Объектно-реляционные базы данных
В БД не могут существовать отдельные собственные части подклассов
Расписание состоит только из шагов операций, порожденных воздействием T, и каждый из этих шагов выполняется точно раз в Sch
NOP 4 NOP ELSE SCTXN ;
VALUE SZ_HDROBJ
OLS 10 GOTOC NCHAN 4 DO_IOBSCC DD -1 OLS -1 OLS LENDAT OLS LENDAT OLS
Навигация
В БД не могут существовать отдельные собственные части подклассов
Объектно-ориентированная СУБД (прототип)
117457
знаков
9
таблиц
4
изображения
1. В БД не могут существовать отдельные собственные части подклассов
2. Каждой части сложного объекта должна соответствовать только одна собственная часть.
В качестве решения они предлагают использование ссылок на классы и каждую собственную часть класса хранить отдельно.
В дипломной работе предлагается вместо хранения ссылок на классы установить для каждого поля свой идентификатор. При наследовании поле сохраняет свой идентификатор. Таким образом, переименование полей не нарушает связь наследования. Переименование может быть автоматическим, например, из-за конфликтов имен полей при множественном наследовании. Аналогично поступает оператор SQL Select, когда в качестве результата запроса ему нужно вернуть несколько столбцов, имеющих одинаковые имена.
Идентификаторы полей уникальны в пределах базы данных, т.е. при объявлении нового поля в классе, идентификатор поля в дальнейшем появляется только в классах-наследниках и только через наследование.
Кроме того, программисты могут использовать для имен полей привычный для них родной язык, другими словами: есть возможность создавать синонимы имен полей.
2.5 Триггеры. Ограничение доступаВ множество поведений любого объекта можно включить два списка с предопределенными именами «PRE_TRIGGERS» и «POST_TRIGGERS». Список PRE_TRIGGERS содержит объекты, обрабатывающие входящее сообщение. Как правило, это объекты-условия. Такой подход называется фильтрацией [20]. Список POST_TRIGGERS содержит объекты, которые проверяют результат воздействия и могут произвести откат. POST_TRIGGERS вызываются по окончании действия транзакции при выполнении операции удаления транзакционных зависимостей.
Все триггеры множеств и последовательностей можно разбить на две классификации: это триггеры, следящие за целостностью множества (последовательности), сохраняя отношение порядка на последовательности, ограничение суммы чисел элементов множества и др.; и следящие за целостностью одного элемента, что соответствует проверке значения на соответствие домену.
Список PRE_TRIGGERS позволяет организовать ограничение доступа, фильтруя сообщения, посланные объектом, ктороый не имеет полномочий для выполнения команды, содержащейся в сообщении.
Список POST_TRIGGERS позволяет исключить часть данных из результата выполненной объектом операции, создав тем самым локальное пользовательское представление.
Впрочем, тема безопасности заслуживает отдельного рассмотрения. Как, например, в [9] и [18].
2.6 Действие (knowhow)
Действие представляет собой объект типа “строка”, хранящий текст ДССП-процедуры. Ссылка на действие может хранится в поле OBJKH объекта, через который и происходит вызов действия. Алгоритм выбора выполняемого действия рассматривается ниже. В интерфейсах объектов указаны идентификаторы объектов, которые в поле OBJKH хранят идентификатор действия. Значения этих объектов являются именем действия. Наиболее удобно использовать для этой цели строковые объекты. Использование поля OBJKH позволяет выполнять одно и то же действие для различных методов различных объектов.
При вызове действия с идентификатором OIDKH делается вызов слова с именем kh$<OIDKH>. Например, для объекта с OIDKH=0x00000DFC это будет KH$00000DFC. Если возникает ситуация EXERR, значит слово в словаре отсутствует и подлежит компиляции. Для компиляции текст действия дополняется префиксом “: KH$<oid> ” и суффиксом “ ;”, после чего компилируется командой TEXEC и выполняется. Словарь действий называется $KH_VOC.
При изменении текста метода необходимо полностью очистить словарь ДССП $KH_VOC, хранящий откомпилированные действия, поскольку эти действия содержат в своем коде абсолютные ссылки на прежнюю откомпилированную версию действия. Впрочем, эта процедура очистки словаря выполняется лишь при переопределении текста действия, что бывает достаточно редко.
2.7 Объекты-поведенияВ отсутствии классов, хранить методы в каждом объекте было бы слишком накладно. Вынесение правил поведения в отдельный объект позволяет уменьшить затраты на хранение объектов-данных. Математическая модель ООБД в [17], также разделяет данные и поведения, что дополнительно дает возможность переиспользовать поведение другого объекта.
