ОБЗОР И АНАЛИЗ СУЩЕСТВУЮЩИХ СИСТЕМ КЛАССИФИКАЦИИ ИНФОРМАЦИИ
Описание схемы организационной структуры управления информационных и аналитических технологий аппарата администрации Тульской области
Описание постановки задачи
Текст сообщения должен быть отредактирован. Все спецсимволы в
МАТЕМАТИЧЕСКОЕ ОБЕСПЕЧЕНИЕ
Описание запросов
Описание схемы работы системы
Навигация
МАТЕМАТИЧЕСКОЕ ОБЕСПЕЧЕНИЕ
Автоматизированная интеллектуальная система классификации информационных сообщений средств массовой информации
73358
знаков
15
таблиц
7
изображений
4 МАТЕМАТИЧЕСКОЕ ОБЕСПЕЧЕНИЕ
4.1 Математическая постановка задачи классификации информационных сообщений СМИ
Пусть дано множество статей Х, множество ключевых слов статьи W и множество названий статей A. Каждое множество описывается своим набором элементов:
X = {x1, x2, …, xc},
где xi – i- я статья;
c – количество статей;
W = {w1, w2, …, wc},
где wi – строка ключевых слов i-ой статьи, ![]() ;
;
A = {a1, a2, … ac},
где ai– название i-ой статьи, ![]() .
.
Имеется рубрикатор, состоящий из четырех уровней:
R1 = {r11, r12, … r1k},
где k – количество элементов рубрикатора 1;
R2 = {r21, r22, … r2l},
где l – количество элементов рубрикатора 2;
R3 = {r31, r32, … r3m},
где m – количество элементов рубрикатора 3;
R4 = {r41, r42, … r4n},
где n – количество элементов рубрикатора 4.
К каждому элементу рубрикаторов 3-го и 4-го уровней привязаны словари со своими множествами:
D3j = {d31j, d32j, … d3yj}, ![]() ;
;
D4j = {d41j, d42j, … d4zj}, ![]() ,
,
где j – индекс элемента рубрики;
y, z – количество элементов в словаре для конкретной рубрики.
Функция нечеткого поиска задается следующим образом:
![]()
здесь U = {{X},{W},{A}};
dpqj – ключевое слово,
где j – индекс элемента рубрики, ![]() или
или ![]() ;
;
p – уровень рубрикатора 3-й или 4-й;
q – индекс элементов в словарях D3j и D4j;
![]() или
или ![]() ;
;
pн.п – порог нечеткого поиска.
Далее для каждой статьи применяем функцию нечеткого поиска:
![]()
где ![]() - общее количество совпадений по i-ой статье из словаря 3-го и 4-го уровней;
- общее количество совпадений по i-ой статье из словаря 3-го и 4-го уровней;
![]()
![]() ;
;
![]() .
.
Затем для ключевых слов статьи также применяем функцию нечеткого поиска:
![]()
где ![]() общее количество совпадений по строке ключевых слов i-ой статьи из словаря 3-го и 4-го уровней;
общее количество совпадений по строке ключевых слов i-ой статьи из словаря 3-го и 4-го уровней;
![]()
![]() ;
;
![]() .
.
Для названий статей тоже применяем функцию нечеткого поиска:
![]()
где ![]() - общее количество совпадений по названию i-ой статьи из словаря 3-го и 4-го уровней;
- общее количество совпадений по названию i-ой статьи из словаря 3-го и 4-го уровней;
![]()
![]() ;
;
![]() .
.
Далее для отнесения каждой статьи к той или иной рубрике используется метод ранжирования. Для этого определяются границы трех интервалов:
1) статью однозначно нельзя отнести к рубрике;
2) консультант ОТОИ принимает решение о принадлежности статьи к данной рубрике;
3) статья с заданной вероятностью относится к данной рубрике.
Границей является количество слов, которые должны встретиться в тексте, названии статьи или в списке ключевых слов, относящихся к этой статье.
Метод ранжирования заключается в следующем:
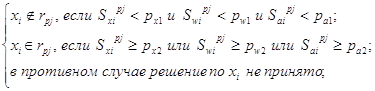
где ![]() границы интервалов по тексту i-ой статьи;
границы интервалов по тексту i-ой статьи;
![]() границы интервалов по строке ключевых слов i-ой статьи;
границы интервалов по строке ключевых слов i-ой статьи;
![]() границы интервалов по названию i-ой статьи.
границы интервалов по названию i-ой статьи.
Для нечеткого поиска информации используется алгоритм, основанный на процентном отношении совпадения двух строк. Процесс поиска начинается со сравнения каждого элемента одной строки с каждым элементом другой и заканчивается сравнением строк целиком. Эта процедура повторяется дважды для одной и той же пары строк. В первом случае первая строка принимается за эталон, во втором – вторая. В процессе сравнения подсчитывается число совпадений и общее число рассматриваемых случаев, после чего вычисляется их процентное соотношение. На основе этого соотношения принимается решение – считать найденную информацию удовлетворяющей условиям поиска или нет. Описанная процедура применяется ко всем записям информационной базы, в результате пользователь получает всю информацию, удовлетворяющую запросу.
Изменяя минимальный процент совпадения можно уменьшать или увеличивать точность соответствия найденной информации искомой. В данной системе используется 50% совпадения, так как (из практики) этого достаточно для нахождения информации. Схема программы поиска данных по алгоритму нечеткого поиска приведена на рисунке 4.2.1, схема программы сравнения строк приведена на рисунке 4.2.2.
