Навигация
1 <1 блок кода>
Subr(<параметры>)
2 <2 блок кода>
End Sub
Используем специальную метку «0» для обозначения конца «рекурсии». Теперь можно переписать процедуру без использования рекурсии, например, так:
Sub Subr(num)
Dim pc As Integer ' Определяет, где нужно продолжить рекурсию.
pc = 1 ' Начать сначала.
Do
Select Case pc
Case 1
<1 блок кода>
If (достигнуто условие остановки) Then
' Пропустить рекурсию и перейти к блоку 2.
pc = 2
Else
' Сохранить переменные, нужные после рекурсии.
' Сохранить pc = 2. Точка, с которой продолжится
' выполнение после возврата из "рекурсии".
' Установить переменные, нужные для рекурсии.
' Например, num = num - 1.
:
' Перейти к блоку 1 для начала рекурсии.
pc = 1
End If
Case 2 ' Выполнить 2 блок кода
<2 блок кода>
pc = 0
Case 0
If (это последняя рекурсия) Then Exit Do
' Иначе восстановить pc и другие переменные,
' сохраненные перед рекурсией.
End Select
Loop
End Sub
======106
Переменная pc, которая соответствует счетчику программы, сообщает процедуре, какой шаг она должна выполнить следующим. Например, при pc = 1, процедура должна выполнить 1 блок кода.
Когда процедура достигает условия остановки, она не выполняет рекурсию. Вместо этого, она присваивает pc значение 2, и продолжает выполнение 2 блока кода.
Если процедура не достигла условия остановки, она выполняет «рекурсию». Для этого она сохраняет значения всех локальных переменных, которые ей понадобятся позже после завершения «рекурсии». Она также сохраняет значение pc для участка кода, который она будет выполнять после завершения «рекурсии». В этом примере следующим выполняется 2 блок кода, поэтому она сохраняет 2 в качестве следующего значения pc. Самый простой способ сохранения значений локальных переменных и pc состоит в использовании стеков, подобных тем, которые описывались в 3 главе.
Реальный пример поможет вам понять эту схему. Рассмотрим слегка измененную версию функции факториала. В нем переписана только подпрограмма, которая возвращает свое значение при помощи переменной, а не функции, для упрощения работы.
Private Sub Factorial(num As Integer, value As Integer)
Dim partial As Integer
1 If num <= 1 Then
value = 1
Else
Factorial(num - 1, partial)
2 value = num * partial
End If
End Sub
После возврата процедуры из рекурсии, требуется узнать исходное значение переменной num, чтобы выполнить операцию умножения value = num * partial. Поскольку процедуре требуется доступ к значению num после возврата из рекурсии, она должна сохранять значение переменных pc и num до начала рекурсии.
Следующая процедура сохраняет эти значения в двух стеках на основе массивов. При подготовке к рекурсии, она проталкивает значения переменных num и pc в стеки. После завершения рекурсии, она выталкивает добавленные последними значения из стеков. Следующий код демонстрирует нерекурсивную версию подпрограммы вычисления факториала.
Private Sub Factorial(num As Integer, value As Integer)
ReDim num_stack(1 to 200) As Integer
ReDim pc_stack(1 to 200) As Integer
Dim stack_top As Integer ' Вершина стека.
Dim pc As Integer
pc = 1
Do
Select Case pc
Case 1
If num <= 1 Then ' Это условие остановки. value = 1
pc = 0 ' Конец рекурсии.
Else ' Рекурсия.
' Сохранить num и следующее значение pc.
stack_top = stack_top + 1
num_stack(stack_top) = num
pc_stack(stack_top) = 2 ' Возобновить с 2.
' Начать рекурсию.
num = num - 1
' Перенести блок управления в начало.
pc = 1
End If
Case 2
' value содержит результат последней
' рекурсии. Умножить его на num.
value = value * num
' "Возврат" из "рекурсии".
pc = 0
Case 0
' Конец "рекурсии".
' Если стеки пусты, исходный вызов
' подпрограммы завершен.
If stack_top <= 0 Then Exit Do
' Иначе восстановить локальные переменные и pc.
num = num_stack(stack_top)
pc = pc_stack(stack_top)
stack_top = stacK_top - 1
End Select
Loop
End Sub
Так же, как и устранение хвостовой рекурсии, этот метод имитирует поведение рекурсивного алгоритма. Процедура заменяет каждый рекурсивный вызов итерацией цикла While. Поскольку число шагов остается тем же самым, полное время выполнения алгоритма не изменяется.
Так же, как и в случае с устранением хвостовой рекурсии, этот метод устраняет глубокую рекурсию, которая может переполнить стек.
Нерекурсивное построение кривых ГильбертаПример вычисления факториала из предыдущего раздела превратил простую, но неэффективную рекурсивную функцию вычисления факториала в сложную и неэффективную нерекурсивную процедуру. Намного лучший нерекурсивный алгоритм вычисления факториала, был представлен ранее в этой главе.
=======107-108
Может оказаться достаточно трудно найти простую нерекурсивную версию для более сложных алгоритмов. Методы из предыдущего раздела могут быть полезны, если алгоритм содержит многократную или косвенную рекурсию.
В качестве более интересного примера, рассмотрим нерекурсивный алгоритм построения кривых Гильберта.
Private Sub Hilbert(depth As Integer, Dx As Single, Dy As Single)
If depth > 1 Then Hilbert depth - 1, Dy, Dx
HilbertPicture.Line -Step(Dx, Dy)
If depth > 1 Then Hilbert depth - 1, Dx, Dy
HilbertPicture.Line -Step(Dy, Dx)
If depth > 1 Then Hilbert depth - 1, Dx, Dy
HilbertPicture.Line -Step(-Dx, -Dy)
If depth > 1 Then Hilbert depth - 1, -Dy, -Dx
End Sub
В следующем фрагменте кода первые строки каждого блока кода между рекурсивными шагами пронумерованы. Эти блоки включают первую строку процедуры и любые другие точки, в которых может понадобиться продолжить выполнение после возврата после «рекурсии».
Private Sub Hilbert(depth As Integer, Dx As Single, Dy As Single)
1 If depth > 1 Then Hilbert depth - 1, Dy, Dx
2 HilbertPicture.Line -Step(Dx, Dy)
If depth > 1 Then Hilbert depth - 1, Dx, Dy
3 HilbertPicture.Line -Step(Dy, Dx)
If depth > 1 Then Hilbert depth - 1, Dx, Dy
4 HilbertPicture.Line -Step(-Dx, -Dy)
If depth > 1 Then Hilbert depth - 1, -Dy, -Dx
End Sub
Каждый раз, когда нерекурсивная процедура начинает «рекурсию», она должна сохранять значения локальных переменных Depth, Dx, и Dy, а также следующее значение переменной pc. После возврата из «рекурсии», она восстанавливает эти значения. Для упрощения работы, можно написать пару вспомогательных процедур для заталкивания и выталкивания этих значений из нескольких стеков.
