Міністерство освіти і науки України
Національний технічний університет
„Харківський політехнічний інститут"
Курсова робота
з курсу:
„Теорія імовірностей та математична статистика”
по темі: "Розрахунок типових задач з математичної статистики"
Харків 2007
Анотація
У виконаному курсовому проекті наведено огляд теоретичних відомостей з курсу Теорії ймовірностей та математичної статистики, окреслено послідовність виконання типових завдань з Теорії ймовірностей. І також виконано розрахунок типової задачі з визначення законів розподілення випадкових величин.
Зміст
1. Теорія імовірностей та математичної статистики
1.1 Основні закони розподілення випадкових величин
1.2 Числові характеристики дискретних випадкових величин
2. Види типових задач з математичної статистики
3. Загальна методика розв‘язання типових задач
3.1 Обчислити значення критерію збіжності Пірсона
3.2 Зробити висновок про вірність висунутої гіпотези H0
4. Приклад розв'язку типової задачі
Висновки
Список літератури
1. Теорія імовірностей та математичної статистики 1.1 Основні закони розподілення випадкових величин
Дискретною називають випадкову величину, можливі значення якої є окремі ізольовані числа (тобто між двома сусідніми можливими значеннями немає інших), котрі ця величина приймає з певними ймовірностями.
Іншими словами, можливі значення випадкової величини можна пронумерувати. Кількість можливих значень випадкової величини може бути кінцевою або нескінченною (в останньому разі множину усіх можливих значень називають ліченою).
Законом розподілення дискретної випадкової величини називають перелік її можливих значень та відповідних до них ймовірностей.
Закон розподілення дискретної випадкової величини Х може бути задано у вигляді таблиці, перший рядок якої утримує можливі значення xi, а другий - імовірності pi
| X | x1 | x2 | … | xn |
| p | p1 | p2 | … | pn |
причому![]() .
.
Якщо множина можливих значень х нескінчена, то ряд р1 + р2 + … сходиться й його сума дорівнює одиниці.
Закон розподілення випадкової дискретної величини Х може бути подано також в аналітичній формі (у вигляді формули)
P (X=xi) =xi),
або за допомогою функції розподілення імовірності
F (xi) =P (X<xi).
Біноміальним називають закон розподілення дискретної випадкової величини Х - кількості появ результатів у n незалежних випробуваннях, в кожному з яких імовірність появи результату дорівнює p; імовірність можливого значення Х=k (числа k появ результату) обчислюють за формулою Бернуллі:
![]() .
.
Якщо кількість випробувань значна, а імовірність р появи результату в кожному випробуванні дуже мала, то використовують наближену формулу
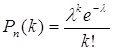 ,
,
де k - кількість появи результату в n незалежних випробуваннях, np (середнє число появ результату в n випробуваннях), і кажуть, що випадкова величина розподілена за законом Пуассона.
1.2 Числові характеристики дискретних випадкових величин
Характеристикою середнього значення даної випадкової величини є математичне очікування.
Математичним очікуванням дискретної випадкової величини називають суму добутків усіх її можливих значень на їх імовірності:
M [X] = x1p1 + x2p2 + … + xnpn
Якщо дискретна випадкова величина приймає лічену множину значень, то
![]() ,
,
математичне очікування існує, якщо ряд в правій частині рівності сходиться абсолютно. Математичне очікування має наступні властивості: математичне очікування постійної величини дорівнює самій постійній:
M [C] = C
Постійних множник можна виносити за знак математичного очікування:
M [CX] = CM [X]
Математичне очікування взаємно незалежних випадкових величин дорівнює добутку математичних очікувань множників:
M [X1X2…Xn] = M [X1] *M [X2] *…*M [Xn]
Математичне очікування суми випадкових величин дорівнює сумі математичних очікувань доданків:
M [X1+X2+…+Xn] = M [X1] + M [X2] + … +M [Xn]
Характеристиками розсіювання випадкової величини навколо математичного очікування служать дисперсія та середнє квадратичне відхилення.
Дисперсією випадкової величини Х називають математичне очікування квадрату відхилення випадкової величини від її математичного очікування:
D [X] = M [X - M [X]] 2=M [X2] - (M [X]) 2
Дисперсія володіє наступними властивостями:
Дисперсія постійної дорівнює 0.
Постійний множник можна виносити за знак дисперсії, початково піднісши його до квадрату:
D [CX] = C2D [X]
Дисперсія суми незалежних випадкових величин дорівнює
сумі дисперсій доданків:
D [X1 + X2 + … + Xn] = D [X1] + D [X2] + … + D [Xn]
Середнім квадратичним відхиленням називають квадратний корінь з дисперсії.
Функцією розподілення називають функцію F (x), що визначає для кожного значення х імовірність того, що випадкова величина Х прийме значення, менше х, тобто
F (x) = P (X<x).
