Системный анализ и проект
Конспект - черновой (лекторский) вариант, в некоторых разделах носит характер иллюстративной поддержки
Существуют две очень близкие точки зрения на то, что есть СА –
Первая - это механизм раскрытия неопределенностей и формализации решения любой проблемы – эта точка зрения работает, как источник новых научных направлений, выросших из системного анализа - таких как "Исследование операций", "Теория графов", "Сеттевое планирование" и прочее, прочее, прочее.
Вторая – это более общий вгляд, обобщение проблемы (задачи ) моделирования . Как следствие - понадобилась формализация этого более общего вгляда на моделирование – как на процесс исследования объекта и всех связанных с этим исследованием идей, проблем, вопросов, - что-бы
1.-структурировать последовательность решения задач при моделировании
2.-выделить общие механизмы в различных задачах моделирования и
3.-разработать специальные подходы в особо интересных для практики задачах
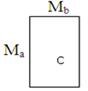
Результат структуризации вопросов связанных с моделированием может быть представлен, как упорядоченный перечень задач, процедур которые стоят между неформальной постановкой проблемы и окончательным математическим ее решением .
Сказанное можно итожить в виде таблицы задач, связанных с моделированием , таким образом:
Структура задач процесса моделирования
наиб просто - это задачи Анализа - и - Синтеза:
Анализ-Синтез = ![]() Анализ Объекта- Синтез Модели - Анализ Модели =
Анализ Объекта- Синтез Модели - Анализ Модели = ![]()
= Декомпозиция Объекта - ПричинноСледственный Анализ - Синтез Модели - Анализ Модели
таблица 1
|
1.Декомпозиция объекта |
2.Прич.Следств.Анал. |
3. Синтез модели |
4.Анализ модели |
Содержание каждого раздела таблицы мы рассм позже - сейчас общая х-ка
1-вый раздел - это вопросы декомпозиции (умозрительного расчленения) анализа и исследования объекта и его струкуры непосредственно имея дело с объектом и в результате чего мы должны получить
1.- моделеобразующие гипотезы об объекте и приближенное укрупненное представление о его структуре
2.- определится с структурными кирпичиками изучаемой системы (переменные состояния, управления,если оно имеется, шумами в системе)
3. Получить возможные характеристики и наборы экспериментальных данных которые мы в дисциплине "Статистическое моделирование" считаем заранее предоставленными в виде таблиц или матриц ОБЪЕКТ-СВОЙСТВА.
Однако после решения задач 1-го раздела еще невозможно приступать к собственно моделированию. Мы об этом говорили ранее, когда отмечали недостатки методологии статистического моделирования, которое моделирует лишь исходя из факта силы связи но никак не анализирует направления связи между предполагаемыми входными и выходными переменными. Предварительный причинно-следстенный анализ даст ответ какие переменные имеют право оказатся в правых частях моделируемых соотношений типа у=f(x)
итак
2-й раздел посвящен решению вопросов ПСА - методам определения направления ПСС ![]() ,
,![]() во всех парах доступных переменных (процессах)
во всех парах доступных переменных (процессах) ![]()
![]()
![]()
![]() . дающим возможность приступить к задачам непосредственно моделирования (3-ий столбец-раздел задач). Кроме того мы рассмотрим и применение ПСА непосредственно к решению некоторых задач моделирования и классификации (мед диагностики)
. дающим возможность приступить к задачам непосредственно моделирования (3-ий столбец-раздел задач). Кроме того мы рассмотрим и применение ПСА непосредственно к решению некоторых задач моделирования и классификации (мед диагностики)
- составление матриц ПСС и сравнение их в классах
к курсовому - пост2 - признаки процессы.
3-й раздел - собственно различные задачи моделирования свойств, объектов и систем. Здесь 3 подраздела - моделирование свойств данных, моднлирование систем и моделирование взаимодействия систем. Мы здесь рассмотрим современные подходы к моделированию экспериментальным данным и некоторые новые методы решения задач классификации и диагностики в усложненной постановке - для объектов заданных множеством измерений
(коротко суть проблемы)
А. Технология для детерминированной постановки:
- объекты заданы подматрицами объект-свойства Х,Y. Построив структуру у=f(a1х1,a2х2,...,amхm) - переходим для классификации в пространство параметров a1,a2,...,am
В. Технологии для задачи классификации объектов, характеризующихся процессами (реализациями процессов)
Для процессов, описывающих объекты классификации, могут быть характерны
1. Детерминированные по времени составляющие
2. Детерминированные по запаздываниям составляющие (детерминированные по структуре и параметрам автокорреляционных и взаимокорреляционных составляющих)
3.Случайные составляющие
4. Взаимные статистические причинно-следственные связи между процессами.
Тогда возможно использовать для формирования пространства параметров классификации следующие технологии
В1). Детерминированный случай =параметризация составляющей процесса/ов сводится к п.А
пример.- разгонные х-ки двигателей w=F(а,t) при подаче 220в на двигатель
В2.) Построение автокорреляционных моделей для каждого процесса и перевод задачи классификации в пространство параметров этих автокорреляционных моделей (а1 1,а1 2...а1 к1, а2 1,а2 2,...а2 к2, ..., аm 1,am 2,...,amkm)
В3) Построение взаимокорреляционных моделей для моделирования ведущего/их процесса/ов объектов и перевод задачи классификации в пространство параметров этих моделей
В4 ) Вычисление случайных составляющих процессов и определение их распределений = маргинальных и совместных распределений и их параметров
в4.1)- Дополнителные признаки - параметры маргинальных и совм распределений
в4.2) - Классификация по распределениям параметров распределений (маргинальных и совместных) случайных составляющих исходных процессов -типа класс метод (макс правдоподобия) для распределений параметров распределений (так как для каждого объекта имеем целые распределения - поэтому далее получаем для множества объектов -- распределения параметров распределений)
В5 ) Определение матриц статистических причинно-следственных связей (ПСА) и классификация объектов по мере близости этих матриц в классах
раздел-столбец 4 таблицы- изучение основных свойств полученных моделей с тем, что-бы убедится в ее адекватности нашим ожиданиям
Мы вернемся еще к рассмотрению задач разделов табл. 1.
Пока же начнем с сердца системного анализа - собственно моделирования, и моделирования по экспериментальным данным. Это графа 3 таблицы - здесь рассмотрим задачи параметрического и структурно-параметрического синтеза для решения задачи построения многомерной регрессии данных
МОДЕЛИРОВАНИЕ
Современное моделирование (в том числе аналитическое) принято отслеживать от группы ученых связанных с Ньютоном, создавшего теорию бесконечно малых – Теорию Диференциального и Интегрального исчисления. Это удивительное прозрение практически впервые породило аналит ические математические модели в точности соотв-щие реальным физическим процессам.
Он выдвинул гениальную по простоте и адекватности идею что значительное количество физических моделей макромира увязывают в своих взаимоотношениях линейные перемещения с их скоростями,ускорениями и тд и создал строгий аппарат обращения с данными величинами и уравнениями связвывающими эти величины.
С помощью этого аппарата была решена грандиозная задача - задача моделирования движения тел небесной механики.
Паралельно эта задача породила к жизни сопутствующие направления исследований - теорию вероятности (ЛАГРАНЖ, МУАВР, БАЙЕС).
Конечно ТВ имеет свои родные корни, связанные с изучением случайности, но вычислительные, практические аспекты ТВ стимулировала родственная «небесной механике» задачка из теории измерений. Именно ниже указанная задача стала первой сформулированной задачей статистического моделирования.
Надо было наиболее точно определить начальные условия для реш задачи Неб Мех – то есть определить наиболее точное положение звезд на небосклоне по неоднократным их измерениям..
Таким образом в 1800-тых годах - Лаплас, Гаусс и Лежандр, каждый из которых в то время работал над теорией движения небесных тел и не мог обойти проблемы теории измерений предложили свои варианты решения такой задачи. Сначала о Лапласе.
Лапласом было предложено оценивать неизвестное значение измеряемой величины ![]() по его повторным измерениям
по его повторным измерениям ![]() как такую величину
как такую величину ![]() , которая обеспечивает минимум ф-лу
, которая обеспечивает минимум ф-лу 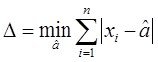 (*)
(*)
Оказалось, что такое значение ![]() соответствует нахождению выборочной эмпирической медианы - то есть такому числу
соответствует нахождению выборочной эмпирической медианы - то есть такому числу ![]()
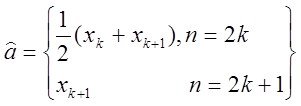 , справа и слева от которого находится одинаковое количество измерений.
, справа и слева от которого находится одинаковое количество измерений.
Позже, было показано что задача минимизации суммы модулей отклонений решаеться линейным программированием. О ЛП?
Но в то время ученому сообществу более простой и технологичной показалась идея двух других французов –Гаусса и Лежандра которые для тех же условий задачи предложили минимизировать ф-нал
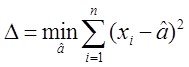 (**)
(**)
и предложили технологию Метода Наименьших Квадратов которую мы в общих чертах уже представляем.
Ниже немного обобщим взгляд на эту технологию моделирования
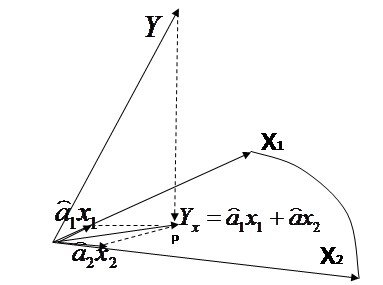
Задачи моделирования по экпериментальным данным
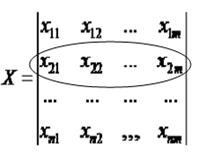
Исх.данные задачи моделивания - , здесь
, здесь 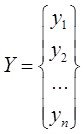 – вектор выхода, Х1,….,Хm – входы¸ m= кол. перем., n-кол точек данных
– вектор выхода, Х1,….,Хm – входы¸ m= кол. перем., n-кол точек данных  - матрица значений входных переменных
- матрица значений входных переменных
Модель в самом общем виде предполагем вида ![]()
Делаем шаг упрощения задачи – предполагаем наличие в структуре переменных быстрых - х и медленных - а , то есть
![]() и назовем медленые переменые
и назовем медленые переменые
а – параметрами модели
При моделировании выделяют две задачи
– параметрический и структурный синтез модели ![]()
То есть необходимо найти структуру![]() и параметры модели
и параметры модели ![]() .
.
Однако на практике применяються несколько другие две задачи:
1.расчета вектора коэфф ![]() при заданной структуре модели
при заданной структуре модели ![]() и
и
2. более практическая задача, когда ищем и структуру ![]() и параметры модели
и параметры модели![]()
По поводу различных структур –
Пример – какие ниже стуктуры одинаковые а какие разные
1. у = з-х+х3 2. у= 3х-х2 3.у= 3+х2+х3 4. у=3х-х3
При фиксированой структуре эффективность найденных параметров модели ![]() оценивают по разному
оценивают по разному
– один из вариантов - функционалом
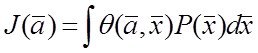 или
или 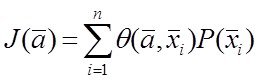 (*)
(*)
где ![]() - функция адекватности модели , а
- функция адекватности модели , а ![]() - плотность распределения.
- плотность распределения.
С адекватностью понятно –в дискретном случае это может быть “обьясненная дисперсия”, коэфф детерминации (мах) или отн. норм.среднекв.ошибка (мин)
Ну а причем здесь плотность распределения ![]() – а?
– а?
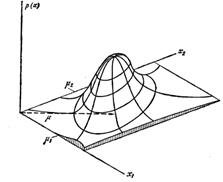
![]() играет роль весовых коэффициентов в ф-ле, учитывающих частоту попадания объекта в точку i (облaсть i ).
играет роль весовых коэффициентов в ф-ле, учитывающих частоту попадания объекта в точку i (облaсть i ).
Обычно для построения ![]()
-(обращаю внимание на то, что
![]() - вектор и
- вектор и ![]() - многомерная плотность)
- многомерная плотность)
нужно очень много данных,
Когда же мы имеем такую роскошную
возможность иметь столько данных? –
когда имеем длинный сигнал (временной ряд) ,например, в медицинских приборах, и вообще работа в реале с накоплением данных об объекте.

Если наша задача – построить прогнозирующий фильтр (прогнозирующую модель)– тогда для Р(х) учитывают данные всей доступной кривой, а прогнозирующую модель расчитывают используя ограниченный скользящий участок методами стохастической аппроксимации, - то есть взвешивая невязки в соответствие с плотностью.
Когда нет доступа к такому большому количествку данных то
чаще обходятся без ![]() , считая в (*), что
, считая в (*), что ![]() неизвестна, вернее принимая
неизвестна, вернее принимая ![]() , считая все слагаемые равноправными таким образом принимая что плотность равномерна.
, считая все слагаемые равноправными таким образом принимая что плотность равномерна.
Если теперь функционал качества задачи моделирования выбрать в виде суммы квадратичных. невязок
J (а)=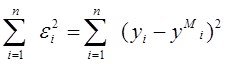 и при виде моделии
и при виде моделии 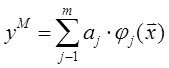
придем к для поиска параметров а к обычному механизму МНК
Но будем помнить что принцип взвешивания невязок в МНК – важное ответвление РА (называемое взвешенный МНК), и используется он в задачах моделирования при непрерывном поступлении новых данных в систему – это моделироваие сигналов, временных рядов под. которые необходимо подстроить их модели для дальнейшей обработки - например для прогноза ряда, или очистки сигнала от шума и т.д.
Вернемся к обычному МНК
Задача параметрического синтеза
Постановку задачи для поиска коэффициентов по методу наименьших квадратов (МНК) при фиксированной структуре модели:
 Задана матрица значений аргументов
Задана матрица значений аргументов
(**) и вектор выхода 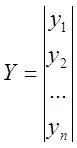 ,
,
1.Введем предположеие – достаточно сильное и тем неприятное - – предположим что модель линейна по параметрам
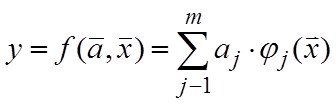
Предположение вводится в основном потому что мы умеем решать такие задачи, а не потому что это как то обосновано, Здесь есть нечто общее с тем что « будем искать потеряное под.фонарем, потому что там видно а не потому что там потеряли».
2 Наконец предполагаем что нам известна структура 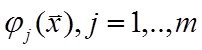 то есть сейчас мы занимаемся задачей параметрического синтеза
то есть сейчас мы занимаемся задачей параметрического синтеза
Если тепер, как мы говорили выше, функционал качества задачи моделирования выбрать в виде сумм квадратичных. невязок
J(у) =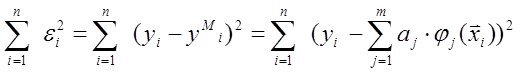 (**)
(**)
то для определения вектора параметров![]() достаточно решить систему линейных уравнений
достаточно решить систему линейных уравнений 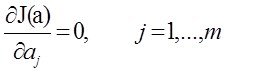 (*О*)
(*О*)
Действительно вспомним условия экстремума функций, тогда понятно откуда получена система (*О *)
Обратим внимание что систему получим линейную отностельно аj
Все достаточно просто.Решая эту систему получаем наилучший вектор парамеров а который дает минимум функционалу (**)
Таким образом решается задача параметрического синтеза.
Для частного случая одномерной регресии У=ах+в, его решение МНК можно получить как простые формулы для ![]() , где
, где ![]() - коэффициент регрессии,
- коэффициент регрессии, 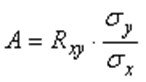 ,
, 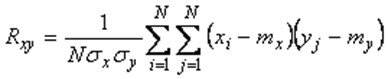 -коэффициент корреляции х,у,
-коэффициент корреляции х,у,
![]() и
и ![]() ,
,![]() выборочные среднеквадратические отклонения и выборочные математические ожидания случайных величин
выборочные среднеквадратические отклонения и выборочные математические ожидания случайных величин ![]() и
и ![]()
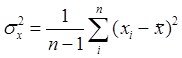 ,
, 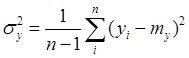 ,
, 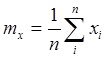 ,
, 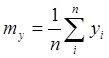
№2
Но если регрессия не одномерная, то никто в наше время в расчетах не записывает функционал в скалярном виде, не берут производные , не составляют системы скалярных уравнений и тд. Для решения задачи поиска параметров регрессии пользуются матричные представления данных и операций. Я пользовался выше скалярной записью, только затем, что-бы в начале было проще показать смысл процедур поиска параметров.
 Упрощенный вывод формулы МНК в матричном виде
Упрощенный вывод формулы МНК в матричном виде
Напомним
1.–Для умножения матриц А и В – А*В=С
–то есть получения элемента ![]() необходимо взять в А (первой матрице) j-тую строку
необходимо взять в А (первой матрице) j-тую строку ![]() и в В (второй матрице) k-тый столбец
и в В (второй матрице) k-тый столбец ![]() и образовать скаляное поизведение
и образовать скаляное поизведение 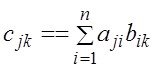 .
.
 2. Траспонирование
2. Траспонирование
– столбцы делает строками, строки столбцами
(в квадратной матрице – просто зеркально отображаем относительно гл диагонали)
 3.Обратная матрица А-1 матрицы А это такая матрица для которой выполняется А-1*А=Е, где
3.Обратная матрица А-1 матрицы А это такая матрица для которой выполняется А-1*А=Е, где  единичная матрица
единичная матрица
Итак имеем матрицу Х и вектор выхода У
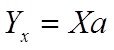 необходимо построить модель линейной структуры
необходимо построить модель линейной структуры
Уже понимаем почему пишем Ха а не аХ
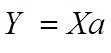 При этом необходимо максимально приблизить с помощью вектора а матричное соотношение (***)
При этом необходимо максимально приблизить с помощью вектора а матричное соотношение (***)
В скалярном виде это соответствует наилучшему приближению
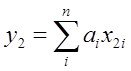 в первой точке
в первой точке 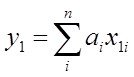
………… в n-ой точке - 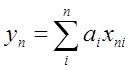 (***)
(***)
Далее будем исходить из (***) как из равенства и будем из него искать а. Более обосновано вывод проведем немного позже. Итак имеем
![]() Для того что-бы освободить а (умножить то что при а на обратную Х матрицу и получить в результате Е – ед матрицу ) надо чтобы при а стояла квадратная матрица.
Для того что-бы освободить а (умножить то что при а на обратную Х матрицу и получить в результате Е – ед матрицу ) надо чтобы при а стояла квадратная матрица.
Умножим слева и справа на ХТ получим Теперь поскольку ХТХ – квадратная – можем ее умножить на обратную -
слева и справа на (Х ХТ)-1
и окончательно имеем для а
![]() и для модели
и для модели
Все - И все расчеты проводятся по этой формуле
- в любых инжененых пакетах реализованы матричные операции -
все очень просто (мы поработаем на практике) и
не очень просто в связи с операцией взятия обратной матрицы и понятием плохой обусловленности матрицы.
Что это - плохая обусловленность матрицы:
напомним о так наз. собственных числах матрицы
/А-лЕ/=0 ......для опред Л - решаем степенное уравнение соответствующего порядка напомним на примере 2-го порядка
ПлОбМа возникает когда λmin << λmax.
и численно мера ПОМ выражается их отношением
или близостью к нулю ее детерминанта -
Этот эффект ПОМ обычно набл когда в А одновременно присутствуют очень большие и очень малые числа - тогда при операции нахождения обратной матрицы обусловленность резко ухудшается (очень малые числа деляться на очень большие) и лавинообразно растет погрешность (изза выхода значущих цифр за пределы разрядной сетки ВМ)- решение теряется в эффекте ПлОбМа
Это одна из причин что РА только начинается а не заканчивается на формуле для а. Преодоление ПОМ - различные олгоритмя регуляризаци матрицы А ......желательно с минимальной потерей ее эквивалентности
Другие проблемы больше связаны с задачей структурного синтеза - об этом позже А пока более строгий вывод, который
повторяет логику, изложенную для скалярного вида:
Пусть размерность задачи m перем и n точек
Критерий по которому работает МНК: минимировать сумму квадратов ошибок еi=Уi-(ао+а1х1i+…+аmxmi) модели У=ао+а1х1+…+аmxm в заданных точках. В матричном виде, модель У=Ха должна минимизировать критерий в матричной форме:
![]()
Дифференцируя эту функцию по вектору параметров и приравняв производные к нулю, получим систему уравнений (в матр. форме)
![]() , отсюда
, отсюда ![]() (** ) и далее решая (**) можем найти вектор а=(хтх)-1хту
(** ) и далее решая (**) можем найти вектор а=(хтх)-1хту
В расшифрованном матричном виде эта система уравнений имеет вид
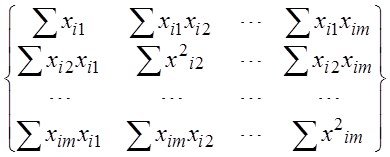
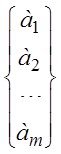 =
=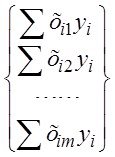 X и XTX - осн
X и XTX - осн
Где все суммы берутся по количеству точек ![]()
Если в модель включен свободный член то ![]() для всех
для всех ![]() i
i
Это и есть т.н. нормальная система уравнений Xи XTX- осн зол матр мод
Решение этой системы и дает общую формулу МНК-оценок
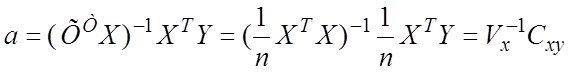
X и XTX- основные золотые матр мод -матрица объект-свойства и информационная матрица Фишера (при центр Х - ковар матрица)
И так с расчетов параметров на первый взгляд все просто (на самом деле проблема есть с обращением матриц,)
А вот со структурно-параметрическим синтезом так просто не получается
Для понимания в каких условиях и почему классические шаговые алгоритмы многомерной регрессии, к сожалению, не дают ожидаемых наилучших результатов моделирования при структурно-парам. Синтезе. Нам полезно
1. рассмотреть геометрические интерпретации МНК и
2. привести некоторые свойства метода МНК и регрессионных моделей
1 что такое обусл М 2 почему она плоха
Геометрические интерпретации МНК или почему регрессия не алгебра (более корректно -почему регрессионные. уравнения не алгебраические уравнения).Детский вопрос –
если в алгебре из ![]()
![]()
![]()
![]()
![]()
то почему в регрессионных уравнениях из ![]() ,
, ![]()
не следует что ![]() и
и ![]() ?
?
А имеем мы (у вас эти ф-лы есть)
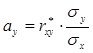 ,
, ![]() и
и
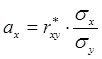
![]() где
где ![]() - выборочный коэффициент корреляции
- выборочный коэффициент корреляции
( 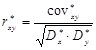 - оцен зн. коэфф корр. ур совпадут при одинаковом расбросе
- оцен зн. коэфф корр. ур совпадут при одинаковом расбросе ![]() - это так потому что просто первая формула представит график в осях у-х а вторая х-у )
- это так потому что просто первая формула представит график в осях у-х а вторая х-у )
Для того что бы не формально понять эти результаты (и для других целей) полезны геометрические интерпретации регрессии.
…………..
Напомним, что нам известно
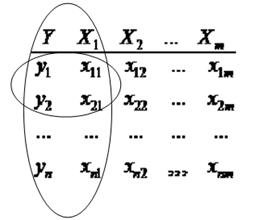
Любая задача моделированмя по экспериментальным данным начинается с данных – таблицы результатов эксперимента или таблицы наблюдений –
здесь m= кол.перем., n-кол точек данных
Итак, матрица данных имеет m столбцов и nстрок, соответственно
геометрическую интерпретацию регресии можно получить
в пространстве столбцов или
в пространстве строк
= или что то же самое
в пространстве переменных (оси –переменные) или
в пространстве точек. (оси - номера точек)
Интерпретация в пространстве переменных (столбцов)
 Рассмотрим случай одномерной регрессии – имеем только столбцы У и Х1
Рассмотрим случай одномерной регрессии – имеем только столбцы У и Х1
Идея регрессии пришла в математику из теории вероятности. ТВ по сути дала следующее
определение уравнению регресии: регрессия это
матожидание условной вероятности
![]() (1)
(1)
или с учетом,что у нас есть только конечная выборка ![]() , то
, то ![]() ( 2)
( 2)
Теоретически при увеличении выборки ( 2)![]() (1), то есть
(1), то есть
![]() , аналогично для
, аналогично для ![]() - с учетом конечности выборки
- с учетом конечности выборки
![]() ( 2*)
( 2*)
Тогда использовав выборочные оценки мат. ожиданий как формулы для средних значений точек попавших в полосы ![]() и
и ![]() получим приближенные выражения для геометрического построения регрессий
получим приближенные выражения для геометрического построения регрессий
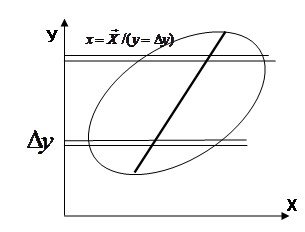
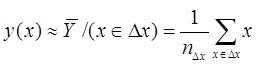
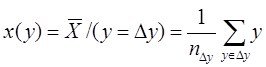
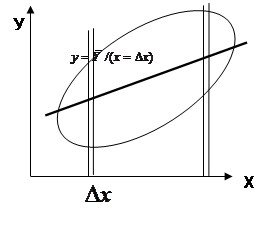 |
 Если условные распределения
Если условные распределения ![]() и
и ![]() унимодальны и симметричны то по этим формулам для средних линий в полосах получим в каждом “яйце” точки, принадлежащие линии регрессии. Для каждой линии достаточно построить по 2 точки и мы их проведем.
унимодальны и симметричны то по этим формулам для средних линий в полосах получим в каждом “яйце” точки, принадлежащие линии регрессии. Для каждой линии достаточно построить по 2 точки и мы их проведем.
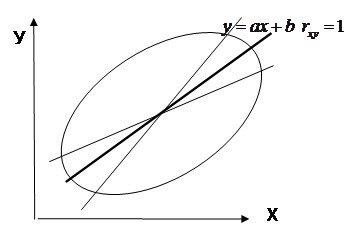
Обращаю внимание что регрессии у=f(x) и х=f(у) не совпадают ?Они совпадут (центральная линия) – и регр превр в алгебру - когда рассеяние симм отн бисктр и ![]()
Интерпретация в пространстве точек
Интерпретируем на осях двух точек
и для 2-х векторов - У и Х1
(хотя при осях 2 точек можно и все вектора
изобразить )
Для простоты будем изображать
центрированные варианты векторов
(без своб.члена)
Отложим в пространстве осей 2-х точек (две оси, чтобы возможно. было изобразить геометрическую интепретацию) вектора у и х
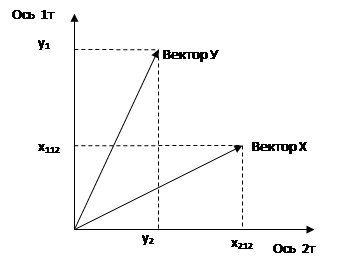
Регрессия МНК это проекция
моделируемого вектора в
плоскость векторов, по которым
моделируем.
А в одномерном случае
- это проекция на тот вектор,
с помощью которого мы
мы моделируем . То есть -
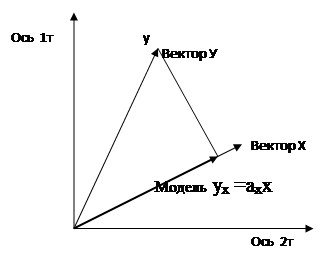
Проектируем вектор у на вектор х и получаем модель у по х:
ух =ахх
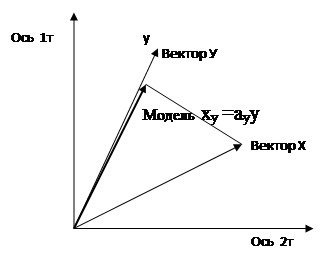
Проектируем вектор х на вектор у и получаем модель х по у: ху =ауу
Или на одном рисунке -
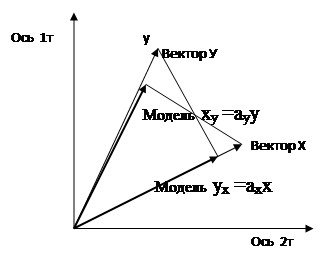
Теперь понятно, - поскольку проекции ух и ху – не совпадают, то и уравнения у них разные - из одной модели другая не получится.
А совпадут они - при колинеарности у и х
(что есть геометрический эквивалент коррелируемости ![]() )
)
 Регрессия МНК это проекция моделируемого вектора в плоскость векторов, по которым моделируем ----------в плоск 2-х иксов
Регрессия МНК это проекция моделируемого вектора в плоскость векторов, по которым моделируем ----------в плоск 2-х иксов
2 ?? === ===========================
Свойство проективности МНК
( вывод осн ф-ла МНК, используя теперь свойство проективности)
1. Напомним, что применяя МНК для регресии 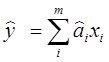 (1)
(1)
мы оцениваем параметры регресии ![]() с точки зрения минимизации функционала
с точки зрения минимизации функционала ![]() :
: 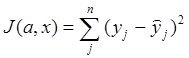 =
=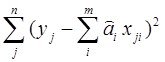 (1*)
(1*)
Здесь ![]() и
и ![]() наблюдаемые и модельные значения соответственно.
наблюдаемые и модельные значения соответственно.
Напомним что дальнейшие результаты будут такие же, если мы вместо (1) будем рассматривать модель более общую модель 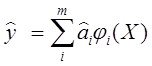 (2) и ф-нал
(2) и ф-нал 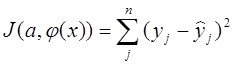 =
=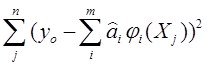 (2*)
(2*)
Результаты будут верны с точностью до переобозначения.
Поэтому, рассуждая в дальнейшем об (1) что формально проще, имеем далее в виду и (2) то есть модель нелинейную по аргументам регрессии.
2. Описывая данные задачи регрессии в виде таблиц естественно и выводить основные результаты в матричном виде (что бы не выделять отдельно своб член - ниже для упрощения записи - ![]() - ед.вектор) поэтому введем обозначения:
- ед.вектор) поэтому введем обозначения:
вектор 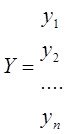 матрица
матрица  и вектор
и вектор 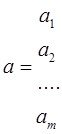
Напомним осн. правила матричных операций
1.–Умножения – А*В=С - 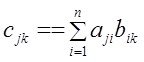 то есть для получениия jk-того элемента С - в А берут j-тую строку, в В k-тый столбец и их скалярно перемножают.
то есть для получениия jk-того элемента С - в А берут j-тую строку, в В k-тый столбец и их скалярно перемножают.
 2. Траспонирование
2. Траспонирование
– столбцы делает строками, строки столбцами
(в квадратной матрице – просто зеркально
отображаем относительно гл диагонали)
кроме того: (АВ)Т=ВТ АТ и следствие (АВС)Т=СТВТАТ
3.Обратная матрица А-1 матрицы А это такая матрицадля которой выполняется
![]() А-1*А=Е, где единичная матрица
А-1*А=Е, где единичная матрица
4.Свойство ортогональности векторов а и в: 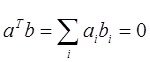
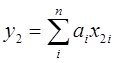 Наше требование к регресии - выполнение равенств - что должно бы выполняться - в первой точке
Наше требование к регресии - выполнение равенств - что должно бы выполняться - в первой точке 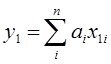
………… в n-ой точке - 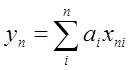 (*)
(*)
На самом деле выполнить их невозможно ввиду предположения ![]()
Эти условия (требования) (*) в матричном виде можно записать как
![]() (именно в таком порядке =операция умножения – срока Х на столбец а)
(именно в таком порядке =операция умножения – срока Х на столбец а)
Для решения задачи регрессии среди всех моделей ![]() нужно выбрать ту
нужно выбрать ту ![]() которая удовлетворяет условиям (*) наилучшим образом в смысле функционала (1)
которая удовлетворяет условиям (*) наилучшим образом в смысле функционала (1)
Матричную запись модели ![]() можно представить как
можно представить как ![]() уже выполн. условие
уже выполн. условие ![]() (вместо
(вместо ![]() ) с найденными оценками
) с найденными оценками ![]() .
.
То есть в результате решения мы находим такие ![]() которые формируют
которые формируют![]() наилучшим образом приближая условие
наилучшим образом приближая условие ![]()
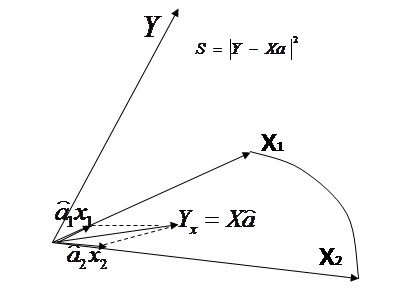 Приближение это реализуется МНК как проектирующий механизм. Покажем это
Приближение это реализуется МНК как проектирующий механизм. Покажем это
Если выражение, которое нам надо приблизить в матричном виде выглядит как ![]()
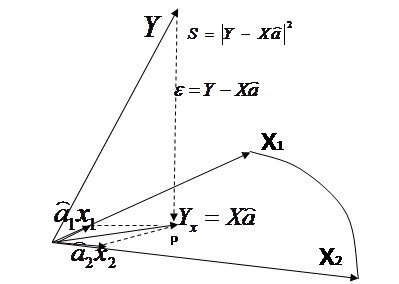 то естественно что матричный аналог квадратичной невязки (1) –это
то естественно что матричный аналог квадратичной невязки (1) –это ![]() . Эта ошибка
. Эта ошибка ![]() есть расстояние от вектора
есть расстояние от вектора ![]() до вектора
до вектора![]() .
