Навигация
3.3. Задача построения ФРО.
Для того, чтобы более правильно и экономно построить нейронную сеть ФРО, необходимо понять смысл или “концепцию” [Turchin] формируемых образов, т.е., более точно выражаясь, найти для данного образа множество обучающих входных фильмов или множество всех таких реализаций входных процессов, которые приводят к обучению данного нейрона или формированию данного образа. Введем понятие обучающего входного фильма.
Определение 3.3.1. Всякий входной фильм назовем обучающим для нейрона , если - начальный момент времени работы системы и , .
Таким образом, задачу построения НС ФРО можно сформулировать следующим образом: для данной совокупности входных фильмов построить такую сеть, в которой бы присутствовали нейроны, для которых данные входные фильмы являются обучающими. Построенная таким образом сеть способна решать эталонную задачу классификации, где в качестве эталонов используются данные входные фильмы. Известно множество способов конструирования и настройки сетей для классических формальных моделей нейронов, например, сети обратного распространения, использующие обобщенное -правило. Проблема предлагаемого подхода состоит в том, что 1) система должна быть автономной, а значит отсутствует “учитель”; 2) вообще говоря, a priori не известны все жизненно необходимые для системы образы. Но если мы обладаем априорной информацией об условиях существования системы (что почти всегда бывает), ее следует использовать при конструировании ФРО.
Можно иначе сформулировать задачу построения ФРО. Приведем пример с системой “Пилот” [Диссер, Жданов9]. В математической модели спутника используются величины углового положения спутника и его производной , следовательно, очевидно, что всевозможные сочетания возможных значений этих величин (т.е. некоторая область на фазовой плоскости) необходимы для нахождения законов управления системой. Действительно, допустим система в момент времени t находится в состоянии и УС выбирает некоторое управляющее воздействие (включение одного из двигателей, например). Мы знаем, что в момент времени система окажется в некотором состоянии, соответствующем точке на фазовой плоскости с некоторой вероятностью , где - точка на фазовой плоскости, таким образом, можно говорить о некотором вероятностном распределении , заданном в фазовом пространстве и характеризующем предсказание поведения системы через интервал при выборе воздействия в момент времени t. Если бы параметров было недостаточно для описания законов управления, то функция распределения зависела бы еще и от других параметров, и при одних и тех же величинах принимала бы другие значения в зависимости от значений неучтенных параметров. Следовательно, УС не смогла бы найти никакого закона управления, поскольку система ищет статистически достоверную корелляцию между наблюдаемым состоянием ОУ, выбранным действием и состоянием ОУ через некоторый интервал времени. Законом управления здесь мы назовем совокупность функций распределения для каждого управляющего воздействия , где находится в некотором диапазоне. Найденный УС закон управления отобразится в некотором внутреннем формате в БЗ, причем он может быть получен в процессе обучения системы в реальных условиях прямо во время работы, либо на тестовом стенде, “на земле”. Следовательно, можно сказать, что задача построения ФРО состоит в конструировании образов, соответствующих необходимому набору параметров, описывающих состояние системы, и их комбинациям, необходимым для нахождения закона управления. Нахождению таких образов может помочь математическая модель объекта управления, если таковая имеется.
3.4. Распознавание пространственно-временных образов.
Определение 3.4.1. Всякую совокупность значений реализации входного процесса в некоторые выбранные интервалы времени будем называть пространственно-временным образом (ПВО).
Отметим, что один нейрон способен распознавать (т.е. способен обучиться выделять конкретный ПВО среди всех остальных) только те ПВО, у которых единичное значение сигнала для каждой выбранной компоненты входного процесса встречается не более одного раза (пример изображен на верхнем графике рис. 3.4.1). Сеть нейронов можно построить так, что в ней будут формироваться любые заданные ПВО (нижний график рис. 3.4.1).
Рис 3.4.1.
4. База знаний.
Процесс накопления знаний БЗ в рамках методологии ААУ подробно рассмотрен в [Диссер], [Жданов4-8]. В данном разделе мы опишем лишь основные отличия от указанных источников.
