Объектно-реляционные базы данных
В БД не могут существовать отдельные собственные части подклассов
Расписание состоит только из шагов операций, порожденных воздействием T, и каждый из этих шагов выполняется точно раз в Sch
NOP 4 NOP ELSE SCTXN ;
VALUE SZ_HDROBJ
OLS 10 GOTOC NCHAN 4 DO_IOBSCC DD -1 OLS -1 OLS LENDAT OLS LENDAT OLS
Навигация
Расписание состоит только из шагов операций, порожденных воздействием T, и каждый из этих шагов выполняется точно раз в Sch
Объектно-ориентированная СУБД (прототип)
117457
знаков
9
таблиц
4
изображения
1. Расписание состоит только из шагов операций, порожденных воздействием T, и каждый из этих шагов выполняется точно раз в Sch.
2. В расписании сохраняется отношение порядка выполнения шагов операций для всех транзакций.
3. Если порожденная от T транзакция имеет две операции над одним объектом, находящиеся в методе на одном уровне вложенности, то времена выполнения этих операций не пересекаются; все вызванные подоперации одной операции завершаются до начала выполнения другой операции. Очередность выполнения задается системой управления транзакциями.
Таким образом, корректное объектно-ориентированное расписание гарантирует, что спецификации точек разрыва для операций будут соблюдаться должным образом, т.е. другие кооперативные (взаимодействующие) операции не могут видеть никаких промежуточных результатов, кроме описанных спецификацией точки разрыва.
Этот критерий корректности заменяет собой критерий сериализуемости в ООБД.
Эквивалентность расписанийДля определения эквивалентности расписаний: вводится следующее правило: если результат одной операции получается на основе результата другой операции, то в любом корректном расписании порядок следования конфликтующих операций одинаков. Если конфликта нет, то допустимым является любой порядок следования операций. Если при этом получаются разные результаты, то каждый из них, тем не менее, является правильным. Этот парадокс можно проиллюстрировать на следующем примере:
Положим, имеются две операции: увеличить сумму на счете вдвое и увеличить сумму на счете на 10%. Очевидно, что результат будет разным в зависимости от порядка следования операций. Но, поскольку операции независимы, в любом случае он считается правильным.
Если объекты, которые доступны различным транзакциям, заранее известны, задача механизма согласованного управления относительно проста. Априорная информация облегчает статичное определение конфликтующих операций; следовательно, стратегия управления чередованием операций может быть сформулирована. Однако, позднее связывание (late binding), характерная черта объектно-ориентированных систем, приводит к трудности предварительного определения объектов доступа. При отсутствии такого знания, одним из выходов является блокировка некоторых транзакций до тех пор, пока вид объектов доступа не станет известен. Однако, для продолжительных (long-duration) транзакций (например, запись звука в мультимедийной БД) , такая блокировка может привести к слишком большому времени ожидания.
Протокол использует оптимистический подход, при котором априорные знания недоступны. Когда протокол использует оптимистичный подход, некорректное выполнение обнаруживается только когда все объекты доступа известны. При обнаружении некорректного чередования, для одной или более транзакций (операций) должен быть произведен обрыв (aborted) или откат (rolled back) к моменту перед некорректным выполнением. Это хорошо зарекомендовавший себя подход, но для продолжительных транзакций откат или обрыв приведет к значительной потери системных ресурсов, которые были использованы и времени, потраченного на бесполезные вычисления.
Одним из методов решения этой проблемы состоит в том, чтобы ограничить сумму откатов. Для этого используется идея точек проверки, ограничивающих глубину отката. Если происходит событие приводящее к обрыву или откату, эффект, произведенный действиями за точкой проверки должен быть отменен. Это минимизирует потери ресурсов и в то же время сокращает продолжительные ожидания.
Спецификация точки проверкиИдея точки проверки используется для минимизации глубины отката в случае обрыва транзакций. Эти точки могут быть описаны пользователем. Точки проверки связаны с операциями на объектах и могут быть описаны как шаг операции. Нет необходимости иметь спецификацию точки проверки для каждого объекта в системе. Однако пользователь может описать точки проверки в некоторых операциях на некоторых объектах, так, что каждая точка представляет логическую единицу работы. Идея установки точек проверки предоставляет базе данных возможность определять, находится ли она в согласованном состоянии. Точка проверки служит как механизмом синхронизации, так и заботой о связности базы данных. Любая пользовательская транзакция может иметь зависимость от результатов других транзакций. Таким образом, точка проверки в транзакции имеет значение только если все другие активные операции также согласны с тем, что состояние базы данных в этой точке является непротиворечивым состоянием (consistent state). При этом точка проверки действует как точка встречи, в которой все активные транзакции системы фиксируют (commit) свою, возможно, частично сделанную, до этой точки работу.