.
Вектор ![]() должен лежать в пространстве переменных (столбцов) матрицы
должен лежать в пространстве переменных (столбцов) матрицы ![]() , так как
, так как ![]() есть линейная комбинация столбцов этой матрицы с коэфф.
есть линейная комбинация столбцов этой матрицы с коэфф. ![]() .
.
Отыскание решения ![]() по методу наименьших квадратов эквивалентно задаче отыскания такой точки (вектора)
по методу наименьших квадратов эквивалентно задаче отыскания такой точки (вектора)
![]()
которая лежит ближе всего к ![]() и находится при этом в пространстве столбцов матрицы
и находится при этом в пространстве столбцов матрицы![]() .
.
Таким образом, вектор ![]() должен быть проекцией
должен быть проекцией ![]() на пространство столбцов
на пространство столбцов ![]() и вектор невязки
и вектор невязки ![]() должен быть ортогонален этому пространству.
должен быть ортогонален этому пространству.
Далее для упощения записи вывода формулы МНК отрбросим значки “тильда”
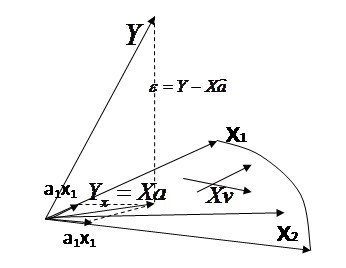
Ортоганальность вектора невязки ![]() пространству
пространству ![]() можно определить след образом:
можно определить след образом:
|
При произвольном ![]() вектор
вектор ![]() - это любой произвольный вектор, который можно положить в гиперплоскость построенную на векторах
- это любой произвольный вектор, который можно положить в гиперплоскость построенную на векторах![]() .
.
Для всех ![]() в пространстве
в пространстве ![]() , эти вектора должны быть перпендикулярны невязке
, эти вектора должны быть перпендикулярны невязке ![]() , в силу этого – условие отрогональности:
, в силу этого – условие отрогональности:
![]()
Так как это равенство должно быть справедливо для произвольного вектора ![]() , то
, то ![]() (*)
(*)
Таким образом мы нашли сооошение дающее решение по МНК несовместной системы условных уравнений ![]() , состоящей из n уравнений с m неизвестными (*)
, состоящей из n уравнений с m неизвестными (*)
![]()
которая называется системой нормальных уравнений
Если столбцы матрицы ![]() линейно независимы????, то матрица
линейно независимы????, то матрица ![]() обратима и можем получить решение для
обратима и можем получить решение для ![]() - одна их причин треб незав Х - и чем ближе к ЛЗ будут вектора тем хуже обусловлена
- одна их причин треб незав Х - и чем ближе к ЛЗ будут вектора тем хуже обусловлена ![]()
![]() (**)
(**)
Правда, естественно, решение не в том смысле, что оно превращает его в равенство, а в том, что в пространстве ![]() находит ближайший к нему вектор - проекцию
находит ближайший к нему вектор - проекцию ![]() . Вот для него имеем равенство
. Вот для него имеем равенство
![]()
Что и есть решение – основная народнохозяйственная ф-ла МНК
(брать производн. ф-ла,, приравн его=0, решать систему– проверте на примерах).То есть машина производных не берет а реалмзует полученную матричную формлу различными вычисдтельными процедурами. Самое слабое место – обращение матрицы, особенно при ее плохой обусловленности (корр переменных) – это будет у нас отдельный разговор.
*2 ====== Оператор проектирования. Свойства оператора.
Полученный результат имеет полезное для приложений свойство –
Из выражение ![]() получаем формулу оператора проектирования вектора
получаем формулу оператора проектирования вектора ![]() в плоскость
в плоскость ![]() :
:
Проекция вектора ![]() на пространство столбцов матрицы
на пространство столбцов матрицы ![]() имеет вид (подставляя значение
имеет вид (подставляя значение ![]() из (**))
из (**))
![]()
![]()
Матрица ![]()
называется матрицей проектирования вектора ![]() на пространство столбцов матрицы
на пространство столбцов матрицы ![]() .
.
Посмотрите какой интересный вид у нее.
Эта матрица имеет два основных свойства:
1. она идемпотентна ![]() , и
, и
2. онасимметрична - ![]() .
.
Проверим
1.![]()
![]()
2.по 2![]() =
=![]() =
=![]() =
=![]() =
=![]() Или более просто по 3- центральную скобку не трогаем при перестановке, края меняем местами и транспонируем, ценр тоже транспонируем
Или более просто по 3- центральную скобку не трогаем при перестановке, края меняем местами и транспонируем, ценр тоже транспонируем
![]() =
=![]() =
=![]()
Очень важно что верно и обратное: матрица Р, обладающая этими двумя свойствами есть матрица проектирования на свое пространство столбцов Х произвольного вектора У.
Данные свойства могут использоватся при проверке корректности использования МНК (в первую очередь зашумленность данных)
- потеря указанных свойств матрицей Р служит сигналом что оценки МНК (в силу нарушения условий применения - о них ниже ) потеряли свое качество
Структурно-параметрический синтез. Индуктивное моделирование
Переходя к третьоему столбцу (СИНТЕЗ ) Напомним что при моделировании мы решаем или о задачу параметр. синтеза ( при фикс. структуре) или задачу структурно-параметрического синтезу (СПС)
Коротко о проблемах СПС
Мы уже знаем что подход в лоб - с критерием "максимум точности" модели для задачи структурно параметрического синтеза в условиях
1 шумов в данных и
2. значимой корреляции между входными переменными
не корректен - почему ?
1- модель с нулевой ошибкой может оказатся абсолютно непригодной на свежих данных (переобученная модель) ..... пример ракета-волки
2.- вопрос а с какой же ошибкой считать модель оптимальной в алгоритмах ШМР например решается с помощью заданием оператором вероятностей
ошибок первого ![]() и второго рода -
и второго рода -![]()
Это вероятности ![]() при включении ложного арг в модель и -
при включении ложного арг в модель и - ![]() при исключении истинного аргумента из модели
при исключении истинного аргумента из модели
Но какие значения ![]() и
и ![]() нужны в каждом конкретном случае повисает в воздухе
нужны в каждом конкретном случае повисает в воздухе
3.- модель с сильно коррелированными (близкими к коллинеарности) аргументами может оказатся крайне неустойчивой к смене (даже однородных) обучающих выборок, при этом замена даже 1 точки или 1признака может дать существенную дисперсию оценки параметров модели.
4.- Кроме того проблемы плохой обусловленности ХтХ часто не позволяют в принципе получать решение задачи в лоб как у= (ХтХ)-1ХтУ
Поэтому был предложен ряд методов который в оговоренных выше тех или иных условиях позволяет получать наилучшие в некотором смысле модели.
Эти методы объединены названием (так введено основателями теор самоорганизации)
"Индуктивное моделирование" а вот подтверждение насколько тот или иной метод лучше более или менее может быть подтвержден (до испытаний на новых объектных данных) только модельным экспериментом который восстанавливает насколько это возможно
условия формирования экспериментальных данных и проверяет
насколько точно проверяемый подход открывает преполагаемую структуру и параметры модели.
Кратко по сути модельного эксперимента чуть позже далее
К1------ -------
Cтруктурно-параметрический синтез регрессионных моделей
Индуктивное моделирование - Как выбирать структуру модел
Напомним коротко что уже знаем
Постановка задачи структурного синтеза
Заданы, как обычно, матрица наблюдений Х(n*m), вектор отклика Y(n*1)
предполагается задание
А) перечня аргументов Х1….ХM, с избытком для синтеза модели: , M>m (лин. случай). Необходимо найти наилучшую модель 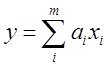 или
или
Б) предполагается синтез наилучшей нелинейной модели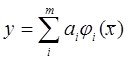 тогда количество обобщенных аргументов φj(x), j=1,...,m,...неисчерпаемо.
тогда количество обобщенных аргументов φj(x), j=1,...,m,...неисчерпаемо.
Очевидный вариант, - давайте усложнять структуру модели до тех пор, пока не получим «нулевую ошибку» (то есть догоняем структуру до m= n) - не проходит, так как любая структура удовлетворит такой «0-й ошибке», в том числе связывающая скорость ракеты с поговьем волков в Тамбовской области. В идеальных условиях:
отсутствие шумов в данных и независимость (или менее корректное и более слабое условие - отсутствие корреляции) случайных входных аргументов, возможно применить (не всегда –только при достаточно больших n, чтобы рассматривались модели при m<n) подход в лоб
Моделирование по полному списку аргументов (знаем)
Заметим что в оговоренных идеальные условия применения любых известных структурно-параметрическихметодов синтеза (СПС) - отсутствие шумов в данных и независимость случайных входных признаков - тогда и классические ШАМР и методы ИМ будут давать близкие приемлемые результаты
Однако обозначенные идеальные условия – иллюзия
- …шум вычислений всегда присутствует,
- практически всегда присутсттвует коррелированность аргументов, даже порожденных ГСЧ (корреляция 0.3-0.07) ,
- не говоря о постановке Б), где коррелированность заложена в постановке задачи (корреляция –то есть аппроксимация лин. зависимости есть и в нелинейных базисах …. )
Проблемы нарушения условий применения МНК приводятв СПС к различным отклонениям в
1.оценках параметров (состоятельности, несмещенности, эффективности)
2. включению фиктивных аргументовв модель вместо истинных
Как мы уже знаем наращивать точность до 0-й ошибки - плохая стратегия. Модели должны быть более простые, чем достигающие 0-й ошибки при m= n. В этой ситуации любая структура даст 0-й ошибку.
А какой механизм выбрать для получения более простых (с ненулевой ошибкой) структур, которые наболее соответствовали нашим ожиданиям?
– минимальной ошибке на новых точках?
(имеено эта сверхзадача обычно стоит за любой задачей моделирования).
Решение проблемы проводится по 2-м направлениям
1. Отбор наилучших структур осуществляется за счет применения механизма штрафов за сложность модели в явном виде
Механизмы учитывают доступную информацию о шумах в выходных данных и позволяют получать оптимально упрощенные (по отношению к даже истинной структуре) - модели. Оптимальные, например с точки зрения точности прогноза на тестовых данных
2. Отбор наилучших структур осуществляется за счет применения штрафа за сложность в неявном виде.
Данный механизм чаще применяется в наиболее сложных условиях когда о шуме не предполагается известных оценок и этот подход также обеспечивает решение сверхзадачи – минимизацию ошибки модели на новых выборках.
- 1.Первый путь (явный штраф засложность) частично реализуется в классических ШАМР и принципе отбора моделей по критериям Акаике, Шварца и Меллоуза
- 2. Второй путь (неявный штраф за сложность) основан на различных принципах нахождения новых, свежих выборок и отбор осуществляется тех структур моделей, которые обеспечивают минимум ошибки моделей на этих свежих данных.
Методы, которые предлагают свой ответ на вопрос как сформировать новые выборки данных - это
А) будстреп, Б) метод складного ножа (джек найф), и В) МГУА
В МГУА предложены варианты внешнего критерия которые обеспечивают модели оптимальной сложности для различных содержательных задач (аппроксимация, прогноз, дискриминация) и различных условий синтеза моделей.
Методы моделирования с явным штрафом за сложность моделей
Классические шаговые алгоритмы многомерной регрессии
Мы уже знаем ШАМР - напомним их. Новое тут - в анализе проблем ШАМР
Наиболее распространенные ШАМР – три следующих алгоритма –
1. Метод прямого отбора МПрО (Forward Selection) или
метод последовательного включения
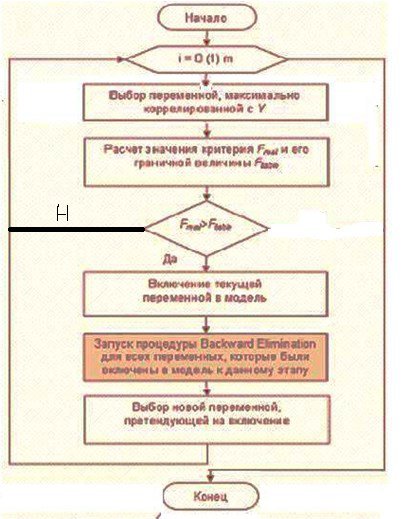
2. Метод обратного исключения МОИ (Backward Elimination) или
метод последовательного исключения
3. Метод последовательного отбора МПО (Stepwise) или
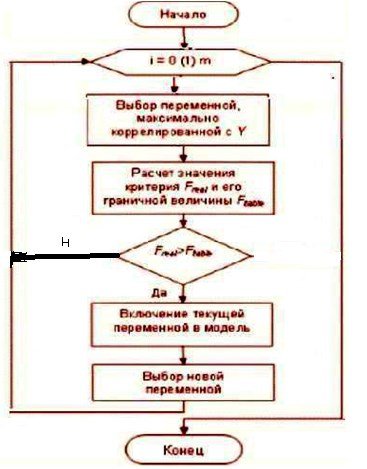 метод последовательного включения и исключения
метод последовательного включения и исключения
Данные шаговые регрессионные алгоритмы идеологически похожи. Постулируется некоторый начальный состав аргуметов в начальной модели - при МПрО и МПО – состав пуст – константа, начальный состав при МОИ - полное описание – состав из всех претендентов аргументов.
В методе последовательного отбора МПО на основании некоторого порогового критерия принимается решение о вводе или не вводе в модель 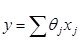 претендента
претендента ![]()
ВМетоде обратного исключения “Backward Elimination” на основе подобного же критерия критерия принимается решение о выводе или не выводе из модели претендента на аргумент модели.
Метод последовательного отбора МПО решение о вводе в модель некоторого аргумента – затем просматриваются все остальные ранее вошедшие в модель аргументы – и на основе того же порогового критерия определяется - не следует ли теперь вывести из модели какой-либо аргумент из вошедших ранее
Замечание: во избежание зацикливания процесса включения исключения значимость включения устанавливается меньше значимости исключения
В ШАМР для отбора лучших структур используют
- порог критерия качества модели (связанный с уровнем значимости) и
- коррекцию формулы расчета критерия качества модели, учитывающий штраф за сложность модели.
Подход имеет недостаток в том смысле что не формализует очевидным образом выбор порога в зависимости от условий моделирования (дисперсия и параметры шума, степень коррелированности входов и тд)
А используемый механизм штрафи за сложность – (деление на n-m) мало чувствителен к условиям моделирования при больших и средних значениях n –кол. точек
Остается привести формулу расчета статистики Фишера (F теста) который был создан для сравнения и выводов о различие дисперсий.
Введем обозначения
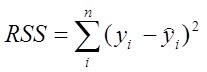 |
· ![]() — сумма квадратов ошибок, - здесь
— сумма квадратов ошибок, - здесь
![]() - наблюдаемые значения,
- наблюдаемые значения, ![]() - значения модели
- значения модели
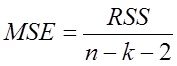 ·
· ![]() — среднеквадратичная ошибка, - в завис. от шага использования -
— среднеквадратичная ошибка, - в завис. от шага использования -
ее в методе шаговой регрессии
где ![]() - количество точек,
- количество точек, ![]() - количество оцениваемых параметров модели
- количество оцениваемых параметров модели ![]() - число степеней свободы модели, (-2). – потому что учитывается свободный член модели и одна степень свободы у среднего
- число степеней свободы модели, (-2). – потому что учитывается свободный член модели и одна степень свободы у среднего ![]() .
.
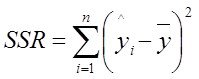 - сумма квадратов регрессии
- сумма квадратов регрессии
Есть ![]() до ввода регрессора претендента в модель -
до ввода регрессора претендента в модель - ![]() ,
,
есть ![]() после ввода регрессора претендента в модель
после ввода регрессора претендента в модель ![]()
и есть разница ![]()
Сумма квадратов регрессий при введении полезного аргумента 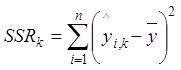 увеличивается и стремится к значению
увеличивается и стремится к значению 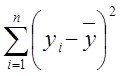
Поэтому аргумент с большим приростом ![]() - лучше.
- лучше.
Соответственно рассматриваются ![]() и
и ![]() - значение среднеквадратичной ошибки до и после ввода регрессора в модель
- значение среднеквадратичной ошибки до и после ввода регрессора в модель
Тогда статистку 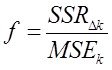 (*) называют критерием или F-тестом Фишера. применительно к шаговой регрессии. Доказано что данная статистика распределена по закону Фишера и ее используют для определения порога отсева аргументов по значению улучшения дисперсии модели.
(*) называют критерием или F-тестом Фишера. применительно к шаговой регрессии. Доказано что данная статистика распределена по закону Фишера и ее используют для определения порога отсева аргументов по значению улучшения дисперсии модели.
Вопрос:
Зачем для определения порога отсева аргументов рассматривать отношение 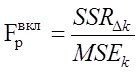 (*) а не просто улучшение ошибки
(*) а не просто улучшение ошибки![]() или прирост
или прирост ![]() ????. – Резон в том что это отношение расределено по известному закону Фишера и для определения состава аргументов модели привлекают механизм проверки статистических гипотез:
????. – Резон в том что это отношение расределено по известному закону Фишера и для определения состава аргументов модели привлекают механизм проверки статистических гипотез:
При реализации процедурывключения аргумента - рассматривается гипотеза H0 , что улучшение качества модели незначимо.
То есть Н0 состоит в том что введенный аргумент - ложный.
Проверка гипотезы H0 сводиться к последовательности действий:
1. Задаемся уровнем значимости ![]() , например 0,01 или 0,05.
, например 0,01 или 0,05.![]() характеризует риск принятия неправильного решения. То есть риск введения ложного аргумента (вероятность ошибки 1 рода)
характеризует риск принятия неправильного решения. То есть риск введения ложного аргумента (вероятность ошибки 1 рода)
2. По специальным таблицам находим -процентную точку ![]() распределения Фишера со степенями свободы d1=1 d = n-k-2 (для формулы (**) степень свободы определяется как d1=(п-k)-(n-k-1)=1). Это значение будет являться нашим пороговым для статистики (*).
распределения Фишера со степенями свободы d1=1 d = n-k-2 (для формулы (**) степень свободы определяется как d1=(п-k)-(n-k-1)=1). Это значение будет являться нашим пороговым для статистики (*).
Сравниваем точку![]() со значением расчетной статистики
со значением расчетной статистики ![]() .
.
Если окажется, что![]() , то делается вывод о значимости введенного признака и, соответственно, его следует включить в модель (отдается предпочтение гипотезе H1 с вероятностью
, то делается вывод о значимости введенного признака и, соответственно, его следует включить в модель (отдается предпочтение гипотезе H1 с вероятностью ![]() ошибиться).
ошибиться).
Если же![]() , то принимается решение о неэффективности включения переменной в модель,то есть гипотеза H0 принимается с вероятностью
, то принимается решение о неэффективности включения переменной в модель,то есть гипотеза H0 принимается с вероятностью![]() как не противоречащая экспериментальным данным.
как не противоречащая экспериментальным данным.
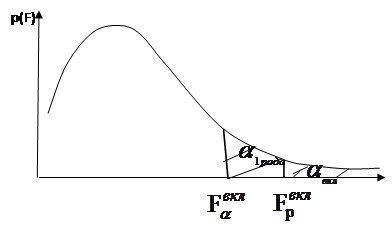 ( здесь p(F) = -плотность распределения Фишеровской случ величины, чем выше (боль) порог
( здесь p(F) = -плотность распределения Фишеровской случ величины, чем выше (боль) порог ![]() тем меньше уровень значимости
тем меньше уровень значимости ![]() - ошибк.1 род).
- ошибк.1 род).
На рис. видим что зона допуст. расчетных значений ![]() лежат выше (в смысле справа) порога
лежат выше (в смысле справа) порога ![]() , а соответствующая зона расчетной ошибки 1рода -
, а соответствующая зона расчетной ошибки 1рода - ![]() (площадь под хвостом)-должна быть меньше порогового уровня уровня значения ошибки 1-ого рода -
(площадь под хвостом)-должна быть меньше порогового уровня уровня значения ошибки 1-ого рода - ![]() . Таким образом задавая в Stepwise
. Таким образом задавая в Stepwise ![]() =допустим 0.05 (или соответств
=допустим 0.05 (или соответств ![]() ) -что есть вероятность вкл. ложного аргумента (вер ош 1 рода) мы этим параметром полностью доопределяем процедуру включения аргументов в модель.
) -что есть вероятность вкл. ложного аргумента (вер ош 1 рода) мы этим параметром полностью доопределяем процедуру включения аргументов в модель.
Аналогично при процедуре исключения аргументов из модели рассматривается гипотеза H0 , что ухудшение качества моделинезначимо
Соответственно выбранный уровень значимости ![]() =допустим 0.1 (или соотв
=допустим 0.1 (или соотв ![]() ) - есть вероятность исключения истинного аргумента (вер ошибки 2-го рода). Соответственно решение о принятии H0 "гипотезы о незначимости аргумента" - и исключении аргумента из модели реализуется при выполнении условия
) - есть вероятность исключения истинного аргумента (вер ошибки 2-го рода). Соответственно решение о принятии H0 "гипотезы о незначимости аргумента" - и исключении аргумента из модели реализуется при выполнении условия ![]() . То есть область допустимых для исключения значений
. То есть область допустимых для исключения значений![]() лежит слева от
лежит слева от ![]()
1-к
---------- ====
2 Л
Проблемы методов структурной идентификации
Обратим внимание на множитель (![]() ) в формуле МST и попадающий в числитель в статистике Фишера (*)
) в формуле МST и попадающий в числитель в статистике Фишера (*)
Чем сложнее модель тем более корректируется расчетное значение критерия в сторону уменьшения (то есть ухудшения) препятствуя включению аргумента в модель. Таким образом мы видим что даже классичский ШАМР уже использовал определенную форму штрафа за сложность модели. Правда его влияние при больших n незначительно и практически не влияет на структуру модели.
Другие проблемы ШАМР
1. Для конкретных условий шума в данных (в Х и У) соотношение ![]() и
и ![]() - свое "с точки зрения наиболее точного прогноза на свежих точках или более общо - с точки зрения "внешнего критерия" который мы определяем как "истина для нас " - в то время как сам алгоритм ШР опирается лишь на точность текущей обуч выборки и значение
- свое "с точки зрения наиболее точного прогноза на свежих точках или более общо - с точки зрения "внешнего критерия" который мы определяем как "истина для нас " - в то время как сам алгоритм ШР опирается лишь на точность текущей обуч выборки и значение ![]() и
и ![]() предлагает выбирать нам.
предлагает выбирать нам.
2. известный недостаток теории стат. гипотез:
только результат по введению аргумента (не принятию H0 ) в ней считается достоверным. Результаты по принятию H0 в обще-то ничего не гарантирует. Применяется такая хитрозделанная формулировка – принятие гипотезы H0 не противоречит исходным данным.
= это приблизительно так как если бы у вас во дворе се8одня ночью убили дворника и обвинили в этом меня только на том основаниии что я спал дома один и некому подтвердить мое алиби. Так ведь еще в эту ночь 200 тыс киевлян спали одни – однако от этого вывод не меняется – гипотеза об обвинении в убичтве принимается на том основании что она не притиворечит исходны. данным. – Так накопайте другие данные – или лучше смените алгоритм - но как часто бвыает в жизни – лень и пользуются тем что имеют.
3. Кроме того, уменьшая ![]() (увелич порог качества аргумента) мы не тоько увеличиваем вероятность правильного отвержения ложного аргумента 1-
(увелич порог качества аргумента) мы не тоько увеличиваем вероятность правильного отвержения ложного аргумента 1- ![]() но и очевидно увеличиваем вероятность отвержения вместе с ним и истинного аргумента увеличиваем ошибку второго рода -истинный аргумент тоже может не проскочить слишком высокий порог ФИШЕРА.
но и очевидно увеличиваем вероятность отвержения вместе с ним и истинного аргумента увеличиваем ошибку второго рода -истинный аргумент тоже может не проскочить слишком высокий порог ФИШЕРА.
И магическое число ![]() =0,05 совсем не магическое и в разных задачах при разных шумах и разных корреляциях истинных и ложных аргументов с выходом (в некоторых случаях корреляция ложного будет выше корреляции истинного с выходом - зависит от коэффициента при соответствующем аргументе в модели) это число имеет свое опт значение - а какое ???? - проблема проблема
=0,05 совсем не магическое и в разных задачах при разных шумах и разных корреляциях истинных и ложных аргументов с выходом (в некоторых случаях корреляция ложного будет выше корреляции истинного с выходом - зависит от коэффициента при соответствующем аргументе в модели) это число имеет свое опт значение - а какое ???? - проблема проблема
4. Адекватность (статистическая значимость ) получен. уравнения регрессии
Для проверки значимости уравнения регрессии “в целом” используется критерий Фишера: если
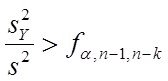 то уравнение регрессии адекватно (статистически значимо) описывает результаты эксперимента при (
то уравнение регрессии адекватно (статистически значимо) описывает результаты эксперимента при (![]() ) - процентном уровне значимости. Отношение (полной
) - процентном уровне значимости. Отношение (полной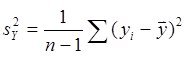 и остаточной
и остаточной 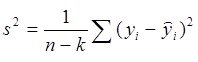 дисперсий)
дисперсий) ![]() показывает, во сколько раз уравнение регрессии аппроксимирует предсказывает результаты опыта лучше, чем среднее
показывает, во сколько раз уравнение регрессии аппроксимирует предсказывает результаты опыта лучше, чем среднее ![]() , где k – сумма числа входных переменных плюс свободный член.
, где k – сумма числа входных переменных плюс свободный член.
Необходимо помнить, что доверительная оценка отклонения эмпирической линии регрессии от теоретической резко ухудшается по мере удаления от среднего значения ![]() . В частности, по этой причине опасна экстраполяция эмпирической регрессионной зависимости за пределы интервала входных переменных
. В частности, по этой причине опасна экстраполяция эмпирической регрессионной зависимости за пределы интервала входных переменных ![]() , для которого она получена
, для которого она получена
По сути это значит что заранее признается неработоспособность модели на новых свежих данных если они по сути не повторяют старые!!!!!
И этот аргумент у нас будет одним из главных в критике, потому что если в алгоритме нет серьезных механизмов настройки структуры модели то она будет беспомощна в реальных условиях применения на живых данных
Ниже мы рассмотрим механизмы штрафов (критерии) которые более чувствительно и обоснованно реагируют на усложнение модели
Критерии с явным штрафом за сложность модели (продолжение)
И так постулируем следующие части алгоритма структурно-параметрического синтеза.
1.Генератор структур -(он может быть более или менее удачным, то есть более или менее удачно решить выбор пути неполного перебора структур (если перебор полный то это самый простой алгоритм генерации)
2.Механизм расчета параметров (МНК, ЗЛП, град. Процедуры)
3. Критерии выбора структуры (внешние критерии)
Будем сейчас вести речь о самом интересном –критериях отбора структур.
1 Пусть известна ![]() дисперсия шума
дисперсия шума
Наиболее подходящий критерий для выбора структуры оптимальной сложности при условии известности ![]() дисперсии шума есть
дисперсии шума есть
Критерий Маллоуза
Критерий Маллоуза оказываеся дает при этом несмещенную оценку ошибки прогнозирования
, ![]() где RSS – квадрат нормы невязки у,
где RSS – квадрат нормы невязки у, ![]() - дисперсия шума,
- дисперсия шума, ![]() - сложность модели (для лин модели -количество расч параметров).
- сложность модели (для лин модели -количество расч параметров).
Но надо знать дисп шума ![]() , тогда этот критерий позволяет отобрать структуру с наилучшей оценкой прогноза,
, тогда этот критерий позволяет отобрать структуру с наилучшей оценкой прогноза,
2.Пусть известно распределение шума ![]()
Когда известно распределение шума ![]() можно построить функцию распределения модели у с учетом этого распределения шума
можно построить функцию распределения модели у с учетом этого распределения шума ![]() ,
,
Для нахождения параметров ![]() предполагаетсяч использование метода наибольшего правдоподобия. Как известно, для этого надо найти такие
предполагаетсяч использование метода наибольшего правдоподобия. Как известно, для этого надо найти такие ![]() которые доставляют максимум ф-ции правдоподобия
которые доставляют максимум ф-ции правдоподобия 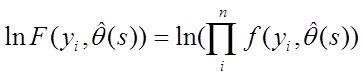 при каждом варианте структуры
при каждом варианте структуры ![]() в известных точках
в известных точках ![]() .
.
Тогда для поиска оптимальной структуры ![]() используется информационный критерий Акаике (AIC):
используется информационный критерий Акаике (AIC):
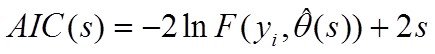
где ![]() - максимизированное значение функции правдоподобия модели.
- максимизированное значение функции правдоподобия модели.
В частном случае нормального шума он принимает вид критерия Маллоуза. При этом на практике он применяется в упрощенном виде
![]()
Этот вариант формулы называют критерием Акаике-Маллоуза
Данный критерий существенно ограничивает рост сложности модели наличием аддитивного члена 2s. Однако проблема применения состоит в том, что в практических задачах функция распределения шума да часто и его дисперсия неизвестны.
А что тогда делать? Используют тогда менее обоснованные но практически неплохо работающие критерии
3. Байесовский информационный критерий (критерий Шварца):
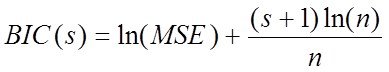
4. Также популярен критерий финальной ошибки предсказания Акаике применяемый при неизвестном характере шума и корректирующий остаточную сумму квадратов ошибки
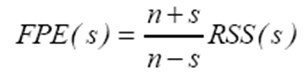
Критерии с использованием штрафа за сложность в неявном виде и с порождением новых выборок
1. Бутстреп – предполагается что раз данные n точек появились у нас в віборке то у них равная вероятность появления в віборке - отсюда алгоритм получения подобных выборок - имитационное моделирование исходной выборки с помощью равномерного распределения - ключевой момент если некоторая точка реализовалась она возвращается в множество генерации (т.о. получаем выборки размером n с возможным количеством повторения некоторых точек)
2. Критерий "скользящего контроля", "усредненный критерий регулярности", или "джекнайф"-складной нож:
Используется при крайне малом количестве точек ( когда точек просто маловато используют разбиения выборки по МГУА -- ниже)
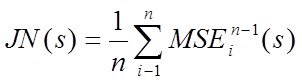
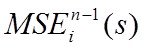 - значение критерия MSEi при синтезе модели на n-1 точке - то есть при выброшеной из выборки i-той точке при данном s. Когда s определено - считаем параметры на полной выборке.
- значение критерия MSEi при синтезе модели на n-1 точке - то есть при выброшеной из выборки i-той точке при данном s. Когда s определено - считаем параметры на полной выборке.
КРИТЕРИИ С РАЗБИЕНИЕМ ВЫБОРКИ
Внешние критерии, применяемые в М ГУА.
Здесь принцип компромисса (в неявном виде) достигается за счет разбиения выборки на две части. По одной части – „внутренней” –
осуществляется оценивание параметров, по другой – „внешней” – определяется прогнозирующая способность моделей. К этой группе относится критерий регулярности:
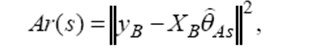 где A и B – соответственно обучающая и проверочная части выборки,
где A и B – соответственно обучающая и проверочная части выборки, ![]() – оценка параметров модели сложности s по МНК на подвыборке А.
– оценка параметров модели сложности s по МНК на подвыборке А.
Комментарий к материалу
Поскольку во всех методах есть какие-то проблемы - (хотя с моей точки зрения алгоритмы МГУА наиболее совершенны и технологичны в настоящее время), то если бы рядом со мной стоял «старый зубр» - статистик (например Цейтлин Натан Абрамович автор книги “из опыта аналитического статистика”) он сумел бы доказывать что и Акаике и МГУА не совершенны, а в рамках АШР он, Цейтлин сможет получать модели не хуже чем мы по МГУА
Ну что же. В этом он наверное прав. Но для этого надо быть Цейтлиным, и иметь многолетний опыт практической работы статистика, чтобы преодолевать проблему множественности моделей с помощью своего многолетнего опыта.
Для других практиков, не такого высокопрофессионального уровня, то методология МГУА и рекомедации, которые мы рассмотрели выше позволят вам решать сложные практические задачи моделирования не хуже Цейтлина.
Подведем промежуточные итоги:
Если вам известны распределение шума или его дисперсия применяейте информационный критерий Акаике или Маллоуза соответственно.
Если параметры шума неизвестны и выборка критически мала, наиболее подходящий подход – «джекнайф». В других случаях я бы рекомендовал различные алгоритмы МГУА.
Таким образом несмотря на достаточно подробное разложение проблем структурного моделирования - что в каких случаях рекомендуется применить значительное количество методов при неизвестных параметрах шума и коррелированности входных переменных могут выступать конкурентами при решении задач моделироания
– это критерий Шварца, различные алгоритмы МГУА, в некоторых случаях ШАМР, другие, не рассмотренные нами неклассические подходы к моделированию:
-агентное моделирование, генетические алгротритмы, нейронные сети и прочее..
Для того что бы вы, (которые не “неЦейтлины”), сами могли решить вашу задачу, смогли решить: вот данный, конкретный метод, подходит ли вам для решения вашей конкретной задачи, Вам необходимо сформировать собственное мнение о применяемых и сравниваемых алгоритмах.
