Навигация
Автоматическое распознавание текстов
59645
знаков
0
таблиц
0
изображений
1.3. Автоматическое распознавание текстов
После обработки документа сканером получается графическое изображение документа (графический образ). Но графический образ еще не является текстовым документом. Человеку достаточно взглянуть на лист бумаги с текстом, чтобы понять, что на нем написано. С точки зрения компьютера, документ после сканирования превращается в набор разноцветных точек, а вовсе не в текстовый документ.
Проблема распознавания текста в составе точечного графического изображения является весьма сложной. Подобные задачи решают с помощью специальных программных средств, называемых средствами распознавания образов. Реальный технический прорыв в этой области произошел лишь в последние годы. До этого распознавание текста было возможно только путем сравнения обнаруженных конфигураций точек со стандартным образцом (эталоном, хранящимся в памяти компьютера). Авторы программ задавали критерий «похожести», используемый при идентификации символов.
Подобные системы назывались OCR (Optical Character Recognition – оптическое распознавание символов) и опирались на специально разработанные шрифты, облегчавшие такой подход. Если приходилось сталкиваться с произвольным и, тем более, сложным шрифтом, программы такого рода начинали давать серьезные сбои.
Современные научные достижения в области распознавания образов буквально перевернули представление об оптическом распознавании символов. Современные программы вполне могут справляться с различными (и весьма вычурными) шрифтами без перенастройки. Многие распознают даже рукописный текст.
1.3.1. Программы распознавания текстов
Поскольку потребность в распознавании текста отсканированных документов достаточно велика, неудивительно, что имеется значительное число программ, предназначенных для этой цели. Так как разные научные методы распознавания текста развивались независимо друг от друга, многие из этих программ используют совершенно разные алгоритмы.
Эти алгоритмы могут давать разные результаты на разных документах. Например, упоминавшиеся выше системы OCR, способны распознавать только стандартный специально подготовленный шрифт и дают на этом шрифте наилучшие результаты, которые не может превзойти ни одна из более универсальных программ.
Современные алгоритмы распознавания текста не ориентируются ни на конкретный шрифт, ни на конкретный алфавит. Большинство программ способно распознавать текст на нескольких языках. Одни и те же алгоритмы можно использовать для распознавания русского, латинского, арабского и других алфавитов и даже смешанных текстов. Разумеется, программа должна знать, о каком алфавите идет речь.
Нас, прежде всего, интересуют программы, способные распознавать текст, напечатанный на русском и украинском языках. Такие программы выпускаются в основном российскими производителями. Наиболее широко известны и распространены программы FineReader и CuneiForm. Мы подробно остановимся на программе FineReader, обеспечивающей высокое качество распознавания и удобство применения.
1.3.2. Программа FineReader
Программа FineReader выпускается российской компанией ABBYY Software (www.bitsoft.ru). Эта программа предназначена для распознавания текстов на русском, английском, немецком, украинском, французском и многих других языках, а также для распознавания смешанных двуязычных текстов.
Программа имеет ряд удобных возможностей. Она позволяет объединять сканирование и распознавание в одну операцию, работать с пакетами документов (или с многостраничными документами) и с бланками. Программу можно обучать для повышения качества распознавания неудачно напечатанных текстов или сложных шрифтов. Она позволяет редактировать распознанный текст и проверять его орфографию.
FineReader работает с разными моделями сканеров. В частности, программа поддерживает стандарт TWAIN. Мы рассмотрим программу на примере версии 4.0, одной из последних версий на данный момент.
2. Распознавание документов в программе finereader
2.1. Окно программы
После установки программы FineReader в меню «Программы» Главного меню появляются пункты, обеспечивающие работу с ней. Окно программы имеет типичный для приложений Windows9Х вид и содержит строку меню, ряд панелей инструментов и рабочую область.
В левой части рабочей области располагается панель «Пакет», содержащая список графических документов, которые должны быть преобразованы в текст. Эти графические файлы рассматриваются как части одного документа. Результаты их обработки в дальнейшем объединяются в единый текстовый файл. Форма значка, отмечающего исходные файлы, указывает, было ли произведено распознавание.
Панель в нижней части рабочей области содержит фрагмент графического документа в увеличенном виде. С ее помощью можно оценить качество распознавания. Эту панель используют также при «обучении» программы в ходе распознавания текста.