Досить часто замість терміну "функція розподілення" використовують термін "інтегральна функція розподілення". Функція розподілення має наступні властивості: значення функції розподілення належать відрізку [0; 1]
Функція розподілення є не спадаючою функцією:
![]()
Наслідок 1: Імовірність того, що випадкова величина Х прийме значення у інтервалі (a,b), дорівнює приросту функції на цьому інтервалі.
Наслідок 2: Імовірність того, що неперервна випадкова величина Х прийме одне визначене значення, наприклад, х1, дорівнює 0.
Якщо всі можливі значення випадкової величини Х належать інтервалу (a,b), то
![]()
Справедливі також наступні межові співвідношення:
![]()
Функція розподілення неперервна зліва:
![]()
Нормальним називають розподілення імовірностей неперервної випадкової величини Х, щільність якого має вигляд:
![]() ,
,
де a - математичне очікування випадкової величини Х, - середнє квадратичне значення Х.
Для нормального розподілення імовірність того, що Х прийме значення, що належать інтервалу (), дорівнює
![]() , де
, де
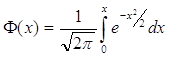 - функція Лапласа.
- функція Лапласа.
Експоненціальним називають розподілення імовірностей неперервної випадкової величини Х, яке описується щільністю:
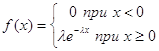 , де - постійна додатна величина.
, де - постійна додатна величина.
Функція розподілення експоненціального закону:
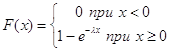 ,
,
а імовірність попадання у інтервал (a,b) безперервної випадкової величини Х, розподіленою за експоненціальним законом дорівнює:
![]() .
.
2. Види типових задач з математичної статистики
Тип 1
Ланка дослідів дала певну послідовність результатів. Вирахувати середнє значення виміряння, дисперсію, похибки, а також встановити закони розподілення результатів розрахунку [f (x), F (x)]
Тип 2
В результаті експерименту можливі n випадків. Побудувати математичну модель, що характеризує випадкову величину та побудувати закони розподілення f (x) та F (x), використовуючи результати 100 експериментів.
Тип 3
Число заявок, що надходять за 1 секунду в систему, характеризується поданими результатами. Побудувати математичну модель, що пояснює результати експериментів і вирахувати закони розподілення f (x) та F (x).
Тип 4
Час опрацювання заявок у обчислювальної системі приведено нижче (у мікросекундах). Побудувати математичну модель, що характеризує результати експериментів і розрахувати закони розподілення f (x) та F (x).
3. Загальна методика розв‘язання типових задач
Позначимо випадкову величину, закон розподілення якої підлягає визначенню, X.
Виділити найбільше та найменше значення випадкової величини X у вибірці (це потрібно для того, щоб провести розбиття діапазону зміни випадкової величини на інтервали).
Провести розбиття діапазону зміни значень випадкової величини X на інтервали. Кількість інтервалів у методі Пірсона (а саме таким ми будемо користуватися для перевірки гіпотез), взагалі, обмежена.
Таким чином, потрібно розбити весь діапазон значень X на інтервали, кількість та межі яких потрібно буде визначати.
В загальному випадку (і для безперервної випадкової величини, і для дискретної) розбиття проводять наступним чином.
Межі інтервалів можуть бути як цілими, так і дробовими. Довжина інтервалів не обмежена і залежить від частоти появи значень. Але обов’язково потрібно виконати наступну умову: кількість значень випадкової величини X, що попадають у кожний інтервал, повинна бути не менша 10. Ця умова забезпечує „хороші" (статистичний термін) результати застосування методу збіжності Пірсона.
Пояснюється це тим, що при меншій кількості значень випадкової величини X, що попадають в межі будь-якого інтервалу розбиття, випадкові відхилення (флуктуації) її значень від істинного зміщують практично отримане значення до сусідніх інтервалів. Загальна картина погіршується, похибка розрахунків збільшується.
Позначимо кількість інтервалів розбиття s.
Окрім цього потрібно врахувати також число ступенів свободи (чого, буде вказано далі) - позначимо його k (воно знадобиться при підрахунку критерію збіжності Пірсона, бо має для нього дуже важливе значення; а поки воно впливатиме лише на розбиття діапазону значень випадкової величини X). В нашому випадку оцінимо його значення числом інтервалів (в дійсності число ступенів свободи менше: k<s), тобто вважатимемо k≈s. Пояснимо такий вибір тим, що, взагалі, число ступенів свободи при першому наближенні - число незалежних значень, які може приймати випадкова величина (які їй ніщо не заважає набувати). В нашому випадку (при розбитті діапазону зміни значень випадкової величини X на s інтервалів) кількість значень випадкової величини, що попадають в кожний інтервал, буде також випадковою величиною. Як би ми не проводили розбиття всього діапазону на s інтервалів, завжди б отримали s таких кількостей.