Для этого вам надо хорошо в первую очередь разобраться в своей прикладной задаче. То есть хорошо представлять особенности данных и иметь хотя бы общие предположения о классе опорных функций (степенные, гармонич …..) и порядке сложности предполагаемой модели.
Тогда существует эффективный подход для определения адекватности метода вашей конкретной задаче – конструирование модельного примера.
Проверка структуры модельным экспериментом
Если вы разбираетесь в сути вашей практ. задачи то проверить метод на адекватность в конкретных условиях достаточно просто – создать модельный пример: то есть
задаемся предполагаемой моделью,
задаемся аргументами с запасом (истинные и фиктивные),
генерируем входные данные,
по заданной модели считаем выход.
Полученные входы и выход даем на вход тестируемого алгоритма и смотрим что он нам нарисует. Рассмотрим что такое при этом хорошо и что такое плохо. Если
1. метод при отсутствии шума в данных и некоррелированности входных аргументов дает решение на нашей структуре – это нормально. В противном случае метод безоговорочно не подходит как не обладающий сходимостью к истинной структуре.
2. Медот сходится к истинной структуре в большинстве практически значимых случаях пр условии коррелированности входных аргументов. Это хорошо - значит он обладает сходимостью к истинной структуре отфильровывая фиктивные аргументы и отбирая истинные в модель.
3. если при коррелированности аргументов и введении шума метод
3а)упрощая модель (в условии шума более простые модели обладают меньшими ошибками чем более сложные и при этом даже истинные)
обеспечивает минимальную ошибку на свежих данных – это говорит о том что синтезируутся модели оптимальной сложности – и это хорошо – для таких моделей будем иметь минимальные ошибки и прогноза и аппроксимации на новых данных
3б) Если метод при этом остается на подмножестве истинных аргументов – это отлично, так как решает сразу 2 задачи – получает модель оптимальной сложности при этом на подмножестве истинных аргументов.
К какому варианту стремится – к 3а или 3б зависит от цели задачи.
–Если стоит задача прогноза или аппроксимации в сравнительно неизменных условях – то очевидна полезность 3а.
- Если стоит та же задача в сильно изменяющихся условиях или задача поразумевает влияние на изучаемый процесс через истинные аргументы (то есть нужна модель максимально приближенная к физической модели) то необходимо решение как в 3б.
-------------
Независимая вставка ---------------
Таким образом при фиксации условий моделировании (как в модельных примерах так и в реальной задаче) необходимо различать три ситуации:
1. Конструируемые модели линейны 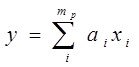 , - строятся на множестве
, - строятся на множестве ![]() , здесь
, здесь ![]() - истинные аргументы, остальные
- истинные аргументы, остальные ![]() - фиктивные
- фиктивные
Входное множество Х – независимые переменные, (шума в данных нет)
Задача: отыскать среди всех моделей 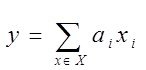 которые можно построить на Х - истинную модель
которые можно построить на Х - истинную модель 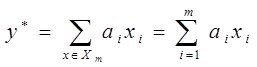
(почему мы вводим фиктивные переменные?? – потому что в реальной задаче мы никогда не знаем истинной структуры, что входит в модель – то есть мы копируем реальную практическую ситуацию)
2. Конструируемые модели нелинейны,(шума в данных нет),
строятся на базисе ![]() ,
,
здесь ![]() - множество истинных аргументов нелинейной модели, остальные -
- множество истинных аргументов нелинейной модели, остальные -![]() - фиктивные,
- фиктивные, ![]() - вектор входных аргументов
- вектор входных аргументов ![]() . Среди моделей
. Среди моделей 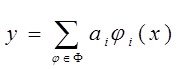 ищем истин. модель
ищем истин. модель 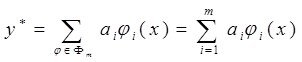
Как видим вторая задача может быть сформулирована точно как первая с точность до переобозначения ![]() (кроме…):
(кроме…):
2.а Конструируемые модели линейны, строятся на базисе
![]() , здесь
, здесь ![]() - множество истинных аргументов, остальные -
- множество истинных аргументов, остальные -![]() - фиктивные, Среди моделей
- фиктивные, Среди моделей 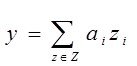 ищется истинная модель
ищется истинная модель 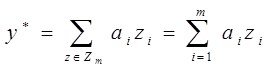
(***) Но неременные zi, ![]() могут быть коррелированы – это единсвенное но важнейшее отличие в данных постановках.
могут быть коррелированы – это единсвенное но важнейшее отличие в данных постановках.
Т.о. п.2 может быть сформулирован точно как п.1
только с условием то. Есть
2б.Конструируемые модели линейны но имеется условие (***) возможной коррелируемости входных переменных.
И наконец.
3. В данных ….. присутствует шум в общем случае неизвестого уровня распределения и точек приложения.
Рассмотрим первую ситуацию.
Очевидно, что в данном случае любой шаговый алгоритм справится с открытием истинной струкуры, ведь любой аргумент ![]() для которого
для которого ![]() будет истинным (за сключением множества фиктивных аргументом мощности меры 0, вероятность наличия которых в нашем списка = 0 – то есть вмешаться может только слепой случай)
будет истинным (за сключением множества фиктивных аргументом мощности меры 0, вероятность наличия которых в нашем списка = 0 – то есть вмешаться может только слепой случай)
Покажем это
Итак, по формулировке 1. – имеем
![]() для всех
для всех ![]() в силу их независимости и
в силу их независимости и
![]() для всех
для всех ![]() истинных (по определению, истинный аргумент имеет связь с выходом)
истинных (по определению, истинный аргумент имеет связь с выходом)
Предположим обратное,
что для некоторого ![]() выполняется
выполняется ![]()
Тогда ![]() связан с выходом
связан с выходом ![]() .
.
И при этом по определению не является истинным аргументом.
Когда такое возможно? – либо это случайность (генератор так случайно сгенерировал ![]() - этомножество меры 0, вероятность которого - 0) либо
- этомножество меры 0, вероятность которого - 0) либо ![]() связан с неким
связан с неким ![]() , то есть
, то есть
для них ![]() , что противоречит условию независимости всех
, что противоречит условию независимости всех ![]()
Поскольку выбор в претенденты на участие в модели происходит в шаговых алгоритмах по величине ![]() то оно последовательно включит истинные аргументы в модель.
то оно последовательно включит истинные аргументы в модель.
----------------------
Вот во всех остальных случаях, у классических шаговых алгоритмах начинаются сложности. Если
1.поданные на вход переменные (истинные и фиктивние) независимы а
2. данные точные без шума и
3.при этом количество наблюдений ![]() количества претендентов на аргументы в модель
количества претендентов на аргументы в модель
то с такой задачей открытия истинной модели могут справится классические шаговые и другие неклассические методы индуктивного моделирования. Покажем это.
Более серьезные проблемы ШАМР
Первым проблемным изменением в постановке – отмена независимости входных аргументов. Это реальная проблема в силу того что
1.в реальности входные аргументы часто могут быть коррелированы (СОЕ и температура, белок в моче и краетинин в крови и тд )
2. истинный характер модели нам не известен и в качестве претендентов на входящие аргументы мы должны формировать различные нелинейные комбинации из исходного набора входных аргументов. Ну тот самый базис ![]() о котором мы упоминали выше
о котором мы упоминали выше
Для сведения:
линейная корреляция х и х2 где-то 0.97 а х и х3 - 0.95 и теперь при истинных аргументах х1 и х2 , аргумент х1х2 может быть фиктивным, но тем не менее иметь большую корреляцию с выходом.
В таких условиях классические шаговые алгоритмы сталкиваются с поблемой множественности решений.
Истинные и фиктивные коррелируют, конкурируют и претендуют на вход в модель. При этом сильно коррелирующий фиктивный оттесняет слабо влияющего с малым коэффициентом истинный аргумент. В результате путь к истинной модели ША может циклится или вообще к ней не прийти. Можете сами попробовать – в этих условиях раззичные алгоритмы дадут результирующие различные структуры, Один и тот же алгоритм часто даст вам разные решения при смене условий счета
– изменений в данных,
- изменений в составе переменных (при неизменной истинной модели и неизменном присутствии истинных аргументов)
- изменений в порядке ввода- вывода аргуменнтов в модель
- изменений в значениях порогов отсева аргументов.
Точное решение возможно только при полном переборе всех моделей претентентов – только тогда получим истинную модель
Но полные перебор чаще всего не возможен –
Действительно рассматривая скажем степенные модели -
Количество членов полного полинома Колмогорова – Габора –
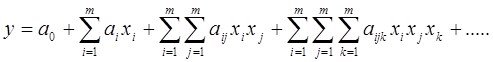
При ![]() при входных аргументах и заданной
при входных аргументах и заданной ![]() -той его степени
-той его степени
количество членов такого полинома можно рассчитать по формуле
![]() а количество частных моделей которые можно образовать из этого полинома -
а количество частных моделей которые можно образовать из этого полинома - ![]()
Пример.
Таким образом при несчастных 10-ти входных аргументах 4 степени полного описания порождает полинома с 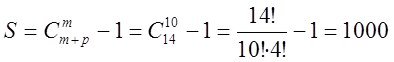 что порождает
что порождает ![]() моделей претендентов - это приблизительно
моделей претендентов - это приблизительно ![]() моделей которые можно из него построить.
моделей которые можно из него построить.
Это число не только изобразить его вообразить невозможно. Тем более пересчитать эти модели.
Попробуте их перебрать за реальное время …..
Итак вывод:
- корреляция входных переменных порождает необходимость разрешения проблемы множественности моделей и соответственно
огромного количества возможных путей перебора среди которых ничтожное меньшинство приводит к модели истинной структуры.
Необходимо предложить решения, позволяющие найти пути к истинной или квазиистинной модели, не прибегая к процедуре полного перебора –
Рассмотренные выше шаговые классические алгоритмы на практике такие задачи решают не эффективно.
Хотя решить такую задачу казалось бы очень просто – задать полный полином и найти по МНК для него коэффициенты для полной структуры.
В этом случае для фиктивных аргументов в уравнении как бы должны выйти нули. Почему же не пользуются этой возможностью?
Потому что, как мы помним, из корреллированности входных аргументов следует воможность коррелированности выходной переменной и фиктивных – что создает реальную конкуренцию при выборе структуры между истинными и фиктивными аргументами.
Еще более усложняет выбор структуры наличие шума в данных.
Ситуация 3
3.Проблема шума в данных
Итак, все дело в шуме, который обязательно присутствует в любых данных и даже минимальные уровень которого, деформирует исходные корреляционные отношения так, что из полного полинома невозможно увидеть истинную структуру.
Теперь оценки параметров при фиктивных, но коррелированных с выходом аргументах, уже точно не будут нулевыми, а значимыми или незначимыми они будут и, насколько значимыми, оценить заранее невозможно.
И даже при полном отсутствии шума в данных, шум все равно в расчетах присутствует, и, чем выше корреляция аргументов, тем хуже обусловленность матрицы (детерминант системы ближе к нулю) аргументов и тем выше уровень вычислительного шума. Поэтому никто мало кто (напрямую) при коррелированных аргументах не оценивает параметры полного полинома.
Более подробно.
И так, коррелированность обуславливает
1. близость к нулю главного дискриминанта матрицы аргументов – чем выше коррелированность аргументов, тем ближе дискриминант к нулю, тем выше погрешность вычислений.
Однако, проблема коррелированности аргументов в присутствии шума имеет еще одну важную особенность:
2. роль самого шума в искажении оценок параметров многократно возрастает. Оценки становятся и несостоятельными и смещенными и неэффективными. И, чем выше коррелированность, тем сильнее эффект искажения.
Покажем это, используя геометрическую интерпретацию получения МНК оценок параметров модели ![]() при аргументах х1 и х2,как коэффициентов проекции исходного вектора
при аргументах х1 и х2,как коэффициентов проекции исходного вектора ![]() в плоскость х1,х2.
в плоскость х1,х2.
Интерпретацию покажем в пространстве точек (см рис.1) .
Очевидно, что если коррелированность аргументов возрастает, то уменьшается угол между векторами х1 и х2 ,. При малом угле (рис.2) даже совершенно ничтожный шум в данных влияет через коррелированность, как через увеличительное стекло, на смещение положение плоскости аргументов. И, чем меньше угол между векторами, которые определяют плоскость тем легче шум вращает плоскость аргументов.
![]()
Рис1 Рис 2 Рис 3 Рис 4
Рис 3 показывает случай коллинеарности векторов х1, х2, что позволяет плоскости вертеться на оси векторов и принимать любое положение. Соответственно и проекции (модели) в эти сдвинутые плоскости будут как угодно разные. Именно поэтому, наиболее предпочтительный вариант проекции в плоскость, это в плоскость, определенную ортогональными (независимыми), а еще лучше ортонормированными векторами –рис.4.
Здесь важно понять, что как только мы определились (выбрали), какими исходными векторами (х1, х2) определена плоскость, куда будем опускать проекцию – все, модель по сути, уже зафиксирована. Это будет проекция в эту плоскость. И все выше сказанное относится только к тому, как перезадать эту плоскость так, чтобы
А) вычислительный шум минимально повлиял на процесс определения проекции – надо перезадать плоскость ортогональными векторами и
Б) минимизировать сам вычислительный шум нормировав вектора аргументов
См рис 4
Кстати, именно поэтому, шум совсем не так страшен при оценке параметров, когда аргументы независимы – ортогональны: плоскость аргументов при этом максимально устойчива (к вращению шумом) и еще менее страшен, если он ортогонален к Х-ам и у,( тогда в случае ортогональности к выходу у он не войдет в модель, потому что корреляция его ![]() равна нулю с выходной переменной.
равна нулю с выходной переменной.
А устойчивость плоскости – определяет точность полученной проекции (нашей модели) в этой плоскости.
Отдельно проблема коллинеарности может оцениваться близостью главного детерминанта матрицы аргументов к нулю.
Совместное влияние коллинеарности и разброса длин векторов аргументов отражающееся на погрешности вычисления оценок характеризуется понятием обусловленности матрицы аргументов.
Степень обусловленности снизу оценивается т.н. числом обусловленности матрицы равным отношению максимального и минимального собственных собственных чисел матрицы аргументов.![]()
Чем данное отношение больше тем хуже степень обусловленности
Вопрос – ведь данные уже с шумом, значит, уже плоскость определена на неистинных коррелированных аргументах и это уже плохо. И если теперь ортогонализировать вектора – то вроде как «поздно пить боржоми». Но модель полученная на ортогональных векторах будет лучшая с точки зрения того что
1. когда новые вектора приходят и мы их подставляем в модель – выражение модели их преобразует так, как будто мы посчитали модель на независимых некоррелированных векторах, т.о. минимизируя эффект вращения плоскости, на которой мы посчитали значение модели (проекции)
2. Минимизирует нормировкой одну из причин вычислительного шума (а если максимум на которой делим при нормировании меньше 1?).
Итак, для коррелированных аргументов при небольших М (10-20) и Р (2-3) возможно решать задачу структурно параметрического синтеза через полное описание, ортонормируя его в обобщенных аргументах (скажем обобщенные аргументы для МНК формируются как ортогональные полиномы Форсайта).
Но при реальных размерностях практических задач мы опять вынуждены возвращаться к алгоритмам шаговой регрессии, где должна быть предусмотрена ортогонализация и нормировка аргументов при расчете их оценок по МНК (алгоритмы с ортогонализацией Грамма – Шмидта ..).
Справка
Обусловленность систем линейных уравнений
Две на первый взгляд похожие системы линейных уравнений могут обладать различной чувствительностью к погрешностям задания входных данных. Это свойство связано с понятием обусловленности системы уравнений.
Числом обусловленности линейного оператора A, действующего в нормированном пространстве ![]() а также числом обусловленности системы линейных уравнений Ax = у назовем величину
а также числом обусловленности системы линейных уравнений Ax = у назовем величину
![]()
Таким образом, появляется связь числа обусловленности с выбором нормы.
Предположим, что матрица и правая часть системы заданы неточно. При этом погрешность матрицы составляет dA, а правой части — dу. Можно показать, что для погрешности dx имеет место следующая оценка (![]() ):
):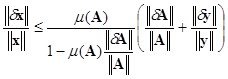
![]()
В частности, если dA = 0, то
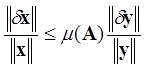
При этом решение уравнения Ax = у не при всех у одинаково чувствительно к возмущению dу правой части.
Свойства числа обусловленности линейного оператора:
1. 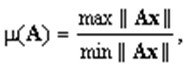
причем максимум и минимум берутся для всех таких x, что ![]() Как следствие,
Как следствие,
2. ![]()
3 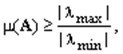
где ![]() и
и ![]() — соответственно минимальное и максимальное по модулю собственные значения матрицы A. Равенство достигается для самосопряженных матриц в случае использования евклидовой нормы в пространстве
— соответственно минимальное и максимальное по модулю собственные значения матрицы A. Равенство достигается для самосопряженных матриц в случае использования евклидовой нормы в пространстве ![]()
4. ![]()
Матрицы с большим числом обусловленности (ориентировочно ![]() ) называются плохо обусловленными матрицами. При численном решении систем с плохо обусловленными матрицами возможно сильное накопление погрешностей, что следует из оценки для погрешности dx. Исследуем вопрос о погрешности решения, вызванной ошибками округления в ЭВМ при вычислении правой части. Пусть t — двоичная разрядность чисел в ЭВМ. Каждая компонента
) называются плохо обусловленными матрицами. При численном решении систем с плохо обусловленными матрицами возможно сильное накопление погрешностей, что следует из оценки для погрешности dx. Исследуем вопрос о погрешности решения, вызванной ошибками округления в ЭВМ при вычислении правой части. Пусть t — двоичная разрядность чисел в ЭВМ. Каждая компонента ![]()
![]() вектора правой части округляется с относительной погрешностью
вектора правой части округляется с относительной погрешностью ![]() Следовательно,
Следовательно,
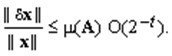
Таким образом, погрешность решения, вызванная погрешностями округления, может быть недопустимо большой в случае плохо обусловленных систем.
Итак – принципиально остаются две проблемы –
1.не обеспечивается обоснованная сходимость алгоритма к единственной (в случае модельного примера- истинной) структуре и
2. Не разрешено противоречие о неадекватности моделей шаговой регрессии на новых точках, не участвовавших при оценке параметров модели. Возможно ли, если не обеспечить такую адекватность при других способах синтеза моделей, то хотя бы найти путь к решению такой задачи (возможно и адекватность определить другим способом )
.
Для АШР даже в случае применения для МНК оценки процедуры Грамма-Шмидта не разрешается вопрос о единственности модели – просто оценки параметров становятся наиболее точными и несмещенными
Т.о. гарантированное нахождение всего множества подходящих решений в реальных задачах (при ![]() - количество линейных входных аргументов и степени ПП p >3) получим только после полного
- количество линейных входных аргументов и степени ПП p >3) получим только после полного
перебора всех подструктур полной структуры как в методе всех регрессий (у Дрейпера и Смита). Тогда мы найдем все те модели, в которых все аргументы входят с уровнем значимости не менее чем заданный. Со всеми выше описанными проблемами – а какая же из них, из этого множества та, которая действительно наша.
Можно еще добавить камень в огород АШР о неиспользуемой возможности вариации уровнем значимости для учета уровня шума в данных
Именно эту проблему предлагает решать МГУА с помощью введения понятия внешних критериев.
Необходимое примечание.
при ![]() все типы АШР МВИ, МГУА, другие целесообразные подходы, дают практически одинаково эффективные (или неэффективные) решения. Кривые критериев одинаково асимптотически стремятся к некоторому ненулевому уровню, при подходе к которому и определяется единственная модель.
все типы АШР МВИ, МГУА, другие целесообразные подходы, дают практически одинаково эффективные (или неэффективные) решения. Кривые критериев одинаково асимптотически стремятся к некоторому ненулевому уровню, при подходе к которому и определяется единственная модель.
Каждый из них это делает по своему, и определить адекватность метода по сходимости к нужной модели можно только построив соответствующий вашей задаче модельный пример.
Однако наиболее распространенный случай – это когда число точек невелико ![]() , тогда мы здесь решаем не переопределенную задачу
, тогда мы здесь решаем не переопределенную задачу ![]() (здесь точного решения нет и мы ищем среди плохих решений наилучшие), а близкую к определенной
(здесь точного решения нет и мы ищем среди плохих решений наилучшие), а близкую к определенной ![]()
![]()
![]() - вернее даже когда неизвестно, задача переопределена – определена или недоопределена. То есть включается сюда и совсем, казалось бы некорректная задача.
- вернее даже когда неизвестно, задача переопределена – определена или недоопределена. То есть включается сюда и совсем, казалось бы некорректная задача.
И наиболее эффективный подход к решению структурно-параметрического синтеза при данных условиях демонстрирует МГУА
Как видим нарушение уже первого условия порождает необходимомость разрешения проблемы множественности моделей не прибегая к процедуре полного перебора –надо предложить какой-то принцип, позволяющий найти путь к истинной или квазиистинной модели без полного перебора претендентов моделей.
Следующая проблема не менее реальна и еще более запутывает задачу поиска структуры. – проблема шума в данных – мы помним что при это нарушаются свойства проекционности аппарата МНК – нарушаются свойства оценок, но проблема в том что на зашумленных данных найти истинную структуру вообще может бытььпроблематично – если неизвестны х-ки шума и точки их приложения алгоритм будет тупо подстраиваться под шум.
Основная проблема – проблема необоснованности выбора структуры модели классическими АШГ многократно обостряется в связи с тем что порог используемый критерием Фишера в виде уровня значимости
на самом деле регулирует не только риск ошибки
– его выбор должен учитывать уровень шума и точки его приложения.
Ведь увеличение уровня шума например на выходе неизбено требует загрубить модель (не подстраивать ее под шум) а значит изменить уровень увеличить значимости с тем чтобы более жестко фильтровать апгументы в модель и ее упрощать .
Гораздо сложнее учесть шумы на входе тем более если они проходят нелинейное преобразование модели.
Однако методологически механизмов учета данных коррекций в агоритмах нет что делает выбор структур в условиях шума необоснованным.
Ну и последняя третья проблема из нашего списка когда у нас не
![]() а
а ![]() или не дай бог
или не дай бог ![]()
При иложении проблемы я буду неиного упрощать схему и критерии АШР буду говорить только о первом - Методе прямого отбора и о его критерии как минимуме остаточной дисперсии или максимуме точности модели- эти упрощения непринципиальны так как речь пойдет все о том же - о множкственности получаемых моделей и о необоснованности выбора структуры классическими алгоритмами.
И так принимаем в полном соответствии с критерием МНК синтезируемая модель должна стремиться к максимальной точности – мин МСЕ.
И так возращаемся к десткому вопросу при моделировании – что такое хорошо и что такое плохо. + То есть что такое хорошая модель и что такое плохая.
И вообще – мы часто подменяем суть задачи - хотим решать одну но не можем ее решить (получить качественную модель во всей области определения) - тогда решаем другую попроще, которую можем решить (точную только в известных точках) и пользуюмся ей как будто решили ту, более сложную
при нарушении условия 1. (а это также наиболее распространенный случай задач когда точек не тысячи а сотня или десяток –два -пять – особенно при структурно-пар синтезе ) мы говорим о применении большой полезной группы методов под общим названием МИМ –Методы индуктивного К----- моделирования ( в том числе МГУА – укр. изобретение - Ивахненко)
Метод группового учета аргументов
Понятие внешнего критерия. Критерий регулярности.
Таким образом появилась идея внешних критериев, идея подстройки структуры модели на новой, свежей информации, не использованной для оценки параметров. Эта идея позволяет разумно решить проблему множественности предлагаемых алгоритмами моделей, проблему, как найти среди этих моделей истинную или хотя бы ту которая, вела бы себя как истинная, касательно тех свойств которые нас интересуют прежде всего.
Формальное определение.
Под внешним критерием понимается мера наиболее важного для определения структуры модели свойства (точность аппроксимации или, прогноза, дискриминации или гладкости …..) вычисленная по информации, не использованной при оценке параметров модели.
Один из наиболее распространенных внешних критериев (критерий селекции структур) – это критерий регулярности ![]() .
.
Критерий регулярности.
Пусть полная выборка данных обозначена ![]() . Поделим ее на 2 подвыборки
. Поделим ее на 2 подвыборки ![]() и
и ![]() такие что
такие что ![]() ,
, ![]() ,
,
![]()
![]() называют обучающей выборкой (learning) на которой оцениваем параметры модели. Для нее нормированная среднеквадратичная ошибка
называют обучающей выборкой (learning) на которой оцениваем параметры модели. Для нее нормированная среднеквадратичная ошибка ![]() равна
равна![]() , где
, где ![]()
![]() - называют проверочной выборкой (training) на которой отбираем структуры. Нормированная среднеквадратичная ошибка
- называют проверочной выборкой (training) на которой отбираем структуры. Нормированная среднеквадратичная ошибка ![]() для той же модели равна
для той же модели равна ![]()
Что и называют критерием регулярности
В чем смысл критерия? - если модель без подстройки параметров (а только за счет структуры, ведь параметры оцениваем на А) неплохо угадывает прогноз или аппроксимацию на свежих точках (на В), то наверное и на некоторых других свежих (будущих - выборка С) точках следует ожидать неплохих результатов.
Данная идея и соответствующий подход впервые появились именно в Украине (кроме подхода кросс-валидейшн- о нем позже) – в школе ак. Ивахненко А.Г. в 1968гг. и получил название метода группового учета аргументов (МГУА).
Но идея МГУА гораздо шире критерия регулярности – это подход о необходимости выбора внешнего критерия для отбора структур.
А разнообразие внешних критериев дало возможность эффективного применения МГУА практически во всех типах задач моделирования – прогноза, аппроксимации, классификации подробно мы об этом поговорим видимо в другом курсе – технической кибернетики. Кстати именно А,Г, Ивахненко, 1959 автор этого термина.
Схема МГУА
В наиболее общем виде алгоритм МГУА нашел свое отражение в следующей обобщенной схеме :
![]()
![]()
![]()
![]()
![]()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. Общая схема алгоритма МГУА
Схему проиллюстрируем для варианта МГУА на основе внешнего критерия – критерия регулярностиГ– блок: генератор частных описаний (моделей претендентов)
А–блок расчет коэффициентов частных описаний на обучающей выборке А
В – блок: выбор лучших частных описаний по внешнему критерию ( ошибке моделей на проверочной В выборке данных)
р–количество частичных описаний, генерируемых на каждом ряду
F – показатель свободы принятия решений
К – количество рядов селекции
![]() - модель оптимальной сложности.
- модель оптимальной сложности.
Работа многорядного алгоритма МГУА
Генератор генерирует некоторое множество моделей претендентов по некоторому правилу, например, сочетая входные переменные по две ![]() , и формируя из них например, квадратичную форму. Тогда на выходе Г имеем
, и формируя из них например, квадратичную форму. Тогда на выходе Г имеем ![]() квадратичных форм (моделей претендентов). Для каждой из них на множестве А ищутся наилучшие оценки вектора
квадратичных форм (моделей претендентов). Для каждой из них на множестве А ищутся наилучшие оценки вектора ![]() параметров. Т.о. на выходе блока А имеем
параметров. Т.о. на выходе блока А имеем ![]() моделей претендентов
моделей претендентов
![]() .
.
В блоке В каждая из них оценивается на проверочной выборке В – и некоторая часть моделей – F штук пропускается дальше в следующий идентичный ряд (этап) алгоритма.
Качество модели оценивают ошибкой на В (и на совокупной W=A+B) по формуле нормированной относительной среднеквадратической ошибки: ![]() и
и ![]()
![]() . Далее для следующего ряда селекции (ГАВ) роль входных переменных Х играют отобранные Fштук (свобода выбора) моделей у.
. Далее для следующего ряда селекции (ГАВ) роль входных переменных Х играют отобранные Fштук (свобода выбора) моделей у.
Синтезпродолжается до тех пор пока уменьшается ошибка на В - ![]()
Если выборки А и В достаточно велики ![]() и представительны, то ошибка на В может стабилизироваться , - в данном случае разница между качеством алгоритмов размывается - все алгоритмы и МИМ и АШР дадут приблизительно одинаковое качество (без шума)
и представительны, то ошибка на В может стабилизироваться , - в данном случае разница между качеством алгоритмов размывается - все алгоритмы и МИМ и АШР дадут приблизительно одинаковое качество (без шума)
Если выборки малы - ![]() и данные зашумлены – то, как правило будем иметь выраженный минимум критерия ошибки на В.
и данные зашумлены – то, как правило будем иметь выраженный минимум критерия ошибки на В.
Что и необходимо для преодоления множественности решений,
Здесь выбирается
-не истинная модель ( как ее получить при неизвестных параметрах шума?)
- и не модель, получаемую АШР на всех точках в обучении. Вот тут конечно мы получим минимальную ошибку на всей выборке W, потому что модель подстроится под шум в рамках предоставленного уровня значимости.
- а модель оптимальной сложности – она более проста чем модель с истинной структурой и более проста и менее точна, чем модель полученная АШР на всех точках.
НО как правило имеет лучше ошибки на выборках С –экзамене. (потому что мы структуру модели настраиваем на свежих точках В, и поскольку В и С принадлежат одной генеральной совокупности возможно ожидать ее структурной настроенности и на другие свежие точки С).
То есть, проигрывая на точках В (не включая их в А) мы получаем лучшие ошибки на С.
Как видим этот исторически первый “многорядный алгоритм” не очень удачен так как допускает скачки сложности-2-4-8…..
Гораздо удачнее алгоритм с которым мы познакомились на практических занятиях, его название- релаксационный итерационный алгоритм – РИА МГУА
Основополагающие принципы МГУА
Рассматриваемая система алгоритмов (алгоритмических отображений) базируется на фундаментальных принципах самоорганизации, таких как эволюция, скрещивание, мутация, селекция, свобода выбора.
(биологически инспирированная когнитивная архитектура)
Присутствие некоторых из них очевидно (эволюция, скрещивание, селекция) некоторые для простоты далее не указаны (мутация).
Рассмотрим наиболее важные из них
1. Принцип неокончательности решения и свободы выбора
(принцип Д.Габора)
В различных реализациях МГУА МИМ используются следующие возможности:
1.На каждый последующий ряд пропускается не одно а несколько лучших решений.
Кроме того
-для избегания вырождения процесса используются случайные скрещивания с элементами предыдущих рядов и
- ограниченные мутации выживших элементов
2. Отбор по выживаемости в процессе эволюции
– алгоритм реализует (блок В) отбор структур - уже готовых, настроенных на новых условиях, которые встречает модель(точки В). .
Эти модели запускаются в дальнейшую эволюцию. Но что получается в результате? На фиксированном множестве данных решение дается
следующим утверждением
Принцип внешнего дополнения (принцип Геделя)
Структура модели выбирается при наименьшем значении внешнего критерия.
В соответствии с принципом внешнего дополнения Геделя при постепенном усложнении структуры модели значения внешних критериев сначала уменьшаются, а затем увеличиваются.
Таким образом в процессе алгоритмического отображения при постепенном увеличении уровня сложности модели получаем минимум внешнего критерия (внешнего дополнения), что и сигнализирует нам о найденной оптимальной структуре.
Базовое утверждение МГУА
Модель оптимальной сложности (МОС) находится при минимуме на внешнего критерия.
![]() То есть наилучшей структурой модели считается та при которой достигается минимум внешнего критерия
То есть наилучшей структурой модели считается та при которой достигается минимум внешнего критерия
И ее называют моделью оптимальной сложности.
То что минимум должен быть это понятно – нулем ошибка быть не может, а какая-то модель должна иметь минимум.
Почему минимум ошибки на В должен быть - еще соображения:
Закономерность которая связывает точки А и В, находящиеся в пространстве Х,, обусловлена существованием выхода У , а шум эту закономерность размывает.
До тех пор пока по мере усложнения модели структура и параметры согласованно улучшают ошибку, связанную с незашумленным выходом – будет улучшатся и ошибка на В.
Ну потому, хотя бы, потому что А и В - из одной генеральной совокупности, из выборки W с одними свойствами, обусловленными связью с незашумленным выходом У.
Как только процесс моделирования исчерпает возможности настройки на зависимость между У и Х и начнет подстраиваться под шум
- а подстройка, в основном, идет по точкам А, так как именно на А подстраиваются параметры; подстройка структурами, на В, - более грубый и слабый инструмент,
– то поскольку точки В не участвуют в параметрической подстройке на шум, то ошибка на В начнет увеличиваться ухудшатся.
Строгое аналитическое доказательство данного механизма существует, но займет много времени.
Важные свойства МОС –
1/ При увеличении уровня шума модель оптимальной сложности – что?
Упрощается – мы раньше начнем подстраиваться под шум, соответственно, раньше начнет ухудшаться ошибка на В
Следствие. при определенном уровне шума (1 ош) среднее становиться лучшей моделью.
2/ Особенно важно –
Модель оптимальной структуры (МОС), полученная по данным с шумом, оценивает незашумленный выход, как правило, точнее чем точная модель, полученная на данных с шумом точной структуре с оценками МНК по всем точкам.
“Как правило” - это значит при достаточном уровне шума, Для каждой задачи это свой уровень, но, как правило, достаточно совсем небольшого уровня шума, чтобы получить эффективность модели оптимальной сложности для оценки незашумленного входа перед моделью с истинной структурой оцененной по зашумленной выборке на всех точках.