Рассмотрим общий алгоритм формирования БЗ. Основная цель алгоритма состоит в накоплении статистической информации, помогающей установить связь между выбранными управляющей системой воздействиями на среду и реакцией среды на эти воздействия. Другая задача алгоритма состоит в приписывании оценок сформированным образам и их корректировки в соответствии с выходным сигналом блока оценки состояния.
Определение 4.1. Будем называть полным отсоединением ФРО от среды следующее условие: процессы и являются независимыми. Вообще говоря, в действующей системе, конечно же эти процессы зависимы, например, в простом случае без блока датчиков , но для введения некоторых понятий требуется мысленно “отсоединить” входной процесс и процесс среды.
Определение 4.2. Назовем временем реакции среды на воздействие число , где случайные величины и являются зависимыми при полном отсоединении ФРО от среды. Закономерностью или реакцией среды будем считать зависимость от .
Другими словами, время реакции среды это время, через которое проявляется, т.е. может быть распознана блоком ФРО, реакция на воздействие.
Пример 4.1. = . Очевидно, что здесь .
Определение 4.3. Назовем минимальной и максимальной инертностью среды минимальное и максимальное соответственно время реакции среды на воздействие для всех . Интервал будем называть интервалом чувствительности среды.
Заметим, что .
Введем совокупность образов
. (4.1)
Параметр n > 0 назовем запасом на инертность среды. Смысл состоит в том, что если обучен, в текущий момент времени распознан образ и УС выберет воздействие то с некоторой вероятностью через n шагов распознается образ . Аналогично введем образ
, (4.2)
смысл которого совпадает со смыслом , с тем лишь различием, что не распознается, а вытеснится. Поскольку в конечном итоге способом управления УС является вызов определенных образов и вытеснение других, то совокупность обученных образов является материалом, способствующим достижению цели управления, то есть вызову или вытеснению определенных образов посредством выбора воздействия из множества возможных воздействий Y на каждом шаге t. Как используется этот материал будет изложено в разделе “Блок принятия решений”.
Запас на инертность введен из следующих соображений. Совершенно очевидно, что бесполезно пытаться уловить закономерность вида “был распознан образ , применили и через m шагов получили ”, где , так как среда будет просто не успевать отреагировать. Таким образом, УС может уловить закономерности со временем реакции среды не большим чем n. Аналогично, нет смысла выбирать n слишком большим, т.е. гораздо большим, чем . С другой стороны, используя синаптические задержки входных сигналов в нейроне, мы можем отловить любую закономерность со временем реакции меньшим либо равным запасу на инертность. Действительно, мы можем построить ФРО так, чтобы образы и формировались с нужными задержками , где m – время реакции среды. Заметим, что a priori нам неизвестно время реакции среды m, поэтому имеет смысл лишь выбрать параметр n для всех образов одинаковым и “наверняка” большим чем (для этого необходимо воспользоваться априорной информацией о среде).
Теперь сопоставим каждому образу из ФРО некоторое число или оценку. Пусть – выход блока оценки состояния, а – оценка образа , получающаяся по следующему алгоритму:
, ,
где – некоторая “усредняющая” функция, - множество моментов времени, в которые образ был распознан. В качестве обычно берется просто среднее арифметическое
.
Теперь можно определить, что такое база знаний.
Определение 4.4. Назовем базой знаний совокупность сформированных образов и совокупность оценок для всех образов ФРО.
Определение 4.5. Обозначим объединение множеств всех образов (4.1) и (4.2) через , где F – множество образов ФРО, Y – множество возможных воздействий. Назовем B пространством образов БЗ.
Похожие работы
... , бистабильность восприятия. В дальнейшем планируется разработка программных моделей более сложных нейронных сетей и их комбинаций с целью получения наиболее эффективных алгоритмов для задачи распознавания образов. Литераура. 1.Горбань А.Н.,Россиев Д.А..Нейронные сети на персональном компьюере. 2. Минский М.Л.,Пайперт С..Персепроны.М.: Мир.1971 3. Розенблатт Ф.Принципы ...