====109
Const STACK_SIZE =20
Dim DepthStack(0 To STACK_SIZE)
Dim DxStack(0 To STACK_SIZE)
Dim DyStack(0 To STACK_SIZE)
Dim PCStack(0 To STACK_SIZE)
Dim TopOfStack As Integer
Private Sub SaveValues (Depth As Integer, Dx As Single, _
Dy As Single, pc As Integer)
TopOfStack = TopOfStack + 1
DepthStack(TopOfStack) = Depth
DxStack(TopOfStack) = Dx
DyStack(TopOfStack) = Dy
PCStack(TopOfStack) = pc
End Sub
Private Sub RestoreValues (Depth As Integer, Dx As Single, _
Dy As Single, pc As Integer)
Depth = DepthStack(TopOfStack)
Dx = DxStack(TopOfStack)
Dy = DyStack(TopOfStack)
pc = PCStack(TopOfStack)
TopOfStack = TopOfStack - 1
End Sub
Следующий код демонстрирует нерекурсивную версию подпрограммы Hilbert.
Private Sub Hilbert(Depth As Integer, Dx As Single, Dy As Single)
Dim pc As Integer
Dim tmp As Single
pc = 1
Do
Select Case pc
Case 1
If Depth > 1 Then ' Рекурсия.
' Сохранить текущие значения.
SaveValues Depth, Dx, Dy, 2
' Подготовиться к рекурсии.
Depth = Depth - 1
tmp = Dx
Dx = Dy
Dy = tmp
pc = 1 ' Перейти в начало рекурсивного вызова.
Else ' Условие остановки.
' Достаточно глубокий уровень рекурсии.
' Продолжить со 2 блоком кода.
pc = 2
End If
Case 2
HilbertPicture.Line -Step(Dx, Dy)
If Depth > 1 Then ' Рекурсия.
' Сохранить текущие значения.
SaveValues Depth, Dx, Dy, 3
' Подготовиться к рекурсии.
Depth = Depth - 1
' Dx и Dy остаются без изменений.
pc = 1 Перейти в начало рекурсивного вызова.
Else ' Условие остановки.
' Достаточно глубокий уровень рекурсии.
' Продолжить с 3 блоком кода.
pc = 3
End If
Case 3
HilbertPicture.Line -Step(Dy, Dx)
If Depth > 1 Then ' Рекурсия.
' Сохранить текущие значения.
SaveValues Depth, Dx, Dy, 4
' Подготовиться к рекурсии.
Depth = Depth - 1
' Dx и Dy остаются без изменений.
pc = 1 Перейти в начало рекурсивного вызова.
Else ' Условие остановки.
' Достаточно глубокий уровень рекурсии.
' Продолжить с 4 блоком кода.
pc = 4
End If
Case 4
HilbertPicture.Line -Step(-Dx, -Dy)
If Depth > 1 Then ' Рекурсия.
' Сохранить текущие значения.
SaveValues Depth, Dx, Dy, 0
' Подготовиться к рекурсии.
Depth = Depth - 1
tmp = Dx
Dx = -Dy
Dy = -tmp
pc = 1 Перейти в начало рекурсивного вызова.
Else ' Условие остановки.
' Достаточно глубокий уровень рекурсии.
' Конец этого рекурсивного вызова.
pc = 0
End If
Case 0 ' Возврат из рекурсии.
If TopOfStack > 0 Then
RestoreValues Depth, Dx, Dy, pc
Else
' Стек пуст. Выход.
Exit Do
End If
End Select
Loop
End Sub
======111
Время выполнения этого алгоритма может быть нелегко оценить непосредственно. Поскольку методы преобразования рекурсивных процедур в нерекурсивные не изменяют время выполнения алгоритма, эта процедура так же, как и предыдущая версия, имеет время выполнения порядка O(N4).
Программа Hilbert2 демонстрирует нерекурсивный алгоритм построения кривых Гильберта. Задавайте вначале построение несложных кривых (меньше 6 порядка), пока не узнаете, насколько быстро будет выполняться эта программа на вашем компьютере.
Нерекурсивное построение кривых СерпинскогоПриведенный ранее алгоритм построения кривых Серпинского включает в себя косвенную и множественную рекурсию. Так как алгоритм состоит из четырех подпрограмм, которые вызывают друг друга, то нельзя просто пронумеровать важные строки, как это можно было сделать в случае алгоритма построения кривых Гильберта. С этой проблемой можно справиться, слегка изменив алгоритм.
Рекурсивная версия этого алгоритма состоит из четырех подпрограмм SierpA, SierpB, SierpC и SierpD. Подпрограмма SierpA выглядит так:
Private Sub SierpA(Depth As Integer, Dist As Single)
If Depth = 1 Then
Line -Step(-Dist, Dist)
Line -Step(-Dist, 0)
Line -Step(-Dist, -Dist)
Else
SierpA Depth - 1, Dist
Line -Step(-Dist, Dist)
SierpB Depth - 1, Dist
Line -Step(-Dist, 0)
SierpD Depth - 1, Dist
Line -Step(-Dist, -Dist)
SierpA Depth - 1, Dist
End If
End Sub
Три другие процедуры аналогичны. Несложно объединить эти четыре процедуры в одну подпрограмму.
Private Sub SierpAll(Depth As Integer, Dist As Single, Func As Integer)
Select Case Punc
Case 1 ' SierpA
<код SierpA code>
Case 2 ' SierpB
<код SierpB>
Case 3 ' SierpC
<код SierpC>
Case 4 ' SierpD
<код SierpD>
End Select
End Sub
======112
Параметр Func сообщает подпрограмме, какой блок кода выполнять. Вызовы подпрограмм заменяются на вызовы процедуры SierpAll с соответствующим значением Func. Например, вызов подпрограммы SierpA заменяется на вызов процедуры SierpAll с параметром Func, равным 1. Таким же образом заменяются вызовы подпрограмм SierpB, SierpC и SierpD.
Полученная процедура рекурсивно вызывает себя в 16 различных точках. Эта процедура намного сложнее, чем процедура Hilbert, но в других отношениях она имеет такую же структуру и поэтому к ней можно применить те же методы устранения рекурсии.
Можно использовать первую цифру меток pc, для определения номера блока кода, который должен выполняться. Перенумеруем строки в коде SierpA числами 11, 12, 13 и т.д. Перенумеруем строки в коде SierpB числами 21, 22, 23 и т.д.
Теперь можно пронумеровать ключевые строки кода внутри каждого из блоков. Для кода подпрограммы SierpA ключевыми строками будут:
' Код SierpA.
11 If Depth = 1 Then
Line -Step(-Dist, Dist)
Line -Step(-Dist, 0)
Line -Step(-Dist, -Dist)
Else
SierpA Depth - 1, Dist
12 Line -Step(-Dist, Dist)
SierpB Depth - 1, Dist
13 Line -Step(-Dist, 0)
SierpD Depth - 1, Dist
14 Line -Step(-Dist, -Dist)
SierpA Depth - 1, Dist
End If
Типичная «рекурсия» из кода подпрограммы SierpA в код подпрограммы SierpB выглядит так:
SaveValues Depth, 13 ' Продолжить с шага 13 после завершения.
Depth = Depth - 1
pc = 21 ' Передать управление на начало кода SierpB.
======113
Метка 0 зарезервирована для обозначения выхода из «рекурсии». Следующий код демонстрирует нерекурсивную версию процедуры SierpAll. Код для подпрограмм SierpB, SierpC, и SierpD аналогичен коду для SierpA, поэтому он опущен.
