Навигация
Реализация запросов к базе данных
108575
знаков
10
таблиц
0
изображений
4.2 Реализация запросов к базе данных.
В данном разделе описывается построение запросов к базе данных, то есть написание самих файлов ASP с помощью которых пользователем осуществляется ввод информации для поиска необходимой ему информации, а так же программ-скриптов, находящиеся непосредственно на сервере и обрабатывающие запросы.
Специальных оболочек для написания данных программ-скриптов не использовалось, хотя компания Microsoft рекомендует для разработки свою программу Visual InterDev.
Начальная программа-скрипт (Db008.asp), запускается у пользователя-клиента, осуществляет вывод полей для ввода уточняющей информации по запросу. Эта же программа осуществляет вызов следующего ASP файла и передачу ему необходимой информации по конкретному запросу.
Существует два метода для передачи параметров из форм: метод GET и метод POST.
Метод GET служит для получения любой информации, идентифицированной URI-Запроса. Если URI - Запроса ссылается на процесс, выдающий данные, в качестве ответа будут выступать данные, сгенерированные данным процессом, а не код самого процесса (если только это не является выходными данными процесса). Использование метода условный GET направлено на разгрузку сети, так как он позволяет не передавать по сети избыточную информацию.
Метод POST используется для запроса сервера, чтобы тот принял информацию, включенную в запрос, как субординантную для ресурса, указанного в Строке Статус в поле URI-Запроса. Метод POST был разработан, чтобы была возможность использовать один общий метод для следующих функций:
Аннотация существующих ресурсов
Добавление сообщений в группы новостей, почтовые списки или подобные группы статей
Доставка блоков данных процессам, обрабатывающим данные
Расширение баз данных через операцию добавления
Реальная функция, выполняемая методом POST, определяется сервером и обычно зависит от URI- Запроса. Добавляемая информация рассматривается как субординатная указанному URI в том же смысле, как файл субординатен каталогу, в котором он находится, новая статья субординатна группе новостей, в которую она добавляется, запись субординатна базе данных.
Клиент может предложить URI для идентификации нового ресурса, включив в запрос заголовок "URI". Тем не менее, сервер должен рассматривать этот URI только как совет и может сохранить тело запроса под другим URI или вообще без него.
Для передачи параметров запроса используется метод POST, так как объем передаваемых параметром большой.
Далее происходит вызов других ASP файлов, в зависимости от введённой информации по конкретному запросу или активизации определённой ссылки, а так же передача параметров самого запроса.
Вызванный файл - обработчик запроса. Он формирует конкретный запрос к базе данных и возвращает полученную информацию пользователю.
Список выполняемых функций конкретного файла:
Srch_Org.asp – осуществляет запрос на выборку информации по организациям;
Org_Info.asp - осуществляет запрос на выборку подробной информации об организациях;
Srch_Glb.asp - осуществляет запрос по конкретной информации;
Stat_TY1.asp - осуществляет запрос на выборку статистической информации по категории товаров;
Stat_TY2.asp - осуществляет запрос на выборку статистической информации по категории услуги.
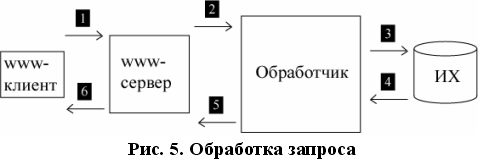
Схема взаимосвязей между файлами запросов:
SearchFr.asp
Srch_Org.asp
Org_Info.asp
Srch_TY1.asp
Stat_TY1.asp
Appendix.asp
Srch_Glb.asp
Stat_TY2.asp
Рис.5 Схема взаимосвязей между файлами запросами.
Начальный файл базы Db008.asp - содержит форму для ввода параметров поиска. Здесь пользователь может выбрать интересующий его раздел или просто задать слово для контекстного поиска, так же выбрав разделы где искать.
Рис.6 Db008.asp
Далее происходит следующее:
Когда пользователь нажимает кнопку типа "Submit" в форме Web-браузер запрашивает определённый ASP-файл с необходимым запросом по выборке необходимой информации, а так же передаёт необходимые параметры запроса.
