Навигация
С помощью среднего (общего) коэффициента эластичности дайте сравнительную оценку силы связи фактора с результатом
24629
знаков
8
таблиц
6
изображений
4. С помощью среднего (общего) коэффициента эластичности дайте сравнительную оценку силы связи фактора с результатом.
Рассчитаем коэффициент эластичности для линейной модели:
· Для уравнения прямой: y = 5,777+7,122∙x
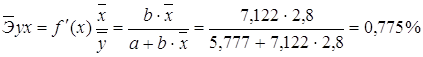
· Для уравнения степенной модели ![]() :
:
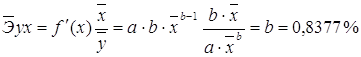
· Для уравнения экспоненциальной модели![]() :
:
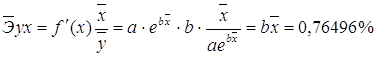
Для уравнения полулогарифмической модели ![]() :
:
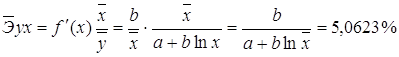
· Для уравнения обратной гиперболической модели 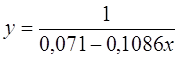 :
:
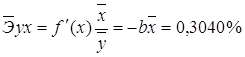
· Для уравнения равносторонней гиперболической модели 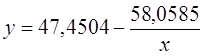 :
:
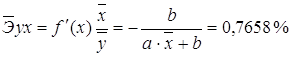
Сравнивая значения ![]() , характеризуем оценку силы связи фактора с результатом:
, характеризуем оценку силы связи фактора с результатом:
· ![]()
· ![]()
· ![]()
· ![]()
· ![]()
· ![]()
Известно, что коэффициент эластичности показывает связь между фактором и результатом, т.е. на сколько% изменится результат y от своей средней величины при изменении фактора х на 1% от своего среднего значения. В данном примере получилось, что самая большая сила связи между фактором и результатом в полулогарифмической модели, слабая сила связи в обратной гиперболической модели.
5. Оценка качества уравнений с помощью средней ошибки аппроксимации.
Подставляя в уравнение регрессии фактические значения х, определим теоретические (расчетные) значения ![]() . Найдем величину средней ошибки аппроксимации
. Найдем величину средней ошибки аппроксимации ![]() :
:
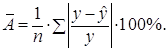
В среднем расчетные значения отклоняются от фактических на:
· Линейная регрессия. ![]() =
=![]() *100%= 8,5%, что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.
*100%= 8,5%, что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.
Качество построенной модели оценивается как хорошее, так как ![]() не превышает 8 -10%.
не превышает 8 -10%.
· Степенная регрессия. ![]() =
=![]() *100%= 8,2%, что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.
*100%= 8,2%, что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.
Качество построенной модели оценивается как хорошее, так как ![]() не превышает 8 -10%.
не превышает 8 -10%.
· Экспоненциальная регрессия. ![]() =
=![]() *100%= 9%, что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.
*100%= 9%, что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.
Качество построенной модели оценивается как хорошее, так как ![]() не превышает 8 -10%.
не превышает 8 -10%.
· Полулогарифмическая регрессия. ![]() =
=![]() *100%= 7,9 что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.
*100%= 7,9 что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.
Качество построенной модели оценивается как хорошее, так как ![]() не превышает 8 -10%.
не превышает 8 -10%.
· Гиперболическая регрессия. ![]() =
=![]() *100%= 9,3 что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.
*100%= 9,3 что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.
Качество построенной модели оценивается как хорошее, так как ![]() не превышает 8 -10%.
не превышает 8 -10%.
· Обратная регрессия. ![]() =
=![]() *100%= 9,9 3 что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.
*100%= 9,9 3 что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.
Качество построенной модели оценивается как хорошее, так как ![]() не превышает 8 -10%.
не превышает 8 -10%.
6. Рассчитаем F-критерий:
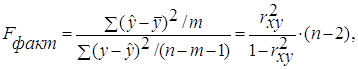
· Линейная регрессия. ![]() =
= 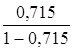 *19= 47,579
*19= 47,579
где ![]() =4,38<
=4,38< ![]()
· Степенная регрессия. ![]() =
=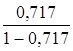 *19= 48,257
*19= 48,257
где ![]() =4,38<
=4,38< ![]()
· Экспоненциальная регрессия. ![]() =
=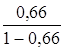 *19= 36,878
*19= 36,878
где ![]() =4,38<
=4,38< ![]()
· Полулогарифмическая регрессия. ![]() =
=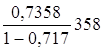 *19= 52,9232
*19= 52,9232
где ![]() =4,38<
=4,38< ![]()
· Гиперболическая регрессия. ![]() =
=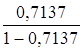 *19= 47,357
*19= 47,357
где ![]() =4,38<
=4,38< ![]()
· Обратная регрессия. ![]() =
=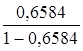 *19= 36,627
*19= 36,627
где ![]() =4,38<
=4,38< ![]()
Для всех регрессий ![]() =4,38<
=4,38< ![]() , из чего следует, что уравнения регрессии статистически значимы.
, из чего следует, что уравнения регрессии статистически значимы.
Вывод: ![]() остается на допустимом уровне для всех уравнений регрессий.