Private Sub SierpAll(Depth As Integer, pc As Integer)
Do
Select Case pc
' **********
' * SierpA *
' **********
Case 11
If Depth <= 1 Then
SierpPicture.Line -Step(-Dist, Dist)
SierpPicture.Line -Step(-Dist, 0)
SierpPicture.Line -Step(-Dist, -Dist)
pc = 0
Else
SaveValues Depth, 12 ' Выполнить SierpA
Depth = Depth - 1
pc = 11
End If
Case 12
SierpPicture.Line -Step(-Dist, Dist)
SaveValues Depth, 13 ' Выполнить SierpB
Depth = Depth - 1
pc = 21
Case 13
SierpPicture.Line -Step(-Dist, 0)
SaveValues Depth, 14 ' Выполнить SierpD
Depth = Depth - 1
pc = 41
Case 14
SierpPicture.Line -Step(-Dist, -Dist)
SaveValues Depth, 0 ' Выполнить SierpA
Depth = Depth - 1
pc = 11
' Код для SierpB, SierpC и SierpD опущен.
:
' *******************
' * Конец рекурсии. *
' *******************
Case 0
If TopOfStack <= 0 Then Exit Do
RestoreValues Depth, pc
End Select
Loop
End Sub
=====114
Так же, как и в случае с алгоритмом построения кривых Гильберта, преобразование алгоритма построения кривых Серпинского в нерекурсивную форму не изменяет время выполнения алгоритма. Новая версия алгоритма имитирует рекурсивный алгоритм, который выполняется за время порядка O(N4), поэтому порядок времени выполнения новой версии также составляет O(N4). Она выполняется немного медленнее, чем рекурсивная версия, и является намного более сложной.
Нерекурсивная версия также могла бы рисовать кривые более высоких порядков, но построение кривых Серпинского с порядком выше 8 или 9 непрактично. Все эти факты определяют преимущество рекурсивного алгоритма.
Программа Sierp2 использует этот нерекурсивный алгоритм для построения кривых Серпинского. Задавайте вначале построение несложных кривых (меньше 6 порядка), пока не определите, насколько быстро будет выполняться эта программа на вашем компьютере.
РезюмеПри применении рекурсивных алгоритмов следует избегать трех основных опасностей:
· Бесконечной рекурсии. Убедитесь, что условия остановки вашего алгоритма прекращают все рекурсивные пути.
· Глубокой рекурсии. Если алгоритм достигает слишком большой глубины рекурсии, он может привести к переполнению стека. Минимизируйте использование стека за счет уменьшения числа определяемых в процедуре переменных, использования глобальных переменных, или определения переменных как статических. Если процедура все равно приводит к переполнению стека, перепишите алгоритм в нерекурсивном виде, используя устранение хвостовой рекурсии.
· Ненужной рекурсии. Обычно это происходит, если алгоритм типа рекурсивного вычисления чисел Фибоначчи, многократно вычисляет одни и те же промежуточные значения. Если вы столкнетесь с этой проблемой в своей программе, попробуйте переписать алгоритм, используя подход снизу вверх. Если алгоритм не позволяет прибегнуть к подходу снизу вверх, создайте таблицу промежуточных значений.
Применение рекурсии не всегда неправильно. Многие задачи являются рекурсивными по своей природе. В этих случаях рекурсивный алгоритм будет проще понять, отлаживать и поддерживать, чем его нерекурсивную версию. В качестве примера можно привести алгоритмы построения кривых Гильберта и Серпинского. Оба по своей природе рекурсивны и намного понятнее, чем их нерекурсивные модификации. При этом рекурсивные версии даже выполняются немного быстрее.
Если у вас есть алгоритм, который рекурсивен по своей природе, но вы не уверены, будет ли рекурсивная версия лишена проблем, запишите алгоритм в рекурсивном виде и выясните это. Может быть, проблемы не возникнут. Если же они возникнут, то, возможно, окажется проще преобразовать эту рекурсивную версию в нерекурсивную, чем написать нерекурсивную версию с нуля.
======115
Глава 6. ДеревьяВо 2 главе приводились способы создания динамических связных структур, таких, как изображенные на рис 6.1. Такие структуры данных называются графами (graphs). В 12 главе алгоритмы работы с графами и сетями обсуждаются более подробно. В этой главе рассматриваются графы особого типа, которые называются деревьями (trees).
В начале этой главы приводится определение дерева и разъясняются некоторые термины. Затем в ней описываются некоторые методы реализации деревьев различных типов на языке Visual Basic. В последующих разделах рассматривается несколько алгоритмов обхода для деревьев, записанных в этих разных форматах. Глава заканчивается обсуждением некоторых специальных типов деревьев, включая упорядоченные деревья (sorted trees), деревья со ссылками[RV7] (threaded trees), боры[RV8] (tries) и квадродеревья[RV9] (quadtrees).
В 7 и 8 главе обсуждаются более сложные темы — сбалансированные деревья и деревья решений.
@Рис. 6.1. Графы
=====117
ОпределенияМожно рекурсивно определить дерево как:
* Пустую структуру или
* Узел, называемый корнем (node) дерева, связанный с нулем или более поддеревьев (subtrees).
На рис. 6.2 показано дерево. Корневой узел A связан с тремя поддеревьями, начинающимися в узлах B, C и D. Эти узлы связаны с поддеревьями с корнями E, F и G, и эти узлы, в свою очередь связаны с поддеревьями с корнями H, I и J.
Терминология деревьев представляет собой смесь терминов, позаимствованных из ботаники и генеалогии. Из ботаники пришли термины, такие как узел (node), определяемый как точка, в которой может начинаться ветвление, ветвь (branch), определяемая как связь между двумя узлами, и лист (leaf) — узел, из которого не выходят другие ветви.
Из генеалогии пришли термины, которые описывают родство. Если один узел находится непосредственно над другим, верхний узел называется родителем (parent), а нижний дочерним узлом (child). Узлы на пути вверх от узла до корня называются предками (ancestors) узла. Например, на рис. 6.2 узлы E, B и A — это все предки узла I.
Узлы, которые находятся ниже какого‑либо узла дерева, называются потомками (descendants) этого узла. Узлы E, H, I и J на рис. 6.2 — это все потомки узла B.
Иногда узлы, имеющие одного родителя, называются узлами‑братьями или узлами‑сестрами (sibling nodes).
Существует еще несколько терминов, которые не пришли из ботаники или генеалогии. Внутренним узлом (internal node) называется узел, который не является листом. Порядком узла (node degree) называется число его дочерних узлов. Порядок дерева — это наибольший порядок его узлов. Дерево на рис. 6.2 — третьего порядка, потому что узлы с наибольшим порядком, узлы A и E, имеют по 3 дочерних узла.
Глубина (depth) дерева равна числу его предков плюс 1. На рис. 6.2 глубина узла E равна 3. Глубиной (depth) или высотой (height) дерева называется наибольшая глубина его узлов. Глубина дерева на рис. 6.2 равна 4.
Дерево 2 порядка называется двоичным деревом (binary tree). Деревья третьего порядка иногда называются троичными[RV10] (ternary) деревьями. Более того, деревья порядка N иногда называются N‑ичными (N‑ary) деревьями.
@Рис. 6.2. Дерево
======118
Дерево порядка 12, например, называется 12‑ричным (12‑ary) деревом, а не додекадеричным (dodecadary) деревом. Некоторые избегают употребления лишних терминов и просто говорят «деревья 12 порядка».
Рис. 6.3 иллюстрирует некоторые из этих терминов.
Представления деревьевТеперь, когда вы познакомились с терминологией, вы можете представить себе способы реализации деревьев на языке Visual Basic. Один из способов — создать отдельный класс для каждого типа узлов дерева. Для построения дерева, показанного на рис. 6.3, вы можете определить структуры данных для узлов, которые имеют ноль, один, два или три дочерних узла. Этот подход был бы довольно неудобным. Кроме того, что нужно было бы управлять четырьмя различными классами, в классах потребовались бы какие‑то флаги, которые бы указывали тип дочерних узлов. Алгоритмы, которые оперировали бы этими деревьями, должны были бы уметь работать со всем различными типами деревьев.