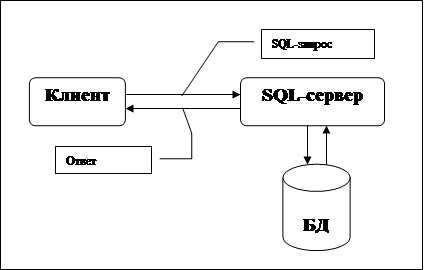
Далее уже непосредственно ASP-программа осуществляет запрос к базе данных SQL через драйвер ODBC с полученными параметрами.
Затем полученные результаты поиска передаются WEB-браузеру пользователя.
Термин ODBC означает "open database connectivity" - технологию, основанную на стандарте ANSI/ISO, которая позволяет приложениям осуществлять доступ к нескольким базам данных сторонних поставщиков. В ODBC применяется интерфейс общего назначения CLI (call level interface), в котором SQL используется как стандарт для доступа к данным. Нашей целью является обеспечение устойчивых серверных сессий для клиентских систем, поддерживающих ODBC. Сессии могут переживать системный крах без потребности того, чтобы клиентские приложения не беспокоились об остановке работы, разве только из соображений времени выполнения.
Когда клиентское приложение запрашивает информацию из базы данных, запрос поступает драйверу ODBC, который является специфической программой для системы баз данных, реально производящей доступ к базе данных. Драйвер ODBC транслирует запрос таким образом, чтобы сервер баз данных мог понять его и ответить. Сервер передает запрошенные данные драйверу ODBC, который преобразует данные в форму, которую может понять клиентское приложение ODBC.
Все запросы на получение практически любого количества данных из одной или нескольких таблиц выполняются с помощью единственного предложения SELECT. В общем случае результатом реализации предложения SELECT является другая таблица. К этой новой (рабочей) таблице может быть снова применена операция SELECT и т.д., т.е. такие операции могут быть вложены друг в друга. Представляет исторический интерес тот факт, что именно возможность включения одного предложения SELECT внутрь другого послужила мотивировкой использования прилагательного "структуризированный" в названии языка SQL.
Предложение SELECT может использоваться как:
самостоятельная команда на получение и вывод строк таблицы, сформированной из столбцов и строк одной или нескольких таблиц (представлений);
элемент WHERE- или HAVING-условия (сокращенный вариант предложения, называемый "вложенный запрос");
фраза выбора в командах CREAT VIEW, DECLARE CURSOR или INSERT;
средство присвоения глобальным переменным значений из строк сформированной таблицы (INTO-фраза).
Здесь в синтаксических конструкциях используются следующие обозначения:
звездочка (*) для обозначения "все" - употребляется в обычном
для программирования смысле, т.е. "все случаи, удовлетворяющие определению";
квадратные скобки ([]) – означают, что конструкции, заключенные в эти скобки, являются необязательными (т.е. могут быть опущены);
фигурные скобки ({}) – означают, что конструкции, заключенные в эти скобки, должны рассматриваться как целые синтаксические единицы, т.е. они позволяют уточнить порядок разбора синтаксических конструкций, заменяя обычные скобки, используемые в синтаксисе SQL;
многоточие (...) – указывает на то, что непосредственно предшествующая ему синтаксическая единица факультативно может повторяться один или более раз;
прямая черта (|) – означает наличие выбора из двух или более возможностей. Например обозначение ASC|DESC указывает, можно выбрать один из терминов ASC или DESC; когда же один из элементов выбора заключен в квадратные скобки, то это означает, что он выбирается по умолчанию (так, [ASC]|DESC означает, что отсутствие всей этой конструкции будет восприниматься как выбор ASC);
точка с запятой (;) – завершающий элемент предложений SQL;
запятая (,) – используется для разделения элементов списков;
пробелы ( ) – могут вводиться для повышения наглядности между любыми синтаксическими конструкциями предложений SQL;
прописные жирные латинские буквы и символы – используются для написания конструкций языка SQL и должны (если это специально не оговорено) записываться в точности так, как показано;
строчные буквы – используются для написания конструкций, которые должны заменяться конкретными значениями, выбранными пользователем, причем для определенности отдельные слова этих конструкций связываются между собой символом подчеркивания (_);
термины таблица, столбец, ... – заменяют (с целью сокращения текста синтаксических конструкций) термины имя_таблицы, имя_столбца, ..., соответственно;
термин таблица – используется для обобщения таких видов таблиц, как базовая_таблица, представление или псевдоним; здесь псевдоним служит для временного (на момент выполнения запроса) переименования и (или) создания рабочей копии базовой_таблицы (представления).
