Навигация
4. Описание алгоритма
В данном разделе наводятся алгоритмы для нахождения победителей выборов. Для определения победителей Борда и Копленда воспользуемся непосредственно приведенными выше правилами, то есть реализуем их программно. Сложность алгоритмов, описанных ниже, прямо пропорциональна количеству групп избирателей и количества кандидатов, что еще раз подтверждает принадлежность данной задачи к Р-типу.
4.1 Определение победителя Борда
Для нахождения оценок Борда кандидаты ранжируются, то есть за каждое место в шкале избирателей кандидат получает определенное количество баллов.
Далее эти баллы суммируются.
Введем следующие переменные.
Пусть М – количество кандидатов;
S – количество групп избирателей;
Nаme[M] – массив имен избирателей;
Rаng[1..M, 1..S] – профиль преимуществ;
Many[S] – количество избирателей в каждой группе;
Bord[M] – массив оценок кандидатов.
Рассматриваем отдельно каждую группу избирателей. Для этой группы кандидат получает оценку [количество избирателей many[i]]*([количество кандидатов M] – [текущее значение счетчика j]). Найденная оценка добавляется к предыдущей. Алгоритм продолжает работу до тех пор, пока не будут рассмотрены все группы избирателей (i=S).
По правилу Борда получаем следующий алгоритм для нахождения оценок Борда.
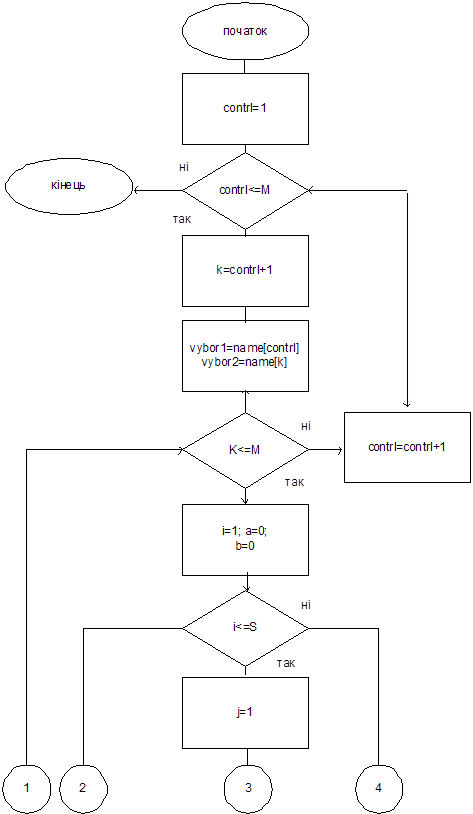
Рис. 4.1 Алгоритм нахождения оценок Борда.
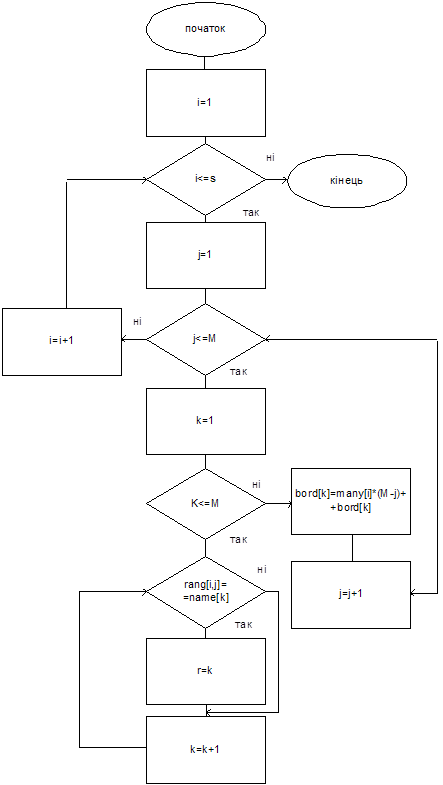
Рис. 4.2 Алгоритм нахождения оценок Копленда (начало)
4.2 Нахождение оценки Копленда
Для нахождения оценки Копленда кроме выше приведенных используем следующие переменные: Kopl[M] – массив оценок Копленда; Vybor1, vybor2 – вспомогательные переменные; используются для пересмотра имен кандидатов из массива имен name.
Сравнение проходит следующим образом.
Переменной vybor1 присваиваем значение имени первого кандидата из множественного числа имен name (contrl=1), а vybor2 – следующее (k=contrl+1). Если vybor1 находится выше, чем vybor2, в преимуществах избирателей всех групп, то к оценке Копленда (kopl[contrl]) кандидата vybor1 добавляется глазок, а vybor2 (kopl[k]) – отнимается и наоборот. Дальше переменной vybor2 присваивается следующее значение из массива имен (k=k+1), и процедура сравнения опять повторяется. Цикл продолжается до тех пор, пока не исчерпаются имена в списке кандидатов.