Полные узлыВ качестве простого решения можно определить один тип узлов, который содержит достаточное число указателей на потомков для представления всех нужных узлов. Я называю это методом полных узлов, так как некоторые узлы могут быть большего размера, чем необходимо на самом деле.
Дерево, изображенное на рис 6.3, имеет 3 порядок. Для построения этого дерева с использованием метода полных узлов (fat nodes), требуется определить единственный класс, который содержит указатели на три дочерних узла. Следующий код демонстрирует, как эти указатели могут быть определены в классе TernaryNode.
Public LeftChild As TernaryNode
Public MiddleChild As TernaryNode
Public RightChild As TernaryNode
@Рис. 6.3. Части троичного (3 порядка) дерева
======119
При помощи этого класса можно построить дерево, используя записи Child узлов, для связи их друг с другом. Следующий фрагмент кода строит два верхних уровня дерева, показанного на рис. 6.3.
Dim A As New TernaryNode
Dim B As New TernaryNode
Dim C As New TernaryNode
Dim D As New TernaryNode
:
Set A.LeftChild = B
Set A.MiddleChild = C
Set A.RightChild = D
[RV11] :
Программа Binary, показанная на рис. 6.4, использует метод полных узлов для работы с двоичным деревом. Когда вы выбираете узел с помощью мыши, программа подсвечивает кнопку Add Left (Добавить слева), если узел не имеет левого потомка и кнопку Add Right (Добавить справа), если узел не имеет правого потомка. Кнопка Remove (Удалить) разблокируется, если выбранный узел не является корневым. Если вы нажмете на кнопку Remove, программа удалит узел и всех его потомков.
Поскольку программа позволяет создать узлы с нулевым числом, одним или двумя дочерними узлами, она использует представление в виде полных узлов. Вы можете легко распространить этот пример на деревья более высоких порядков.
Списки потомковЕсли порядки узлов в дереве сильно различаются, метод полных узлов приводит к напрасному расходованию большого количества памяти. Чтобы построить дерево, показанное на рис. 6.5 с использованием полных узлов, вам понадобится определить в каждом узле по шесть указателей, хотя только в одном узле все шесть из них используются. Это представление дерева потребует 72 указателей на дочерние узлы, из которых в действительности будет использоваться только 11.
@Рис. 6.4. Программа Binary
======120
Некоторые программы добавляют и удаляют узлы, изменяя порядок узлов в процессе выполнения. В этом случае метод полных узлов не будет работать. Такие динамически изменяющиеся деревья можно представить, поместив дочерние узлы в списки. Есть несколько подходов, которые можно использовать для создания списков дочерних узлов. Наиболее очевидный подход заключается в создании в классе узла открытого (public) массива дочерних узлов, как показано в следующем коде. Тогда для оперирования дочерними узлами можно использовать методы работы со списками на основе массивов.
Public Children() As TreeNode
Public NumChildren As Integer
К сожалению, Visual Basic не позволяет определять открытые массивы в классах. Это ограничение можно обойти, определив массив как закрытый (private), и оперируя элементами массива при помощи процедур свойств.
Private m_Chirdren() As TreeNode
Private m_NumChildren As Integer
Property Get Children(Index As Integer) As TreeNode
Set Children = m_Children(Index)
End Property
Property Get NumChildren() As Integer
NumChildren = m_NumChildren()
End Property
Второй подход состоит в том, чтобы сохранять ссылки на дочерние узлы в связных списках. Каждый узел содержит ссылку на первого потомка. Он также содержит ссылку на следующего потомка на том же уровне дерева. Эти связи образуют связный список узлов одного уровня, поэтому я называю этот метод представлением в виде связного списка узлов одного уровня (linked sibling). За информацией о связных списках вы можете обратиться ко 2 главе.
@Рис. 6.5. Дерево с узлами различных порядков
======121
Третий подход заключается в том, чтобы определить в классе узла открытую коллекцию, которая будет содержать дочерние узлы:
Public Children As New Collection
Это решение позволяет использовать все преимущества коллекций. Программа может при этом легко добавлять и удалять элементы из коллекции, присваивать дочерним узлам ключи, и использовать оператор For Each для выполнения циклов со ссылками на дочерние узлы.
Программа NAry, показанная на рис. 6.6, использует коллекцию дочерних узлов для работы с деревьями порядка N в основном таким же образом, как программа Binary работает с двоичными деревьями. В этой программе, тем не менее, можно добавлять к каждому узлу любое количество потомков.
Для того чтобы избежать чрезмерного усложнения пользовательского интерфейса, программа NAry всегда добавляет новые узлы в конец коллекции дочерних узлов родителя. Вы можете модифицировать эту программу, реализовав вставку дочерних узлов в середину коллекции, но пользовательский интерфейс при этом усложнится.
Представление нумерацией связейПредставление нумерацией связей (forward star), впервые упомянутое в 4 главе, позволяет компактно представить деревья, графы и сети при помощи массива. Для представления дерева нумерацией связей, в массиве FirstLink записывается индекс для первых ветвей, выходящих из каждого узла. В другой массив, ToNode, заносятся узлы, к которым ведет ветвь.
Сигнальная метка в конце массива FirstLink указывает на точку сразу после последнего элемента массива ToNode. Это позволяет легко определить, какие ветви выходят из каждого узла. Ветви, выходящие из узла I, находятся под номерами от FirstLink(I) до FirstLink(I+1)-1. Для вывода связей, выходящих из узла I, можно использовать следующий код:
For link = FirstLink(I) To FirstLink(I + 1) - 1
Print Format$(I) & " -> " & Format$(ToNode(link))
Next link
@Рис. 6.6. Программа Nary
=======123
На рис. 6.7 показано дерево и его представление нумерацией связей. Связи, выходящие из 3 узла (обозначенного буквой D) это связи от FirstLink(3) до FirstLink(4)-1. Значение FirstLink(3) равно 9, а FirstLink(4) = 11, поэтому это связи с номерами 9 и 10. Записи ToNode для этих связей равны ToNode(9) = 10 и ToNode(10) = 11, поэтому узлы 10 и 11 будут дочерними для 3 узла. Это узлы, обозначенные буквами K и L. Это означает, что связи, покидающие узел D, ведут к узлам K и L.
Представление дерева нумерацией связей компактно и основано на массиве, поэтому деревья, представленные таким образом, можно легко считывать из файлов и записывать в файл. Операции для работы с массивами, которые используются при таком представлении, также могут быть быстрее, чем операции, нужные для использования узлов, содержащих коллекции дочерних узлов.
По этим причинам большая часть литературы по сетевым алгоритмам использует представление нумерацией связей. Например, многие статьи, касающиеся вычисления кратчайшего пути, предполагают, что данные находятся в подобном формате. Если вам когда‑либо придется изучать эти алгоритмы в журналах, таких как “Management Science” или “Operations Research”, вам необходимо разобраться в этом представлении.