Доказательство достаточно сложное, но а простенький пример, почему такое возможно – ниже
. ![]()
Синяя- данные без шума, черная – на данные наложен шум в том же спектре. Модель, как МО, среднее – лучше (в смысле суммы кв ошибок), чем точная структура, которая с помощью МНК своими параметрами подстраивается под шум (волнистый пунктир)– то есть при шуме модель необходимо упрощать именно поэтому МОС полезнее в смысле оценки истинных незашумленных значений выхода, чем модель на точной структуре с МНК оценками по всем точкам.
Основной вывод из базового утверждения МГУА такой
Уже при достаточно малых уровнях шумов модель оптимальной сложности (имея смещенные оценки параметров) оценивает незашумленный вектор выхода более точно чем оценки МНК точной структуры (которые при этом теоретически являются несмещенными )
Классификация и обзор алгоритмов МГУА и методов индуктивного моделирования.
![]()
Рис. Классификация алгоритмов и методов индуктивного моделирования
Классификацию естественно проводить в соответствии с блоками общей схемы работы таких алгоритмов - блоками Г, А и В.
1.По возможностям генератора моделей алгоритмы классифицируют
1.1.Тип решаемых задач:
1.1.1.Аппроксимации
1.1.2.Дискриминации (диагностики, классификации)
1.1.3.Прогнозирования
1.2. Класс применяемых опорных функций
1.2.1.Класс полиномиальных опорных функций
1.2.2.Класс гармонических опорных функций
1.2.3.Класс опорных функций с запаздываниями
1.3. Тип генерирующего алгоритма
1.3.1. Переборные алгоритмы
1.3.1.1. Полный перебор (комбинаторный алгоритм)
1.3.1.2 Направленный перебор (МАЛТИ - многоэт селекц-комбинорный алг)
1.3.2. Итерационные алгоритмы
1.3.2.1.Релаксационные итерационные РИА– шелудько, максо, риапдс (на полном дереве структур)
1.3.2.2.Многорядные (с квадратичными описаниями)
2. Расчет параметров частных описаний производится в соответствии с внутренним критерием алгоритма – наиболее известные
2.1. Оценки МНК (с подклассом сходящихся к ним оценки Шелудько)
2.2 . Оценки ЛП задач
3. Классификация алгоритмов по применяемому внешнему критерию селекции структур
3.1 Критерий Акаике
3.2.Критерий Шварца
3.3. Критерий “кросс-валидейшн”
3.4. Критерий регулярности
3.5.Критерии несмещенности (решений и/или параметров)
3.6. Критерии баланса
3.7. Специфичные (гладкость – мин сумм первых разностей, макс уг пер знака )
3.8. Комбинированные критерии
Многорядый упрощенный алгоритм метода группового учета аргументов - МУА МГУА.
Введение к схеме алгоритма
Алгоритм относится к т.н. разновидности итерационных алгоритмов с вложенными структурами.
Действительно, для произвольного ряда с номером «s» выражения для частных моделей (описаний) ![]() выглядят как вложенные матрешки:
выглядят как вложенные матрешки:
![]() (1*)
(1*)
где ![]() - лучшая модель «s-1» ряда селекции
- лучшая модель «s-1» ряда селекции ![]() - некоторый новый аргумент,
- некоторый новый аргумент, ![]() - параметр, который ищем по МНК.
- параметр, который ищем по МНК.
При заданнх критериях качества СКОА и НОСКОВ согласно которым порождается модель , генератор структур (1*) обеспечивает процесс,сходящийся на обучающей последовательности (куда, пока не понятно, но сходящийся), так как в худшем случае при ![]() =0 то
=0 то
![]() и алгоритм дает решение в точке стабилизации. - ухудшатся решение не может.
и алгоритм дает решение в точке стабилизации. - ухудшатся решение не может.
![]() Описание алгоритма
Описание алгоритма
Входными данными алгоритма есть входные ![]()
![]() и выходная
и выходная ![]() переменные, представленные матрицей данных
переменные, представленные матрицей данных ![]() и вектором выхода
и вектором выхода![]() , здесь -
, здесь - ![]() - количество входных переменных.
- количество входных переменных.
Рассматривается выборка из ![]() точек - это множество W, разделеное на обучающую A и проверочнyю (тестовую) B последовательности данных.
точек - это множество W, разделеное на обучающую A и проверочнyю (тестовую) B последовательности данных.
Подготовительный этап
Алгоритм формирует дополнительные нелинейные входные переменые - из исходных ![]()
![]() формируются –
формируются –![]() ,
, ![]() ,
, ![]()
Тогда расширенным множеством![]() входных переменных для алгоритма, будем иметь суммарное множество переменных:
входных переменных для алгоритма, будем иметь суммарное множество переменных:
![]() :
: ![]() ,
,![]() и их функций
и их функций ![]() :
: ![]() ,
, ![]() . Т.о
. Т.о ![]()
Далее формируется множество обобщенных входных переменных алгоритма ![]() как множество произведений
как множество произведений
![]() нулевого, первого второго, и др. порядков
нулевого, первого второго, и др. порядков
от переменных исходного входного множества Т:
![]() или иначе
или иначе ![]() .
.
Далее
При формировании частных моделей 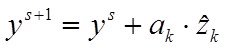 последовательно вводят в модель ортогонализованный вариант
последовательно вводят в модель ортогонализованный вариант ![]() обобщенных переменных
обобщенных переменных![]() , взятых из множества
, взятых из множества![]() , где количество множителей
, где количество множителей ![]() в слагаемом модели
в слагаемом модели ![]() , называют максимальным числом коррекций алгоритма -
, называют максимальным числом коррекций алгоритма - ![]() , количество элементов (мощность) данного множества
, количество элементов (мощность) данного множества ![]() обозначим через К.
обозначим через К.
На произвольном![]() -том этапе (ряду) алгоритма для каждого из F лучших описаний предыдущего этапа генеруеться моделей претендентов.
-том этапе (ряду) алгоритма для каждого из F лучших описаний предыдущего этапа генеруеться моделей претендентов.
Обычный путь расчета модели ![]() по двум агументам (
по двум агументам (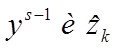 ) –нужно расчитывать три параметра:
) –нужно расчитывать три параметра:
![]() (2*)
(2*)
Уменьшим размерность векора искомых параметров. Напомним что размерность вектора параметров – это по сути размерность системы нормальных уравнений или что то же (напомним материал регрессионного анализа) - размерность матрицы ![]() ( только у нас тут переменные Уменьшение размерности
( только у нас тут переменные Уменьшение размерности ![]() єквивалентно уменьшению ошибки расчета параметров по известной нам формуле
єквивалентно уменьшению ошибки расчета параметров по известной нам формуле ![]() . Для уменьшения размерности уравнения (2*) эквивалентно сводится к уравнению типа (1*).
. Для уменьшения размерности уравнения (2*) эквивалентно сводится к уравнению типа (1*).
Этап центрирования входных переменных
Для этого, сначала входные обобщенные переменные ![]() и выходная
и выходная ![]() переменные центрируются по данным обучающей выборки А:
переменные центрируются по данным обучающей выборки А:
![]()
![]()
![]() , где
, где ![]() - значения средних на выборке А:
- значения средних на выборке А:
В дальнейшем волну в обозначениях переменных опусим подразумевая что переменные центрированы. Теперь в центрированных переменных
Уравнения модели можем писать в виде
![]() - от одного параметра избавились.
- от одного параметра избавились.
Можно показать что ниже описанная процедура формирования модели первого и последующих рядов позволяет находить модель в виде
где ![]() - лучшая модель «s-1» ряда селекции
- лучшая модель «s-1» ряда селекции ![]() -ортогонализированная к
-ортогонализированная к ![]() составляющая аргумента
составляющая аргумента ![]() ,
, ![]() -уже единственный параметр, который ищем методом наименьших квадратов.
-уже единственный параметр, который ищем методом наименьших квадратов.
Вы спросите ?– а нужна ли еще зачем-то отрогонализация (кроме уменьшения еще на 1 размерности вектора параметров, который ищем через МНК) -из ![]() получать
получать ![]() и таким образом пользоватся в дальнейшем ортогональной парочкой аргментов
и таким образом пользоватся в дальнейшем ортогональной парочкой аргментов ![]()
![]()
![]()
![]()
![]()
Рис1 Рис 2 Рис 3 Рис 4
Напомним, что параметры расчитанные на ортогональных входных аргументах (независимых) наиболее точно расчитаны
– для этого варианта расчета плоскость аргументов, куда опускается проекция, в пространстве расположена наиболее «устойчиво» относительно шума в данных – угол между векторами ![]() , на которых эта плоскость нами определяется - наиболее устойчивый - 900
, на которых эта плоскость нами определяется - наиболее устойчивый - 900
– таким образом шум данных на положение плоскости влияет в наименшей степени и таким образом посчитанная модель имеет наименьшую погрешность связанную с наличием шума.
![]() Формирования первого ряда моделей алгоритма
Формирования первого ряда моделей алгоритма
На первом этапе рассматриваются все одночленные модели приближения объекта, -
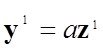 , (*)
, (*)
где ![]() перебираются из множества
перебираются из множества ![]()
Коэффициенты ![]() частных моделей первого этапа находим по МНК на точках обучения - множестве точек А, требуя приближения моделями (*) выхода
частных моделей первого этапа находим по МНК на точках обучения - множестве точек А, требуя приближения моделями (*) выхода ![]() ,
,
Вывод формулы МНК для одномерного случая повторим применяя ранее ипользовавшийся прием:
Нам необходимо приблизить ![]() Поэтому из (*) запишем
Поэтому из (*) запишем 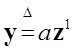 (**) . Отсюда, домножив слева каждую сторону (**) на вектор строку
(**) . Отсюда, домножив слева каждую сторону (**) на вектор строку ![]() (далее знак транспонир. будем опускать применив знак скалярного произведения векторов) получим для каждой к-той модели претендента
(далее знак транспонир. будем опускать применив знак скалярного произведения векторов) получим для каждой к-той модели претендента
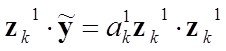 или
или 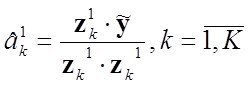
где точка – знак скалярного произведения векторов.
Тоже самое можем записать в виде
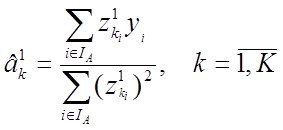 , где IA - множество индексов обучающих точек А выборки данных.
, где IA - множество индексов обучающих точек А выборки данных.
Выбрав по значению критерия селекции (о нем ниже) лучшую модель первого ряда, продолжим генерацию частных описаний на последующих рядах.
Произвольный s-тый ряд:
Далее будем искать ортогонализироваые частные модели описание в виде![]() ( 1)
( 1)
здесь![]() = индекс этапа,
= индекс этапа, ![]() - сформирован как лучший из F просчитанных путей нахождения обобщенной переменной путем образования произведения из расширенного множества входных переменных Т, при этом
- сформирован как лучший из F просчитанных путей нахождения обобщенной переменной путем образования произведения из расширенного множества входных переменных Т, при этом ![]() - это ортогональная
- это ортогональная ![]() составляющая вектора
составляющая вектора ![]() ,
,
![]() - лучшая модель предыдущего ряда,
- лучшая модель предыдущего ряда,
При условии центрирования переменных по среднему значению в частных частных моделях (1) как уже говорили свободный член равен нулю, а коэффициент при третьем члене
![]()
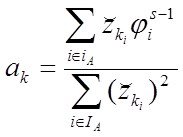 .
.
где вектор ![]() - это невязка модели предыдущего ряда а
- это невязка модели предыдущего ряда а ![]() - это ортогональная
- это ортогональная ![]() составляющая вектора
составляющая вектора ![]() .
.
Ортогональна добавка ![]() к
к ![]() из уравнения ( 1) связана с
из уравнения ( 1) связана с ![]() векторной зависимостью
векторной зависимостью
![]() =
= ![]() -
- ![]()
![]() (1*) см рямоугольный треугольник
(1*) см рямоугольный треугольник
где коэффициент ![]() определяется из из условия ортогональности;
определяется из из условия ортогональности;
![]() или
или 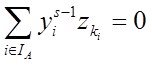 , отсюда
, отсюда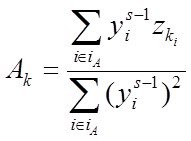
Смысл проведенного преобразования в том, что исходный вектор ![]() раскладывается по двум направлениям - по направлению вектора
раскладывается по двум направлениям - по направлению вектора ![]() , и ортогональном ему направлении
, и ортогональном ему направлении ![]() :
: 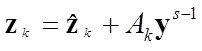 Рис. А
Рис. А
и в последующих расчетах (определение ![]() ) участвует только его часть
) участвует только его часть![]() , ортогональная вектору лучшей модели предыдущего ряда.
, ортогональная вектору лучшей модели предыдущего ряда.
Геометрически, вектор ![]() получается путем проекции вектора
получается путем проекции вектора ![]() (вектор проекции - невязка
(вектор проекции - невязка ![]() - обозначена пунктиром) на направление AВ, являющийся продолжением вектора
- обозначена пунктиром) на направление AВ, являющийся продолжением вектора ![]()
По сути эта процедура проекии является процедурой расчета методом наименш квадратов коефициету ![]() .
.
Сходимость алгоритма по моделям ![]() к вектору выхода
к вектору выхода ![]()
Сходимость последовательности . ![]()
![]() ....
.... ![]()
![]() ..... к исходному вектору
..... к исходному вектору![]() становится очевидной из рассмотрения прямоугольного треугольника формирующейся векторами,
становится очевидной из рассмотрения прямоугольного треугольника формирующейся векторами, ![]() ,
,![]() и
и ![]() . Здесь, как указывалось ранее
. Здесь, как указывалось ранее ![]() ,
,![]() - невязки лучших моделей
- невязки лучших моделей ![]()
![]() соответствующего ряда. Если учесть что в прямоугольном треугольнике
соответствующего ряда. Если учесть что в прямоугольном треугольнике![]() ,
,![]() ,
,![]() ,, вектор
,, вектор ![]() - гипотенуза, а вектор
- гипотенуза, а вектор![]() - катет, то становится очевидным невозрастающий характер последовательности невязок,
- катет, то становится очевидным невозрастающий характер последовательности невязок, ![]() ,
,![]() ,....
,....![]() ,
,![]() ,....а следовательно и сходимость последовательности векторов .
,....а следовательно и сходимость последовательности векторов . ![]()
![]() ....
.... ![]()
![]() ..... ....на обучающей последовательности к исходному вектору.
..... ....на обучающей последовательности к исходному вектору. ![]()
Критерий селекции алгоритма МИА МГУА
Выбор лучших моделей на каждом этапе осуществляется в соответствии с значения критерия селекции который есть смесь критерия регулярности и критерия баланса. В версии Ал критерий имеет вид
![]() +
+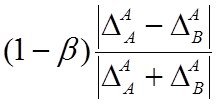 (***)
(***)
Здесь NRSS 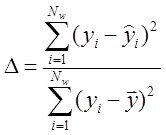 ,
, ![]() - ошибка на выборке А, посчитанная на модели, параметры которой оценивались на выборке А.
- ошибка на выборке А, посчитанная на модели, параметры которой оценивались на выборке А. ![]() -ошибка модели на выборке В, причем на модели, параметры которой оценивались на выборке А,
-ошибка модели на выборке В, причем на модели, параметры которой оценивались на выборке А,
Оператор завершает работу алгоритма после достижения минимума критерия селекции. Соответствующая модель являеться моделью оптимальной сложности.
Алгоритм включает возможность осуществлять разбиение выборки данных на учебную и проверочную последовательно: первые А –обучение, последующие В - проверка (для задач прогнозирования) или случайным образом (для задач идентификации).
В версии Ан критерий имеет вид
 +
+
-----------------
Один из наиболее интересных вариантов алгоритммов МГУА -
многорядный алгоритм, в узлах- комбинаторный
Перед тем как рассмотреть далее один новый подход к решению задач классификации нужно рассказать о тонкостях формирования "естественных" критериев классификации
Под "естественным" критерием будем понимать какую либо форму критерия качества классификации, использующий величину "процент правильно классифицированных объектов" (в отличии от косвенных критериев типа "Уилкса", расстояния Махалонобиса и прочих).
О критериях качества классификации
Перейдем к известной нам постановке задачи РО. класс ДА, лог , ...., МГУА
Имеется матрица об/св Х и дискретный выход У
Необходимо построить классификатор, наилучшим образом классифицирующий известные объекты.
Мы умеем решать такую задачу с помощью ДА, логререссии (бин выход), можем применить и нелинейные границы с помощью МГУА
Если мы для задачи разделения n классов зададим n идеальных классификаторов
gi(x) таких, что gp(xpi)>=gq(xpi) и gq(xqi) >= gp(xqi) (*)
для всех классов p,q=1.,...K и где объекты xpi принадлежат классу p и
объекты xqi принадлежат классуq
![]() Одним из возможных вариантов для МГУА есть задание идеального классификатора типа ступени - уровень А классификатора для своих точук и уровень В- для чужих.
Одним из возможных вариантов для МГУА есть задание идеального классификатора типа ступени - уровень А классификатора для своих точук и уровень В- для чужих.
Найденные по МГУА классификаторы gi(x) затем используются для распознавания по правилам (*)
Все рассмотренные нами методы решают задачу построения классификаторов исходя из задания некоторых целесообразно заданных критериев качества классификации. Казалось бы в данном вопросе нет подвоха - классификатор должен быть таков, что-бы наилучшим образом классифицировать - то есть в пределе давать 100% классификацию на всех классах. Однако не все так очевидно.
Ниже мы рассмотрим наиболее очевидные проблемы в
КРИТЕРИЯХ КАЧЕСТВА КЛАССИФИКАЦИИ
О вопросе, который к сожалению содержит очень неприятную путаницу и которая неизбежно доставит вам проблемы если вы будете работать в зарубежными источниками.
Вопрос связан с критериями распознавания и его распространенным вариантом, называемым чувствительностью и специфичностью. Поскольку проблема широко распространена, проникла даже в стандарты России и наши методики по характеристике тестов то нам четко необходимо ориентироватся в создавшейся ситуации.
Критерии качества классификации (некоторые проблемы)
Вопрос критерия оценки качества распознавания никогда не был простым, хотя это и не очевидно на первый взгляд. Мы уже говорили когда-то что задачи РаспОбразов (Кл) – частный случай задач типа РегрАн при которой выходная переменная имеет множество дискретных значений (или значений номинальной переменной) соответствующих классам рассматриваемой задачи.
Казалось бы, если РО -частный случай, то проблемы с критериями должны бы быть по крайней мере одного порядка с более общим механизмом – как в регрессии: – это точность и различные меры точности. Но оказалось что специфика задачи принципиально отразилась на критериях задачи.
Естественные меры точности (такие как максимум вероятности количества правильно распознанных объектов) довольно сложно запихнуть непосредственно в алгоритм получения классифицирующего правила. И в подавляющем большинстве случаев мы ищем правило по некоторым косвенным (например, дисперсионным) критериям, а затем полученный результат оцениваем по «естественному» критерию.
Классический пример - ДискрАн, которым мы уже пользовались в СПСС.
Различные дисперсионные критерии –
1.критерий разделимости классов  .
.
где ![]() - межклассовая дисперсия а
- межклассовая дисперсия а ![]() - внутриклассовая
- внутриклассовая
2.лямбда” Уилкса - максимум 
3. расстояние Махалонобиса Mahalonobis distance .
Оцениваем эффективность классификатора и , максимизируя расстояние Махалонобиса между ближайшими групповыми центрами. Расстояние между классами k1 и k2определяется по формуле:
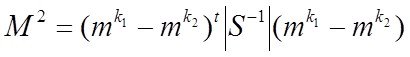
Или в скалярном виде
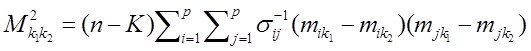
Р- кол переменных в классификаторе m – коорд центра по соотв переменной в соотв. классе
И тд
Получив решение, и оценив его с помощью «естественного» критерия - типа "процент правильно распознанных объектов", мы затем включаем рычаги влияния на косвенный критерий (меняем косвенный, меняем значения параметров критерия Фишера –F вкл.- Fискл. и тд), интуитивно и с помощью накопленного опыта, стремимся получить лучшие значения «естественного» критерия
Но и это не вся проблема . «Естественный» критерий тоже содержит ловушку специфики задачи классификации.
2. Противоречия между «естественными» критериями распознавания.
Казалось бы, вопрос, как «естественно» определять качество распознающей системы должно решатся в рамках известной для всех единственно правильной на все века стратегии Байеса. То есть для принятия решения с точки зрения
минимизации вероятности неправильного решения
каждого отдельного объекта классификации (*)
стратегия Байеса – единственно верная всегда и на века.
![]() Напомним что Байесовский подход в самом общем виде дает формулу пересчета априорной вероятности
Напомним что Байесовский подход в самом общем виде дает формулу пересчета априорной вероятности ![]() в апостериорную
в апостериорную ![]() , при известных плотностях распределения объектов в классах
, при известных плотностях распределения объектов в классах ![]() , что дает оценку вероятности появления каждого из
, что дает оценку вероятности появления каждого из ![]() классов в конкретной точке пространства признаков
классов в конкретной точке пространства признаков ![]() :
: ![]()
![]() Исходя из формулы Байеса и принципа правдоподобия для классификации объекта с минимальной вероятностью ошибки исходят из выбора максимума любого из следующих величин (выражений)
Исходя из формулы Байеса и принципа правдоподобия для классификации объекта с минимальной вероятностью ошибки исходят из выбора максимума любого из следующих величин (выражений)
1. ![]() - наибольшей апостериорной вероятности (АпсВ) класса
- наибольшей апостериорной вероятности (АпсВ) класса ![]() для данного объекта
для данного объекта ![]() или
или
2.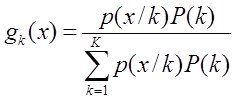 - выражение (Апстер.Вер.) через ф-лу Байеса
- выражение (Апстер.Вер.) через ф-лу Байеса
Или с учетом что для всех к знаменатели одинаковы -
3.![]()
или с учетом того что логарифмирование не смещает максимума функции – 4.![]() Эти решаюшие правила эквивалентны,
Эти решаюшие правила эквивалентны,
Интересно прослеживать варианты оптимальных решений даже для самого простого скалярного варианта задачи Дискриминации (разделения )- . когда нужно найти порог разделения (пару порогов) значений некоторого признака по байесовской стратегии и оптимизирующий какой-нибудь интегральный критерий распознавания. Оказывается тогда что его оптимум (по порогу) может быть где угодно, только не в точке П,
По Байесу в случае равенства априорных вероятностей (кол в классах) как видим слева от точки (линии) пересечения Р1(Х ) и Р2(Х ) находится область первого класса, справа – второго. – и опт. порог (в одномерном случае) с точки зрения критерия (*) находится в точке П.
Но поскольку разность плотностей слева существенно выше чем разность плотностей слева от П то интегральные критерии, учитывающие максимизацию правильного распознавания в целом по классам, в отдельности по каждому классу а тем более с учетом степени ущерба (различного по 1 и 2-ого родам ошибок) в смысле значения порога классификации могут находится где угодно но только не в точке П.
Действительно, как только мы начинаем привлекать дополнительные, вполне рациональные соображения, Байесовская стратегия оказывается лишь одной из многих возможных решений.
Т.о. вопрос: классификация проведена хорошо или не хорошо – вопрос меры качества распознавания совершенно не так очевиден как могло бы показаться вначале.
Интуитивно мы с этим сталкиваемся повсеместно – ДАспсс использует как минимум 5 рабочих критериев (внутри которых еше и Фишер зашит, которым мы и манимулируем с помощью порогов)а в конце концов ориентируемся на проценты распознавания в классах
Проблема чувствительности и специфичности
Ниже приведены общепринятые обозначение в нашей литературе используемые при определении соотношений качества Чувст и Специф
|
Заболевание |
||||
|
Присутствует ( 1 класс) |
Отсутствует (2 класс) |
|||
|
Тест |
Положительный |
a |
b |
a+b |
|
Отрицательный |
c |
d |
c+d |
|
|
a+c |
b+d |
|||
Процент правильного распознавания в этих группах
(а+ d)/( a+c+ b+d) )*100% (1)
И тут же понимаем что получив распознавание 90% (вроде ого-го) возможны случаи что при этом правильно не отделились ни одна точка первого (например) класса!!!!!!!,(больные) если их в общей выборке менее 10% (при этом правильно определилось 100% точек второго класса 0 здоровые).
Таким образом в задаче скрининга (типа профилактического медосмотра) не буде выделен ни один заболевший, хотя никто из здоровых обьявлен больным не будет.
То есть такой вроде естественный критерий " % правильного распознавания" на деле оказывается абсолютно здесь не пригоден. !!!!!! хотя на первый взгляд напрашивался именно такой подход оценки качества тестирования
Далее приведем меры " чувствительность" и "специфичность" тестов (и классификаторов) как они в своем большинстве присутствуют в отечественных работах:
Чувствительность (sensitivity):
доля правильных позитивных результатов теста в группе (в популяции) больных пациентов
Se = a/(a+c) (2) и
Специфичность (specificity):
доля правильных негативных результатов теста в группе здоровых пациентов
Sp = d/(b+d) (3)Это определение в РОСсийских и наших методиках эффективности тестов (а не только мат.стат литературе). Казалось бы и (2 и (3) надо максимизировать – так давайте максимизировать их сумму a/(a+c) + d/(b+d) и это будет правильно если цена ошибки первого рода ( пропуск заболевшего) такая же как цена ошибки второго рода ( обозвали здорового – больным).
Если нет – нужны веса у частных критериев – что говорит об соотношении ущерба от ошибок 1и2 родов и задача будет в таком виде критерия называтся задачей минимизации рисков.
Ну пусть цена ошибок одинакова.
Но ведь и тогда, как мы видели, при критерии "% правильного распознавания" (а это именно на него мы ориентируемся в ДАспсс, например) оценки моделей могут полностью терять смысл при значительных отличиях в количестве точек в классах и вместо критерия (1) надо ориентироватся отдельно на чувств (2) и специфичность (3) или их сумму.
С другой стороны если цены ошибок различны то еще нужно учитывать веса поощрения за несовершенную ошибку.
А вот теперь самое интересное.
Рассмотрим те же соотношения только в тех обозначения, как это принято на Западе
И так ![]()
И так наша славянская(ВАМ ЗНАКОМАЯ) версия
показатели:
1. Чувствительность - процент правильного опознавания больных ![]()
Специфичность–процент правильного опознавания здоровых ![]()
- процент правильной классификации «здоровых» (-) людей среди всех отнесенных классификатором к (-) «здоровым» имеющихся в выборке
http://ebm.org.ua/clinical-epidemiology/testing/sensitivity-specificity/
http://medspecial.ru/wiki
2.А вот как эти термины понимают в Западной литературе
Положительная точность классификатора ![]() - точность на больных
- точность на больных
Отрицательная точность классификатора ![]() точность на здоровых
точность на здоровых
Чувствительность 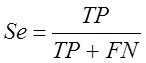 - насколько классификатор правильно работает на своих только (+) значениях
- насколько классификатор правильно работает на своих только (+) значениях
- это вероятность правильной классификации больных (+) людей среди всех отнесенных классификатоом к (+) больным имеющихся в выборке
Специфичность 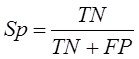 насколько классификатор правильно работает на своих только (-) значениях –
насколько классификатор правильно работает на своих только (-) значениях –
процент правильной классификации «здоровых» (-) людей среди всех отнесенных классификатором к (-) «здоровым» имеющихся в выборке
http://en.wikipedia.org/wiki/Sensitivity_and_specificity
а вот ссылочка компромиссная, так сказать - пожалуйста - и так можно и так можно - "как хотите так и можно"
http://vmede.org/sait/?page=3&id=Onkologiya_analiz_vasilev_2008&menu=Onkologiya_analiz_vasilev_2008
и 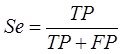 и
и 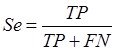 наз чувствительность а
наз чувствительность а
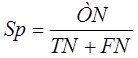 и
и 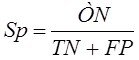 - специфичность
- специфичность
И это катастрофическая глупость так как максимизируя первую Чуств мы улучшаем показатель по больным, а вторая Чувств – улучшает показатель по здоровым (при фикс TP)
а по специфичности - наоборот – славянская формула при максимизации улучшает показатель по здоровым, а вторая, западная - по больным.
Теперь немного о ROCанализе
– еще один распространенный критериальный поход к выбору параметра решающего правила (обычно это порог)
Receiver operating characteristic, операционная характеристика приёмника
Можно сталнутся с 2-мя версиями изображения ROCкривой - левая (у нас) и правая (западная)
Или
Справа имеется в виду относительные True positive и False positive :TP/(TP+FP) и FP/(FP+TP)
–иностранные источники последовательно ссылются на правую версию. И правая схема пляшет с обозначением левой 1-SP при западном варианте определения SP
На каком этапе используется РОК анализ (это обычно одно-двух параметрическая задача).
Так при заданной структуре Логистичексой кривой ищутся ее параметря (коэфициенты ологисты) максимизируя площадь над диагнальюна рис.1. ТО получают уравнение погичты, которое возможно использовать для классификации при варьировании порога решающего правила. -от 0 до 1. Таким образом получаем кривую на рок графике. Для одномернй (одно или двупороговой оптимизации) в задаче дискриминации также для каждого значения порога получим точку на грвфике соответствующей кривой . Возниеъкает вопрос –какую точку на ней выбрать . Мне логически представляется – точка минимаольно удаленная от верхнего левого угла. Еще применяют точку наиболее уладенную от диагонали. Мера тоже может быть разная –Евклидова или Манхетеннская.
При этом мы сталкиваемся с несовпадением объективно оптимальной Байесовской стратегии распознавания отдельных объектов и рассмотренными выше интегральными критериями. БС в любом отдельном случае распознавания требует принятия решения которое соответствует максимуму вероятности что данная точка в к-том классе. Но принятие такого решения по каждому случаю распознавания вовсе не гарантирует наилучших решений в смысле рассмотренных выше интегральных критериев. В каких случаях эти стратегии совпадают – ROC – анализ , ****
Интересны вопросы соотношения БС и стратегий полученных в результате оптимизации интегр критериев, в том числе через РОК анализ
Очевидно что при совпадающих полностью плотностях, отличающихся только МО – и соответственно максимально близких формах гистограммм отлич только средними в класах порог по БС должен совпасть с макс (а+в)/(А+В)*100% процента распознавания
Интересны вопросы соотношения и сближения БС и интегр критериев, в том числе через критериев РОК анализа.
Разрешение конфликтов классификаторов
Рассмотренные выше выше вопросы жестко связаны с механизмом разрешения конфликтов классификаторов. (распонаваемые и нераспознаваемые ошибки классификаторов)
Мы помним что при использовании принципа «1против всех» по одному из косвенных (дисперсионных) критериев мы получаем дискриминантные функции (например ф-ции Фишера) Фi , Фi0 i=1,...K на основании которых формируются решающие правила Fi= Фi - Фi0 используемые в логике
![]() отвечает i-тому классу,
отвечает i-тому классу, ![]() другим классам (*)
другим классам (*)
Функции ![]() могут быть получены и непосредственно как в МГУА или логистической регрессии.
могут быть получены и непосредственно как в МГУА или логистической регрессии.
Вопрос нахождения наилучшего значения ![]() обеспечивающего наилучшее распознавание – это вопрос предыдущего параграфа. Как определим критерий так и получим соотв значение параметра
обеспечивающего наилучшее распознавание – это вопрос предыдущего параграфа. Как определим критерий так и получим соотв значение параметра ![]()
РЕКУРРЕНТНЫЙ АДДИТИВНО-МУЛЬТИПЛИКАТИВНЫЙ МНОГОЭТАПНЫЙ АЛГОРИТМ МГУА ДЛЯ ЗАДАЧИ КЛАССИФИКАЦИИ ОБЪЕКТОВ, ЗАДАННЫХ МНОЖЕСТВАМИ НАБЛЮДЕНИЙ
![]() Стандартная постановка задачи клаассификации предполагает описание объекта одной многомерной точкой в пространстве его признаков-свойств
Стандартная постановка задачи клаассификации предполагает описание объекта одной многомерной точкой в пространстве его признаков-свойств
Для такой постановки разработтан весь известный нам аппарат многомерной классификации - - ДА, логрегрессия, метод оп. векторов и тд.. Однако данной постановкой далеко не исчерпываются потребности практических задач классификации-диагностики в медикобоилогической области.
Вважным и актуальным случаем задачи классификации есть ее обобщение, когда объект характеризуется не одиночными измерениями в многомерном пространстве признаков, а их подмножествами, причем для каждого из них допускается частичное пересечение для объектов из различных классов.
![]()
Такая постановка задачи РО возникает при недостаточной информативности "портрета" объекта классификации с помощью одиночных многомерных измерений. Проблема распознавания становится тем более очевидной, если значения признаков объекта могут меняться в зависимости от значения некоторого неконтролируемого параметра объекта, или от состояния среды измерения. Проблема проистекает из возможности, как говорилось, частичного пересечения областей значений признаков в исходном пространстве измеряемых переменных для объектов из различных классов при различных состояниях среды, что влечет очевидную неоднозначность результата классификации.
Выходом из положения является описание объекта не одним, а множеством измерений, осуществленных при различных состояниях среды. Такой комплекс измерений позволяет более точно описать объект, как некоторое множество его состояний в исходном многомерном пространстве.
![]() Однако проблема классификации остается, так как, во-первых, разработанные подходы к распознаванию, как правило, предполагают однократное измерение признаков объекта, а во-вторых, мы допускаем частичное пересечение областей исходного пространства признаков для объектов классификации из различных классов (рис.1).