Объект-поведение представляет собой множество объектов-методов, которое и называется интерфейсом объекта.
При посылке на вход произвольного объекта OID2 сообщения OID1 (которое тоже является объектом), сначала проверяется, содержится ли OID1 в интерфейсе объекта OID2 (проверка идентичности). Если да, то выполняется действие объекта OID1, иначе сравниваются значения OID1 и объектов интерфейса (проверка эквивалентности). Если соответствие найдено, выполняется действие, указанное в найденном в интерфейсе объекте.
2.8 Принципы взаимодействия объектовЕсть два основных способа управления объектами:
· Посылка сообщений
· Алгебра объектов
·
Определения операций Select и Pickup алгебры объектов можно найти в [17]. Здесь оно не рассматривается по той причине, что является надстройкой над управлением посылкой сообщений и описывается через механизм посылки сообщений. То есть операции алгебры объектов могут быть заданы через операции посылки сообщений, без исправления структуры СУБД. Полная алгебра объектов является замкнутой и состоит из следующих операций: Select s, Pickup d, Apply r, Expression Apply l, Project p, Combine c, Union È, Interselect Ç, Subtract -, Collapse v, Assimilate a. Объектная алгебра более выразительна, чем реляционная, поскольку поддерживает полиморфность. Оператор Select, например, может работать с любыми видами операндов, а не только с множествами.
Согласно [17], любое сообщение в системе является объектом. Любой объект может иметь связанное с ним действие (knowhow), или не иметь его.
Алгоритм определения метода для выполненияПри посылке объекта проверяется, находится ли идентификатор объекта-сообщения в интерфейсе объекта-получателя. Если да, то выполняется knowhow, связанное с этим идентификатором. Если нет – проверяется, совпадает ли значение объекта-сообщения со значением какого-либо метода из интерфейса объекта-получателя. Если да, то выполняется связанное с этим методом действие. Иначе возвращается объект fail.
Параметры методовНабор_параметров (Blackboard) представляет собой множество меток, аргументных пар { (L1, arg1), … , (Ln, argn) }. Li ÎA, argi ÎO для 1 £ i £ n и "i, j Î 1,…,n : i ¹ j Þ Li ¹ Li.
Впрочем, базовые методы также используют передачу параметров через стек, как более эффективный способ программирования.
Синтаксис посылки сообщенияВоздействие(Набор_параметров) ~> Получатель. Объект, называемый Воздействие (Invoker), является сообщением (message) и посылается к другому объекту, названному Получателем (Reciver), используя Набор_параметров, предоставляющий необходимые аргументы. Если параметры в Наборе_параметров отсутствуют, то можно записать короче: Воздействие ~> Получатель. Посланное сообщение всегда возвращает объект, называемый Результат (Result).
Посылка простого сообщенияПусть B – Набор_параметров и m и r – два объекта в O.
Примитивные взаимодействия(1) m(B) ~> fail º fail; fail(B) ~> r º fail;
(2) m(B) ~> null º null; null(B) ~> r º null;
(когда m¹ fail)
(3) m(B) ~> same º same; same(B) ~> r º r;
(когда m¹ fail и m¹ null)
При совпадении идентификатора(4) Если существует метод x из r такой, что x º m и sig(x) = (A1,c1) ´ …´ (An,cn)® cr и {(A1,a1) ´ …´ (An,an)} ÍB и FID каждого поля сi присутствует в ai (в терминах ОО-программирования: ci является предком по значению для ai), тогда
m(B) ~> r º r.kh(x)(A1 : a1, … , An : an )
иначе проверяется совпадение значения.
При совпадении значения(5) Если существует метод x в r или его объектах-учителях (объектов, от которых наследуется поведение) такой, что x » m и sig(x) = (A1,c1) ´ …´ (An,cn)® cr и {(A1,a1) ´ …´
´ (An,an)}ÍB и FID каждого поля сi присутствует в ai, тогда
m(B) ~> r º r.kh(x)(A1 : a1, … , An : an )
иначе
(6) Если r является атомарным, то m(B) ~> r º fail.
Иначе m(B) ~> r является комплексным сообщением (complex message sending), обладает сложной структурой.
Комплексные сообщенияЕсли Воздействие является объектом-агрегатом, то
s(B) ~> o º null, если s=[ ]
s(B) ~> o º [A1 : s1(B) ~> o1, …, An : sn(B) ~> on], если s=[A1 : s1, …, An : sn]
где oj » o, ojнеº o) и orf(oi) Ç orf(o) = Æ для j = 1,..,n и для любого i, j Î [1,..,n], если i ¹ j тогда ojнеº o и orf(oi) Ç orf(oj) = Æ (т.е. o1,…,on являются глубокими копиями объекта-получателя o).