Приложение базы данных предполагает значительную известность относительно семантики операций в базе данных. Семантика знаний может быть использована для установки точек проверки в транзакциях в точках, которые соответствуют логическому завершению некоторой части работы. В традиционных базах данных с быстро выполняющимися транзакциями сама транзакция является логической единицей работы. Однако в крупных приложениях нельзя трактовать транзакцию целиком как логическую единицу работы. В этом и состоит полезность идеи точек проверки.
Состояние пользовательских транзакций на объектахКаждый объект O в системе хранит состояние каждой пользовательской транзакции в системе. Состояние пользовательской транзакции (т.е. операции на DBIO) может принимать одно из следующих значений:
Никогда не активировалась (Never Activated)
Любая пользовательская транзакция, которая не воздействовала на O прямо или косвенно, находится в этом состоянии на O. Это эквивалентно тому, что не имеется никакой информации о пользовательской транзакции в O.
Завершена (Completed)
Пользовательская транзакция находится в состоянии Завершена на O, если операция вызванная ей на O закончила выполнение всех своих шагов.
Находится в точке проверки (Chekpoint)
Пользовательская транзакция не произвела никаких действий с тех пор, как оказалась в точке проверки.
Задержана для проверки (BlockedForCheckPoint)
Пользовательская транзакция ожидает выполнения условий, которые будут удовлетворять переводу ее в Точку проверки.
Выполняется (Executing)
Пользовательская транзакция выполняется на O, если операция op(O), вызванная этой транзакцией выполняется.
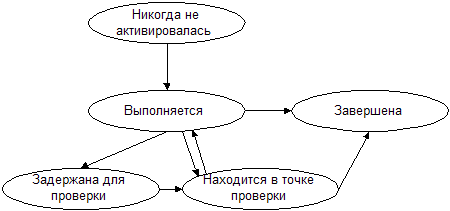
Рис 4: Диаграмма переходов транзакции из состояния в состояние
Таблица 4: Пример изменения состояния транзакции при ее выполнении
| Действия | Новое состояние транзакции |
| Никогда не активировалась | |
| Объект O получил запрос на выполнение op(O) впервые для транзакции Tr(op(O)) и op(O) начинает выполняться | Выполняется |
| Операция транзакции достигла описанной для нее точки проверки, все остальные активные операции на O "никогда не активировались" в точке проверки | Находится в точке проверки |
| Операция транзакции достигла описанной для нее точки проверки, но активные операции не находятся в своих точках проверки | Блокирована для точки проверки |
| Tr(op(O)) закончила все свои шаги | Завершена |
Таким образом, если объект имеет точки проверки, описанные для своих операций, то операции встречаются (рандеву) в точке проверки. Если операции в точке проверки произведены успешно, то в будущем нет необходимости любой операции откатываться (rollback) за точку проверки.
Шаги протокола согласованного управления1. Операция запрошена (requested)
2. Операция вызывает другую операцию
3. Вызванная операция возвращается
4. Операция завершена
5. Точка разрыва (breakpoint) достигнута
6. Точка проверки (checkpoint) достигнута
7. В точке проверки получено сообщение
Детально алгоритм выполнения шагов описан в [19].
4. Представление данных в ООБД 4.1 Базовые объекты системыСистеме известны следующие базовые объекты: ROOT, FAIL, NULL, SAME, ATOMIC, INT, STR, DATIME, BIO, AGG, SET, SEQ.
1. ROOT – корень – предок всех объектов. Данных не имеет.
2. FAIL, копия ROOT – возвращается, если при воздействии произошла ошибка.
3. NULL, копия ROOT – объект-заменитель при отсутствующем значении. Эта проблема возникла недавно, но в теории реляционных баз данных пока не нашла приемлемого решения. Суть проблемы заключается в том, что при вводе данных, некоторые из них могут отсутствовать (например, не известен год рождения), поэтому нельзя сказать, чему они в точности равны. В некоторых случаях нуль может являться значением, для этого и вводится специальное обозначение (NULL).
