ОСНОВНЫЕ БЛОКИ GPSS/PC И СВЯЗАННЫЕ С НИМИ ОБЪЕКТЫ
Блоки, связанные с аппаратными объектами
Блоки для сбора статистических данных
Блоки, изменяющие маршруты транзактов
Блоки, работающие с памятью
УПРАВЛЯЮЩИЕ ОПЕРАТОРЫ GPSS/PC
НЕКОТОРЫЕ ПРИЕМЫ КОНСТРУИРОВАНИЯ GPSS-МОДЕЛЕЙ
Ввод новой модели
Получение и интерпретация стандартного отчета
Навигация
ОСНОВНЫЕ БЛОКИ GPSS/PC И СВЯЗАННЫЕ С НИМИ ОБЪЕКТЫ
Системы и сети связи на GPSS/PC
113808
знаков
0
таблиц
0
изображений
2. ОСНОВНЫЕ БЛОКИ GPSS/PC И СВЯЗАННЫЕ С НИМИ ОБЪЕКТЫ
2.1. Блоки, связанные с транзактами
С транзактами связаны блоки создания, уничтожения, задержки транзактов, изменения их атрибутов и создания копий транзактов.
Для создания транзактов, входящих в модель, служит блок GENERATE (генерировать), имеющий следующий формат:
имя GENERATE A,B,C,D,E
В поле A задается среднее значение интервала времени между моментами поступления в модель двух последовательных транзактов. Если этот интервал постоянен, то поле B не используется. Если же интервал поступления является случайной величиной, то в поле B указывается модификатор среднего значения, который может быть задан в виде модификатора-интервала или модификатора-функции.
Модификатор-интервал используется, когда интервал поступления транзактов является случайной величиной с равномерным законом распределения вероятностей. В этом случае в поле B может быть задан любой СЧА, кроме ссылки на функцию, а диапазон изменения интервала поступления имеет границы A-B, A+B.
Например, блок
GENERATE 100,40 создает транзакты через случайные интервалы времени, равномерно распределенные на отрезке [60;140].
Модификатор-функция используется, если закон распределения интервала поступления отличен от равномерного. В этом случае в поле B должна быть записана ссылка на функцию (ее СЧА), описывающую этот закон, и случайный интервал поступления определяется, как целая часть произведения поля A (среднего значения) на вычисленное значение функции.
В поле C задается момент поступления в модель первого транзакта. Если это поле пусто или равно 0, то момент появления первого транзакта определяется операндами A и B. Поле D задает общее число транзактов, которое должно быть создано блоком GENERATE. Если это поле пусто, то блок генерирует неограниченное число транзактов до завершения моделирования.
В поле E задается приоритет, присваиваемый генерируемым транзактам. Число уровней приоритетов неограничено, причем самый низкий приоритет - нулевой. Если поле E пусто, то генерируемые транзакты имeют нулевой приоритет.
Транзакты имеют ряд стандартных числовых атрибутов. Например, СЧА с названием PR позволяет ссылаться на приоритет транзакта. СЧА с названием M1 содержит так называемое резидентное время транзакта, т.е. время, прошедшее с момента входа транзакта в модель через блок GENERATE. СЧА с названием XN1 содержит внутренний номер транзакта, который является уникальным и позволяет всегда отличить один транзакт от другого. В отличие от СЧА других объектов, СЧА транзактов не содержат ссылки на имя или номер транзакта. Ссылка на СЧА транзакта всегда относится к активному транзакту, т.е. транзакту, обрабатываемому в данный момент симулятором.
Важными стандартными числовыми атрибутами транзактов являются значения их параметров. Любой транзакт может иметь неограниченное число параметров, содержащих те или иные числовые значения. Ссылка на этот СЧА транзактов всегда относится к активному транзакту и имеет вид P j или Р$ имя, где j и имя - номер и имя параметра соответственно. Такая ссылка возможна только в том случае, если параметр с указанным номером или именем существует, т.е. в него занесено какое-либо значение.
Для присваивания параметрам начальных значений или изменения этих значений служит блок ASSIGN (присваивать), имеющий следущий формат:
имя ASSIGN A,B,C
В поле A указывается номер или имя параметра, в который заносится значение операнда B. Если в поле A после имени (номера) параметра стоит знак + или -, то значение операнда B добавляется или вычитается из текущего содержимого параметра. В поле С может быть указано имя или номер функции-модификатора, действующей аналогично функции-модификатору в поле B блока GENERATE.
