Навигация
Многопроцессорный вычислительный комплекс на основе коммутационной матрицы с симметричной обработкой заданий всеми процессорами
75096
знаков
0
таблиц
11
изображений
Московский государственный институт радиотехники, электроники и автоматики (Технический Университет)
Проект по курсу
“Вычислительные комплексы, системы и сети ЭВМ”Многопроцессорный вычислительный комплекс на основе коммутационной матрицы с симметричной обработкой заданий всеми процессорами
Группа: АВ-33-93
Студент: Липин В.В.
Москва1998
1. Общая часть 1.1 Содержание
1. Общая часть
1.1. Содержание
1.2. Задание
1.3. Введение
2. Аппаратная организация МПВК
2.1. Структурная схема МПВК
2.2. Функциональная схема элемента коммутационной матрицы
2.3. Организация оперативной памяти
2.3.1. Память с расслоением
2.3.2. Применение кода Хэмминга в модулях памяти
2.4. Организация резервирования и восстановления при отказе любого компонента МПВК
3. Организация функционирования ОС на МПВК
3.1. Симметричная многопроцессорная обработка (SMP)
3.2. Нити
3.2.1. Подходы к организации нитей и управлению ими в разных вариантах ОС UNIX
3.3. Семафоры
3.3.1. Определение семафоров
3.3.2. Реализация семафоров
3.4. Тупиковые ситуации
3.5. Предотвращение тупиковых ситуаций
3.5.1. Линейное упорядочение ресурсов 3.5.2. Иерархическое упорядочение ресурсов 3.5.3. Алгоритм банкира3.6. Защита информации
4. Литература
1.2 Задание (вариант №16)
Разработать многопроцессорный вычислительный комплекс по следующим исходным данным:
· использовать матрицу с перекрестной коммутацией;
· количество процессоров – 8;
· количество блоков ОЗУ – 4;
· количество каналов ввода-вывода – 4;
Требуется разработать структурную схему коммутационной матрицы и функциональную схему элемента коммутационной матрицы.
Описать функционирование ОС для организации многопроцессорной обработки.
Описать организацию резервирования и восстановления вычислительного процесса при отказе любого компонента многопроцессорного вычислительного комплекса.
1.3 Введение
Разработка многопроцессорных (МПВК) и многомашинных (ММВК) вычислительных комплексов, как правило, имеет свой целью повышение либо уровня надежности, либо уровня производительности комплекса до значений недоступных или труднореализуемых (реализуемых с большими экономическими затратами) в традиционных ЭВМ.
На большинстве классов решаемых задач для достижения высокой производительности наиболее эффективны МПВК. Это связано с большой интенсивностью информационных обменов между подзадачами, которая приводит к слишком высоким накладным расходам в ММВК. ММВК, в принципе, позволяют достичь много большей производительности благодаря лучшей масштабируемости, однако это преимущество проявляется только при соответствия решаемых задач условию максимального удлинения независимых ветвей программы, что не всегда возможно.
Указанный в задании МПВК с матрицей перекрестной коммутации позволяет достичь наибольшей производительности, что связано с минимизацией вероятности конфликтов при доступе к компонентам комплекса. При построении МПВК на основе доступа с использованием одной или нескольких общих шин конфликты доступа намного более вероятны, что приводит к заметному снижению производительности по сравнению с МПВК на основе матрицы перекрестной коммутации.
Исходя из этих соображений было решено проектировать МПВК по критерию максимальной производительности, меньше уделяя внимания высокой отказоустойчивости комплекса. Это решение также обосновывается и тем, что современные микроэлектронные изделия обладают вполне достаточной надежностью для подавляющего большинства коммерческих применений, что делает экономически необоснованным существенное усложнение комплекса с целью достижения высокой отказоустойчивости.