Якщо k приблизно дорівнює декільком десяткам (тобто приблизно k>30), то число значень, що попадають в кожний інтервал розбиття, можна зменшити до 5, або навіть до 3. За великих об’ємів вибірки довжину всіх інтервалів беруть однаковою.
Необхідне для застосування методу Пірсона розбиття можна звести до розбиття на рівновіддалені.
1) Для більшої зручності в представленні результатів розбиття та подальших обчислень, мабуть, було б бажано межі діапазону розбиття округлити до більшого цілого для додатних чисел та меншого цілого для від’ємних чисел (зробити межі діапазону цілими).
2) Розбити діапазон значень випадкової величини X на інтервали однакової довжини, при цьому по можливості задаючи межі кожного інтервалу цілими або напівцілими значеннями. Кількість інтервалів s0 на цьому етапі не дорівнює s, а більша (бо серед цих інтервалів є такі, що не задовольняють застосувати метод Пірсона для отримання „хороших” результатів).
Результати занести в таблицю.
Коректування розбиття буде проводитися в наступному пункті.
Обчислити частоти появи значень випадкової величини X в кожному з інтервалів розбиття - експериментальні частоти (вони будуть розглядатися як експериментальні, або практичні, імовірності появи значень цієї випадкової величини - оцінками імовірності).
![]() ,
,![]() ,
,
де ni - кількість експериментальних даних, що попали в і-й інтервал, N - загальна кількість експериментальних даних (у РГЗ N = 100).
Отримані результати занести в таблицю (див. далі Таблицю 3.1).
Розбиття на рівновіддалені дає наглядну картину розподілення значень випадкових величин. Але для застосування методу Пірсона таке розбиття не годиться, бо дасть не дуже „хороші" результати.
Тому необхідно провести корекцію розбиття:
Розширити інтервали, що не задовольняють критерію розбиття (кількість значень випадкової величини X, що попадають у кожний інтервал, повинна бути не менша 10). Розширення здійснюється укрупненням інтервалів шляхом складання частот появи значень випадкової величини X в інтервалі, що не задовольняє умовам розбиття, з частотами появи значень випадкової величини X в сусідніх інтервалах.
Оновлені дані занести в нову таблицю для застосування методу Пірсона (див. далі Таблицю 3.2).
Таким чином, застосування методу Пірсона повинне буде дати „хороші" результати.
Провести обчислення оцінок основних характеристик випадкової величини (бо, по-перше, виявивши деякий зв’язок між ними, можна буде зробити припущення про можливий закон розподілення, по-друге, вони використовуються при розрахункові теоретичних ймовірностей).
Розрахунок оцінки математичного чекання (знаходження вибіркової середньої) можна провести за наступною оціночною формулою:
![]() ,
,
де Xi - отримане в вибірці і-те значення випадкової величини (![]() ), N - загальна кількість експериментальних даних (у РГЗ N = 100).
), N - загальна кількість експериментальних даних (у РГЗ N = 100).
Розрахунок оцінки дисперсії (розрахунок вибіркової дисперсії) можна провести за наступною оціночною формулою:
![]() ,
,
де Xi - отримане в вибірці і-те значення випадкової величини (![]() ),
), ![]() - оцінка математичного очікування випадкової величини X, що розглядається.
- оцінка математичного очікування випадкової величини X, що розглядається.
Або ж застосувати загальний теоретичний зв‘язок між дисперсією та математичним чеканням (що буде дещо неправильним для знаходження вибіркової дисперсії):
![]() .
.
Середньоквадратичне відхилення також розраховується через загальний теоретичний зв‘язок між ним та дисперсією:
![]()
(вибіркове середньоквадратичне відхилення).
Побудувати гістограму або багатокутник розподілення - експериментальний (практичний) варіант графіка функції щільності імовірності.
Гістограма та багатокутник розподілення будуються за даними Таблиці 3.1
Гістограма матиме вигляд стовбчастої діаграми (основа кожного прямокутника - і-й інтервал розбиття, висота - частота появи значень випадкової величини X в і-му інтервалі). Багатокутник розподілення - незамкнута ламана (і-та вершина ламаної знаходяться над серединою і-го інтервалу розбиття на висоті, що відповідає частоті появи значень випадкової величини X в і-му інтервалі).
Проаналізувати обчислені оцінки математичного чекання та отриману гістограму. На основі цього зробити припущення про можливий закон розподілення випадкової величини - висунути гіпотезу H0. Далі відповідно до неї обчислити теоретичні значення ймовірностей попадання випадкової величини X в кожний з s інтервалів розбиття.
Якщо випадкова величина X приймає від’ємні значення, то вона не може бути розподіленою за біноміальним, пуасоновським, експоненціальним законами.