Если Воздействие является объектом-условием, то
s(B) ~> o º s.then(B) ~> o, если s.if(B) Ï {False, fail}
s(B) ~> o º s.else(B) ~> o, иначе.
Где s.if, s.then, s.else обозначение if-части, then-части и else-части s соответственно.
Если Воздействие является объектом-множеством, то
s(B) ~> o º null, если s={ }
s(B) ~> o º s1(B) ~> o, если s={s1}
s(B) ~> o º s’(B) ~> o, s’= s – {x} после x(B) ~> o
где x – произвольно выбранный элемент из множества s.
Если Воздействие является объектом-списком, то
s(B) ~> o º null, если s=( )
s(B) ~> o º sn(B) ~>(… ~>( s2(B) ~>( s1(B) ~> o))…) где s = (s1, s2, …, sn)
Семантика дробящейся посылкиПусть B – Набор_параметров и пусть s, oÎO. Тогда оператор дробящейся посылки, обозначаемый ~1> определяется следующим образом:
Таблица 1: Семантика дробящейся посылки
| Условие | S(B) ~1> o º |
| s(B) ~> o неº fail | s(B) ~> o |
| AGG(o) & o = [A1 : o1, …, An : on] | [A1 : s(B) ~> o1, …, An : s(B) ~> on] |
| BIO(o) & o.if неº null | s(B) ~> o.then |
| BIO(o) & o.if º null | s(B) ~> o.else |
| SET(o) & o = {o1,…,on} | {s(B) ~> o1, …, s(B) ~> on} |
| SEQ(o) & o = (o1,…,on) | (s(B) ~> o1, …, s(B) ~> on) |
| Иначе | Fail |
Согласованное управление является важным аспектом управления транзакциями в СУБД. В обычных базах данных, транзакции являются независимыми атомарными воздействиями, которые выполняются изолированно, в том числе от результатов выполнения других транзакций. Однако, для повышения производительности, для некоторых транзакций составляется расписание выполнения. Механизм согласованного управления обеспечивает корректное выполнение этого множества транзакций, в том числе продолжительных.
В отличие от традиционных баз данных, исследования в области согласованного управления для объектно-ориентированных баз данных были ограничены. Это в значительной мере связано с уникальностью требований к объектно-ориентированным базам данных. Природа транзакций в таких приложениях, как CAD, мультимедийные базы данных, является весьма различной. Эти приложения характеризуются совместно выполняемыми продолжительными транзакциями с обобщающими операциями. Поскольку результат выполнения транзакции может быть основан на промежуточных результатах других транзакций, критерий сериализуемости не может быть применим непосредственно в этом случае.
Сериализуемость состоит в том, что результат совместного выполнения транзакций эквивалентен результату их некоторого последовательного исполнения, называемого планом выполнения транзакций. Это обеспечивает реальную независимость пользователей. Существует теорема Эсварана о двухфазной блокировке: если все транзакции подчиняются протоколу двухфазной блокировки, то для всех возможных существующих графиков запуска (порядков выполнения транзакций) существует возможность упорядочения. Эта тема хорошо освещена в [9] и [22].
В зависимости от организации протокола совместного выполнения транзакций он является пессимистическим или оптимистическим.
Пессимистический метод ориентирован на ситуации, когда конфликты возникают часто. Конфликты распознаются и разрешаются немедленно при их возникновении. Оптимистический метод основан на том, что результаты всех операций модификации базы данных сохраняются в рабочей памяти транзакций. Реальная модификация базы данных производится только на стадии фиксации транзакции. Тогда же проверяется, не возникают ли конфликты с другими транзакциями.
Протокол согласованного управления СУООБД обеспечивает:
· Управление совместно выполняющимися продолжительными транзакциями
· Усиливает корректность критерия другого, чем сериализуемость
· Учитывает объектную ориентированность данных
· Допускает обобщение операций (не только чтение и запись)
Подробное описание и теоретическое обоснование протокола согласованного управления для ООБД содержится в [19].
3. Разработка структуры СУ 3.1 Положение дел в области интероперабельности системРост мощности программных приложений привел к выделению нового архитектурного слоя – информационной архитектуры систем, определяющей способность совместного использования, совместной деятельности (в дальнейшем будет использоваться термин "интероперабельность") компонентов (информационных ресурсов) для решения задач [21]. Этот слой расположен обычно над сетевой архитектурой, являющейся необходимой предпосылкой такой совместной деятельности компонентов, обеспечивающей их взаимосвязь.
