Навигация
Исследование статистических характеристик случайной последовательности
11269
знаков
2
таблицы
4
изображения
Министерство Образования Республики Таджикистан
Таджикский Технический Университет
имени М.С. Осими
Кафедра «АСОИиУ»
Лабораторная работа №1
На тему: Исследование статистических характеристик
случайной последовательности.
Душанбе-2010
Лабораторная работа №1. Исследование статистических характеристик случайной последовательности
Цель работы:
1.Освоение методов оценки закона распределения и вероятностных характеристик случайной последовательности: математического ожидания, дисперсии, среднеквадратичного отклонения и автокорреляционной функции.
2.Освоение метода проверки гипотезы о законе распределения по критерию согласия хи- квадрат Пирсона.
3.Исследование свойств базовой псевдослучайной последовательности.
Теоретические сведения.
Оценка вероятностных характеристик.
Числовая последовательность Х1,Х2,...Хn, статистические характеристики которой требуется определить считается реализацией стационарной эргодической случайной последовательности Х1,Х2,...хn. Вероятностные характеристики случайной последовательности неизвестны и подлежат оценке с помощью соответствующих статистических характеристик числовой последовательности. При вероятностном моделировании последовательности Х1,Х2,...хn представляет собой совокупность результатов отдельных опытов. В данной лабораторной работе в качестве такой последовательности Х1,Х2,...хn рассматриваются псевдослучайные числа вырабатываемые генератором, построенным на М – последовательности (датчиком случайных чисел) в котором
M= g ⁿ -1 (1)
Где М – общее количество чисел, вырабатываемых генератором
g-основание системы исчисления
n- Количество разрядов в генераторе.
Генератор строится на базе регистра Хi(i=1,n),состоящего из ячеек , в которые записываются целые числа от 1 до g. Случайные числа М- последовательности снимаются с последнего элемента Хn. Числа записанные в ячейки Xm и Xn складываются по модулю g
R= Xm + Xn (2)
И приводится сдвиг чисел в регистре:
Xn-i= Xn-j-I (i=0,..n-2) (3)
В первую ячейку записывается содержимое сумматора Xi=R
Такая процедура повторяется М – раз, в процессе которой получается исследуемая базовая псевдослучайная последовательность Х1,Х2,...хn, где M=N. Для данной последовательности рассчитываются ее вероятностные характеристики.
Математическое ожидание M(Xi)=m оценивается по формуле:
m* =1/N ∑ Xi (5)
Дисперсия Dx оценивается по формуле:
Dx= 1/n-1∑(xi-mx)² (6)
Среднеквадратическое отклонение оценивается по формуле:
n
(м*=1/n∑xi) δ*= √D* (7)
i=1
Aавтокорреляционная функция (нормированная) представляет собой последовательность коэффициентов корреляции, зависящих от величины сдвига, как от аргумента.
K(r)=1/D · M[(xi - m)(xi + r-m)]
Ее оценка вычисляется:
K*(r)=1/D*(N-r-1)n-2∑i=1[(xi-m*)(xi+r-m*)]=1/D*(1/N-r-1)n-2∑i=1xixi+r-(N-r)/(N-r-1)m* (8)
Оценка закона распределения.
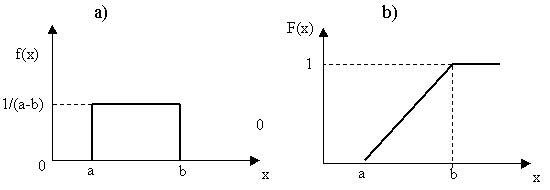
Одномерный закон распределения при большом объеме последовательности оценивается статистическим рядом, графическое изображение которого называется гистограммой. При малом объеме последовательности, когда N не превосходит несколько десятков, используется статистическая функция распределения, называемая также выборочной и эмпирической.
Для построения гистограммы диапазон возможных значений элементов последовательности разбивается на е участков точками U1,U2,Ue
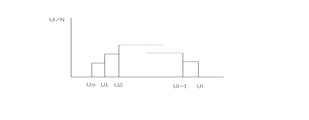
![]() Крайние точки Uo и Ue могут быть бесполезными. Длины участков ΔU могут быть необязательно одинаковыми. Если они различны, то чаще всего называются так, чтобы вероятности попадания на все участки были одинаково близки друг к другу. В связи с тем, что моделируемый генератор вырабатывает целые случайные числа от 1 до g , то участки выделяются точками U1=1;U2=2;Ue=g.
