Вивчення алгоритмів сортування
Мета: Ознайомитися із простими алгоритмами сортування та навчитися їх програмувати. Засвоїти базові умови тестування програм та вимірювання їх ефективності.
Хід роботи
Сортування вставкамиСортування вставками - простий алгоритм сортування на основі порівнянь. На великих масивах є значно менш ефективним за такі алгоритми, як швидке сортування, пірамідальне сортування та сортування злиттям. Однак, має цілу низку переваг:
простота у реалізації
ефективний (за звичай) на маленьких масивах
ефективний при сортуванні масивів, дані в яких вже непогано відсортовані: продуктивність рівна O (n + d), де d - кількість інверсій
на практиці ефективніший за більшість інших квадратичних алгоритмів (O (n2)), як то сортування вибором та сортування бульбашкою: його швидкодія рівна n2/4, і в найкращому випадку є лінійною є стабільним алгоритмом
Код програми сортування вставками:
#include <stdio. h>
#include <conio. h>
#include <stdlib. h>
#include <time. h>
// Insertion-------------------------------------------------------------
void Insertion (int *arr, int n)
{
int i,j,buf;
clock_t start, end;
FILE *rez;
start = clock ();
for (i=1; i<n; i++)
{
buf=* (arr+i);
for (j=i-1; j>=0 && * (arr+j) >buf; j--)
* (arr+j+1) =* (arr+j);
* (arr+j+1) =buf;
}
end = clock ();
printf ("The time was:%f s\n", (end - start) / CLK_TCK);
rez=fopen ("rezult. txt","wt");
for (i=0; i<n; i++)
fprintf (rez,"%d\n",* (arr+i));
fclose (rez);
}
// ---------------------------------------------------------------------
void main ()
{
FILE *f;
int *X, N;
clock_t start, end;
f=fopen ("massiv. txt","rt");
N=0;
while (! feof (f))
{
fscanf (f,"%d",X+N);
N++;
}
fclose (f);
clrscr ();
Insertion (X,N);
getch ();
}
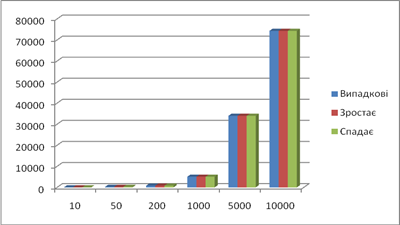
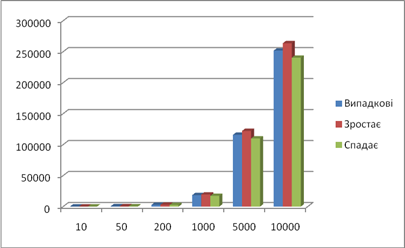
| Результат роботи сортування вставками | |||||||||
| Довжина послідовності | Випадкові | Зростає | Спадає | ||||||
| 312 | 17 | 927 | 85 | 10009 | середнє | ||||
| Час | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 10 | Пересилан-ня | 38 | 37 | 41 | 35 | 35 | 37,2 | 18 | 63 |
| Порівняння | 29 | 28 | 32 | 26 | 26 | 28,2 | 9 | 54 | |
| Час | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 50 | Пересилан-ня | 816 | 647 | 691 | 679 | 668 | 700,2 | 98 | 1323 |
| Порівняння | 767 | 598 | 642 | 630 | 619 | 651,2 | 49 | 1274 | |