Якщо побудована гістограма починається з максимуму імовірності та далі спадає, також ![]() , то випадкова величина X може бути розподіленою за експоненціальним законом.
, то випадкова величина X може бути розподіленою за експоненціальним законом.
Якщо ![]() , то випадкова величина X може бути розподіленою за законом Пуассона.
, то випадкова величина X може бути розподіленою за законом Пуассона.
Якщо виконується зв’язок ![]() та
та ![]() , то випадкова величина X може бути розподіленою за біноміальним законом (Бернуллі).
, то випадкова величина X може бути розподіленою за біноміальним законом (Бернуллі).
Для законів розподілення Бернуллі та Пуассона (його окремий випадок) форма гістограми сильно залежить від основних параметрів випадкової величини (максимум імовірності може переміщатися від початку в деякому інтервалі), але максимум завжди вирізняється досить чітко.
Якщо максимум імовірності на побудованій гістограмі нечіткий та виконується „правило 3-х сігм” (більшість значень випадкової величини лежить у інтервалі
![]() ,
,
а імовірність появи значень, що лежать за межами цього інтервалу приблизно не перевищує 0.0027), то можна припустити, що випадкова величина X розподілена нормально (за Гауса законом розподілення). В цьому випадку відхилення практичної гістограми нормально розподіленої випадкової величини від теоретичної допоможе оцінити асиметрія та ексцес.
Таблиця 3.1
| І | 1 | 2 | 3 | 4 | ... | s0 |
| і-й рівновіддалений інтервал діапазону значень випадкової величини за даними вибірки, (Xi - 1; Xi) | (X0; X1) | (X1; X2) | (X2; X3) | (X3; X4) | … | (XS0 - 1; XS0) |
| Кількість значень випадкової величини X, що попадають в даний інтервал, ni | n1 | n2 | n3 | n4 | … | nS0 |
| Частоти появи значень випадкової величини X, що лежать в і-му рівновіддаленому інтервалі, |
|
|
|
| ... |
|
Таблиця 3.2
| І | 1 | 2 | 3 | 4 | ... | s |
| і-й інтервал діапазону значень випадкової величини за даними вибірки, (Xi - 1; Xi) | (X0; X1) | (X1; X2) | (X2; X3) | (X3; X4) | … | (XS - 1; XS) |
| Кількість значень випадкової величини X, що попадають в даний інтервал, ni | n1 | n2 | n3 | n4 | … | nS |
| Частоти появи значень випадкової величини X, що лежать в і-му інтервалі, |
|
|
|
| ... |
|
| Теоретичні імовірності знаходження значень випадкової величини X в і-му інтервалі, |
|
|
|
| ... |
|
| Теоретична кількість значень випадкової величини X, що попадають в даний інтервал, ni0 | n10 | n20 | n30 | n40 | ... | nS0 |
Обчислення теоретичних ймовірностей знаходження значень випадкової величини X в і-му інтервалі проводиться шляхом взяття визначеного інтеграла від функції щільності імовірності. Вигляд функцій щільності імовірності для основних законів розподілення випадкових величин відомий. Параметрами цих функцій при обчисленнях будуть попередньо підраховані оцінки основних параметрів випадкової величини - вибіркова середня, вибіркова дисперсія, вибіркове середньоквадратичне відхилення.
3.1 Обчислити значення критерію збіжності Пірсона
На основі отриманих результатів обробки даних вибірки потрібно підрахувати наступний статистичний критерій:
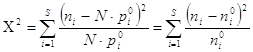 ,
,
де s - кількість інтервалів розбиття,
ni - кількість експериментальних даних, що попали в і-й інтервал, ni0 - теоретична кількість даних, що попали в і-й інтервал, pi0 - теоретична імовірність знаходження значень випадкової величини X в і-му інтервалі,
N - загальна кількість експериментальних даних (у РГЗ N = 100). Тут ![]() - велика літера
- велика літера ![]() (хі).
(хі).
Поведінку отриманої величини ![]() в залежності від правильності чи неправильності висунутої гіпотези H0 пояснює теорема Пірсона.
в залежності від правильності чи неправильності висунутої гіпотези H0 пояснює теорема Пірсона.
Скорочене формулювання теореми Пірсона:
Якщо гіпотеза H0 вірна, то при N→ ∞ закон розподілення величини ![]() наближується до закону розподілення хі-квадрат (
наближується до закону розподілення хі-квадрат (![]() ) з k = s - 1 ступенями свободи.
) з k = s - 1 ступенями свободи.
Тут k дорівнює s-1 (а не s, як видно з визначення поняття ступеня свободи), бо величини ni і відповідні їм величини ni0, по-перше, пов’язані, по-друге, пов’язані лінійними співвідношеннями (напр. ![]() ,
, ![]() ). Тому вираховується 1.