После этого переменной vybor1 присваивается второе имя из списка кандидатов (contrl=contrl+1), а vybor2 – третья. Опять проходит цикл по переменной vybor2. Цикл по переменной vybor1 заканчивается тогда, когда будут пересмотрены все кандидаты.
Получаем следующий алгоритм нахождения оценки Копленда.
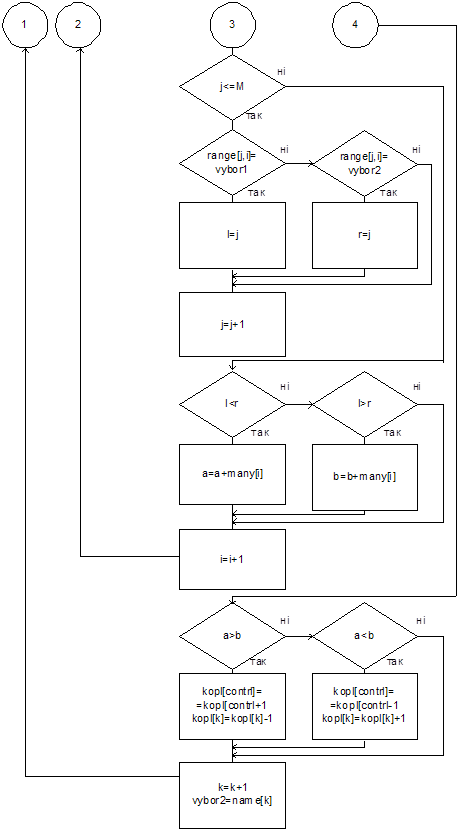
Рис. 4.3 Алгоритм нахождения оценок Копленда (конец)
4.3 Алгоритм определения победителя за правилами Борда или Копленда
Как можно было увидеть, победителем по Борду (Копленду) является кандидат с наивысшей суммой очков. Поэтому процесс его определения является одинаковым для обоих случаев, и я его объединила одним алгоритмом. Как известно, правила Копленда и Борда порождают множественное число решений. Для нахождения победителя используем следующие переменные: K – количество победителей; Max – оценка победителей; Hl[M] – массив номеров победителей.
Сначала массив номеров победителей заполняем нулями.
Массивы оценок Копленда и Борда (kopl и bord) заменим формальным массивом v[M].
После того, как мы нашли оценки для кандидатов (массивы kopl и bord), среди них ищем максимальную (max). Дальше отбираем кандидатов, оценка которых равняется max (их номера из массива name заносятся в массив hl), и считаем количество победителей (k).
Пересматриваем заполненный массив hl. Если в нем только первое значение отличающееся от нуля, то значит, что мы нашли единственного победителя, и, следовательно, сохранили условие нейтральности.
В другом случае просматриваем те значения имен кандидатов (массив name), номера которых встречаются в массиве hl. Отобраны имена кандидатов упорядочиваем по списку. Победителем становится тот, имя которого находится первым в данном списке.
В данном случае условие нейтральности не сохраняется.
Мы получили следующий алгоритм.

Рис. 4.4 Алгоритм определения победителя (начало).
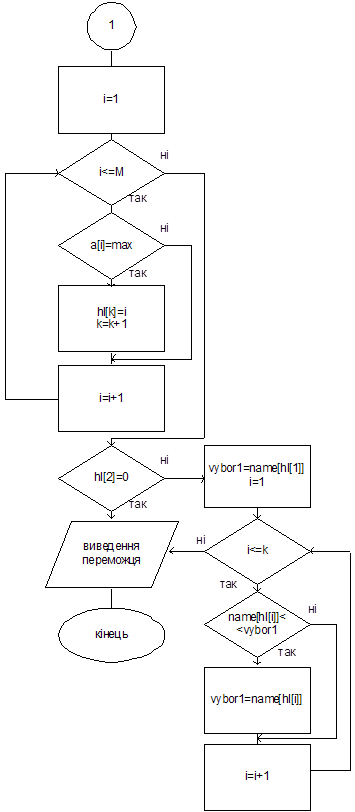
Рис. 4.5. Алгоритм определения победителя (конец).
5. Описание программы
5.1 Выбор технологии программирования
Наиболее распространенными парадигмами программирования, которые к тому же могут быть использованы в данной курсовой работе, являются парадигмы процедурного и объектно-ориентированного программирования.