Крайние точки Uo и Ue могут быть бесполезными. Длины участков ΔU могут быть необязательно одинаковыми. Если они различны, то чаще всего называются так, чтобы вероятности попадания на все участки были одинаково близки друг к другу. В связи с тем, что моделируемый генератор вырабатывает целые случайные числа от 1 до g , то участки выделяются точками U1=1;U2=2;Ue=g.
Статистический ряд- это совокупность чисел V1,V2,Ve , где Vj0- количество элементов последовательности, удовлетворяющее неравенствуUj-1 < Xi < Uj т.е попавших в j –участок. Графическое представление статистического ряда, т. Е гистограмму, удобно строить в относительных величинах. Поэтому производится нормировка:
e
∑ Vj / N=1 (9)
i=1
Статистическая (выборочная , эмпирическая) функция распределения F*(X) является оценкой для интегральной функции распределения и вычисляется по формуле :
![]() 0,если X<X1
0,если X<X1
F*(X)= k/n, если Хk<Х<Хk+1
1, если X>Xn (k=1,2,..N-1) (10)
Где Xk-тый элемент вариационного ряда, т.е. последовательности, в которой элементы расположены в порядке возрастания числовых значений. Графическое представление функции распределения показано показано на рис.

Проверка гипотезы о законе распределения.
Гипотеза о законе распределения элементов последовательности задается названием закона и численным значением параметров. Она может быть задана плотностью вероятности в виде формулы или графика.
Иногда может быть задана интегральная функция распределения. Тогда знак F(x)можно всегда найти плотность вероятности как f(x)=p(x).
Для проверки гипотезы о законе распределения при большом объеме последовательности (n>100)пользуются критерием X² Пирсона. По построенному статистическому ряду (гистограмме) вычисляется статис. х² (Δ)
e
Δ= X² = ∑(Vj-NPj)² /(NPj) (11)
i=1
Где Pj- вероятность попадания элемента последовательности в j-ый участок
Vj- j-ый член стат.ряда, т.е. количество элементов последовательности попавших в j-ый участок
N – общее количество элементов последовательности.
Распределение Х² зависит от параметра r , называемого числом «степени свободы». Число степеней свободы r равно числу участков е минус число независимых условий, наложенных на частоты Pj =Vj / n (j=1,e). Примером такого условия может быть условие вида (9), которое накладывается при любом случае. Поэтому
R=e-1 (12)
Если для теоретического распределения задаются математическое ожидание, дисперсия и другие параметры, то число степеней свободы уменьшается на число таких параметров.
Для распределения Х² имеются специальные таблицы, по которым можно для каждого значения Х² и числа степеней свободы r найти вероятность P того, что величина, распределенная по закону Х² превзойдет его значение. Вероятность P, определенная по таблице, есть вероятность того, что за счет числа случайных причин мера расхождения теоретического и статистического распределения (11)будет не меньше, чем фактически наблюденное в данном серии опытов значения Х². если эта вероятность P весьма мала, то результат опыта следует считать противоречивым гипотезе о том, что закон распределения величины Х есть F(x). Поэтому эту гипотезу следует отбросить как неправдоподобную. Напротив, если вероятность P сравнительно велика, то можно признать расхождения между теоретическим и статистическим распределением вещественным. При этом гипотеза о том, что величина X распределена по закону F(x) можно считать правдоподобной или не противоречащей опытным данным.
На практике, если P оказывается меньше, чем 0,1, то рекомендуется проверить и по возможности повторить эксперимент. В случае, если опять появятся замеченные расхождения, то следует подобрать более подходящий для описания стат. Данных закона распределения.
Содержание исследования
В состав исследования, проводимого в данной лабораторной работе входит:
1. программная реализация базой псевдослучайной последовательности, вырабатываемой генератором случайных чисел при заданных преподавателем параметрах: g,n,m.