). Тому вираховується 1.
Практичне значення цієї теореми полягає в тому, що за правильності висунутої гіпотези H0 при великих об’ємах вибірки закон розподілення величини ![]() можна вважати законом розподіленням
можна вважати законом розподіленням ![]() з k = s - 1 ступенями свободи.
з k = s - 1 ступенями свободи.
Якщо ж висунута гіпотеза H0 не вірна, то при великих об’ємах вибірки величина ![]() необмежено зростає (тобто
необмежено зростає (тобто ![]() ).
).
Зосталося визначити, чому ж дорівнює число ступенів свободи k в нашому випадку. Значення k знаходиться з формули:
k = s - 1 - r,
де s - число інтервалів розбиття діапазону значень випадкової величини X, r - число параметрів розподілення, що були оцінені за даними вибірки (і використовувалися при підрахункові теоретичних імовірностей). Величини ni і відповідні їм величини ni0, по-перше, пов’язані, по-друге, пов’язані через r параметрів. Тому ще вираховується число параметрів розподілення r.
З таблиці розподілення ![]() з k = s - 1 - r ступенями свободи знаходимо найближче більше значення. З того міркування що, якщо нульова гіпотеза (H0) вірна, то повинна виконуватися нерівність
з k = s - 1 - r ступенями свободи знаходимо найближче більше значення. З того міркування що, якщо нульова гіпотеза (H0) вірна, то повинна виконуватися нерівність ![]() . Цьому найближчому більшому значенню відповідає певне значення рівня значимості α.
. Цьому найближчому більшому значенню відповідає певне значення рівня значимості α.
Рівень значимості α - імовірність помилково відкинути висунуту гіпотезу H0, коли вона вірна. Тоді імовірність того, що гіпотеза H0 правильно описує закон розподілення випадкової величини X, дорівнюватиме 1 - α.
Потрібно задатися рівнем значимості α0. На практиці α0 часто приймається рівним 0.05 (або 5%).
Таким чином, якщо отримане з таблиці значення рівня значимості α не перевищує заданого α0, то гіпотеза H0 приймається з імовірністю 1 - α. На основі цього робиться наступний висновок: практичні дані узгоджуються з гіпотезою H0, не має підстав її спростувати.
4. Приклад розв'язку типової задачі
Нехай випадкова величина X приймає наступний безперервний ряд значень:
0.3977801.6260473.712942-0.732191-1.070720
0.594877 - 0.0112791.716456-3.3376170.007172
0.663299-0.4412122.0750801.881620-2.088742
1.9913241.0363951.1338381.1655331.264862
2.3115392.8839420.232771-1.5445800.319252
2.9683571.775734-0.3564310.8063171.110993
0.0249601.838822-0.5991992.512275-3.040607
2.874235-1.6642481.0080920.7625010.107686
1.565826-0.4559481.887287-0.8452910.719599
2.3363190.9064131.733929-0.4664472.120893
0.3313110.8929770.988919-0.1805820.101599
2.1264641.0965252.121343-1.2558211.779378
4.356973-0.098316-1.3924411.6871980.374275
1.631167-1.9162120.4193822.026432-1.076515
1.467196-1.3863272.266472-1.1286360.291052
0.9213022.2678832.4135031.424872-1.084125-0.856300-0.055433-1.1430031.1496910.179690
1.7908670.3897065.6872311.014007-1.892447
1.0589170.564070-0.288985-0.0135031.470428
0.3068732.869473-0.8498070.6511941.461751
Виділили найбільше та найменше значення випадкової величини X у вибірці:
XMIN=-4.356973, XMAX=5.687231.
Проводимо розбиття діапазону значень випадкової величини X на рівновіддалені.
Маємо 11 одиничних інтервалів (в нашому випадку це зручно для побудови гістограми). Тобто s=11. Оцінивши число ступенів свободи k як k≈ s, робимо висновок, що знижувати кількість значень випадкової величини, які попадають в кожний інтервал розбиття не можна (враховуємо це при корекції розбиття в наступному пункті).
Результати заносимо в Таблицю 4.1 (друга строчка).
Обчислюємо частоти появи значень випадкової величини X в кожному з інтервалів розбиття - експериментальні частоти. Результати заносимо в Таблицю 4.1 (третя строчка).
Проводимо корекцію розбиття для застосування методу Пірсона (проводимо укрупнення крайніх інтервалів шляхом їхнього об’єднання, доки не отримаємо мінімальну допустиму в методі Пірсона кількість значень випадкової величини, що попадають у формуємий інтервал; в нашому випадку ця кількість повинна бути не менша 10).
Результати заносимо в Таблицю 4.2 (друга строчка).
Проводимо обчислення оцінок основних характеристик випадкової величини: математичного чекання, дисперсії та середньоквадратичного відхилення.
