Перейти
на шаг 1
Умножить
каждую компоненту
полученного
произведения
на производную
сжимающей функции соответствующего
нейрона в скрытом
слое
Дать случайное
изменение весу и пересчитать
выход сети и изменение целевой функции в соответствии
со сделанным изменением
веса
Постепенно уменьшать искусственную температуру
и повторять
шаг 1, пока
не будет достигнуто
равновесие
Вторая
тройная сумма равна нулю в
том и только
в том случае,
если каждый столбец (порядковый номер посещения)
содержит не
более одной
единицы
В
противном
случае
Навигация
В противном случае
Нейрокомпьютерные системы
243425
знаков
1
таблица
0
изображений
0 в противном случае,
где Т представляет собой порог. Принято, что латеральное торможение существует, но игнорируется здесь для сохранения простоты выражений. Оно обеспечивает тот факт, что только нейрон с максимальным значением NET будет иметь выход, равный единице; все остальные нейроны будут иметь нулевой выход. Можно рассмотреть системы, в которых в распознающем слое возбуждаются несколько нейронов в каждый момент времени, однако это выходит за рамки данной работы.
Сравнение. На этой фазе сигнал обратной связи от слоя распознавания устанавливает G1 в нуль; правило двух третей позволяет возбуждаться только тем нейронам, которые имеют равные единице соответствующие компоненты векторов Р и X. Блок сброса сравнивает вектор С и входной вектор X, вырабатывая сигнал сброса, когда их сходство S ниже порога сходства. Вычисление этого сходства упрощается тем обстоятельством, что оба вектора являются двоичными (все элементы либо 0, либо 1). Следующая процедура проводит требуемое вычисление сходства:
1. Вычислить D - количество единиц в векторе X.
2. Вычислить N - количество единиц в векторе С.
Затем вычислить сходство S следующим образом:
S= N/D (8.5)
Например, примем, что
Х=1 0 1 1 1 0 D=5
С=0 0 1 1 1 0 1 N=4
S = N/D = 0.8
S может изменяться от 1 (наилучшее соответствие) до О (наихудшее соответствие). Заметим, что правило двух третей делает С логическим произведением входного вектора Х и вектора Р. Однако Р равен Тj, весовому вектору выигравшего соревнование нейрона. Таким образом, D может быть определено как количество единиц в логическом произведении векторов Тj и X.
Поиск. Если сходство S выигравшего нейрона превышает параметр сходства, поиск не требуется. Однако если сеть предварительно была обучена, появление на входе вектора, не идентичного ни одному из предъявленных ранее, может возбудить в слое распознавания нейрон со сходством ниже требуемого уровня. В соответствии с алгоритмом обучения возможно, что другой нейрон в слое распознавания будет обеспечивать более хорошее соответствие, превышая требуемый уровень сходства, несмотря на то, что свертка между его весовым вектором и входным вектором может иметь меньшее значение. Пример такой ситуации показан ниже. Если сходство ниже требуемого уровня, запомненные образы могут быть просмотрены с целью поиска, наиболее соответствующего входному вектору образа. Если такой образ отсутствует, вводится новый несвязанный нейрон, который в дальнейшем будет обучен. Для инициализации поиска сигнал сброса тормозит возбужденный нейрон в слое распознавания на время проведения поиска, сигнал 01 устанавливается в единицу и другой нейрон в слое распознавания выигрывает соревнование. Его запомненный образ затем проверяется на сходство, и процесс повторяется до тех пор, пока конкуренцию не выиграет нейрон из слоя распознавания со сходством, большим требуемого уровня (успешный поиск), либо пока все связанные нейроны не будут проверены и заторможены (неудачный поиск). Неудачный поиск будет автоматически завершаться на несвязанном нейроне, так как его веса все равны единице, своему начальному значению. Поэтому правило двух третей приведет к идентичности вектора С входному век тору X, сходство S примет значение единицы и критерий сходства будет удовлетворен.
Обучение. Обучение представляет собой процесс, в котором набор входных векторов подается последовательно на вход сети и веса сети изменяются при этом таким образом, чтобы сходные векторы активизировали соответствующие нейроны. Заметим, что это - неуправляемое обучение, нет учителя и нет целевого вектора, определяющего требуемый ответ. В работе [2] различают два вида обучения: медленное и быстрое. При медленном обучении входной вектор предъявляется настолько кратковременно, что веса сети не имеют достаточного времени для достижения своих асимптотических значений в результате одного предъявления. В этом случае значения весов будут определяться скорее статистическими характеристиками входных векторов, чем характеристиками какого-то одного входного вектора. Динамика сети в процессе медленного обучения описывается дифференциальными уравнениями. Быстрое обучение является специальным случаем медленного обучения, когда входной вектор прикладывается на достаточно длительный промежуток времени, чтобы позволить весам приблизиться к их окончательным значениям. В этом случае процесс обучения описывается только алгебраическими выражениями. Кроме того, компоненты весовых векторов Тj принимают двоичные значения, в отличие от непрерывного диапазона значений, требуемого в случае быстрого обучения. В данной работе рассматривается только быстрое обучение, интересующиеся читатели могут найти превосходное описание более общего случая медленного обучения в работе [2]. Рассмотренный далее обучающий алгоритм используется как в случае успешного, так и в случае неуспешного поиска. Пусть вектор весов Вj (связанный с возбужденным нейроном j распознающего слоя) равен нормализованной величине вектора С. В [2] эти веса вычисляются следующим образом:
(8.6)
где сi - i-я компонента выходного вектора слоя сравнения; j - номер выигравшего нейрона в слое распознавания; Ьij - вес связи, соединяющей нейрон i в слое сравнения с нейроном j в слое распознавания; L - константа > 1 (обычно 2).
Компоненты вектора весов Т., связанного с новым запомненным вектором, изменяются таким образом, что они становятся равны соответствующим двоичным величинам вектора С:
tij=ci для всех i (8.7)
где tij является весом связи между выигравшим нейроном j в слое распознавания и нейроном i в слое сравнения.
ПРИМЕР ОБУЧЕНИЯ СЕТИ APT
В общих чертах сеть обучается посредством изменения весов таким образом, что предъявление сети входного вектора заставляет сеть активизировать нейроны в слое распознавания, связанные с сходным запомненным вектором. Кроме этого, обучение проводится в форме, не разрушающей запомненные ранее образы, предотвращая тем самым временную нестабильность. Эта задача управляется на уровне выбора критерия сходства. Новый входной образ (который сеть не видела раньше) не будет соответствовать запомненным образам с точки зрения параметра сходства, тем самым формируя новый запоминаемый образ. Входной образ, в достаточной степени соответствующий одному из запомненных образов, не будет формировать нового экземпляра, он просто будет модифицировать тот, на который он похож. Таким образом при соответствующем выборе критерия сходства предотвращается запоминание ранее изученных образов и временная нестабильность.
На рис. 8.6 показан типичный сеанс обучения сети APT. Буквы показаны состоящими из маленьких квадратов, каждая буква размерностью 8х8. Каждый квадрат в левой части представляет компоненту вектора Х с единичным значением, не показанные квадраты являются компонентами с нулевыми значениями. Буквы справа представляют запомненные образы, каждый является набором величин компонент вектора Тj . Вначале на вход заново проинициированной системы подается буква С. Так как отсутствуют запомненные образы, фаза поиска заканчивается неуспешно; новый нейрон выделяется в слое распознавания, и веса Тj устанавливаются равными соответствующим компонентам входного вектора, при этом веса Вj представляют масштабированную версию входного вектора.
Далее предъявляется буква В. Она также вызывает неуспешное окончание фазы поиска и распределение нового нейрона. Аналогичный процесс повторяется для буквы Е. Затем слабо искаженная версия буквы Е подается на вход сети. Она достаточно точно соответствует запомненной букве Е, чтобы выдержать проверку на сходство, поэтому используется для обучения сети. Отсутствующий пиксель в нижней ножке буквы Е устанавливает в 0 соответствующую компоненту вектора С, заставляя обучающий алгоритм установить этот вес запомненного образа в нуль, тем самым воспроизводя искажения в запомненном образе. Дополнительный изолированный квадрат не изменяет запомненного образа, так как не соответствует единице в запомненном образе. Четвертым символом является буква Е с двумя различными искажениями. Она не соответствует ранее запомненному образу (S меньше чем р), поэтому для ее запоминания выделяется новый нейрон. Этот пример иллюстрирует важность выбора корректного значения критерия сходства. Если значение критерия слишком велико, большинство образов не будут подтверждать сходство с ранее запомненными и сеть будет выделять новый нейрон для каждого из них. Это приводит к плохому обобщению в сети, в результате даже незначительные изменения одного образа будут создавать отдельные новые категории. Количество категорий увеличивается, все доступные нейроны распределяются, и способность системы к восприятию новых данных теряется. Наоборот, если критерий сходства слишком мал, сильно различающиеся образы будут группироваться вместе, искажая запомненный образ до тех пор, пока в результате не получится очень малое сходство с одним из них. К сожалению, отсутствует теоретическое обоснование выбора критерия сходства, в каждом конкретном случае необходимо решить, какая степень сходства должна быть принята для отнесения образов к одной категории. Границы между категориями часто неясны, и решение задачи для большого набора входных векторов может быть чрезмерно трудным. В работе [2] предложена процедура с использованием обратной связи для настройки коэффициента сходства, вносящая, однако, некоторые искажения в результате классификации как «наказание» за внешнее вмешательство с целью увеличения коэффициента сходства. Такие системы требуют правил определения, является ли производимая ими классификация корректной.
ХАРАКТЕРИСТИКИ APT
Системы APT имеют ряд важных характеристик, не являющихся очевидными. Формулы и алгоритмы могут казаться произвольными, в то время как в действительности они были тщательно отобраны с целью удовлетворения требований теорем относительно производительности систем APT. В данном разделе описываются некоторые алгоритмы APT, раскрывающие отдельные вопросы инициализации и обучения.