Однако проблема классификации остается, так как, во-первых, разработанные подходы к распознаванию, как правило, предполагают однократное измерение признаков объекта, а во-вторых, мы допускаем частичное пересечение областей исходного пространства признаков для объектов классификации из различных классов (рис.1).
Данные условия не позволяют при классификации объекта непосредственно использовать отдельные точки, а требуют разработки специальных подходов, где возможно оперировать множествами измерений, или характеристиками, полученными на основании этих множеств, или параметрами различных целесообразных разложений имеющихся характеристик в модельный ряд.
1. Постановка задачи.
Задан факт существования некоторого множества классов ![]() , представляющих собой конечные или бесконечные множества объектов:
, представляющих собой конечные или бесконечные множества объектов: ![]() ,
,![]() ,...,
,...,![]() . Известен факт, что множества
. Известен факт, что множества ![]() Æ при
Æ при ![]() . Нам классы
. Нам классы ![]() задаются, как их приближения
задаются, как их приближения ![]() ,
, ![]() , … ,
, … , ![]() через усеченные множества объектов, им принадлежащих:
через усеченные множества объектов, им принадлежащих:
![]() ,
, ![]() , … ,
, … , ![]() , где
, где
![]() ,
, ![]() , ….,
, …., ![]() .
.
Очевидно, что ввиду ![]() Æ, выполняется
Æ, выполняется ![]() Æ при
Æ при ![]() .
.
Предполагается, что объекты классификации ![]() , описываются в конечномерном пространстве
, описываются в конечномерном пространстве ![]() множествами
множествами ![]() векторов признаков
векторов признаков ![]() , образующими в пространстве
, образующими в пространстве ![]() соответствующие классам
соответствующие классам ![]() множества (области)
множества (области) ![]() . Причем, как указывалось ранее, в пространстве
. Причем, как указывалось ранее, в пространстве ![]() допускаются частичные пересечения, как множеств (областей), в которых формируются множества
допускаются частичные пересечения, как множеств (областей), в которых формируются множества![]() (по типу рис.1) так и множеств (областей)
(по типу рис.1) так и множеств (областей) ![]() .
.
Необходимо на основании обучающих подмножеств объектов ![]() из различных классов
из различных классов ![]() ,
,![]() ... ,
... , ![]() построить наилучшее правило классификации объектов из исходных множеств
построить наилучшее правило классификации объектов из исходных множеств![]() . Рассмотрим некоторые известные подходы к решения задач такого класса.
. Рассмотрим некоторые известные подходы к решения задач такого класса.
2. Анализ и обоснование подхода к решению задачи.
Исходя из особенностей практических приложений задачи распознавания образов традиционно формулируются в 2-х (в некоторых случаях эквивалентных) постановках:
- (1*) для многомерного пространства, где объекты классификации задаются одной многомерной точкой и
- (2*) для многомерного пространства, где объекты задаются, как подмножества многомерных точек (многомерных измерений).
Подавляющее число методов и алгоритмов распознавания образов были разработаны для решения задач классификации в первой постановке, для второго случая рассматриваются, как правило, подходы к сведению задачи к постановке (1*). Исторически, постановка (2*) рассматривалась, как задача распознавания кривых, или, в более сложном случае, плоских геометрических объектов (например букв).
И так, имеем множество кривых (одна из них приведена на - рис.2), заданных, каждая, множеством двухмерных точек ( или графиком - рис.2) и множество геометрических форм (рис.3), заданных на условной (пиксельной) сетке. Для решения задачи распознавания кривых чаще применяется координатный подход, для распознавания геометрических форм - пиксельный.
Рис.2 К задача распознавания Рис.3 К задаче распознавания
кривых плоской формы
Для описания первой задачи классификации в форме постановки (1*), кривые ( рис.2) определяются значением признака z1, как значением z(t1) ,..., значение признака zn принимается, как значение z(tn). Для описания второй задачи в форме постановки (1*), значениями переменных zi есть степени заштрихованности (яркости, цветности) соответствующего пикселя. Признаки интерпретируются, как случайные величины, задача нахождения классификатора сводится к получению распределений значений признаков в классах и нахождению дискриминантной функции позволяющей разделить эти распределения [1]. Однако существуют известные препятствия на пути классического подхода:
1.Построение многомерных (а в данном случае, очень многомерных) распределений требует значительных объемов обучающих выборок и выполнения достаточно жестких предположений о виде функций распределения (например нормальность)
2.Крайне желательно применить целесообразные процедуры сокращения размерности пространства переменных
3.В общем случае, когда объекты классификации задаются в многомерном пространстве, и при этом, представлены, каждый, подмножеством многомерных точек, решение задачи классификации требует построения плотностей распределения, размерностью, на порядки большей, чем в рассмотренных выше случаях. Таким образом, в общей постановке данный подход уже не конструктивен. Рассмотрим ниже еще два возможные пути решения проблемы.
Пусть в пространстве ![]() заданы обучающие подмножества
заданы обучающие подмножества ![]() ,
,![]() ... ,
... , ![]() объектов
объектов ![]() , где i - индекс класса, j - индекс объекта в классе. Каждый объект
, где i - индекс класса, j - индекс объекта в классе. Каждый объект ![]() описывается в пространстве
описывается в пространстве ![]() подмножествами
подмножествами ![]() многомерных точек (вектор-строк) матрицы объект-свойства
многомерных точек (вектор-строк) матрицы объект-свойства ![]() :
: ![]() . Пусть данные в матрице объект-свойства упорядочены по классам. Обозначим
. Пусть данные в матрице объект-свойства упорядочены по классам. Обозначим ![]() - количество объектов в k-том классе,
- количество объектов в k-том классе, ![]() - количество объектов в матрице. Тогда
- количество объектов в матрице. Тогда ![]() - количество точек в k-м классе, если количество точек в каждом объекте k-го класса одинаково и равно
- количество точек в k-м классе, если количество точек в каждом объекте k-го класса одинаково и равно ![]() , и
, и ![]() если количество точек в объектах
если количество точек в объектах ![]() различно и равно
различно и равно ![]() . Здесь
. Здесь ![]() и
и ![]() - подмножества точек в соответствующих классах и отдельных объектах класса k, соответственно. Общее количество точек (строк) в матрице данных
- подмножества точек в соответствующих классах и отдельных объектах класса k, соответственно. Общее количество точек (строк) в матрице данных ![]() . Существенным далее есть то, что для каждого объекта
. Существенным далее есть то, что для каждого объекта ![]() известна не одна, а некоторое подмножество точек
известна не одна, а некоторое подмножество точек ![]() , тут
, тут ![]() , где i - номер объекта в классе k. Существенным есть также то, что, в общем случае, области существования объектов
, где i - номер объекта в классе k. Существенным есть также то, что, в общем случае, области существования объектов ![]() и
и ![]() :
: ![]() , представленные в обучении подмножествами векторов
, представленные в обучении подмножествами векторов ![]() ,
, ![]() , могут частично пересекаться, при этом указанные объекты, могут принадлежать и различным классам [2]. Тогда возможно рассматривать следующие 2 пути для сведения постановки (2*) задачи классификации к постановке (1*):
, могут частично пересекаться, при этом указанные объекты, могут принадлежать и различным классам [2]. Тогда возможно рассматривать следующие 2 пути для сведения постановки (2*) задачи классификации к постановке (1*):
1. Необходимо определить свертку типа ![]() подмножества многомерных векторов
подмножества многомерных векторов ![]() в некоторую многомерную точку
в некоторую многомерную точку ![]() , таким образом, чтобы она однозначно определяла объект
, таким образом, чтобы она однозначно определяла объект ![]() в своем классе
в своем классе ![]() в исходном пространстве признаков z1…..zM. Определение такой свертки должно сопровождаться условиями наилучшей классификации объектов в данном классе сверток.
в исходном пространстве признаков z1…..zM. Определение такой свертки должно сопровождаться условиями наилучшей классификации объектов в данном классе сверток.
2. Пусть в исходном пространстве признаков z1…..zM описание объекта d дается подмножеством точек ![]() , неизвестной нам характеристики объекта fd(z1,…,zM)=0. Тогда указанных характеристик предполагается столько, сколько объектов:
, неизвестной нам характеристики объекта fd(z1,…,zM)=0. Тогда указанных характеристик предполагается столько, сколько объектов:
![]() (1)
(1)
Далее, рассматриваем тот случай, задачи, когда среди исходных переменных z1,…,zM возможно выделить выходную переменную.
Определим новое пространство признаков x, как пространство обобщенных переменных (ОП) x1, x2,…,xМ1 полученных из переменных исходного пространства![]() , при этом ОП x1, x2,…,xМ1 наилучшим образом представляют характеристики fd(z1,…,zM)=0 d=1,..,n по исходным множествам точек
, при этом ОП x1, x2,…,xМ1 наилучшим образом представляют характеристики fd(z1,…,zM)=0 d=1,..,n по исходным множествам точек ![]() уже как линейные свертки по хi. Тогда с точностью до переобозначения, характеристики (1) возможно искать в виде (2):
уже как линейные свертки по хi. Тогда с точностью до переобозначения, характеристики (1) возможно искать в виде (2):
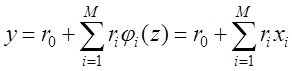 (2)
(2)
где, для простоты, М снова обозначает размерность нового пространства обобщенных переменных x для представления объекта d.
Тогда решение задачи классификации переведем в сопряженное пространству обобщенных переменных x, пространство параметров ![]() характеристик
характеристик 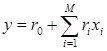 , что позволит рассматривать объекты d уже не как множества
, что позволит рассматривать объекты d уже не как множества ![]() , и не как характеристики fd(z1,…,zM)=0, d=1,..,n, а как точки в пространстве параметров
, и не как характеристики fd(z1,…,zM)=0, d=1,..,n, а как точки в пространстве параметров ![]() [2]. Отдельные точки rdуже однозначно определяют объекты d ввиду отсутствия полностью совпадающих подмножеств
[2]. Отдельные точки rdуже однозначно определяют объекты d ввиду отсутствия полностью совпадающих подмножеств ![]() . В дальнейшем предполагается классифицировать объекты d, как точки rd в пространстве параметров
. В дальнейшем предполагается классифицировать объекты d, как точки rd в пространстве параметров ![]() .
.
Ниже рассматривается второй из указанных путей для перевода исходной задачи в постановке (2*) к постановке (1*) построения классификатора. Возражением для применением данного похода могут быть соображения по поводу возможного нарушения гипотезы компактности и сопутствующих проблем, связанных с выбором меры близости в полученном пространстве R при решении задачи классификации. Однако риск данных проблем существует в любой задаче и обоснованность подхода подтверждается, или не подтверждается результатами классификации на проверочной и экзаменационной выборках данных. Близкий по постановке подход рассматривался в задаче диагностики нарушений работы сердечной мышцы при выделении признаков, как параметров разложения сигнала электрокардиограммы в ортогональный дискретный ряд Кравчука [3]. Другим примером использования указанного подхода в исходном пространстве Z фазовых координат являются работы [4,5] по применению методов классификации для оценки областей параметров устойчивости динамических систем. К этому же пути решения задачи принадлежит предлагаемый подход, когда при нахождения наилучшей структуры параметрического пространства характеристик объектов d предлагается использовать метод группового учета аргументов [6].
3. Рекуррентныйаддитивно-мультипликативный многоэтапный алгоритм (РАММА) МГУА
Ключевым моментом в реализации изложенного выше подхода есть задача определения единой, наилучшей для всех известных объектов полиномиальной структуры (2). Решение данной задачи целесообразно осуществить в рамках направления моделирования, известного, как метод группового учета аргументов - МГУА [6]. Существует большое количество работ, посвященных развитию, оптимизации различных алгоритмов МГУА [6]. В [2], например, предложено искать указанную выше полиномиальную структуру с помощью версии комбинаторного алгоритма МГУА, адаптированного для одновременного поиска множества моделей единой структуры. Однако такой подход возможен только для класса задач достаточно ограниченной размерности. В [2] применение комбинаторного алгоритма оправдано размерностью расширенного пространства переменных m=8 и количеством объектов моделирования - порядка 150. Для размерностей, существенно больших, необходимо предлагать версии многорядных или многоэтапных алгоритмов МГУА. В настоящей работе для реализации целесообразной версии сокращенного перебора возможных структур моделей объектов классификации предложен рекуррентный аддитивно-мультипликативный многоэтапный алгоритм МГУА. Перебираемые структуры при этом имеют вид ![]() и образуют последовательно усложняющиеся описания, к каждому из (F) которых, на каждом k-том этапе, добавляется лучшая, по внешнему критерию, обобщенная переменная (ОП)
и образуют последовательно усложняющиеся описания, к каждому из (F) которых, на каждом k-том этапе, добавляется лучшая, по внешнему критерию, обобщенная переменная (ОП) ![]() , генерируемая, как член полного полинома вида
, генерируемая, как член полного полинома вида
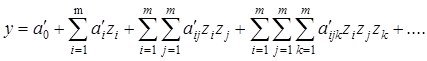 (3)
(3)
где, ![]() - переменные расширенного множества исходных переменных.
- переменные расширенного множества исходных переменных.
Рассмотрим основные этапы предлагаемого алгоритма
1. Предварительная обработка данных.
1.1 Формирование матрицы расширенного множества переменных. Расширение обеспечивает лучшую способность алгоритма к отражению моделируемых свойств объектов классификации. Здесь реализовано расширение исходного множества переменных ![]() дополнительными переменными
дополнительными переменными ![]() ,
, ![]() ,
, ![]() . Обозначим далее, для простоты, переменные из расширенного множества, снова через
. Обозначим далее, для простоты, переменные из расширенного множества, снова через ![]() .
.
1.2 Формирование матрицы обобщенных переменных (ОП). Каждая из ОП является одним из возможных произведений уже существующих переменных расширенного множества переменных, как членов полного полинома (3) заданной максимальной степени p.
Известно, что число членов такого полинома определяется (4), где m – количество аргументов (переменных)
![]() (4)
(4)
Далее, по аналогии с [6], возможно сформировать в (р+1) системе счисления ряд чисел (обозначим его, как ряд "S"), каждое из которых будет определять вид соответствующей ОП. В отличие от [6], генерируются последовательно десятичные натуральные числа и переводятся в (р+1) систему счисления. Будем игнорировать те из них, для которых сумма цифр данного числа в десятичной системе будет более (p+1). Сформированный таким образом ряд из S чисел есть табличное отображение полинома. Действительно, каждой ОП из полинома (4), соответствует некоторый член ряда "S". В каждой ОП участвует столько сомножителей, сколько имеет разрядов соответствующее число ряда "S". Каждый сомножитель, есть исходная переменная, десятичный индекс которой есть место по порядку разряда числа ряда "S", а его степень - значение в данном разряде.
1.3. Переход к матрице центрированных переменных. Позволяет отбросить свободный член в искомой структуре, вплоть до момента ее окончательного определения. После нахождения оптимальной структуры выполняется обратный переход к исходным переменным и рассчитывается свободный член полученной модели.
Центрирование осуществляется по среднему обучающей выборки в данном объекте:
![]() ,
, ![]() (5)
(5)
2 Формирование информационной матрицы ![]() максимального размера для каждого объекта. Этап позволяет избежать повторных расчетов при формировании исходных данных для нахождения параметров каждой новой структуры.
максимального размера для каждого объекта. Этап позволяет избежать повторных расчетов при формировании исходных данных для нахождения параметров каждой новой структуры.
3 Организация перебора вложенными структурами.
Для генерации моделей используется дерево переборного алгоритма (рис.4). Ветви дерева соответствуют созданным ранее ОП. На каждом ряду алгоритма реализуется движение по узлам дерева слева направо и сверху вниз. Для дерева, изображенного на рис.4, соответствующим образом полинома будет набор отображенный в табл.1. Для того, чтоб двигаться по данному дереву слева направо и сверху вниз необходимо восходить по соответствующему табличному массиву снизу вверх, - сначала по рядам, сумма значений которых равна 1, потом, где равна 2 и далее (до p+1).
Таблица 1 – Схема полинома
|
Z3 |
Z2 |
Z1 |
|
0 |
0 |
1 |
|
0 |
0 |
2 |
|
0 |
0 |
3 |
|
0 |
1 |
0 |
|
0 |
1 |
1 |
|
0 |
1 |
2 |
|
0 |
2 |
0 |
|
0 |
2 |
1 |
|
0 |
3 |
0 |
|
1 |
0 |
0 |
|
1 |
0 |
1 |
|
1 |
0 |
2 |
|
1 |
1 |
0 |
|
1 |
1 |
1 |
|
1 |
2 |
0 |
|
2 |
0 |
0 |
|
2 |
0 |
1 |
|
2 |
1 |
0 |
|
3 |
0 |
0 |
Рис. 4 – Дерево переборного алгоритма
Для первого и всех последующих уровней дерева в алгоритме введены степени свободы (F1 иF2), которые определяют максимальное количество лучших, по внешнему критерию, узлов на данном уровне, от которых продолжается поиск. Параметр F определяет количество моделей которые отбираем в процессе выполнения алгоритма.
Для каждой из сгенерированных структур:
3.1 Из полученной ранее полной матрицы ![]() для каждого объекта на обучающей выборке формируются информационные матрицы, соответствующие рассматриваемой структуре. Как впервые было предложено для алгоритмов МГУА в [7], для сокращения времени расчета параметров модели в данном алгоритме на всех рядах селекции, начиная со второго, обратные матрицы рассчитываются с использованием метода «окаймления»:
для каждого объекта на обучающей выборке формируются информационные матрицы, соответствующие рассматриваемой структуре. Как впервые было предложено для алгоритмов МГУА в [7], для сокращения времени расчета параметров модели в данном алгоритме на всех рядах селекции, начиная со второго, обратные матрицы рассчитываются с использованием метода «окаймления»:
Обозначив матрицу ![]() на n-той итерации алгоритма для конкретной структуры через An, напомним (8,9):
на n-той итерации алгоритма для конкретной структуры через An, напомним (8,9):
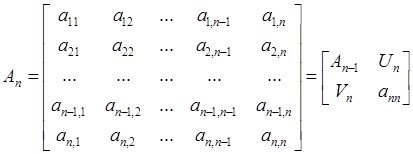 ; (6)
; (6)
Тогда обратную ей матрицу ![]() ищем:
ищем:
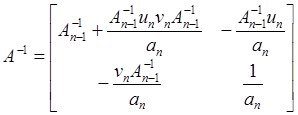 ; (7)
; (7)
3.2 Рассчитываем параметры моделей (коэффициенты при ОП в оцениваемой структуре) для каждого объекта на обучающей подвыборке (8)
![]() (8)
(8)
Количество формируемых структур ограничивается степенями свободы на каждом уровне. Поиск оптимальных моделей (ОП) не продолжается далее по ветке, если её узел не улучшил структуру.
Для полученной структуры рассчитывается критерий селекции и его значение сравнивается со значением критерия худшей структуры из F уже сохраненных в буфере (худшей из лучших). Если сравнение в пользу новой структуры - она замещает в буфере ранее отобранный вариант.
В программной реализации применено две целесообразные формы внешнего критерия:
1.Критерий селекции [2] , который базируется на значениях относительных нормированных среднеквадратических ошибок ![]() и
и ![]() для данной структуры моделей. Рассчитывается значение критерия (9), где
для данной структуры моделей. Рассчитывается значение критерия (9), где![]() – вес ошибок обучения,
– вес ошибок обучения, ![]() – вес несогласованности ошибок, а
– вес несогласованности ошибок, а ![]() – веса соответствующих классов.
– веса соответствующих классов.
 ; (9)
; (9)
 (10)
(10)
 (11)
(11)
2.Предлагается рассчитывать критерий селекции, который базируется на значениях дисперсий (12). Поскольку, конечной целью работы является именно классификация, то логичной есть оценка качества искомой структуры с точки зрения ее разделяющей способности. Такой критерий селекции представляет собой отношение суммы дисперсий внутри классов к значению дисперсии между центрами классов. Пусть Rj - множество точек ri в пространстве параметров моделей объектов классификации Rm, принадлежащих классу j, j=1,..,K , i=1,...,nj а ![]() - количество сочетаний из К по 2, тогда введем критерий в виде:
- количество сочетаний из К по 2, тогда введем критерий в виде:
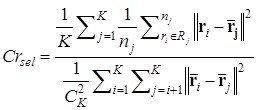 (12)
(12)
С учетом покоординатной дисперсии для m координат (p=1,...,m, где m - размерность пространства Rm ), понимая под нормой эвклидово расстояние между i-той точкой q-того кластера и его центром, выражение для нормы будет иметь вид (13), а (12) примет вид (14). Здесь для удобства, введено переобозначение: текущий номер класса q перенесли, как верхний индекс.
![]() (13)
(13)
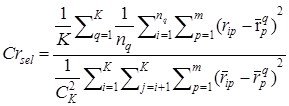 (14)
(14)
4.Лучшая структура (и мультипликативная, и аддитивная составляющие) определяются минимумом критерия селекции или «наращивание» структуры происходит до тех пор, пока критерий селекции будет улучшаться более, чем на некоторую минимальную заданную величину (предельное значение улучшения модели). После определения критерия селекции новая структура сравнивается с худшей из сохраненных в буфере и, при сравнении в пользу новой, замещает ее.
Для окончательно отобранных моделей выполняется расчет свободных членов полинома (15).
![]() ; (15)
; (15)
Выводы
Мы расмотрели подход к распознаванию объектов, заданных подмножествами строк матрицы объект-свойства. Подход предполагает построение процедур распознавания в пространстве параметров наилучшей структуры моделей объектов классификации, что позволяет перевести задачу в многомерное пространство, где каждый объект представлен точкой в пространстве параметров своей модели. Для нахождении такой структуры разработан рекуррентный аддитивно-мультипликативный многоэтапный алгоритм МГУА.
Для увеличения точности искомых моделей предусмотрено расширение исходного множества переменных. Для организации передвижения по проверяемым структурам образуется дерево переборного алгоритма с использованием вложенных структур. Организованная последовательность вложенных структур позволила использовать подход [9] и применить для расчета параметров моделей рекуррентные формулы метода «окаймления», что существенно увеличило быстродействие алгоритма.
Применено два варианта внешнего критерия алгоритма: критерий селекции [2], основанный на значениях относительных нормированных среднеквадратических ошибок для модели и предложен критерий селекции основанный на значениях внутриклассовой и межклассовой дисперсий в пространстве моделей объектов классификации.
В результате, осуществленный переход в параметрическое пространство моделей заданных объектов позволяет применять затем весь набор разработанных в настоящее время методов многомерной классификации.
----------------------------------------------------------------
перед пса -Мы теперь владеем МГУА - сравнительно надежным и эффекивным аппаратом моделирования, его возможно будет обратить на нужды анализа – причинно-следственного анализа, учтя если будет необходимо, нелинейный характер связей между переменными
Мы достаточно полно рассмотрели различные задачи моделирования (более полно мы это сделаем в конце курса в обзорном варианте )
а теперь вспомним что перед любой задачей оделирования необходим (более полно в обзорном варианте мы о убедится что причинноследстенные связи действительно направленыв сторону моделируемого выхода.Иначе получаемые модели могут оказатся лишенными физического смысла.
ПСА
Вернемся к нашей таблицеиэтапов моделирования и подробноее распишем первый (декомпозиция ) и второй (ПСА) этапы. Затем рассмотрим одно из приложений ПСА к решению задачи классификации
Напомним что в этой таблице мы приводим этапы (по столбцам) решения задачи моделирования - мы рассмотриваем те процедуры что стоят между неформальной постановкой проблемы и окончательным мат решением задачи моделирования.
Обобщение моделирования в виде обзорная таблицы
задачи А-С =Анализа – Синтеза ![]()
![]() Ан обСМ Ан модели
Ан обСМ Ан модели![]() Декоб ПСС СМ Анмодели
Декоб ПСС СМ Анмодели
|
Декомпозиция объекта |
Прич.Следств.Анал. |
Синтез модели |
Анализ модели |
|
Дек сост из ВертД и ГорД то есть осуществляем разбиение объекта на целесообразные верт и гор-ые уровни
ВД- определяет кол целесообр вертикальних уровней иерархии объекта ГД –определяет колич и содержаниеие переменных на фиксированном верт -----уровне, позвол-щих адекватно отразить его работу |
для каждого уровня реш
определить –список экзогенных перемен.объекта - у=(Х)-что из сист вычеркн. –матр . и граф ПССвязей (исс-ем пары переменных} –спис пер. на вх. АлгМо Когда зад. решены на кажд уровне можно прист к мод |
||
|
Наим разр апарат, В СА – рассм мех гор и верт Д, крит Д, Целев Д. пример шарики (в СА) |
Механизмырешения: –прич по Грейнджеру –нелин конкур. модели –КросКорФункции |
Пройдемся по таблице останавливаясь коротко на позициях которым в дальнейшем не будем уделять внимания за неимением достаточного времени.
==Адекватность модели-Чувствительность модели-Регулярность модел-Устойчивость модели (трпектории
З-4 3л более подробно- Декомпозиция объекта
Наименее теоретически разработанный аппарат с точки зрения адекватности результатов анализа сложных систем.
Упирается в необходимость перебора огромного количества вариантов структур для различных «точек зрения» на исследуемый объект.
Опирается на сомнительную, но часто единственную практически пригодную концепцию моделирования СлСи, т.н. принцип моделируемости.
Модель СлС (адекватно) представима по совокупности частных моделей.
Что-бы осознать конструктивность этого принципа и его слабость приведем
2 примера
1. Модель предприятия (мед. пром.-и :) )
Точки зрения на объект (частные модели) и соответств декомпозиции
П Е Р Е Б О Р
Эконом М Технол М Информац М …… Целевая Д
Все эти модели по совокупности должны адекватно представлять предприятие
– как правило на практике это удается.
Но представим себе необходимое количество вариантов структур которое может быть необходимо опробовать для того что-бы выбрать наилучший …… (концепция ИМ)
2. Модель Электрона:- Как волны и - Как частицы
Долгое время существовали эти модели «по совокупности» - в рамках принципа моделируемости. Пока не была создана единая энергетическая модель електрона, объединившая обе частные модели и проявляющая себя частицей на одном ЭУ и волной на другом ЭУ.
Для разбиения объекта (Д) применяют понятие критерия Дек.
Определение –
Критерий декомпозиции - это характеристика, на основе которой производится разбиение. Характеристики – например по времени, по функциональному назначению, по цели достижения, по механизму передачи информации и тд. Критериев декомп. множество. Относительно их применения определены следующие положення:
1. Конкретный вариант дек. системы определяется порядком применения критериев дек.
2. На каждом уровне Д необходимо применять только 1 критерий дек.
Для иллюстр этих принципов приведем утрировано простой пример
Есть шары двух цветов - белые и черные, сделанные из различных материалов – дерева и железа. Критерии дек. – «цвет» и «материал»
задача:
структурировать шары с помощью критериев декомпозиции.
Существует три варианта решения.
![]() Первый вариант - можно разделить все шары на
Первый вариант - можно разделить все шары на
белые, черные,
деревянные, железные.
Дерево шаров,
изображено= Рис.1
Второй вариант:
шары сначала делим по «цвету» на белые и черные,
а потом – по «материалу» - на деревянные и железные.
Третий вариант.
Шары сначала делятся по «материалу», а потом по «цвету».
материал и цвет являются критериями дек. (рис. 2.) 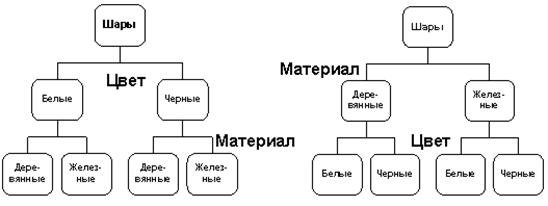
Второй и третий вариант разделяют (классифицируют) объекты исчерпывающе. На нижнем уровне дек. в каждый класс попадают объекты, у которых являются общими все значения примененных критериев и отличающиеся от объектов других классов, значением хотя бы одного критерия.
Первый вариант неправильный, так как на окончательном уровне Д. в нем элементы пересекаются – здесь каждый шар может х-тся одновременно двумя различными значениями некоторого критерия.
Причина - при структуризации шаров на 1 ур Д были одновременно применены два критерия классификации.
Отсюда следуют два правила Д:
1. На одном уровне Д. применяется только один критерий декомпозиции.
2. Для одной системы можно построить несколько вариантов "деревьев" в зависимости от различной последовательности применения критериев декомпозиции.
Рекомендуют на верхних уровнях Д. использовать более существенные (важные) критерии декомпозиции. Понятие важности критерия формируется в теории экспертных оценок.
Другой Примердекомпозиции поближе к биосистемам - экосфера
Попробуем представить основные уровни экосферы разумно ограничив размерность моделирования. Определение.
– экосфера это экологическая оболочка Земли, как совокупность объектов и свойств, создающих условия для развития биологических систем. Пространственно включает в себя слои атсмосферы, гидросферу, часть литосферы и распространенную в них биосферу.,
И так объект - срез ограниченной размерности экосферы
Представим его как Декомпозицию(иерархическую функциональную модель) по уровням трофики (уровням преобразования материи и энергии)
С большой долей упрощения такую модеь можно представить следующим образом
раст О2![]() жв
жв![]() чел-прмшл
чел-прмшл![]() СО2 отх
СО2 отх![]() 3 ур среды
3 ур среды
![]()
![]()
![]() уравнения св. уровни 2-3
уравнения св. уровни 2-3
среда![]()
![]()
![]() растения
растения![]() О2 отх
О2 отх![]() 2ур.ср уравнения связ. уровни 1-3
2ур.ср уравнения связ. уровни 1-3
![]()
![]() уравнения связ. уровни 1-2
уравнения связ. уровни 1-2
гумус![]() пр. гния
пр. гния ![]()

![]() среда 1ур среды
среда 1ур среды
Учитывая приращения и скорости приращений переменных данную экологическую систему можно представить как
двух уровневую систему трофических процессов с перекрестными связями – обычно ур типа Х-Ж
Обозначим х(t)- численность добычи, у(t)- численность популяции хищника.
Модели, которыми описывают данную систему
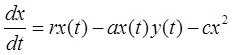 всегда заст объяснять логику ур-й
всегда заст объяснять логику ур-й
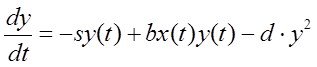 Это так называемая модель Вольтерры двух зацепленных уравнений.
Это так называемая модель Вольтерры двух зацепленных уравнений.
Логика уравнений:
- в первом ур. понятно, почему скорость роста популяции пропорц. ее численности – больше пап и мам – быстрее темп размножения.при этом. Жертвы,: обладают неограниченным источником питания (ограниченным лишь квадратичным членом моделирующим ограничение по плотности заселения территории)
- Популяция хищников увеличивается лишь за счёт поедания ими жертв-сами по себе они вымирают . Поэтому чем больше популяция хищника тем больше коннкуренция у них за жервы – поэтому первый член второгоу равнения со знаком -.
а вот со вторым слагаемым как? Если бы в первом ур. просто было ( –у)-то понятно чем больше хищника тем медленнеее темп роста популяции жертвы – но причем здесь –аху (во втором +вху)
Дело в том что произведение ху пропорионально вероятности встречи хищника и жертвы и только тогда хищник имеет возможность сьесть жертву – поэтому наличие здесь –ху это более точно чем просто –у.
Третий член ограничмивает рост популяций в связи с перенаселенностью территории собственной популяцией
2. Для описания таких систем применяли и более простые варианты моделей – модель Брауна и Гордона
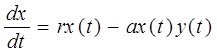
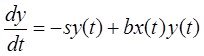
В заключение - вспомним ![]()
![]() Решение по Д. в практической исследовательской задаче связана как правило с огромным объемом перебора структур и с привлечением затем для выбора варианта либо экспертных оценок либо имитационного эксперимента ИМ.
Решение по Д. в практической исследовательской задаче связана как правило с огромным объемом перебора структур и с привлечением затем для выбора варианта либо экспертных оценок либо имитационного эксперимента ИМ.
Типичная схема имитационной модели:
Рис. 1 Схема имитационной модели
Здесь
МОЭП - мат-ое описание процесса и алгоритм его решения
АИВВ - алгоритм имитации внешних воздействий
АОР - алгоритм обработки результатов
АРИЭ - Алгоритм расчета и управления имитационным експериментом
О вер моделировании отдельная лекция
О ИМ – некорр перевода
4л
------ Следующий столбец 2
Выше мы связали (интуитивно) в моделях уровней, что должно быть на входах процессов, что должно быть выходными процессами уровня.
Таким образом мы зашли в компетенцию второго столбца Анализа.
Действительно роль Дек. - произвести целесообразное разбиение на вертикальные уровни иерархии (ВД) и получить разбиение на каждом горизонтальном уровне (ГД) – то есть получить исходные кирпичи из
![]() которых на каждом уровне будем лепить модели данного уровня.
которых на каждом уровне будем лепить модели данного уровня.
Когда (умозрительные) разбиения для объекта произведены
возможно строить модели на каждом уровне и затем увязывать уровни в рамках целостной модели объекта.
Т.о. в результате мы считаем что для наждого уровня определен список переменных с помощью которых возможно описать ф-ние данного уровня.
Соответственно данные разбиения должны сопровождать таблицы данных называемые обычно матрицами объект=свойства. это и есть входные данные для выполнения задач столбца ПСА и столбца СИНТЕЗ.
Как я уже говорил, задачи стлбца ПСА удобно рассматривать на примере моделей прогноза. Поэтому перед рассмотрением аглоритмов ПСА целесообразно подробнее познакомится со спецификой задач моделирования прогнозирующих моделей.
