Навигация
3.3 Реализации MPI
Библиотеки MPI реализованы практически на всех современных суперкомпьютерах, к примеру, в университете Коимбра (Португалия) разработали библиотеку MPI для Windows 95 (http://pandora.uc.pt/w32mpi), которая особенно интересна для преподавателей и студентов, поскольку при отладке достаточно иметь обычный ПК, а запуск параллельных приложений в сети позволяет получить реальный выигрыш в производительности.
Практический опыт показывает, что идеально распараллеливаемые задачи, такие как параллельное умножение матриц, можно решать практически на любых сетях, и добавление даже относительно слабых вычислительных узлов дает выигрыш. Другие задачи, в частности решение систем линейных уравнений, более требовательны к коммуникационному оборудованию и качеству реализации передачи сообщений. Именно поэтому тесты для оценки реального быстродействия параллельных вычислительных систем базируются на параллельных аналогах известного пакета Linpack. Так, система линейных уравнений размером 800х800 решается на четырех компьютерах Sun SPARCstation 5, объединенных сетью Ethernet 10 Мбит/c, быстрее, чем на трех; на пяти - приблизительно за то же время, что и на четырех, а добавление шестого компьютера однозначно ухудшает производительность вычислительной системы. Если вместо Fast Ethernet 10 Мбит/c использовать Fast Ethernet 100 Мбит/с, что лишь незначительно увеличивает общую стоимость системы, время, затрачиваемое на коммуникацию, уменьшается почти в 10 раз, а для решения данной задачи можно будет эффективно применять уже десятки рабочих станций.
3.4 Средства программирования высокого уровня
Часто в сетях отдельные компьютеры неравноценны, и имеет смысл нагружать их по-разному, однако даже простейшая программа, учитывающая балансировку нагрузки, - если кодировать ее, используя лишь средства MPI, - становится необъятной, и отладка ее мало кому окажется по силам. Так, матрицы в пакете SсаLAPACK, независимо от решаемой задачи и мощностей вычислительных элементов, всегда распределяются по процессорам равномерно. В результате, при наличии хотя бы одного слабого компьютера в сети, вычисления затягиваются - все ждут отстающего. Динамическая балансировка нагрузки, практически бесплатно получающаяся на SMP-компьютерах, в распределенных системах чрезвычайно трудна, и даже простое распределение данных в соответствии с мощностями узлов и последующие пересылки кодируются весьма непросто.
Выходом из создавшегося положения стали языки программирования, основанные на параллелизме данных. Первый из них, Fortran-D, появился в 1992 г. На смену ему пришел High Performance Fortran (HPF), представляющий собой расширение языка Fortran 90 и требующий от пользователя лишь указать распределение данных по процессорам. В остальном программа имеет последовательный вид (это, впрочем, не означает, что, придумывая алгоритм, не следует задумываться о присущем ему параллелизме). Транслятор самостоятельно распределяет вычисления по процессорам, выбирая в качестве узла, на котором следует производить вычисления, тот процессор, на котором будет использован результат вычисления выражения. При необходимости транслятор генерирует обращения к библиотеке передачи сообщений, например MPI. От компилятора HPF требуется тщательный анализ программы. Пользователь практически не имеет рычагов управления количеством пересылок, а поскольку инициализация каждой пересылки, независимо от объема передаваемой информации, - это десятки тысяч машинных тактов, качество получаемой программы от него зависит слабо.
В языке программирования mpC (http://www.ispras.ru/) - расширении ANSI Cи - принят компромиссный подход. Здесь пользователь распределяет не только данные, но и вычисления. Переменные и массивы распределяются по виртуальным сетям (networks) и подсетям, при этом в описаниях сетей указываются относительные мощности узлов и скорости связей между ними. В процессе выполнения mpC-программы система поддержки языка стремится максимально эффективно отобразить виртуальные сети на группы процессоров. В результате пользователь получает возможность равномерно нагружать узлы
3.5 Попытка прогноза
Использование сетей компьютеров для вычислительных задач - уже сегодня дело вполне реальное. В этом направлении ведутся научные разработки и сделан ряд пилотных проектов. В качестве коммуникационной платформы сейчас наиболее экономически оправдано применение коммутируемых сетей Fast Ethernet. При этом себестоимость системы производительностью 1,5-6 операций с вещественными числами в секунду на задачах линейной алгебры будет ниже 100 тыс. долл. Через пару лет в качестве коммуникационной платформы можно будет использовать Gigabit Ethernet или ATM (Asynchronous Transfer Mode - асинхронный режим передачи), обеспечивающие на порядок более высокие скорости передачи данных. В течение одного-двух лет должны появиться общепризнанные широковещательные протоколы транспортного уровня и основанные на них реализации MPI. На уровне прикладных программ MPI использоваться не будет. На нем станут базироваться лишь некоторые библиотеки и системы поддержки языков, основанные на параллелизме данных.
4 ПИМЕРЫ ИСПОЛЬЗОВАНИЯ СУПЕРКОМПЬЮЮТЕРОВ
4.1 Моделирование построение белка
Корпорация IBM объявила о том, что планирует выделить 100 миллионов долларов на создание самого быстрого в мире суперкомпьютера, который будет использоваться для моделирования построения белка из аминокислот.