2.Определение оценок математич. ожидания, дисперсии, среднеквадратического отклонения и g коэффициентов корреляции (для r=1,g).
Похожие работы
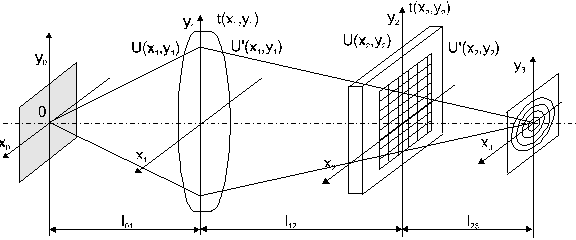
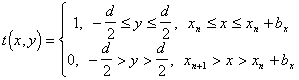
... -ным законом распределения ширины щелей и стенок может быть представ-лен следующим выражением: (2.16). Наибольший интерес для практической реализации в оптических системах КОС для автоматизации контроля статистических характеристик пространственной структуры ЛЗ представляет второе слагаемое выражения (2.16), содержащее функциональную взаимосвязь этих характеристик. Пос-кольку это слагаемое ...



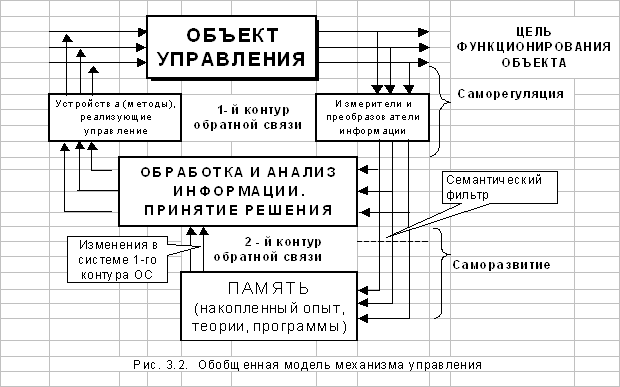
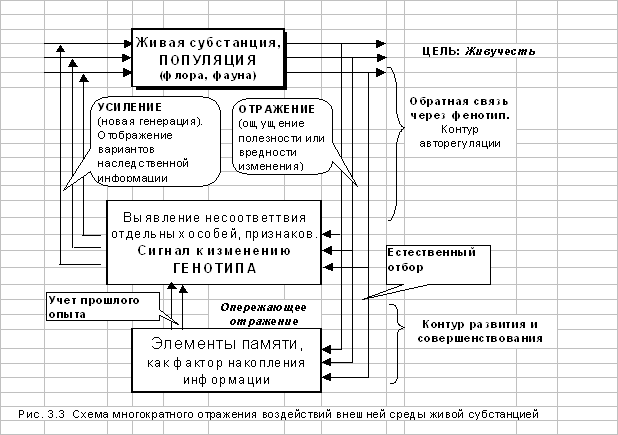
... Возникшие потребности в научно обоснованных методах и средствах управления нашли свое выражение в кибернетике - науке об управлении и системном анализе, особым предметом исследования которых являются сложные и очень сложные системы окружающего мира. 4.4 Организационные системы Традиционно современная кибернетика рассматривала, в основном, простые и сложные управляемые системы, для которых ...
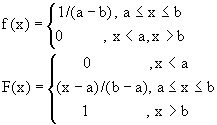
... на ЭВМ, колеблется в достаточно широких пределах в зависимости от класса объекта моделирования, вида оцениваемых характеристик, необходимой точности и достоверности результатов моделирования. Для метода статистического моделирования на ЭВМ характерно, что большое число операций, а соответственно большая доля машинного времени расходуются на действия со случайными числами. Кроме того, результаты ...
... итерационного процесса, состоящего из последовательно реализуемых шагов, удовлетворяющих направлению: s → 0, Cpk -> Ср. 4. ИСПОЛЬЗОВАНИЕ СТАТИСТИЧЕСКИХ МЕТОДОВ АНАЛИЗА ПРОИЗВОДСТВЕННЫХ ПРОЦЕССОВ Рассмотрим применение вышеизложенных статистических методов контроля качества производственных процессов на нескольких примерах. 4.1 Контроль технологической точности Пример 4.1.1. ...
0 комментариев