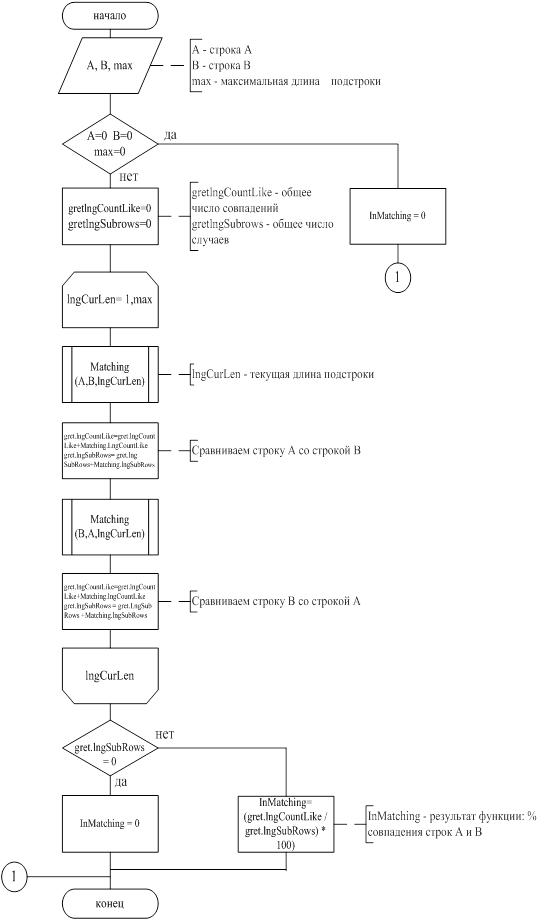
Рисунок 4.2.1 - Схема программы поиска данных по алгоритму нечеткого поиска
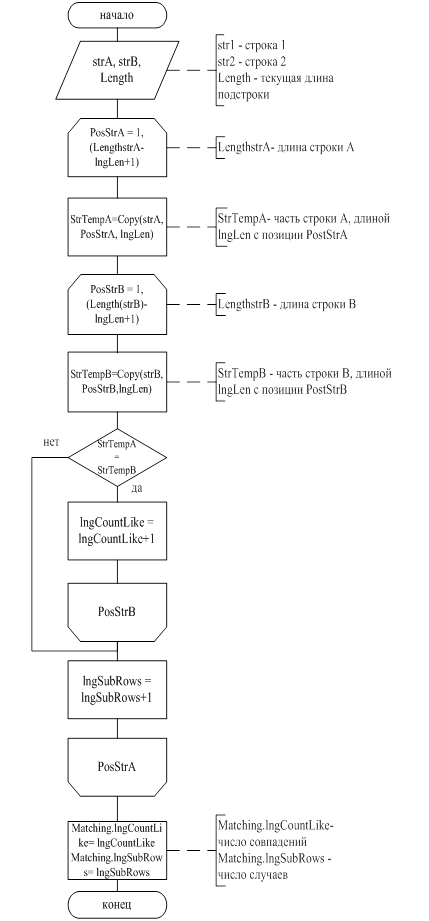
Рисунок 4.2.2 - Схема программы сравнения строк «Matching»
Похожие работы
... мероприятия по новому месту работы, жительства; также в окружении носителей коммерческих секретов. Персонал оказывает существенное, а в большинстве случаев даже решающее влияние на информационную безопасность банка. В этой связи подбор кадров, их изучение, расстановка и квалифицированная работа при увольнениях в значительной степени повышают устойчивость коммерческих предприятий к возможному ...
... ; однако, чтобы выполнять предназначенную ему роль, сам модуль также нуждается в защите, как собственными средствами, так и средствами окружения (например, операционной системы). Стандарт шифрования DES Также к стандартам информационной безопасности США относится алгоритм шифрования DES, который был разработан в 1970-х годах, и который базируется на алгоритме DEA. Исходные идеи алгоритма ...
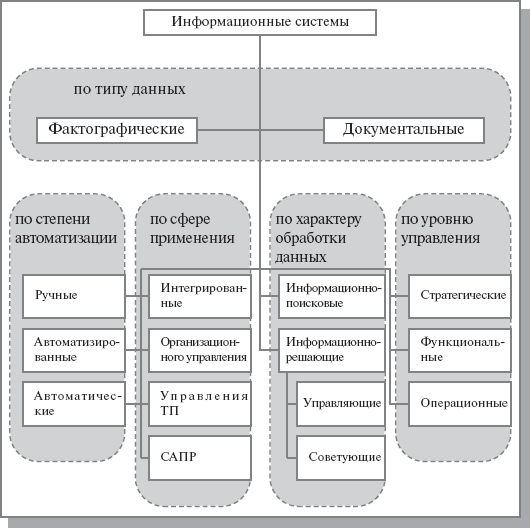
... не производится. Рис. 1.1. Классификация информационных систем Основываясь на степени автоматизации информационных процессов в системе управления фирмой, информационные системы делятся на ручные, автоматические и автоматизированные. Ручные ИС характеризуются отсутствием современных технических средств переработки информации и выполнением всех операций человеком. В автоматических ИС все ...





... средства защиты должны строиться с учетом их сопряжения с ее аппаратными и программными средствами. В целях перекрытия возможных каналов НСД к информации ЭВМ, кроме упомянутых, могут быть применены и другие методы и средства защиты. При использовании ЭВМ в многопользовательском режиме необходимо применить в ней программу контроля и разграничения доступа. Существует много подобных программ, ...
0 комментариев