Инициализация весовых векторов Т
Из ранее рассмотренного примера обучения сети можно было видеть, что правило двух третей приводит к вычислению вектора С как функции И между входным вектором Х и выигравшим соревнование запомненным вектором Тj. Следовательно, любая компонента вектора С будет равна единице в том случае, если соответствующие компоненты обоих векторов равны единице. После обучения эти компоненты вектора Тj остаются единичными; все остальные устанавливаются в нуль.
Это объясняет, почему веса tij. должны инициализироваться единичными значениями. Если бы они были проинициализированы нулевыми значениями, все компоненты вектора С были бы нулевыми независимо от значений компонент входного вектора, и обучающий алгоритм предохранял бы веса от изменения их нулевых значений. Обучение может рассматриваться как процесс «сокращения» компонент запомненных векторов, которые не соответствуют входным векторам. Этот процесс необратим, если вес однажды установлен в нуль, обучающий алгоритм никогда не восстановит его единичное значение. Это свойство имеет важное отношение к процессу обучения. Предположим, что группа точно соответствующих векторов должна быть классифицирована к одной категории, определяемой возбуждением одного нейрона в слое распознавания. Если эти вектора последовательно предъявляются сети, при предъявлении первого будет распределяться нейрон распознающего слоя, его веса будут обучены с целью соответствия входному вектору. Обучение при предъявлении остальных векторов будет приводить к обнулению весов в тех позициях, которые имеют нулевые значения в любом из входных векторов. Таким образом, запомненный вектор представляет собой логическое пересечение всех обучающих векторов и может включать существенные характеристики данной категории весов. Новый вектор, включающий только существенные характеристики, будет соответствовать этой категории. Таким образом, сеть корректно распознает образ, никогда не виденный ранее, т.е. реализуется возможность, напоминающая процесс восприятия человека.
Настройка весовых векторов Вj.
Выражение, описывающее процесс настройки весов (выражение (8.6) повторено здесь для справки) является центральным для описания процесса функционирования сетей APT.
Сумма в знаменателе представляет собой количество единиц на выходе слоя сравнения. Эта величина может быть рассмотрена как «размер» этого вектора. В такой интерпретации «большие» векторы С производят более маленькие величины весов bij, чем «маленькие» вектора С. Это свойство самомасштабирования делает возможным разделение двух векторов в случае, когда один вектор является поднабором другого; т.е. когда набор единичных компонент одного вектора составляет подмножество единичных компонент другого. Чтобы продемонстрировать проблему, возникающую при отсутствии масштабирования, используемого в выражении (8.6), предположим, что сеть обучена двум приведенным ниже входным векторам, при этом каждому распределен нейрон в слое распознавания.
Х1 = 1 0 0 0 0
X2= 1 1 1 0 0
Заметим, что Х1 является поднабором Х2 . В отсутствие свойства масштабирования веса bij и tij получат значения, идентичные значениям входных векторов. Если начальные значения выбраны равными 1,0, веса образов будут иметь следующие значения:
T1 = В1 = 1 0 0 0 0
Т2 = B2 =1 1 1 0 0
Если X прикладывается повторно, оба нейрона в слое распознавания получают одинаковые активации; следовательно, нейрон 2, ошибочный нейрон, выиграет конкуренцию. Кроме выполнения некорректной классификации, может быть нарушен процесс обучения. Так как Т2 равно 1 1 1 0 0, только первая единица соответствует единице входного вектора, и С устанавливается в 1 0 0 0 0, критерий сходства удовлетворяется и алгоритм обучения устанавливает вторую и третью единицы векторов Т2 и В2 в нуль, разрушая запомненный образ. Масштабирование весов bij предотвращает это нежелательное поведение. Предположим, что в выражении (8.2) используется значение L=2, тем самым определяя следующую формулу:
Значения векторов будут тогда стремиться к величинам
В1 = 1 0 0 0 0
В2 = 1/2 1/2 1/2 0 0
Подавая на вход сети вектор X1, получим возбуждающее воздействие 1,0 для нейрона 1 в слое распознавания и 1/2 для нейрона 2; таким образом, нейрон 1 (правильный) выиграет соревнование. Аналогично предъявление вектора Х2 вызовет уровень возбуждения 1,0 для нейрона 1 и 3/2 для нейрона 2, тем самым снова правильно выбирая победителя.
Инициализация весов bij
Инициализация весов bij малыми значениями является существенной для корректного функционирования систем APT. Если они слишком большие, входной вектор, который ранее был запомнен, будет скорее активизировать несвязанный нейрон, чем ранее обученный. Выражение (8.1), определяющее начальные значения весов, повторяется здесь для справки
bij =0,
OUT=0 при NET < 0.
Предполагая, что NET имеет положительное значение, это можно записать следующим образом:
OUT = (E - I)/(1 + I).
Когда тормозящий вход мал ( I >1 и I >>1.
В данном случае OUT определяется отношением возбуждающих входов к тормозящим входам, а не их разностью. Таким образом, величина OUT ограничивается, если оба входа возрастают в одном и том же диапазоне X. Предположив, что это так, Е и I можно выразить следующим образом:
Е = рХ, I = qX, p,q - константы, и после некоторых преобразований OUT = [(р - q)/2q]{1 + th[log(pq)/2]}.
Эта функция возрастает по закону Вебера-Фехнера, который часто используется в нейрофизиологии для аппроксимации нелинейных соотношений входа/выхода сенсорных нейронов. При использовании этого соотношения нейрон когнитрона в точности эмулирует реакцию биологических нейронов. Это делает его как мощным вычислительным элементом, так и точной моделью для физиологического моделирования.
Тормозящие нейроны.
В когнитроне слой состоит из возбуждающих и тормозящих узлов. Как показано на рис. 10.4, нейрон слоя 2 имеет область связи, для которой он имеет синаптические соединения с набором выходов нейронов в слое 1. Аналогично в слое 1 существует тормозящий нейрон, имеющий ту же область связи. Синаптические веса тормозящих узлов не изменяются в процессе обучения; их веса заранее установлены таким образом, что сумма весов в любом из тормозящих нейронов равна единице. В соответствии с этими ограничениями, выход тормозящего узла INHIB является взвешенной суммой его входов, которые в данном случае представляют собой среднее арифметическое выходов возбуждающих нейронов, к которым он подсоединен. Таким образом,
где =1, сi - возбуждающий вес i.
Процедура обучения. Как объяснялось ранее, веса возбуждающих нейронов изменяются только тогда, когда нейрон возбужден сильнее, чем любой из узлов в области конкуренции. Если это так, изменение в процессе обучения любого из его весов может быть определено следующим образом:
ai=qcjuj
где сj- тормозящий вес связи нейрона j в слое 1 с тормозящим нейроном i, иj - выход нейрона j в слое 1, аi - возбуждающий вес i, q - нормирующий коэффициент обучения. Изменение тормозящих весов нейрона i в слое 2 пропорционально отношению взвешенной суммы возбуждающих входов к удвоенному тормозящему входу. Вычисления проводятся по формуле
Когда возбужденных нейронов в области конкуренции нет, для изменения весов используются другие выражения. Это необходимо, поскольку процесс обучения начинается с нулевыми значениями весов; поэтому первоначально нет возбужденных нейронов ни в одной области конкуренции, и обучение производиться не может. Во всех случаях, когда победителя в области конкуренции нейронов нет, изменение весов нейронов вычисляется следующим образом :
где q' - положительный обучающий коэффициент меньший чем q. Приведенная стратегия настройки гарантирует, что узлы с большой реакцией заставляют возбуждающие синапсы, которыми они управляют, увеличиваться сильнее, чем тормозящие синапсы. И наоборот, узлы, имеющие малую реакцию, вызывают малое возрастание возбуждающих синап сов, но большее возрастание тормозящих синапсов. Таким образом, если узел 1 в слое 1 имеет больший выход, синапс а1 возрастет больше, чем синапс b1 . И наоборот, узлы, имеющие малый выход, обеспечат малую величину для приращения аi. Однако другие узлы в области связи будут возбуждаться, тем самым увеличивая сигнал INHIB и значения bi. В процессе обучения веса каждого узла в слое 2 настраиваются таким образом, что вместе они составляют шаблон, соответствующий образам, которые часто предъявляются в процессе обучения. При предъявлении сходного образа шаблон соответствует ему и узел вырабатывает большой выходной сигнал. Сильно отличающийся образ вырабатывает малый выход и обычно подавляется конкуренцией.
Латеральное торможение. На рис. 10.4 показано, что каждый нейрон слоя 2 получает латеральное торможение от нейронов, расположенных в его области конкуренции. Тормозящий нейрон суммирует входы от всех нейронов в области конкуренции и вырабатывает сигнал, стремящийся к торможению целевого нейрона. Этот метод является эффектным, но с вычислительной точки зрения медленным. Он охватывает большую систему с обратной связью, включающую каждый нейрон в слое; для его стабилизации может потребоваться большое количество вычислительных итераций. Для ускорения вычислений в работе [2] используется остроумный метод ускоренного латерального торможения (рис. 10.5). Здесь дополнительный узел латерального торможения обрабатывает выход каждого возбуждающего узла для моделирования требуемого латерального торможения. Сначала он определяет сигнал, равный суммарному тормозящему влиянию в области конкуренции:
где OUTi - выход i-го нейрона в области конкуренции, g1-вес связи от этого нейрона к латерально-тормозящему нейрону; gi выбраны таким образом, что =1.
