачи. Эксперт, как правило, легче понимает правила, записанные на языке, близком к естественному.
5. Недостаток ресурсов. В качестве ресурсов выступают персонал (инженеры знаний, разработчики инструментальных средств, эксперты) и средства построения ЭС (средства разработки и средства поддержки). Удвоение персонала не сокращает время разработки наполовину, т.к. процесс создания ЭС – это процесс со множеством обратных связей.
6. Неадекватность инструментальных средств решаемой задаче. Часто определенные типы знаний (например, временные или пространственные) не могут быть легко представлены на одном ЯПЗ, так же как и разные схемы представления (например, фреймы и продукции) не могут быть достаточно эффективно реализованы на одном ЯПЗ. Некоторые задачи могут быть непригодными для решения по технологии ЭС (например, отдельные задачи по анализу сцен). Необходим тщательный анализ решаемых задач, чтобы определить пригодность предлагаемых инструментальных средств и сделать правильный выбор.
Методология построения экспертных систем. Рассмотрим методику формализации экспертных знаний на примере создания экспертных диагностических систем. Целью создания таких систем является определение состояния объекта диагностирования (ОД) и имеющихся в нем неисправностей.
Состояниями ОД могут быть: исправно, неисправно, работоспособно. Неисправностями, например, радиоэлектронных ОД являются: обрыв связи, замыкание проводников, неправильное функционирование элементов и т.п. Число неисправностей может быть велико. В ОД могут быть одновременно несколько неисправностей.
Разные неисправности ОД проявляются во внешней среде информационными параметрами. Совокупность значений информационных параметров определяет «информационный образ» (ИО) неисправности ОД. ИО может быть полным, т.е. содержать всю необходимую информацию для постановки диагноза, или, соответственно, неполным. В последнем случае постановка диагноза носит вероятностный характер.
Основой для построения эффективных экспертных диагностических систем являются знания эксперта для постановки диагноза, записанные в виде информационных образов, и система представления знаний, встраиваемая в информационные системы обеспечения функционирования и контроля ОД, интегрируемые с соответствующей технической аппаратурой.
Для описания своих знаний эксперт с помощью инженера по знаниям должен выполнить следующее.
1.Выделить множество всех неисправностей ОД, которые должна различать система.
2. Выделить множество информативных (существенных) параметров, значения которых позволяют различить каждую неисправность ОД и поставить диагноз с некоторой вероятностью.
3.Для выбранных параметров следует выделить информативные значения или информативные диапазоны значений, которые могут быть как количественными, так и качественными. Например, точные количественные значения могут быть записаны: задержка 25 нсек, задержка 30 нсек и т. Д. Количественный диапазон значений может быть записан: задержка 25-49 нсек, 40-50 нсек, 50 нсек и выше. Качественный диапазон значений может быть записан: индикаторная лампа светится ярко, светится слабо, не светится. Для более удобного дальнейшего использования диапазон значений может быть закодирован.
4. Процедура создания полных или неполных ИО каждой неисправности в алфавите значений информационных параметров может быть определена следующим образом. Составляются диагностические правила, определяющие вероятный диагноз на основе различных сочетаний диапазонов значений выбранных параметров ОД. Правила могут быть записаны в различной форме. Механизм записи последовательности проведения тестовых процедур в виде правил реализуется, например, следующим образом:
ЕСЛИ: Р» = 1
ТО: таст = Т1, Т3, Т7,
Где Т1, Т3, Т7 – тестовые процедуры, подаваемые на ОД при активизации (срабатывании) соответствующей продукции. В ЭС приоритет отдается прежде всего знаниям и опыту, а лишь затем логическому выводу.
Оболочки ЭС
К настоящему времени ЭС стали одной из серьезных отраслей информационной индустрии. Программное обеспечение в этой области быстро расширяется. При создании первых ЭС было отмечено, что механизм логического вывода и язык представления знаний могут быть отделены от конкретных знаний и использованы в различных проблемных областях. "Пустые" проблемно-независимые ЭС с незаполненной базой знаний называются оболочками ЭС.
Внутренние средства оболочки ЭС обеспечивают манипуляцию знаниями, генерацию объяснений, а также сервис разработки и отладки базы знаний. Для создания прикладной ЭС пользователь должен написать свою собственную базу знаний, используя предлагаемый оболочкой язык представления знаний.
Несмотря на обилие оболочек ЭС — CxPERT, Exsys, GoldWorks, Guru, KDS3, KnowledgePro, Nexpert, Rule Master, VP Expert — можно выделить ограниченное число методов построения механизмов вывода ЭС: применение правил продукций, использование механизма исчисления предикатов, символьная обработка знаний, представленных в текстовой форме, использование вероятностного подхода к обработке знаний.
Вывод заключения может быть произведен экспертной системой двумя способами:
· Прямой ход — определяются все входные данные и на их основании выводится заключение.
· Обратный ход — выбирается гипотеза и проверяются на истинность ее признаки. Если они истинны, то верна и гипотеза, если нет — проверяется следующая гипотеза.
Применение ЭС на основе нейронных сетей
За рубежом интерес к нейронным сетям стремительно растет. На нейронной технологии в сочетании с использованием проводящих полимеров основано устройство распознавания запахов, разработанное совместно фирмами Neotronics и Neoral Technologies. Системы на основе одного из типов нейронной сети осуществляют контроль за энергоустановками в некоторых городах США. Сеть РАРNЕТ после пробного рассмотрения нескольких тысяч образцов определяет пораженные раком клетки быстрее и точнее, чем это делает лаборант. "Гибридная" система анализа данных Clementine, разработанная ISL, применяется банком Чейз Манхэттен (Chase Manhattan Bank) для изучения вкусов и склонностей части своей клиентуры. Датский институт мясной промышленности приспособил нейронную сеть для анализа качества свинины. Фирма АЕА Technology разработала на основе нейронной сети средство определения идентичности подписи.
