Навигация
Журнал регистрации событий Windows NT
126025
знаков
4
таблицы
0
изображений
1. Журнал регистрации событий Windows NT.
Журнал ошибок SQL Server (находится в каталоге '\SQL60\LOG\').
3.Выходные файлы инсталляционных скриптов. В директории '\SQL60\INSTALL\' вы найдете около 20 файлов с расширением '.SQL' (скрипты) и соответствующих им файлов с теми же именами и расширением '.OUT' (выходные файлы). В процессе инсталляции SQL Server выполняет скрипты (они же сценарии) и результаты выполнения записываются в выходные файлы. Просматривая выходные файлы, вы можете обнаружить сообщения об ошибках.
ОПТИМИЗАЦИЯ И НАСТРОЙКА MICROSOFT SQL SERVER
Применительно к современным системам обработки данных в архитектуре клиент-сервер, вопрос о качестве той или иной СУБД так или иначе сводится к вопросу о ее производительности. Ибо средства разработки как серверной, так и клиентской части позволяют сегодня вложить в систему практически любую функциональность и создать самый удобный пользовательский интерфейс, хранить данные любых мыслимых объемов. И только одного нельзя гарантировать - приемлемой скорости выполнения запросов. И большая часть усилий разработчиков сводится к тому, чтобы обеспечить эту самую приемлемую скорость. Поэтому большую часть нашего семинара мы посвятим тому, как спроектировать оптимальное приложение и затем настроить SQL Server так, чтобы приложение работало с достойной вашей фирмы производительностью.
Ключи к производительности
• Структура базы данных;
• Пути доступа к данным;
• Аппаратура;
• Физическое распределение данных;
• Настройка параметров среды и SQL Server
Проектирование базы данных - фундамент производительности
Грамотное проектирование баз данных, по мнению многих специалистов и моему собственному, является наиболее критическим моментом в оптимизации производительности системы, построенной на SQL Server. Если система медленно работает - скорее всего, дело в плохом проектировании структуры таблиц, запросов и индексов. И именно этому следует уделять главное внимание. Следует принимать проектные решения, постоянно задаваясь вопросом - как это решение скажется на производительности? И в первую очередь, здесь важно оптимальное логическое проектирование баз данных.
Логическое проектирование базы данных
Оптимальное логическое проектирование баз данных базируется на применении трех основных методологий:
Моделирование данных;
Нормализация;
3. Разумная денормализация
Моделирование данных
Для моделирования данных традиционно применяется методология диаграмм "Сущность-Связь", которая позволяет построить законченную логическую модель данных, то есть представление в виде связанных таблиц. Существуют различные модификации этой методологии, как правило реализуемые фирмами-производителями CASE-инструментов в своих продуктах. Базовая методология построения диаграмм "Сущность-Связь" зафиксирована в стандарте IDEF1X. Некоторые CASE-инструменты основаны на методологиях, расширяющих возможности этого стандарта. К таким инструментам относится, в частности, S-Designor фирмы Powersoft.
Есть и другие методологии, в частности Объектно-Ролевое моделирование, которое позволяет описывать предметную область на более абстрактном уровне, чем моделирование "Сущность-Связь", по крайней мере базовый вариант последней. Объектно-Ролевое моделирование реализовано в CASE-инструменте InfoModeler фирмы Asymetrix. Применение S-Designor и InfoModeler рассмотрено в докладе "Проектирования структур баз данных с использованием CASE-инструментов S-Designor и InfoModeler".
Нормализация
В процессе построения логической модели осуществляется также нормализация, т.е. построенная модель удовлетворяет требованиям трех уровней нормализации:
1. Первая нормальная форма - отсутствие многозначных полей.
Вторая нормальная форма - каждое неключевое поле в таблице должно зависеть от всего первичного ключа, а не от какой-либо его части.
3. Третья нормальная форма - неключевое поле не должно зависеть от другого неключевого поля.
В сущности, нормализация приводит к большему количеству более узких таблиц в логической модели. Соблюдение правил нормализации снижает избыточность данных и, соответственно, сложность их обновления и занимаемый ими объем на носителе. Связи между полученными таблицами разрешаются через построение сложных соединяющих запросов. Оптимизатор запросов SQL Server умеет строить эффективные планы выполнения запросов, связывающих высоко нормализованные таблицы. Этому способствует также построение индексов, основанное на связи первичных и внешних ключей таблиц.
CASE-инструменты, как правило, строят логическую модель в третьей нормальной форме.
Денормализация
Однако зачастую, разумная, именно разумная, сознательная денормализация логической структуры может повысить скорость выполнения определенных запросов. Если проектирование нормализованной структуры идет, так сказать, "от данных", то денормализация идет "от процессов". То есть, денормализация должна быть основана на знании того, какие действия будут осуществляться с данными при работе с ними клиентских приложений. Вот несколько практических советов по денормализации:
• Если спроектированная база данных требует связывания в одном запросе 4-х и более таблиц, стоит ввести избыточность, добавляя поля в таблицы или целые таблицы.