4. SAME, копия ROOT – объект, позволяющий создавать копии. Он означает, что для взаимодействующего с ним объекта создается копия.
5. ATOMIC – предок всех атомарных объектов. Задает для них основные методы поведения.
6. INT – целое.
7. STR – строка.
8. DATIME – дата и время
9. BIO – условный объект
10. AGG – агрегат
11. SET – множество
12. SEQ – последовательность
4.2 Строение объекта
Каждому объекту выделяется персональное виртуальное пространство. Объект предваряется заголовком. За заголовком следуют виртуальные пространства данных и журнала. Каждый объект имеет уникальный идентификатор в пределах системы.
Таблица 5: Заголовок объекта (все поля 32-битные)
| Поле | Семантика |
| OID | Идентификатор объекта (уникальный в пределах системы) |
| OBJBHR | Идентификатор объекта-поведения (методы) |
| OBJKH | Идентификатор объекта-действия |
| TRCOOBJ | Идентификатор транзакционного сообъекта |
| VALUE | Адрес заголовка вложенного канала, хранящего значение |
| HISTORY | Адрес заголовка вложенного канала, хранящего историю изменений |
Атомарный объект хранит внутри блока данных свое значение.
Объект-условие хранит внутри блока данных три идентификатора в следующем порядке: идентификатор метода условия, идентификатор метода, выполняемого, если условие выполнено («истина») и идентификатор метода, выполняемого, если условие не выполнено ( «ложь»).
У объектов агрегат, список и множество первое слово блока данных – размер элемента. Для списка и множества он равен 4. Для агрегата – 12.
Элементом списка и множества является идентификатор объекта. Элементом агрегата является кортеж:
· идентификатор объекта-значения (он обязательно является потомком объекта-образца)
· идентификатор поля (FID)
· идентификатор объекта-образца
Если идентификатор объекта-экземпляра в списке или множестве равен нулю, это означает, что элемент удален. Признаком конца списка, множества, полей объекта служит размер виртуальной памяти, выделенной для размещения данных.
Таблица 6: Строение данных для DATIME
| Длина в байтах | Значение |
| 2 | Год |
| 1 | Месяц |
| 1 | День |
| 1 | Час |
| 1 | Минуты |
| 1 | Секунды |
| 2 | Доли секунд |
Такая структура журнала позволяет фиксировать изменения не только данных, но и поведений, knowhow…
Таблица 7: Структура записи изменений во внутреннем журнале объекта
| Число байт | Значение |
| 4 | Номер транзакции |
| 2 | Адрес размещения в заголовке |
| 4 | Замененное значение |
| 2 | Год |
| 1 | Месяц |
| 1 | День |
| 1 | Час |
| 1 | Минуты |
| 1 | Секунды |
| 2 | Доли секунд |
Информация о транзакциях в системе
Все пользовательские объекты в системе имеют транзакционные сообъекты. Транзакционный сообъект – это объект, хранящий информацию о воздействии операций транзакций на состояние пользовательского объекта. Ссылка на сообъект находится внутри объекта, для которого отслеживаются воздействия.
Таблица 8: Структура транзакционного сообъекта (агрегата)
| Имя поля | Значение |
| DSL | Множество локальных зависимостей |
| DSI | Множество унаследованных зависимостей |
| DSR | Множество приобретенных зависимостей |
| DS | Множество зависимостей |
Множество зависимостей получается объединением множеств локальных, унаследованных и приобретенных зависимостей. Каждый элемент какого-либо из этих множеств зависимостей – пара номеров транзакций (Ti,Tj). Если трактовать это множество как множество ребер графа, в котором вершины – номера транзакций, а ребра – зависимости между транзакциями, то наличие цикла в графе означает некорректное выполнение транзакций.
В целях упрощения решено отказаться от таблицы конфликтов. Таблица конфликтов описывает какие операции конфликтуют между собой, т.е. может ли выполняться операция A, если в данных момент выполняется операция B. Ячейка таблицы может принимать одно из трех значений: «Конфликтует», «Не конфликтует», «Неизвестно». Значение «Неизвестно» вводится по причине наличия механизма позднего связывания, при котором заранее не известно, конфликтуют ли операции.