Парадигма процедурного программирования больше всего широко распространена среди существующих словно программирование (например, Си и Паскаль). Здесь явно выделяют два вида разнообразных сущностей:
1) процедуры, которые исполняют активную роль, то есть представляются тем, которое задает поведение (функционирование) программы;
2) данные, что исполняют пассивную роль, то есть представляют тем, которое прорабатывается средством, продиктованным процедурами. Возможность составлять процедуры из команд (операторов) и вызывать их является ключом данной парадигмы. Особенностью этой парадигмы являются "боковые эффекты", которые возникают в тех случаях, когда разнообразные процедуры, которые используют общие данные, независимо их изменяют.
В процедурной парадигме активная роль в организации поведения уделяется процедурам, а не данным; причем процедура активизируется вызовом. Подобные средства задания поведения удобны для описаний детерминированной последовательности действий или одного процесса, или нескольких, но строго взаимозависимых процессов. При использовании программирования, ориентированного на данные, активную роль играют данные, а не процедуры. Здесь со структурами активных данных связывают некоторые действия (процедуры), которые активизируются тогда, когда осуществляется доступ к этим данным. Некоторые специалисты называют это средство активации действий "демонами". Программирование, ориентированное на данные, позволяет организовать поведение мало зависимых процессов, что тяжело реализовать в процедурной парадигме. Имела зависимость процессов значит, что они могут рассматриваться и программироваться отдельно. Однако при использовании парадигмы, управляемой данными, эти независимо запрограммированные процессы могут взаимодействовать между собой без их изменения (то есть без перепрограммирования). Парадигма объектного программирования в отличие от процедурной парадигмы не разделяет программу на процедуры и данные. Здесь программа организуется вокруг сущностей, названных объектами, что включают локальные процедуры (методы) и локальные данные (переменные). Поведение (функционирование) в этой парадигме организуется путем пересылки сообщений между объектами. Объъект, получив сообщение, осуществляет его локальную интепретацию, базируясь на локальных процедурах и данных. Такой подход позволяет описывать сложные системы наиболее естественным путем. Особенно он удобен для интегрированных IC. Объектно-ориентированное программирование (ООП) базируется на абстракциях данных. В основе этого метода лежит представление предметной области в виде совокупности объектов, которые взаимодействуют между собой через передачу сообщений. Модель абстракции данных заключается в инкапсуляции данных и операций над ними в отдельный классовый тип. Доступ к данным возможная лишь с помощью инкапсулированных операций. Классовый тип является автономно завершенным и позволяет полное или частичное наследование для других классов. ООП концентрируется на цели задачи, для которой разрабатывается программа. Задача строится как совокупность объектов, которые взаимодействуют между собой с помощью сообщений. Элементы программы разрабатываются в соответствии с объектами в описании задачи. Суть ООП заключается в определении наиболее удачных объектовых типов. Объектовый тип служит модулем, который может быть использованным для решения других подобных задач. Такой подход не нуждается в специальной вычислительной технике, но существенно отличается характером мышления исполнителей в сравнении с процедурными языками программирования.
Через очевидную простоту алгоритма для реализации задачи лучше всего выбрать процедурную парадигму программирования и языка Паскаль или Си. Конечно, для написания красивого интерфейса можно взять объектно-ориентированные языки C Builder или Delphi. Однако, как можно было увидеть из рассмотрения алгоритма задачи, построение интерфейса сводилось бы к последовательному выведению окон. Еще одним аргументом в интересах словно Паскаль или Си есть размеры программы, которые бы при использовании C Builder или Delphi были намного большими.
Среди двух языков – Паскаль и Си, – я изберу Паскаль как более привычный для себя.
5.2 Структура программы
Структурно данную программу можно разделить на блоки.
Каждый блок может быть отнесен к одной из функциональных групп:
1. Построение интерфейса;
2. Реализация алгоритмов, представленных в разделе 4.
Следовательно, программа имеет следующую структуру:
Процедура victory – это реализация алгоритма определения победителя, описанного в предыдущем разделе. Во время вызова данной процедуры задается массив оценок Борда или Копленда, а также текст, для выведения результатов (им служат слова "Копленда" и"Борда"). В предыдущем разделе уже было обосновано, почему для определения победителя за разными правилами использован единственный алгоритм. Процедура help выводит список имен кандидатов в нижней строке экрана. Она введена для облегчения ввода информации пользователем.
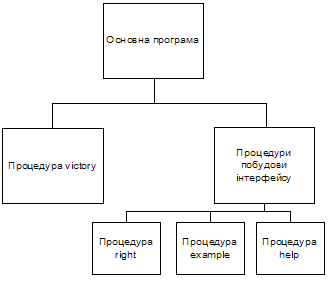
Рис. 5.1 Структура программы.
Процедура example содержит данные контрольного примера. Она введена для облегчения проверки правильности работы программы и носит демонстрационный характер.