Наиболее часто уравнения прогноза записывают в одной из следующих форм
Уn+1=f(yn,yn-1,...,yn-k) (1) или
уn+1=f(yn/0-k,x1.n/0-k,...,xm.n/0-k) (2)
следуюшие проблемы: как мы говорили
1. Если моделируется не одно уравнение прогноза, а система уранений на данном горизонтальном уровне
x1.+1=f(x1.0-k,x2.0-k, ... xm.0-k)
x2.+1=f(x1.0-k,x2.0-k, ... xm.0-k
...........................................
xm.+1=f(x1.0-k,x2.0-k, ... xm.0-k (*)
то возникает необходимость определения, что из (*) доказуемо необходимо моделировать – то есть найти список экзогенных переменных обьекта
- решение можно получить ести решенызадачи ПСА №2. – все связи от переменной это єкзогенная переменная
2.составление и иссл первичных статистических ПССв
графы ПСС и как следствие
3. Списки переменных на входе алгоритма моделирования – этим мы оптимизируем задачу структ- парам синтеза, уменьшая список на входе
алгоритма мод-я и уменьшая время реш задачи, увеличивая адекватность моделей.
Как именно решать вопрос направления связи - об этом отдельный раздел нашого курса
… …………………………..
Первая форма
Для (1)![]()
![]()
То есть прогнозирующая модель -это механизм прогноза буд. значениу по прошлым значениям. В случае (1) – это прогн значения ряда по его же прошлым значениям.Покажем, тесную связь (алгоритмическую) между статической задачей моделирования и задачей мод-я модели прогноза
У=f(X) Yn+1=f(Yn,n-k)
,УУ…У У+1,У0 У-1…У-К У+1,У0 У-1…У-К
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() У Х
У Х У
У 
Ось так алгоритмічно споріднені задачі моделювання статичних і прогнозних моделей.
![]() Як визначити заздалегідь, які запізнювання перспективні для введення в модель прогнозу уn+1=f(yn,yn-1,...,yn-k) (що дуже бажано для адекватності та хороших прогнозуючих властивостей)
Як визначити заздалегідь, які запізнювання перспективні для введення в модель прогнозу уn+1=f(yn,yn-1,...,yn-k) (що дуже бажано для адекватності та хороших прогнозуючих властивостей)
Зрозуміло , що прогноз моделі ( 1 ) ПОВИНЕН спиратися на автокореляційна ефект - тобто наскільки сильно пов'язані між собою
сусідні значення настільки точну і интервально довгострокову модель прогнозу можливо побудувати .
Зрозуміло й те , що для побудови такої моделі корисно дослідити автокорреляційну функцію ряду. Вона безпосередньо вказує на ступінь сили лінійного зв'язку сусідніх значень .
Формула АКФ проста
- Це Коефіцієнт Кореляції ряду з самим з собою зсунутим на часовий зсув k - тобто це Коефіцієнт кореляції ( k )
Формула
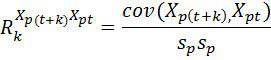
де ![]()
![]() - виборочні коварації та виборочні оцінки дисперсії відповідних рядів . Индекс зсуву може и запізнюватися и упереджати але так як це один и той же ряд то АКФ – ФУНКЦІЯ парна – симметрична відносно k
- виборочні коварації та виборочні оцінки дисперсії відповідних рядів . Индекс зсуву може и запізнюватися и упереджати але так як це один и той же ряд то АКФ – ФУНКЦІЯ парна – симметрична відносно k
Деталізуючи виборочні![]() одержуємо формулу для
одержуємо формулу для
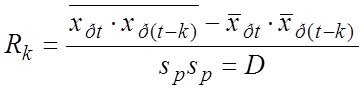 інакінецьякщо повністю розкрити формулу через значення ряду то маємо розрахунок через зміщенудисперсію -
інакінецьякщо повністю розкрити формулу через значення ряду то маємо розрахунок через зміщенудисперсію -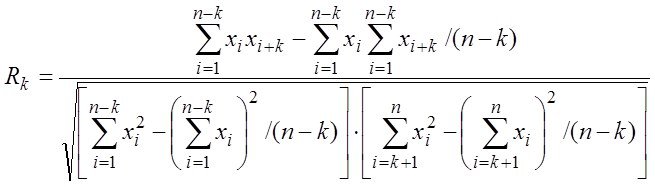
або розрахунок через незміщену дисперсію -
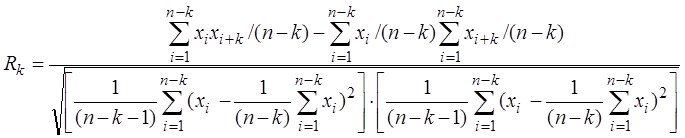
Вид автокореляційної функции тісно пов'язаний зі виглядом самого ряду.
АКФ для "білого шуму" (стаціонарний випадк. часовий ряд ), при k > 0 , також утворює стаціонарний часовий ряд із середнім значенням 0 .
Для стаціонарного випадкового ряду АКФ швидко убуває із зростанням k .
АКФ , що повільно спадає відповідає наявності виразного тренду у вихідному ряду
Якщо є періодичність у графіку АКФ то і в початковому ряду також присутні періодичності на відповідних періодах , але !!!!!!!!!!
на графіку вихідного ряду ці періодичності можуть бути не видно , -
вони можуть бути завуальовані –
- присутністю тренда ,
- іншими періодичностями або
- великою дисперсією випадкової компоненти
цим і цінна АКФ - це часовий аналог частотного аналізу
Розглянемо приклади автокореляційної функції :
• на рис. представлений графік АКФ ряду N , що характеризується помірним трендом і неясно вираженою сезонністю ;
с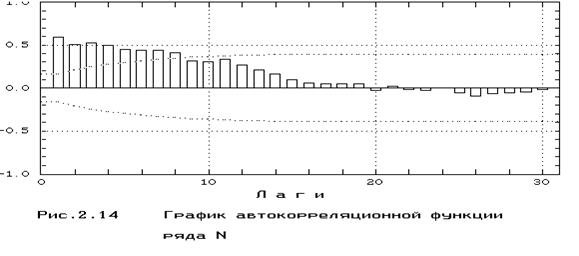
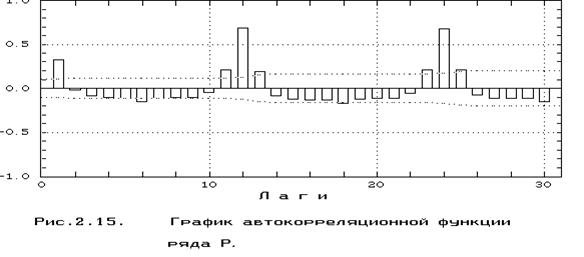
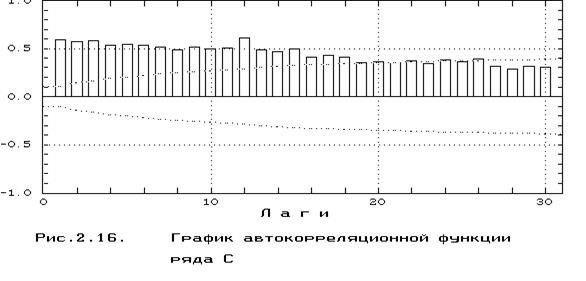 Часто можна припускати, що в рядах, що складаються з відхилень від тренда, автокореляції немає.
Часто можна припускати, що в рядах, що складаються з відхилень від тренда, автокореляції немає.Наприклад, на рис. нижче представлений графік АКФ для залишків, отриманих від моделювання ряду трендом (див. рис. 2.16), і АКФ нагадує процес "білого шуму".
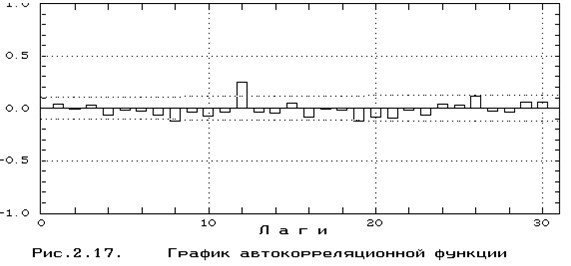
Проте нерідкі випадки, коли залишки (випадкова компонента h) можуть виявитися автокоррелірованнимі, наприклад, з наступних причин:
• в детермінованих чи стохастичних моделях динаміки не врахований періодичний фактор (в залишках є періодичність)
• в моделі не враховано кілька несуттєвих факторів, взаємний вплив яких виявляється істотним внаслідок збігу фаз і напрямків їх зміни;
• обраний неправильний тип моделі
Кросс-корреляционная функция
Такий же аналіз потрібний для побудовимоделі
Уn+1=f(y0.n/0-k,x1.n/0-k,...,xm.n/0-k) (2)
тільки для взаємних чи кросс корр функций – ККР
Розлянемо реалізації ![]()
![]() процесів
процесів ![]() .
.
Виберемо реалізації ![]() и
и ![]() .
. ![]() деяких процесів
деяких процесів ![]() ,
, ![]() и побудуємо кросс-корреляційну функцію (ККФ) з упереджаючим індексом зсуву k для кожного з них.
и побудуємо кросс-корреляційну функцію (ККФ) з упереджаючим індексом зсуву k для кожного з них.
На рис.1 и рис. 2 показано формування рядів для розрахунку ККФ ![]() та
та ![]() для k=2
для k=2

Рис.1 ККФ с опережающим индексом сдвига k для ![]()
По элементам рядівщо виділені розраховуємо значеня ![]() .
.
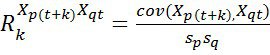 , (1)
, (1)
де ![]() –вибіркова коваріація,
–вибіркова коваріація, ![]() - незміщені вибіркові оцінки дисперсії рядів що виділені
- незміщені вибіркові оцінки дисперсії рядів що виділені
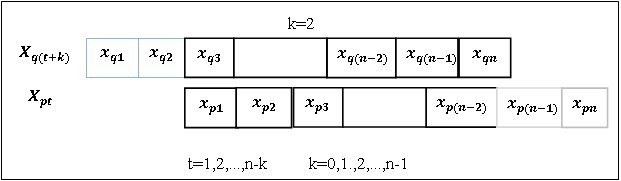
Рис.2 ККФ с опережающим индексом сдвига k для ![]()
По элементам рядівщо виділені розраховуємо значеня ![]()
![]() , (2)
, (2)
де ![]() – вибіркова коваріація,
– вибіркова коваріація, ![]() - незміщені вибіркові оцінки дисперсії рядів що виділені
- незміщені вибіркові оцінки дисперсії рядів що виділені
Розрахунок ККФ через вибіркові значення ряду та незміщену оцінку дисперсії:
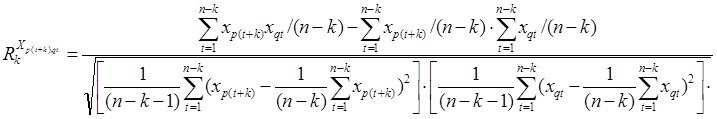 ,
, 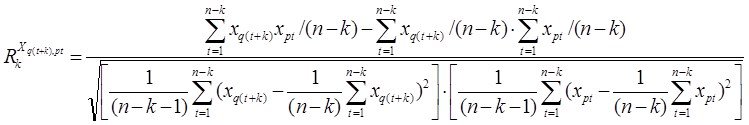 Розрахунок ККФ через вибіркові значення ряду тазміщену оцінку дисперсії:
Розрахунок ККФ через вибіркові значення ряду тазміщену оцінку дисперсії:
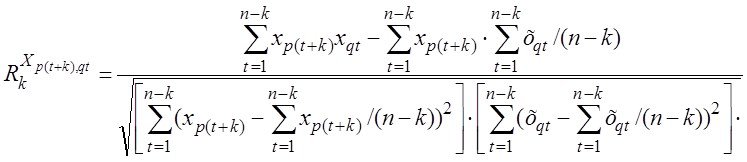 ,
,
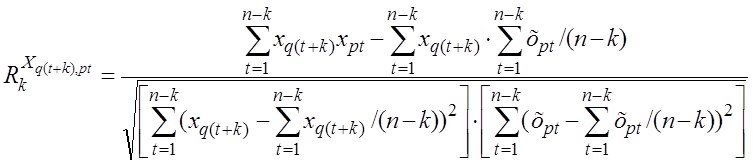 Для слабо пов'язаних випадкових рядів xi і yi, r (k) дорівнює нулю або загасає досить швидко.
Для слабо пов'язаних випадкових рядів xi і yi, r (k) дорівнює нулю або загасає досить швидко.
Наявність піків в ВКФ вказує на наявність зв'язку між xi і yi + k на даному часовому лагу k.
Якщо піки у функції r (k) повторюються через певний час, то взаємний вплив рядів носить періодичний характер.
Наприклад, на рис нижче можна угледіти достовірну взаємозв'язок рядів при тимчасових зсувах на 1 і 11 місяцях
.
Практика – спец – курс физкульт - данные
маги - курс Ваня и Саша и курс физкульт
всем - ф. смещения, ККР и АКР по демографи и экономике
=================
3 неделя -_ПСА
5л – 6л ПСА Грейнджер нелин ПСА с порогами
\ ПСА через ККР су четом параметров порогов
Задача - опис Х-в и данных
(если прошлую практ сделали - то
Практика – переход к курсовому
- перейти к к особо интнресной задаче класс –зад вр рядями,
статья по этой теме и переход к практ
Когда пойдет РА – пр. – Шаг алгоритмы
Моделирование взаимодействия систем
Агентное моделирование – это не описание соотношения между переменными(как в в регрессионном анализе -описание обїекта) а математический апарат отражает противоборство/ сотрудничество/ сосуществование субъектов (кирпичи моделируемого ?явления)– не переменных а систем с своими уравнениями состояния ограничениями на область определения и интересами (целями) формализованніми в функционалах этих систем
Чинно-наслідковий аналіз
Отже, як ми говорили, відразу посде Д. приступити до моделювання горизонтальних рівнів об'єкту заважають наступні проблеми:
1. Якщо на даному горизонтальному рівні моделюється не одне рівняння прогнозу, а система рівнянь
x1.+1=f(x1.0-k,x2.0-k, ... xm.0-k)
x2.+1=f(x1.0-k,x2.0-k, ... xm.0-k
...........................................
xm.+1=f(x1.0-k,x2.0-k, ... xm.0-k (*)
то виникає необхідність визначення, що з (*) доказово необхідно моделювати - тобто знайти список екзогенних змінних об'єкта.
-Рішення можна отримати якщо вирішені завдання ПСА по п. № 2. - Тоді якщо всі зв'язки ![]()
![]() то
то ![]() -экзогенна змінна, Так знаходиться список Экз змінних объекту.
-экзогенна змінна, Так знаходиться список Экз змінних объекту.
2. Складаються і досліджуються первинні статистичні звязки, результати ПСА зводяться в матриці і графи ПСС
і як наслідок
3. можемо визначити списки змінних на вході алгоритму моделювання - цим ми оптимізуємо задачу структурно-параметричного синтезу, зменшуючи список змінних на вході алгоритму мод-я і
зменшуємо час вирішення завдання,
збільшуємо адекватність моделей.
Як саме вирішувати питання направлення зв'язку - про це наступний розділ нашого курсу
ЗастосуванняККФ для розрахунку матриць та графів ЧНЗ
Рассматривается задача ПСА объекта который характеризуется множествами точек, представляющими собой реализации ![]() временных рядов (процесcов)
временных рядов (процесcов) ![]() , p=1,..,m.
, p=1,..,m.
Эффективность предложенного далее подхода зависит от степени выполнения следующих предположений:
1. Временные ряды ![]() , характеризующие объект представляют собой взаимосвязанные процессы.
, характеризующие объект представляют собой взаимосвязанные процессы.
2. Взаимосвязь процессов ![]() в значительной мере должна характеризоваться линейным эффектом.
в значительной мере должна характеризоваться линейным эффектом.
Рассмотрим далее реализации ![]()
![]() процессов
процессов ![]() , p=1,..,m.
, p=1,..,m.
объекта исследования, Выберем реализаци![]() и
и ![]() .
. ![]() некоторых процессов
некоторых процессов ![]() ,
, ![]() и построим кросс-корреляционную функцию (ККФ) с опережающим индексом сдвига k для каждого из них.
и построим кросс-корреляционную функцию (ККФ) с опережающим индексом сдвига k для каждого из них.
Мы уже знаем какэто делается- напомним
На рис.1 и рис. 2 показано формирование рядов для расчета ККФ ![]() и
и ![]() .
.
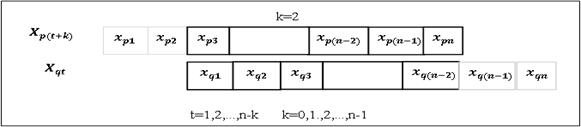
Рис.1 ККФ с опережающим индексом сдвига k для ![]()
По выделенным элементам рядов рассчитываем значения ![]() .
. ![]() , (1)
, (1)
где ![]() –выборочная ковариация,
–выборочная ковариация, ![]() - несмещенные выборочные оценки дисперсии выделенных рядов.
- несмещенные выборочные оценки дисперсии выделенных рядов.
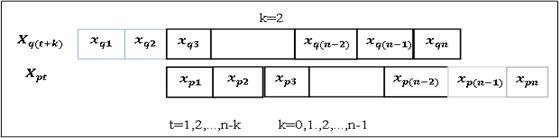
Рис.2 ККФ с опережающим индексом сдвига k для ![]()
По выделенным элементам рядов рассчитываем значения ![]() , (2)
, (2)
где ![]() –выборочная ковариация и
–выборочная ковариация и ![]() - несмещенные выборочные оценки дисперсии выделенных рядов.
- несмещенные выборочные оценки дисперсии выделенных рядов.
Величины ККФ при каждом k характеризуют силу линейной связи между значениями рядов с данным сдвигом, а следовательно степень прогностической способности соответствующей линейной модели. Таким образом, отличия в значениях ![]() и
и ![]() возможно использовать для установления направления статистичексой причинно-следственной связи значений ряда при данном k. Грубо говоря, при
возможно использовать для установления направления статистичексой причинно-следственной связи значений ряда при данном k. Грубо говоря, при ![]() линейный прогноз
линейный прогноз ![]() по
по ![]() будет более точный, чем
будет более точный, чем ![]() по
по ![]() и при данном k статистически
и при данном k статистически ![]()
Однако суть причинно-следственных отношений неоднозначна. Очевидно, что при различных k соотношения между ![]() и
и ![]() могут менятся и соответственно меняется направление влияния процессов. Поэтому для оценки «взаимоотношений» процессов
могут менятся и соответственно меняется направление влияния процессов. Поэтому для оценки «взаимоотношений» процессов ![]() и
и ![]() и построения причинно-следственных структур (ПСС) целесообразно ввести ряд критериев, как для отдельных значений k, так и интегральных, для характеристики преимущественного направления влияния. В зависимости от цели задачи (прогноз, классификация, анализ объекта) возможно предложить ряд таких критериев. Ниже ограничимся наиболее простыми критериями селекции ПСС.
и построения причинно-следственных структур (ПСС) целесообразно ввести ряд критериев, как для отдельных значений k, так и интегральных, для характеристики преимущественного направления влияния. В зависимости от цели задачи (прогноз, классификация, анализ объекта) возможно предложить ряд таких критериев. Ниже ограничимся наиболее простыми критериями селекции ПСС.
Упростим запись ККФ обозначив ![]() и
и![]() . Тогда далее рассмотрим для селекции ПСС следующие критерии:
. Тогда далее рассмотрим для селекции ПСС следующие критерии:
![]() –
– ![]() , (5)
, (5)
![]() –
– ![]() (6)
(6)
![]() –
– ![]() (7)
(7)
![]() –
– ![]() (8)
(8)
где ![]() – один из искомых параметров, в простом случае
– один из искомых параметров, в простом случае ![]() - параметр алгоритма.
- параметр алгоритма.
С точки зрения чувствительности при идентификации однонаправленных и двунаправленных статистических причинно-следственных связей процедуру определения ПСС целесообразно параметризовать так же как при построении матриц ПСС на основе ошибок прогноза конкурирующих моделей исследуемых переменных .
Далее в качестве параметров процедуры введем два порога:
1. ![]() - порог чувствительности определения направления связи ПСС .
- порог чувствительности определения направления связи ПСС .
2. ![]() - порог значения
- порог значения ![]() при котором правило процедуры действительно.
при котором правило процедуры действительно.
Для характеристики ПСС системы процессов ![]() введем матрицу ПСС
введем матрицу ПСС
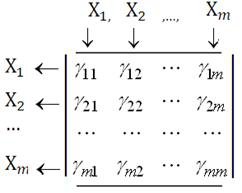 (*)
(*)
Рис.3. Матрица ПСС процессов ![]()
для которой элементы ![]() , если
, если![]() и
и![]() , если
, если ![]()
Определим далее правило процедуры для всех вариантов критерия ![]() дляустановления направления связи (и соответствующих значений элементов матрицы ПСС) следующим образом: (*)
дляустановления направления связи (и соответствующих значений элементов матрицы ПСС) следующим образом: (*)
1. При ![]() то :
то :
1.1. если ![]() , то
, то ![]() ,
,
1.2. если ![]() , то
, то ![]()
1.3. если ![]() , то имеем двустороннюю связь
, то имеем двустороннюю связь ![]()
![]() .
.
2. При ![]() -
-
2.1. ![]() связи между
связи между ![]() и
и ![]() нет.
нет.
2.2. ![]() требует дополнительного исследования: возможны разные варианты
требует дополнительного исследования: возможны разные варианты
2.2.1 -А) связь устанавливается как в п.1.1 и 1.2 (приоритет чувствительности ) или
2.2.2 –Б) работаем как в п. 2.1 ( чувствительность игнорируется)
Режим п.2.2 устанавливается в зависимости от результатов исследований или исп режим 2.2.1 расчитывая на коррекцию на этапе моделирования (по МГУА, когда лишние связи обрывает сам алгоритм)
В результате применения конкретного критерия при конкретных значениях порогов получим соответствующую данному выбору матрицу ПСС типа (*)
Далее строим графы ПСС
Приклад
Розглянемо спрощений випадок - граф без петіль (тобто не розглядаємо вплив змінних самих на себе). Нехай маємо систему з п'ятьма змінними![]() , проведений аналіз дав в якості результатів напрямки зв'язків між змінним що зведено у матрицю ЧНЗ -5 * 5 - на рис.
, проведений аналіз дав в якості результатів напрямки зв'язків між змінним що зведено у матрицю ЧНЗ -5 * 5 - на рис.
![]()
![]() звідси маємо наступну структуру графа- рис 3:
звідси маємо наступну структуру графа- рис 3:
Тепер можемо вирішити всі задачі ЧНА стовпчика 3 нашої таблиці
1. Список екзогенних змінних системи:
Розглянемо для деякої змінної ![]() всі (n-1) пар моделей виду (9) (10) . Якщо після завершення порівняльних процедур маємо всі отримані співвідношення типу
всі (n-1) пар моделей виду (9) (10) . Якщо після завершення порівняльних процедур маємо всі отримані співвідношення типу![]() або те , що в деяких парах зв'язок відсутній, тоді змінна є екзогенна для даної системи. Переглянувши за запропонованим алгоритмом всі
або те , що в деяких парах зв'язок відсутній, тоді змінна є екзогенна для даної системи. Переглянувши за запропонованим алгоритмом всі ![]() отримаємо множину екзогенних для даного об'єкта змінних
отримаємо множину екзогенних для даного об'єкта змінних ![]() =
=![]() .
.
Тоді для розглянутого об'єкту , необхідно моделювати всі компоненти початкового вектора за винятком отриманого списку компонент![]() . Такі змінні є внутрішніми ( ендогенними ) для системи -
. Такі змінні є внутрішніми ( ендогенними ) для системи - ![]() .
.
2. Одержуємо матриці та граф ЧНЗ системи процесів (одержали вище)
3. Визначення множини змінних на вході алгоритму моделюваня
Одержавши граф ЧНЗ системи (третя задача) ми тим самим офільтрували для кожної ендогенної змінної всі не направлені на неї процеси і отже одержали множини змінних що требо визначити
Накінець можливо одержати кінцевий вигляд структури об’єкту – промоделювати за МГВА змінні у вершинах графу:
![]() від
від![]() ;
; ![]() від
від![]() ,
,![]() ;
; ![]() від
від![]() ,
,![]() ,
, ![]() ;
; ![]() від
від![]() ,
,![]() ,
, ![]() ,
,![]() .
.
Після чого лишні (що насправді існують через треті змінні) зв’язки відпадуть. – Задача визначення системі моделей прогнозу -вирішена
(приложение ПСА к решению задачи классификации)
Класифікація об’єктів заданих часовими рядами
Розглядається задача класифікації, в якій объект характеризуєтся не одинаочными измерениями (точками) в многомерном пространстве признаков, а их множествами, представляющими собой реализации временных рядов.
Для простоты рассматривается случай двух классов. Объекты ![]() и
и ![]() классов А и В характеризуются реализациями
классов А и В характеризуются реализациями ![]() временных рядов (процесcов)
временных рядов (процесcов) ![]() , p=1,..,m.
, p=1,..,m.
Ряды признаки ![]() , затруднительно непосредственно использовать для оценки меры близости объектов к определенному классу. Поэтому далее предложим процедуру формирования вторичных признаков, позволяющих применить привычные меры близости и алгоритмы классификации. Данная процедура должна использовать целесообразные критерии и параметры селекции для получения наилучшего качества результатов классификации
, затруднительно непосредственно использовать для оценки меры близости объектов к определенному классу. Поэтому далее предложим процедуру формирования вторичных признаков, позволяющих применить привычные меры близости и алгоритмы классификации. Данная процедура должна использовать целесообразные критерии и параметры селекции для получения наилучшего качества результатов классификации
Так же как выше
Эффективность предложенного далее подхода зависит от степени выполнения следующих предположений:
1. Временные ряды ![]() , характеризующие объект представляют собой взаимосвязанные процессы.
, характеризующие объект представляют собой взаимосвязанные процессы.
2. Взаимосвязь процессов ![]() в значительной мере должна характеризоваться линейным эффектом.
в значительной мере должна характеризоваться линейным эффектом.
Логично считать, что при выполнении предположений метода одним из характерных признаков классифицируемых объектов могут быть статистические причинно-следственные структуры (ПСС) процессов ![]() . А отличия в ПСС объектов различных классов в определенных случаях могут быть основой для их классификации.
. А отличия в ПСС объектов различных классов в определенных случаях могут быть основой для их классификации.
Как указывалось выше описание ПСС может быть получено с помощью расчетов ККФ для каждой пары переменных ![]() , застосування критеріїв (5)-(8), та механізму встановлення напряму звязку згідно відношень (*).
, застосування критеріїв (5)-(8), та механізму встановлення напряму звязку згідно відношень (*).
Тоді логічно далі визначити критерии тапараметри селекції ЧНС, що дадуть найкращі результати класифікації.
Тоді
В результате применения конкретного критерия при конкретных значениях порогов получим соответствующую данному выбору матрицу ПСС.
Пусть матрицы ПСС Аk объектов класса А и матрицы ПСС Вk объектов класса В имеют вид:
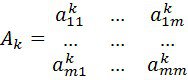 ,
, 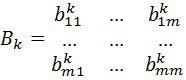 . (9)
. (9)
Учитывая предположение о ПСС, как характеристике классов объектов, заданными временными рядами, необходимо выбрать критерий ![]() и значения порогов селекции ПСС, обеспечивающие наиболее близкие матрицы ПСС на объектах одного класса, в соответствии с минимумом внутриклассовой дисперсии:
и значения порогов селекции ПСС, обеспечивающие наиболее близкие матрицы ПСС на объектах одного класса, в соответствии с минимумом внутриклассовой дисперсии:
![]() , (10)
, (10)
и наиболее различающиеся ПСС на объектах различных классов в соответствии с максимумом межклассовой дисперсии:
![]() . (11)
. (11)
Тогда выбор конкретного критерия и порогов селекции ПСС задачи классификации возможно рассчитывать согласно следующих дисперсионных критериев:
![]() , (12)
, (12)
где коэффициенты ![]() и
и ![]() балансируют требования совпадения и различения матриц ПСС или аналог критерия разделимости классов [2]
балансируют требования совпадения и различения матриц ПСС или аналог критерия разделимости классов [2]
![]() . (13)
. (13)
Процедура максимизации критериев может учитывать разбиение выборки объектов классификации: расчет параметров для всех вариантов критериев селекции на обучающей выборке и выбор наилучшего варианта по максимуму дисперсионного критерия (12) или (13) на проверочной выборке.
Меру близости объекта к классу, возможно принять как сумму отличий матрицы ПСС классифицируемого объекта от матриц ПСС объектов каждого класса. Естественные алгоритмы классификации: определение наилучшего граничного значения меры близости, разделяющего объекты классов (дискриминантный анализ), алгоритм ближайшего соседа или алгоритм взвешенного по объектного голосования в каждом классе.
Далі про причинність
Всі м механізми що було застосовано вище виходили з того що змінні в системі процесів що розглядаються зв’язані тільки лінійними залежностями чи по крайній мірі лінійний єффект є домінуючим . Нижче розлядаються підходи, що допускають нелінійні чинно-наслідкові зв’язки.
+
-----------------
В у нас есть сравнительно надежный и эффекивный аппарат моделирования, его возможно обратиь на нужды анализа – причинно-следственного анализа, учтя теперь, реальный – нелинейный характер связей между переменными
.
Далее о методах ПСА
Причинність по Грейнджеру
Основна ідея цього методу полягає у побудові прогностичних моделей, і якщо дані з першого часового ряду ![]() допомагають точніше передбачати поведінку другого ряду
допомагають точніше передбачати поведінку другого ряду ![]() , то вважається, що змінна
, то вважається, що змінна ![]() , що породжує перший ряд – впливає на змінну
, що породжує перший ряд – впливає на змінну![]() , що породжує другий ряд:
, що породжує другий ряд: ![]() .
.
З такого визначення випливає дуже важливій висновок
Причинність по Грейнджеру не співпадає з нашим уявленням про фізичне поняття причинності. Це тільки висновок з певного методологічного механізму порівняння адекватності моделей прогнозу що розглядаються. Нижче про це скажемо більш детально.
Метод причинності по Грейнджеру використовується зараз в різних областях проте одна з головних проблем методу - вдалий/невдалий вибір структури моделі.
Нижче наведена одна з реалізацій методу (курс економетрики) механізм застосування якої запропоновано ще у 2002-4 роках. Для аналізу причинності спочатку будується індивідуальні моделі, що враховує точки тільки з одного ряду ![]() чи
чи ![]() вплив на який оцінюється.
вплив на який оцінюється.
![]()
![]() (1)
(1)
з якої оцінюється похибки ![]() та
та![]() .
.
Потім будуємо спільні моделі, які враховують точки з обох рядів ![]() та
та ![]() .
.
![]() (2)
(2)
![]() (3)
(3)
з яких оцінюються похибки ![]() та
та ![]() , і де fx, fу, fxy, fyх - поліноми загального вигляду від D1, D2,(D1+D2 ) кількості змінних відповідно,
, і де fx, fу, fxy, fyх - поліноми загального вигляду від D1, D2,(D1+D2 ) кількості змінних відповідно,
s - дальність прогнозу, l- лаг,
Для обох моделей параметри розраховуються через МНК.
Коефіцієнти покращення прогнозу, що характеризують причинність по Грейнджеру, виражаються через ці помилки
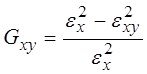 (4)
(4)
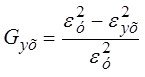 (5)
(5)
За більшим значенням коефіцієнту покращення прогнозу (покращення прогнозу х та у відносно коли прогнозуємо самі по собі- х по х та у по у) і визначается напрям впливу:
При ![]() маємо
маємо ![]() та при
та при ![]() маємо
маємо![]()
Причинність по Грейнджеру має сенс тільки як ми «вгадали» індивідуальні та взаємні моделі найкращим чином.
Для малих дальностей прогнозу, як правило, лаг береться такий, щоб захопити точку, що лежить через інтервал Z, відповідний нулю автокореляційної функції. Для великих дальностей прогнозу оптимальним виявляється лаг, обираний так, щоб захопити точку, що лежить через характерний період s+ l= T або через два характерних періоду s+ 2l = T.
Найбільш слабким місцем наведеної методології є
1.Відсутність раціональних міркувань щодо вибору структури fx, fу, fxy, fyх
2. Відсутність обгрунтувань належної дальності прогнозу P (приклад економіки України?) та лагу l, крім того що і лаги lу конкур. моделей можуть бути різні.
3. Cама необхідність вираховувати, невідомо як, 4 невідомі структури
fx, fу, fxy, fуx, замість 2-х: fxпоyта fу поx типу (6) (7) викликає обґрунтовані сумніви.
Дійсно при застосуванні обґрунтованого підхіду до вибору структури моделей типу
![]()
![]() чи навіть просто
чи навіть просто
![]() (6)
(6)
![]() (7)
(7)
(де тут l вже інтервал врахування передісторії) можливо використувати для визначення напряму впливу Х та Уякщо дійсно ми їх можемо обґрунтувати.
Моделі (6) (7) дозволяють оцінити «чистий» взаємний вплив змінних, що розглядаються. Не врахування ж єффекту впливу у моделях членів структур типу ху чи самих х, у для fxy, fуx відповідно, не є обґрунтованими, так як моделі що розглядаються завідомо є «фіктивними» і не враховують ще низку взаємовпливів через треті змінні, що достовірно присутні у дійсних прогнозуючих моделях.