| Час | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 200 | Пересилан-ня | 10003 | 11251 | 9802 | 10387 | 10455 | 10379,6 | 398 | 20298 |
| Порівняння | 9804 | 11052 | 9603 | 10188 | 10256 | 10180,6 | 199 | 20099 | |
| Час | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 1000 | Пересилан-ня | 255877 | 250330 | 249604 | 249928 | 252295 | 251606,8 | 1998 | 501498 |
| Порівняння | 254879 | 249331 | 248605 | 248929 | 251296 | 250608 | 999 | 500499 | |
| Час | 0,054 | 0,055 | 0,054 | 0,054 | 0,55 | 0,054 | 0 | 0,1 | |
| 5000 | Пересилан-ня | 6302053 | 6183921 | 6229604 | 6391053 | 6282323 | 6277791 | 9998 | 12507498 |
| Порівняння | 6297054 | 6178922 | 6224605 | 6386054 | 6277324 | 6272792 | 4999 | 12502499 | |
| Час | 0,21 | 0,21 | 0,21 | 0,21 | 0,22 | 0,21 | 0 | 0,44 | |
| 10000 | Пересилан-ня | 25166644 | 24940616 | 24897941 | 24822544 | 24963312 | 24958211 | 19998 | 50014998 |
| Порівняння | 25156645 | 24930617 | 24887942 | 24812545 | 24953313 | 24948212 | 9999 | 50004999 | |
Час виконання:
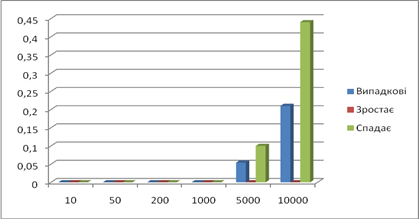
Кількість порівняннь:
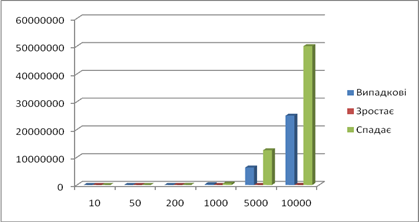
Кількість пересилань:
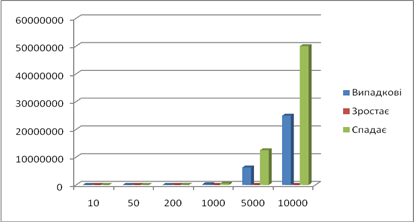
Сортування злиттям - алгоритм сортування, в основі якого лежить принцип Розділяй та володарюй. В основі цього способу сортування лежить злиття двох упорядкованих ділянок масиву в одну впорядковану ділянку іншого масиву. Злиття двох упорядкованих послідовностей можна порівняти з перебудовою двох колон солдатів, вишикуваних за зростом, в одну, де вони також розташовуються за зростом. Якщо цим процесом керує офіцер, то він порівнює зріст солдатів, перших у своїх колонах і вказує, якому з них треба ставати останнім у нову колону, а кому залишатися першим у своїй. Так він вчиняє, поки одна з колон не вичерпається - тоді решта іншої колони додається до нової.
Під час сортування в дві допоміжні черги з основної поміщаються перші дві відсортовані підпослідовності, які потім зливаються в одну і результат записується в тимчасову чергу.
Потім з основної черги беруться наступні дві відсортовані підпослідовності і так до тих пір доки основна черга не стане порожньою. Після цього послідовність з тимчасової черги переміщається в основну чергу. І знову продовжується сортування злиттям двох відсортованих підпослідовностей.
Сортування триватиме до тих пір поки довжина відсортованої підпослідовності не стане рівною довжині самої послідовності.