Транзакции и объекты-поведенияОбъекты поведения представляют собой множество объектов, поле OBJKH которых хранит идентификатор выполняемого действия. Это множество имеет ширину элемента не 4, как обычное множество, хранящее данные, а 8. В следующих четырех байтах может храниться идентификатор списка – строки таблицы чередований в точках разрыва (части подсистемы транзакций). Таблица чередований образуется из точек разрыва и группировки спецификаций для объекта. Она позволяет определить: в каких точках разрыва каких операций можно переключиться на выполнение операции, соответствующей этой строке таблицы чередований. Это статическая информация, которая может быть сформирована перед началом работы системы. Элемент строки таблицы чередований состоит из 2 значений: идентификатора операции и идентификатора множества, хранящего номера точек разрыва.
4.3 Контекст транзакцииВ системе есть объект DBIO (Database User-Intarface Object), которому известны состояния всех транзакций. Этот объект представляет собой множество, элементами которого являются объекты-агрегаты, описывающие контекст транзакции.
Таблица 9: Контекст транзакции
| Имя поля | Размер в байтах | Значение |
| TR_MESS | 4 | OID сообщения |
| TR_KH | 4 | OID knowhow |
| TR_PARAM | 4 | OID агрегата с параметрами |
| TR_TARGET | 4 | OID целевого объекта сообщения |
| TR_RES | 4 | OID результата |
| TR_STACK | 4 | OID стека |
| TR_N | 4 | Номер транзакции |
| TR_HOSTN | 4 | Номер вызвавшей транзакции |
| TR_STATUS | 1 | Состояние транзакции |
| TR_POINT | 2 | Точка разрыва, в которой находимся |
Для каждой транзакции выделяется свой стек. Механизм сохранения и восстановления стеков описан в [7]. Стеки сохраняются в атомарных объектах.
5. Описание операций над объектами в БД[] DB.NEW [] -- создать новую БД
[] DB.OPEN [] -- открыть БД
[] DB.CLOSE [] -- закрыть БД
Операции клонирования:
[oid] CLONE [oid'] -- клонировать объект
[] CLONE_ROOT [oid'] -- Создать объект от "Корень"
[int] CLONE_INT [oid'] -- Создать объект "Целое"
["string"] CLONE_STR [oid'] -- Создать объект "Строка"
["string"] CLONE_AGG [oid'] -- Создать объек-агрегат
[oid_if oid_then oid_else]
CLONE_BIO [oid'] -- Создать объект-условие
[] CLONE_SET [oid'] -- Создать объект-множество
[] CLONE_SEQ [oid'] -- Создать объект-последовательность
OIDROOT, OIDINT, OIDAGG, …, OIDSEQ -– Узнать идентификаторы соотв. Объектов
[oid_bhr] SET_BHR [] -- переопределить поведение
[] GET_BHR [oid] -- узнать поведение
[oid_kh] SET_KH [] -- переопределить действие
[] GET_KH [oid] -- узнать действие
[oid] GET_INT [int] -- Получить целое число из объекта-целого
[int oid] SET_INT [] -- Занести целое число в объект-целое
[oid] PRINT_STR [] -- Печатать на экране содержимое строки
["string" oid] SET_STR [] -- Занести строку в объект-строку
[oid_super oid] SUPER+ [] -- наследовать данные из oid_super в oid
[oid] DELOBJ [] -- удалить объект
Операции над множеством:
[oid_el oid] SET+E [] -- добавить элемент в множество
[oid_el oid] SET-E [] -- удалить элемент из множества
[oid_el oid] SET?E [0/1] -- найти элемент в множестве
[oid1 oid] SET+ [] -- объединение
[oid1 oid] SET- [] -- разность
[oid1 oid] SET* [] -- пересечение
Операции над списком:
[oid_el n oid] SEQ+E [] -- добавить элемент в последовательность