Например, блок
ASSIGN 5,0 записывает в параметр с номером 5 значение 0, а блок ASSIGN COUNT+,1 добавляет 1 к текущему значению параметра с именем COUNT.
Для записи текущего модельного времени в заданный параметр транзакта служит блок MARK (отметить), имеющий следующий формат:
имя MARK A
В поле A указывается номер или имя параметра транзакта, в который заносится текущее модельное время при входе этого транзакта в блок MARK. Содержимое этого параметра может быть позднее использовано для определения транзитного времени пребывания транзакта в какой-то части модели с помощью СЧА с названием MP.
Например, если на входе участка модели поместить блок
MARK MARKER, то на выходе этого участка СЧА MP$MARKER будет содержать разность между текущим модельным временем и временем, занесенным в параметр MARKER блоком MARK.
Если поле A блока MARK пусто, то текущее время заносится на место отметки времени входа транзакта в модель, используемой при определении резидентного времени транзакта с помощью СЧА M1.
Для изменения приоритета транзакта служит блок PRIORITY (приоритет), имеющий следующий формат:
имя PRIORITY A,B
В поле A записывается новый приоритет транзакта. В поле B может содержаться ключевое слово BU, при наличии которого транзакт, вошедший в блок, помещается в списке текущих событий после всех остальных транзактов новой приоритетной группы, и список текущих событий просматривается с начала. Использование такой возможности будет рассмотрено ниже.
Для удаления транзактов из модели служит блок TERMINATE (завершить), имеющий следующий формат:
имя TERMINATE A
Значение поля A указывает, на сколько единиц уменьшается содержимое так называемого счетчика завершений при входе транзакта в данный блок TERMINATE. Если поле A не определено, то оно считается равным 0, и транзакты, проходящие через такой блок, не уменьшают содержимого счетчика завершений.
Начальное значение счетчика завершений устанавливается управляющим оператором START (начать), предназначенным для запуска прогона модели. Поле A этого оператора содержит начальное значение счетчика завершений (см. разд. 3). Прогон модели заканчивается, когда содержимое счетчика завершений обращается в 0. Таким образом, в модели должен быть хотя бы один блок TERMINATE с непустым полем A, иначе процесс моделирования никогда не завершится.
Текущее значение счетчика завершений доступно программисту через системный СЧА TG1.
Участок блок-схемы модели, связанный с парой блоков GENERATE-ТERMINATE, называется сегментом. Простые модели могут состоять из одного сегмента, в сложных моделях может быть несколько сегментов.
Например, простейший сегмент модели, состоящий всего из двух блоков GENERATE и TERMINATE и приведенный на рис. 1, в совокупности с управлящим оператором START моделирует процесс создания случайного потока транзактов, поступащих в модель со средним интервалом в 100 единиц модельного времени, и уничтожения этих транзактов. Начальное значение счетчика завершений равно 1000. Каждый транзакт, проходящий через блок TERMINATE, вычитает из счетчика единицу, и таким образом моделирование завершится, когда тысячный по счету транзакт войдет в блок TERMINATE. При этом точное значение таймера в момент завершения прогона непредсказуемо. Следовательно, в приведенном примере продолжительность прогона устанавливается не по модельному времени, а по количеству транзактов, прошедших через модель.
1
GENERATE 100,40
TERMINATE 1
START 1000
1.5
Рис. 1
Если необходимо управлять продолжительностью прогона по модельному времени, то в модели используется специальный сегмент, называемый сегментом таймера.
1
GENERATE 100,40
TERMINATE
GENERATE 100000
TERMINATE 1
START 1
1.5
Рис. 2
Например, в модели из двух сегментов, приведенной на рис. 2, первый (основной) сегмент выполняет те же функции, что и в предыдущем примере. Заметим, однако, что поле A блока TERMINATE в первом сегменте пусто, т.е. уничтожаемые транзакты не уменьшают содержимого счетчика завершений. Во втором сегменте блок GENERATE создаст первый транзакт в момент модельного времени, равный 100000. Но этот транзакт окажется и последним в данном сегменте, так как, войдя в блок TERMINATE, он обратит в 0 содержимое счетчика завершений, установленное оператором START равным 1. Таким образом, в этой модели гарантируется завершение прогона в определенный момент модельного времени, а точное количество транзактов, прошедших через модель, непредсказуемо.