Код сортування злиттям:
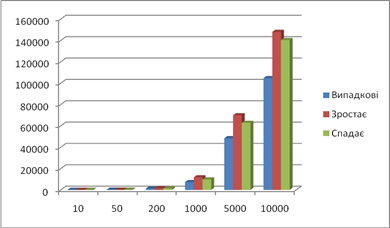
| #include <stdio. h> #include <conio. h> #include <stdlib. h> #include <time. h> // Merge----------------------------------------------------------------- void merge (int *a, int l, int m, int r) { int h, i,j,b [10000],k; h=l; i=l; j=m+1; while ( (h<=m) && (j<=r)) { if (a [h] <=a [j]) { b [i] =a [h]; h++; } else { b [i] =a [j]; j++; } i++; } if (h>m) { for (k=j; k<=r; k++) { b [i] =a [k]; i++; } } else { for (k=h; k<=m; k++) { b [i] =a [k]; i++; } } for (k=l; k<=r; k++) {a [k] =b [k]; } } void MergeSort (int *a, int l, int r) { int m; if (l<r) { m= (l+r) /2; MergeSort (a,l,m); MergeSort (a,m+1,r); merge (a,l,m,r); } } // ---------------------------------------------------------------------- void main () { FILE *f,*rez; int *X, N; clock_t start, end; clrscr (); f=fopen ("massiv. txt","rt"); N=0; while (! feof (f)) { fscanf (f,"%d",X+N); N++; } fclose (f); start= clock (); MergeSort (X,0,N-1); end= clock (); printf ("The time was:%f s\n", (end - start) / CLK_TCK); rez=fopen ("rezult. txt","wt"); for (int i=0; i<N; i++) fprintf (rez,"%d\n",* (X+i)); fclose (rez); getch (); }Результат роботи сортування злиттям |
| Довжина послідовності | Випадкові | Зростає | Спадає | ||||||
| 312 | 17 | 927 | 85 | 10009 | середнє | ||||
| 10 | Пересилання | 78 | 78 | 78 | 78 | 78 | 78 | 78 | 78 |
| Порівняння | 22 | 22 | 22 | 22 | 22 | 22 | 22 | 22 | |
| 50 | Пересилання | 568 | 568 | 568 | 568 | 568 | 568 | 568 | 568 |
| Порівняння | 257 | 257 | 257 | 257 | 257 | 257 | 257 | 257 | |
| 200 | Пересилання | 3106 | 3106 | 3106 | 3106 | 3106 | 3106 | 3106 | 3106 |
| Порівняння | 818 | 818 | 818 | 818 | 818 | 818 | 818 | 818 | |
| 1000 | Пересилання | 19974 | 19974 | 19974 | 19974 | 19974 | 19974 | 19974 | 19974 |
| Порівняння | 5049 | 5049 | 5049 | 5049 | 5049 | 5049 | 5049 | 5049 | |
| 5000 | Пересилання | 123644 | 123644 | 123644 | 123644 | 123644 | 123644 | 123644 | 123644 |
| Порівняння | 33965 | 33965 | 33965 | 33965 | 33965 | 33965 | 33965 | 33965 | |
| 10000 | Пересилання | 267262 | 267262 | 267262 | 267262 | 267262 | 267262 | 267262 | 267262 |
| Порівняння | 74335 | 74335 | 74335 | 74335 | 74335 | 74335 | 74335 | 74335 | |
Кількість порівняннь:
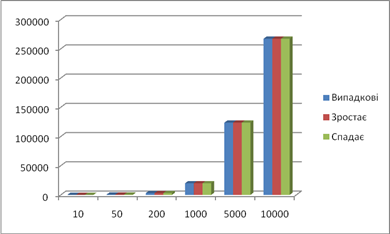
Кількість пересилань:
Швидке сортування (англ. Quick Sort) - алгоритм сортування, добре відомий, як алгоритм розроблений Чарльзом Хоаром, який не потребує додаткової пам'яті і виконує у середньому O (n log (n)) операцій. Однак, у найгіршому випадку робить O (n2) порівнянь. Оскільки алгоритм використовує дуже прості цикли і операції, він працює швидше інших алгоритмів, що мають таку ж асимптотичну оцінку складності.
Ідея алгоритму полягає в переставлянні елементів масиву таким чином, щоб його можна було розділити на дві частини і кожний елемент з першої частини був не більший за будь-який елемент з другої. Впорядкування кожної з частин відбувається рекурсивно. Алгоритм швидкого сортування може бути реалізований як у масиві, так і в двозв’язному списку.
Швидке сортування є алгоритмом на основі порівнянь, і не є стабільним.