Остальную часть рабочей области занимают окна документов. Здесь располагается окно графического документа, подлежащего распознаванию, а также окно текстового документа, полученного после распознавания.
В верхней части окна приложения под строкой меню располагаются панели инструментов. На приведенном рисунке включено отображение всех панелей, которые могут использоваться в программе FineReader.
Панель инструментов «Стандартная» содержит кнопки для открытия документов и для операций с буфером обмена. Прочие кнопки этой панели служат для изменения представления документа.
Панель «Scan&Read» содержит кнопки, соответствующие всем этапам превращения бумажного документа в электронный текст. Первая кнопка позволяет выполнить такое преобразование в рамках единой операции. Остальные кнопки соответствуют отдельным этапам работы и содержат раскрывающиеся меню, служащие для управления соответствующей операцией.
Панель «Распознавание» позволяет указать язык документа и вид шрифта. Последнее требуется делать только в тех случаях, когда документ имеет недостаточное качество печати.
Панель «Инструменты» используют при работе с исходным изображением. В частности, она позволяет управлять сегментацией документа. С помощью элементов управления этой панели задают последовательность фрагментов текста в итоговом документе.
Элементы управления панели «Форматирование» используют для изменения представления готового текста или при его редактировании.
Похожие работы
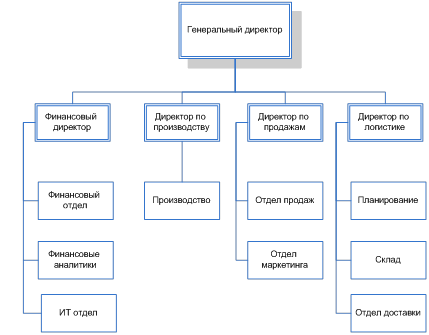

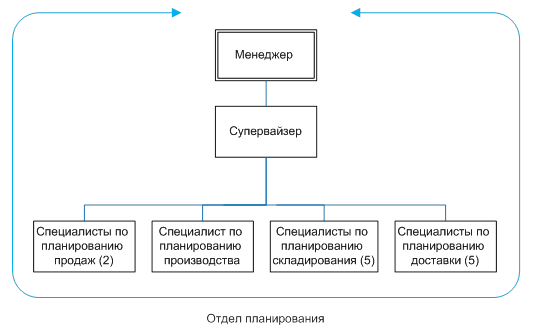
... Евразия»: 1.2.4 Обоснования необходимости использования вычислительной техники для решения задачи Основываясь на данных, полученных из библиотеки компании ООО «Кока-Кола ЭйчБиСи Евразия» из раздела «Организация деятельности подразделений» составим схему документооборота в отделе планирования. Схема представлена на рисунке Рис. 9. Рис. 9. Схема документооборота отдела планирования на ...
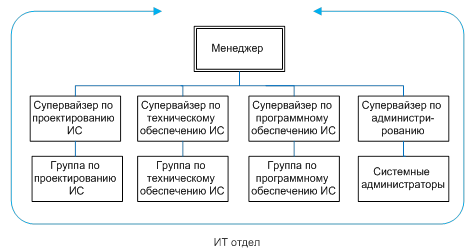
... активно работает целый ряд компаний, предлагающих как самостоятельные продукты, предназначенные для автоматизации отдельных управленческих, проектных и конструкторских задач, так и компании, поставляющие полнофункциональные интегрированные решения, способные охватить весь технологический цикл подготовки производства. Предлагаемые решения можно условно разделить на три больших класса. Легкие САПР ...
... функций, выстраивая описание. QBE-запрос Access легко транслирует в соответствующий SQL-запрос. Обратная операция тоже не составляет труда. Вообще для Access безразлично, с каким типом запроса работает пользователь. Запросы можно создавать с помощью Конструктора запросов. Он ускоряет проектирование нескольких специальных типов запросов. Формуляры Просмотр базы данных в виде таблицы в режиме ...
... работе в СКА - Бесплатно Обучение работе в сети Интернет (час) 10 Бесплатно 10 10 10 Прежде чем перейти к расчету показателей эффективности внедрения автоматизированной информационной системы в офисе туристской компании, сформулируем выводы по проектной части данной дипломной работы. 1. Задачей предварительного моделирования предстоящих этапов внедрения информационных технологий на ...
0 комментариев