Деятельность по созданию технологии интероперабельных систем охватывает весь мир. Наиболее существенный вклад в принимаемые идеологические, архитектурные и технологические решения интероперабельных систем вносит Object Management Group (OMG) (http://www.omg.org) - крупнейший в мире консорциум разработки программого обеспечения, включающий свыше 600 членов - компаний - производителей программного продукта, разработчиков прикладных систем и конечных пользователей. Целью OMG является создание согласованной информационной архитектуры, опирающейся на теорию и практику объектных технологий и общедоступные для интероперабельности спецификации интерфейсов информационных ресурсов. Эта архитектура должна обеспечивать повторное использование компонентов, их интероперабельность и мобильность, опираясь на коммерческие продукты.
Другие организации, которые работают в кооперации с OMG, например, с целью доведения результатов OMG до официальных стандартов в различных аспектах, включают: ANSI, ISO, CCITT, ANSA, X/Open Company, Object Database Management Group (ODMG).
Развитие возможностей информационных систем и Internet и желание обеспечить их взаимодействие между собой, привело к необходимости разработки единого протокола взаимодействия. Для этого была создана OMG, которая и занялась этим вопросом. В результате была разработана эталонная модель, которая определяет концептуальную схему для поддержки технологии, удовлетворяющей техническим требованиям OMG. Она идентифицирует и характеризует компоненты, интерфейсы и протоколы, составляющие Архитектуру Управления Объектами OMG (Object Management Architecture (OMA)), не определяя, впрочем, их детально.
Согласованная с OMA прикладная система состоит из совокупности классов и экземпляров, взаимодействующих при помощи Брокера Объектных Заявок (Object Request Broker (ORB)). Объектные Службы (Object Services) представляют собой коллекцию служб, снабженных объектными интерфейсами и обеспечивающих поддержку базовых функций объектов. Общие Средства (Common Facilities) образуют набор классов и объектов, поддерживающих полезные во многих прикладных системах функции. Прикладные объекты представляют прикладные системы конечных пользователей и обеспечивают функции, уникальные для данной прикладной системы.
CORBA (Common Object Request Broker Architecture) определяет среду для различных реализаций ORB (Object Request Broker), поддерживающих общие сервисы и интерфейсы. Это обеспечивает переносимость клиентов и реализаций объектов между различными ORB.
Брокер Объектных Заявок обеспечивает механизмы, позволяющие объектам посылать или принимать заявки, отвечать на них и получать результаты, не заботясь о положении в распределенной среде и способе реализации взаимодействующих с ними объектов.
Объектные Службы:
· Служба Уведомления Объектов о Событии (Event Notification Service).
· Служба Жизненного Цикла Объектов (Object Lifecycle Service).
· Служба Именования Объектов (Name Service).
· Служба Долговременного Хранения Объектов (Persistent Object Service).
· Служба Управления Конкурентым Доступом (Concurrency Control Service).
· Служба Внешнего Представления Объектов (Externalization Service).
· Служба Объектных Связей (Relationships Service).
· Служба Транзакций (Transaction Service).
· Служба Изменения Объектов (Change Management Service).
· Служба Лицензирования (Licensing Service)/
· Служба Объектных Свойств (Properties Service).
· Служба Объектных Запросов (Object Query Service).
· Служба Безопасности Объектов (Object Security Service).
· Служба Объектного Времени (Time Service).
Общие Средства заполняют концептуальное пространство между ORB и объектными службами с одной стороны, и прикладными объектами с другой. Таким образом, ORB обеспечивает базовую инфраструктуру, Объектные Службы – фундаментальные объектные интерфейсы, а задача Общих Средств – поддержка интерфейсов сервисов высокого уровня. Общие Средства подразделяются на две категории: "горизонтальные" и "вертикальные" наборы средств. "Горизонтальный" набор средств определяет операции, используемые во многих системах, и не зависящие от конкретных прикладных систем. "Вертикальный" набор средств представляет технологию поддержки конкретной прикладной системы (вертикального сегмента рынка), такого, как здравоохранение, производство, управление финансовой деятельностью, САПР и т.д.
· Средства поддержки пользовательского интерфейса (User Interface Common Facilities)
· Средства управления информацией (Information Management Common Facilities)
· Средства управления системой (System Management Common Facilities)
· Средства управления задачами (Task Management Common Facilities)
· Вертикальные общие средства (Vertical Common Facilities)
· Вертикальные общие средства предназначены для использования в качестве стандартных для обеспечения интероперабельности в специфических прикладных областях.
