Навигация
Использование WWW-Технологии для создания образовательных ресурсов
22582
знака
0
таблиц
0
изображений
3. Использование WWW-Технологии для создания образовательных ресурсов
Использование сети Интернет как инфраструктуры информационного обмена для образовательного процесса в высшей школе имеет широкие перспективы. С одной стороны сеть может обеспечить недорогую оперативную связь между преподавателем и студентом, находящимися в географически удаленных точках, создавая базу для развития дистанционного обучения, а с другой -- позволяет передавать и воспроизводить с помощью WWW-технологии на абонентских точках сети учебно-методические материалы в форме, удобной для восприятия.
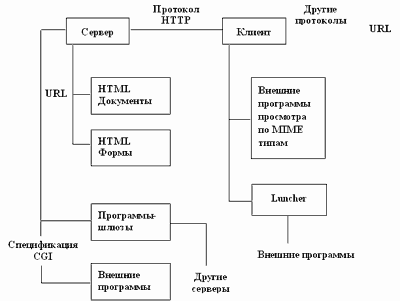
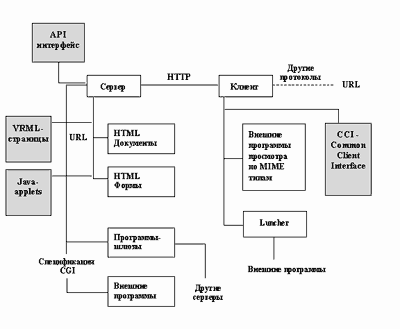
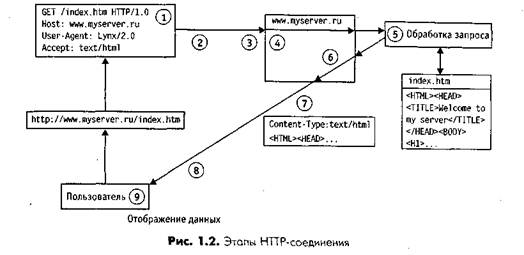
WWW-технология, широко используемая в сети Интернет, позволяет хранить информацию в распределенной гипертекстовой форме с включением графических иллюстраций, видео и аудио фрагментов. Фрагменты гипертекста могут размещаться на разных компьютерах, на которых должно быть установлено программное обеспечение, поддерживающее фрагмент как ресурс в сети. Такие ресурсы называются WWW-серверами.
Фрагменты гипертекста связаны между собой посредством гиперссылок. Пользователь, работая с клиентским программным обеспечением, может легко переходить от одного фрагмента к другому, перемещаясь по гиперссылкам и не заботясь о том, на каком из WWW-серверов находится требуемый фрагмент.
Совокупность фрагментов гипертекста, находящуюся на всех WWW-серверах сети Интернет называют гиперпространством.
Установка WWW-серверов учреждениями высшей школы и перевод перевод наработанных учебно-методических материалов в гипертекстовую форму приведут к возникновению в сети гиперпространства образовательных ресурсов( ГОР). Успешное развитие образовательных ресурсов в состоянии решить проблему эффективного переиспользования наработанных учебно-методических материалов по всем специальностям в масштабах высшей школы страны в целом, что должно резко повысить качество образовательного процесса во всех учреждениях высшей школы.
Для этого необходимо решить ряд организационных и технических задач. Рассмотрим одну из важнейших технических задач -- сокращение издержек в ГОР. Издержки определяются двумя взаимосвязанными величинами: затратами времени пользователя на получение информации и загрузкой сети при выполнении транзакций по поиску и доставке информации.
Следует отметить, что задача сокращения издержек на получение информации актуальна и для всего гиперпространства в целом, поэтому применительно к образовательным ресурсам предлагается решать ее с помощью апробированных методов, а именно за счет оптимизации структуры ГОР.
Такую оптимизацию целесообразно проводить на двух уровнях:
- всего ГОР в целом,
- отдельных WWW-серверов.
На уровне ГОР предлагается создать службу, позволяющую проводить распределенный поиск учебно-методических материалов на образовательных WWW-серверах по ряду критериев, например, по номеру специальности и названию дисциплины, для которых предназначен тот или иной учебно-методический материал. Это в свою очередь накладывает определенные требования на оформление WWW-серверов как образовательных ресурсов.