Выход тормозящего нейрона OUT' затем вычисляется следующим образом:
Благодаря тому что все вычисления, связанные с таким типом латерального торможения, являются нерекурсивными, они могут быть проведены за один проход для слоя, тем самым определяя эффект в виде большой экономии в вычислениях. Этот метод латерального торможения решает и другую сложную проблему. Предположим, что узел в слое 2 возбуждается сильно, но возбуждение соседних узлов уменьшается постепенно с увеличением расстояния. При использовании обычного латерального торможения будет обучаться только центральный узел. Другие узлы определяют, что центральный узел в их области конкуренции имеет более высокий выход. С предлагаемой системой латерального торможения такой ситуации случиться не может. Множество узлов может обучаться одновременно и процесс обучения является более достоверным.
Рецептивная область. Анализ, проводимый до этого момента, был упрощен рассмотрением только одномерных слоев. В действительности когнитрон конструировался как каскад двумерных слоев, причем в данном слое каждый нейрон получает входы от набора нейронов на части двумерного плана, составляющей его область связи в предыдущем слое. С этой точки зрения когнитрон организован подобно зрительной коре человека, представляющей собой трехмерную структуру, состоящую из нескольких различных слоев. Оказывается, что каждый слой мозга реализует различные уровни обобщения; входной слой чувствителен к простым образам, таким, как линии, и их ориентации в определенных областях визуальной области, в то время как реакция других слоев является более сложной, абстрактной и независимой от позиции образа. Аналогичные функции реализованы в когнитроне путем моделирования организации зрительной коры. На рис. 10.6 показано, что нейроны когнитрона в слое 2 реагируют на определенную небольшую область входного слоя 1. Нейрон в слое 3 связан с набором нейронов слоя 2, тем самым реагируя косвенно на более широкий набор нейронов слоя 1. Подобным образом нейроны в последующих слоях чувствительны к более широким областям входного образа до тех пор, пока в выходном слое каждый нейрон не станет реагировать на все входное поле. Если область связи нейронов имеет постоянный размер во всех слоях, требуется большое количество слоев для перекрытия всего входного поля выходными нейронами. Количество слоев может быть уменьшено путем расширения области связи в последующих слоях. К сожалению, результатом этого может явиться настолько большое перекрытие областей связи, что нейроны выходного слоя будут иметь одинаковую реакцию. Для решения этой проблемы может быть использовано расширение области конкуренции. Так как в данной области конкуренции может возбудиться только один узел, влияние малой разницы в реакциях нейронов выходного слоя усиливается.
В альтернативном варианте связи с предыдущим слоем могут быть распределены вероятностно с большинством синаптических связей в ограниченной области и с более длинными соединениями, встречающимися намного реже. Это отражает вероятностное распределение нейронов, обнаруженное в мозге. В когнитроне это позволяет каждому нейрону выходного слоя реагировать на полное входное поле при наличии ограниченного количества слоев.
Результаты моделирования. В [4] описываются результаты компьютерного моделирования четырехслойного когнитрона, предназначенного для целей распознавания образов. Каждый слой состоит из массива 12 х 12 возбуждающих нейронов и такого же количества тормозящих нейронов. Область связи представляет собой квадрат, включающий 5 х 5 нейронов. Область конкуренции имеет форму ромба высотой и шириной в пять нейронов. Латеральное торможение охватывает область 7 х 7 нейронов. Нормирующие параметры обучения установлены таким образом, что q=l6,0 и q' =2,0. Веса синапсов проинициализированы в 0. Сеть обучалась путем предъявления пяти стимулирующих образов, представляющих собой изображения арабских цифр от 0 до 4, на входном слое. Веса сети настраивались после предъявления каждой цифры, входной набор подавался на вход сети циклически до тех пор, пока каждый образ не был предъявлен суммарно 20 раз. Эффективность процесса обучения оценивалась путем запуска сети в реверсивном режиме; выходные образы, являющиеся реакцией сети, подавались на выходные нейроны и распространялись обратно к входному слою. Образы, полученные во входном слое, затем сравнивались с исходным входным образом. Чтобы сделать это, обычные однонаправленные связи принимались проводящими в обратном направлении и латеральное торможение отключалось. На рис. 10.7 показаны типичные результаты тестирования. В столбце 2 показаны образы, произведенные каждой цифрой на выходе сети. Эти образы возвращались обратно, вырабатывая на входе сети образ, близкий к точной копии исходного входного образа. Для столбца 4 на выход сети подавался только выход нейрона, имеющего максимальное возбуждение. Результирующие образы в точности те же, что и в случае подачи полного выходного образа, за исключением цифры 0, для которой узел с максимальным выходом располагался на периферии и не покрывал полностью входного поля.
НЕОКОГНИТРОН
В попытках улучшить когнитрон была разработана мощная парадигма, названная неокогнитрон [5-7]. В то время как когнитрон и неокогнитрон имеют определенное сходство, между ними также существуют фундаментальные различия, связанные с эволюцией исследований авторов. Оба образца являются многоуровневыми иерархическими сетями, организованными аналогично зрительной коре. В то же время неокогнитрон более соответствует модели зрительной системы, предложенной в работах [10-12]. В результате неокогнитрон является намного более мощной парадигмой с точки зрения способности распознавать образы независимо от их преобразований, вращений, искажений и изменений масштаба. Как и когнитрон, неокогнитрон использует самоорганизацию в процессе обучения, хотя была описана версия [9], в которой вместо этого использовалось управляемое обучение. Неокогнитрон ориентирован на моделирование зрительной системы человека. Он получает на входе двумерные образы, аналогичные изображениям на сетчатой оболочке глаза, и обрабатывает их в последующих слоях аналогично тому, как это было обнаружено в зрительной коре человека. Конечно, в неокогнитроне нет ничего, ограничивающего его использование только для обработки визуальных данных, он достаточно универсален и может найти широкое применение как обобщенная система распознавания образов. В зрительной коре были обнаружены узлы, реагирующие на такие элементы, как линии и углы определенной ориентации. На более высоких уровнях узлы реагируют на более сложные и абстрактные образы такие, как окружности, треугольники и прямоугольники. На еще более высоких уровнях степень абстракции возрастает до тех пор, пока не определятся узлы, реагирующие на лица и сложные формы. В общем случае узлы на более высоких уровнях получают вход от группы низкоуровневых узлов и, следовательно, реагируют на более широкую область визуального поля. Реакции узлов более высокого уровня менее зависят от позиции и более устойчивы к искажениям.
Структура
Неокогнитрон имеет иерархическую структуру, ориентированную на моделирование зрительной системы человека. Он состоит из последовательности обрабатывающих слоев, организованных в иерархическую структуру (рис. 10.8). Входной образ подается на первый слой и передается через плоскости, соответствующие последующим слоям, до тех пор, пока не достигнет выходного слоя, в котором идентифицируется распознаваемый образ.
Структура неокогнитрона трудна для представления в виде диаграммы, но концептуально проста. Чтобы подчеркнуть его многоуровневость (с целью упрощения графического представления), используется анализ верхнего уровня. Неокогнитрон показан состоящим из слоев, слои состоят из набора плоскостей и плоскости состоят из узлов.
Слои. Каждый слой неокогнитрона состоит из двух массивов плоскостей (рис. 10.9). Массив плоскостей, содержащих простые узлы, получает выходы предыдущего слоя, выделяет определенные образы и затем передает их в массив плоскостей, содержащих комплексные узлы, где они обрабатываются таким образом, чтобы сделать выделенные образы менее позиционно зависимыми.
Плоскости. Внутри слоя плоскости простых и комплексных узлов существуют парами, т.е. для плоскости простых узлов существует одна плоскость комплексных узлов, обрабатывающая ее выходы. Каждая плоскость может быть визуально представлена как двумерный массив.
Простые узлы. Все узлы в данной плоскости простых узлов реагируют на один и тот же образ. Как показано на рис. 10.10, плоскость простых узлов представляет массив узлов, каждый из которых «настраивается» на один специфический входной образ. Каждый простой узел чувствителен к ограниченной области входного образа, называемой его рецептивной областью. Например, все узлы в верхней плоскости простых узлов на рис. 10.10 реагируют на С. Узел реагирует, если С встречается во входном образе и если С обнаружено в его рецептивной области. На рис. 10.10 показано, что другие плоскости простых узлов в этом слое могут реагировать на поворот С на 90°, другие на поворот на 180° и т.д. Если должны быть выделены другие буквы (и их искаженные версии), дополнительные плоскости требуются для каждой из них. Рецептивные области узлов в каждой плоскости простых узлов перекрываются с целью покрытия всего входного образа этого слоя. Каждый узел получает входы от соответствующих областей всех плоскостей комплексных узлов в предыдущем слое. Следовательно, простой узел реагирует на появление своего образа в любой сложной плоскости предыдущего слоя, если он окажется внутри его рецептивной области.
Рис. 10.10. Система неокогнитрона.
Комплексные узлы. Задачей комплексных узлов является уменьшение зависимости реакции системы от позиции образов во входном поле. Для достижения этого каждый комплексный узел получает в качестве входного образа выходы набора простых узлов из соответствующей плоскости того же слоя. Эти простые узлы покрывают непрерывную область простой плоскости, называемую рецептивной областью комплексного узла. Возбуждение любого простого узла в этой области является достаточным для возбуждения данного комплексного узла. Таким образом, комплексный узел реагирует на тот же образ, что и простые узлы в соответствующей ему плоскости, но он менее чувствителен к позиции образа, чем любой из них. Таким образом, каждый слой комплексных узлов реагирует на более широкую область входного образа, чем это делалось в предшествующих слоях. Эта прогрессия возрастает линейно от слоя к слою, приводя к требуемому уменьшению позиционной чувствительности системы в целом.