• Замените длинные ключи на искусственно введенные короткие ключи и текстовые поля на символьные строки ограниченной длины.
• Если определенная группа запросов затрагивает только часть полей широкой таблицы, ее можно разбить на несколько более узких таблиц, продублировав в них первичный ключ исходной таблицы. Это может уменьшить количество операций ввода-вывода и облегчить одновременную работу разных пользователей.
• Если определенная группа запросов затрагивает только часть строк таблицы большого объема, ее можно разбить по горизонтали на несколько таблиц, особенно если определенные группы пользователей обращаются к разным горизонтальным подмножествам таблицы.
Противоречия логического проектирования
Нормализация и денормализация - две диалектически противоречивые стратегии, которые необходимо применять при проектировании логической структуры. И это не единственное противоречие в этом процессе. Например - использование типов данных с переменной длиной приводит, с одной стороны, к сокращению занимаемого дискового пространства, к меньшему количеству операций чтения и, таким образом, к сокращению времени на чтение таблицы. С другой стороны, обновление таких строк происходит путем удаления старой и вставки новой, в то время, как строки с полями фиксированной длины могут обновляться "на месте", что значительно быстрее. Еще один пример - использование большого числа индексов сокращает время выполнения запросов, соединяющих несколько таблиц и сортирующих полученные строки. Но в то же время, индексы замедляют операцию вставки новых записей.
Приложения по обработке данных можно условно разделить на два класса:
• Системы оперативной обработки транзакций, характеризующиеся большой интенсивностью вставки и обновления записей.
• Системы поддержки принятия решений, характеризующиеся сложной обработкой больших объемов данных. Эти приложения, как правило, не обновляют данные, но производят различные суммирования, сортировки и связывают данные из многочисленных таблиц.
Поняв, к какому классу относится ваше приложение, можно делать выбор из противоречивых альтернатив при проектировании логической структуры. Правда, часто приложения должны сочетать качества как одной, так и другой системы, так что приходится находить компромиссы. В этом случае может выручить разделение приложения на две подсистемы, каждая из которых функционирует на своем SQL Server'е, и обеспечение информационной связи подсистем при помощи тиражирования данных.
Проектирование путей доступа
Когда создана структура базы данных, можно проектировать запросы, при помощи которых клиентские приложения будут манипулировать данными на сервере, осуществляя операции выборки, вставки, изменения и удаления данных. Каждый запрос характеризуется определенным путем доступа к данным. В понятие пути доступа входит:
• структура таблицы, к которой обращается запрос;
• поля, по которым происходит поиск;
• индексы, которые можно использовать для ускорения поиска;
• состав полей, которые обновляются в процессе выполнения запроса.
Цель проектирования оптимальных путей доступа - минимизация количества операций чтения/записи при выполнении клиентских запросов. Основа для этого должна быть заложена на этапе проектирования структуры базы данных.
Оптимизация путей доступа
Главный вопрос в оптимизации путей доступа - использование индексов. Если некий запрос выбирает строки в таблице по полю "field1", то при отсутствии индекса по этому полю сервер будет сканировать всю таблицу, что может быть очень "дорого" в терминах операций чтения. Если по полю "field1" построен индекс, то количество операций чтения может сократиться в несколько тысяч раз. Индексы существенны также при операциях соединения таблиц (JOIN) и операциях сортировки.
Какие еще моменты необходимо учитывать при проектировании путей доступа? Это
• обращение клиента к серверу через SQL-запрос или через вызов хранимой процедуры. Второй вариант работает немного быстрее, но необходимо учитывать один важный нюанс. План выполнения хранимой процедуры составляется при ее первом (после создания) вызове и затем хранится в кэше. Этот план оптимизируется для набора параметров и индексной статистики, имевших место именно при первом вызове. При дальнейших вызовах этот план может оказаться неоптимальным, то есть может потребоваться перекомпиляция процедуры, например, путем вызова с опцией "WITH RECOMPILE".
• проведение операций обновления "на месте" или путем удаления с последующей вставкой - обновление "на месте" проходит гораздо быстрее.
• наличие триггеров, срабатывающих на вставку или изменение записи, может существенно замедлить соответствующие операции.
Очевидно, что в процессе проектирования путей доступа может возникнуть необходимость пересмотреть решения, принятые при проектировании структуры данных.