[n oid] SEQ-E [] -- удалить n-й элемент из
последовательности
[oid_el oid] SEQ?E [0/n] -- найти позицию в последовательности
[n oid] SEQ?N [0/oid] -- определить oid n-го элемента послед-ти
Операции над агрегатом:
[fid oid_etalon oid] AGG+F [] -- добавить поле к объекту
[fid oid] AGG-F [] -- удалить поле из объекта
[fid oid] ETALON [oid] -- получить идентификатор объекта-эталона
[fid oid] FIELD [oid] -- получить идентификатор
объекта-значения
Операции над объектом-условием:
[oid] GET_BIO
[oid_else oid_then oid_if] -- Получить параметры объекта-условия
[oid_else oid_then oid_if oid]
SET_BIO [] -- Сохранить параметры объекта-условия
Специальные операции:
[oid_str oid] SET_NAMEOBJ [oid] -- именовать объект
[oid_str fid] SET_NAMEFID [fid] -- именовать поле
[oid_str] NAMEOBJ [oid] -- получить идентификатор по имени
[oid_str] NAMEFID [fid] -- получить идентификатор поля по имени
[oid_mess oid_par oid] SEND [] -- послать сообщение объекту
[oid_mess oid_obj] METHOD? [] -- определить идентификатор метода
[oid1 oid] CHIELD [1/0] -- определить, является ли oid1 потомком oid
[oid_kh] RUN_KH [] -- выполнить knowhow
[] NCHAN [chan] -- узнать номер текущего канала
[chan] !NCHAN [] -- переключиться на заданный канал
Операции просмотра:
[oid] JVIEW [] -- просмотр журнала
[] A.VIEW [] -- просмотр адресов объектов в БД
[] Q.VIEW [] -- просмотр очереди
[] IC [] -- просмотр состояния канала
6. Требования к техническим и программным средствамДССП реализована на множестве компьютерных платформ (VAX, PDP-11, IBM PC, R3000, MC68020, SPARC) и операционных систем (MSDOS, MSDOS-экстендеры, UNIX, RT-11, RSX, OS9, CPM и др.). В данный момент практически закончена разработка ДССП на Си, что обеспечивает перенос этой системы на любую платформу, где есть Си.
Аппаратные средства:
Любая платформа, на которой функционирует ДССП, с объемом оперативной памяти для нужд БД не менее 1 Мб.
Программные средства:
ДССП с диспетчером параллельных процессов (версия 4.42) и Операционная Система.
Разрабатываемая СУООБД может также работать в качестве host-программы на файл-сервере, обрабатывая команды с рабочих станций, поступающие в их персональные ящики на файл-сервере. Ответ рабочие станции получают также через почтовые ящики.
В дальнейшем, могут быть реализованы сетевые протоколы и тогда СУООБД будет являться сервером в клиент-серверных приложениях.
Использование отдельных почтовых ящиков для нескольких параллельно работающих пользователей позволяет возложить на СУООБД функции монитора [6], осуществляющего линеаризацию поступающих запросов к содержимому СУООБД.
7. Реализация прототипа 7.1 ПостроительLOAD TIMEM
LOAD M0
LOAD M2
LOAD Soms
LOAD CHMS
LOAD SYSOBJS
LOAD M3
LOAD LS_CASH
UNDEF
PROGRAM $KH_VOC
7.2 Заголовочный модуль для каналовPROGRAM $M0
B16
1000 VALUE TOTMEMLEN
TOTMEMLEN BYTE VCTR MEMORY
: T-1 D -1 ;
: *4 SHL SHL ;
: &0FF 0FF & ;
: <= 1+ < ;
: >= 1- > ;
[20 WORD VCTR CHAN] [каналы. Начиная с 5-го]
VAR NCHAN [Номер текущего канала]
: !NCHAN ! NCHAN ;
5 VALUE NBASECH [Первый не базовый канал]
: GETDATA NCHAN 10 * + CHDATA ;
: PUTDATA NCHAN 10 * + ! CHDATA ;
[Размер заголовка блока в байтах]
FIX VAR HSIZE 10 ! HSIZE
: HSIZE+ HSIZE + ;
[Pred, Next, BusyLen, Len]
1 *4 VALUE ctfPREDADDR
[$M4] [как самодостаточный]