· Поддержка интероперабельности брокеров в стандарте CORBA 2.0
О роли СУООБД в архитектуре OMG можно прочесть в [13].
На основе анализа вышеизложенного, были выбраны в качестве основания следующие базовые службы СУООБД:
· Служба Долговременного Хранения Объектов – управление хранением объектов
· Служба Управления Конкурентным Доступом и Служба Транзакция – объединены вместе протоколом согласованного управления.
· Служба Изменения Объектов – управление журнализацией изменений
3.2 Менеджер памяти
Менеджер памяти является ключевым модулем системы.
Его наличие позволяет
· Абстрагироваться от особенностей обращения к различным видам памяти.
· Создавать сколь угодно вложенные друг в друга структуры данных.
· Иметь единый интерфейс на каждом уровне вложенности.
· Организовать кэширование объектов
В состав менеджера памяти входит 3 системы управления:
1. Система управления виртуальной памятью
2. Система управления каналами
3. Система управления кэшированием объектов
3.3 Виртуальная память и каналыВиртуальная память представляет собой непрерывную для пользователя, с ней работающего, область памяти, которая может быть вложена в другую виртуальную память. Виртуальная память состоит из сегментов, связанных между собой в двунаправленную цепь. Каждому сегменту известно его положение относительно нижнего логического уровня. Работа с виртуальной памятью происходит через канал, выделенный для нее. Канал – это набор характеристик описывающих: где расположена виртуальная память, и в каком ее месте мы находимся. Количество каналов ограничено, поэтому канал выделяется той виртуальной памяти, которая нужна в данный момент. Система имеет набор каналов, которые могут иметь ссылку на виртуальную память, либо быть незанятыми. Первые 5 каналов – это базовые каналы, отображенные на физические носители (оперативная память, файл). Вторые 5 каналов – каналы виртуальной памяти, хранящие каталоги объектов. Остальные каналы предназначены для работы с объектами. Все каналы основываются на каких-либо других каналах, образуя, в общем случае, 5 независимых деревьев. Корень – один из базовых каналов (0..4). Одна и та же виртуальная память не может быть загружена в два канала. При переходе от верхнего канала к нижнему выполняется трансляция адреса.
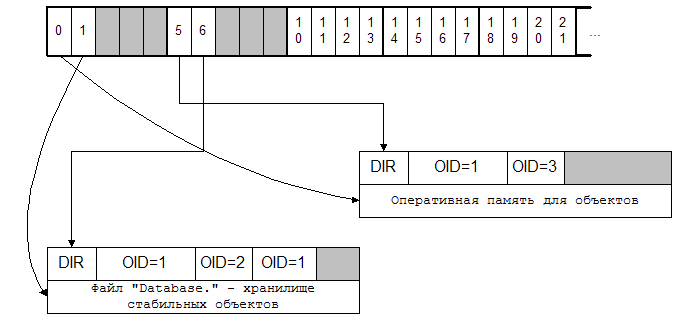
Рис 3: Связь каналов с хранилищами объектов
Таблица 2: Параметры канала
| Параметр канала | Семантика |
| NCHAN | Номер текущего канала |
| LOWCH | Нижний канал; в него вложен этот канал |
| CHGCTX | Признак изменения данных заголовка фрагмента |
| TEKADR | Текущая позиция для чтения/записи |
| SYNCADDR | Адрес начала заголовка текущего сегмента в нижнем канале |
| TEKADR0 | Позиция, соответствующая началу данных фрагмента |
| PREDADDR | Адрес заголовка предыдущего фрагмента (–1, если его нет) |
| NEXTADDR | Адрес заголовка следующего фрагмента (–1, если его нет) |
| BUSYLEN | Занятая длина |
| LEN | Выделенная длина |
Таблица 3: Операции доступа к данным виртуальной памяти
| Операция | Семантика (все операции работают с текущим каналом) |
| IBS | Чтение байта из канала |
| OBS | Запись байта в канал |
| GOTO | Переход по адресу в канале |
| @GOTO | Переход по смещению в канале |
| UPSIZE | Выделить доп. память в конце канала и встать на ее начало |
| DEFRAG | Сделать виртуальную память непрерывной на уровне нижнего канала (т.е. однофрагментной) |
Начало виртуальной памяти соответствует нулевому значению TEKADR. Доступ осуществляется через операции позиционирования (GOTO и @GOTO), чтения байта (IBS) и записи байта (OBS). Остальные функции, реализуются через них (например, чтение длинного слова). К памяти может быть применена функция UPSIZE с аргументом, содержащим необходимое количество байт для выделения. Память может гарантированно выделяться до заполнения всей выделенной длины. При исчерпании выделенной длины, делается запрос к нижестоящему уровню о выделении дополнительной памяти. Если такой запрос применяется к каналу ниже 5-го, соответствующего дисковому файлу, файл увеличивается в размере, если его выделенная длина исчерпана. Если увеличение размера файла невозможно из-за нехватки дискового пространства, то, в случае невозможности выделения памяти за счет упаковки, возбуждается ситуация NOMEMORY. При попытке доступа за пределы определенной виртуальной памяти (например, чтение после расположения данных), возникает ситуация OUTDATA.
