Основные положения
Иерархическая и сетевая даталогические модели СУБД
Файловая модель
Реляционные даталогические модели СУБД
Объектно-ориентированные СУБД (ООСУБД)
Иерархические структуры в реляционных базах данных
Введение в OLE
Различие между связыванием и внедрением объектов
Межпредметные связи и компьютерное обучение
Навигация
2.1. Файловая модель
Кратко рассмотрим файловую модель, неправомерно относимую довольно часто к СУБД. Файловая модель представляет собой набор файлов данных определенной структуры, но связь между данными этих файлов отсутствует. Естественно, программные средства работы с таким образом организованной инфобазой могут устанавливать связь между данными ее файлов, но на концептуальном уровне файлы модели являются независимыми. Системы, обеспечивающие работу с файловыми инфобазами, называют системами управления файлами (СУФ) и они оказываются весьма эффективными во многих приложениях. СУФ используются на всех классах ЭВМ, но особенно они распространены для обработки информации на ПК. При этом во многих источниках они фигурируют в качестве СУБД. Файловые системы легко осваиваются, достаточно просты и эффективны в использовании и, как правило, для работы с ними используются простые языки запросов либо и вовсе ограничиваются набором программ-утилит. Такие системы обычно поддерживают работу с небольшим числом файлов, содержащих ограниченное число записей с небольшим количеством полей.
Иерархические модели СУБД имеют древовидную структуру, когда каждому узлу структуры соответствует один сегмент, представляющий собой поименованный линейный кортеж полей данных. Каждому сегменту (кроме S1-корневого) соответствует один входной и несколько выходных сегментов (рис. 3а). Каждый сегмент структуры лежит на единственном иерархическом пути, начинающемся от корневого сегмента.
Для описания такой логической организации данных ЯОД достаточно предусматривать для каждого сегмента данных только идентификацию входного для него сегмента. Так как в иерархической модели каждому входному сегменту данных соответствует N выходных, то такие модели весьма удобны для представления отношений типа 1:N в предметной области. Следует отметить, что в настоящее время не разрабатываются СУБД, поддерживающие на концептуальном уровне только иерархические модели. Как правило, использующие иерархический подход системы допускают связывание древовидных структур между собой и/или установление связей внутри них. Это приводит к сетевым даталогическим моделям СУБД. К основным недостаткам иерархических моделей следует отнести: неэффективность реализации отношений типа N:N, медленный доступ к сегментам данных нижних уровней иерархии, четкая ориентация на определенные типы запросов и др. В связи с этими недостатками ранее созданные иерархические СУБД подвергаются существенным модификациям, позволяющим поддерживать более сложные типы структур и, в первую очередь, сетевые и их модификации. Сетевая даталогическая модель СУБД во многом подобна иерархической: если в иерархической модели (рис. 3а) для каждого сегмента записи допускается только один входной сегмент при N выходных, то в сетевой модели для сегментов допускается несколько входных сегментов наряду с возможностью наличия сегментов без входов с точки зрения иерархической структуры. На рис. 3б представлен простой пример сетевой структуры, полученной на основе модификации иерархической структуры (рис. 3а). Графическое изображение структуры связей сегментов такого типа моделей представляет собой сеть. Сегменты данных в сетевых БД могут иметь множественные связи с сегментами старшего уровня. При этом направление и характер связи в сетевых БД не являются столь очевидными, как в случае иерархических БД. Поэтому имена и направление связей должны идентифицироваться при описании БД средствами ЯОД.
Таким образом, под сетевой СУБД понимается система, поддерживающая сетевую организацию: любая запись, называемая записью старшего уровня, может содержать данные, которые относятся к набору других записей, называемых записями подчиненного уровня. Возможно обращение ко всем записям в наборе, начиная с записи старшего уровня. Обращение к набору записей реализуется по указателям. В рамках сетевых СУБД легко реализуются и иерархические даталогические модели. Сетевые СУБД поддерживают сложные соотношения между типами данных, что делает их пригодными во многих различных приложениях. Однако пользователи таких СУБД ограничены связями, определенными для них разработчиками БД-приложений. Более того, подобно иерархическим сетевые СУБД предполагают разработку БД приложений опытными программистами и системными аналитиками.
Среди недостатков сетевых СУБД следует особо выделить проблему обеспечения сохранности информации в БД, решению которой уделяется повышенное внимание при проектировании сетевых БД.
Глава 3
Реляционные структуры
Реляционный подход стал широко известен благодаря первым работам Е.Кодда, которые появились около 1970г. В течение долгого времени реляционный подход рассматривался как удобный формальный аппарат анализа баз данных, не имеющий практических перспектив, так как его реализация требовала слишком больших машинных ресурсов. Только с появлением персональных ЭВМ реляционные и близкие к ним системы неожиданно стали распространяться, практически не оставив места другим моделям. Один из самых естественных способов представления данных для пользователей - это двумерная таблица. Она привычна для пользователя, понятна и обозрима, ее легко запомнить. Поскольку любая сетевая структура может быть разложена в совокупность древовидных структур, то и любое представление данных может быть сведено к двумерным плоским файлам. Связи между данными могут быть представлены в форме двумерных таблиц.
Таблица обладает следующими свойствами:
Каждый элемент таблицы представляет собой один элемент данных. Повторяющиеся группы отсутствуют.
Все столбцы в таблице однородные. Это означает, что элементы столбца имеют одинаковую природу.
Столбцам присвоены уникальные имена.
В таблице нет двух одинаковых строк.
Порядок расположения строк и столбцов в таблице безразличен. Таблица такого рода называется отношением. База данных, построенная с помощью отношений, называется реляционной базой данных.
