Навигация
1.4 Классификация Шора
Классификация Дж.Шора, появившаяся в начале 70-х годов, интересна тем, что представляет собой попытку выделения типичных способов компоновки вычислительных систем на основе фиксированного числа базисных блоков: устройства управления, арифметико-логического устройства, памяти команд и памяти данных. Дополнительно предполагается, что выборка из памяти данных может осуществляться словами, то есть выбираются все разряды одного слова, и/или битовым слоем - по одному разряду из одной и той же позиции каждого слова (иногда эти два способа называют горизонтальной и вертикальной выборками соответственно). Конечно же, при анализе данной классификации надо делать скидку на время ее появления, так как предусмотреть невероятное разнообразие параллельных систем настоящего времени было в принципе невозможно. Итак, согласно классификации Шора все компьютеры разбиваются на шесть классов, которые он так и называет: машина типа I, II и т.д.
Машина I (рис. 1.5) - это вычислительная система, которая содержит устройство управления, арифметико-логическое устройство, память команд и память данных с пословной выборкой. Считывание данных осуществляется выборкой всех разрядов некоторого слова для их параллельной обработки в арифметико-логическом устройстве. Состав АЛУ специально не оговаривается, что допускает наличие нескольких функциональных устройств, быть может конвейерного типа. По этим соображениям в данный класс попадают как классические последовательные машины (IBM 701, PDP-11, VAX 11/780), так и конвейерные скалярные (CDC 7600) и векторно-конвейерные (CRAY-1).
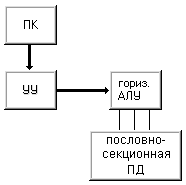
Рисунок 1.5 – Машина I
Если в машине I осуществлять выборку не по словам, а выборкой содержимого одного разряда из всех слов, то получим машину II (рис. 1.6) . Слова в памяти данных по прежнему располагаются горизонтально, но доступ к ним осуществляется иначе. Если в машине I происходит последовательная обработка слов при параллельной обработке разрядов, то в машине II - последовательная обработка битовых слоев при параллельной обработке множества слов.
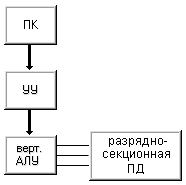
Рисунок 1.6 – Машина II
Структура машины II лежит в основе ассоциативных компьютеров (например, центральный процессор машины STARAN), причем фактически такие компьютеры имеют не одно арифметико-логическое устройство, а множество сравнительно простых устройств поразрядной обработки. Другим примером служит матричная система ICL DAP, которая может одновременно обрабатывать по одному разряду из 4096 слов.
Если объединить принципы построения машин I и II, то получим машину III (рис. 1.7). Эта машина имеет два арифметико-логических устройства - горизонтальное и вертикальное, и модифицированную память данных, которая обеспечивает доступ как к словам, так и к битовым слоям. Впервые идею построения таких систем в 1960 году выдвинул У.Шуман , называвший их ортогональными (если память представлять как матрицу слов, то доступ к данным осуществляется в направлении, "ортогональном" традиционному - не по словам (строкам), а по битовым слоям (столбцам)). В принципе, как машину STARAN, так и ICL DAP можно запрограммировать на выполнение функций машины III, но поскольку они не имеют отдельных АЛУ для обработки слов и битовых слоев, отнести их к данному классу нельзя. Полноправными представителями машин класса III являются вычислительные системы семейства OMEN-60 фирмы Sanders Associates, построенные в прямом соответствии с концепцией ортогональной машины.
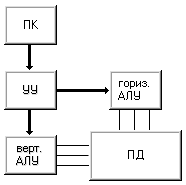
Рисунок 1.7 – Машина III
Если в машине I увеличить число пар арифметико-логическое устройство <=> память данных (иногда эту пару называют процессорным элементом) то получим машину IV (рис. 1.8). Единственное устройство управления выдает команду за командой сразу всем процессорным элементам. С одной стороны, отсутствие соединений между процессорными элементами делает дальнейшее наращивание их числа относительно простым, но с другой, сильно ограничивает применимость машин этого класса. Такую структуру имеет вычислительная система PEPE, объединяющая 288 процессорных элементов.
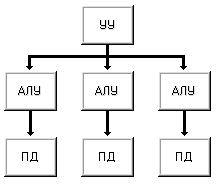
Рисунок 1.8 – Машина IV
Если ввести непосредственные линейные связи между соседними процессорными элементами машины IV, например в виде матричной конфигурации, то получим схему машины V (рис. 1.9). Любой процессорный элемент теперь может обращаться к данным как в своей памяти, так и в памяти непосредственных соседей. Подобная структура характерна, например, для классического матричного компьютера ILLIAC IV.
