Основные положения
Иерархическая и сетевая даталогические модели СУБД
Файловая модель
Реляционные даталогические модели СУБД
Объектно-ориентированные СУБД (ООСУБД)
Иерархические структуры в реляционных базах данных
Введение в OLE
Различие между связыванием и внедрением объектов
Межпредметные связи и компьютерное обучение
Навигация
Иерархическая и сетевая даталогические модели СУБД
СУБД
71178
знаков
0
таблиц
0
изображений
1.2. Иерархическая и сетевая даталогические модели СУБД
Каждая БнД содержит и обрабатывает информацию из конкретной прикладной области, представляющей интерес для определенных приложений. Описание предметной области без акцента на ее последующие БнД-реализации определяет инфологическую модель предметной области (рис. 2). Инфологическая модель является исходной для построения даталогической модели БД и служит промежуточной моделью для специалистов предметной области (для которой создается БнД) и администратора БД в процессе проектирования и разработки конкретной БнД.
Под даталогической понимается модель, отражающая логические взаимосвязи между элементами данных безотносительно их содержания и физической организации. При этом даталогическая модель разрабатывается с учетом конкретной реализации СУБД, также с учетом специфики конкретной предметной области на основе ее инфологической модели. Для конкретной реализации даталогической модели проектируется физическая модель (рис. 2), oтображающая первую на конкретные программные и аппаратные средства (ОС, внешняя память, работа с данными на физическом уровне и т.д.). Наполненная конкретной информацией физическая модель и составляет собственно БД. Система, обеспечивающая cоответствующее совместное функционирование указанных компонентов и составляет суть конкретной СУБД.
Современные СУБД допускают целый ряд классификаций в зависимости от уровня их рассмотрения (в целом либо по совокупности их функциональных характеристик): по интерфейсу с пользователем в зависимости от поддерживаемых моделей, по назначению и режиму функционирования, по способу обработки информации и т.д. Мы кратко остановимся на моделях даталогического уровня, который берется за основу большинства современных классификаций СУБД.
Обычно различают три класса СУБД, обеспечивающих работу иерархических, сетевых и реляционных моделей. Однако различия между этими классами постепенно стираются, причем, видимо, будут появляться другие классы, что вызывается прежде всего интенсивными работами в области баз знаний (БЗ) и объектно-ориентированной инфотехнологией, о которой будет идти речь ниже. Поэтому традиционной классификацией пользуются все реже, но мы пока будем придерживаться именно ее, как наиболее устоявшуюся. Каждая из указанных моделей обладает характеристиками, делающими ее наиболее удобной для конкретных приложений. Одно из основных различий этих моделей состоит в том, что для иерархических и сетевых СУБД их структура часто не может быть изменена после ввода данных, тогда как для реляционных СУБД структура может изменяться в любое время. С другой стороны, для больших БД, структура которых остается длительное время неизменной, и постоянно работающих с ними приложений с интенсивными потоками запросов на БД-обслуживание именно иерархические и сетевые СУБД могут оказаться наиболее эффективными решениями, ибо они могут обеспечивать более быстрый доступ к информации БД, чем реляционные СУБД.
Глава 2
Сетевые структуры
Если в отношении между данными порожденный элемент имеет более одного исходного элемента, то это отношение уже нельзя описать как древовидную или иерархическую структуру. Его описывают в виде сетевой структуры. Любая сетевая структура может быть приведена к более простому виду введением избыточности. “БД постоянно грозит опасность стать громоздкими, застывшими и слишком сложными системами. Новые приложения порождают новые виды запросов пользователей к базе, что увеличивает набор логических связей между ее элементами. В итоге многие системы БД оказываются очень сложными в построении и эксплуатации. Если разработчики не придумают ясные и простые схемы организации, эти системы будут подобны паутине” [К.Дейт.].
Сетевая модель более симметрична, чем иерархическая модель. Однако процедуры (обновления) значительно сложнее проблема состоит в следующем: всегда имеются две стратегии для определения места одного экземпляра записи, первая начинается с "владельца" и просмотра его цепочки для выбора звена, а другая начинается с "подчиненного звена" и просмотра его цепочки для выбора "владельца". Как пользователь может решить, какую стратегию принять? Выбор и здесь имеет большое значение. Как в иерархических, так и сетевых СУБД при описании данных обычно указываются характеристики записей каждого типа, способствующие более эффективному размещению данных во внешней памяти и более быстрому доступу к ним. К таким характеристикам относятся: размеры полей записи (минимальные, средние, максимальные), состав ключа, допустимый набор символов, интервалы значений и т.д.
Иерархические и сетевые базы данных часто называют базами данных с навигацией. Это название отражает технологию доступа к данным, используемую при написании обрабатывающих программ на языке манипулирования данными. При этом, очевидно, что доступ к данным по путям, не предусмотренным при создании базы данных, может потребовать неразумно большого времени. Повышая эффективность доступа к данным и сокращая таким образом время ответа на запрос, принцип навигации вместе с этим повышает и степень зависимости программ и данных. Обрабатывающие программы оказываются жестко привязанными к текущему состоянию структуры базы данных и должны быть переписаны при ее изменениях. Операции модификации и удаления данных требует переустановки указателей, а манипулирование данными остается записеориентированным. Кроме того, принцип навигации не позволяет существенно повышать уровень языка манипулирования данными, чтобы сделать его доступным пользователю-непрограммисту, или даже программисту-непрофессионалу. Для поиска записи-цели в иерархической или сетевой структуре программист должен вначале опеределить путь доступа, а затем просмотреть все записи, лежащие на этом пути, - шаг за шагом.