Обобщение
Каждый нейрон в слое, близком к входному, реагирует на определенные образы в определенном месте, такие, как угол с определенной ориентацией в заданной позиции. Каждый слой в результате этого имеет более абстрактную, менее специфичную реакцию по сравнению с предшествующим; выходной слой реагирует на полные образы, показывая высокую степень независимости от их положения, размера и ориентации во входном поле. При использовании в качестве классификатора комплексный узел выходного слоя с наибольшей реакцией реализует выделение соответствующего образа во входном поле. В идеальном случае это выделение нечувствительно к позиции, ориентации, размерам или другим искажениям.
Вычисления
Простые узлы в неокогнитроне имеют точно такие же характеристики, что и описанные для когнитрона, и используют те же формулы для определения их выхода. Здесь они не повторяются. Тормозящий узел вырабатывает выход, пропорциональный квадратному корню из взвешенной суммы квадратов его входов. Заметим, что входы в тормозящий узел идентичны входам соответствующего простого узла и область включает область ответа во всех комплексных плоскостях. В символьном виде
где v - выход тормозящего узла; i - область над всеми комплексными узлами, с которыми связан тормозящий узел; bi - вес i-й синаптической связи от комплексного узла к тормозящему узлу; иi- выход i-го комплексного узла. Веса Ь. выбираются монотонно уменьшающимися с увеличением расстояния от центра области реакции, при этом сумма их значений должна быть равна единице.
Обучение
Только простые узлы имеют настраиваемые веса. Это веса связей, соединяющих узел с комплексными узлами в предыдущем слое и имеющих изменяемую силу синапсов, настраиваемую таким образом, чтобы выработать максимальную реакцию на определенные стимулирующие свойства. Некоторые из этих синапсов являются возбуждающими и стремятся увеличить выход узлов, в то время как другие являются тормозящими и уменьшают выход узла.
Рис. 10.11. Связи от сложных клеток одного уровня к простым клеткам следующего уровня.
На рис. 10.11 показана полная структура синаптических связей между простым узлом и комплексными узлами в предшествующем слое. Каждый простой узел реагирует только на набор комплексных узлов внутри своей рецептивной области. Кроме того, существует тормозящий узел, реагирующий на те же самые комплексные узлы. Веса синапсов тормозящего узла не обучаются; они выбираются таким образом, чтобы узел реагировал на среднюю величину выходов всех узлов, к которым он подключен. Единственный тормозящий синапс от тормозящего узла к простому узлу обучается, как и другие синапсы. Обучение без учителя. Для обучения неокогнитрона на вход сети подается образ, который необходимо распознать, и веса синапсов настраиваются слой за слоем, начиная с набора простых узлов, ближайших ко входу. Величина синаптической связи от каждого комплексного узла к данному простому узлу увеличивается тогда и только тогда, когда удовлетворяются следующие два условия: 1) комплексный узел реагирует; 2) простой узел реагирует более сильно, чем любой из его соседних (внутри его области конкуренции). Таким образом, простой узел обучается реагировать более сильно на образы, появляющиеся наиболее часто в его рецептивной области, что соответствует результатам исследований, полученных в экспериментах с котятами. Если распознаваемый образ отсутствует на входе, тормозящий узел предохраняет от случайного возбуждения. Математическое описание процесса обучения и метод реализации латерального торможения аналогичны описанным для когнитрона, поэтому здесь они не повторяются. Необходимо отметить, что выходы простых и комплексных узлов являются аналоговыми, непрерывными и линейными и что алгоритм обучения предполагает их неотрицательность. Когда выбирается простой узел, веса синапсов которого должны быть увеличены, он рассматривается как представитель всех узлов в плоскости, вызывая увеличение их синаптических связей на том же самом образе. Таким образом, все узлы в плоскости обучаются распознавать одни и те же свойства, и после обучения будут делать это независимо от позиции образа в поле комплексных узлов в предшествующем слое. Эта система имеет ценную способность к самовосстановлению. Если данный узел выйдет из строя, будет найден другой узел, реагирующий более сильно, и этот узел будет обучен распознаванию входного образа, тем самым перекрывая действия своего отказавшего товарища.
Обучение с учителем. В работах [3] и [8] описано самоорганизующееся неуправляемое обучение. Наряду с этими впечатляющими результатами, были опубликованы отчеты о других экспериментах, использующих обучение с учителем [9]. Здесь требуемая реакция каждого слоя заранее определяется экспериментатором. Затем веса настраиваются с использованием обычных методов для выработки требуемой реакции. Например, входной слой настраивался для распознавания отрезков линий в различных ориентациях во многом аналогично первому слою обработки зрительной коры. Последующие слои обучались реагировать на более сложные и абстрактные свойства до тех пор, пока в выходном слое требуемый образ не будет выделен. При обработке сети, превосходно распознающей рукописные арабские цифры, экспериментаторы отказались от достижения биологического правдоподобия, обращая внимание только на достижение максимальной точности результатов системы.
Реализация обучения. В обычных конфигурациях рецептивное поле каждого нейрона возрастает при переходе к следующему слою. Однако количество нейронов в слое будет уменьшаться при переходе от входных к выходным слоям. Наконец, выходной слой имеет только один нейрон в плоскости сложных узлов. Каждый такой нейрон представляет определенный входной образ, которому сеть была обучена. В процессе классификации входной образ подается на вход неокогнитрона и вычисляются выходы слой за слоем, начиная с входного слоя. Так как только небольшая часть входного образа подается на i вход каждого простого узла входного слоя, некоторые простые узлы регистрируют наличие характеристик, которым они обучены, и возбуждаются. В следующем слое выделяются более сложные характеристики как определенные комбинации выходов комплексных узлов. Слой за слоем свойства комбинируются во все возрастающем диапазоне; выделяются более общие характеристики и уменьшается позиционная чувствительность. В идеальном случае только один нейрон выходного слоя должен возбудиться. В действительности обычно будет возбуждаться несколько нейронов с различной силой, и входной образ должен быть определен с учетом соотношения их выходов. Если используется сила латерального торможения, возбуждаться будет только нейрон с максимальным выходом. Однако это часто является не лучшим вариантом. На практике простая функция от небольшой группы наиболее сильно возбужденных нейронов будет часто улучшать точность классификации.
ЗАКЛЮЧЕНИЕ
Как когнитрон, так и неокогнитрон производят большое впечатление с точки зрения точности, с которой они моделируют биологическую нервную систему. Тот факт, что эти системы показывают результаты, имитирующие некоторые аспекты способностей человека к обучению и познанию, наводит на мысль, что наше понимание функций мозга приближается к уровню, способному принести практическую пользу. Неокогнитрон является сложной системой и требует существенных вычислительных ресурсов. По этим причинам кажется маловероятным, что такие системы реализуют оптимальное инженерное решение сегодняшних проблем распознавания образов. Однако с 1960 г. стоимость вычислений уменьшалась в два раза каждые два-три года, тенденция, которая, по всей вероятности, сохранится в течение как минимум ближайших десяти лет. Несмотря на то, что многие подходы, казавшиеся нереализуемыми несколько лет назад, являются общепринятыми сегодня и могут оказаться тривиальными через несколько лет, реализация моделей неокогнитрона на универсальных компьютерах является бесперспективной. Необходимо достигнуть тысячекратных улучшений стоимости и производительности компьютеров за счет специализации архитектуры и внедрения технологии СБИС, чтобы сделать неокогнитрон практической системой для решения сложных проблем распознавания образов, однако ни эта, ни какая- либо другая модель искусственных нейронных сетей не должны отвергаться только на основании их высоких вычислительных требований.
Приложение А Биологические нейронные сети
ЧЕЛОВЕЧЕСКИЙ МОЗГ: БИОЛОГИЧЕСКАЯ МОДЕЛЬ ДЛЯ ИСКУССТВЕННЫХ НЕЙРОННЫХ СЕТЕЙ
Структура искусственных нейронных сетей была смоделирована как результат изучения человеческого мозга. Как мы отмечали выше, сходство между ними в действительности очень незначительно, однако даже эта скромная эмуляция мозга приносит ощутимые результаты. Например, искусственные нейронные сети имеют такие аналогичные мозгу свойства, как способность обучаться на опыте, основанном на знаниях, делать абстрактные умозаключения и совершать ошибки, что является более характерным для человеческой мысли, чем для созданных человеком компьютеров.
Учитывая успехи, достигнутые при использовании грубой модели мозга, кажется естественным ожидать дальнейшего продвижения вперед при использовании более точной модели. Разработка такой модели требует детального понимания структуры и функций мозга. Это в свою очередь требует определения точных характеристик нейронов, включая их вычислительные элементы и элементы связи. К сожалению, информация не является полной; большая часть мозга остается тайной для понимания. Основные исследования проведены в области идентификации функций мозга, однако и здесь отсутствуют подходы, отличающиеся от чисто «схематических». Биохимия нейронов, фундаментальных строительных блоков мозга, очень неохотно раскрывает свои секреты. Каждый год приносит новую информацию относительно электрохимического поведения нейронов, причем всегда в направлении раскрытия новых уровней сложности. Ясно одно: нейрон является намного более сложным, чем представлялось несколько лет назад, и нет полного понимания процесса его функционирования.
Однако, несмотря на наши ограниченные познания, мозг может быть использован в качестве ценной модели в вопросах развития искусственных нейронных сетей. Используя метод проб и ошибок, эволюция, вероятно, привела к структурам, оптимальным образом пригодным для решения проблем, более характерных для человека. Кажется маловероятным, что мы получим более хорошее решение. Тщательно моделируя мозг, мы продвигаемся в исследовании природы и в будущем будем, вероятно, воспроизводить больше возможностей мозга.
Данное приложение содержит штриховые наброски современных знаний относительно структуры и функций мозга. Хотя изложение этих сведений очень краткое, мы пытались сохранить точность. Следующие разделы иллюстрируют текст данной работы и, возможно, будут стимулировать интерес к биологическим системам, что приведет к развитию искусственных нейронных сетей.