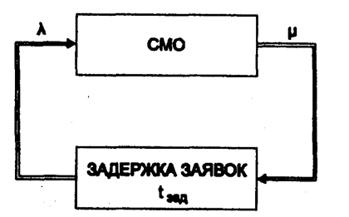
В приведенных примерах транзакты, входящие в модель через блок GENERATE, в тот же момент модельного времени уничтожались в блоке TERMINATE. В моделях систем массового обслуживания заявки обслуживаются приборами (каналами) СМО в течение некоторого промежутка времени прежде, чем покинуть СМО. Для моделирования такого обслуживания, т.е. для задержки транзактов на определенный отрезок модельного времени, служит блок ADVANCE (задержать), имеющий следующий формат:
имя ADVANCE A,B
Операнды в полях A и B имеют тот же смысл, что и в соответствующих полях блока GENERATE. Следует отметить, что транзакты, входящие в блок ADVANCE, переводятся из списка текущих событий в список будущих событий, а по истечении вычисленного времени задержки возвращаются назад, в список текущих событий, и их продвижение по блок-схеме продолжается. Если вычисленное время задержки равно 0, то транзакт в тот же момент модельного времени переходит в следующий блок, оставаясь в списке текущих событий.
Например, в сегменте, приведенном на рис. 3, транзакты, поступающие в модель из блока GENERATE через случайные интервалы времени, имеющие равномерное распределение на отрезке [60;140], попадают в блок ADVANCE. Здесь определяется случайное время задержки транзакта, имеющее равномерное распределение на отрезке [30;130], и транзакт переводится в список будущих событий. По истечении времени задержки транзакт возвращается в список текущих событий и входит в блок TERMINATE, где уничтожается. Заметим, что в списке будущих событий, а значит и в блоке ADVANCE может одновременно находиться произвольное количество транзактов.
1
GENERATE 100,40
ADVANCE 80,50
TERMINATE 1
1.5
Рис. 3
В рассмотренных выше примерах случайные интервалы времени подчинялись равномерному закону распределения вероятностей. Для получения случайных величин с другими распределениями в GPSS/PC используются вычислительные объекты: переменные и функции.
Как известно, произвольная случайная величина связана со случайной величиной R, имеющей равномерное распределение на отрезке [0;1], через свою обратную функцию распределения. Для некоторых случайных величин уравнение связи имеет явное решение, и значение случайной величины с заданным распределением вероятностей может быть вычислено через R по формуле. Так, например, значение случайной величины E с показательным (экспоненциальным) распределением с параметром d вычисляется по формуле:
E=-(1/d)*ln(R) Напомним, что параметр d имеет смысл величины, обратной математическому ожиданию E, а, следовательно, 1/d - математическое ожидание (среднее значение) случайной величины E.
Для получения случайной величины R с равномерным распределением на отрезке [0;1] в GPSS/PC имеются встроенные генераторы случайных чисел. Для получения случайного числа путем обращения к такому генератору достаточно записать системный СЧА RN с номером генератора, например RN1. Правда, встроенные генераторы случайных чисел GPSS/PC дают числа не на отрезке [0;1], а целые случайные числа, равномерно распределенные от 0 до 999, но их нетрудно привести к указанному отрезку делением на 1000.
Проще всего описанные вычисления в GPSS/PC выполняются с использованием арифметических переменных. Они могут быть целыми и действительными. Целые переменные определяются перед началом моделирования с помощью оператора определения VARIABLE (переменная), имеющего следующий формат:
имя VARIABLE выражение Здесь имя - имя переменной, используемое для ссылок на нее, а выра жение - арифметическое выражение, определяющее переменную. Арифметическое выражение представляет собой комбинацию операндов, в качестве которых могут выступать константы, СЧА и функции, знаков арифметических операций и круглых скобок. Следует заметить, что знаком операции умножения в GPSS/PC является символ # (номер). Результат каждой промежуточной операции в целых переменных преобразуется к целому типу путем отбрасывания дробной части, и, таким образом, результатом операции деления является целая часть частного.
Действительные переменные определяются перед началом моделирования с помощью оператора определения FVARIABLE, имеющего тот же формат, что и оператор VARIABLE. Отличие действительных переменных от целых заключается в том, что в действительных переменных все промежуточные операции выполняются с сохранением дробной части чисел, и лишь окончательный результат приводится к целому типу отбрасыванием дробной части.
Арифметические переменные обоих типов имеют единственный СЧА с названием V, значением которого является результат вычисления арифметического выражения, определяющего переменную. Вычисление выражения производится при входе транзакта в блок, содержащий ссылку на СЧА V с именем переменной.