остается на допустимом уровне для всех уравнений регрессий.
| А | R^2 | Fфакт | |
| Линейная модель | 8,5 | 0,714 | 47,500 |
| Степенная модель | 8,2 | 0,718 | 48,250 |
| Полулогарифмическая модель | 7,9 | 0,736 | 52,920 |
| Экспоненциальная модель | 9,0 | 0,660 | 36,870 |
| Равносторонняя гипербола | 9,3 | 0,714 | 47,350 |
| Обратная гипербола | 9,9 | 0,453 | 15,700 |
Все уравнения регрессии достаточно хорошо описывают исходные данные. Некоторое предпочтение можно отдать полулогарифмической функции, для которой значение R^2 наибольшее, а ошибка аппроксимации – наименьшая
7. Рассчитаем прогнозное значение результата по линейному уравнению регрессии, если прогнозное значение фактора увеличится на 7% от его среднего уровня. Определим доверительный интервал прогноза для уровня значимости α=0,05:
Прогнозное значение ![]() определяется путем подстановки в уравнение регрессии
определяется путем подстановки в уравнение регрессии ![]() соответствующего (прогнозного) значения
соответствующего (прогнозного) значения ![]() .
.![]() 5,777+7,122*2,996=27,114
5,777+7,122*2,996=27,114
где ![]() =
= ![]() =2,8*1,07=2,996
=2,8*1,07=2,996
Средняя стандартная ошибка прогноза ![]() :
:
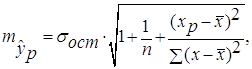 =
=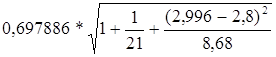 =3,12
=3,12
где 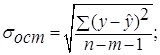 =
=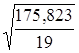 =0,697886
=0,697886
Предельная ошибка прогноза:
![]()
![]()
![]()
Доверительный интервал прогноза
![]() где
где ![]()
![]() =27,11
=27,11![]() 6,53;
6,53;
![]()
![]() 27,11–6,53 = 20,58
27,11–6,53 = 20,58
27,11+6,53 = 33,64
Выполненный прогноз среднедушевых денежных доходов в месяц, x оказался надежным (р = 1 – α = 1 – 0,05 = 0,95), но неточным, так как диапазон верхней и нижней границ доверительного интервала ![]() составляет 2,09 раза:
составляет 2,09 раза:
![]() =
=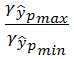 =
=![]() =1,63
=1,63
Похожие работы
о формуле: Таким образом, среднее число государственных вузов в России составляет 570 шт, а вариация 169. ТЕМА 2. Модель парной регрессии Задача 12 1. Предварительно вычисленная ковариация двух рядов составляет -4.32, а вариация ряда занятых в экономике равна 7,24. Средние выборочные равняются 68,5 и 5,87 соответственно. Оцените параметры линейного уравнения парной ...
... деле независимой постоянной составляющей в отклике нет (альтернатива – гипотеза Н1: a ¹ 0). Для проверки этой гипотезы, с заданным уровнем значимости g, рассчитывается t-статистика, для парной регрессии: Значение t-статистики сравнивается с табличным значением tg/2(n-1) - g/2-процентной точка распределения Стьюдента с (n-1) степенями свободы. Если |t| < tg/2(n-1) – гипотеза Н0 не ...
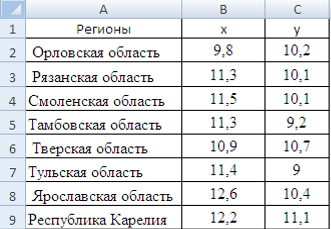
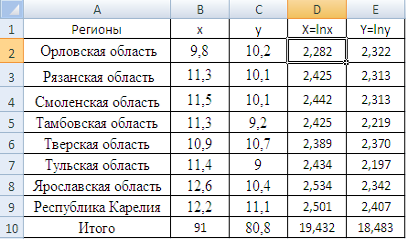
... и детерминации и F-критериев Фишера наибольшие. 3. Множественная регрессия Цель работы – овладеть методикой построения линейных моделей множественной регрессии, оценки их существенности и значимости, расчетом показателей множественной регрессии и корреляции. Постановка задачи. По данным изучаемых регионов (таблица 1) изучить зависимость общего коэффициента рождаемости () от уровня бедности ...
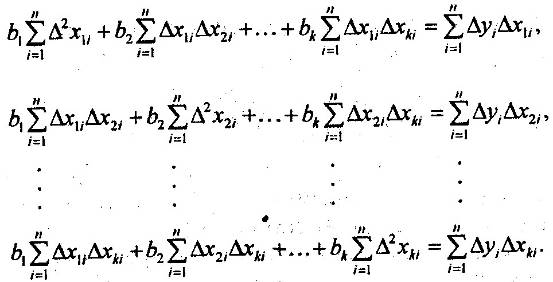

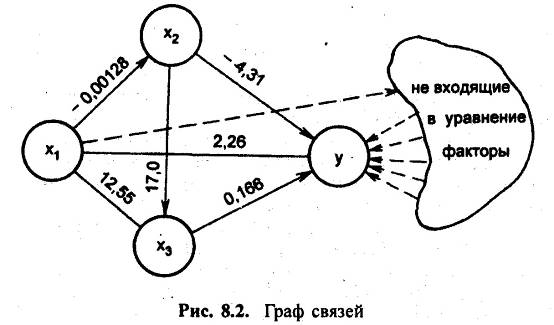
... t-критерий Стъюдента и доверительные интервалы каждого из показателей. Выдвигается гипотеза Но о случайной природе показателей, т.е. о незначимом их отличии от нуля. Оценка значимости коэффициентов регрессии и корреляции с помощью f-критерия Стьюдента проводится путем сопоставления их значений с величиной случайной ошибки: Оценка значимости коэффициентов чистой регрессии с помощью /-критерия ...
0 комментариев