@Рис. 6.7. Дерево и его представление нумерацией связей
=======123
Используя представление нумерацией связей, можно быстро найти связи, выходящие из определенного узла. С другой стороны, очень сложно изменять структуру данных, представленных в таком виде. Чтобы добавить к узлу A на рис. 6.7 еще одного потомка, придется изменить почти все элементы в обоих массивах FirstLink и ToNode. Во‑первых, каждый элемент в массиве ToNode нужно сдвинуть на одну позицию вправо, чтобы освободить место под новый элемент. Затем, нужно вставить новую запись в массив ToNode, которая указывает на новый узел. И, наконец, нужно обойти массив ToNode, обновив каждый элемент, чтобы он указывал на новое положение соответствующей записи ToNode. Поскольку все записи в массиве ToNode сдвинулись на одну позицию вправо, чтобы освободить место для новой связи, потребуется добавить единицу ко всем затронутым записям FirstLink.
На рис. 6.8 показано дерево после добавления нового узла. Записи, которые изменились, закрашены серым цветом.
Удаление узла из начала представления нумерацией связей так же сложно, как и вставка узла. Если удаляемый узел имеет потомков, процесс занимает еще больше времени, поскольку придется удалять и все дочерние узлы.
Относительно простой класс с открытой коллекцией дочерних узлов лучше подходит, если нужно часто модифицировать дерево. Обычно проще понимать и отлаживать процедуры, которые оперируют деревьями в этом представлении. С другой стороны, представление нумерацией связей иногда обеспечивает более высокую производительность для сложных алгоритмов работы с деревьями. Оно также являются стандартной структурой данных, обсуждаемой в литературе, поэтому вам следует ознакомиться с ним, если вы хотите продолжить изучение алгоритмов работы с сетями и деревьями.
@Рис. 6.8. Вставка узла в дерево, представленное нумерацией связей
=======124
Программа Fstar использует представление нумерацией связей для работы с деревом, имеющим узлы разного порядка. Она аналогична программе NAry, за исключением того, что она использует представление на основе массива, а не коллекций.
Если вы посмотрите на код программы Fstar, вы увидите, насколько сложно в ней добавлять и удалять узлы. Следующий код демонстрирует удаление узла из дерева.
Sub FreeNodeAndChildren(ByVal parent As Integer, _
ByVal link As Integer, ByVal node As Integer)
' Recursively remove the node's children.
Do While FirstLink(node) < FirstLink(node + 1)
FreeNodeAndChildren node, FirstLink(node), _
ToNode(FirstLink(node))
Loop
' Удалить связь.
RemoveLink parent, link
' Удалить сам узел.
RemoveNode node
End Sub
Sub RemoveLink(node As Integer, link As Integer)
Dim i As Integer
' Обновить записи массива FirstLink.
For i = node + 1 To NumNodes
FirstLink(i) = FirstLink(i) - 1
Next i
' Сдвинуть массив ToNode чтобы заполнить пустую ячейку.
For i = link + 1 To NumLinks - 1
ToNode(i - 1) = ToNode(i)
Next i
' Удалить лишний элемент из ToNode.
NumLinks = NumLinks - 1
If NumLinks > 0 Then ReDim Preserve ToNode(0 To NumLinks - 1)
End Sub
Sub RemoveNode(node As Integer)
Dim i As Integer
' Сдвинуть элементы массива FirstLink, чтобы заполнить
' пустую ячейку.
For i = node + 1 To NumNodes
FirstLink(i - 1) = FirstLink(i)
Next i
' Сдвинуть элементы массива NodeCaption.
For i = node + 1 To NumNodes - 1
NodeCaption(i - 1) = NodeCaption(i)
Next i
' Обновить записи массива ToNode.
For i = 0 To NumLinks - 1
If ToNode(i) >= node Then ToNode(i) = ToNode(i) - 1
Next i
' Удалить лишнюю запись массива FirstLink.
NumNodes = NumNodes - 1
ReDim Preserve FirstLink(0 To NumNodes)
ReDim Preserve NodeCaption(0 To NumNodes - 1)
Unload FStarForm.NodeLabel(NumNodes)
End Sub
Это намного сложнее, чем соответствующий код в программе NAry:
Public Function DeleteDescendant(target As NAryNode) As Boolean
Dim i As Integer
Dim child As NAryNode
' Является ли узел дочерним узлом.
For i = 1 To Children.Count
If Children.Item(i) Is target Then
Children.Remove i
DeleteDescendant = True
Exit Function
End If
Next i
' Если это не дочерний узел, рекурсивно
' проверить остальных потомков.
For Each child In Children
If child.DeleteDescendant(target) Then
DeleteDescendant = True
Exit Function
End If
Next child
End Function
=======125-126
Полные деревьяПолное дерево (complete tree) содержит максимально возможное число узлов на каждом уровне, кроме нижнего. Все узлы на нижнем уровне сдвигаются влево. Например, каждый уровень троичного дерева содержит в точности три дочерних узла, за исключением листьев, и возможно, одного узла на один уровень выше листьев. На рис. 6.9 показаны полные двоичное и троичное деревья.
Полные деревья обладают рядом важных свойств. Во‑первых, это кратчайшие деревья, которые могут содержать заданное число узлов. Например, двоичное дерево на рис. 6.9 — одно из самых коротких двоичных деревьев с шестью узлами. Существуют другие двоичные деревья с шестью узлами, но ни одно из них не имеет высоту меньше 3.
Во‑вторых, если полное дерево порядка D состоит из N узлов, оно будет иметь высоту порядка O(logD(N)) и O(N) листьев. Эти факты имеют большое значение, поскольку многие алгоритмы обходят деревья сверху вниз или в противоположном направлении. Время выполнения алгоритма, выполняющего одно из этих действий, будет порядка O(N).
Чрезвычайно полезное свойство полных деревьев заключается в том, что они могут быть очень компактно записаны в массивах. Если пронумеровать узлы в «естественном» порядке, сверху вниз и слева направо, то можно поместить элементы дерева в массив в этом порядке. На рис. 6.10 показано, как можно записать полное дерево в массиве.
Корень дерева находится в нулевой позиции. Дочерние узлы узла I находятся на позициях 2 * I + 1 и 2 * I + 2. Например, на рис. 6.10, потомки узла в позиции 1 (узла B), находятся в позициях 3 и 4 (узлы D и E).
Легко обобщить это представление на полные деревья более высокого порядка D. Корень дерева также будет находиться в позиции 0. Потомки узла I занимают позиции от D * I + 1 до D * I +(I - 1). Например, в троичном дереве, потомки узла в позиции 2, будут занимать позиции 7, 8 и 9. На рис. 6.11 показано полное троичное дерево и его представление в виде массива.
@Рис. 6.9. Полные деревья
=========127
@Рис. 6.10. Запись полного двоичного дерева в массиве
При использовании этого метода записи дерева в массиве легко и просто получить доступ к потомкам узла. При этом не требуется дополнительной памяти для коллекций дочерних узлов или меток в случае представления нумерацией связей. Чтение и запись дерева в файл сводится просто к сохранению или чтению массива. Поэтому это несомненно лучшее представление дерева для программ, которые сохраняют данные в полных деревьях.
Обход дереваПоследовательное обращение ко всем узлам называется обходом (traversing) дерева. Существует несколько последовательностей обхода узлов двоичного дерева. Три простейших из них — прямой (preorder), симметричный (inorder), и обратный (postorder)обход, описываются простыми рекурсивными алгоритмами. Для каждого заданного узла алгоритмы выполняют следующие действия:
Прямой обход:
1. Обращение к узлу.
2. Рекурсивный прямой обход левого поддерева.
3. Рекурсивный прямой обход правого поддерева.