Процедура right предназначена для проверки правильности вводу символа. Она используется при выборе внесения информации (демонстрация контрольного примера или самостоятельное внесение профиля) и выборе способа заноса данных (отдельными избирателями или работниками избирательного комитета).
Перейдем к рассмотрению основной программы.
Прежде всего в ней проходит вызов и взаимосвязь описанных выше процедур.
Процедуры построения интерфейса вызываются в начале работы программы. Они предназначенные для облегчения внесения данных.
Процедура victory определяет победителя и выводит результат голосования по определенному правилу. Потому ее вызов происходит напоследок основной программы.
Опишем переменные, которые используются в основной программе.
N: кол-во избирателей;
M: кол-во кандидатов;
s: кол-во групп;
rang: профиль преимуществ;
а,b: для определения оценки Копленда (используется в бинарных сравнениях);
kopl: массив оценок Копленда;
vybor1, vybor2: переменные внешних циклов при определении оценки Копленда;
bord: массив оценок Борда;
name: массив имен кандидатов;
к, и, j, l, r: вспомогательные переменные;
many: массив групп избирателей.
Опишем структуру программы.
Сначала программа просит внести всю нужную информацию. Пользователь должен указать количество избирателей и кандидатов и способ заноса информации (будет ли свои преимущества вносить каждый избиратель отдельно, будет ли это проводить комиссия, оперируя сгруппированными данными). Дальше идет внесение профиля преимуществ и проверка на его корректность. Профиль является некорректным, если в нем встречается имя лица, которое не является выше указанным кандидатом, или же имена кандидатов повторяются.
В программе используются алгоритмы правил Борда и Копленда, указанные в предыдущем разделе. Согласно полученных оценок определяется победитель с помощью процедуры victory, и проходит выведение результата.
Следует заметить, что полученные победители Копленда и Борда могут не совпадать, что еще раз свидетельствует о несовершенстве правил голосования большинством голосов. Результаты работы алгоритма будут показаны в соответствующем разделе.
Сложность программы (в данном случае понимается время, тратящее на выполнение), прямо пропорционально зависит от величины количества избирателей и кандидатов.
Так как данная программа носит более демонстрационный характер, то я ввела границу для количества избирателей и кандидатов для того, чтобы ограничить время выполнения – 200 и 50 соответственно. В общем оно не является существенным, так как всегда можно разбить избирательный округ на более малый с условием того, чтобы выполнялось данное ограничение.
Похожие работы
... Поэтому целесообразно разработать предназначенный для поддержки проведения экспертных исследований АРМ "МАТЭК" ("Математика в экспертизе") на базе РС фирмы "Apple" с использованием современных достижений в области теории и практики экспертных оценок, в области прикладной математической статистики, прежде всего статистики объектов нечисловой природы. Список литературы 1. Орлов А.И. Допустимые ...
... применение количественных методов как при организации экспертизы, так и при оценке суждений экспертов и формальной групповой обработке результатов. Эти две особенности отличают метод экспертных оценок от обычной давно известной экспертизы, широко применяемой в различных сферах человеческой деятельности. Экспертные коллективные оценки широко использовались в государственном масштабе для решения ...

... элемента на качество принимаемых управленческих решений - одна из главных задач оптимизации процессов принятия решений в управлении общественным производством. Одним из условий преодоления субъективизма при подготовке управленческих решений являются методы исследования операций, методы экспертных оценок. Процедура выработки управленческих решений, являясь сложным логико-мыслительным процессом, ...
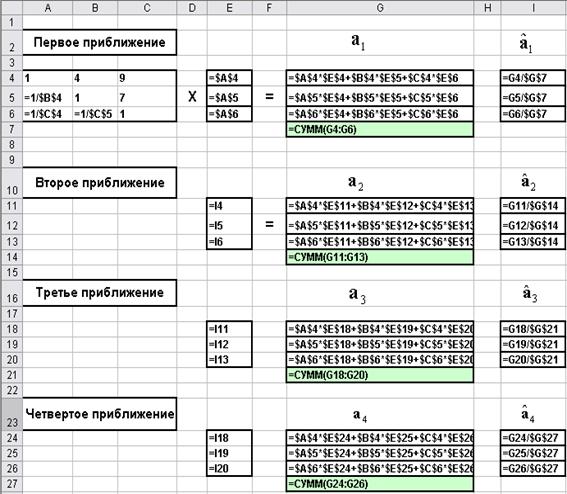


... : Подставляя (6.7) в (6.8) получим более удобное для использования соотношение: , (6.9) где квадратная симметрическая матрица называется матрицей взаимосвязи экспертных оценок и определяется равенством: (6.10) Для иллюстрации работы вышеописанного алгоритма приведем простой пример. экспертиза объект оценка Пример 1 ...
0 комментариев