![]()
![]()
![]()
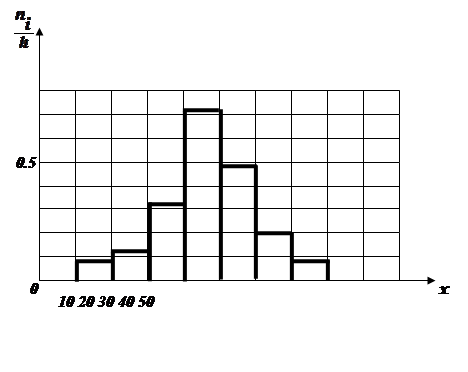
Будуємо за даними Таблиці 4.1 гістограму (рис.4.1) - експериментальний варіант графіка функції щільності імовірності. Будуємо гістограму, бо маємо справу з попаданням безперервної випадкової величини X в один з інтервалів розбиття на рівновіддалені.
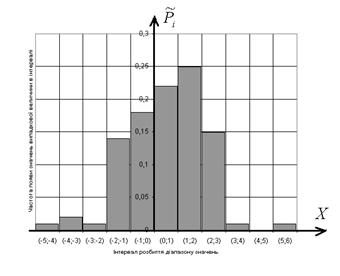
Рис.4.1 Гістограма експериментального графіку функції щільності імовірності.
Аналізуємо обчислені оцінки математичного чекання та отриману гістограму.
Безперервна випадкова величина X приймає від’ємні значення. Отже, їй залишається бути розподіленою за нормальним (гаусовським) законом розподілення.
„Правило 3-х сігм” приблизно виконується (більшість значень дійсно лежить в інтервалі (-4.165276; 5.252514)). Відхилення практичної гістограми від теоретичної допоможе оцінити характеристика асиметрії та ексцес.
Таким чином, висуваємо гіпотезу H0 - випадкова величина X розподілена за нормальним законом розподілення.
Для обчислення теоретичних частот попадання випадкової величини X в коректований інтервал (з Таблиці 4.2) можна використовувати дві методики. Ми будемо застосовувати другу як більш теоретично обґрунтовану та правильнішу, а також точнішу.
Перша методика проста, але обчислення на її основі носять приблизний, оціночний характер. Перейдемо в обчисленнях від загальної до центрованої нормальної величини. Теоретично наша випадкова величина вважається розподіленою за загальним нормальним законом. Його функція щільності імовірності має в нашому випадку вигляд:
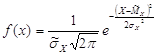 .
.
Перехід до центрованої нормальної величини:
![]() .
.
Функція щільності імовірності для неї:
![]() .
.
Таким чином
![]() .
.
Імовірність попадання випадкової величини X в інтервал (Xi; Xi+1) дорівнює
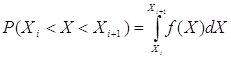 .
.
Дорівнює площі фігури, обмеженої графіком щільності імовірності, віссю 0X та прямими X=Xi, X=Xi+1.
Тобто можна приблизно вважати ії рівною добутку довжини інтервалу h на значення функції щільності імовірності в середині інтервалу (вищесказане є фактично двосторонньою оцінкою визначеного інтегралу):
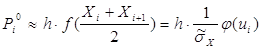 ,
,
де значення ![]() відповідає середині інтервалу
відповідає середині інтервалу
![]() .
.
Знаючи теоретичну імовірність Pi, можна буде обчислити теоретичну кількість ni попадань випадкової величини X в і-й інтервал (Xi; Xi+1).
Але це буде дуже приблизна оцінка, бо коректування інтервалів розширило межі інтервалів та збільшило різницю між значеннями функції щільності імовірності в них. Точність цього методу обчислення теоретичних частот буде зростати при зменшенні інтервалу розбиття. Проте, це не можливо без порушення правила розбиття діапазону зміни значень випадкової величини в методі Пірсона. З загальних теоретичних відомостей імовірність попадання випадкової величини X в інтервал (Xi; Xi+1) можна виразити через функцію щільності імовірності
![]() ,
,
або через функцію розподілення імовірності
![]()
![]() .
.
Для нормованого нормального розподілення функція розподілення імовірності обчислюється через функцію Лапласа (сама функція Лапласа не є функцією розподілення імовірності):
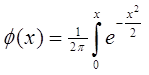 .
.
Значення функції Лапласа затабульовані, або ж їх можна підрахувати за допомогою математичних пакетів прикладних програм. Хоча з досить високою точністю можна й самому підрахувати значення функції Лапласа, використавши наступну наближену формулу (підінтегральну функцію було розкладено в ряд та взято інтеграл):
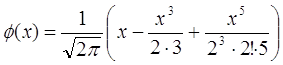 .
.
