С.В. Усатиков, кандидат физ-мат наук, доцент; С.П. Грушевский, кандидат физ-мат наук, доцент; М.М. Кириченко, кандидат социологических наук
Во многих практических задачах мы исследуем объекты, обладающие несколькими (двумя или более) признаками, и хотим выяснить, насколько эти признаки связаны между собой. Например, у каждого человека есть возраст и место рождения, уровень образования и годовой доход, пол и социальная принадлежность и т.п. Вопрос состоит в том, можно ли по степени выраженности одного признака судить о степени выраженности другого, либо же знание об одном ничего не добавляет к знанию о другом (т.е. эти признаки проявляются независимо друг от друга). Ответы на такие вопросы могут иметь значительную практическую ценность. Например, если мы установим, что признаки “профессия” и “политические убеждения” независимы, то социологические опросы по предсказанию результатов выборов можно проводить без учета профессии опрашиваемых.
Прежде всего следует дать определение интуитивно понятной вероятностной независимости. А именно, случайное событие А независимо от случайного события В, если вероятность одновременного появления и события А, и события В в опыте равна произведению вероятностей этих событий.
Иногда признаки связаны жестко: если профессия - горняк или сталевар, то пол, несомненно, мужской. Тем самым по некоторым значениям признака “профессия” можно узнать значение признака “пол”. Другая крайность - отсутствие связи: если глаза серые, то какая профессия? Исследователя в подобных задачах интересует, насколько точно можно предсказать значение одного признака по значению другого. Этой проблеме должна предшествовать более простая: надо сначало проверить существует ли вообще какая-либо связь между этими признаками? Таким образом, возникает и требует проверки следующая нулевая гипотеза: проявления одного признака независимы от проявлений другого в опыте.
Отметим еще одно важное обстоятельство. Ведь необходимо исследуемые признаки как-то измерить, представить в виде делений какой-то шкалы, и очень часто это не деления секундомера или линейки. Как измерить” профессию”, “политические убеждения” или “степень доверия”? Если присвоить проявлениям признака какие-либо числовые значения, очень часто эти числа нельзя даже упорядочить по возрастанию.
Заметим еще также, что к проверке независимых признаков очень часто можно свести задачу однофакторного анализа об отсутствии эффекта обработки. Тогда одним признаком становится отклик, а другим - способ обработки. Причем в отличие от рассмотренного в предыдущем пункте критерия Вилкоксона, Манна и Уитни, способов обработки может быть и два, и три, и больше трех.
Пусть первый признак имеет шкалу х1,...,хк. Например, признак “лекарство” может быть х1=“первое”, х2=“второе”, х3=“третье”. Второй признак имеет шкалу у1,...,уl. Например, признак “результат” может быть у1=“благоприятный” или у2=“неблагоприятный”
Проведено n экспериментов, в которых nij ряд деления шкал xi (1Ј iЈ k) и y1 (1Ј jЈ l) появились вместе. Эти числа nij удобно записать в виде таблицы сопряженности признаков размера k· l.
Например:
| результат yi | первое= х1 | второе=х2 | третье= х3 | всего |
| у1=благоприятный | 29=n11 | 38=n21 | 53=n31 | 120=N1 |
| у2=неблагоприятный | 1=n12 | 2=n22 | 7=n32 | 10=N2 |
| всего | 30=n1 | 40=n2 | 60=n3 | 130=n |
Здесь “лекарство” можно трактовать как способ обработки, а “результат” как отклик. Отсутствие эффекта обработки означает, что все эти три лекарства действуют одинаково и признаки независимы.
В этом примере проведено n =130 экспериментов, в которых n11=29 раз первое лекарство помогло,n12=1 раз от первого лекарства стало хуже и т.п.
Обозначим ni (1Ј iЈ k) сумму чисел по столбцам таблицы, а Nj (1Ј jЈ l) сумму чисел по строкам таблицы. В данном примере n1 =30 по первому столбцу, n2=40 по второму столбцу, N1=120 по первой строке и т.п. Ясно, что ni/n есть оценка вероятности появления деления xi шкалы, а Nj/n - вероятность для yj. В свою очередь nij/n есть оценка вероятности одновременного появления делений xi и yj на шкалах первого и второго признаков.
Требуется проверить нулевую гипотезу о независимости признаков.
Прежде всего назначим уровень значимости a - вероятность ошибочно отвергнуть правильную нулевую гипотезу. Теперь будем искать то явление, чья вероятность при верной нулевой гипотезе мала и равна a . Если в опыте это явление происходит, то мы смело отвергаем нулевую гипотезу (с риском ошибки a ).