3.4 Система управления кэшированием объектовСамостоятельное кэширование данных – неотъемлемая черта любой СУБД. Кэш состоит из двух частей: очереди кэшируемых объектов и памяти для кэшируемых объектов. Память для кэшируемых объектов – это оперативная память, в которую объект загружается. В этой памяти могут располагаться только те объекты, идентификаторы которых находятся в очереди кэшируемых объектов. Удаляемый из очереди объект выгружается в дисковую память. В данной дипломной работе все создаваемые объекты являются стабильными (Persistent), т.е. они обязательно сохраняются на диске и могут быть использованы после открытия базы данных для использования.
Задача управления кэшированием объектов подобна задаче управления памятью в операционной системе. В операционной системе для организации процесса обмена между оперативной и внешней памятью информация представлена набором сегментов (блоки переменной длины) или страниц (блоки фиксированной длины). Способ управления памятью называется алгоритмом замещения, который определяет состав сегментов или страниц в более быстродействующей основной памяти. Таким образом, частота обращений к внешней памяти, а, следовательно, и быстродействие двухуровневой памяти (уровень внешней памяти и уровень оперативной памяти) в целом, существенно зависят от выбранного алгоритма замещения. Наибольшее распространение получила страничная структура памяти.
В дипломной работе роль страницы играет объект. Минимальную частоту обращений к ВП (внешней памяти) давал бы алгоритм, замещающий те объекты в ОП (оперативной памяти), обращение к которым в будущем произойдет через максимально долгое время. Однако реализовать такой алгоритм невозможно, поскольку заранее неизвестна информация о будущих обращениях к объектам программой.
Наиболее популярны следующие пять алгоритмов замещения:
1. Случайное замещение (СЗ): с равной вероятностью может быть замещен любой объект,
2. Раньше пришел – раньше ушел (РПРУ, или FIFO): замещается объект дольше всех находившийся в оперативной памяти,
3. Замещение наиболее давно использовавшегося объекта (НДИ),
4. Алгоритм рабочего комплекта (РК): хранятся в памяти только те объекты, к которым было обращение в течении времени t, назад от текущего момента,
5. Лестничный алгоритм (ЛЕСТН): в списке объектов при обращении к объекту он меняется местами с объектом, находящемся ближе к голове списка. При обращении к отсутствующему в ОП объекту объект, находящийся в последней позиции вытесняется.
Для алгоритма замещения желательно, чтобы он обладал двумя отчасти противоречивыми свойствами: с одной стороны, он должен сохранять в ОП объекты к которым обращения происходят наиболее часто, с другой – быстро обновлять содержимое ОП при смене множества рабочих объектов.
Например, алгоритм РПРУ эффективен только в отношении быстрого обновления ОП, он не выделяет в списке объектов объекты, обращения к которым происходят чаще, чем к остальным. Алгоритм НДИ также позволяет быстро обновлять содержимое ОП. Однако последовательность одиночных обращений достаточной длины к объектам, находящимся во ВП, вытеснит из ОП все объекты, к которым, в среднем, обращения происходят чаще всего.
В [1] описывается класс многоуровневых алгоритмов замещения c, которые позволяют решить эту проблему. Они зависят от конечного числа параметров и при адаптивном подборе этих параметров соединяют свойство быстрого обновления части ОП со свойством сохранения в ОП тех объектов, которые наиболее часто запрашиваются.
В дипломной работе решено использовать алгоритм замещения из класса c, при следующих параметрах: лимит времени нахождения объекта в ОП отсутствует, размеры подсписков на всех уровнях одинаковы, параметр l=1 (это соответствует алгоритму замещения НДИ для объектов всех подсписков; если i – положение объекта в подсписке, и i £ l, то при обращении к нему применяется алгоритм РПРУ, иначе НДИ).