ОРГАНИЗАЦИЯ ЧЕЛОВЕЧЕСКОГО МОЗГАЧеловеческий мозг содержит свыше тысячи миллиардов вычислительных элементов, называемых нейронами. Превышая по количеству число звезд в Млечном Пути галактики, эти нейроны связаны сотнями триллионов нервных нитей, называемых синапсами. Эта сеть нейронов отвечает за все явления, которые мы называем мыслями, эмоциями, познанием, а также и за совершение мириадов сенсомоторных и автономных функций. Пока мало понятно, каким образом все это происходит, но уже исследовано много вопросов физиологической структуры и определенные функциональные области постепенно изучаются исследователями.
Мозг также содержит густую сеть кровеносных сосудов, которые обеспечивают кислородом и питательными веществами нейроны и другие ткани. Эта система кровоснабжения связана с главной системой кровообращения посредством высокоэффективной фильтрующей системы, называемой гематоэнцефалическим барьером, этот барьер является механизмом защиты, который предохраняет мозг от возможных токсичных веществ, находящихся в крови.
Защита обеспечивается низкой проницаемостью кровеносных сосудов мозга, а также плотным перекрытием глиальных клеток, окружающих нейроны. Кроме этого, глиальные клетки обеспечивают структурную основу мозга. Фактически весь объем мозга, не занятый нейронами и кровеносными сосудами, заполнен глиальными клетками.
Гематоэнцефалический барьер является основой для обеспечения сохранности мозга, но он значительно осложняет лечение терапевтическими лекарствами. Он также мешает исследованиям, изучающим влияние различных химических веществ на функции мозга. Лишь небольшая часть лекарств, созданных с целью влияния на мозг, может преодолевать этот барьер. Лекарства состоят из небольших молекул, способных проникать через крошечные поры в кровеносных сосудах. Чтобы воздействовать на функции мозга, они должны затем пройти через глиальные клетки или раствориться в их мембране. Лишь некоторые молекулы интересующих нас лекарств удовлетворяют этим требованиям; молекулы многих терапевтических лекарств задерживаются этим барьером.
Мозг является основным потребителем энергии тела. Включая в себя лишь 2% массы тела, в состоянии покоя он использует приблизительно 20% кислорода тела. Даже когда мы спим, расходование энергии продолжается. В действительности существуют доказательства возможности увеличения расходования энергии во время фазы сна, сопровождаемой движением глаз. Потребляя только 20 Вт, мозг с энергетической точки зрения невероятно эффективен. Компьютеры с одной крошечной долей вычислительных возможностей мозга потребляют много тысяч ватт и требуют сложных средств для охлаждения, предохраняющего их от температурного саморазрушения.
НейронНейрон является основным строительным блоком нервной системы. Он является клеткой, подобной всем другим клеткам тела; однако определенные существенные отличия позволяют ему выполнять все вычислительные функции и функции связи внутри мозга.
Функционально дендриты получают сигналы от других клеток через контакты, называемые синапсами. Отсюда сигналы проходят в тело клетки, где они суммируются с другими такими же сигналами. Если суммарный сигнал в течение короткого промежутка времени является достаточно большим, клетка возбуждается, вырабатывая в аксоне импульс, который передается на следующие клетки. Несмотря на очевидное упрощение, эта схема функционирования объясняет большинство известных процессов мозга.
Тело ячейки. Нейроны в мозгу взрослого человека не восстанавливаются; они отмирают. Это означает, что все компоненты должны непрерывно заменяться, а материалы обновляться по мере необходимости. Большинство этих процессов происходит в теле клетки, где изменение химических факторов приводит к большим изменениям сложных молекул. Кроме этого, тело клетки управляет расходом энергии нейрона и регулирует множество других процессов в клетке. Внешняя мембрана тела клетки нейрона имеет уникальную способность генерировать нервные импульсы (потенциалы действия), являющиеся жизненными функциями нервной системы и центром ее вычислительных способностей.
Были идентифицированы сотни типов нейронов, каждый со своей характерной формой тела клетки (рис. А.2), имеющей обычно от 5 до 100 мкм в диаметре. В настоящее время этот факт рассматривается как проявление случайности, однако могут быть найдены различные морфологические конфигурации, отражающие важную функциональную специализацию. Определение функций различных типов клеток является в настоящее время предметом интенсивных исследований и основой понимания обрабатывающих механизмов мозга.
Дендриты. Большинство входных сигналов от других нейронов попадают в клетку через дендриты, представляющие собой густо ветвящуюся структуру, исходящую от тела клетки. На дедритах располагаются синаптические соединения, которые получают сигналы от других аксонов. Кроме этого, существует огромное количество синаптичес-ких связей от аксона к аксону, от аксона к телу клетки и от дендрита к дендриту; их функции не очень ясны, но они слишком широко распространены, чтобы не считаться с ними.
В отличие от электрических цепей, синаптические контакты обычно не являются физическими или электрическими соединениями. Вместо этого имеется узкое пространство, называемое синаптической щелью, отделяющее дендрит от передающего аксона. Специальные химические вещества, выбрасываемые аксоном в синаптическую щель, диффундируют к дендриту. Эти химические вещества, называемые нейротрансмиттерами, улавливаются специальными рецепторами на дендрите и внедряются в тело клетки.
Определено более 30 видов нейротрансмиттеров. Некоторые из них являются возбуждающими и стремятся вызывать возбуждение клетки и выработать выходной импульс. Другие являются тормозящими и стремятся подавить такой импульс. Тело клетки суммирует сигналы, полученные от дендритов, и если их результирующий сигнал выше порогового значения, вырабатывается импульс, проходящий по аксону к другим нейронам.
Аксон. Аксон может быть как коротким (0,1 мм), так и превышать длину 1 м, распространяясь в другую часть тела человека. На конце аксон имеет множество ветвей, каждая из которых завершается синапсом, откуда сигнал передается в другие нейроны через дендриты, а в некоторых случаях прямо в тело клетки. Таким образом, всего один нейрон может генерировать импульс, который возбуждает или затормаживает сотни или тысячи других нейронов, каждый из которых, в свою очередь, через свои дендриты может воздействовать на сотни или тысячи других нейронов. Таким образом, эта высокая степень связанности, а не функциональная сложность самого нейрона, обеспечивает нейрону его вычислительную мощность.
Синаптическая связь, завершающая ветвь аксона, представляет собой маленькие утолщения, содержащие сферические структуры, называемые синаптическими пузырьками, каждый из которых содержит большое число нейротрансмиттерных молекул. Когда нервный импульс приходит в аксон, некоторые из этих пузырьков высвобождают свое содержимое в синаптическую щель, тем самым инициализируя процесс взаимодействия нейронов (рис. А.З).
Кроме распространения такого бинарного сигнала, обеспечиваемого возбуждением первого импульса, в нейронах при слабой стимуляции могут также распространяться электрохимические сигналы с последовательной реакцией. Локальные по своей природе, эти сигналы быстро затухают с удалением от места возбуждения, если не будут усилены. Природа использует это свойство первых клеток путем создания вокруг аксонов изолирующей оболочки из шванковских клеток. Эта оболочка, называемая миелиновой, прерывается приблизительно через каждый миллиметр вдоль аксона узкими разрывами, называемыми узлами, или перехватами Ранвье. Нервные импульсы, приходящие в аксон, передаются екачкообразно от узла к узлу. Таким образом, аксону нет нужды расходовать энергию для поддержания своего химического градиента по всей своей длине. Только оставшиеся неизолированными перехваты Ранвье являются объектом генерации первого импульса; для передачи сигнала от узла к узлу более эффективными являются градуальные реакции. Кроме этого свойства оболочки, обеспечивающего сохранение энергии, известны ее другие свойства. Например, миелинизирован-ные нервные окончания передают сигналы значительно быстрее немиелинизированных. Обнаружено, что некоторые болезни приводят к ухудшению этой изоляции, что, по-видимому, является причиной других болезней.
Мембрана клетки
В мозгу существует 2 типа связей: передача химических сигналов через синапсы и передача электрических сигналов внутри нейрона. Великолепное сложное действие мембраны создает способность клетки вырабатывать и передавать оба типа этих сигналов.
Мембрана клетки имеет около 5 нм толщины и состоит из двух слоев липидных молекул. Встроенные в мембрану различные специальные протеины можно разделить на пять классов: насосы, каналы, рецепторы, энзимы и структурные протеины.
Насосы активно перемещают ионы через мембрану клетки для поддержания градиентов концентрации. Каналы пропускают ионы выборочно и управляют их прохождением через мембрану. Некоторые каналы открываются или закрываются распространяющимся через мембрану электрическим потенциалом, тем самым обеспечивая быстрое и чувствительное средство изменения ионных градиентов. Другие типы каналов управляются химически, изменяя свою проницаемость при получении химических носителей.
Рецепторами являются протеины, которые распознают и присоединяют многие типы молекул из окружения клетки с большой точностью. Энзимы оболочки ускоряют разнообразные химические реакции внутри или около клеточной мембраны. Структурные протеины соединяют клетки и помогают поддерживать структуру самой клетки.
Внутренняя концентрация натрия в клетке в 10 раз ниже, чем в ее окружении, а концентрация калия в 10 раз выше. Эти концентрации стремятся к выравниванию с помощью утечки через поры в мембране клетки. Чтобы сохранить необходимую концентрацию, протеиновые молекулы мембраны, называемые натриевыми насосами, постоянно отсасывают натрий из клетки и подкачивают калий в клетку. Каждый насос перемещает приблизительно две сотни ионов натрия и около ста тридцати ионов калия в секунду. Нейрон может иметь миллионы таких насосов, перемещающих сотни миллионов ионов калия и натрия через мембрану клетки в каждую секунду. На концентрацию калия внутри ячейки влияет также наличие большого числа постоянно открытых калиевых каналов, т.е. протеиновых молекул, которые хорошо пропускают ионы калия в клетку, но препятствуют прохождению натрия. Комбинация этих двух механизмов отвечает за создание и поддержание динамического равновесия, соответствующего состоянию нейрона в покое.