... того привлекает огромный запас контекстных знаний, который системам распознавания образов пока недоступен. 7. Заключение Дан обзор различных нейросетевых методов распознавания изображений. Рассмотрены достоинства и недостатки этих методов при распознавании двумерных и трёхмерных объектов. Указаны проблемы при распознавании трёхмерных объектов. Выделены перспективные направления в распознавании ...
... в популяциях, которые являются существенными для развития. Точный ответ на вопрос: какие биологические процессы существенны для развития, и какие нет? - все еще открыт для исследователей. Реализация генетических алгоритмов В природе особи в популяции конкурируют друг с другом за различные ресурсы, такие, например, как пища или вода. Кроме того, члены популяции одного вида часто конкурируют ...
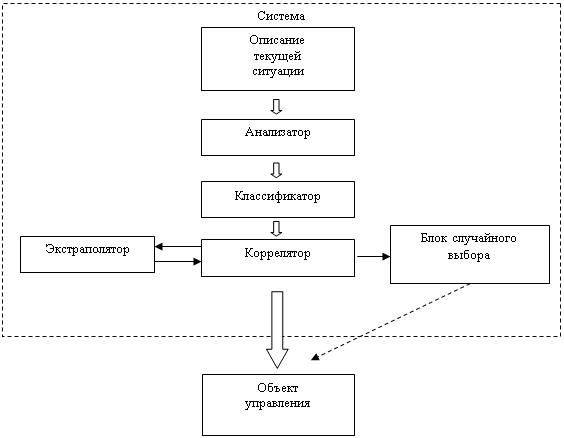
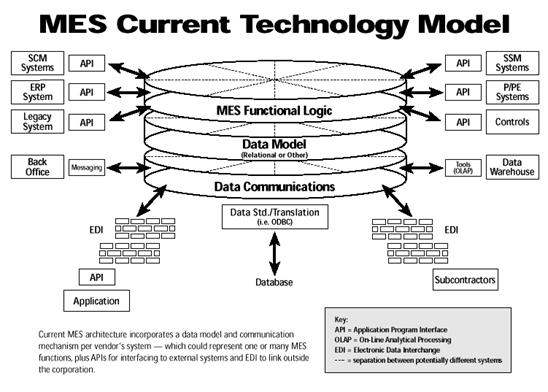
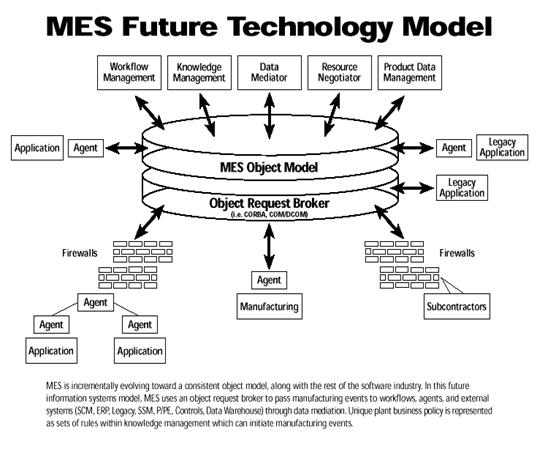
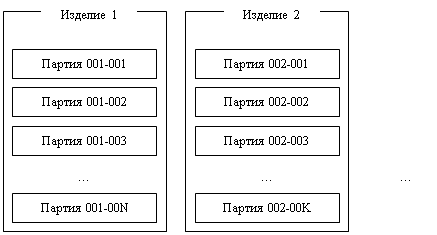
... на дипломное проектирование. Необходимо разработать программу регистрации процеса производства партий полупроводниковых пластин для использования в автоматизированной системе управления. Программа должна обеспечивать контроль и регистрацию производственного процесса производства партий пластин. Вести учет за прохождением партий полупроводниковых пластин по технологическому маршруту. Разработку ...
0 комментариев