Насколько запутанной являются схемы представления иерархических и сетевых баз данных, настолько и трудоемким является проектирование конкретных прикладных систем на их основе. Как показывает, опыт длительные сроки разработки прикладных систем нередко приводят к тому, что они постоянно находятся в стадии разработки и доработки.
Указанные и некоторые другие проблемы, с которыми столкнулись разработчики и пользователи иерархических и сетевых систем послужили стимулом к созданию реляционной модели данных и реляционных СУБД.
Похожие работы
... в качестве инструментального средства для создания автоматизированных информационных систем, основанных на технологии БД, позволяет существенно сокращать сроки разработки, экономить трудовые ресурсы. Развитые функциональные возможности таких СУБД, присущая им, как правило, функциональная избыточность позволяют иметь значительный «запас мощности», необходимый для безболезненного эволюционного ...
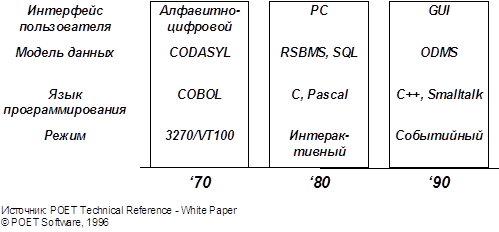



... как для С++, так и для Smalltalk. · Versant Object Technology, Inc. (СУБД Versant) проводит двойную стратегию, предлагая средство обеспечения объектно-ориентированной СУБД высокого класса для телекоммуникаций и инструментальные средства Smalltalk для более общих случаев разработки приложений. Используя разработанный фирмой интерфейс VERSANT Smalltalk Language Interface, СУБД совместима как с ...
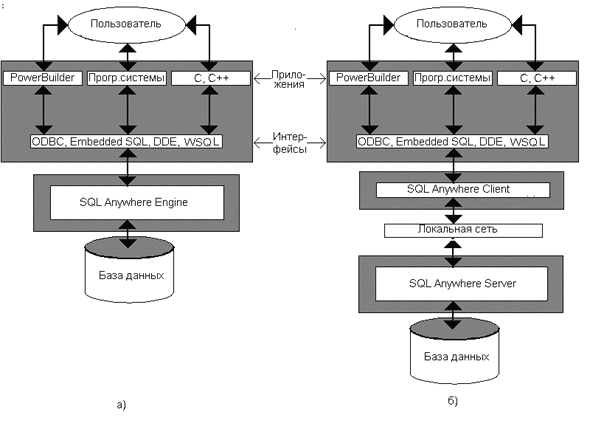
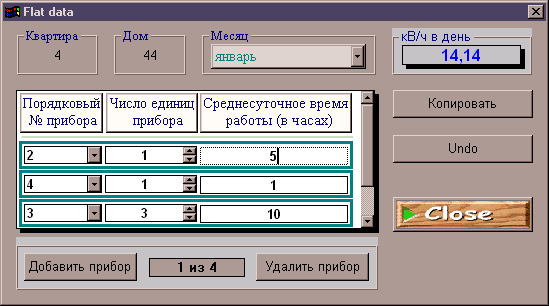
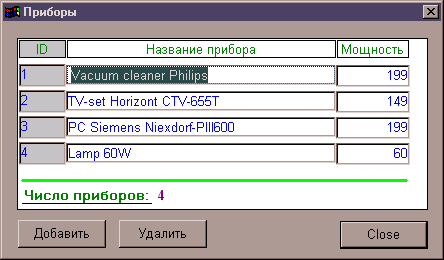
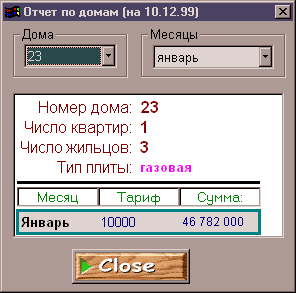
... для разработки приложений по технологии “клиент-сервер”. СУБД SYBASE SQL Anywhere является составным элементом системы SYBASE System 11 и ее последующей версии SYBASE System 11.5 Adaptive. Основным элементом этих систем является мощная СУБД SYBASE SQL. Server. Она позволяет хранить огромные объемы информации и обрабатывать запросы к базам данных с применением технологии клиент-сервер. СУБД ...


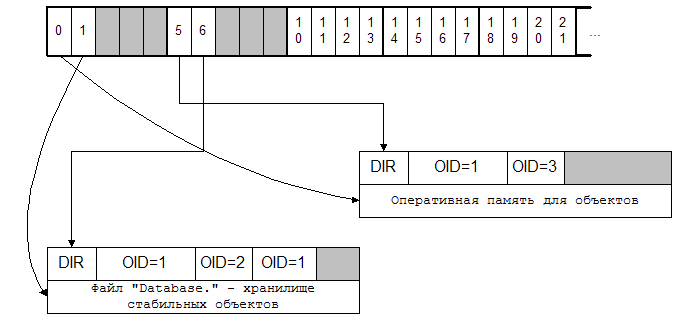
... едиными операциями. Такое разбиение позволяет ввести понятие точки разрыва. Точка разрыва ставится между двумя шагами на одном уровне любой операции. Объектно-ориентированное расписание Для увеличения производительности СУБД, некоторые операции могут взаимодействовать друг с другом в базе данных. Некоторые из этих операций могут выполняться на одном объекте. Совместное выполнение многих ...
0 комментариев