Градиент ионной концентрации в мембране клетки вырабатывает внутри клетки электрический потенциал -70 мВ относительно ее окружения. Чтобы возбудить клетку (стимулировать возникновение потенциала действия) синаптические входы должны уменьшить этот уровень до приблизительно -50 мВ. При этом потоки натрия и калия сразу направляются в обратную сторону; в течение миллисекунд внутренний потенциал клетки становится +50 мВ относительно внешнего окружения. Это изменение полярности быстро распространится через клетку, заставляя нервный импульс распространиться по всему аксону до его пресинаптических окончаний. Когда импульс достигнет окончания аксона, открываются управляемые напряжением кальциевые каналы. Это вызывает освобождение нейротран-смиттерных молекул в синаптическую щель и процесс распространяется на другие нейроны. После генерации потенциала действия клетка войдет в рефракторный период на несколько миллисекунд, в течении которого она восстановит свой первоначальный потенциал для подготовки к генерации следующего импульса.
Рассмотрим этот процесс более детально. Первоначальное получение нейротрансмиттерных молекул снижает внутренний потенциал клетки с -70 до -50 мВ. При этом зависимые от потенциала натриевые каналы открываются, позволяя натрию проникнуть в клетку. Это еще более уменьшает потенциал, увеличивая приток натрия в клетку, и создает самоусиливающийся процесс, который быстро распространяется в соседние области, изменяя локальный потенциал клетки с отрицательного до положительного.
Через некоторое время после открытия натриевые каналы закрываются, а калиевые каналы открываются. Это создает усиленный поток ионов калия из клетки, что восстанавливает внутренний потенциал -70 мВ. Это быстрое изменение напряжения образует потенциал действия, который быстро распространяется по всей длине аксона подобно лавине.
Натриевые и калиевые каналы реагируют на потенциал клетки и, следовательно, можно сказать, что они управляют напряжением. Другой тип каналов является химически управляемым. Эти каналы открываются только тогда, когда специальная нейротрансмиттерная молекула попадает на рецептор, и они совсем не чувствительны к напряжению.
Такие каналы обнаруживаются в постсинаптических мембранах на дендритах и ответственны за реакцию нейронов на воздействие различных нейротрансмиттерных молекул. Чувствительный к ацетилхолину белок (ацетилхолиновый рецептор) является одним из таких химических каналов. Когда молекулы ацетилхолина выделяются в синаптическую щель, они диффундируют к ацетилхолиновым рецепторам, входящим в постсинаптическую мембрану. Эти рецепторы (которые также являются каналами) затем открываются, обеспечивая свободный проход как калия, так и натрия через мембрану. Это приводит к кратковременному локальному уменьшению отрицательного внутреннего потенциала клетки (формируя положительный импульс). Так как импульсы являются короткими и слабыми, то чтобы заставить клетку выработать необходимый электрический потенциал, требуется открытие многих таких каналов.
Ацетилхолиновые рецепторы-каналы пропускают и натрий, и калий, вырабатывая тем самым положительные импульсы. Такие импульсы являются возбуждающими, поскольку они способствуют появлению необходимого потенциала. Другие химически управляемые каналы пропускают только калиевые ионы из клетки, производя отрицательный импульс; эти импульсы являются тормозящими, поскольку они препятствуют возбуждению клетки.
Гамма-аминомасляная кислота (ГАМК) является одним из более общих тормозных нейротрансмиттеров. Обнаруженная почти исключительно в головном и спинном мозге, она попадает на рецептор канала, который выборочно пропускает ионы хлора. После входа эти ионы увеличивают отрицательный потенциал клетки и тем самым препятствуют ее возбуждению. Дефицит ГАМК связан с хореей Хантингтона, имеющей нейрологический синдром, вызывающий бесконтрольное движение мускулатуры. К несчастью, гематоэнцефалический барьер препятствует увеличению снабжения ГАМК, и как выйти из этого положения, пока неизвестно. Вероятно, что и другие нейрологические и умственные растройства будут наблюдаться при подобных нарушениях в нейротрансмиттерах или других химических носителях. Уровень возбуждеия нейрона определяется кумулятивным эффектом большого числа возбуждающих и тормозящих входов, суммируемых телом клетки в течение короткого временного интервала. Получение возбуждающей нейротрансмиттерной молекулы будет увеличивать уровень возбуждения нейрона; их меньшее количество или смесь тормозящих молекул уменьшает уровень возбуждения. Таким образом, нейронный сигнал является импульсным или частотно-модулируемым (ЧМ). Этот метод модуляции, широко используемый в технике (например, ЧМ-радио), имеет значительные преимущества при наличии помех по сравнению с другими способами. Исследования показали изумляющую сложность биохимических процессов в мозге. Например, предполагается наличие свыше 30 вешеств, являющихся нейротрансмиттерами, и большое количество рецепторов с различными ответными реакциями. Более того, действие определенных нейротрансмиттерных молекул зависит от типа рецептора в постсинаптической мембране, некоторые нейротрансмиттеры могут быть возбуждающими для одного синапса и тормозящими для другого. Кроме того, внутри клетки существует система «вторичного переносчика», которая включается при получении нейротрансмиттера, что приводит к выработке большого количества молекул циклического аденозинтрифосфата, тем самым производя значительное усиление физиологических
реакций.
Исследователи всегда надеются найти простые образы для унификации сложных и многообразных наблюдений. Для нейробиологических исследований такие простые образы до сих пор не найдены. Большинство результатов исследований подвергаются большому сомнению прежде, чем ими воспользуются. Одним из таких результатов в изучении мозга явилось открытие множества видов электрохимической деятельности, обнаруженных в работе мозга; задачей является их объединение в связанную функциональную модель.
КОМПЬЮТЕРЫ И ЧЕЛОВЕЧЕСКИЙ МОЗГ
Существует подобие между мозгом и цифровым компьютером: оба оперируют электронными сигналами, оба состоят из большого количества простых элементов, оба выполняют функции, являющиеся, грубо говоря, вычислительными. Тем не менее существуют и фундаментальные отличия. По сравнению с микросекундными и даже наносекундными интервалами вычислений современных компьютеров нервные импульсы являются слишком медленными. Хотя каждый нейрон требует наличия миллисекундного интервала между передаваемыми сигналами, высокая скорость вычислений мозга обеспечивается огромным числом параллельных вычислительных блоков, причем количество их намного превышает доступное современным ЭВМ. Диапазон ошибок представляет другое фундаментальное отличие: ЭВМ присуща свобода от ошибок, если входные сигналы безупречно точны и ее аппаратное и программное обеспечение не повреждены. Мозг же часто производит лучшее угадывание и приближение при частично незавершенных и неточных входных сигналах. Часто он ошибается, но величина ошибки должна гарантировать наше выживание в течение миллионов лет.
Первые цифровые вычислители часто рассматривались как «электронный мозг». С точки зрения наших текущих знаний о сложности мозга, такое заявление оптимистично, да и просто не соответствует истине. Эти две системы явно различаются в каждой своей части. Они оптимизированы для решения различных типов проблем, имеют существенные различия в структуре и их работа оценивается различными критериями.
Некоторые говорят, что искусственные нейронные сети когда-нибудь будут дублировать функции человеческого мозга. Прежде чем добиться этого, необходимо понять организацию и функции мозга. Эта задача, вероятно, не будет решена в ближайшем будущем. Надо отметить то, что современные нейросети базируются на очень упрощенной модели, игнорирующей большинство тех знаний, которые мы имеем о детальном функционировании мозга. Поэтому необходимо разработать более точную модель, которая могла бы качественнее моделировать работу мозга.
Прорыв в области искусственных нейронных сетей будет требовать развития их теоретического фундамента. Теоретические выкладки, в свою очередь, должны предваряться улучшением математических методов, поскольку исследования серьезно тормозятся нащей неспособностью иметь дело с такими системами. Успокаивает тот факт, что современный уровень математического обеспечения был достигнут под влиянием нескольких превосходных исследователей. В действительности аналитические проблемы являются сверхтрудными, так как рассматриваемые системы являются очень сложными нелинейными динамическими системами. Возможно, для описания систем, имеющих сложность головного мозга, необходимы совершенно новые математические методы. Может быть и так, что разработать полностью удовлетворяющий всем требованиям аппарат невозможно.
Несмотря на существующие проблемы, желание смоделировать человеческий мозг не угасает, а получение зачаровывающих результатов вдохновляет на дальнейшие усилия. Успешные модели, основанные на предположениях о структуре мозга, разрабатываются нейроанатомами и нейрофизиологами с целью их изучения для согласования структуры и функций этих моделей. С другой стороны, успехи в биологической науке ведут к модификации и тщательной разработке искуственных моделей. Аналогично инженеры применяют искусственные модели для реализации мировых проблем и получают положительные результаты, несмотря на отсутствие полного взаимопонимания.
Объединение научных дисциплин для изучения проблем искусственных нейросетей принесет эффективные результа ты, которые могут стать беспримерными в истории науки. Биологи, анатомы, физиологи, инженеры, математики и даже философы активно включились в процесс исследований. Проблемы являются сложными, но цель высока: познается сама человеческая мысль.