2. Аппаратная организация МПВК
2.1 Структурная схема МПВК
В МПВК с перекрестной коммутацией все связи осуществляются с помощью специального устройства – коммутационной матрицы. Коммутационная матрица позволяет связывать друг с другом любую пару устройств, причем таких пар может быть сколько угодно – связи не зависят друг от друга. Структурная схема МПВК приведена на рисунке:
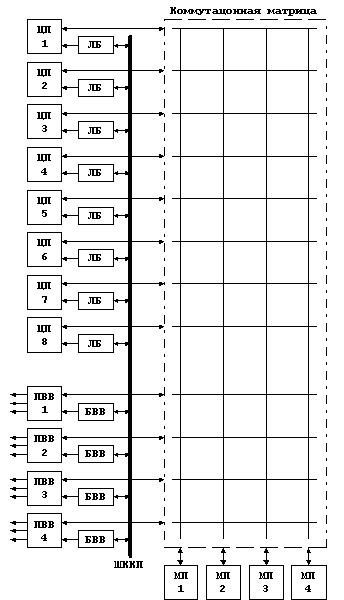
Коммутационная матрица выполняет передачу данных между процессорами и памятью, а также между процессорами ввода-вывода и памятью. Коммутируются только внутренние шины МПВК, основное назначение которых – высокоскоростная передача данных, для этих шин нет смысла добиваться высокой протяженности проводников или стандартизации с целью упрощения подключения дополнительных устройств. Высокоскоростной обмен с периферийными устройствами осуществляется посредством процессоров ввода-вывода, которые являются контроллерами периферийных высокоскоростных шин, к которым, в свою очередь и подключаются контроллеры соответствующих устройств. На роль таких периферийных шин подходят, например, VME (применяется в МПВК фирмы Digital Equipment Company), SBus (применяется в МПВК фирмы Sun Microsystems) или PCI (применяется в МПВК, построенных на процессорах фирмы Intel семейства x86).
В SMP совместимой системе прерывания управляются контроллерами APIC (Advanced Programmable Interrupt Controller), БИС которых серийно выпускаются многими производителями микроэлектронных изделий (например DEC, Sun, IBM, Texas Instruments). Данные контроллеры обладают распределенной архитектурой, в которой функции управления прерываниями распределены между двумя функциональными блоками: локальным (ЛБ) и ввода-вывода (БВВ). Эти блоки обмениваются информацией через шину, называемую шиной коммуникаций контроллера прерываний (ШККП). Устройство ввода-вывода определяет появление прерывания, адресует его локальному блоку и посылает по шине ШККП. Блоки APIC совместно отвечают за доставку прерывания от источника прерываний до получателей по всей системе. Использование такой организации дополнительно увеличивает расширяемость за счет разгрузки разделения между процессорами нагрузки по обработке прерываний. Благодаря распределенной архитектуре, локальные блоки или блоки ввода-вывода могут быть реализованы в отдельной микросхеме или интегрированы с другими компонентами системы.
В МПВК подобной структуры нет конфликтов из-за связей, остаются только конфликты из-за ресурсов. Возможность одновременной связи нескольких пар устройств позволяет добиваться очень высокой производительности комплекса. Важно отметить и такое обстоятельство, как возможность установления связи между устройствами на любое, даже длительное время, так как это совершенно не мешает работе других устройств, зато позволяет передавать любые массивы информации с высокой скоростью, что также способствует повышению производительности комплекса.
Кроме того, к достоинствам структуры с перекрестной коммутацией можно отнести простоту и унифицированность интерфейсов всех устройств, а также возможность разрешения всех конфликтов в коммутационной матрице. Важно отметить и то, что нарушение какой-то связи приводит не к выходу из строя всего устройств, т.е. надежность таких комплексов достаточно высока. Однако и организация МПВК с перекрестной коммутацией не свободна от недостатков.
Прежде всего - сложность наращивания ВК. Если в коммутационной матрице заранее не предусмотреть большого числа входов, то введение дополнительных устройств в комплекс потребует установки новой коммутационной матрицы. Существенным недостатком является и то, что коммутационная матрица при большом числе устройств в комплексе становится сложной, громоздкой и достаточно дорогостоящей. Надо учесть то обстоятельство, что коммутационные матрицы строятся обычно на схемах, быстродействие которых существенно выше быстродействия схем и элементов основных устройств – только при этом условии реализуются все преимущества коммутационной матрицы. Это обстоятельство в значительной степени усложняет и удорожает комплексы.