Код сортування злиттям:
#include <stdio. h>
#include <conio. h>
#include <stdlib. h>
#include <time. h>
// ----------------------------------------------------------------------
void QuickSort (int *arr, int a, int b)
{
int i=a, j=b, m = rand ()% (b-a) +a;
int x = * (arr+m);
do
{
while (i<=b && * (arr+i) < x) i++;
while (j>=a && * (arr+j) > x) j--;
if (i <= j)
{
if (i < j)
{
int buf=* (arr+i);
* (arr+i) =* (arr+j);
* (arr+j) =buf;
}
i++;
j--;
}
} while (i <= j);
if (i < b) QuickSort (arr, i,b);
if (a < j) QuickSort (arr,a,j);
}
// ---------------------------------------------------------------------
void main ()
{
FILE *f;
int *X, N;
clock_t start, end;
N=0;
f=fopen ("massiv. txt","rt");
start= clock ();
while (! feof (f))
{
fscanf (f,"%d",X+N);
N++;
}
QuickSort (X,0,N-1);
end= clock ();
printf ("The time was:%f s\n", (end - start) / CLK_TCK);
start= clock ();
fclose (f);
getch ();
}
| Результат роботи швидкого сортування | |||||||||
| Довжина послідовності | Випадкові | Зростає | Спадає | ||||||
| 312 | 17 | 927 | 85 | 10009 | середнє | ||||
| 10 | Пересилан-ня | 31 | 21 | 35 | 30 | 35 | 30,4 | 6 | 21 |
| Порівняння | 16 | 20 | 11 | 19 | 13 | 15,8 | 23 | 15 | |
| 50 | Пересилан-ня | 258 | 240 | 259 | 240 | 255 | 250,4 | 31 | 107 |
| Порівняння | 186 | 249 | 188 | 171 | 178 | 194,4 | 214 | 213 | |
| 200 | Пересилан-ня | 1219 | 1292 | 1240 | 1227 | 1241 | 1243,8 | 126 | 428 |
| Порівняння | 1130 | 1357 | 1149 | 1377 | 1308 | 1264,2 | 1562 | 1433 | |
| 1000 | Пересилан-ня | 8055 | 7945 | 8038 | 7997 | 8109 | 8028,8 | 642 | 2139 |
| Порівняння | 7697 | 7652 | 6906 | 7161 | 7030 | 7289,2 | 11779 | 9793 | |
| 5000 | Пересилан-ня | 48603 | 47722 | 48371 | 48384 | 48839 | 48383,8 | 3167 | 10664 |
| Порівняння | 47782 | 55603 | 46085 | 48296 | 44447 | 48442,6 | 69909 | 62812 | |
| 10000 | Пересилан-ня | 104555 | 103469 | 103598 | 103603 | 104151 | 103875,2 | 6333 | 263688 |
| Порівняння | 97973 | 106301 | 106409 | 106769 | 106294 | 104749,2 | 148007 | 140384 | |
Кількість пересилань:
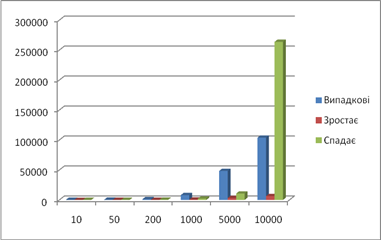
Кількість порівняннь:
Сортування купою - алгоритм сортування на основі порівнянь. Він полягає у побудові купи і за її допомогою виділення наступного елемента відсортованої послідовності. Хоча, на практиці, він трохи повільніший на більшості машин, ніж швидке сортування, у нього є перевага - швидкодія у найгіршому випадку рівна (n log n). Є не стабільним алгоритмом.