По определению вероятностной независимости, в ячейках таблицы сопряженности признаков должны стоять (при верной нулевой гипотезе) следующие числа Nij:
![]() или
или ![]()
которые мы называем ожидаемыми частотами. Если Nij и nij не совпадают, это еще ничего не означает, т.к. такие отклонения могут быть вызваны случайностью. Числа nij являются суммой большего числа случайных величин - отдельных испытаний, поэтому по центральной предельной теореме они пожчиняются нормальному закону (рис.1). Можно доказать, что средняя m этого нормального закона равна ожидаемой частоте Nij, а среднее отклонение: s =Ц Nij. Следовательно числа
![]()
подчиняются Z- закону Гаусса, а число
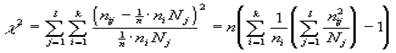
подчиняется c 2-закону Пирсона с n =(к-1)(L-1) степенями свободы (рис.2). Практически должно быть для ожидаемых частот Nij і 4, а если n і 8 и n і 40, то можно Nij і 1. В противном случае необходимы соответствующие строки и столбцы объединить с соседними стороками и столбцами таблицы сопряженности признаков.
Вспомнив правило “трех s ” для c 2-закона, можно сказать, что при a =0,1 величина c 2Ј n +![]() . Таким образом, при уровне значимости 10% (т.е. с риском ошибиться в 1 случае из 10) гипотеза о независимости признаков отвергается, если подсчитанное числоc 2> n +
. Таким образом, при уровне значимости 10% (т.е. с риском ошибиться в 1 случае из 10) гипотеза о независимости признаков отвергается, если подсчитанное числоc 2> n +![]() . В противном случае наблюдения не противоречат гипотезе о независимости.
. В противном случае наблюдения не противоречат гипотезе о независимости.
Заметим, что при других уровнях значимости a величину критического значения c 2 необходимо брать из таблиц распределения Пирсона в статистических справочниках или учебниках.
Вернемся к нашему примеру. Считаем по формуле c 2:
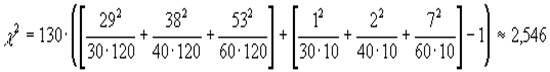
Число степеней свободы n =(2-1)(3-1)=2, следовательно критическое значение c 2 равно n +![]() =4. Поскольку вычисленное c 2» 2,5 не превосходит критического 4, нулевая гипотеза о независимости не может быть отвергнута, т.е. все три лекарства действуют примерно одинаково.
=4. Поскольку вычисленное c 2» 2,5 не превосходит критического 4, нулевая гипотеза о независимости не может быть отвергнута, т.е. все три лекарства действуют примерно одинаково.
Список литературы
Для подготовки данной работы были использованы материалы с сайта http://mschool.kubsu.ru
Похожие работы
... данных и по внедрению накопленного арсенала современных методов прикладной статистики. По нашему мнению, широкого внедрения заслуживают, в частности, методы многомерного статистического анализа, планирования эксперимента, статистики объектов нечисловой природы. Очевидно, рассматриваемые работы должны быть плановыми, организационно оформленными, проводиться мощными самостоятельными организациями и ...
... вызывает негативные ассоциации. Изначальное определение интроверсии, однако, не содержит оценочной характеристики. Таблица 1. Холерики Номер опрашиваемого Темперамент по тесту Г. Айзенка Тип личности по тесту Г. Айзенка Авторский опросник Лейни. М 1 холерик экстраверт экстраверт 2 холерик интроверт экстраверт 3 холерик ...
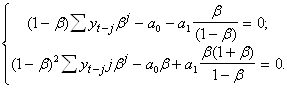
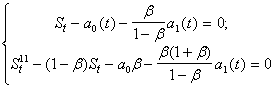

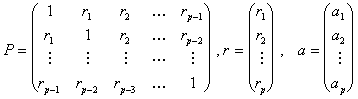
... последовательность случайные величины распределены одинаково, так что определенный выше процесс белого шума является стационарным. 7.Числовые характеристики случайной составляющей При анализе временных рядов используются числовые характеристики, аналогичные характеристикам случайных величин: – математическое ожидание (среднее значение процесса) ; – автоковариационная функция ; ...
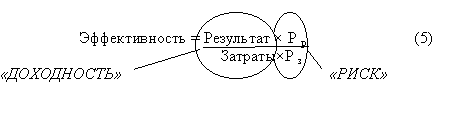
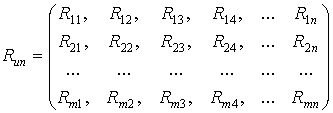
... риска и его сложных взаимосвязях говорит тот факт, что даже решение минимизации риска содержит риск. На основе данного анализа автор предлагает определение риска инвестиционного проекта, которое отражает сущность одноимённой концепции: Риск ИП (Rип ) – это система факторов, проявляющаяся в виде комплекса рисков (угроз), индивидуальных для каждого участника ИП, как в количественном так и в ...
0 комментариев