0 VALUE ctLOWCH [Нижний канал.]
[0=Оперативная/1=Дисковая память/2=Журнал/-1=свободен]
1 VALUE ctTEKADR [Логический адрес внутри участка (по данным)]
2 VALUE ctBUSYLEN [Длина фрагмента, занятая данными]
3 VALUE ctLEN [Максимальная допустимая длина данных фрагмента]
4 VALUE ctTEKADR0 [=TEKADR, когда TEKADR стоит на нулевом байте данных фрагм]
5 VALUE ctNEXTADDR [Адрес начала заголовка следующего фрагмента (пф)]
6 VALUE ctPREDADDR [Адрес начала заголовка предыдущего фрагмента (пф)]
7 VALUE ctSYNCADDR [Адрес начала заголовка фрагмента (пф)]
8 VALUE ctCHGCTX [признак изменения контекста]
9 VALUE ct1STLONG [Первое число в канале]
[в начальном блоке в начальном слове данных лежит адрес начала данных]
: LOWCH ctLOWCH GETDATA ; : !LOWCH ctLOWCH PUTDATA ;
: TEKADR ctTEKADR GETDATA ; : !TEKADR ctTEKADR PUTDATA ;
: TEKADR0 ctTEKADR0 GETDATA ; : !TEKADR0 ctTEKADR0 PUTDATA ;
: TEKADR++ TEKADR 1+ !TEKADR ; : !+TEKADR TEKADR + !TEKADR ;
: BUSYLEN ctBUSYLEN GETDATA ; : !BUSYLEN ctBUSYLEN PUTDATA ;
: LEN ctLEN GETDATA ; : !LEN ctLEN PUTDATA ;
: NEXTADDR ctNEXTADDR GETDATA ; : !NEXTADDR ctNEXTADDR PUTDATA ;
: PREDADDR ctPREDADDR GETDATA ; : !PREDADDR ctPREDADDR PUTDATA ;
: SYNCADDR ctSYNCADDR GETDATA ; : !SYNCADDR ctSYNCADDR PUTDATA ;
: CHGCTX ctCHGCTX GETDATA ; : !CHGCTX ctCHGCTX PUTDATA ;
: FSTLONG ct1STLONG GETDATA ; : !FSTLONG ct1STLONG PUTDATA ;
TRAP NOMEMORY NOMEMORY#
: NOMEMORY# ."
No free memory" ;
TRAP OUTDATA OUTDATA#
: OUTDATA# ."
Out of data. " ;
TRAP OUTMEM OUTMEM#
: OUTMEM# ."
Out of memory. " ;
TRAP UNKCH UNKCH#
: UNKCH# ."
Unknown primitive channel:" NCHAN .D CR ;
TRAP O_NOTFND NOTFND#
: NOTFND# ."
Object not found. OID=" . CR ;
[*** Информация по каналу ***]
: IC CR
." NCHAN=" NCHAN .D SP ." LOWCH=" LOWCH .D CR
."SYNCADDR=" SYNCADDR .D SP ."PREDADDR=" PREDADDR .D SP ."NEXTADDR="
NEXTADDR .D CR
." BUSYLEN=" BUSYLEN .D SP ." LEN=" LEN .D CR
." TEKADR0=" TEKADR0 .D SP ." TEKADR=" TEKADR .D CR ;
CHANNEL DATACH "DATA." CONNECT DATACH
7.3 Менеджер виртуальной памятиPROGRAM $M2
B16 [физическая организация памяти]
[вычисление физического адреса и номера базового канала]
:: : POSIX [addr(i)] NCHAN C NBASECH < BR+ LEAVE [addr nchan] D
GOTO DELTA2 S( NCHAN ) TOLOW POSIX [addr(i-1)] ;
:: : TOLOW LOWCH !NCHAN ;
[Пересчет адреса в адрес нижнего уровня: TEKADR(i) -> TEKADR(i-1)]
:: : DELTA2 SYNCADDR HSIZE + TEKADR TEKADR0 - + ;
:: : IBS EON OUTDATA OUTDATA# LAST?
TEKADR POSIX TEKADR++ S( NCHAN ) !NCHAN BSGOTO
NCHAN BR 0 IBS0 1 IBS1 [2 IBS2] ELSE UNKCH ;
:: : OBS EON OUTDATA OUTDATA# LAST?