Поэтому на уровне WWW-серверов необходимо разработать рекомендации по их оформлению, которые бы гарантировали работоспособность глобальной поисковой службы и минимизировали издержки на получение информации в рамках одного фрагмента. Рекомендации должны быть обеспечены программными средствами, облегчающими создание WWW-серверов, а также средствами, позволяющими в автоматическом режиме проводить проверку WWW-серверов на соответствие данным рекомендациям.
Для сокращения издержек на получение информации на уровне WWW-серверов рекомендации должны учитывать следующие требования:
- конструкции языка HTML, используемые при создании гипертекста, должны обеспечивать получение информации для пользователей, применяющих разное клиентское программное обеспечение,
- предоставляемая информация не должна в общем случае зависеть от возможности получения иллюстраций, видео и аудио фрагментов;
- размер иллюстраций, видео и аудио фрагментов должен учитывать среднюю пропускную способность каналов передачи информации;
- WWW-сервер должен содержать оглавление разделов и список ключевых слов с указанием страниц, на которых эти слова встречаются;
- на WWW-сервере должна быть обеспечена возможность поиска информации по словам, задаваемым пользователем.
4. Всемирная паутинаНесмотря на то, что в первые годы своего существования Gopher завоевал большую популярность, назревала нужда в какой – то более простой и в то же время максимально универсальной системе, в которой связи между ресурсами были бы более свободными и ассоциативными. Такая система была разработана в 1993 г. и названа WWW. Система WWW строится на понятии гипертекстом, или, точнее, гипермедиа. Гипертекст – это текст, составные части которого связаны друг с другом и с друг и с другими текстами с помощью ссылок. Гипермедиа – это то, что получится из гипертекста, если заменить в его определении слово «текст» на выражение «любые виды информации». WWW означает буквально «всемирная паутина». WWW позволяет не отказываться от информационных ресурсов уже накопленных в Internet, доступных с помощью других средств: FTP, Telnet и Gopher. Больше того, работа с этими ресурсами через WWW настолько удобна, что FTP клиенты, бывшие когда - то отдельным классом программ, теперь используются лишь немногим.
И все - таки главное в WWW – это не удобства доступа FTP архиву и Gopher меню. Большинство серверов системы предлагают информацию, которая без WWW вряд ли вообще когда – либо попала бы в сеть. Быстрота создания и обновления, богатые изобразительные возможности в сочетании с легкостью доступа и огромной аудиторией сделала WWW новым средством массовой информации. С другой стороны, быстрому распространению системы, столь естественно объединяющий разнородные ресурсы, способствовало не в последнюю очередь ее зарождение не в недрах коммерческой фирмы, а в научном учреждении – Европейской лаборатории физики частиц, сотрудники которой не стали делать секретов из своей разработки и даже не попытались на ней разбогатеть. К счастью, сама природа WWW как средства поиска и организации информации позволяет надеяться, что это изобретение не превратится в инструмент одной лишь коммерции и рекламы. Серверы и клиенты WWW связываются между собой по протоколу НТТР. URL для WWW выглядит так http://<адрес сервера>.
Поисковые инструменты первого типа чаще всего называются предметными, или тематическими каталогами. Компания, владеющая таким каталогом, непрерывно ведет огромную работу, исследуя, описывая, каталогизируя и раскладывая по полочкам содержимое WWW серверов и других сетевых ресурсов, разбросанных по всему миру. Результатом ее титанических усилий является постоянно обновляющийся иерархический каталог. На верхнем уровне каталога собраны самые общие категории, такие как «бизнес», «наука» и др. Элементы самого нижнего уровня представляют собой ссылки на отдельные WWW страницы вместе с кратким описанием их содержимого. Гарантий того, что такой каталог действительно охватывает все содержимое WWW, никто не даст, однако возможная неполнота и даже однобокость подбора материалов с лихвой искупается тем, что пока еще не под силу никакому компьютеру – осмысленность отбора.
Предметные каталоги представляют и возможность поиска по ключевым словам. Однако поиск этот происходит не в содержимом самих WWW серверов, а их кратких описаниях, хранящихся в каталоге. Предметные каталоги Internetа можно пересчитать буквально на пальцах, так как их создание и поддержка требуют огромных затрат. К наиболее известным относятся Yahoo, WWW Virtual Library, Galaxy и некоторые другие.