Действительные переменные могут быть использованы для получения случайных интервалов времени с показательным законом распределения. Пусть в модели из примера на рис. 3 распределения времени поступления транзактов и времени задержки должны иметь показательный закон. Это может быть сделано так, как показано на рис. 4.
1
TARR FVARIABLE -100#LOG((1+RN1)/1000)
TSRV FVARIABLE -80#LOG((1+RN1)/1000)
GENERATE V$TARR
ADVANCE V$TSRV
TERMINATE 1
1.5
Рис. 4
Переменная с именем TARR задает выражение для вычисления интервала поступления со средним значением 100, вторая переменная с именем TSRV - для вычисления времени задержки со средним значением 80. Блоки GENERATE и ADVANCE содержат в поле A ссылки на соответствующие переменные, при этом поле B не используется, так как в поле A содержится случайная величина, не нуждающаяся в модификации.
Большинство случайных величин не может быть получено через случайную величину R с помощью арифметического выражения. Кроме того, такой способ является достаточно трудоемким, так как требует обращения к математическим функциям, вычисление которых требует десятков машинных операций. Другим возможным способом является использование вычислительных объектов GPSS/PC типа функция.
Функции используются для вычисления величин, заданных табличными зависимостями. Каждая функция определяется перед началом моделирования с помощью оператора определения FUNCTION (функция), имеющего следующий формат:
имя FUNCTION A,B Здесь имя - имя функции, используемое для ссылок на нее; A - стандартный числовой атрибут, являющийся аргументом функции; B - тип функции и число точек таблицы, определяющей функцию.
Существует пять типов функций. Рассмотрим вначале непрерывные числовые функции, тип которых кодируется буквой C. Так, например, в определении непрерывной числовой функции, таблица которой содержит 24 точки, поле B должно иметь значение C24.
При использовании непрерывной функции для генерирования случайных чисел ее аргументом должен быть один из генераторов случайных чисел RNj. Так, оператор для определения функции показательного распределения может иметь следующий вид:
EXP FUNCTION RN1,C24 Особенностью использования встроенных генераторов случайных чисел RNj в качестве аргументов функций является то, что их значения в этом контексте интерпретируются как дробные числа от 0 до 0,999999.
Таблица с координатами точек функции располагается в строках, следующих непосредственно за оператором FUNCTION. Эти строки не должны иметь поля нумерации. Каждая точка таблицы задается парой Xi (значение аргумента) и Yi (значение функции), отделяемых друг от друга запятой. Пары координат отделяются друг от друга символом "/" и располагаются на произвольном количестве строк. Последовательность значений аргумента Xi должна быть строго возрастающей.
Как уже отмечалось, при использовании функции в поле B блоков GENERATE и ADVANCE вычисление интервала поступления или времени задержки производится путем умножения операнда A на вычисленное значение функции. Отсюда следует, что функция, используемая для генерирования случайных чисел с показательным распределением, должна описывать зависимость y=-ln(x), представленную в табличном виде. Оператор FUNCTION с такой таблицей, содержащей 24 точки для обеспечения достаточной точности аппроксимации, имеет следующий вид:
1
EXP FUNCTION RN1,C24
0,0/.1,.104/.2,.222/.3,.355/.4,.509/.5,.69/.6,.915
.7,1.2/.75,1.38/.8,1.6/.84,1.85/.88,2.12/.9,2.3
.92,2.52/.94,2.81/.95,2.99/.96,3.2/.97,3.5/.98,3.9
1.5
.99,4.6/.995,5.3/.998,6.2/.999,7/.9998,8
Вычисление непрерывной функции производится следующим образом. Сначала определяется интервал (Xi;Xi+1), на котором находится текущее значение СЧА-аргумента (в нашем примере - сгенерированное значение RN1). Затем на этом интервале выполняется линейная интерполяция с использованием соответствующих значений Yi и Yi+1. Результат интерполяции усекается (отбрасыванием дробной части) и используется в качестве значения функции. Если функция служит операндом B блоков GENERATE или ADVANCE, то усечение результата производится только после его умножения на значение операнда A.
Использование функций для получения случайных чисел с заданным распределением дает хотя и менее точный результат за счет погрешностей аппроксимации, но зато с меньшими вычислительными затратами (несколько машинных операций на выполнение линейной интерполяции). Чтобы к погрешности аппроксимации не добавлять слишком большую погрешность усечения, среднее значение при использовании показательных распределений должно быть достаточно большим (не менее 50). Эта рекомендация относится и к использованию переменных.