Предложение SELECT (выбрать) имеет следующий формат:
подзапрос [UNION [ALL] подзапрос] ...
[ORDER BY {[таблица.]столбец | номер_элемента_SELECT} [[ASC] | DESC]
[,{[таблица.]столбец | номер_элемента_SELECT} [[ASC] | DESC]] ...;
и позволяет объединить (UNION) а затем упорядочить (ORDER BY) результаты выбора данных, полученных с помощью нескольких "подзапросов". При этом упорядочение можно производить в порядке возрастания - ASC (ASCending) или убывания DESC (DESCending), а по умолчанию принимается ASC.
В этом предложении подзапрос позволяет указать условия для выбора нужных данных и (если требуется) их обработки
SELECT
(выбрать) данные из указанных столбцов и (если необходимо) выполнить перед выводом их преобразование в соответствии с указанными выражениями и (или) функциями
FROM
(из) перечисленных таблиц, в которых расположены эти столбцы
WHERE
(где) строки из указанных таблиц должны удовлетворять указанному перечню условий отбора строк
GROUP BY
(группируя по) указанному перечню столбцов с тем, чтобы получить для каждой группы единственное агрегированное значение, используя во фразе SELECT SQL-функции SUM (сумма), COUNT (количество), MIN (минимальное значение), MAX (максимальное значение) или AVG (среднее значение)
HAVING
(имея) в результате лишь те группы, которые удовлетворяют указанному перечню условий отбора групп
и имеет формат
SELECT [[ALL] | DISTINCT]{ * | элемент_SELECT [,элемент_SELECT] ...}
FROM {базовая_таблица | представление} [псевдоним]
[,{базовая_таблица | представление} [псевдоним]] ...
[WHERE фраза]
[GROUP BY фраза [HAVING фраза]];
Элемент_SELECT - это одна из следующих конструкций:
[таблица.]* | значение | SQL_функция | системная_переменная
где значение – это:
[таблица.]столбец | (выражение) | константа | переменная
Синтаксис выражений имеет вид
( {[ [+] | - ] {значение | функция_СУБД} [ + | - | * | ** ]}... )
а синтаксис SQL_функций – одна из следующих конструкций:
{SUM|AVG|MIN|MAX|COUNT} ( [[ALL]|DISTINCT][таблица.]столбец )
{SUM|AVG|MIN|MAX|COUNT} ( [ALL] выражение )
COUNT(*)
Фраза WHERE включает набор условий для отбора строк:
WHERE [NOT] WHERE_условие [[AND|OR][NOT] WHERE_условие]...
где WHERE_условие – одна из следующих конструкций:
значение { = | | < | | >= } { значение | ( подзапрос ) }
значение_1 [NOT] BETWEEN значение_2 AND значение_3
значение [NOT] IN { ( константа [,константа]... ) | ( подзапрос ) }
значение IS [NOT] NULL
[таблица.]столбец [NOT] LIKE 'строка_символов' [ESCAPE 'символ']
EXISTS ( подзапрос )
Кроме традиционных операторов сравнения (= | | < | | >=) в WHERE фразе используются условия BETWEEN (между), LIKE (похоже на), IN (принадлежит), IS NULL (не определено) и EXISTS (существует), которые могут предваряться оператором NOT (не). Критерий отбора строк формируется из одного или нескольких условий, соединенных логическими операторами:
AND
- когда должны удовлетворяться оба разделяемых с помощью AND условия;
OR
- когда должно удовлетворяться одно из разделяемых с помощью OR условий;
AND NOT
- когда должно удовлетворяться первое условие и не должно второе;
OR NOT- когда или должно удовлетворяться первое условие или не должно удовлетворяться второе,причем существует приоритет AND над OR (сначала выполняются все операции AND и только после этого операции OR). Для получения желаемого результата WHERE условия должны быть введены в правильном порядке, который можно организовать введением скобок.