Одно из самых известных систем такого рода – каталог Magellan. Эта база данных содержит сведенья о 80 тыс. WWW страниц, что очень немного в сравнении с теми миллионами, которые существуют в сети. Однако если Yahoo в качестве описания ресурса использует одну – две строчки текста, то сотрудники системы Magellan на некоторые из страниц, заносимые в их базу данных, сами пишут небольшие рецензии, а также оценивают качество этих информационных ресурсов по пятибалльной шкале. Помимо базы рецензии, Magellan владеет также собственным автоматическим индексом, для поиска в котором нужно перебросить переключатель под полем ввода в положение entire database. Как правило, запрос представляет собой одно или несколько ключевых слов, разделенных пробелом.
Похожая по своим принципам служба фирмы Point вообще основной упор делает не на поиск, а на работу с тематическим каталогом. Служба Point известна в сети тем, что ее сотрудники постоянно заняты оцениванием сетевых ресурсов и ведут списки тех узлов, которые как они считают, принадлежат к «лучшим пяти процентам WWW».
Сама фирма Point ведет общедоступную базу данных всех «пятипроцентных» WWW страниц, где о каждом можно прочитать подробную лицензию. Самым старым предметным каталога WWW является каталог Virtual Library. Эта система достаточно полно охватывает научную прослойку WWW серверы университетов, лабораторий и учебных заведений.
Для пользователей в нашей стране определенный интерес может представлять тематический каталог Russia – on- line Subject Guide. Этот каталог содержит довольно пестрое собрание ссылок на зарубежные источники плюс тематический обзор российских и русскоязычных ресурсов WWW.
К проблеме поиска информации в Internet можно подойти и с другой стороны. Существуют программы, в которые загрузили несколько тысяч общеизвестных программ, в которые загрузили несколько тысяч общеизвестных URL адресов. Будучи запущена на компьютере с доступом к WWW, эта программа начинает автоматически скачивать из сети документы по этим URL, причем из каждого нового документа она извлекает все содержащиеся в нем ссылки и добавляет их в свою базу адресов. Поскольку все WWW документы связаны между собой, рано или поздно такая программа обойдет весь Internet. Разумеется, программа не может ни понять, ни как – либо классифицировать то, что она видит в сети. Программы такого типа называются роботами. Они ограничиваются сбором статической информации и построением слов – указателей (индексов) по текстам документов. Собираемая роботом база данных – индекс – хранит в себе сведения о том, в каких WWW документах содержатся те или иные слова. Именно такой автоматически собираемый индекс и лежит в основном поисковых систем второго типа, которые часто так и называют – Автоматические индексы. Автоматический индекс состоит из трех частей: программы – роботы, собираемой этим роботом базы данных и интерфейса для поиска в этой базе, с которым работает пользователь. Все эти компоненты вполне могут функционировать без вмешательства человека. Поскольку какая – либо классификация или оценивание материалов в системах такого рода отсутствует, к ним следует прибегать только тогда, когда вы точно знаете ключевые слова, относящиеся к тому, что вам нужно, например фамилию человека или несколько достаточно редких терминов из соответствующей области.
Если же задать по сколько – нибудь распространенным словам, то вам не хватит жизни, чтобы обойти все полученное в результате прииска URL адреса. Например, индекс системы Alta Vista содержит 11 млрд. слов, извлеченных из 30 млн. WWW страниц. Автоматических индексов WWW страниц существует немало: WebCrawler, Lycos, Excite, Inktomi, Open Text и др. Некоторые из них (например, Lycos) представляют собой более или менее удачливый синтез предметного каталога и автоматического индекса.
Одним из мощных поисковых средств в World Wide Web является система Hot Bot, содержащая сведения о полных текстах 110 млн. страниц. Адрес: http://www. Hotbot.com. Hotbot принадлежит к новейшим системам, поэтому его углубленный поиск дает поразительно широкие возможности для детализации запроса. Это достигается за счет использования многоступенчатого меню, предполагающего различные варианты составления поискового предписания. Можно осуществить поиск по наличию в документе одного или нескольких терминов, поиск по определенной фазе, поиск конкретного лица или ссылки на определенный электронный адрес.