Код сортування злиттям:
#include <stdio. h>
#include <conio. h>
#include <stdlib. h>
#include <time. h>
// Heap------------------------------------------------------------------
void doHeap (int *arr, int k, int n)
{
int c; int a = * (arr+k);
while (k <= n/2)
{
c = 2*k;
if (c < n && * (arr+c) < * (arr+c+1)) c++;
if (a >= * (arr+c)) break;
* (arr+k) = * (arr+c);
k = c;
}
* (arr+k) = a;
}
void HeapSort (int *a, int n)
{
int i;
for (i=n/2; i >= 0; i--) doHeap (a, i, n-1);
for (i = n-1; i > 0; i--)
{
int buf=*a;
*a=* (a+i);
* (a+i) =buf;
doHeap (a,0, i-1);
}
}
// ----------------------------------------------------------------------
void main ()
{
FILE *f;
int *X, N;
clock_t start, end;
clrscr ();
N=0;
f=fopen ("massiv. txt","rt");
while (! feof (f))
{
fscanf (f,"%d",X+N);
N++;
}
start= clock ();
HeapSort (X,N);
end= clock ();
printf ("The time was:%f s\n", (end - start) / CLK_TCK);
fclose (f);
getch ();
}
| Результат сортування купою | |||||||||
| Довжина послідовності | Випадкові | Зростає | Спадає | ||||||
| 312 | 17 | 927 | 85 | 10009 | середнє | ||||
| 10 | Пересилання | 82 | 83 | 83 | 83 | 85 | 83,2 | 86 | 77 |
| Порівняння | 54 | 56 | 56 | 56 | 60 | 56,4 | 59 | 46 | |
| 50 | Пересилання | 532 | 535 | 535 | 535 | 544 | 536,2 | 564 | 497 |
| Порівняння | 490 | 495 | 499 | 495 | 508 | 497,4 | 537 | 435 | |
| 200 | Пересилання | 2567 | 2532 | 2544 | 2555 | 2550 | 2549,6 | 2682 | 2410 |
| Порівняння | 2808 | 2758 | 2767 | 2784 | 2785 | 2780,4 | 2984 | 2549 | |
| 1000 | Пересилання | 15100 | 15115 | 15040 | 15059 | 15093 | 15081,4 | 15708 | 14310 |
| Порівняння | 18549 | 18561 | 18443 | 18485 | 18485 | 18504,6 | 19541 | 17297 | |
| 5000 | Пересилання | 87068 | 87185 | 87111 | 86934 | 87020 | 87063,6 | 90962 | 83326 |
| Порівняння | 115892 | 116054 | 115947 | 115696 | 115841 | 115886 | 122105 | 109970 | |
| 10000 | Пересилання | 184192 | 184125 | 184244 | 184256 | 184293 | 184222 | 191422 | 176974 |
| Порівняння | 251886 | 251786 | 251951 | 251920 | 251997 | 251908 | 263688 | 240349 | |
Кількість пересилань:
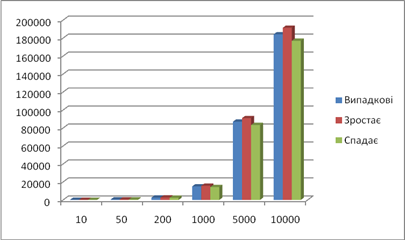
Кількість порівняннь:
Програма генерації послідовностей:
#include <stdio. h>
#include <stdlib. h>
void main ()
{
FILE *f;
int n;
int i,m,s,*a;
if ( (f=fopen ("massiv. txt","wt")) ! =NULL)
{
printf ("Enter amount of elements ");
scanf ("%d",&n);
printf ("Choos method (0: rand; 1: rand up; 2: rand down)");
scanf ("%d",&m);
printf ("Enter sort combination ");
scanf ("%d",&s);
srand (s);
for (i=0; i<n; i++)
* (a+i) =rand ()%30000;
switch (m)
{
case 0: {
for (i=0; i<n; i++)
fprintf (f,"%d\n",* (a+i)); }
break;
case 1: {
int buf=0;
for (int i=1; i<n; i++)
{
buf=* (a+i);
for (int j=i-1; j>=0 && * (a+j) >buf; j--)
* (a+j+1) =* (a+j);
* (a+j+1) =buf;
}
for (i=0; i<n; i++)
fprintf (f,"%d\n",* (a+i)); }
break;
case 2: {
int buf=0;
for (int i=1; i<n; i++)
{
buf=* (a+i);
for (int j=i-1; j>=0 && * (a+j) <buf; j--)
* (a+j+1) =* (a+j);
* (a+j+1) =buf;
}
for (i=0; i<n; i++)
fprintf (f,"%d\n",* (a+i)); }
break;
}
}
fclose (f);
}
Висновок
Виконуючи цю роботу я ознайомився і навчився писати різні алгоритми сортування. Існує дуже багато алгоритмів сортування, кожний зі своїми перевагами, недоліками і ефективні в тому чи іншому випадку, виконання цієї роботи допомогло мені зрозуміти принципи роботи деяких з них і коли який з них слід застосовувати.