Симметричный обход:
1. Рекурсивный симметричный обход левого поддерева.
2. Обращение к узлу.
3. Рекурсивный симметричный обход левого поддерева.
Обратный обход:
1. Рекурсивный обратный обход левого поддерева.
2. Рекурсивный обратный обход правого поддерева.
3. Обращение к узлу.
@Рис. 6.11. Запись полного троичного дерева в массиве
=======128
Все три порядка обхода являются примерами обхода в глубину (depth‑first traversal). Обход начинается с прохода вглубь дерева до тех пор, пока алгоритм не достигнет листьев. При возврате из рекурсивного вызова подпрограммы, алгоритм перемещается по дереву в обратном направлении, просматривая пути, которые он пропустил при движении вниз.
Обход в глубину удобно использовать в алгоритмах, которые должны вначале обойти листья. Например, метод ветвей и границ, описанный в 8 главе, как можно быстрее пытается достичь листьев. Он использует результаты, полученные на уровне листьев для уменьшения времени поиска в оставшейся части дерева.
Четвертый метод перебора узлов дерева — это обход в ширину (breadth‑first traversal). Этот метод обращается ко всем узлам на заданном уровне дерева, перед тем, как перейти к более глубоким уровням. Алгоритмы, которые проводят полный поиск по дереву, часто используют обход в ширину. Алгоритм поиска кратчайшего маршрута с установкой меток, описанный в 12 главе, представляет собой обход в ширину, дерева кратчайшего пути в сети.
На рис. 6.12 показано небольшое дерево и порядок, в котором перебираются узлы во время прямого, симметричного и обратного обхода, а также обхода в ширину.
@Рис. 6.12. Обходы дерева
======129
Для деревьев больше, чем 2 порядка, все еще имеет смысл определять прямой, обратный обход, и обход в ширину. Симметричный обход определяется неоднозначно, так как обращение к каждому узлу может происходить после обращения к одному, двум, или трем его потомкам. Например, в троичном дереве, обращение к узлу может происходить после обращения к его первому потомку или после обращения ко второму потомку.
Детали реализации обхода зависят от того, как записано дерево. Для обхода дерева на основе коллекций дочерних узлов, программа должна использовать несколько другой алгоритм, чем для обхода дерева, записанного при помощи нумерации связей.
Особенно просто обходить полные деревья, записанные в массиве. Алгоритм обхода в ширину, который требует дополнительных усилий в других представлениях деревьев, для представлений на основе массива тривиален, так как узлы записаны в таком же порядке.
Следующий код демонстрирует алгоритмы обхода полного двоичного дерева:
Dim NodeLabel() As String ' Запись меток узлов.
Dim NumNodes As Integer
' Инициализация дерева.
:
Private Sub Preorder(node As Integer)
Print NodeLabel (node) ' Узел.
' Первый потомок.
If node * 2 + 1 <= NumNodes Then Preorder node * 2 + 1
' Второй потомок.
If node * 2 + 2 <= NumNodes Then Preorder node * 2 + 2
End Sub
Private Sub Inorder(node As Integer)
' Первый потомок.
If node * 2 + 1 <= NumNodes Then Inorder node * 2 + 1
Print NodeLabel (node) ' Узел.
' Второй потомок.
If node * 2 + 2 <= NumNodes Then Inorder node * 2 + 2
End Sub
Private Sub Postorder(node As Integer)
' Первый потомок.
If node * 2 + 1 <= NumNodes Then Postorder node * 2 + 1
' Второй потомок.
If node * 2 + 2 <= NumNodes Then Postorder node * 2 + 2
Print NodeLabel (node) ' Узел.
End Sub
Private Sub BreadthFirstPrint()
Dim i As Integer
For i = 0 To NumNodes
Print NodeLabel(i)
Next i
End Sub
======130
Программа Trav1 демонстрирует прямой, симметричный и обратный обходы, а также обход в ширину для двоичных деревьев на основе массивов. Введите высоту дерева, и нажмите на кнопку Create Tree (Создать дерево) для создания полного двоичного дерева. Затем нажмите на кнопки Preorder (Прямой обход), Inorder (Симметричный обход), Postorder (Обратный обход) или Breadth-First (Обход в ширину) для того, чтобы увидеть, как происходит обход дерева. На рис. 6.13 показано окно программы, в котором отображается прямой обход дерева 4 порядка.
Прямой и обратный обход для других представлений дерева осуществляется так же просто. Следующий код демонстрирует процедуру прямого обхода для дерева, записанного в формате с нумерацией связей:
Private Sub PreorderPrint(node As Integer)
Dim link As Integer
Print NodeLabel(node)
For link = FirstLink(node) To FirstLink(node + 1) - 1
PreorderPrint ToNode (link)
Next link
End Sub
@Рис. 6.13. Пример прямого обхода дерева в программе Trav1
=======131
Как упоминалось ранее, сложно дать определение симметричного обхода для деревьев больше 2 порядка. Тем не менее, после того, как вы поймете, что имеется в виду под симметричным обходом, реализовать его достаточно просто. Следующий код демонстрирует процедуру симметричного обхода, которая обращается к половине потомков узла (с округлением в большую сторону), затем к самому узлу, а потом — к остальным потомкам.
Private Sub InorderPrint(node As Integer)
Dim mid_link As Integer
Dim link As Integer
' Найти средний дочерний узел.
mid_link - (FirstLink(node + 1) - 1 + FirstLink(node)) \ 2
' Обход первой группы потомков.
For link = FirstLink(node) To mid_link
InorderPrint ToNode(link)
Next link
' Обращение к узлу.
Print NodeLabel(node)
' Обход второй группы потомков.
For link = mid_link + 1 To FirstLink(node + 1) - 1
InorderPrint ToNode(link)
Next link
End Sub
Для полных деревьев, записанных в массиве, узлы уже находятся в порядке обхода в ширину. Поэтому обход в ширину для этих типов деревьев реализуется просто, тогда как для других представлений реализовать его несколько сложнее.
Для обхода деревьев других типов можно использовать очередь для хранения узлов, которые еще не были обойдены. Вначале поместим в очередь корневой узел. После обращения к узлу, он удаляется из начала очереди, а его потомки помещаются в ее конец. Процесс повторяется до тех пор, пока очередь не опустеет. Следующий код демонстрирует процедуру обхода в ширину для дерева, которое использует узлы с коллекциями потомков:
Dim Root As TreeNode
' Инициализация дерева.
:
Private Sub BreadthFirstPrint(}
Dim queue As New Collection ' Очередь на основе коллекций.
Dim node As TreeNode
Dim child As TreeNode
' Начать с корня дерева в очереди.
queue.Add Root
' Многократная обработка первого элемента
' в очереди, пока очередь не опустеет.
Do While queue.Count > 0
node = queue.Item(1)
queue.Remove 1
' Обращение к узлу.
Print NodeLabel(node)
' Поместить в очередь потомков узла.
For Each child In node.Children
queue.Add child
Next child
Loop
End Sub
=====132
Программа Trav2 демонстрирует обход деревьев, использующих коллекции дочерних узлов. Программа является объединением программ Nary, которая оперирует деревьями порядка N, и программы Trav1, которая демонстрирует обходы деревьев.
Выберите узел, и нажмите на кнопку Add Child (Добавить дочерний узел), чтобы добавить к узлу потомка. Нажмите на кнопки Preorder, Inorder, Postorder или Breadth First, чтобы увидеть примеры соответствующих обходов. На рис. 6.14 показана программа Trav2, которая отображает обратный обход.