Также очевидно, что при разработке крупных приложений бывает невозможно проанализировать все пути доступа. Сосредоточиться нужно на критических путях доступа, учитывая размер таблиц, частоту обращений к ним и требования к времени выполнения запроса
Аппаратура и производительность
Не случайно аппаратура стоит у нас на 3-м месте среди ключей к производительности. Этим я хотел подчеркнуть важность хорошей структуры и путей доступа. На самом деле, конечно, аппаратура важна не меньше. Прошу простить несколько банальную аналогию, но грамотный проект базы данных, оптимальные пути доступа и быстрый сервер так важны для производительности системы, как опытные водитель и штурман и мощный автомобиль для победы на авторалли.
Процессор
Процессор, как правило, достаточно интенсивно используется SQL Server'ом.
Чтобы хотя бы качественно оценить нагрузку на процессор, необходимо ответить на следующие вопросы:
• Будет ли компьютер выделен для SQL Server?
• Сколько клиентов будут работать с сервером?
• Каково ожидаемое число транзакций в единицу времени?
• Велика ли доля агрегативных операций?
Количественно оценить загрузку процессора можно, проводя тестовые испытания и отслеживая параметры производительности при помощи Windows NT Performance Monitor.
Лучше, конечно, не скупиться на процессоре и ограничить свой выбор снизу хотя бы 486/50.
Память
Память используется SQL Server'ом очень интенсивно и многообразно. Память расходуется на кэширование данных и процедур, на поддержку подсоединений клиентов, открытых баз данных, открытых таблиц, блокировок таблиц и т.д. Из всех этих пунктов подробно остановиться имеет смысл на кэшировании. Все остальные расходы памяти при 50 одновременно работающих клиентах и достаточно большом количестве открытых объектов не превышают 3.5 Мб. Вся остальная память, доступная SQL Server, используется под кэш. Настраиваемый параметр "procedure cache" регулирует соотношение между кэшем данных и кэшем процедур. По умолчанию данные занимают 80% кэша. Приведенная ниже таблица содержит рекомендации по распределению памяти между SQL Server и остальной системой на выделенном компьютере. SQL Server использует память в количестве, отведенном ему настраиваемым параметром "memory".
| Machine Memory, (MB) | SQL Server Memory, (MB) |
| 16 24 32 48 64 128 256 512 | 4 6 16 28 40 100 216 464 |
Не следует выделять SQL Server слишком много памяти (относительно общего объема памяти компьютера), т.к. это может привести к интенсивному вытеснению страниц оперативной памяти на диск ("paging"), что резко понижает производительность.
Диски
Эффективность дисковой подсистемы может стать критической для производительности вашей системы, особенно если речь идет об объемах данных, значительно превышающих объем памяти, отведенной под кэш. Вот какие свойства и компоненты дисковой подсистемы помогут в повышении производительности:
Быстрый интеллектуальный SCSI-2 контроллер
Кэш-память на контроллере
Bus Master card - процессор на плате снижает нагрузку на CPU
Поддержка асинхронного чтения и записи
32-битные EISA или MCA
Аппаратная поддержка RAID
Быстрые SCSI-2 диски
Кэширование с опережающим чтением
Минимальный рекомендуемый вариант дисковой подсистемы - SCSI-контроллер и два SCSI-диска - один для баз данных и другой для журнала транзакций.
Абсолютно верных рекомендаций быть не может и в каждом конкретном случае необходимо учитывать все требования и подбирать оптимальную дисковую конфигурацию.
Сеть
Так же как и с дисками, лучше иметь интеллектуальную сетевую карту, которая сэкономит процессорное время и расходы памяти. Вот некоторые рекомендации:
• 32-битные EISA или MCA •Bus Master card - процессор на плате снижает нагрузку на CPU;
• Кэш-память на адаптере
Физическое распределение данных
Распределение баз данных, журналов транзакций, логических групп таблиц и индексов по различным физическим устройствам должно обеспечить равномерную, и значит, оптимальную загрузку устройств ввода-вывода.
При планировании физического распределения данных следует учитывать следующие рекомендации:
• Распределение баз данных и журналов транзакций на разные физические устройства повышает производительность.
• Размещение большой таблицы и ее некластеризованного индекса на разных устройствах может повысить производительность.
• Распределение большой, активно используемой таблицы по нескольким устройствам может повысить производительность.
• Использование чередования данных в виде RAID 0 или RAID 5 повышает производительность.
Даже хорошо спланированное физическое распределение данных нуждается в последующем отслеживании реальных нагрузок на физические устройства и корректировке схемы распределения.
Параметры среды и SQL Server
Настройка параметров среды и самого SQL Server - еще один ключ к производительности. Однако, он действительно может помочь лишь в том случае, если правильно подобраны ключи, описанные выше - структура базы данных, пути доступа, аппаратура и физическое распределение данных. Можно ожидать, что оптимальный подбор параметров среды и SQL Server даст прирост производительности на 5-10%.
Операционная система и производительность
Вот несколько советов по настройке Windows NT Server для повышения производительности SQL Server:
• Установка режима "Foreground and Background Applications Equally Response" (Control Panel - System - Tasking).