Новый суперкомпьютер, носящий название Blue Gene, будет способен совершать один квадриллион операций в секунду, то есть будет в тысячу раз мощнее знаменитого Deep Blue, с которым в 1997 году играл в шахматы чемпион мира Гарри Каспаров.
Blue Gene будет работать на основе более миллиона процессоров, каждый из которых способен совершать миллиард операций в секунду, сообщают представители IBM. Новый гигант будет в два миллиона раз быстрее, чем существующие сегодня мощнейшие персональные компьютеры.
Исследователи рассчитывают достигнуть этого уровня мощности в течение пяти лет, по истечении которых суперкомпьютер будет использоваться в генетическом моделировании. Если Blue Gene оправдает возложенные на него надежды, его создание станет огромным шагом вперед в области здравоохранения и биологии.
4.2 Виртуальная башня
По оценкам Федерального управления гражданской авиации США, в течение ближайших 20 лет количество самолетов, используемых для коммерческих полетов, увеличится вдвое. Это станет серьезным испытанием для авиадиспетчеров, которым придется внедрять новые технологии управления авиационными потоками как на земле, так и в воздухе.
НАСА решило внести свою скромную лепту в преодоление этой проблемы и создало симулятор настоящей башни авиадиспетчеров стоимостью в $110 миллионов. Башня FutureFlight Central расположена в Исследовательском центре Эймса НАСА. Она дает возможность симулировать работу крупнейших аэропортов мира, позволяя в реальном времени испытывать новые технологии управления перемещением самолетов. Это двухэтажное сооружение, в котором могут одновременно работать 12 операторов. Мозговым центром башни является 16-процессорный суперкомпьютер Reality Monster от SGI, обошедшийся НАСА в $1 миллион. Именно он обеспечивает вывод симуляции на 12 огромных видеоэкранов башни, имитирующих настоящие окна. Суперкомпьютер позволяет моделировать - помимо обстановки аэропорта - погодные эффекты и до 200 одновременно движущихся самолетов и машин наземного обслуживания. Первый этаж предназначен для "пилотов" и "обслуживающего персонала", которые будут вносить дополнительный элемент реалистичности, общаясь с авиадиспетчерами с помощью портативных радиостанций. Башня также может использоваться и в других симуляционных целях. В частности, планируется, что ее услугами смогут воспользоваться специалисты из Отделения автономных роботов НАСА для создания комнат управления межпланетными миссиями, состоящими из роботизированных машин.
ИСПОЛЬЗУЕМАЯ ЛИТЕРАТУРА:
1. Статья Андрея Шитова «Электронный супермозг», журнал «Эхо планеты» №4 1992г.
2. Статья Дмитрия Арапова «Можно ли превратить сеть в суперкомпьютер?», журнал «Открытые системы» №4 1997г.
3. Статья Н. Дубовой «Суперкомпьютеры nCube», журнал «Открытые системы»
4. Рубрика «Новости» из журналов КомпьюТерра
Похожие работы
... производительностью от 20 до 80 MFLOPS. Спрос на эти машины превзошел все ожидания. Явно рискованные инвестиции в программу Convex обернулись быстрым и солидным доходом от ее реализации. История развития суперкомпьютеров однозначно показывает, что в этой сложнейшей области инвестирование высоких технологий, как правило, дает положительный результат - надо только, чтобы проект был адресован ...
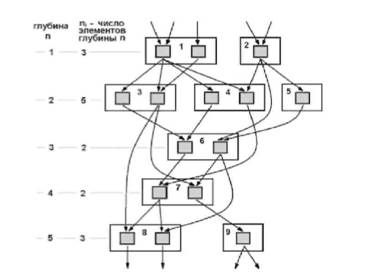
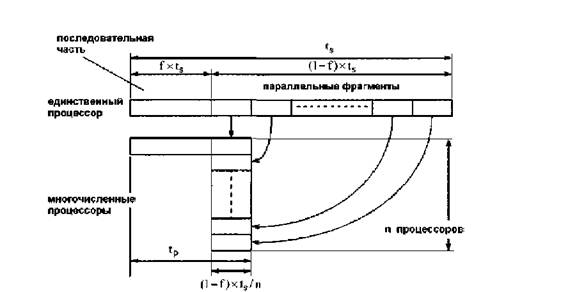
... 5k управления ресурсами (программно-аппаратный комплекс) массивно-параллельного компьютера обязана обрабатывать подобные ситуации в обход катастрофического общего рестарта с потерей контекста исполняющихся в данный момент задач. 2.4.1 Массивно-параллельные суперкомпьютеры серии CRY T3 Основанная в 1972 году фирма Cry Research Inc. (сейчас Cry Inc.), прославившаяся разработкой векторного ...
... создавать суперкомпьютеры, на сборку которых раньше уходили годы, причем их стоимость также значительно уменьшается. Эту тенденцию невозможно игнорировать, поскольку сегодня суперкомпьютеры, ранее доступные только для проектов с огромными бюджетами, могут использоваться в самых разных областях». Самая высокопроизводительная кластерная система в мире Используемый в Национальной лаборатории им. ...
... руководил в НИИ «Квант» разработкой суперпроизводительных проблемно-ориентированных систем, а затем созданием мультипроцессорной вычислительной системы МВС-100 и последовавшего за ней суперкомпьютера МВС-1000. Создание суперпроизводительных ЭВМ остается стратегическим фактором технологического лидерства индустриально развитых стран, показателем интеллектуального потенциала общества. Такие ...
0 комментариев