Упорядоченные деревьяДвоичные деревья часто являются естественным способом представления и обработки данных в компьютерных программах. Поскольку многие компьютерные операции являются двоичными, они естественно преобразуются в операции с двоичными деревьями. Например, можно преобразовать двоичное отношение «меньше» в двоичное дерево. Если использовать внутренние узлы дерева для обозначения того, что «левый потомок меньше правого» вы можете использовать двоичное дерево для записи упорядоченного списка. На рис. 6.15 показано двоичное дерево, содержащее упорядоченный список с числами 1, 2, 4, 6, 7, 9.
@Рис. 6.14. Пример обратного обхода дерева в программе Trav2
======133
@Рис. 6.15. Упорядоченный список: 1, 2, 4, 6, 7, 9.
Добавление элементовАлгоритм вставки нового элемента в дерево такого типа достаточно прост. Начнем с корневого узла. По очереди сравним значения всех узлов со значением нового элемента. Если значение нового элемента меньше или равно значению узла, перейдем вниз по левой ветви дерева. Если новое значение больше, чем значение узла, перейдем вниз по правой ветви. Когда этот процесс дойдет до листа, элемент помещается в эту точку.
Чтобы поместить значение 8 в дерево, показанное на рис. 6.15, мы начинаем с корня, который имеет значение 4. Поскольку 8 больше, чем 4, переходим по правой ветви к узлу 9. Поскольку 8 меньше 9, переходим затем по левой ветви к узлу 7. Поскольку 8 больше 7, снова пытаемся пойти по правой ветви, но у этого узла нет правого потомка. Поэтому новый элемент вставляется в этой точке, и получается дерево, показанное на рис. 6.16.
Следующий код добавляет новое значение ниже узла в упорядоченном дереве. Программа начинает вставку с корня, вызывая процедуру InsertItem Root, new_value.
Private Sub InsertItem(node As SortNode, new_value As Integer)
Dim child As SortNode
If node Is Nothing Then
' Мы дошли до листа.
' Вставить элемент здесь.
Set node = New SortNode
node.Value = new_value
MaxBox = MaxBox + 1
Load NodeLabel(MaxBox)
Set node.Box = NodeLabel(MaxBox)
With NodeLabel(MaxBox)
.Caption = Format$(new_value)
.Visible = True
End With
ElseIf new_value <= node.Value Then
' Перейти по левой ветви.
Set child = node.LeftChild
InsertItem child, new_value
Set node.LeftChild = child
Else
' Перейти по правой ветви.
Set child = node.RightChild
InsertItem child, new_value
Set node.RightChild = child
End If
End Sub
Когда эта процедура достигает конца дерева, происходит нечто совсем неочевидное. В Visual Basic, когда вы передаете параметр подпрограмме, этот параметр передается по ссылке, если вы не используете зарезервированное слово ByVal. Это означает, что подпрограмма работает с той же копией параметра, которую использует вызывающая процедура. Если подпрограмма изменяет значение параметра, значение в вызывающей процедуре также изменяется.
Когда процедура InsertItem рекурсивно вызывает сама себя, она передает указатель на дочерний узел в дереве. Например, в следующих операторах процедура передает указатель на правого потомка узла в качестве параметра узла процедуры InsertItem. Если вызываемая процедура изменяет значение параметра узла, указатель на потомка также автоматически обновляется в вызывающей процедуре. Затем в последней строке кода значение правого потомка устанавливается равным новому значению, так что созданный новый узел добавляется к дереву.
Set child = node.RightChild
Insertltem child, new_value
Set node.RightChild = child
Удаление элементовУдаление элемента из упорядоченного дерева немного сложнее, чем его вставка. После удаления элемента, программе может понадобиться переупорядочить другие узлы, чтобы соотношение «меньше» продолжало выполняться для всего дерева. При этом нужно рассмотреть несколько случаев.
=====134-135
@Рис. 6.17. Удаление узла с единственным потомком
Во‑первых, если у удаляемого узла нет потомков, вы можете просто убрать его из дерева, так как порядок оставшихся узлов при этом не изменится.
Во‑вторых, если у узла всего один дочерний узел, вы можете поместить его на место удаленного узла. Порядок остальных потомков удаленного узла останется неизменным, поскольку они являются также потомками и дочернего узла. На рис. 6.17 показано дерево, из которого удаляется узел 4, который имеет всего один дочерний узел.
Если удаляемый узел имеет два дочерних, то не обязательно один из них займет место удаленного узла. Если потомки узла также имеют по два дочерних узла, то все потомки не смогут занять место удаленного узла. Удаленный узел имеет одного лишнего потомка, и дочерний узел, который вы хотели бы поместить на его место, также имеет двух потомков, так что на узел пришлось бы три потомка.
Чтобы решить эту проблему, удаленный узел заменяется самым правым узлом из левой ветви. Другими словами, нужно сдвинуться на один шаг вниз по левой ветви, выходившей из удаленного узла. Затем нужно двигаться по правым ветвям вниз до тех пор, пока не найдется узел, который не имеет правой ветви. Это самый правый узел на ветви слева от удаляемого узла. В дереве, показанном слева на рис. 6.18, узел 3 является самым правым узлом в левой от узла 4 ветви. Можно заменить узел 4 листом 3, сохранив при этом порядок дерева.
@Рис. 6.18. Удаление узла, который имеет два дочерних
=======136
@Рис. 6.19. Удаление узла, если заменяющий его узел имеет потомка
Остается последний вариант — когда заменяющий узел имеет левого потомка. В этом случае, вы можете переместить этого потомка на место, освободившееся в результате перемещения замещающего узла, и дерево снова будет расположено в нужном порядке. Уже известно, что самый правый узел не имеет правого потомка, иначе он не был бы таковым. Это означает, что не нужно беспокоиться, не имеет ли замещающий узел двух потомков.
Эта сложная ситуация показана на рис. 6.19. В этом примере удаляется узел 8. Самый правый элемент в его левой ветви — это узел 7, который имеет потомка — узел 5. Чтобы сохранить порядок дерева после удаления узла 8, заменим узел 8 узлом 7, а узел 7 — узлом 5. Заметьте, что узел 7 получает новых потомков, а узел 5 сохраняет своих.
Следующий код удаляет узел из упорядоченного двоичного дерева:
Private Sub DeleteItem(node As SortNode, target_value As Integer)
Dim target As SortNode
Dim child As SortNode
' Если узел не найден, вывести сообщение.
If node Is Nothing Then
Beep
MsgBox "Item " & Format$(target_value) & _
" не найден в дереве."
Exit Sub
End If
If target_value < node.Value Then
' Продолжить для левого поддерева.
Set child = node.LeftChild
DeleteItem child, target_value
Set node.LeftChild = child
ElseIf target_value > node.Value Then
' Продолжить для правого поддерева.
Set child = node.RightChild
DeleteItem child, target_value
Set node.RightChild = child
Else
' Искомый узел найден.
Set target = node
If target.LeftChild Is Nothing Then
' Заменить искомый узел его правым потомком.
Set node = node.RightChild
ElseIf target.RightChild Is Nothing Then
' Заменить искомый узел его левым потомком.
Set node = node.LeftChild
Else
' Вызов подпрограмы ReplaceRightmost для замены
' искомого узла самым правым узлом
' в его левой ветви.