2.2 Функциональная схема элемента коммутационной матрицыКоммутационная матрица (см. раздел “Структурная схема МПВК”) представляет собой прямоугольный двумерный массив из коммутационных элементов, установленных в местах пересечения шин процессоров и памяти (по структурной схеме МПВК). Функции каждого из этих элементов просты – при наличии управляющего сигнала должна быть обеспечена двусторонняя связь между шинами со стороны процессора и шинами со стороны памяти. При отсутствии управляющего сигнала связь должна отсутствовать, сигналы на шинах должны распространяться далее.
Не представляет существенных проблем синтез такого блока на стандартных логических элементах, однако каждый такой блок содержит два (как минимум) последовательно соединенных логических элемента, что вносит достаточно ощутимую задержку. Такое решение входит в противоречие с требованием повышенного быстродействия элементов коммутационной матрицы и приводит к необходимости повышения скорости работы за счет применения логики высокого быстродействия, что не всегда возможно или желательно.
Выходом представляется применение специализированных интегральных микросхем, выпускаемых некоторыми производителями микроэлектроники. У Texas Instruments это ИМС SN74CBT3384 (разрядность 10 бит), SN74CBT16244 (разрядность 16 бит), SN74CBT16210 (разрядность 20 бит), у Cypress Semiconductor - CYBUS3384 (два коммутатора в одном корпусе с разрядностью 5 бит каждый), у Sun Microelectronics - STP2230SOP. Данные ИМС имеют достаточное быстродействие (задержка распространения 5.2 – 10.0 нс, что соответствует максимальной тактовой частоте 190 – 100 МГц) и достаточно невысокую цену (несколько долларов за единицу в партиях от 1000 штук).
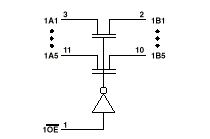 |
Все ИМС этого семейства имеют практически одинаковую функциональную схему:
Видно, что шина данных коммутируется полевым транзистором с изолированным затвором, на который подается управляющее напряжение со входа управления. Элемент полностью симметричен по входу и выходу данных, что делает его применение весьма удобным.
2.3 Организация оперативной памятиПамять МПВК должна удовлетворять требованиям высокого быстродействия и высокой надежности. Несмотря на достаточно высокие характеристики по этим показателям, обеспечиваемые современной элементной базой, с помощью относительно несложных и недорогих методов можно достичь существенно более высоких показателей быстродействия и надежности.
С целью повышения быстродействия имеет смысл применить расслоение памяти по адресам на 4 модуля (разбиение на 4 модуля оговорено в задании, так что целесообразно применить данное разбиение для улучшения быстродействия МПВК). Более подробно расслоение по адресам будет рассмотрено ниже.
Для повышения надежности модулей памяти было решено применить корректирующие коды. Наиболее распространен код Хэмминга позволяющий исправлять одиночные и обнаруживать двойные ошибки. Более подробно его применение рассматривается ниже.
2.3.1 Память с расслоениемНаличие в системе множества микросхем памяти позволяет использовать потенциальный параллелизм, заложенный в такой организации. Для этого микросхемы памяти часто объединяются в банки или модули, содержащие фиксированное число слов, причем только к одному из этих слов банка возможно обращение в каждый момент времени. Как уже отмечалось, в реальных системах имеющаяся скорость доступа к таким банкам памяти редко оказывается достаточной. Следовательно, чтобы получить большую скорость доступа, нужно осуществлять одновременный доступ ко многим банкам памяти. Одна из общих методик, используемых для этого, называется расслоением памяти. При расслоении банки памяти обычно упорядочиваются так, чтобы N последовательных адресов памяти i, i+1, i+2, . . . , i+N-1 приходились на N различных банков. В i-том банке памяти находятся только слова, адреса которых имеют вид k*N + i (где 0 < k < M-1, а M число слов в одном банке). Можно достичь в N раз большей скорости доступа к памяти в целом, чем у отдельного ее банка, если обеспечить при каждом доступе обращение к данным в каждом из банков. Имеются разные способы реализации таких расслоенных структур. Большинство из них напоминают конвейеры, обеспечивающие рассылку адресов в различные банки и мультиплексирующие поступающие из банков данные. Таким образом, степень или коэффициент расслоения определяют распределение адресов по банкам памяти. Такие системы оптимизируют обращения по последовательным адресам памяти, что является характерным при подкачке информации в кэш-память при чтении, а также при записи, в случае использования кэш-памятью механизмов обратного копирования. Однако, если требуется доступ к непоследовательно расположенным словам памяти, производительность расслоенной памяти может значительно снижаться.