Заключение всемирная паутина интернет сеть Сделаем вывод, что ключевыми аспектами WWW-технологии являются: протокол HTTP, язык HTML и информационно-поисковые системы (AltaVista, HotBot, Lycos, Yahoo и др.). Индексирование Web-сайтов. Типовые информационно-поисковые языки как средство проведения поиска информации в Web. Построение сложных поисковых запросов. Коррекция запросов по релевантности отклика. Средства электронного поиска в FTP-архивах (поисковая машина Archie, национальные поисковые системы и Web-шлюзы). Информационные ресурсы Internet, доступные по протоколу Telnet. Русскоязычные ресурсы Сети. Проблема кодировок. Поисковые машины, специализирующиеся в поиске информации на кириллице. Элементы векторного стандарта - Flash.
Трудно себе представить человека XXI века без Internet, с его появлением есть возможность быстро и удобно найти необходимую информацию. Теперь можно не заниматься подбором и изучением огромного количества литературы в книжных магазинах и библиотеках. Нужную для себя информацию можно получить, не выходя из дома или офиса.
Благодаря разнообразию поисковых систем, специально разработанных для рядового пользователя, каждый может без труда отсечь заведомо ненужный поток информации, лишь правильно сформулировав цель поиска.
Список используемой литературы
1. Меженный О.А. «Microsoft Windows Vista, краткое руководство» - М.: ООО «И.Д.Вильямс», 2007 г.
2. Волков А.К. «Моя первая книга об информационных технологиях» - М.: Эксмо, 2007 г.
3. http://www.internet-history.org
4. http://www.internet-history.org
5. Сапков В.В. «Информационные технологии и компьютеризация делопроизводства» - М.: Издательский центр «Академия» 2008 г.
Похожие работы
... gopher-сервер еще работает, то в одном из файлов на нем указан адрес Web-узла, на который перенесена информация. 2.2 Интерфейс Web-приложений при работе в сети Internet Гипертекстовая информационная система World Wide Web (WWW) и ее технологии на сегодняшний день наиболее значительны в Сети и продолжают свой подъем. По своей навигационной картине WWW фактически скопировала Gopher-ресурсы, но ...





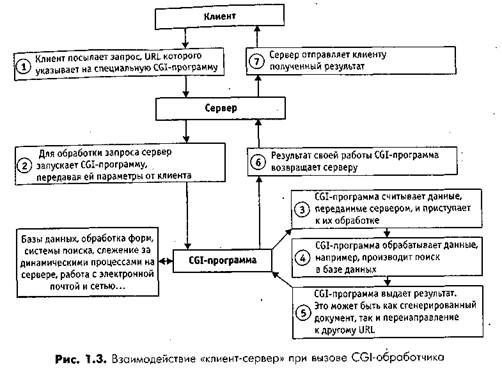
... . Прочие программы—это программы, принимающие данные от сервера и выполняющие какие-либо действия: получение текущей даты, реализацию графических ссылок, доступ к локальным базам данных или просто расчеты. 2.2 Интернет как предмет и средство маркетинга 2.2.1 Интернет и бизнес Сейчас компьютерная сеть такое же обычное дело как копировальный аппарат, факс, телефон и сам компьютер. Заниматься ...
... четкого разделения требуемых функций во избежание излишней сложности и создания структуры, которая может подстраиваться под нужды конкретного пользователя, оставаясь в рамках стандарта. 1.2 Принципы организации сети Интернет Трудно определить, где конкретно расположена Internet. Аппаратное обеспечение, поддерживающее Internet, состоит из компьютеров в сетях и кабелей между ними. Поэтому ...
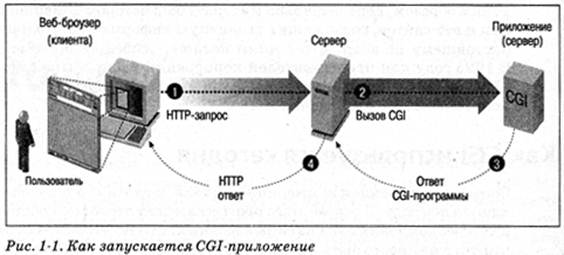
... не зависимый от языка способ создания кода и привязки его к запросам Web-страниц, — .NET Web Forms — управляемую событиями программную модель взаимодействия с элементами управления. Она делает программирование Web-страниц аналогичным программированию форм Visual Basic. ASP.NET содержит развитые средства управления сеансами и функции защиты. Она надежнее, и производительность ее значительно выше ...
0 комментариев