TEKADR POSIX TEKADR++ S( NCHAN ) !NCHAN BSGOTO
NCHAN BR 0 OBS0 1 OBS1 [2 OBS2] ELSE UNKCH ;
: LAST? TEKADR BUSYLEN TEKADR0 + = IF0 LEAVE NEXTBLK ;
[переход для базового канала ]
: BSGOTO [ADDR] NCHAN BR 0 BSGOTO0 1 BSGOTO1 [2 BSGOTO2] ELSE UNKCH ;
: BSGOTO0 !TEKADR ;
: BSGOTO1 C !TEKADR HSIZE+ SPOS DATACH ;
[ : BSGOTO2 C !TEKADR HSIZE+ SPOS JOURCH ;]
0 %IF
: ADDR [PARAGRAF OFFSET] + [address] ; [Сейчас пгф=1 байту]
[Для файлов можно сделать неск. файлов и распределить по ним пространство]
%FI
: IBS0 TEKADR HSIZE+ MEMORY &0FF TEKADR++ ;
: IBS1 IB DATACH &0FF TEKADR++ ;
[: IBS2 IB JOURCH &0FF TEKADR++ ;]
: OBS0 &0FF TEKADR HSIZE+ ! MEMORY TEKADR++ ;
: OBS1 &0FF OB DATACH TEKADR++ ; [Запись байта]
[: OBS2 &0FF OB JOURCH TEKADR++ ;] [Запись байта]
:: : GOTO NCHAN NBASECH < BR+ BSGOTO VGOTO ;
: VGOTO TEKADR - @GOTO ;
[Переход по смещению]
:: : @GOTO C BRS @GOTO- D @GOTO+ ;
: @GOTO+ DO @GOTO1+ ;
: @GOTO- NEG DO @GOTO1- ;
: @GOTO1+
EON OUTDATA OUTDATA#
TEKADR TEKADR0 BUSYLEN + =
IF+ NEXTBLK TEKADR 1+ !TEKADR ;
: @GOTO1-
EON OUTDATA OUTDATA#
TEKADR TEKADR0 =
IF+ PREDBLK TEKADR 1- !TEKADR ;
: NEXTBLK CHGCTX IF+ SCTX NEXTADDR NOEXIST? !SYNCADDR RELCTX
TEKADR !TEKADR0 ;
: NOEXIST? [ADDR] C -1 = IF+ OUTDATA [ADDR] ;
[Pred, Next, BusyLen, Len]
:: : LCTX' [UPCH] PUSH TEKADR ILS ILS ILS ILS POP
NCHAN E2 !NCHAN !LOWCH !LEN !BUSYLEN !NEXTADDR !PREDADDR !SYNCADDR
0 !CHGCTX ;
[Грузить параметры канала]
:: : LCTX [newch] LCTX' 0 !TEKADR 0 !TEKADR0 ;
: RELCTX TEKADR0 TEKADR NCHAN SYNCADDR TOLOW GOTO LCTX !TEKADR !TEKADR0 ;
: PREDBLK CHGCTX IF+ SCTX PREDADDR NOEXIST? !SYNCADDR RELCTX
TEKADR BUSYLEN - !TEKADR0 ;
: IBSC [CHAN] S( NCHAN ) !NCHAN IBS ;
: ILSC S( NCHAN ) !NCHAN ILS ;
: OBSC [N CHAN] S( NCHAN ) !NCHAN OBS ;
: IOBSCC [SRC DST] C2 IBSC C2 OBSC ;
: DO_IOBSCC [SRC_CH DST_CH N] S( NCHAN )
C3 !NCHAN 0 GOTO DO IOBSCC [SRC DST] ;
: IWS IBS IBS SWB &0 ;
: ILS IWS IWS SETHI ; [SWW &0]
: OWS C OBS SWB OBS ;
: OLS C OWS SWW OWS ;
[Перейти к конечному блоку]
: GOTOENDBK NEXTADDR -1 = EX+ BUSYLEN TEKADR0 +
NEXTADDR !SYNCADDR RELCTX C !TEKADR0 !TEKADR ;
: GOBOTTOM RP GOTOENDBK BUSYLEN TEKADR0 + GOTO ;
: LENVMEM GOBOTTOM TEKADR [LEN] ; [длина виртуальной памяти]
: LASTADDR SYNCADDR LEN + HSIZE+ ;
: OBS-0 NCHAN BR 0 OBS00 1 OBS01 [2 OBS02] ELSE OBS0N ;
: OBS00 0 OBS0 ; : OBS01 0 OBS1 ; [: OBS02 0 OBS2 ;] : OBS0N 0 OBS ;
[Спецификация: Размер увеличивается на N байт. Если это невозможно,
возникает исключительная ситуация NOMEMORY.