Неэффективным является подход простого освобождения от объектов, которые стоят в конце списка кэша, поскольку они могут быть малы по размеру, а требуется загрузить объект, который занимает значительное количество памяти. В этом случае, пришлось бы ради одного объекта выгружать значительное количество других. Что привело бы к значительным потерям времени при их повторной загрузке.
Для определения подмножества объектов кэша, подлежащих вытеснению, можно применить алгоритм решения задачи о рюкзаке. Если бы все объекты имели одинаковую длину, без этого можно было бы обойтись. Хотя алгоритм решения задачи о рюкзаке NP-сложен, решение можно компактно записать в виде рекурсивного алгоритма, находящего решение за счет применения принципа динамического программирования Беллмана. Такой способ наиболее эффективен, когда размер кэша составляет 32 объекта, поскольку множество выбранных объектов можно представить битовыми полями в длинном слове. При большем размере кэша возрастают потери памяти и быстродействия, и возникает вопрос о месте расположения данных промежуточных вызовов. Рекурсивный вызов в среде ДССП требует малых затрат ресурсов, а время расчета окупается за счет времени обмена с внешней памятью, работа с которой много медленнее, чем с оперативной.
3.5 Система управления журнализацией и восстановлениемЖурнализация предназначена во-первых, для обеспечения возможности отката некорректных действий транзакций, и, во-вторых, для восстановления базы данных после аппаратного сбоя. В ООБД журнализацию можно проводить на трех уровнях: инфологическом, даталогическом и физическом. На инфологическом уровне журнал фиксирует сообщения, циркулирующие в системе. На даталогическом уровне фиксируется какие примитивы были вызваны на выполнение сообщениями. На физическом уровне фиксируются низкоуровневые операции: по какому адресу в какой виртуальной памяти производилась запись, как изменились границы виртуальной памяти.
Обычные БД хранят мгновенный снимок модели предметной области. Любое изменение в момент времени t некоторого объекта приводит к недоступности состояния этого объекта в предыдущий момент времени. Интересно, что при этом в большинстве развитых СУБД предыдущее состояние объекта сохраняется в журнале изменений, но возможность доступа к этим данным для пользователей закрыта.
Для журнализации избран подход, примененный в СУБД Postgres, разработанной в университете г.Беркли, Калифорния под руководством М.Стоунбрейкера, как наиболее простой в реализации и предоставляющий полезные возможности, недоступные в базах данных с обычным типом журнализации (см. [23]). В этой системе, во-первых, не ведется обычная журнализация изменений базы данных, и мгновенно обеспечивается корректное состояние базы данных после перевызова системы с утратой состояния оперативной памяти. Во-вторых, система управления памятью поддерживает исторические данные. Запросы могут содержать временные характеристики интересующих объектов. Реализационно эти два аспекта связаны.
СУБД, имеющие такой вид журнализации, называются темпоральными СУБД. Основной тезис темпоральных систем состоит в том, что для любого объекта данных, созданного в момент времени t1 и уничтоженного в момент времени t2, в БД сохраняются (и доступны пользователям) все его состояния во временном интервале [t1, t2). Система не только хранит информацию о прошлых состояниях объекта, но и предоставляет пользователю доступ к ней через язык запросов.
Т.е. журнал состоит из меток времен и значений объектов. СУБД POSTGRES является экспериментальной и, в частности, предполагается, что она функционирует на вычислительной аппаратуре, оснащенной статической оперативной памятью, не теряющей информации при отключении внешнего питания. Впрочем, затраты на статическую память компенсируются быстродействием СУБД и дополнительными возможностями, приобретаемыми при таком подходе, а именно: возможность получить значение объекта в произвольный момент времени.
Вообще говоря, каждый объект в системе состоит из трех частей: Заголовка объекта, данных и истории. В заголовке объекта имеется поле VALUE, которое содержит ссылку на начало расположения внутри объекта данных о его состоянии. Объект, с которым пользователь хочет работать, автоматически загружается системой в кэш, где ему выделяются 4 канала:
1. Канал объекта в кэше
2. Канал объекта на диске
3. Канал данных объекта в кэше
4. Канал истории изменений объекта на диске
Прикладной программист не работает напрямую с каналами. С каналами работают примитивы доступа к содержимому объекта. Прикладной программист работает с объектами только через их идентификаторы. А идентификаторам объектов ставятся в соответствие каналы в системе кэширования объектов.