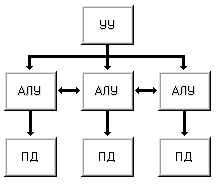
Рисунок 1.9 – Машина V
Заметим, что все машины с I-ой по V-ю придерживаются концепции разделения памяти данных и арифметико-логических устройств, предполагая наличие шины данных или какого-либо коммутирующего элемента между ними. Машина VI (рис. 1.10), названная матрицей с функциональной памятью (или памятью с встроенной логикой), представляет собой другой подход, предусматривающий распределение логики процессора по всему запоминающему устройству. Примерами могут служить как простые ассоциативные запоминающие устройства, так и сложные ассоциативные процессоры.
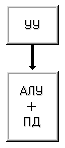
Рисунок 1.10 – Машина VI
1.5 Классификация ХендлераВ основу классификации В.Хендлер закладывает явное описание возможностей параллельной и конвейерной обработки информации вычислительной системой. При этом он намеренно не рассматривает различные способы связи между процессорами и блоками памяти и считает, что коммуникационная сеть может быть нужным образом сконфигурирована и будет способна выдержать предполагаемую нагрузку.
Предложенная классификация базируется на различии между тремя уровнями обработки данных в процессе выполнения программ:
- уровень выполнения программы - опираясь на счетчик команд и некоторые другие регистры, устройство управления (УУ) производит выборку и дешифрацию команд программы;
- уровень выполнения команд - арифметико-логическое устройство компьютера (АЛУ) исполняет команду, выданную ему устройством управления;
- уровень битовой обработки - все элементарные логические схемы процессора (ЭЛС) разбиваются на группы, необходимые для выполнения операций над одним двоичным разрядом.
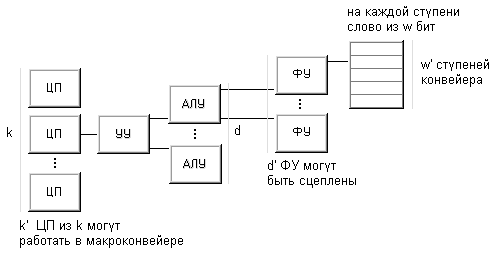
Рисунок 1.11 – Принцип классификации Хендлера
Таким образом, подобная схема выделения уровней предполагает, что вычислительная система включает какое-то число процессоров каждый со своим устройством управления. Каждое устройство управления связано с несколькими арифметико-логическими устройствами, исполняющими одну и ту же операцию в каждый конкретный момент времени. Наконец, каждое АЛУ объединяет несколько элементарных логических схем, ассоциированных с обработкой одного двоичного разряда (число ЭЛС есть ничто иное, как длина машинного слова). Если на какое-то время не рассматривать возможность конвейеризации, то число устройств управления k , число арифметико-логических устройств d в каждом устройстве управления и число элементарных логических схем w в каждом АЛУ составят тройку для описания данной вычислительной системы C:
t(C) = (k, d, w)
Теперь можно расширить возможности описания, допустив возможность конвейерной обработки на каждом из уровней. В самом деле, конвейерность на самом нижнем уровне (т.е. на уровне ЭЛС) это конвейерность функциональных устройств. Если функциональное устройство обрабатывает w-разрядные слова на каждой из w' ступеней конвейера, то для характеристики параллелизма данного уровня естественно рассмотреть произведение w×w'. Знак умножения × будем использовать на каждом уровне чтобы отделить число, представляющее степень параллелизма, от числа ступеней в конвейере. Компьютер TI ASC имеет четыре конвейерных устройства по восемь ступеней в каждом для обработки 64-х разрядных слов, следовательно, он может быть описан так:
t( TI ASC ) = (1,4,64×8)
Следующий уровень конвейерной обработки - это конвейеризация на уровне команд. Предполагается, что в вычислительной системе есть несколько функциональных устройств, которые могут работать одновременно в рамках одного потока команд (в настоящее время используется специальный термин для обозначения данной возможности - сцепление функциональных устройств). Классическим примером этому могут служить компьютеры фирмы Cray Research. А исторически первой, по всей вероятности, является машина CDC 6600, содержащая десять независимых последовательных функциональных устройств, способных подавать результат своей работы на вход другим функциональным устройствам, образуя единый поток команд:
t(CDC 6600) = (1,1×10,~64)