Тому цілком доцільно для встановлення напряму впливу спростити задачу та застосовувати конкуруючі «фіктивні» моделі, що розглядають лише чистий взаємний вплив - моделі типу (6) (7).
Тоді за умови застосування обгунтованого методу моделювання що визначає оптимальну структуру «фіктивних» моделей, що моделюють прогностичний эффект конкуруючих моделей лише за рахунок «чистого взаємного впливу» можливо не враховувати помилки ![]() та
та ![]() , та напрям впливу оцінювати просто за більшою точністью (меншою помилкою) прогностичної моделі - згідно відповідних величин НВСКП (норм. відн сер. кв. помилок)
, та напрям впливу оцінювати просто за більшою точністью (меншою помилкою) прогностичної моделі - згідно відповідних величин НВСКП (норм. відн сер. кв. помилок)
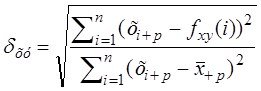 та
та 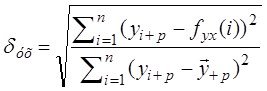
Тоді напрям впливу визначаємо за умовами
При ![]() маємо
маємо ![]() та при
та при ![]() маємо
маємо![]() (*)
(*)
Таким обґрунтованим методом є метод групового врахування аргументів (що ми вже знайомилися чи познайомимося пізніше)і подальший виклад виходить з цього. Однак це вже не буде причинність за Грейнджером так як ми її визначили вище. Визначеним за (*) напрям зв’язку між змінними назвемо просто статистичним чинно-наслідковим зв’язком.
Статистичний чинно-наслідковий зв’язок.
Даний розділ застосовує для побудови статисичних конкуруючих прогностичних моделей метод МГУА. -Так як ми (маю надію) переконані у перевагах МГУА то у наступних пропозиціях ми будемо спиратися на нього як на апарат моделювання а також спиратимося на принципи порівнянні та адекватності що приняті у теорії самоорганізації.(застосуванні зовнішнього критерію)
Так само як і причинность по Грейнджеру, СтЧиНаЗв-к не співпадає з фізичним поняттям причинності. Ми фіксуємо певний напрям СЧНЗ тільки з висновку деякого показника про статистичну більшу чи меншу точність прогнозу відповідних конкуруючих моделей прогнозу.Більш детально про відміності СЧНЗ та фізичної причинності трохи нижче.
Отже розглядаємо далі вже систему змінних (процесів) ![]() для якої передбачається можливість описудискретними моделями. Дана система процесів представлена множинами точок
для якої передбачається можливість описудискретними моделями. Дана система процесів представлена множинами точок
![]() ,
,![]() ,….,
,….,![]() , що формують як вектора стовпці відповідну матрицю об’єкт-властивості
, що формують як вектора стовпці відповідну матрицю об’єкт-властивості
(8)
Далі розглядаємо наступні пари дискретних моделей із запізнюваннями
(розглядаються фіктивні робочі моделі, які будуть використані для вирішення тільки даного локального завдання, - встановлення напряму чинно-наслідковому зв'язку між парою даних змінних ![]() і
і ![]() ):
): 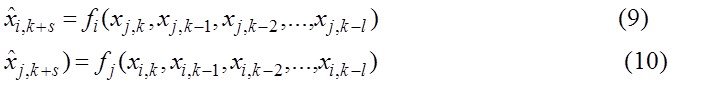 Введемо ознаку по якій надалі встановимо напрям зв'язку між змінними:
Введемо ознаку по якій надалі встановимо напрям зв'язку між змінними:
*) менш точна модель вказує в даній парі ![]()
![]() яке направлення зв'язку з двох можливих, найменш ймовірно в даній парі, тобто указує, як не встановити напрям причинно-наслідковому зв'язку між ними –
яке направлення зв'язку з двох можливих, найменш ймовірно в даній парі, тобто указує, як не встановити напрям причинно-наслідковому зв'язку між ними – ![]() або
або ![]() .
.
За умови максимального об'єктивного характеру отриманих фіктивних моделей ознака *) є необхідна і достатняумова для встановлення неіснуючого напряму зв'язку.
З першою ознакою, заснованою на запереченні неіснуючого напряму впливу, зв'язана і конструктивна ознака:
**) точніша модель указує в даній парі змінних ![]()
![]() найбільш вірогідне з двох, напрям зв'язку, тобто указує, як встановити напрям причинно-наслідковому зв'язку між ними –
найбільш вірогідне з двох, напрям зв'язку, тобто указує, як встановити напрям причинно-наслідковому зв'язку між ними – ![]() або
або ![]() .
.
За умови максимального об'єктивного характеру отриманих пробних моделей ознака **) є необхідною умовою для встановлення напряму зв'язку, що діє .
Припущення, що дана властивість є необхідною умовою відповідного напряму зв'язку є очевидним фактом, що, зокрема, легко показується модельним експериментом.
Як приклад, наведемо аналіз конкуруючих моделей доходів та витрат населення України типу (9) (10) отриманих в однакових умовах алгоритмом МГУА МАКСО
Х дох- доходи населення в Україні (млн. грн.) і
Хвитр - витрати і заощадження населення в Україні (млн. грн.)
за період з листопада 1995 по вересень 1999 року.
Дана пара вибрана з причини очевидності для нас напрями причинно-наслідковому зв'язку в даній парі змінних.
Нижче на малюнку 0*, наведено графіки процесів Хдох (Х01) та Хвитр (Х02),
на мал. 1*-графіки Хдох (Х01) та моделі Хдох через Хвитр (Х02) (макс лаг=10)
на мал.2*-графіки Хвитр (Х02) та моделі Хвитр через Хдох (Х01) (макслаг=10)
![]() Навіть за зовнішнім виглядом графіків процесів (мал. 0*) видно, що блакитна крива (Доходи -х02) в цілому біжить попереду синьої (витрати - х01) та за часом характерні повторення (х02-витрати) відбуваються пізніше (з більшим номером часу) – тобто правіше на графіку, чим (х01=доходи) що і узгоджується із здоровим глуздом.
Навіть за зовнішнім виглядом графіків процесів (мал. 0*) видно, що блакитна крива (Доходи -х02) в цілому біжить попереду синьої (витрати - х01) та за часом характерні повторення (х02-витрати) відбуваються пізніше (з більшим номером часу) – тобто правіше на графіку, чим (х01=доходи) що і узгоджується із здоровим глуздом.
мал. 0*
Тот же висновок випливає з аналізу точності фіктивних моделей графіки яких (блакитним) наближають процеси (синім) - рис 1 * і рис. 2*: більш точна модель (мал. 2) наближає Х02 витрати по Х01-доходи
помилка НВСКП ![]() моделі Х01(д) по Х02(в)=0,73
моделі Х01(д) по Х02(в)=0,73
помилка НВСКП ![]() моделі Х02 (в) по Х01-(д) = 0,53- 0,486
моделі Х02 (в) по Х01-(д) = 0,53- 0,486
![]()
![]()
Рис.1* Рис.2*
і отримуємо очевидний висновок про причину Х01 (д) і ![]() наслідок Х02(в) в даній парі змінних
наслідок Х02(в) в даній парі змінних
Відзначимо, що застосування для порівняння фіктивних робочих моделей роблять необхідним говорити про ймовірнисний (статистичний) характер певного напряму зв'язку. Про достатнасть ознаки (умови) **) для визначення напряму зв'язку говорити не можна з кількох причин –
а/ простий збіг поведінки розглянутих змінних
б/ дві дані змінні є два наслідки однієї загальної причини (третьої змінної), при цьому дані наслідки проявляються з різними запізнюваннями.
і ін.
Проте, не дивлячись на лише умову необхідності приведеної ознаки **) вона є цілком коструктивною для отримання можливого наближення про механізм взаємозв'язків в системі.
Дійсно, якщо метою моделювання системи є, наприклад прогноз, то ні причина а/, ні причина б/, не є перешкодою для включення в розгляд даного в загалі-то фіктивному зв'язку, якщо він послужить поліпшенню точності прогнозу поведінки системи. Тут цілком доцільний принцип – „не важливо якого кольору кішка, аби ловила мишей”.
Для забезпечення максимально об'єктивного характеру отримуваних моделей із запізнюваннями ![]() доцільно використовувати метод групового обліку аргументів МГУА, оскільки саме методи самоорганізації дозволяють одночасно визначити і коефіцієнти і форму нелінійного зв'язку між змінними і будують моделі оптимальної складності .
доцільно використовувати метод групового обліку аргументів МГУА, оскільки саме методи самоорганізації дозволяють одночасно визначити і коефіцієнти і форму нелінійного зв'язку між змінними і будують моделі оптимальної складності .
Далі треба зробити істотне зауваження.
Запропонована ознака **) дасть очікуваний результат при порівнянні кращих моделей вигляду ![]() . Але перебір всіх можливих структур при всіх можливих значеннях параметрів алгоритму є поки непосильним завданням Тому введемо спрощене правило визначення вибору порівнюваних моделей для застосування ознаки **):
. Але перебір всіх можливих структур при всіх можливих значеннях параметрів алгоритму є поки непосильним завданням Тому введемо спрощене правило визначення вибору порівнюваних моделей для застосування ознаки **):
Для деяких, доцільно вибраних параметрів алгоритму, деякого, доцільно вибраного рівня складності (одного і того ж номера ряду селекції, або ж моделей оптимального рівня складності), порівнюємо оцінки точності отриманої пари моделей. Точніша модель указує в даній парі змінних ![]()
![]() найбільш вірогідне з двох, напрям зв'язку, тобто указує, як встановити напрям між ними –
найбільш вірогідне з двох, напрям зв'язку, тобто указує, як встановити напрям між ними – ![]() або
або ![]() .
.
Поняття доцільності визначиться у кожному окремому випадку об'єкту залежно від розмірності завдання, рівня шумів і ін.
На практиці для значного числа складних об'єктів розглянута ознака буде не тільки необхідним але і достатнім для розгляду цілком достовірного наближення об'єкту отриманою моделлю.
Спрощений порядок встановлення напряму СЧНЗ
Структура ЧНЗ системи змінних ![]() може бути описана і зображена у вигляді матриці та графа.
може бути описана і зображена у вигляді матриці та графа.
![]() Результат розгляду взаємозв'язків
Результат розгляду взаємозв'язків ![]() у всіх можливих парах
у всіх можливих парах ![]()
![]() може бути представлений у вигляді матриці на мал.
може бути представлений у вигляді матриці на мал.
![]()
де
Легко визначається і структура графу, який відповідає структурі матриці даної системи.
Приклад
![]() Розглянемо спрощений випадок - граф без петель (не розглядаємо вплив змінних самих на себе). Нехай маємо систему з п'ятьма змінними
Розглянемо спрощений випадок - граф без петель (не розглядаємо вплив змінних самих на себе). Нехай маємо систему з п'ятьма змінними![]() , і дослідження по вище описаному алгоритму дали в якості результатів - напрямки зв'язків між змінним, і ми сформували матрицю ЧНЗ -5 * 5 - на рис.
, і дослідження по вище описаному алгоритму дали в якості результатів - напрямки зв'язків між змінним, і ми сформували матрицю ЧНЗ -5 * 5 - на рис.
отсюда получим следующую структуру графа- рис 3:
![]()
Одержавши матрицю та відповідний граф ми вирішили по суті всі три задання що містяться у графі 3 нашої таблици моделювання.
4. Список екзогенних змінних системи:
Розглянемо для деякої змінної ![]() всі (n-1) пар моделей виду (9) (10) . Якщо після завершення порівняльних процедур маємо всі отримані співвідношення типу
всі (n-1) пар моделей виду (9) (10) . Якщо після завершення порівняльних процедур маємо всі отримані співвідношення типу![]() або те , що в деяких парах зв'язок відсутній, тоді змінна є екзогенна для даної системи. Переглянувши за запропонованим алгоритмом всі
або те , що в деяких парах зв'язок відсутній, тоді змінна є екзогенна для даної системи. Переглянувши за запропонованим алгоритмом всі ![]() отримаємо множину екзогенних для даного об'єкта змінних
отримаємо множину екзогенних для даного об'єкта змінних
![]() =
=![]() . Тоді для розглянутого об'єкту , необхідно моделювати всі компоненти початкового вектора за винятком отриманого списку компонент
. Тоді для розглянутого об'єкту , необхідно моделювати всі компоненти початкового вектора за винятком отриманого списку компонент![]() . Такі змінні є внутрішніми ( ендогенними ) для системи -
. Такі змінні є внутрішніми ( ендогенними ) для системи - ![]() .
.
5. Визначення множини змінних на вході алгоритму моделюваня
Одержавши граф ЧНЗ системи ми тим самим офільтрували для кожної ендогенної змінної всі не направлені на неї процеси і отже одержали множини змінних що шукали.
6. Після вирішення третьой задачі – можливо держати кінцевий вигляд структури об’єкту – промоделювати за МГВА змінні у вершинах графу:
![]() від
від![]() ;
; ![]() від
від![]() ,
,![]() ;
; ![]() від
від![]() ,
,![]() ,
, ![]() ;
; ![]() від
від![]() ,
,![]() ,
, ![]() ,
,![]() .
.
Після чого лишні (що направді існують через треті змінні) зв’язки відпадуть. – Задача визначення системі моделей прогнозу -вирішена
Проте ми у тих вище наведених міркуваннях дещо не врахували
Повний порядок встановлення напряму СЧНЗ
Ми не врахували що значний рівень погрішності (значення нормованої середньоквадратичної погрішності, скажімо, більше 0,9) при моделюванні в парі змінних ![]() дозволяє трактувати пару, яка аналізується, як не зв'язану і повинні ігнорувати зв'язок між ними.
дозволяє трактувати пару, яка аналізується, як не зв'язану і повинні ігнорувати зв'язок між ними.
Якщо ж різниця між оцінками точності (чутливість процедури ) отриманих моделей![]() буде незначна (введемо поріг
буде незначна (введемо поріг![]() ), то зв'язок між змінними, як правило, двонаправлений, що може означати в тому числі і їх взаємозалежність через треті змінні.
), то зв'язок між змінними, як правило, двонаправлений, що може означати в тому числі і їх взаємозалежність через треті змінні.
Ці міркування приводять до детальнішої методології встановлення ЧН зв’язку. Для формалізації прийняття рішень про напрям ЧНЗ з урахуванням вище вказаних обставин доцільно ввести деякі характерні параметри-![]() та
та ![]() . Нехай в процедурі порівняння конкуруючих моделей змінних
. Нехай в процедурі порівняння конкуруючих моделей змінних ![]() та
та ![]() (моделі
(моделі ![]() та
та ![]() ) похибка моделі
) похибка моделі ![]() по змінній
по змінній ![]() позначена
позначена ![]() ,похибка моделі
,похибка моделі ![]() по змінній
по змінній ![]() позначена -
позначена - ![]()
Тут під ![]() розуміємо НВСКП (або доля непоясненої дисперсії)
розуміємо НВСКП (або доля непоясненої дисперсії)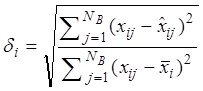 як правило на тестовій вибірці даних
як правило на тестовій вибірці даних
Тоді
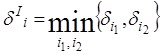 назвем індикативною похибкою, що вказує індексом
назвем індикативною похибкою, що вказує індексом ![]() напрям зв’язку між змінними:
напрям зв’язку між змінними:
|
|
(3) |
|
|
Порогом індикативної похибки ![]() (
(![]() ) назвем гранично найбільше значення індикативної похибки
) назвем гранично найбільше значення індикативної похибки ![]() , при якому допускається процедура порівняння конкурурующих моделей. Тобто, при похибці
, при якому допускається процедура порівняння конкурурующих моделей. Тобто, при похибці ![]()
![]() , відповідна модель не може бути застосована для висновку про напрям звязку.
, відповідна модель не може бути застосована для висновку про напрям звязку.
Очевидно, чим нижче індикативна похибка![]() , тим більше довіри результату порівняння конкурирующих моделей.
, тим більше довіри результату порівняння конкурирующих моделей.
Показником надійності прийняття рішень про чинність в парі змінних![]() та
та ![]() назвем модуль різниціпохибок конкурирующих моделей:
назвем модуль різниціпохибок конкурирующих моделей: ![]() =
= ![]() .
.
Мінімальне значення показникунадійності, при якому приймається рішення про орєінтованийзвязок назвем порогом показника надійності і позначимо ![]() (
(![]() ).
).
Для можливості порівняння результатів у різних парах змінних в одній задачі системного синтезу корисно ввести відносний показник надійності.
Відносним показником надійності ηij приняття рішення про напрям звязку між змінними xj → xi (стрілка в сторону i) назвем відношення:
|
|
(4) |
|||
|
Мінімальна допустиме значення відносного показника надійності поріг відносного показника) визначимо як: |
(5) |
|||
|
Для приведення величин Вибір порогів Процедура порівняння конкуруючих моделей, з урахуванням введених показників надійності, виглядає наступним чином |
||||
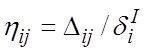
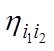 =
=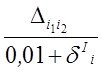 ,
, 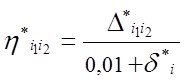
1.![]()
![]()
![]() - множині змінних, «надійно» направлених в сторону
- множині змінних, «надійно» направлених в сторону ![]() , тобто .
, тобто . ![]() , якщо
, якщо ![]() ,
, ![]() ,
, ![]()
2.![]()
![]()
![]() - множині змінних, «надійно» направлених від
- множині змінних, «надійно» направлених від ![]() , тобто
, тобто ![]() , якщо
, якщо ![]() ,
, ![]() ,
, ![]()
3. ![]()
![]()
![]() - множині змінних двустороннього звязку з
- множині змінних двустороннього звязку з ![]() , тобто
, тобто![]() , якщо
, якщо ![]() та
та ![]() (склад цієї множини уточнюємо в подальшому)
(склад цієї множини уточнюємо в подальшому)
4. ![]()
![]()
![]() - множині змінних «надійно» не зв’язаних з
- множині змінних «надійно» не зв’язаних з ![]() , якщо
, якщо ![]() та
та ![]()
5. ![]()
![]()
![]() - множині змінних, для яких не вдалося вирішити питання про приналежність (Indefinit), нідо до однієї з множин, визначених вище, якщо
- множині змінних, для яких не вдалося вирішити питання про приналежність (Indefinit), нідо до однієї з множин, визначених вище, якщо ![]() та
та ![]()
Скористаємосяотриманою інформацією для визначення структури зв'язків у системі.
Очевидно, що для моделювання будь-якої змінної ![]() з
з ![]() ,
,![]() ,...,
,...,![]() необхідно використовувати всі ті змінні, які при аналізі виявилися спрямовані, як
необхідно використовувати всі ті змінні, які при аналізі виявилися спрямовані, як ![]() (якщо такі маємо), тобто змінні з множин
(якщо такі маємо), тобто змінні з множин ![]() , т
, т![]() . Якщо множини
. Якщо множини ![]() ,
,![]() пусті, то
пусті, то ![]()
![]()
![]() - множині єкзогенных змінних даної системи. Таким чином, моделюванню підлягають всі змінні зі списку
- множині єкзогенных змінних даної системи. Таким чином, моделюванню підлягають всі змінні зі списку ![]() ,
,![]() ,...,
,...,![]() , за виключенням множини
, за виключенням множини ![]() .
.
Зазначений порядок формування списку змінних на вході алгоритму моделювання відповідатиме «жорсткій» фільтрації (максимальному скороченню списку змінних). Використання на вході алгоритму моделювання крім множин ![]() ,
,![]() ще множин
ще множин ![]() та/чи
та/чи ![]() відповідає різним варіантам «м'якої» фільтрації.
відповідає різним варіантам «м'якої» фільтрації.
Тепер очевидно, як позначиться на результатах процедури порівняння конкуруючих моделей неоптимальний вибір порогів ![]() та
та ![]() .
.
Так, збільшення вимог по надійності (збільшення ![]() ) до процедури порівняння призведе до вимиваннязмінних з множин
) до процедури порівняння призведе до вимиваннязмінних з множин ![]() ,
,![]() , та приєднанню їх до множин
, та приєднанню їх до множин ![]() ,
,![]() ,
,![]() .
.
Навпаки, зниження вимог по надійності в процедурі порівняння призведе до виключення змінних з множин ![]() ,
,![]() ,
,![]() та включення їх до множин
та включення їх до множин![]() и
и ![]() .
.
Таким чином, не оптимальність порогів приведе не до помилок увизначенні напрямку зв'язків, а до можливого неповного їх урахування.
Наведені міркування у зв'язку з наслідками не оптимального вибору порогів дозволяють зробити висновок, що завищені вимоги по надійності до процедури фільтрації можуть бути компенсовані «м'якістю» варіанту процедури фільтрації.
Серед розглянутих варіантів, як окремий випадок причинно-наслідкового зв'язку, виділяється випадок 3 –
множина «одномоментного» двостороннього зв'язку ![]() .
.
Він відповідає чинно-наслідковій взаємодії ![]() ,
,![]() , на інтервалі часу, меншому, ніж інтервал дискретності даних -
, на інтервалі часу, меншому, ніж інтервал дискретності даних -![]() , а в граничному, неперервному випадку, відповідає диференціальному зв'язку змінних на
, а в граничному, неперервному випадку, відповідає диференціальному зв'язку змінних на ![]() .
.
Виключивши (тимчасово) з розгляду цей окремий випадок, результати дослідження для випадку жорсткої фільтрації можливо уявити квадратною матрицею «М» ЧНЗ, де
1 - відповідає наявності зв'язку на вході відповідної змінної, 0 - її відсутності, а незаповнені елементи - невизначеності ситуації з визначенням зв'язку.. Матриця ЧНЗ М
![]()
Механізм побудови графу ЧНЗ той же що раніше.
У моделях ![]() , використані загальні для обохмоделей оптимальної складності, значеннях параметрів
, використані загальні для обохмоделей оптимальної складності, значеннях параметрів ![]() и
и ![]() . І якщо значення параметра
. І якщо значення параметра ![]() (кількість запізнювань) може бути вибрано з умови врахування наявної мінімальноїчастоти зне нулевою амплитудоюв даних (частота тренда) чи на основі розрахунку корреляційної розмірності, то з параметром
(кількість запізнювань) може бути вибрано з умови врахування наявної мінімальноїчастоти зне нулевою амплитудоюв даних (частота тренда) чи на основі розрахунку корреляційної розмірності, то з параметром ![]() - упередженням, зв’язано певне ускладнення аналізу чинності процесів.
- упередженням, зв’язано певне ускладнення аналізу чинності процесів.
Якщо ми розрахуємо конкуруючі моделі прогнозу для різних упереджень
![]() то можемо побудувати і відповідні матриці Мs ЧНЗ для різих
то можемо побудувати і відповідні матриці Мs ЧНЗ для різих ![]()
![]() При припущенні що матриці Мs для різних
При припущенні що матриці Мs для різних ![]() однакові то співвідношення (типу < >) між похибками
однакові то співвідношення (типу < >) між похибками ![]() и
и ![]() конкуруючих моделей при різних s не змінюються тобто графік залежності похибок конкуруючих моделей
конкуруючих моделей при різних s не змінюються тобто графік залежності похибок конкуруючих моделей ![]() и
и ![]() від величини упередження буде мати вигляд як на рис. 8, що відповідає напрямку
від величини упередження буде мати вигляд як на рис. 8, що відповідає напрямку ![]()
;
![]() Узагальному випадку при різних матрицях Мs можемо мати варианты рис. 4 и 5
Узагальному випадку при різних матрицях Мs можемо мати варианты рис. 4 и 5
![]()
та інш.
Варіанти на рис. 4,5 відображають більш складну взаємодію змінних![]() ,
,![]() , на різних частотах , ніж на рис.3.
, на різних частотах , ніж на рис.3.
Дійсно , амплітуди різних частот при різних фазах сигналу різні, тому вносять різну частку в загальний результат при сумуванні .
Як наслідок , різні частоти по різному впливають на підсумкове значення моделі і, відповідно, її помилки при різних упередженнях.
Тому доцільно отримувати не одну , а ряд матриць ЧНЗ , що відображають результат взаємодії змінних на кожному упередженні .
Такий підхід дозволяє бачити що на коротких s можемо мати один напрям взаємодії , при великих s значеннях знак взаємодії може змінюватися.
Приклад – з економіки України - х1 – доходи насел х2 – об’їм виробництва. Казалось бы ![]() а не тут то было
а не тут то было
При s=1, -имели ![]() при s=2 прибл
при s=2 прибл ![]() то есть двунаправл свіязь и только при s=3и болем получаем
то есть двунаправл свіязь и только при s=3и болем получаем ![]() - причина бешеная инфляция и болем чем 2 мес -цикл производства на екпорт
- причина бешеная инфляция и болем чем 2 мес -цикл производства на екпорт
Для отримання загальної картини взаємодії змінних можно скористатися накладенням матриць суміжності для кожного Мs , отримавши сумарну матрицю М.
За такої матриці можна судити:
про наявність екзогенних змінних в системі для всіх s,
про що залишилися не визначеними відносинами в парах змінних ,
про сумарні взаємодіі змінних та впливи .
Тепер розберемося з множиноюу випадку 3 класифікації результатів порівняння конкуруючих моделей.
З малюнків 4 і 5 видно , що даний варіант (рівності похибок) може існувати не як стійкий двостороній звязок а , як перехід знака впливу на протилежний.
Тому необхідно , як правило , врахувати дану множину , як підмножину в класі![]() і зберегтиумножині
і зберегтиумножині ![]() тільки ті змінні , для яких умова
тільки ті змінні , для яких умова![]() ,
, ![]() , (тобто умова нерозрізнюваності в сенсі порогу
, (тобто умова нерозрізнюваності в сенсі порогу![]() ) , зберігається для кількох s поспіль .
) , зберігається для кількох s поспіль .
Наявність такої особливості в результатах може свідчити про існування стійкоого диференціального зв'язку в системі , що слід врахувати в специфіці синтезу відповідних моделей процесу .
При виборі характерних параметрів ![]() и
и ![]() є очевидними наступні рекомендації:
є очевидними наступні рекомендації:
Вимоги надійності прийняття рішення про направлення зв'язку однозначно зрушують поріг ![]() у бік збільшення , а поріг
у бік збільшення , а поріг ![]() в бік зменшення.
в бік зменшення.
З іншого боку , наявність значного числа змінних умножині ![]() свідчить про можливість зменшення порога
свідчить про можливість зменшення порога![]() , - в ідеалі воно має бути порожнім.
, - в ідеалі воно має бути порожнім.
Крім того , доцільно зменшувати поріг ![]() пропорційно величині предполагаемой кількості факторів у повній залежності , де беруть участь досліджувані змінні.
пропорційно величині предполагаемой кількості факторів у повній залежності , де беруть участь досліджувані змінні.
Проте збільшення рівня шумів в даних робить доцільним відносне збільшення рівня обох порогів ![]() и
и ![]() .
.
Як бачимо , рекомендації багато в чому суперечливі , тому оптимальний вибір прогів ![]() и
и ![]() .є не тривіальною оптимізіційною задачою.
.є не тривіальною оптимізіційною задачою.
Розгляд нелінійного аналогу кроскореляційної функції
На кінець, якщо ми згадаємо зв'язок коєффіціенту корреляції з НВСКП (відносною непоясненою дисперсією) ![]() то
то
можливо запропонувати аналіз деякого нелінійного аналогу ККФ - функції
![]() та
та ![]() побудованих на значеннях кореляції моделей прогнозу
побудованих на значеннях кореляції моделей прогнозу ![]() (на k кроків) рядів
(на k кроків) рядів ![]() по моделям типу (9), (10) тобто коли
по моделям типу (9), (10) тобто коли ![]() моделюємо по
моделюємо по![]() та його лагами, а
та його лагами, а ![]() моделюємо по
моделюємо по ![]() та його лагами. Маємо на увазі що моделі типу (9), (10) - свої для кожного значення k.
та його лагами. Маємо на увазі що моделі типу (9), (10) - свої для кожного значення k.
Ще раз
Для дослідження та побудові ЧНС при гіпотезі лінійного ЧН зв’язку між змінними ми використовуємо значення ККФij (к) при випередженні на к кроків ряду змінної![]() змінної
змінної![]() та навпаки значення ККФji (к) при випередженні на к кроків ряду змінної
та навпаки значення ККФji (к) при випередженні на к кроків ряду змінної![]() змінної
змінної ![]() .
.
Та ж методологія використовуєтся при дослідженні та побудові ЧНС при гіпотезі нелінійного ЧН зв’язку між змінними. Тільки тут ми використовуємо значення коєффіціентів корреляції ![]() та
та ![]()
Висновок – ми одержали узагальнений механізм дослідження ЧНСтр і для лінійного і для нелінійного випадку зв’язку в системі процесів.
(приложение ПСА к решению задачи классификации)
Класифікація об’єктів заданих часовими рядами
Розглядається задача класифікації, в якій объект характеризуєтся не одинаочными измерениями (точками) в многомерном пространстве признаков, а их множествами, представляющими собой реализации временных рядов.
Для простоты рассматривается случай двух классов. Объекты ![]() и
и ![]() классов А и В характеризуются реализациями
классов А и В характеризуются реализациями ![]() временных рядов (процесcов)
временных рядов (процесcов) ![]() , p=1,..,m.
, p=1,..,m.
Ряды признаки ![]() , затруднительно непосредственно использовать для оценки меры близости объектов к определенному классу. Поэтому далее предложим процедуру формирования вторичных признаков, позволяющих применить привычные меры близости и алгоритмы классификации. Данная процедура должна использовать целесообразные критерии и параметры селекции для получения наилучшего качества результатов классификации
, затруднительно непосредственно использовать для оценки меры близости объектов к определенному классу. Поэтому далее предложим процедуру формирования вторичных признаков, позволяющих применить привычные меры близости и алгоритмы классификации. Данная процедура должна использовать целесообразные критерии и параметры селекции для получения наилучшего качества результатов классификации
Так же как выше
Эффективность предложенного далее подхода зависит от степени выполнения следующих предположений:
1. Временные ряды ![]() , характеризующие объект представляют собой взаимосвязанные процессы.
, характеризующие объект представляют собой взаимосвязанные процессы.
2. Взаимосвязь процессов ![]() в значительной мере должна характеризоваться линейным эффектом.
в значительной мере должна характеризоваться линейным эффектом.
Логично считать, что при выполнении предположений метода одним из характерных признаков классифицируемых объектов могут быть статистические причинно-следственные структуры (ПСС) процессов ![]() . А отличия в ПСС объектов различных классов в определенных случаях могут быть основой для их классификации.
. А отличия в ПСС объектов различных классов в определенных случаях могут быть основой для их классификации.
Как указывалось выше описание ПСС может быть получено с помощью расчетов ККФ для каждой пары переменных ![]() , застосування критеріїв (5)-(8), та механізму встановлення напряму звязку згідно відношень (*).
, застосування критеріїв (5)-(8), та механізму встановлення напряму звязку згідно відношень (*).
Тоді логічно далі визначити критерии тапараметри селекції ЧНС, що дадуть найкращі результати класифікації.
Тоді
В результате применения конкретного критерия при конкретных значениях порогов получим соответствующую данному выбору матрицу ПСС.
Пусть матрицы ПСС Аk объектов класса А и матрицы ПСС Вk объектов класса В имеют вид:
, . (9)
Учитывая предположение о ПСС, как характеристике классов объектов, заданными временными рядами, необходимо выбрать критерий ![]() и значения порогов селекции ПСС, обеспечивающие наиболее близкие матрицы ПСС на объектах одного класса, в соответствии с минимумом внутриклассовой дисперсии:
и значения порогов селекции ПСС, обеспечивающие наиболее близкие матрицы ПСС на объектах одного класса, в соответствии с минимумом внутриклассовой дисперсии:
![]() , (10)
, (10)
и наиболее различающиеся ПСС на объектах различных классов в соответствии с максимумом межклассовой дисперсии:
![]() . (11)
. (11)
Тогда выбор конкретного критерия и порогов селекции ПСС задачи классификации возможно рассчитывать согласно следующих дисперсионных критериев:
![]() , (12)
, (12)
где коэффициенты ![]() и
и ![]() балансируют требования совпадения и различения матриц ПСС или аналог критерия разделимости классов [2]
балансируют требования совпадения и различения матриц ПСС или аналог критерия разделимости классов [2]
![]() . (13)
. (13)
Процедура максимизации критериев может учитывать разбиение выборки объектов классификации: расчет параметров для всех вариантов критериев селекции на обучающей выборке и выбор наилучшего варианта по максимуму дисперсионного критерия (12) или (13) на проверочной выборке.
Меру близости объекта к классу, возможно принять как сумму отличий матрицы ПСС классифицируемого объекта от матриц ПСС объектов каждого класса. Естественные алгоритмы классификации: определение наилучшего граничного значения меры близости, разделяющего объекты классов (дискриминантный анализ), алгоритм ближайшего соседа или алгоритм взвешенного по объектного голосования в каждом классе.
Далі про причинність
Всі м механізми що було застосовано вище виходили з того що змінні в системі процесів що розглядаються зв’язані тільки лінійними залежностями чи по крайній мірі лінійний єффект є домінуючим . Нижче розлядаються підходи, що допускають нелінійні чинно-наслідкові зв’язки.
К -1Л
Итоговая структура задач этапов при моделировании "проблем"
назовем суть моделирования общим словом "проблем" так как это и
свойства и процессы и объекты и системы и системы систем
Вернемся к нашей таблице и подробно ее распишем
Напомним что в этой таблице мы приводим этапы (по столбцам) решения задачи моделирования - мы рассмотриваем те процедуры что стоят между неформальной постановкой проблемы и окончательным мат решением задачи моделирования.