3.6 Принципы реализации механизма согласованного управления Область действия операцииКаждый объект обладает поведением, реализуемым через методы (операции). Если операция работает только с внутренними данными объекта, то она является локальной, если же она посылает сообщения другим объектам, то – глобальной. Посланное к другому объекту сообщение порождает на нем выполнение соответствующей операции. Через транзитивное замыкание можно представить процесс порождения отношением предок – потомок.
Областью действия операции на объекте являются:
Данные состояния объекта, входные параметры операции, системные объекты, а также все объекты, обладающие определенным поведением, если это поведение является объектом, над которым выполняется операция.
Воздействие операцииВсе воздействия любой операции на объекте, попадают под одну из четырех категорий: запрос, создание, модификация, удаление. Для каждой операции на объекте определяются соответствующие множества.
Множество запросов QS(opi(O)) определяется рекурсивно как QS(opi(O)) = LocalQS(opi(O)) È GlobalQS(opi(O)), где
· LocalQS = Æ, если нет собственных ivj из O "запрошенных" операцией opi. {O}, иначе.
· GlobalQS =
{Ogq | opi , посылает сообщение к Os для выполнения метода opj, где OsÎ Scope(opi(O)), и OgqÎQS(opj(Os))}.
Аналогично определяются можества создания модификации и удаления операции opi на объекте O.
Множество замен определяется как объединение множеств создания, модификации и удаления. Конфликт операций – выполнение одного из следующих условий:
1. US(opi(O)) Ç US(opj(O')) ¹ Æ
2. QS(opi(O)) Ç US(opj(O')) ¹ Æ
3. US(opi(O)) Ç QS(opj(O')) ¹ Æ
Пользовательские транзакции можно рассматривать как операции над специальным объектом базы данных.
Пользовательские операции могут быть разбиты на ряд шагов, каждый из которых выполняет некоторую логическую единицу работы. Шаги эти также можно считать едиными операциями. Такое разбиение позволяет ввести понятие точки разрыва. Точка разрыва ставится между двумя шагами на одном уровне любой операции.
Объектно-ориентированное расписаниеДля увеличения производительности СУБД, некоторые операции могут взаимодействовать друг с другом в базе данных. Некоторые из этих операций могут выполняться на одном объекте. Совместное выполнение многих операций (псевдопараллельность) может приводить к произвольному чередованию операций (или их шагов). Порядок чередования называется объектно-ориентированным расписанием. Так как "пользовательские транзакции" являются только операциями на специальном объекте, ОО-расписание можно определить на этом объекте как пару (S,<расп), где S – множество всех шагов (как локальных, так и глобальных), а <расп – частичный порядок на множестве шагов в S. Глобальные шаги в S – это результат обращения операций к другим объектам, и шаги основанные на результате этих обращений также включаются в расписание.
Различные пользовательские транзакции могут вызвать один и тот же метод, и одновременно будут выполняться несколько копий одной и той же операции.
В работе [19] утверждается, что расписание Sch для T на специальном объекте является корректным объектно-ориентированным расписанием, если:
Похожие работы
... ); Pisa в университетах Глазго и Св. Эндрю (Universities of Glasgo and St. Andrew). Среди исследовательских институтов, в которых существовали мощные группы, ориентированные на исследования в области объектно-ориентированных баз данных, входили OGI (Oregon Graduate Institute ), MCC (Microelectronics and Computer Technology Corporation ) и французский исследовательский центр INRIA . На базе ...
... ООП. Сейчас язык С++ является языком публикаций по вопросам ООП. Практикум на С/С++:Фактически С++ содержит 2 языка: Полностью включает низкоуровневый Си, поддерживающий конструкции СП, и, собственно, С++ (Си с классами) – язык объектно-ориентированного программирования (ООП). Мы находимся сейчас на технологической ступени структурного программирования, поэтому начинаем с Си: Знакомство с С, ...
... СУБД; можно управлять распределением областей внешней памяти, контролировать доступ пользователей к БД и т.д. в масштабах индивидуальной системы, масштабах ограниченного предприятия или масштабах реальной корпоративной сети. В целом, набор серверных продуктов одиннадцатого выпуска компании Sybase представляет собой основательный, хорошо продуманный комплект инструментов, которые можно ...
... , а иногда и невозможным. Недостатки MOLAP-модели: · Многомерные СУБД не позволяют работать с большими базами данных. · Многомерные СУБД по сравнению с реляционными очень неэффективно используют внешнюю память. В подавляющем большинстве случаев информационный гиперкуб является сильно разреженным, а поскольку данные хранятся в упорядоченном виде, неопределенные значения ...
0 комментариев