Обобщением идеи расслоения памяти является возможность реализации нескольких независимых обращений, когда несколько контроллеров памяти позволяют банкам памяти (или группам расслоенных банков памяти) работать независимо.
Если система памяти разработана для поддержки множества независимых запросов (как это имеет место при работе с кэш-памятью, при реализации многопроцессорной и векторной обработки), эффективность системы будет в значительной степени зависеть от частоты поступления независимых запросов к разным банкам. Обращения по последовательным адресам, или, в более общем случае, обращения по адресам, отличающимся на нечетное число, хорошо обрабатываются традиционными схемами расслоенной памяти. Проблемы возникают, если разница в адресах последовательных обращений четная. Одно из решений, используемое в больших компьютерах, заключается в том, чтобы статистически уменьшить вероятность подобных обращений путем значительного увеличения количества банков памяти. Например, в суперкомпьютере NEC SX/3 используются 128 банков памяти.
Подобные проблемы могут быть решены как программными, так и аппаратными средствами.
2.3.2 Применение кода Хэмминга в модулях памятиС целью повышения общей надежности модулей оперативной памяти было решено применить хранение данных в коде Хэмминга, который за счет избыточности позволяет корректировать одиночные ошибки и обнаруживать ошибки большей кратности. Код Хэмминга получил широкое распространение благодаря простоте кодеров и декодеров, а также минимальной избыточности.
Так как большинство современных высокопроизводительных микропроцессоров имеют разрядность 64 бита, необходимо обеспечить разрядность памяти не менее 64 бит. Этой разрядности соответствует код Хэмминга (72, 64), что означает наличие 64 информационных разрядов и 8 контрольных. Можно рассчитать эффект от применения корректирующего кодирования:
Пусть вероятность отказа одиночного модуля памяти разрядностью 1 бит за некоторое время P1=10-5, тогда вероятность отказа одного из необходимых 64 модулей памяти за то же время Pобщ=64*P1=6.4*10-4. В случае применения кода Хэмминга для потери информации необходимы две ошибки в 72-х разрядах: Pобщ=(72*P1)*(71*P1)= 5.112*10-7. Таким образом надежность возрастает более чем на три порядка при увеличении стоимости на 12.5%. Разумеется эти рассуждения верны лишь в случае пренебрежимо малой вероятности отказов и стоимости кодера и декодера по сравнению с модулями памяти, однако в случае реальных объемов памяти это действительно так.
Похожие работы
... на лазерные компакт-диски. Система моделирования Орлан ориентирована на достаточно широкий круг пользователей. В первую очередь, естественно, это администраторы вычислительных сетей предприятий, стоящие перед задачей проектирования или исследования сети. Обязательное условие, накладываемое системой – проектируемая сеть должны основываться на стандарте Ethernet. Но, так как абсолютное ...
ки гипертекстов будут расширены и на нетекстовые виды информации. ПАКЕТЫ ПРОГРАММ ДЛЯ РАЗРАБОТКИ ЭКОНОМИЧЕСКИХ ДОКУМЕНТОВ 1. Виды АСУ. АСУ отличаются от автоматических СУ тем, что в качестве объекта управления используется используются не машины, а люди. АСУ начали развиваться 30 лет назад. Математическая база этого управления создавалась в течение 15-20 лет. АСУ: - со сложным ...
... коммуникационного центра. 51 1. Реферат. В целях комплексной автоматизации документооборота, а также повышения качества диагностики и лечения онкологических больных в Мелитопольском межрайонном онкологическом диспансере, разработан проект информационно-диагностической системы, предназначенной для оперативного ввода, анализа и хранения графической, текстовой лечебно-диагностической информации и ...
... машины фирмы IBM. 1969г. CDC выпускает компьютер CDC-7600 с восемью независимыми конвейерными функциональными устройствами - сочетание параллельной и конвейерной обработки. Матричные суперкомпьютеры В 1967 г. группа Слотника, объединенная в Центр передовых вычислительных технологий (Center of Advanced Computation) при Иллинойском университете, приступила к практической реализации проекта ...
0 комментариев