Обобщение моделирования в виде обзорная таблицы
задачи А-С =Анализа – Синтеза ![]()
![]() Ан обСМ Ан модели
Ан обСМ Ан модели![]() Декоб ПСС СМ Анмодели
Декоб ПСС СМ Анмодели
|
Декомпозиция объекта |
Прич.Следств.Анал. |
Синтез модели |
Анализ модели |
|
Дек сост из ВертД и ГорД то есть осуществляем разбиение объекта на целесообразные верт и гор-ые уровни
ВД- определяет кол целесообр вертикальних уровней иерархии объекта ГД –определяет колич и содержаниеие переменных на фиксированном верт -----уровне, позвол-щих адекватно отразить его работу |
для каждого уровня реш
решить 4 задачи ПСА: 1.–список экзогенных и эндог перемен.объекта 2. - у=(Х)-что из сист вычеркн. что немодел 3.–матр . и граф ПССвязей (исс-ем пары переменных} 4–спис пер. на вх. АлгМо Когда зад. решены на кажд уровне можно прист к мод |
Моделир. св-тв Д: 1. Близк. пост задачи --Моделир объекта, --- Прогноз объекта Средства реш-- Шаг Регр Алг, - Вероятн мод-е Индукт мод, МГУА Матпрограммирование исп критерии - модуль, -мини мах -одностор аппр Нечеткие модели Н.сети как инструмент +лезем в классификацию Другие задачи-свойства -ДА, КлА, Кл.об., ФА -Клас-я об.заданых множ. проекций а) множ точек б)врем. рядами но реш эти задачи с пом систем-более сложных объектов -Модел. Систем: Ф-л, обкт, обл. сущ.- част системы- сети Петри Н.сети как объекты СМО Матпрограммирование Имит мод (Вер М) Диф. ур. с прав. ч. и опт. Траектории Мод. взаим. систем Теория игр Агентное мод-е - Методы нел динамики (ЕА) |
-Адекватность модели -Чувствительность модели -Регулярность модели -Устойчивость модели (трпектории) |
|
Наим разр апарат, В СА – рассм мех гор и верт Д, крит Д, Целев Д. пример шарики (в СА) |
Механизмырешения: –прич по Грейнджеру –нелин конкур. модели –КросКорФункции |
Пройдемся по этапам (столбцам) 3 и 4 таблицы
Здесь не обзорной лекции по этапу 3 ниже только некоторые ее фрагменты
О вер моделировании отдельная лекция
Л3 к Задачи оптимизации управляющих стратегий
Задачи нахождения оптимальных управляющих стратегий решаються в рамках аппарата методов "математического программирования"
- линейного, лин целочисленного, смешаного, квадратичного, нелинейного, стохастического, динамического.
Ниже познакомимся с идеей решения одного из самых распространенных вариантов ЗМП - задачи линейного программирования.
Общий подход спользуемый при решении линейных оптимизационных задач
Стандартная задача ЛП имеет вид 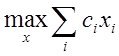 при
при
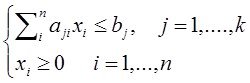
Рассм разл случаи ЛОЗ
1. F= 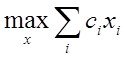 2. F= 3. F= (*)
2. F= 3. F= (*)
![]()
![]()
![]()
![]()
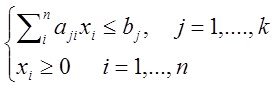
![]()
случай 1 - случай 2 случай 3 - 1) 2)
случай 1 - без ограничений - понятно F![]() , нужно только выбрать движение по
, нужно только выбрать движение по
градиенту. Далее приведем
Основополагающее утверждение (более строго сформ и докажем позже)
При линейной выпуклой области решений и линейном функционале оптимум находиться не в середине области и не на ее грани, а именно в вершине симплекса (симлекс - так называют такую линейную выпуклую область допустимых решений)
Поэтому в случ 2. можно искать оптимум даже тупо методом перебора вычисляя значения ф-ла в каждой вершине.
А вот в случ 3. - вершин может быть так много что перебором можно заниматься бесконечно-!!!-скажем о идее подхода - симплекс-метода (Данциг).
Он состоит из 2-этапов:
Как вы видите мы рассуждаем здесь пока в терминах стандартной задачи то есть область ДР вырезается из исходного пространства Х неравенствами типа "![]() " . Запомним это.
" . Запомним это.
Потом позже мы в рассуждения добавим добавочные переменные хд (расширив исходное Х) приводжящие задачу к коноическому виду с ограничениями только типа "="
Этап 1.
1а. Посколку мы знаем что оптимальное решение находится в вершине области ДР то в начале выходим на произвольную вершину, пусть даже недопустимую - рис 3.1
1б . включаем механизм-процедуру поиска вершины но которая уже принадлежит ОДР - то есть допустимую вершину симплекса
Этап 2.
Далее следует направленный перебор - из текущей вершины переходим в ту соседнюю, в которой получаем максимальный прирост функционала. сохраняя при этом нахождение в ОДР
Идем по симлексу используя данный принцип, пока не достигнем вершины, где значение ф-ла у всех соседей будет меньше, чем в текущей - мы достигли глобального максимума.
Отметим что важно еше раз - такой вывод справедлив только при лин выпуклой области и лин ограничениях. Иначе, это может быть локальный максимум а не глобальный
Использование ЛП постановок для решения
нелинейных оптимизационных задач
Если удается более сложный класс задач свести к решению каких-то пусть и многих задач ЛП - это считается большой удачей - проблема обычно эффективно разрешается.
1. Аппроксимация нелинейной выпуклой 2 . Разбиения нелин невыпуклой области линейными ограничениями на несколько выпуклых областей
Их аппрокс линейными ограничениями
![]() В точках сетки берем частн произ и решение ЛП задач в каждой из них
В точках сетки берем частн произ и решение ЛП задач в каждой из них
и находим направление аппрокс-щих
линейных ограничений
3л кон
Матричная постановка канонической ЛП задачи
В матричном виде постановкa ЛПЗ имеет вид
требуем ![]() (*)
(*)
при ограниченияx Ax = b (**)
Здесь у нас m ограничений и n переменных х
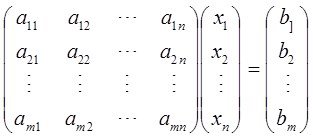
при с э Rn , x э Rn, b э Rm ,
A = A(m,n), rankA =m, (m<n),
![]() или иначе x =(x1,x2,...,xn):
или иначе x =(x1,x2,...,xn): ![]()
2.1.1 Общее и отличия в формализациях ЛП и МНК
Общее
- и МНК и ЛП - разновидности задач оптимизации
-и ЛП и МНК применяются для решения задач моделирования но в случае ЛП - мы гораздо больше можем сформулировать разнообразных ЗадМоделирования так как ограничения на область моделирования (неравенства) - естественный элемент ЗЛП - это очень интересно но на это у нас сейчас в курсе времени нет)
Отличия -
Оптимизацонная постановка МНК определяет функционал задачи мин 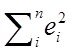 где
где ![]() - составляющие вектора невязок
- составляющие вектора невязок![]() условной системы уравнений
условной системы уравнений![]() , при этом
, при этом
матричная запись системы условных уравнений-требований в МНК
![]() (*)
(*)
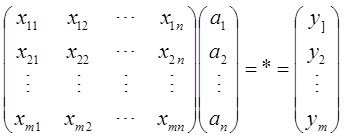 (О)
(О)
определяет переопределенную систему - то есть число ограничений- требований (точек х) к решению - m > n -числа переменных системы, и, то есть, больше чем число искомых параметров при них (то есть размерности вектора А)
Т.о. в постановке МНК мы имеем такуюспецифическую форму задачи оптимизации когда у нас нет допустимых решений - и мы находим наилучшее из недопустимых (дальше мы напомним механизм такого подхода)
А вот в задачеЛП когда mтребов>nпеременных - решения нет и ничего найти нельзя так как нет допустимой области решений.
То есть решение оптимизационной задачи в форме ЗЛП применимо только при недоопределенной системе типа (0) то есть когда nпеременных> mтребов
2.2.2 Подходы к решению несовместных оптимизационных задач
Рассмотрим задачу с линейным ф-лом 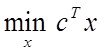 (*)
(*)
и ограничениями Ax = b (**)
при этом имеем ситуацию mтребов>nпеременных
Попытка решать ее через ЗЛП в лоб упирается в несовместность (**) и отсутствие ОДР ввиду m>n
Тогда введя в Ax= *= b невязки - вектор у = Ax - b имеем 2 пути решения
1. Вариант типа МНК:
Метод безусловной оптимизации при несовместной системе ограничений
Сформируем безусловный критерий
L=![]() и потребуем его минимизации
и потребуем его минимизации
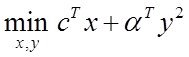 - здесь " у2 "- так как невязка может быть и +и -
- здесь " у2 "- так как невязка может быть и +и -
или правильнее 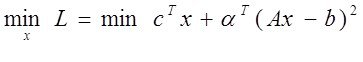
Далее как и в МНК берутся производные 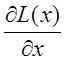 и приравнивая их нулю -получаем систему линейных уравнений относительно х
и приравнивая их нулю -получаем систему линейных уравнений относительно х
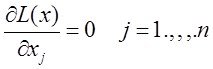
Остается вопрос балансировки требований к нашей задаче -
1.минимизации исходного критерия стх и 2. минимизации невязок у = Ax - b
Это вопрос выбора парамертров ![]() , в тривиальном случае берем все
, в тривиальном случае берем все ![]()
2. Второй вариант -
Использование ЗЛП для оптимизации при несовместной системе ограничений
И так - линейный ф-л 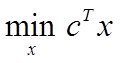 (*)
(*)
и ограничения Ax = b (**) при mогр>nпер
Рассм. минимизацию исходного ф-ла ![]() и модуля вектора невязок
и модуля вектора невязок
у =/ Ax - b /----тогда возможно получить задачууже в классе ЛП
( имеем в виду что
1.после введения в ограничения(**) вектора у в качестве невязок и
2. после приведения к канонической формесистемы (***) будем иметь уже количество mтребов<nпеременных )
Итак задача будет иметь вид 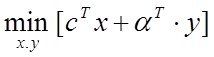
при ограничениях
(1***) ![]() (***)
(***)
(2***) ![]()
![]()
Понимаем что
если получается так, что в одном из(1***) Ax - b >0 то соответствующий "у" обязан быть некоторым + : у=(+) чтобы оно выполнлось и при этом работает минимизация "у" верхнего неравенства (1***) , а соответствующее нижнее (2***)автоматом выполняется,
если же получается так, что в одном из (2***) Ax - b <0 то соответствующий "у" также обязан быть некоторым +: у=(+) чтобы оно выполнялось и при этом работает минимизация "у" нижнего неравенства (2***) , а соответствующее верхнее (1***) автоматом выполняется
Минимизируется именно модуль невязки потому что структура неравенств системы (***) как видим обеспечивает всегда ![]() (
(![]() выполняется автоматом - это доказывается)
выполняется автоматом - это доказывается)
Таким образом убиваем 2 зайцев - осуществляем минимизациюисходного ф-ла ![]() и модуля вектора невязок у =/ Ax - b /
и модуля вектора невязок у =/ Ax - b /
Возникает однако как и в первом случае необходимо балансировать исходный критерий стх с требованием мин невязок у - это вопрос выбора вектора коэффициентов ![]() - но это естественная плата за то что с одной стороны имеемтребование мин стх а с другой несовместную систему из которой необходимо выбрать решение наиболее близкое к совместному этот компромис идолжны отражать параметры
- но это естественная плата за то что с одной стороны имеемтребование мин стх а с другой несовместную систему из которой необходимо выбрать решение наиболее близкое к совместному этот компромис идолжны отражать параметры ![]() . В тривиальном случае возьмем все альфа=1
. В тривиальном случае возьмем все альфа=1
Интересен частный случай вышеприведенной задачи -
Задача моделирования с минимизацией модульного критерия невязок
!!!!!!! итак - модульный критерий
вместо квадратичного - то с чего начиналось моделирование - помните Гаус и Лежандр продвигали квадратичный ф-нал и соответственно МНК а Лаплас- модульный ф-нал и эта задача как мы теперь увидим - решается с помощью ЗЛП
И так пусть мы имеем
Исх. данные задачи моделивания -  , и хотим определить параметры
, и хотим определить параметры ![]() моделі
моделі 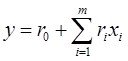 по критерию минимума сумы модулей невязок модели:
по критерию минимума сумы модулей невязок модели:
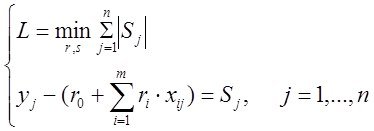
Как мы уже понимаем это частный случай предыдущей задачи:
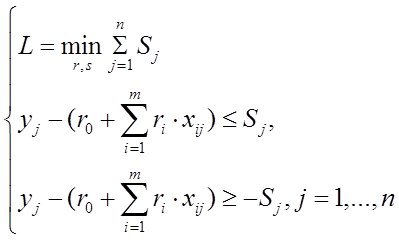
Обращаю ваше внимание, что выше оптимизация ведется по параметрам ri и невязкам s а известными являются элементы матрицы объект-свойства ![]()
И это неприятное, исторически сложившееся обстоятельство - несовпадение известных и неизвестных - коэффициетнов и искомых параметров в задачах моделирования и ЗЛП
- В ЛП аij- известные параметры а хi- неизвестные искомые значения, по котроым идет оптимизация
в МНК и в задачах моделирования - хij - обозначены известные зачения в матрице объект-свойства, а необходимо найти наилучший вектор параметров А - ai или R- ri
Такого типа нестыковки чрезвычайно мешают при формализации содержательной задачи в формализм ЛП который традиционно задается и при описании программных инструментов - вспомним линпрог.
Поэтому достаточно затратной частью решения любой оптимизационной или моделирования задачи есть реализация соответстующего интефейса связующего содержательные пересенные и константы и формализм ЗЛП в реализации конкретного программного инструмента
Подводя короткий итог
Исскуство формализации позволяет сформулировать близкие по содержательному смылу задачи и как задачи безусловной оптимизации и как ЗЛП что дает нам разнообразный инстументарий в руки.
отметим все же что ЗЛП нужна и чаще применяется в задачах где используются ограничения типа неравенств тогда, как правило, с учетом ввода дополнительных переменных, которых столько, сколько неравенств (для перевода задачи в каноническую форму) получаем недоопределенную систему - (m<n), а значит есть и множество область допустимых решений и среди этих допустимых, мы ищем налучшее -это естественное поле для ЗЛП
Однако моделирование через МНК имеет меньше вычислительных проблем.
(проблем с обусловленностью матрицы преабразований - шагов алгоритма гораздо меньше)
Какой подход применить в каждом конкретном случае - ваше профессональное решение
К л3
лк 4 Моделирование статических и простых динамических систем. Общий подход к моделированию систем по экспериментальным данным на примере линейных систем
И так - Первый вариант
Дана матрица объект-свойства Х, характеризующая некоторый объект в n
стационарных состояниях
X=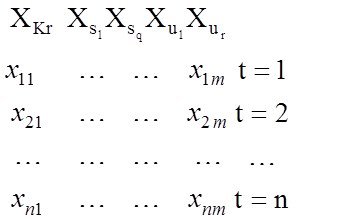 (1)
(1)
Предположения
1.Проведен причинно-следственный анализ, с тем, что-бы построенные регрессионные модели были корректны по направлению причинно-следственной связи (в данном случае - подразумеваем интуитивный прич-сл анализ)
2.Свойства данных таковы, что каждая точка описывает установившееся значения состояния объекта.
Динамикой объекта, в частости, инерционностью и возможным гистерезисом пренебрегается
3.Строятся линейные модели - хотя формализация нелинейных задач не представляет трудностей однако усложняет решение соотв. оптимиз. задачи
Второй вариант - дана матрица объект-свойства Х, характеризующая некоторое явление в которой данные по времени заменены выборкой по объектам.
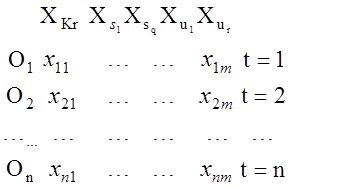 (2)
(2)
Матрицу (2) можно записать через блочные матрицы как (3)
![]() (3)
(3)
Подразумевается что выборка достаточно однородна (в идеале близнецы-объекты) для того что-бы такая замена была корректна. Для более корректной постановки в отличие от (1), в (2) или (3) целесообразно ввести переменные-параметры которыми объекты тем не менее отличаются (не близнецы ведь, реально на самом деле), тогда уточненный вариант (3) будет иметь вид (4)
![]() (4)
(4)
Пример
Пусть у объекта воспаленый процесс:
-критериальная переменная Хkr: СОЕ,
-переменные состояния Хс: Хс1-температура, Хс2- криотенин, Хс2-биллирубин,
-управления Хu: дозировки применяемых препаратов Хu1, Хu2, Хu3,
-переменные-параметры Хр: присутствие/отсутствие в анамнезе уточняющих обстоятельств, которые могут влиять на протекание процесса, пол, возраст, ets- Хр1, ...,Хрк. .
Продолжим
Тогда как для задачи с данными в форме (1) так и для задач с данными (2-4) возможно рассматривать некоторые оптимизационные задачи (далее запись оптимизационной приводим для наиболее общего случая в виде (4)):
Для этого выберем одну (или неск.) ![]() -критериальных перем. ,
-критериальных перем. ,
![]() - переменные которые характеризуют состояние объекта и
- переменные которые характеризуют состояние объекта и ![]() - перемен-е, которыми мы имеем возможность непосредственно влиять на объект. Остальные Хр1, ...,Хрк- это уже просто индивидуальные параметры объекта, назовем их "переменные-параметры" объекта.
- перемен-е, которыми мы имеем возможность непосредственно влиять на объект. Остальные Хр1, ...,Хрк- это уже просто индивидуальные параметры объекта, назовем их "переменные-параметры" объекта.
Тогда можем построить
1.линейные регрессионые модели связи (с учетом прич-следственного фильтра) между критериальной переменной и переменными управления, с учетом и параметров объекта: ![]()
2. линейные регрессионые модели связи (с учетом прич-следственного фильтра) между переменными состояния и переменными управления (и параметрами объекта) типа
![]() для переменных состояния системы
для переменных состояния системы
Полученные результаты используем для формализации линейной оптимизационной задачи расчета оптимального управляющего воздействия для конкретного выбранного объекта
![]() =
= ![]() (0)
(0)
введем в задачу ограничения вида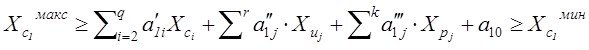
![]() (1)
(1)
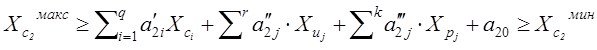
![]()
........................................
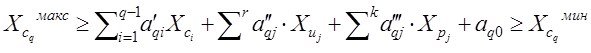
![]()
где значення ограничений ![]() ,
,![]() – это мин. и макс. значення соответствующих табличних значений переменных из имеющеся матрицы Х.
– это мин. и макс. значення соответствующих табличних значений переменных из имеющеся матрицы Х.
Справедливось данных ограничений для даного фиксированного периода (области значений) следует из того, что других значений для этих переменных за даний период не наблюдалось.
После подстановки в уравнение параметров конкретного объекта (это данные некоторого объекта из блочной части ![]() заданной нам матрицы Х или данные нового объекта ) можем записать задачу оптимизации уже подстроенную на конкретный объект (после подстановки соответствующие суммы превращаются в некоторые константы):
заданной нам матрицы Х или данные нового объекта ) можем записать задачу оптимизации уже подстроенную на конкретный объект (после подстановки соответствующие суммы превращаются в некоторые константы):
![]() =
= ![]() (0)
(0)
введем в задачу ограничения вида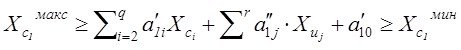
![]() (1)
(1)
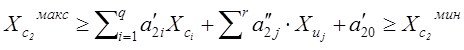
![]()
........................................
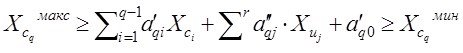
![]()
Константой ![]() во решения ЗО можно пренебречь, добавив ее после решения задачи
во решения ЗО можно пренебречь, добавив ее после решения задачи
Кроме того учтем все другие логические ограничения которые могут следовать из физического смысла задачи![]() (2)
(2)
Приведя полученную задачу к стандартному виду можем использовать стандартные средства решения задачи линейного программирования
Рассмотрим еще один класс объектов для задачи оптимизации -
Оптимизация состояния марковского процесса.
Подробнее о марковских процессах можно узнать в лит (например -Тихонов В.И., Миронов М.А. Марковские процессы).
Здесь отметим что далее мы рассмотрим дискретную марковскую систему (систему, состояние которой зависит только от состояния в предыдущий момент времени, то есть система с предисторией равной 1). То есть состояние системы в некоторый момент времени n - xn зависит только от его состояния в предыдущий момент времени n-1 - xn-1 (и управляюшего воздействия на этом шаге un ) и не зависит от предыдущих состояний системы xn-2 xn-3 .... (то есть от того, каким путем система пришла в xn-1 )
И так пусть рассматриваемая система - марковская и пусть известна расширенная (относительно (4)) матрица состояний системы (5) записанная для некоторых (n-1)-ого и n-ого состояний марковской системы. Запишем ее в блочном виде:
![]()
Содержательная интерпретация части матрицы ![]() описывает состояние объекта до воздействия (на некотором шаге),
описывает состояние объекта до воздействия (на некотором шаге), ![]() - после воздействия.
- после воздействия. ![]() может отсутствовать, если предполагаем марковкую систему, но в более общем случае ничто нам не мешает использовать знание управлений на предыдущем шаге.
может отсутствовать, если предполагаем марковкую систему, но в более общем случае ничто нам не мешает использовать знание управлений на предыдущем шаге.
Далее строим
1.линейные регрессионые модели связи (с учетом прич-следственного фильтра) между критериальной переменной, переменными управления, параметрами и предисторией: ![]() (6)
(6)
2. линейные регрессионые модели связи (с учетом прич-следственного фильтра) между переменными состояния, переменными управления, параметрами и предисторией
![]() (7)
(7)
для переменных состояния системы
Процесс формализации оптимизационной задачи для вида (5) отличается от выше рассмотренной задачи оптимизации для (4) только необходимостью подстановки в найденные модели (6,7) значений не только переменных-параметров объекта но и значений предистории критериальной переменной, предистории переменных состояния и управления системы того объекта для которого необходимо осуществить оптимизацию. После подстановки в уравнение параметров конкретного объекта и предистории можем записать задачу оптимизации уже подстроенную на конкретный объект. Псле подстановки соответствующие части модели превращаются в некоторые константы.
Далее осуществляем формирование (уже по настроенным на конкретный объект и предисторию моделям) оптимизационной задачи для расчета управлений таким же образом как и для задачи (4) .
2Лн Займемся 4 столбцом
Адекватность- в первом приближении - точность. Точность на известных нам данных. Критериями можно брать и ошибку и необясненную дисперсию и Кутум
Классическая оценка меры адекватности дает нам Фишеровская оценка ..... если
![]()
то уравнение регрессии адекватно (статистически значимо)
Это значение описывает результаты эксперимента при (![]() ) - процентном уровне значимости. Отношение
) - процентном уровне значимости. Отношение
полной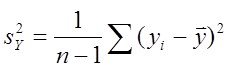 и остаточной
и остаточной 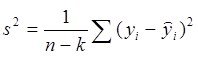 дисперсий)
дисперсий) ![]() показывает, во сколько раз уравнение регрессии аппроксимирует предсказывает результаты опыта лучше, чем среднее
показывает, во сколько раз уравнение регрессии аппроксимирует предсказывает результаты опыта лучше, чем среднее ![]() , где k – сумма числа входных переменных в модели плюс свободный член.
, где k – сумма числа входных переменных в модели плюс свободный член.
Мы должны однако помнить, что данная доверительная оценка резко ухудшается по мере удаления от среднего значения ![]() . В частности, по этой причине опасна экстраполяция эмпирической регрессионной зависимости за пределы интервала входных переменных
. В частности, по этой причине опасна экстраполяция эмпирической регрессионной зависимости за пределы интервала входных переменных ![]() , для которого она получена
, для которого она получена
По сути это значит что заранее признается неработоспособность модели на новых свежих данных если они по сути не повторяют старые!!!!!
Поэтому, действительное качество модели может быть заявлено как требуется в теории самоорганизации - только на свежих данных - поэтому
во втором приближении для оценки адекватности нужно определить оценки точности (ошибка, необясненная дисперсия, Кутум ....) на свежих данных. То есть на экзамене. Если точек мало (10-20) то расчитывают скользящий экзамен и за оценку адекватности берут его среднее.
Чувствительность модели
ЧМ рассм относительно
1.смещения ошибки выхода и 2. смещения оценки параметров модели
в зависимости от
1. вариации шумов в данных
2. смещении области моделирования
Небольшие значения ЧМ говорят о хорошем качестве модели
К сожалению часто неграмотно данные свойства называют устойчивостью модели относительно возмущений по шуму и и области моделирования
Устойчивость
Рассматривают это свойство для динамических моделей либо для многошаговых прогнозирующих
Рассм устояч-ь на примере линейных автономных дин систем
напомн уст тп, уст движение -
-при нач огр сост, при t![]() движ-е остется огранич-м
движ-е остется огранич-м
неуст тп, неуст движ -при нач огр сост, при t![]() движ-е х
движ-е х![]()
асс уст движение при нач огр сост, при t![]() движ-е х
движ-е х![]()
Рассм варианты движения
система и уравнение решения --
++ неу - - ау +- неу седл +0 -0 воробъи и комплексн варианты
Регулярность
- по сути это свойство для модели - "не терять прогнозируемость".
Классические причины потери свойства прогнозируемости -
1. Неуд. качество модели
Не угадали со структурой и/или получили смещенные оценки параметров
2. Неустойчивая схема интегрирования системы (в явных сх - резкое накопление погрешности с кождым шагам Инт, зависимость накопл погрешности от шага интегрированя)
Однако
как мин 2 причины могут подстерегать самую точную и идеально адекватную модель что-бы она потеряла свойство прогнозировать исследуемый процесс -
1.нахождение вблизи точки (пов) бифуркации и
2. Вхождение системы в режим динам хаоса
1.Бифуркационные точки системы
Покажем их влияние на промере лин дин авт систем 2-го порядка
система рис. уст траект
- пусть уст решение -корни -3 и -0.003
В силу принцип нестационарности любой системы параметры ее хоть немного но плавают - пусть попл чуть параметры аij![]() пусть при этом
пусть при этом
осталось уст. решение -корни -2 -0.033
рис - уст траектории
но если попл так что
- смест неуст. седл корни -2 +0.03 - рис траект неуст - седло
получили потерю изоморфизма траекторий до и после смещения
Изоморфизм в топологии - возможность поставить взаимно однозначное соответствие точки на траекториях до и после смешения параметров
Точка бифуркации по параметрам системы - точка в которой теряется изомофизм
В этой точке принципиально неизвестено по какому из двух закономерностях пойдет траектория. Чем ближе система по параметрам к ТБ тем выше вероятность потери прогнозируемости.
С учетом того, что параметров системы > чем корней, то на самом деле в пространстве параметров это не точки а поверхности бифуркаций.
Поэтому необходимо проводить исследования насколько система (по параметрам ) находится близко от поверхности бифуркаций
Динамический хаос
Второй распространенной причиной потери прогнозируемости - есть попадание системы в режим ДХ. - Чернобыль пример
Причин возникновения этого явления несколько.Приведем несколько необходимых условий для возникновения ДХ.
1.нелинейность системы,
2.неустойчивость системы
3.необходимая минимальная размерность пространства, 4.определенные специфические свойства нелинейности системы
5. принятие параметрами системы определенных значений из критической их области (пересечение с п.2)
В данных условиях в системе может возникнуть режим ДХ. Но возможны и другие обстоятельства при наличии которых возникнет ДХ
Интересный факт как определить система находится в ДХ? - или просто ее движение имеет сложный и пока для нас непрогнозируемый характер? -
Если в n-мерном простр системы провести сечение ее траекторий то есть рассечь клубок ее траекторий - то есть получить вариант ее представления в пространстве мерности n-1 ![]() то в сечении будем наблюдать фракталы - и разные системы будут отличаться различным значением фрактальной размерности данной области движения системы - этот факт напр используют для диагностики эпилепсии при анализе энцифалограммы мозга - это яркий пример хаотичного движения системы.
то в сечении будем наблюдать фракталы - и разные системы будут отличаться различным значением фрактальной размерности данной области движения системы - этот факт напр используют для диагностики эпилепсии при анализе энцифалограммы мозга - это яркий пример хаотичного движения системы.
Относительнно неустойчивости
покажем эффект потери прогнозируемости на примере линейной системы второго порядка. рис неуст лин сист +линза нач условий
Для нелинейных нестац систем показатель ![]() что и будет давать всевозможные кульбиты траектории и что в купе с неустойчивостью и представит нам режим ДХ.
что и будет давать всевозможные кульбиты траектории и что в купе с неустойчивостью и представит нам режим ДХ.
Надо иметь в виду что реальных линейных неустойчивых систем в природе не существует - они тогда должны были бы обладать неограниченной энергией. Но нелинейные системы могут быть неустойчивы в ограниченной области. Эти ограниченные области ДХ - имеют названия "странные аттракторы", Эти области представляют собой области притяжения (attraction)- так как в других частях пространства - система устойчива и всегда стремится
попасть в свой странный аттрактор если находится "не дома"
Относительно размерности пространства
В дискретных системах ДХ может возникать даже в одномерном пространстве, в непрерывных - при ![]() - некуда развернутся в клубок - у дифуров запрещены пересечения траекторий - осн свойство дин систием - у обного прошлого одно будущее (кроме особых точек - точек покоя), поэтому
- некуда развернутся в клубок - у дифуров запрещены пересечения траекторий - осн свойство дин систием - у обного прошлого одно будущее (кроме особых точек - точек покоя), поэтому
пример xn+1=xn +C
как в простейшей нелинейной дискретой системе возникает режим ДХ
Необходимый характер нелинейности - наличие в нелинейности правой части точки где произв =0 точки экстремумов (но не перегиба)
Исследования данных вопросов дадаут ответ о возможности потери прогнозируемости вследствие возникновения режима ДХ.
К- 2лк
Похожие материалы
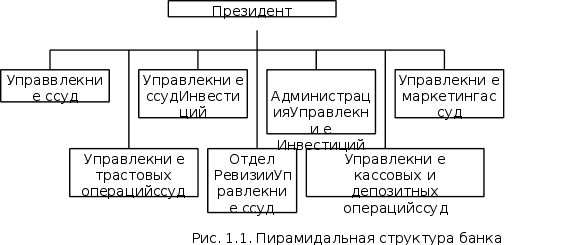
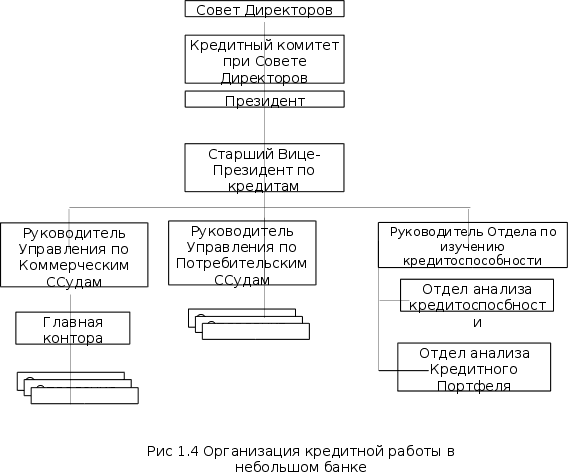
... выявления недостатков и «узких мест» этих систем и подготовке рекомендаций по улучшению функционирования и прогнозированию их развития в условиях информационной неопределенности. Глава 3 Системный анализ управления кредитами.3.1. Анализ кредитных задолженностей в 1995 и 1996 годах. Работа банковской системы любого государства определяется, прежде всего, конечными результатами, представленными в ...
... , связанным с планированием. Разные люди используют различные термины для определения одного и того же явления или понятия. Многие руководители пользуются как синонимами терминами «системный анализ», «исследование операций», «операционный анализ». Другие пытаются выделить специальные области исследований, определяемые перечисленными терминами. Если направить свой интерес на понимание смысла и ...
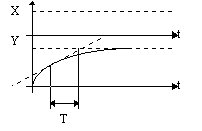
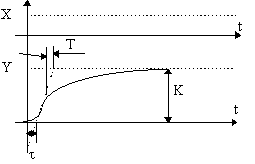

... моделью. Декомпозиция позволяет расчленить всю работу по реализации модели на пакет детальных работ, что позволяет решать вопросы их рациональной организации, мониторинга, контроля и т.д. Агрегирование. В системном анализе процесс, в определенном смысле противоположный декомпозиции – это агрегирование (дословно – соединение частей в целое). Для пояснения его сути приведем такой пример. Допустим, ...
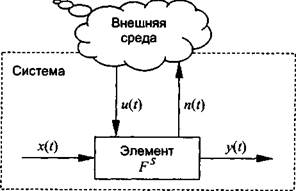
... , динамические и статические, простые и сложные, естественные и искусственные, с управлением и без управления, непрерывные и дискретные, детерминированные и стохастические, открытые и замкнутые. Основы системного анализа Деление систем на физические и абстрактные позволяет различать реальные системы (объекты, явления, процессы) и системы, являющиеся определенными отображениями (моделями) ре ...
0 комментариев