• Установка режима "Maximize Throughput for Network Applications" (Control Panel - Network - Server - Configure).
• Размещение файла подкачки "pagefile.sys" на физическом диске, не занятом данными SQL Server. Еще лучше, если эти диски обслуживаются разными контроллерами.
• Файловая система может быть любой (FAT или NTFS). Небольшой выгоды можно ожидать, если разместить слабо обновляемые базы данных на NTFS, а журнал транзакций - на FAT.
• Желательно отключить все ненужные сервисы Windows NT.
Параметры инсталляции и настройки SQL Server
Из всех параметров инсталляции SQL Server, которые трудно изменить в дальнейшем, на производительность влияет только порядок сортировки, о чем мы уже говорили при обсуждении инсталляции SQL Server. Выбор двоичного порядка сортировки может на 20-30% повысить производительность некоторых операций по сравнению с другими порядками, использующими словарный порядок символов.
Следующие параметры SQL Server могут повысить производительность:
• 'priority boost' (может понизить скорость выполнения других процессов на сервере). Чтобы иметь возможность задать этот параметр, следует сначала установить в 1 параметр 'show advanced option'
• 'memory' - задает размер памяти, доступной SQL Server. Чем больше, тем лучше, но в рекомендованных пределах (см. выше)
• 'user connections' - следует избегать неоправданного завышения этого параметра , т.к. это уменьшает объем кэша. Увеличение этого параметра на 1 "стоит" примерно •24 Кбайт памяти для кэша
• 'procedure cache' - процент кэша, отведенный по хранимые процедуры. При большом числе используемых хранимых процедур можно повысить.
• 'tempdb in RAM' - может существенно ( иногда в несколько раз) повысить скорость выполнения выборок, требующих сортировки или группирования строк.
Кроме того, определенное влияние на производительность могут иметь сетевые установки - выбор транспортных и сеансовых протоколов. Замечено, например, что работа по Named Pipes более всего эффективна над TCP/IP. Это связано с тем, что TCP/IP более эффективно наполняет передаваемые по сети кадры, что снижает общее число передаваемых кадров и, соответственно, повышает производительность.
Стратегия настройки
Под настройкой понимаются изменения параметров SQL Server, операционной системы, аппаратуры, физического размещения данных, путей доступа и даже логической структуры базы данных - то есть всех параметров системы и приложения с целью улучшения производительности. Настройка обычно включает в себя следующие шаги:
Похожие работы
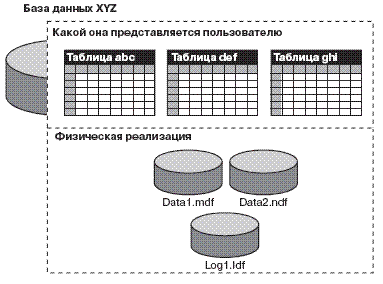
... файлов баз данных — mdf, ndf и Idf; О чтение и запись следующих ключей реестра: « HKEY_LOCAL_MACHINESoftwareMicrosoftMSSQLServer; » HKEY_LOCAL_MACHINESystemCurrentControlsetServicesMSSQLServer. Если свойства запуска служб SQL Server 2000 сконфигурированы некорректно, то впоследствии их можно изменить с помощью утилиты Services (службы) из окна Control Panel (панель управления) или с помощью ...
... , процессов резервного копирования и восстановления, импорта и экспорта, проверки данных и репликации. Кроме того, SQL Server 2000 предоставляет компоненты для создания хранилищ и киосков данных. SQL Server поддерживает системы OLAP и OLTP. Приложения получают доступ к базе данных SQL Server с помощью двух компонентов: API или URL, а также языка баз данных. Microsoft SQL Server 2000 — это ...
... объектов и их ассоциированных свойств, коллекций и так далее. Переход от приложений Microsoft Office 97 к SQL Server Набор программ Microsoft Office 97 предоставляет средства разработки приложений, основанных на входящих в него инструментах. Теперь в Office 97 можно работать с Visual Basic в любом из программных продуктов набора – от Word до Excel и Access. В каждой из этих сред с помощью VB ...
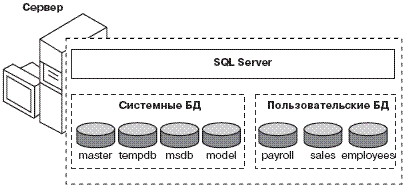
... базе данных. В локальных сетях чаще всего используется именно такой способ обработки данных. Системы централизованных баз данных могут существенно различаться в зависимости от их архитектуры.[1] Администрирование SQL Server 2000 Файл-сервер БД располагается на файл-сервере (или нескольких файл-серверах), в качестве которого может использоваться наиболее мощная из рабочих станций, объединенных в ...
0 комментариев