Set child = node.LeftChild
ReplaceRightmost node, child
Set node.LeftChild = child
End If
End If
End Sub
Private Sub ReplaceRightmost(target As SortNode, repl As SortNode)
Dim old_repl As SortNode
Dim child As SortNode
If Not (repl.RightChild Is Nothing) Then
' Продолжить движение вправо и вниз.
Set child = repl.RightChild
ReplaceRightmost target, child
Set repl.RightChild = child
Else
' Достигли дна.
' Запомнить заменяющий узел repl.
Set old_repl = repl
' Заменить узел repl его левым потомком.
Set repl = repl.LeftChild
' Заменить искомый узел target with repl.
Set old_repl.LeftChild = target.LeftChild
Set old_repl.RightChild = target.RightChild
Set target = old_repl
End If
End Sub
======137-138
Алгоритм использует в двух местах прием передачи параметров в рекурсивные подпрограммы по ссылке. Во‑первых, подпрограмма DeleteItem использует этот прием для того, чтобы родитель искомого узла указывал на заменяющий узел. Следующие операторы показывают, как вызывается подпрограмма DeleteItem:
Set child = node.LeftChild
DeleteItem child, target_value
Set node.LeftChild = child
Когда процедура обнаруживает искомый узел (узел 8 на рис. 6.19), она получает в качестве параметра узла указатель родителя на искомый узел. Устанавливая параметр на замещающий узел (узел 7), подпрограмма DeleteItem задает дочерний узел для родителя так, чтобы он указывал на новый узел.
Следующие операторы показывают, как процедура ReplaceRightMost рекурсивно вызывает себя:
Set child = repl.RightChild
ReplaceRightmost target, child
Set repl.RightChild = child
Когда процедура находит самый правый узел в левой от удаляемого узла ветви (узел 7), в параметре repl находится указатель родителя на самый правый узел. Когда процедура устанавливает значение repl равным repl.LeftChild, она автоматически соединяет родителя самого правого узла с левым дочерним узлом самого правого узла (узлом 5).
Программа TreeSort использует эти процедуры для работы с упорядоченными двоичными деревьями. Введите целое число, и нажмите на кнопку Add, чтобы добавить элемент к дереву. Введите целое число, и нажмите на кнопку Remove, чтобы удалить этот элемент из дерева. После удаления узла, дерево автоматически переупорядочивается для сохранения порядка «меньше».
Обход упорядоченных деревьевПолезное свойство упорядоченных деревьев состоит в том, что их порядок совпадает с порядком симметричного обхода. Например, при симметричном обходе дерева, показанного на рис. 6.20, обращение к узлам происходит в порядке 2-4-5-6-7-8-9.
@Рис. 6.20. Симметричный обход упорядоченного дерева: 2, 4, 5, 6, 7, 8, 9
=========139
Это свойство симметричного обхода упорядоченных деревьев приводит к простому алгоритму сортировки:
Похожие работы
... разработки программ, но и разработку пакетов прикладных программ. Эти разработки должны обеспечивать высокое качество и вестись примерно так же, как и выпуск промышленной продукции. Достижения компьютерной техники 1. Универсальные настольные ПК Что такое настольный компьютер, объяснять никому не надо — это любимое молодежью устройство, чтобы красиво набирать тексты рефератов, а ...
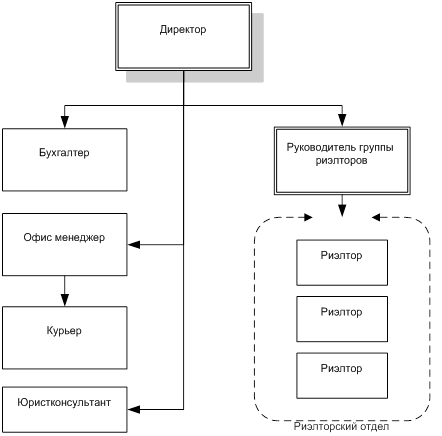
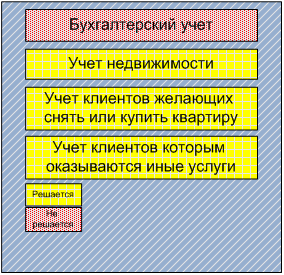
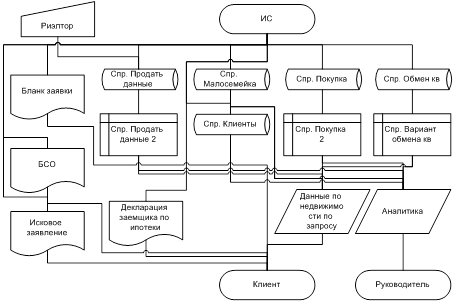
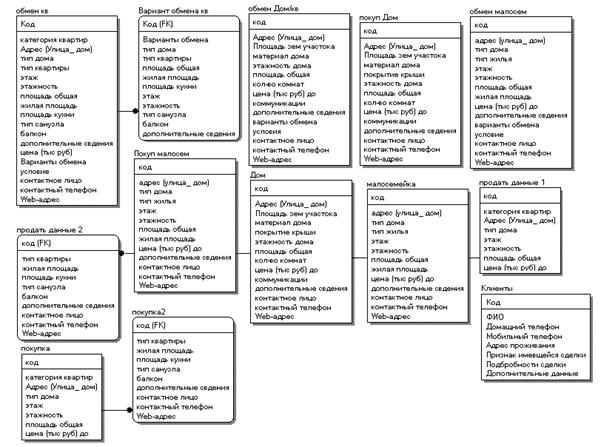
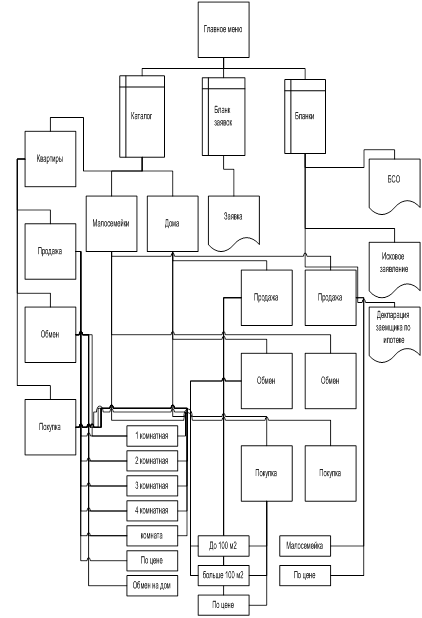
... и дальнейшего использования «Автоматизированной системы агентства недвижимости» на предприятии. 1.4 Постановка цели и подзадач автоматизации. Критерии достижения цели 1.4.1 Экономическая сущность задачи Экономической сущностью задачи автоматизации риэлтерской деятельности агентства недвижимости «Елена» является повышение результативности труда посредством автоматизации ...
... по соответствующему полю). В окне Конструктора таблиц созданные связи отображаются визуально, их легко изменить, установить новые, удалить (клавиша Del). 1 Многозвенные информационные системы. Модель распределённого приложения БД называется многозвенной и её наиболее простой вариант – трёхзвенное распределённое приложение. Тремя частями такого приложения являются: ...
... доступа с записью равной байту. Такие файлы называются двоичными. Файлы прямого доступа незаменимы при написании программ, которые должны работать с большими объемами информации, хранящимися на внешних устройствах. В основе обработке СУБД лежат файлы прямого доступа. Кратко изложим основные положения работы с файлами прямого доступа. 1). Каждая запись в файле прямого доступа имеет свой номер ...
0 комментариев