Функція розподілення імовірності нормального розподілення пов’язана з функцією Лапласа наступним співвідношенням:
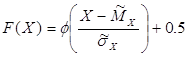 , якщо X>0,
, якщо X>0,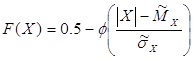 , якщо X<0.
, якщо X<0.
Знову перейдемо в обчисленнях від загальної до центрованої нормальної величини:
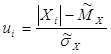 .
.
Це зафіксовано у п’ятій строчці Таблиці 4.2. Тоді імовірність попадання випадкової величини X в інтервал (Xi; Xi+1) можна виразити через функцію Лапласа так:
![]() ,
,
де значення ![]() - нормована нормальна випадкова величина, що відповідає Xi (результат занесено в шосту строчку Таблиці 4.2). Знаючи теоретичну імовірність Pi0, можна буде обчислити теоретичну кількість ni0 попадань випадкової величини X в і-й інтервал (Xi; Xi+1) з Таблиці 4.2 (і результат занесено у відповідну сьому строчку Таблиці 4.2).
- нормована нормальна випадкова величина, що відповідає Xi (результат занесено в шосту строчку Таблиці 4.2). Знаючи теоретичну імовірність Pi0, можна буде обчислити теоретичну кількість ni0 попадань випадкової величини X в і-й інтервал (Xi; Xi+1) з Таблиці 4.2 (і результат занесено у відповідну сьому строчку Таблиці 4.2).
Таблиця 4.1 Інтервали розбиття
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| (-5; - 4) | (-4; - 3) | (-3; - 2) | (-2; - 1) | (-1; 0) | (0; 1) | (1; 2) | (2; 3) | (3; 4) | (4; 5) | (5; 6) |
| 1 | 2 | 1 | 14 | 18 | 22 | 25 | 15 | 1 | 0 | 1 |
| 0.01 | 0.02 | 0.01 | 0.14 | 0.18 | 0.22 | 0.25 | 0.15 | 0.01 | 0 | 0.01 |
Таблиця 4.2 Розраховані імовірності
| I | 1 | 2 | 3 | 4 | 5 |
| (Xi; Xi+1) | (-5; - 1) | (-1; 0) | (0; 1) | (1; 2) | (2; 6) |
| ni | 18 | 18 | 22 | 25 | 17 |
|
| 0.18 | 0.18 | 0.22 | 0.25 | 0.17 |
| (ui; ui+1) | (2.8395; 0.2969) | (0.2969; 0) | (0; 0.2969) | (0.2969; 0.9322) | (0.9322; 3.4752) |
| Pi0 | 0.3798 | 0.1179 | 0.1179 | 0.2059 | 0.1760 |
| ni0 | 38 | 12 | 12 | 21 | 18 |
Обчислили значення критерію збіжності Пірсона. В нашому випадку він дорівнюватиме:
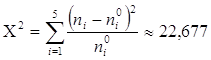 .
.
Робимо висновок про збіжність закону розподілення практичних даних та закону розподілення, що відповідає висунутій гіпотезі H0.
Кількість ступенів свободи k = s - 1 - r, де s=5 - число інтервалів розбиття діапазону значень випадкової величини X, r=2 - число параметрів розподілення, що були оцінені за даними вибірки і використовувалися при підрахункові теоретичних ймовірностей (для нормального розподілення це математичне чекання та середньоквадратичне відхилення), дорівнює k = 5 - 3 =2.
За таблицею розподілення ![]() з k ступенями свободи знаходимо
з k ступенями свободи знаходимо ![]() при α=0.001 (більш точні дані відсутні). Тобто практичні дані узгоджуються з гіпотезою H0 з імовірністю більш ніж 0.999.
при α=0.001 (більш точні дані відсутні). Тобто практичні дані узгоджуються з гіпотезою H0 з імовірністю більш ніж 0.999.
Висока імовірність узгодженості практичних даних з теоретичними дає підставу перевірити та оцінити потужність критерію (імовірність прийняття альтернативних гіпотез).
Висновки
У виконаній курсовій роботі наведено огляд теоретичних відомостей з курсу Теорії ймовірностей та математичної статистики, визначено алгоритм виконання типових завдань з Теорії ймовірностей. І також виконано розрахунок типової задачі з визначення законів розподілення випадкових величин.
Список літератури
1. В.В. Гнеденко. Курс теории вероятностей. М. - Наука, 1988.
2. В.П. Чистяков. Курс теории вероятностей. М. - Наука, 1982.
3. А.А. Боровков. Теория вероятностей.М. - Наука, 1988.
4. Б.А. Севастьянов. Курс теории вероятностей и математической статистики.М. - Наука, 1982.
5. Сборник задач по теории вероятностей, математической статистике и теории случайных функций (под редакцией А.А. Свешникова).