Приложение Б Алгоритмы обучения
Искусственные нейронные сети обучаются самыми разнообразными методами. К счастью, большинство методов обучения исходят из общих предпосылок и имеет много идентичных характеристик. Целью данного приложения является обзор некоторых фундаментальных алгоритмов, как с точки зрения их текущей применимости, так и с ' точки зрения их исторической важности. После ознакомления с этими фундаментальными алгоритмами другие, основанные на них, алгоритмы будут достаточно легки для понимания и новые разработки также могут быть лучше поняты и развиты.
ОБУЧЕНИЕ С УЧИТЕЛЕМ И БЕЗ УЧИТЕЛЯОбучающие алгоритмы могут быть классифицированы как алгоритмы обучения с учителем и без учителя. В первом случае существует учитель, который предъявляет входные образы сети, сравнивает результирующие выходы с требуемыми, а затем настраивает веса сети таким образом, чтобы уменьшить различия. Трудно представить такой обучающий механизм в биологических системах; следовательно, хотя данный подход привел к большим успехам при решении прикладных задач, он отвергается исследователями, полагающими, что искусственные нейронные сети обязательно должны использовать те же механизмы, что и человеческий мозг.
Во втором случае обучение проводится без учителя, при предъявлении входных образов сеть самоорганизуется посредством настройки своих весов согласно определенному алгоритму. Вследствие отсутствия указания требуемого выхода в процессе обучения результаты непредсказуемы с точки зрения определения возбуждающих образов для конкретных нейронов. При этом, однако, сеть организуется в форме, отражающей существенные характеристики обучающего набора. Например, входные образы могут быть классифицированы согласно степени их сходства так, что образы одного класса активизируют один и тот же выходной ней рон.
МЕТОД ОБУЧЕНИЯ ХЭББАРабота [2] обеспечила основу для большинства алгоритмов обучения, которые были разработаны после ей выхода. В предшествующих этой работе трудах в обп^ виде определялось, что обучение в биологических системах происходит посредством некоторых физических изменений в нейронах, однако отсутствовали идеи о том, каки» образом это в действительности может иметь место. Основываясь на физиологических и психологических исследованиях, Хэбб в [2] интуитивно выдвинул гипотезу о том, каким образом может обучаться набор биологических нейронов. Его теория предполагает только локальное взаимодействие между нейронами при отсутствии глобального учителя; следовательно, обучение является неуправляемым. Несмотря на то что его работа не включает математического анализа, идеи, изложенные в ней, настолько ясны и непринужденны, что получили статус универсальных допущений. Его книга стала классической и широко изучается специалистами, имеющими серьезный интерес в этой области.
Алгоритм обучения ХеббаПо существу Хэбб предположил, что синаптическое соединение двух нейронов усиливается, если оба эти нейрона возбуждены. Это можно представить как усиление синапса в соответствии с корреляцией уровней возбужденных нейронов, соединяемых данным синапсом. По этой причине алгоритм обучения Хэбба иногда называется корреляционным алгоритмом. Идея алгоритма выражается следующим равенством:
где ij(t) - сила синапса от нейрона i к нейрону j ,в момент времени t, NETi - уровень возбуждения пресинаптического нейрона; NETj - уровень возбуждения постсинаптического нейрона.
Концепция Хэбба отвечает на сложный вопрос, каким образом обучение может проводиться без учителя. В методе Хэбба обучение является исключительно локальным явлением, охватывающим только два нейрона и соединяющий их синапс; не требуется глобальной системы обратной связи для развития нейронных образований.
Последующее использование метода Хэбба для обучения нейронных сетей привело к большим успехам, но наряду с этим показало ограниченность метода; некоторые образы просто не могут использоваться для обучения этим методом. В результате появилось большое количество расширений и нововведений, большинство из которых в значительной степени основано на работе Хэбба.
Метод сигнального обучения ХэббаКак мы видели, выход NET простого искусственного нейрона является взвешенной суммой его входов. Это может быть выражено следующим образом:
где NETj - выход NET нейрона j; OUTi - выход нейрона i; w,. - вес связи нейрона i с нейроном j. Можно показать, что в этом случае линейная многослойная сеть не является более мощной, чем однословная сеть; рассматриваемые возможности сети могут быть улучшены только введением нелинейности в передаточную функцию нейрона. Говорят, что сеть, использующая сигмои-дальную функцию активации и метод обучения Хэбба, обучается по сигнальному методу Хэбба. В этом случае уравнение Хэбба модифицируется следующим образом:
где ij(t) - сила синапса от нейрона i к нейрону j в момент времени t, OUTi - выходной уровень пресинаптического нейрона равный F(NETi); OUTj - выходной уровень постсинаптического нейрона равный F(NETj).
Метод дифференциального обучения ХэббаМетод сигнального обучения Хэбба предполагает вычисление свертки предыдущих изменений выходов для определения изменения весов. Настоящий метод, называемый методом дифференциального обучения Хэбба, использует следующее равенство:
где ij(t) - сила синапса от нейрона i к нейрону j в момент времени t, OUTi(t) - выходной уровень пресинап-тического нейрона в момент времени t, OUTj(t) - выходной уровень постсинаптического нейрона в момент времени t.
ВХОДНЫЕ И ВЫХОДНЫЕ ЗВЕЗДЫМного общих идей, используемых в искусственных нейронных сетях, прослеживаются в работах Гроссберга; в качестве примера можно указать конфигурации входных и выходных звезд [1], используемые во многих сетевых парадигмах. Входная звезда, как показано на рис. Б.1, состоит из нейрона, на который подается группа входов через синапсические веса. Выходная звезда, показанная на рис. Б.2, является нейроном, управляющим группой весов. Входные и выходные звезды могут быть взаимно соединены в сети любой сложности; Гроссберг рассматривает их как модель определенных биологических функций. Вид звезды определяет ее название, однако звезды обычно изображаются в сети иначе.
Обучение входной звезды
Входная звезда выполняет распознавание образов, т.е. она обучается реагировать на определенный входной вектор Хинина какой другой. Это обучение реализуется путем настройки весов таким образом, чтобы они соответствовали входному вектору. Выход входной звезды определяется как взвешенная сумма ее входов, как это описано в предыдущих разделах. С другой точки зрения, выход можно рассматривать как свертку входного вектора с весовым вектором, меру сходства нормализованных векторов. Следовательно, нейрон должен реагировать наиболее сильно на входной образ, которому был обучен. Процесс обучения выражается следующим образом:
где i - вес входа хi ; хi - i-й вход; - нормирующий коэффициент обучения, который имеет начальное значение 0,1 и постепенно уменьшается в процессе обучения. После завершения обучения предъявление входного вектора Х будет активизировать обученный входной нейрон. Это можно рассматривать как единый обучающий цикл, если « установлен в 1, однако в этом случае исключается способность входной звезды к обобщению. Хорошо обученная входная звезда будет реагировать не только на определенный единичный вектор, но также и на незначительные изменения этого вектора. Это достигается постепенной настройкой нейронных весов при предъявлении в процессе обучения векторов, представляющих нормальные вариации входного вектора. Веса настраиваются таким образом, чтобы усреднить величины обучающих векторов, и нейроны получают способность реагировать на любой вектор этого класса.
Обучение выходной звездыВ то время как входная звезда возбуждается всякий раз при появлении определенного входного вектора, выходная звезда имеет дополнительную функцию; она вырабатывает требуемый возбуждающий сигнал для других нейронов всякий раз, когда возбуждается. Для того чтобы обучить нейрон выходной звезды, его веса настраиваются в соответствии с требуемым целевым вектором. Алгоритм обучения может быть представлен символически следующим образом:
где представляет собой нормирующий коэффициент обучения, который в начале приблизительно равен единице и постепенно уменьшается до нуля в процессе обучения. Как и в случае входной звезды, веса выходной звезды, постепенно настраиваются над множеством векторов, представляющих собой обычные вариации идеального вектора. В этом случае выходной сигнал нейронов представляет собой статистическую характеристику обучающего набора и может в действительности сходиться в процессе обучения к идеальному вектору при предъявлении только искаженных версий вектора.
ОБУЧЕНИЕ ПЕРСЕПТРОНА
В 1957 г. Розенблатт [4] разработал модель, которая вызвала большой интерес у исследователей. Несмотря на некоторые ограничения ее исходной формы, она стала основой для многих современных, наиболее сложных алгоритмов обучения с учителем. Персептрон является настолько важным, что вся гл. 2 посвящена его описанию; однако это описание является кратким и приводится в формате, несколько отличном от используемого в [4]. Персептрон является двухуровневой, нерекуррентной сетью, вид которой показан на рис. Б.З. Она использует алгоритм обучения с учителем; другими словами, обучающая выборка состоит из множества входных векторов, для каждого из которых указан свой требуемый вектор цели. Компоненты входного вектора представлены непрерывным диапазоном значений; компоненты вектора цели являются двоичными величинами (0 или 1). После обучения сеть получает на входе набор непрерывных входов и вырабатывает требуемый выход в виде вектора с бинарными компонентами. Обучение осуществляется следующим образом: 1. Рандомизируются все веса сети в малые величины. 2. На вход сети подается входной обучающий вектор Х и вычисляется сигнал NET от каждого нейрона, используя стандартное выражение
Вычисляется значение пороговой функции актива ции для сигнала NET от каждого нейрона следующим обра зом:
OUTj = 1, если NET больше чем порог j,
OUTj = 0, в противном случае.
Здесь j представляет собой порог, соответствующий нейрону j (в простейшем случае, все нейроны имеют один и тот же порог).
4. Вычисляется ошибка для каждого нейрона посредством вычитания полученного выхода из требуемого выхода:
5. Каждый вес модифицируется следующим образом:
6. Повторяются шаги со второго по пятый до тех пор, пока ошибка не станет достаточно малой.