Функции всех типов имеют единственный СЧА с названием FN, значением которого является вычисленное значение функции. Вычисление функции производится при входе транзакта в блок, содержащий ссылку на СЧА FN с именем функции.
Заменим в примере на рис. 4 переменные TARR и TSRV на функцию EXP (рис. 5).
Поскольку в обеих моделях используется один и тот же генератор RN1, интервалы поступления и задержки, вычисляемые в блоках GENERATE и ADVANCE, должны получиться весьма близкими, а может быть и идентичными. При большом количестве транзактов, пропускаемых через модель (десятки и сотни тысяч), разница в скорости вычислений должна стать заметной.
1
EXP FUNCTION RN1,C24
0,0/.1,.104/.2,.222/.3,.355/.4,.509/.5,.69/.6,.915
.7,1.2/.75,1.38/.8,1.6/.84,1.85/.88,2.12/.9,2.3
.92,2.52/.94,2.81/.95,2.99/.96,3.2/.97,3.5/.98,3.9
.99,4.6/.995,5.3/.998,6.2/.999,7/.9998,8
GENERATE 100,FN$EXP
ADVANCE 80,FN$EXP
TERMINATE 1
1.5
Рис. 5
Особенностью непрерывных функций является то, что они принимают "непрерывные" (но только целочисленные) значения в диапазоне от Y1 до Yn, где n - количество точек таблицы. В отличие от них диск ретные числовые функции, тип которых кодируется буквой D в операнде B оператора определения функции, принимают только отдельные (дискретные) значения, заданные координатами Yi в строках, следующих за оператором определения FUNCTION. При вычислении дискретной функции текущее значение СЧА-аргумента, указанного в поле A оператора FUNCTION, сравнивается по условию <= последовательно со всеми значениями упорядоченных по возрастанию координат Xi до выполнения этого условия при некотором i. Значением функции становится целая часть соответствующего значения Yi.
Если последовательность значений аргумента таблицы с координатами точек функции представляет числа натурального ряда (1,2,3,...,n), то такую дискретную функцию с целью экономии памяти и машинного времени удобно определить как списковую числовую функ цию (тип L).
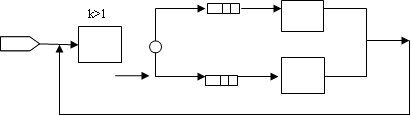
Пусть в модели на рис. 5 заявки, моделируемые транзактами, с равной вероятностью 1/3 должны относиться к одному из трех классов (типов) 1,2 и 3, а среднее время задержки обслуживания заявок каждого типа должно составлять соответственно 70, 80 и 90 единиц модельного времени. Это может быть обеспечено способом, показанным на рис. 6.
В блоке ASSIGN в параметр TYPE каждого сгенерированного транзакта заносится тип заявки, получаемый с помощью дискретной функции CLASS. Аргументом функции является генератор случайных чисел RN1, а координаты ее таблицы представляют собой обратную функцию распределения дискретной случайной величины "класс заявки" с одинаковыми вероятностями каждого из трех значений случайной величины.
Поле A блока ADVANCE содержит ссылку на списковую функцию MEAN, аргументом которой служит параметр TYPE входящих в блок транзактов. В зависимости от значений этого параметра (типа заявки) среднее время задержки принимает одно из трех возможных значений функции MEAN: 70, 80 или 90 единиц.
1
EXP FUNCTION RN1,C24
0,0/.1,.104/.2,.222/.3,.355/.4,.509/.5,.69/.6,.915
.7,1.2/.75,1.38/.8,1.6/.84,1.85/.88,2.12/.9,2.3
.92,2.52/.94,2.81/.95,2.99/.96,3.2/.97,3.5/.98,3.9
.99,4.6/.995,5.3/.998,6.2/.999,7/.9998,8
CLASS FUNCTION RN1,D3
.333,1/.667,2/1,3
MEAN FUNCTION P$TYPE,L3
1,70/2,80/3,90
GENERATE 100,FN$EXP
ASSIGN TYPE,FN$CLASS
ADVANCE FN$MEAN,FN$EXP
TERMINATE 1
1.5
Рис. 6
Следует отметить, что в данном примере можно было бы не использовать параметр TYPE и обойтись одной дискретной функцией, возвращающей с равной вероятностью одно из трех возможных значений среднего времени задержки. Однако использование параметров дает некоторые дополнительные возможности, которые будут рассмотрены позже.