Чем же принципиально отличаются реляционные модели от сетевых и иерархических? Вкратце на это можно ответить следующим образом: иерархические и сетевые модели данных - имеют связь по структуре, а реляционные - имеют связь по значению. Проектирование баз данных традиционно считалось очень трудной задачей. Реляционная технология значительно упрощает эту задачу в трех различных направлениях:
Разделением логического и физического уровней системы она упрощает процесс отображения "уровня реального мира", в структуру, которую система может прямо поддерживать. Поскольку реляционная структура сама по себе концептуально проста, она позволяет реализовывать небольшие и/или простые (и поэтому легкие для создания) базы данных, такие как персональные, сама возможность реализации которых никогда даже бы не рассматривалась в старых более сложных системах.
Теория и дисциплина нормализации может помочь, показывая, что случается, если отношения не структурированы естественным образом.
Реляционная модель данных особенно удобна для использования в базах данных распределенной архитектуры - она позволяет получать доступ к любым информационным элементам, хранящимся в узлах сети ЭВМ. Необходимо обратить особое внимание на высокоуровневый аспект реляционного подхода, который состоит в множественной обработке записей. Благодаря этому значительно возрастает потенциал реляционного подхода, который не может быть достигнут при обработке по одной записи, и прежде всего это касается оптимизации. У системы управления базами данных появляется возможность влиять на эффективность реализации. В настоящее время на рынке программно-математического обеспечения для ПЭВМ представлено более сотни различных СУБД. Они сильно различаются по стоимости, по эффективности работы, по функциональной мощности, по сложности изучения и использования.
Наиболее широкое распространение получили СУБД, использующие реляционную модель данных, теоретической основой которой является логика предикатов первого порядка и теория отношений. Одной из важнейших характеристик как с точки зрения разработчика информационно-управляющих систем, так и их пользователей является быстродействие СУБД, в силу чего практически все фирмы мира-производители СУБД работают над проблемой увеличения реактивности. Большинство известных коммерческих СУБД страдают существенным недостатком : при работе с большими и сверхбольшими базами данных резко снижается время реакции системы при выполнении процедур поиска информации. Кроме того, появляющиеся в периодической печати результаты тестирования коммерческих СУБД не всегда позволяют сделать вывод об эффективности того или иного программного продукта, поскольку почти всегда оцениваемым по времени результатом поиска является первая найденная запись, а время ответа на сложные многоключевые запросы не оценивается, в то время как время поиска всех записей, удовлетворяющих некоторому критерию, линейно зависит от числа записей в базе, от числа записей-целей, от размеров записи, и, следовательно, для больших баз измеряется значительным интервалом времени.
Таким образом проведенный анализ систем управления базами данных, ориентированных на различные модели данных, позволяет сделать вывод: в распределенной интегрированной информационной системе возможно использование СУБД реляционного типа.
Похожие работы
... в качестве инструментального средства для создания автоматизированных информационных систем, основанных на технологии БД, позволяет существенно сокращать сроки разработки, экономить трудовые ресурсы. Развитые функциональные возможности таких СУБД, присущая им, как правило, функциональная избыточность позволяют иметь значительный «запас мощности», необходимый для безболезненного эволюционного ...
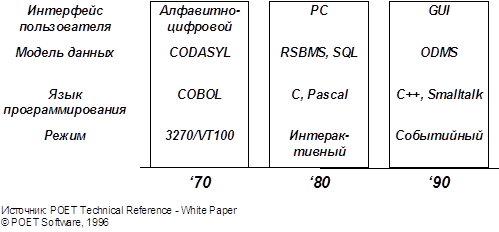



... как для С++, так и для Smalltalk. · Versant Object Technology, Inc. (СУБД Versant) проводит двойную стратегию, предлагая средство обеспечения объектно-ориентированной СУБД высокого класса для телекоммуникаций и инструментальные средства Smalltalk для более общих случаев разработки приложений. Используя разработанный фирмой интерфейс VERSANT Smalltalk Language Interface, СУБД совместима как с ...
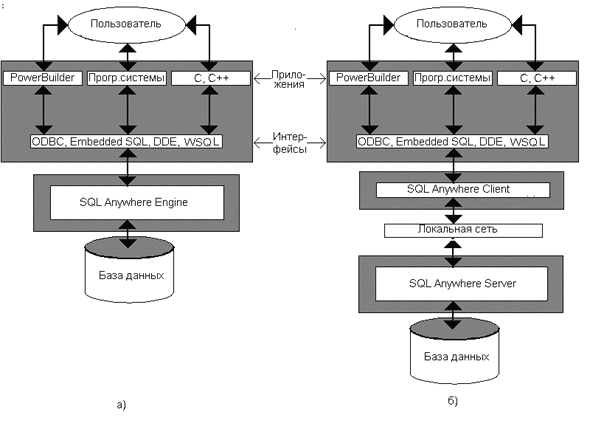
... для разработки приложений по технологии “клиент-сервер”. СУБД SYBASE SQL Anywhere является составным элементом системы SYBASE System 11 и ее последующей версии SYBASE System 11.5 Adaptive. Основным элементом этих систем является мощная СУБД SYBASE SQL. Server. Она позволяет хранить огромные объемы информации и обрабатывать запросы к базам данных с применением технологии клиент-сервер. СУБД ...


... едиными операциями. Такое разбиение позволяет ввести понятие точки разрыва. Точка разрыва ставится между двумя шагами на одном уровне любой операции. Объектно-ориентированное расписание Для увеличения производительности СУБД, некоторые операции могут взаимодействовать друг с другом в базе данных. Некоторые из этих операций могут выполняться на одном объекте. Совместное выполнение многих ...
0 комментариев