МЕТОД ОБУЧЕНИЯ УИДРОУ—ХОФФАКак мы видели, персептрон ограничивается бинарными выходами. Уидроу вместе со студентом университета Хоф-фом расширили алгоритм обучения персептрона на случай непрерывных выходов, используя сигмоидальную функцию [5,6]. Кроме того, они разработали математическое доказательство того, что сеть при определенных условиях будет сходиться к любой функции, которую она может представить. Их первая модель - Адалин - имеет один выходной нейрон, более поздняя модель - Мадалин - расширяет ее на случай с многими выходными нейронами. Выражения, описывающие процесс обучения Адалина, очень схожи с персептронными. Существенные отличия имеются в четвертом шаге, где используются непрерывные сигналы NET вместо бинарных OUT. Модифицированный шаг 4 в этом случае реализуется следующим образом: 4. Вычислить ошибку для каждого нейрона, вычитая сигнал NET из требуемого выхода:
МЕТОДЫ СТАТИСТИЧЕСКОГО ОБУЧЕНИЯВ гл. 5 детально описаны статистические методы обучения, поэтому здесь приводится лишь обзор этих методов. Однослойные сети несколько ограничены с точки зрения проблем, которые они могут решать; однако в течение многих лет отсутствовали методы обучения многослойных сетей. Статистическое обучение обеспечивает путь решения этих проблем. По аналогии обучение сети статистическими способами подобно процессу отжига металла. В процессе отжига температура металла вначале повышается, пока атомы металла не начнут перемещаться почти свободно. Затем температура постепенно уменьшается и атомы непрерывно стремятся к минимальной энергетической конфигурации. При некоторой низкой температуре атомы переходят на низший энергетический уровень. В искуственн.ых нейронных сетях полная величина энергии сети определяется как функция определенного множества сетевых переменных. Искусственная переменная температуры инициируется в большую величину, тем самым позволяя сетевым переменным претерпевать большие случайные изменения. Изменения, приводящие к уменьшению полной энергии сети, сохраняются; изменения, приводящие к увеличению энергии, сохраняются в соответствии с вероятностной функцией. Искусственная температура постепенно уменьшается с течением времени и сеть конвергирует в состояние минимума полной энергии. Существует много вариаций на тему статистического обучения. Например, глобальная энергия может быть определена как средняя квадратичная ошибка между полученным и желаемым выходным вектором из обучаемого множества, а переменными могут быть веса сети. В этом случае сеть может быть обучена, начиная с высокой искусственной температуры, путем выполнения следующих шагов:
Подать обучающий вектор на вход сети и вычислить выход согласно соответствующим сетевым правилам.
Вычислить значение средней квадратичной ошибки между желаемым и полученным выходными векторами.
Изменить сетевые веса случайным образом, затем вычислить новый выход и результирующую ошибку. Если ошибка уменьшилась, оставить измененный вес; если ошибка увеличилась, оставить измененный вес с вероятностью, определяемой распределением Больцмана. Если изменения весов не производится, то вернуть вес к его предыдущему значению.
Повторить шаги с 1 по 3, постепенно уменьшая искусственную температуру. Если величина случайного изменения весов определяется в соответствии с распределением Больцмана, сходимость к глобальному минимуму будет осуществляться только в том случае, если температура изменяется обратно пропорционально логарифму прошедшего времени обучения. Это может привести к невероятной длительности процесса обучения, поэтому большое внимание уделялось поиску более быстрых методов обучения. Выбором размера шага в соответствии с распределением Коши может быть достигнуто уменьшение температуры, обратно пропорциональное обучающему времени, что существенно уменьшает время, требуемое для сходимости. Заметим, что существует класс статистических методов для нейронных сетей, в которых переменными сети являются выходы нейронов, а не веса. В гл. 5 эти алгоритмы рассматривались подробно.
САМООРГАНИЗАЦИЯВ работе [3] описывались интересные и полезные результаты исследований Кохонена на самоорганизующихся структурах, используемых для задач распознавания образов. Вообще эти структуры классифицируют образы, представленные векторными величинами, в которых каждый компонент вектора соответствует элементу образа. Алгоритмы Кохонена основываются на технике обучения без учителя. После обучения подача входного вектора из данного класса будет приводить к выработке возбуждающего уровня в каждом выходном нейроне; нейрон с максимальным возбуждением представляет классификацию. Так как обучение проводится без указания целевого вектора, то нет возможности определять заранее, какой нейрон будет соответствовать данному классу входных векторов. Тем не менее это планирование легко проводится путем тестирования сети после обучения. Алгоритм трактует набор из п входных весов нейрона как вектор в п-мерном пространстве. Перед обучением каждый компонент этого вектора весов инициализируется в случайную величину. Затем каждый вектор нормализуется в вектор с единичной длиной в пространстве весов. Это делается делением каждого случайного веса на квадратный корень из суммы квадратов компонент этого весового вектора. Все входные вектора обучающего набора также нормализуются и сеть обучается согласно следующему алгоритму:
Вектор Х подается на вход сети.
Определяются расстояния Dj (в n-мерном пространстве) между Х и весовыми векторами j каждого нейрона. В эвклидовом пространстве это расстояние вычисляется по следующей формуле
где xi - компонента i входного вектора X, ij - вес входа i нейрона j.
Нейрон, который имеет весовой вектор, самый близкий к X, объявляется победителем. Этот весовой вектор, называемый c , становится основным в группе весовых векторов, которые лежат в пределах расстояния D от c .
Группа весовых векторов настраивается в соответствии со следующим выражением:
для всех весовых векторов в пределах расстояния D от c
Повторяются шаги с 1 по 4 для каждого входного вектора.
В процессе обучения нейронной сети значения D и ос постепенно уменьшаются. Автор [3] рекомендовал, чтобы коэффициент в начале обучения устанавливался приблизительно равным 1 и уменьшался в процессе обучения до О, в то время как D может в начале обучения равняться максимальному расстоянию между весовыми векторами и в конце обучения стать настолько маленьким, что будет обучаться только один нейрон. В соответствии с существующей точкой зрения, точность классификации будет улучшаться при дополнительном обучении. Согласно рекомендации Кохонена, для получения хорошей статистической точности количество обучающих циклов должно быть, по крайней мере, в 500 раз больше количества выходных нейронов. Обучающий алгоритм настраивает весовые векторы в окрестности возбужденного нейрона таким образом, чтобы они были более похожими на входной вектор. Так как все векторы нормализуются в векторы с единичной длиной, они могут рассматриваться как точки на поверхности единичной гиперсферы. В процессе обучения группа соседних весовых точек перемещается ближе к точке входного вектора. Предполагается, что входные векторы фактически группируются в классы в соответствии с их положением в векторном пространстве. Определенный класс будет ассоциироваться с определенным нейроном, перемещая его весовой вектор в направлении центра класса и способствуя его возбуждению при появлении на входе любого вектора данного класса. После обучения классификация выполняется посредством подачи на вход сети испытуемого вектора, вычисления возбуждения для каждого нейрона с последующим выбором нейрона с наивысшим возбуждением как индикатора правильной классифи
Похожие работы
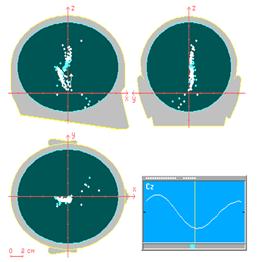
... - это та сложная и разная по физическому проявлению полевая структура, которая окружает пространство, примыкающее к телу человека». Признание факта существования биополя (а не признать это невозможно) означает, что живые организмы создают предпосылки для дистанционных взаимодействий между ними. Однако, для того чтобы признать возможность таких взаимодействий, необходимо наличие способности к ...
... в связи с необходимостью упорядоченного сообщения с высоким приоритетом при радикальном изменении окружающих условий и двунаправленностью каналов. Возможности вычисления путей маршрутизации можно применять при построении интегральных схем и проектирования кристаллов процессоров. Нейрокомпьютеры с успехом применяются при обработке сейсмических сигналов в военных целях для определения коорди
... человеческое внимание устремилось к этой высшей области, которая должна преобразить многие основы жизни. Во времена темного средневековья, наверное, всякие исследования в области парапсихологии кончились бы инквизицией, пытками и костром. Современные нам "инквизиторы" не прочь и сейчас обвинить ученых исследователей или в колдовстве или в сумасшествии. Также мы ...
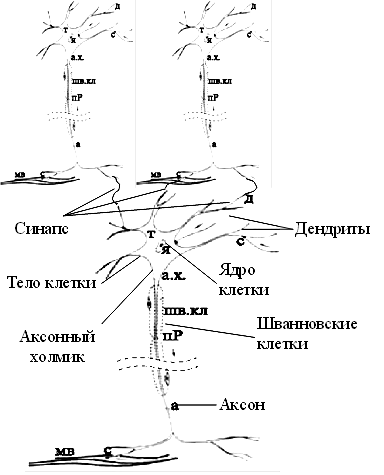
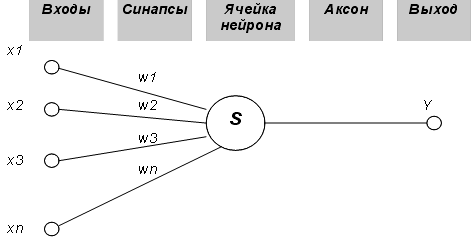

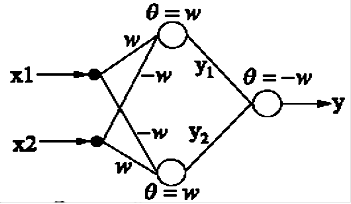
... информацию, находить в ней закономерности, производить прогнозирование и т.д. В этой области приложений самым лучшим образом зарекомендовали себя так называемые нейронные сети – самообучающиеся системы, имитирующие деятельность человеческого мозга. Область науки, занимающаяся построением и исследованием нейронных сетей, находится на стыке нейробиологии, математики, электроники и программирования ...
0 комментариев