При обработке условия числа сравниваются алгебраически - отрицательные числа считаются меньшими, чем положительные, независимо от их абсолютной величины. Строки символов сравниваются в соответствии с их представлением в коде, используемом в конкретной СУБД, например, в коде ASCII. Если сравниваются две строки символов, имеющих разные длины, более короткая строка дополняется справа пробелами для того, чтобы они имели одинаковую длину перед осуществлением сравнения.
Наконец, синтаксис фразы GROUP BY имеет вид
GROUP BY [таблица.]столбец [,[таблица.]столбец] ... [HAVING фраза]
GROUP BY инициирует перекомпоновку формируемой таблицы по группам, каждая из которых имеет одинаковое значение в столб-цах, включенных в перечень GROUP BY. Далее к этим группам применяются агрегирующие функции, указанные во фразе SELECT, что приводит к замене всех значений группы на единственное значение (сумма, количество и т.п.).
С помощью фразы HAVING (синтаксис которой почти не отличается от синтаксиса фразы WHERE)
HAVING [NOT] HAVING_условие [[AND|OR][NOT] HAVING_условие]...
можно исключить из результата группы, не удовлетворяющие заданным условиям:
значение { = | | < | | >= } { значение | ( подзапрос )
| SQL_функция }
{значение_1 | SQL_функция_1} [NOT] BETWEEN
{значение_2 | SQL_функция_2} AND {значение_3 | SQL_функция_3}
{значение | SQL_функция} [NOT] IN { ( константа [,константа]... )
| ( подзапрос ) }
{значение | SQL_функция} IS [NOT] NULL
[таблица.]столбец [NOT] LIKE 'строка_символов' [ESCAPE 'символ']
EXISTS ( подзапрос )
Все выборки информации из базы данных SQL осуществляются с помощью команды SELECT.
Пример запроса на выборку информации по фирмам (фрагмент файла Srch_org.asp):
.......
SQL = "SELECT OrgID, ShortName, Address, Tel1 FROM Org WHERE Visible = 1 ORDER BY ShortName".
.......
Запрос на выдачу подробной информации о фирмах: (фрагмент файла Srch_org.asp):
Header
= Header & "
" & Encode( "Результат
расширенного
поиска:"
) & ""
Name = SEARCH.Item( "TXT" )
Name_Prec = SEARCH.Item( "TXT_PREC" )
Address = SEARCH.Item( "ADDRESS" )
Address_Prec = SEARCH.Item( "ADDRESS_PREC" )
TypeOrg = SEARCH.Item( "TYPE" )
Phone = SEARCH.Item( "PHONE" )
Phone_Prec = SEARCH.Item( "PHONE_PREC" )
Fax = SEARCH.Item( "FAX" )
Fax_Prec = SEARCH.Item( "FAX_PREC" )
FaxRek = SEARCH.Item( "APPENDIX" )
FaxRek_Prec = SEARCH.Item( "APPENDIX_PREC" )
SQL = "SELECT OrgID, ShortName, Address, Tel1 FROM Org WHERE Visible = 1"
If Name "" Then
Header
= Header & "
" &
Encode( "Наименование
" ) & ""
If Name_Prec = 1 Then
Header = Header & Encode( "содержит " )
Else
Header = Header & Encode( "начинается с " )
End If
Header = Header & """" & Name & """"
If Name_Prec = 1 Then
Name = "%" & Name & "%"
Else
Name = Name & "%"
End If
SQL = SQL & " AND ( ( ShortName Like '" & Name & "' ) OR ( FullName Like '" & Name & "' ) )"
End If
If Address "" Then
Header
= Header & "
" &
Encode( "Адрес
" ) & ""
If Address_Prec = 1 Then
Header = Header & Encode( "содержит " )
Else
Header = Header & Encode( "начинается с " )
End If
Header = Header & """" & Address & """"
If Address_Prec = 1 Then
Address = "%" & Address & "%"
Else
Address = Address & "%"
End If
SQL = SQL & " AND ( Address Like '" & Address & "' )"
End If
В результате поиска на экране пользователя появляется следующая информация:
Рис.7 Информация по выборке - организации.