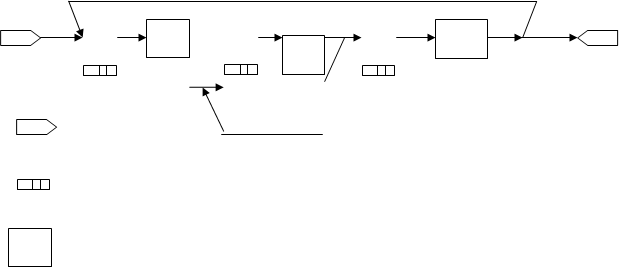
Транзакты могут входить в модель не только через блок GENERATE, но и путем создания копий уже существующих транзактов в блоке SPLIT (расщепить), имеющем следующий формат:
имя SPLIT A,B,C
В поле A задается число создаваемых копий исходного транзакта (родителя), входящего в блок SPLIT. После выхода из блока SPLIT транзакт-родитель направляется в следующий блок, а все транзакты-потомки поступают в блок, указанный в поле B. Если поле B пусто, то все копии поступают в следующий блок.
Транзакт-родитель и его потомки, выходящие из блока SPLIT, могут быть пронумерованы в параметре, имя или номер которого указаны в поле C. Если у транзакта-родителя значение этого параметра при входе в блок SPLIT было равно k, то при выходе из блока оно станет равным k+1, а значения этого параметра у транзактов-потомков окажутся равными k+2, k+3 и т.д.
Например, блок
SPLIT 5,MET1,NUM создает пять копий исходного транзакта и направляет их в блок с именем MET1. Транзакт-родитель и потомки нумеруются в параметре с именем NUM. Если, например, перед входом в блок значение этого параметра у транзакта-родителя было равно 0, то при выходе из блока оно станет равным 1, а у транзактов-потомков значения параметра NUM будут равны 2, 3, 4, 5 и 6.
Похожие работы
... того, имеется ряд так называемых системных атрибутов, относящихся не к отдельным объектам, а к модели в целом. Значения атрибутов всех объектов модели по окончании моделирования Выводятся в стандартный отчет GPSS/PC. Большая часть атрибутов дос- тупна программисту и составляет так называемые стандартные число- вые атрибуты (СЧА), 0которые могут использоваться в ...


... 6. Петухов О.А. , Морозов А.В. , Петухова Е.О. Моделирование системное, имитационное, аналитическое. Учебное пособие – Санкт-Петербург 2008 7. Норенков И.П., Федорук Е.В.Имитационное моделирование систем массового обслуживания. Методические указания – Москва 1999 8. Кутузов О.И., Татарникова Т.М., Петров К.О. Распределенные информационные системы управления. Учебное пособие – Санкт-Петербург ...
... них 10 час. – обзорные лекции, 4 час. –практические занятия, 6 час. – лабораторные работы на ЭВМ. Рабочая программа курса «Моделирование систем радиосвязи и сетей радиовещания». СОДЕРЖАНИЕ ДИСЦИПЛИНЫ 1 Введение Цели и задачи дисциплины. Основные понятия теории моделирования систем. Использование моделирования при исследовании и проектировании сетей ...
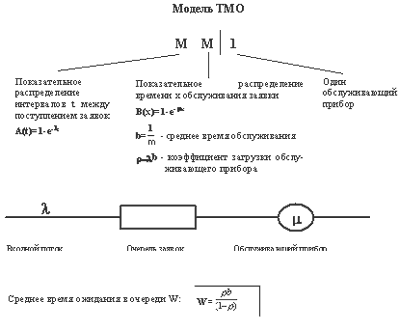
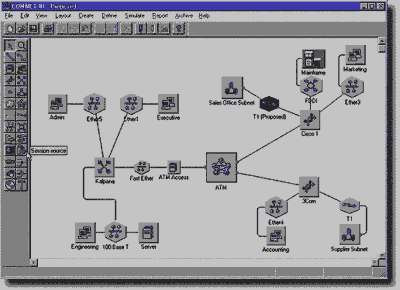
... , пакетов и кадров внутри операционной системы, процесс получения доступа компьютером к разделяемой сетевой среде, процесс обработки поступающих пакетов маршрутизатором и т.д. При имитационном моделировании сети не требуется приобретать дорогостоящее оборудование - его работы имитируется программами, достаточно точно воспроизводящими все основные особенности и параметры такого оборудования. ...
0 комментариев