6. И.Н. Коваленко, А.А. Филлипов. Теория вероятностей и математическая статистика. М. - Высшая школа, 1988.
7. Е.С. Вентцель. Теория вероятностей. М. - Наука, 1969.
8. И.И. Гихман, А.В. Скороход, М.И. Ядренко. Теория вероятностей и математическая статистика. Киев - Высшая школа, 1979.
9. И.И. Гихман, А.В. Скороход. Введение в теорию случайных процессов.М. - Наука, 1969.
10. А.Т. Гаврилин, О.Н. Репин, И.П. Смирнов. Задачи по теории вероятностей, математической статистике и теории случайных процессов. Методическая разработка для студентов дневного отделения радиофизического факультета. Горький, ГГУ, 1983.
11. Г.И. Агапов. Задачник по теории вероятностей. М. - Высшая школа, 1994.
12. Большев Л.Н., Смирнов Н.В. Таблицы математической статистики. М.: Наука, 1965.
13. Боровков А.А. Математическая статистика. М.: Наука, 1984.
14. Коршунов Д.А., Чернова Н.И. Сборник задач и упражнений по математической статистике. Новосибирск: Изд-во Института математики им. С.Л. Соболева СО РАН, 2001.
15. Феллер В. Введение в теорию вероятностей и ее приложения. М.: Мир, Т.2, 1984.
Похожие работы
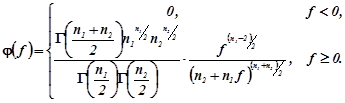
... такому випадку розподіл умовних варіант (3.5) такий: . , , , , . Умовні початкові моменти обчислюються за формулами (3.6): ; ;;; На підставі формул (3.7 – 3.10) при : ; ; ; . 4. Стандартні розподіли математичної статистики 4.1 Розподіл (хі-квадрат) Нехай - система нормальних випадкових величин з одинаковими математичними сподіваннями та середньоквадратичними ...

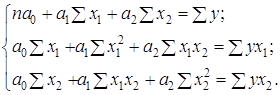
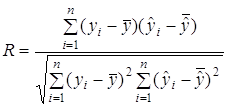
... і над плановим. Відомо, що собівартість є одним з головних джерел резервів підвищення ефективності роботи підприємства. Звідси сформуємо мету і задачі даної роботи. Метою даної роботи є підвищення ефективності роботи підприємства ВАТ «Дніпрополімермаш» шляхом управління собівартістю продукції. Відповідно, для досягнення поставленої мети необхідно вирішити наступні задачі: 1. Проаналізувати ...

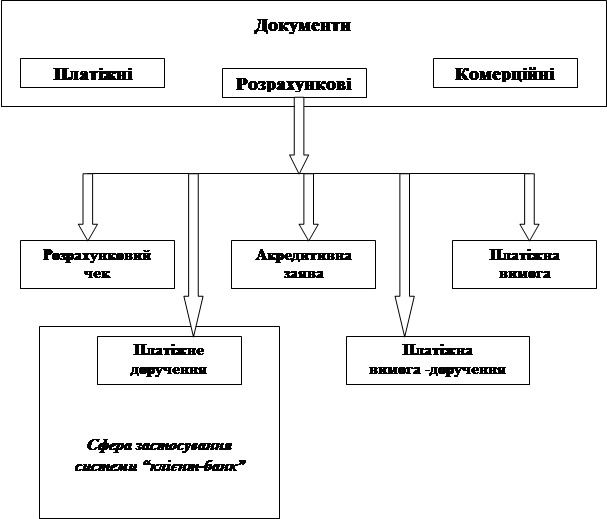



... ін платіжними документами з програмним комплексом ОДБ (зокрема, банківська частина системи «клієнт - банк» може бути одним з компонентів ОДБ), який власне і виконує розрахунки клієнта за документами, що отримані через систему «клієнт - банк», а також ведення рахунків клієнтів з відображенням фактично виконаних трансакцій; • обмін із клієнтською частиною допоміжною технологічною інформацією та ...
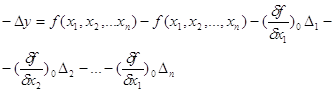
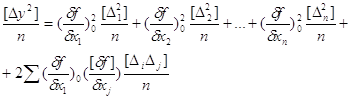
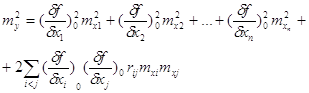
... ТЕОРІЇ ЙМОВІРНОСТЕЙ 1. Поняття та закон розподілу системи випадкових величин До цього часу ми розглядали одномірну випадкову величину X. Однак в сучасній теорії математичної обробки результатів багаторазових повторних геодезичних вимірювань використовують багатомірні випадкові величини. Багатомірна випадкова величина може складатися із декількох компонентів і бути двомірною, тримірною і так ...
0 комментариев