Распечатка листингов запросов к базе данных приведена в приложении.
Тестирование и отладка.
В ходе тестирования, были выявлены некоторые ошибки работы программы обработки. Все они устранены. Результатом разработки явилась полностью работоспособная база данных компании "Телефонная Коммерческая Служба 008".
Помимо работ, связанных с отладкой программ, проводилось так же тестирование базы данных на предмет быстродействия. Быстродействие зависит от многих составляющих системы. Сюда можно отнести:
быстродействие самого компьютера-сервера баз данных;
быстродействие операционной системы и WEB-сервера (MS IIS в данном случае);
быстродействие выбранного сервера баз данных;
объём базы данных;
конечно же скорость соединения с Internet.
Для объективного оценивания быстродействия первые два пункта не рассматривались.
По оценкам экспертов из уважаемого издания «СУБД», сервер баз данных Microsoft SQL Server 7.0 на сегодняшний день является одним из самых мощных и производительных решений на сегодняшний день на платформе Windows NT. Собственно тестирование производилось по критерию объёма.
Как показали испытания, даже большой объём базы (более 3000 записей) не увеличивал сильно время выдачи результата. Когда как реализация этого же проекта средствами Microsoft Access приводила к большому времени ожидания выдачи результата. Выигрыш в скорости выдачи выборки даже визуально был велик. Хотя и так известно, что Access не предназначен для больших баз данных.
По результатам тестирования, можно сказать, что переход на более производительную СУБД MSSQL 7.0 оправдался.
Заключение.
Оглавление.
Выбор темы для дипломного проектирования…………………………………....4
Разработка технического задания на дипломное проектирование…………...5
Выбор методов и средств решения…………………………………………………5
Выбор сервера баз данных……………………………………………………………………...5
Выбор методов доступа к базе данных………………………………………………………13
3.2.1 CGI – Common Gateway Interface………………………………………………………………14 3.2.2 PHP - Personal Home Page Tools………………………………………………………………14 3.2.3 ISAPI
– приложения………………………………………………………………………………15 3.2.3.1 dBWeb…………………………………………………………………………………………..15 3.2.3.2 IDC……………………………………………………………………………………………….17
3.2.3.3 ADO – Active Data Objects……………………………………………………………………18
Похожие работы
... Java-совместимом Web-обозревателе. Необходимо использовать обозреватель, имеющий поддержку JDK (Java Development Kit √ стандарт Java) версии 1.1.x или выше. 3.2 Технология доступа к базам данных на стороне сервера с использованием механизма CGI В соответствии с идеологией CGI-интерфейсов, вся функциональность размещается на сервере приложений. Ее реализует один или несколько CGI-скриптов, ...

... Java, JavaScript и встроенные в сервер средства LiveConnect. Более мощными реляционными возможностями доступа к базе данных и более эффективным выполнением виртуальной Java-машины будут расширены услуги разработки приложений, обеспечиваемых в Enterprise Server 2.0,. Сервис управления. В дополнение к использованию встроенной машины каталога LDAP Enterprise Server 2.0 будет управляем через общие ...

... поставленной задачи показала правильность выбранного подхода. Тем не менее, работа требует дальнейше доработаки для организации постоянного доступа читателей к библиографическим ресурсам библиотекам города через Интернет. Литература 1. Глушаков С.В., Ломотьков Д.В. Базы данных: Учебный курс. – К.: Абрис, 2000. -504с. 2. Джейсон Мейнджер. Java: основы программирования :Пер ...
... данных означает, что в распределенной системе могут мирно сосуществовать СУБД различных производителей, и возможны операции поиска и обновления в базах данных различных моделей и форматов. распределённая база данные компьютерный 3 Проблемы распределенных баз данных Исходя из определения Дэйта, распределенную базу данных в общем случае можно рассматривать как слабосвязанную сетевую структуру, ...
0 комментариев