Опыт показал, что применение нейронных сетей оправданно там, где закономерности не изучены, а входные данные избыточны, иногда противоречивы и засорены случайной информацией.
Языки представления знаний
Стремление к эффективной программной реализации моделей представления знаний привело к разработке большого числа языков представления знаний от простых, предназначенных для решения отдельных специальных задач, до мощных универсальных.
Общими свойствами ЯПЗ высокого уровня являются следующие;
- наличие средств описания типов данных и процедур управления более сложных, чем в универсальных языках программирования;
- наличие встроенных механизмов представления поиска и обработки информации;
- наличие средств построения дедуктивных алгоритмов.
ЯПЗ условно можно разделить на три группы:
1.Языки обработки символьной информации. Характерными представителями этой группы являются LISP, РЕФАЛ, SNOBOL.
2.Языки, ориентированные на поиск решения в пространстве состояний и доказательства теорем. К ним относятся, например, PLANNER,QLISP.
3.Языки, представления знаний общего назначения. Характерными представителями являются KRL, FRL.
Наиболее распространенным языком обработки символьной информации является LISP. Основными единицами информации в этом языке являются атомы и списки. Атом – любая последовательность алфавитно-цифровых символов и специальных знаков, заключенных между ограничениями. Атомы могут использоваться для представления имен, отношений, действий, свойств, переменных, а также для представления синтаксических признаков, семантических маркеров.
Список – это упорядоченная совокупность элементов, в качестве которых могут выступать либо атомы, либо другие списки. Под выражением в LISP понимается либо атом, либо список. Выражение (6, 8, SPM, B) представляет собой список из четырех элементов, каждый из которых является атомом; выражение (PUT (NHE PEN) (IN (THE TABLE))) – список из трех элементов. Первый элемент – атом, второй – список из двух атомов, третий – двухэлементный список со вторым элементом в виде списка.
В LISP есть аппарат интерпретации списков, называемый вычислением. Первый элемент интерпретируется как имя функции, остальная часть рассматривается как множество аргументов функции. Примеры: Список (PLUS 2 4) вырабатывает значение 6 = 2 + 4. Список (TIMES 9 3 ) вырабатывает значение 27=9х3. LISP имеет целый ряд встроенных стандартных функций, но может строить и вводить свои функции.
Для присвоения значения переменной используется функция SETQ. Например, (SETQ R 4) переменная R получает значение 4. Для обработки списков в LISP используется ряд элементарных функций, таких, как CAR, CDR, CONS и др.
Литература
1 – Тугенгольд А.К., Рубанчик В.Б. Искусственный интеллект в машиностроительных технологических системах: Учеб. пособие. Ростов-на-Дону, Изд. центр ДГТУ, 1996. – 140 с.
2 – Базы знаний интеллектуальных систем/ Т.А. Гаврилова, В.Ф. Хорошевский – СПб. Питер, 2000. – 384 с.
3 – Статические и динамические экспертные системы: Учеб. Пособие / Э.В. Попов и др. – М.: Финансы и статистика, 1996. – 320 с.
4 - Фу К., Гонсалес Р., Ли К. Робототехника. – М.: Мир, 1989. – 624 с.
5 – Накано Э. Введение в робототехнику. - М.: Мир, 1988. – 334 с.
6. Робототехника и гибкие автоматизированные производства. Кн. 6. Техническая имитация интеллекта. Назаретов В.М., Ким Д.П. Высшая школа, 1986. – 144 с.
7. Интеллектуальные робототехнические системы. Уч. пособие. В.Л. Афонин, В.А. Макушин. Москва, 2005. Интернет университет информационных технологий. – 208 с.
8. Введение в мехатронику. Кн.2.
Похожие работы
... структуры. PROSPECTOR — экспертная система, созданная для содействия поиску коммерчески оправданных месторождений полезных ископаемых. 2. Перспективы и тенденции развития AI Сообщения об уникальных достижениях специалистов в области искусственного интеллекта (ИИ), суливших невиданные возможности, пропали со страниц научно-популярных изданий много лет назад. Эйфория, связанная с первыми ...
... создать эффективные программы в распознавании образов, в классификационных задачах и в обучении ЭВМ. Лингвопсихология Лингвопсихология является еще одной наукой, задействованной в процессе лингвистического обеспечения искусственной интеллекта. Данный термин образован по образцу многих уже устоявшихся терминов. Так, психолингвистика – исследование предмета лингвистики методами психологии (в ...
... математически, что есть проблемы, решаемые человеческим интеллектом, которые принципиально недоступны ЭВМ. Эти взгляды высказываются как кибернетиками, так и философами. Проблема искусственного интеллекта Гносеологический анализ проблемы искусственного интеллекта вскрывает роль таких познавательных орудий, как категории, специфическая семиотическая система, логические структуры, ранее накопленное ...
... начнет думать как человек. Ничего подобного не произошло. Стало ясно, что никакого мышления, аналогичного человеческому, сходу построить не получится. Поэтому акценты сместились в сторону создания искусственного интеллекта – т.е. машинным решением «трудных» задач, которые человек решает, а машина пока нет. Таким образом, первоначально ИИ не претендовал на прямое моделирование мышления, а был ...
0 комментариев