После работы мы стоим в том же канале в начале выделенного пространства. ]
: UPSIZE [N] GOBOTTOM TEKADR E2 UPSIZE' GOTO [] ;
: UPSIZE' [N] GOBOTTOM LEN BUSYLEN - CALCOST [HARD SOFT] UPSIZEI
C BR0 D UPSIZEO ;
: CALCOST [N FREE] C2C2 <= BR+ COST1 COST2 [HARD SOFT] ;
: COST1 [N FREE] T0 E2 [0 N] ;
: COST2 [N FREE] C PUSH - POP [N-FREE FREE] ;
: UPSIZEI [N_SOFT] BUSYLEN + !BUSYLEN 1 !CHGCTX SCTX ;
: UPSIZEO [N_HARD] NCHAN BR 0 USO0 1 USO1 2 USO1 ELSE USON ;
: USO1 C GOBOTTOM TEKADR E2 DO OBS-0 [!TEKADR] BSGOTO
C BUSYLEN + !BUSYLEN LEN + !LEN 1 !CHGCTX SCTX ;
: USO0 NOMEMORY [Сюда можно вставить упаковку] ;
[Спецификация: увеличение размера (жестко, т.е. за счет нижнего уровня)]
: USON [N] SYNCADDR LASTADDR USON1 RELCTX [>] UPSIZE' ;
: USON1 S( NCHAN ) TOLOW BUSYLEN = BR+ USON_ADD USON_NEW ;
[Расширение увеличением длины фрагмента]
: USON_ADD C2 [N SYNCADDR N] UPSIZE' C BUSYLEN E2 - HSIZE - E2
[N LEN SYNCADDR] 3 *4 + GOTO OLS [N] [UPSIZEI] ;
[Расширение созданием нового фрагмента]
: USON_NEW C2 [N SYNCADDR N] [GOBOTTOM] C HSIZE+ UPSIZE'
[N SYNCADDR N] C2 -1 0 C4 TEKADR PUSH WRITECTX D 4+ GOTO POP OLS [N] ;
: WRITECTX [PRED NEXT BUSY LEN] C4 OLS C3 OLS C2 OLS C OLS DD DD ;
FIX VAR UPCONST 10 ! UPCONST [Этому числу байт кратно увеличение]
[Увеличение размера нижнего уровня]
[увеличение физического размера этого уровня]
: SCTX CHGCTX IF0 LEAVE 0 !CHGCTX NCHAN BR 0 NOP 1 SCTX1 [2 SCTX2]
Похожие работы
... ); Pisa в университетах Глазго и Св. Эндрю (Universities of Glasgo and St. Andrew). Среди исследовательских институтов, в которых существовали мощные группы, ориентированные на исследования в области объектно-ориентированных баз данных, входили OGI (Oregon Graduate Institute ), MCC (Microelectronics and Computer Technology Corporation ) и французский исследовательский центр INRIA . На базе ...
... ООП. Сейчас язык С++ является языком публикаций по вопросам ООП. Практикум на С/С++:Фактически С++ содержит 2 языка: Полностью включает низкоуровневый Си, поддерживающий конструкции СП, и, собственно, С++ (Си с классами) – язык объектно-ориентированного программирования (ООП). Мы находимся сейчас на технологической ступени структурного программирования, поэтому начинаем с Си: Знакомство с С, ...
... СУБД; можно управлять распределением областей внешней памяти, контролировать доступ пользователей к БД и т.д. в масштабах индивидуальной системы, масштабах ограниченного предприятия или масштабах реальной корпоративной сети. В целом, набор серверных продуктов одиннадцатого выпуска компании Sybase представляет собой основательный, хорошо продуманный комплект инструментов, которые можно ...
... , а иногда и невозможным. Недостатки MOLAP-модели: · Многомерные СУБД не позволяют работать с большими базами данных. · Многомерные СУБД по сравнению с реляционными очень неэффективно используют внешнюю память. В подавляющем большинстве случаев информационный гиперкуб является сильно разреженным, а поскольку данные хранятся в упорядоченном виде, неопределенные значения ...
0 комментариев