Похожие работы
... сортування включенням; - сортування вибором; - сортування обміном. У курсовій роботі ми детально розглянемо швидкі алгоритми сортування елементів масиву, проведемо їх порівняльний аналіз. Крім цього, розглянемо і прямі методи сортування, їх позитиви і недоліки, що дасть змогу краще визначити ефективність і складність швидких алгоритмів сортування. Розділ І. Прямі методи сортування масивів ...
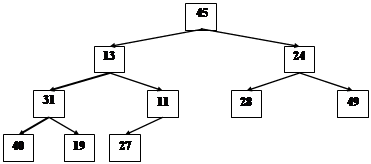
... M2(n) = O(l n), C2(n) = O(l n). Оскільки l = log2n, M2(n)=O(n log2 n)), C2(n)=O(n log2 n), Але З(n) = C1(n) + C2(n), M(n) = M1(n) + M2(n). Тому що C1(n) < C2(n), M1(n) < M2(n), остаточно одержуємо оцінки складності алгоритму TreeSort за часом: M(n) = O(n log2 n), C(n) = O(n log2 n), У загальному випадку, коли n не є ступенем 2, сортуюче дерево будується трохи інакше. “Зайвий” елемент ...
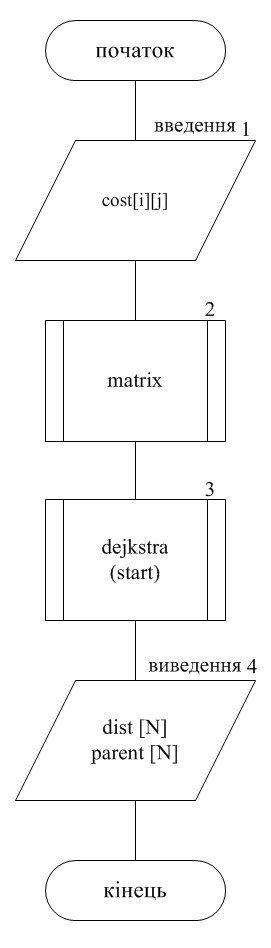
... , пірамідальне сортування, швидке сортування Хоара та метод цифрового сортування. 2. Постановка задачі Необхідно розробити програму, в якій реалізувати алгоритм сортування методом піраміди. Ця програма буде застосовуватись для сортування числових даних у файлі. 3. Обгрунтування вибору методів розв’язку задачі Алгоритм пірамідального сортування HeapSort використовує представлення ...

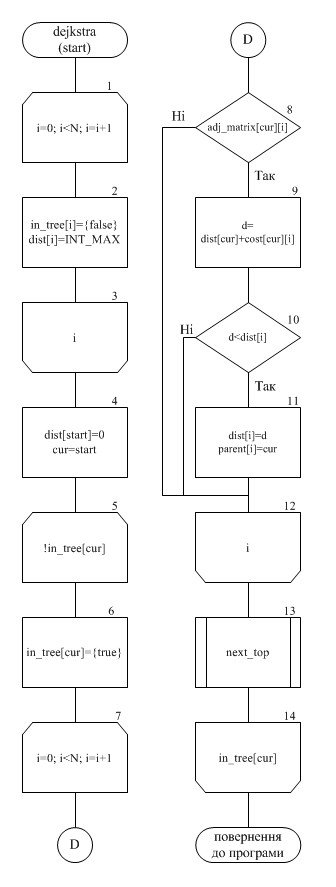
... оцінка складності алгоритму - О(n*log(n)). Даний алгоритм має сенс застосування лише на великих обсягах даних від 500-1000 елементів. Тільки в цьому випадку можна побачити виграш алгоритму в ефективності. Для менших обсягів даних він малопридатний. 3 Синтез машини Тьюрінга 3.1 Загальні відомості Машина Тьюрінга - це кінцевий автомат, забезпечений безкінченою стрічкою і читаючою/записуючою голівкою ...
0 комментариев