Наконец, осталось рассмотреть конвейеризацию на самом верхнем уровне, известную как макро-конвейер. Поток данных, проходя через один процессор, поступает на вход другому, возможно через некоторую буферную память. Если независимо работают n процессоров, то в идеальной ситуации при отсутствии конфликтов и полной сбалансированности получаем ускорение в n раз по сравнению с использованием только одного процессора. Так компьютер PEPE, имея фактически три независимых системы из 288-ми устройств, описывается следующим образом:
t( PEPE ) = (1×3,288,32)
После расширения трехуровневой модели параллелизма средствами описания потенциальных возможностей конвейеризации каждая тройка t( PEPE ) = (k×k',d×d',w×w') интерпретируется так:
- k - число процессоров (каждый со своим УУ), работающих параллельно
- k' - глубина макроконвейера из отдельных процессоров
- d - число АЛУ в каждом процессоре, работающих параллельно
- d' - число функциональных устройств АЛУ в цепочке
- w - число разрядов в слове, обрабатываемых в АЛУ параллельно
- w' - число ступеней в конвейере функциональных устройств АЛУ
1.6 Классификация ХокниР. Хокни - известный английский специалист в области параллельных вычислительных систем, разработал свой подход к классификации, введенной им для систематизации компьютеров, попадающих в класс MIMD по систематике Флинна.
Как отмечалось выше (см. классификацию Флинна), класс MIMD чрезвычайно широк, причем наряду с большим числом компьютеров он объединяет и целое множество различных типов архитектур. Хокни, пытаясь систематизировать архитектуры внутри этого класса, получил иерархическую структуру, представленную на рис. 1.12:
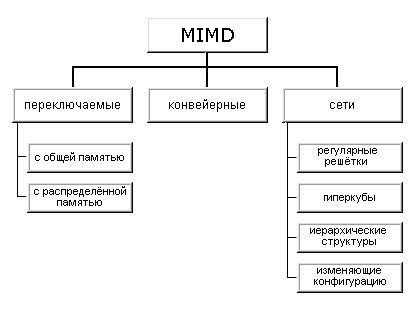
Рисунок 1. 12 – Иерархическая структура класса MIMD
Основная идея классификации состоит в следующем. Множественный поток команд может быть обработан двумя способами: либо одним конвейерным устройством обработки, работающем в режиме разделения времени для отдельных потоков, либо каждый поток обрабатывается своим собственным устройством. Первая возможность используется в MIMD компьютерах, которые автор называет конвейерными (например, процессорные модули в Denelcor HEP). Архитектуры, использующие вторую возможность, в свою очередь опять делятся на два класса:
- MIMD компьютеры, в которых возможна прямая связь каждого процессора с каждым, реализуемая с помощью переключателя;
- MIMD компьютеры, в которых прямая связь каждого процессора возможна только с ближайшими соседями по сети, а взаимодействие удаленных процессоров поддерживается специальной системой маршрутизации через процессоры-посредники.
Далее, среди MIMD машин с переключателем Хокни выделяет те, в которых вся память распределена среди процессоров как их локальная память (например, PASM, PRINGLE). В этом случае общение самих процессоров реализуется с помощью очень сложного переключателя, составляющего значительную часть компьютера. Такие машины носят название MIMD машин с распределенной памятью. Если память это разделяемый ресурс, доступный всем процессорам через переключатель, то такие MIMD являются системами с общей памятью (CRAY X-MP, BBN Butterfly). В соответствии с типом переключателей можно проводить классификацию и далее: простой переключатель, многокаскадный переключатель, общая шина.
Многие современные вычислительные системы имеют как общую разделяемую память, так и распределенную локальную. Такие системы автор рассматривает как гибридные MIMD c переключателем.
При рассмотрении MIMD машин с сетевой структурой считается, что все они имеют распределенную память, а дальнейшая классификация проводится в соответствии с топологией сети: звездообразная сеть (lCAP), регулярные решетки разной размерности (Intel Paragon, CRAY T3D), гиперкубы (NCube, Intel iPCS), сети с иерархической структурой, такой, как деревья, пирамиды, кластеры (Cm* , CEDAR) и, наконец, сети, изменяющие свою конфигурацию.
Заметим, что если архитектура компьютера спроектирована с использованием нескольких сетей с различной топологией, то, по всей видимости, по аналогии с гибридными MIMD с переключателями, их стоит назвать гибридными сетевыми MIMD, а использующие идеи разных классов - просто гибридными MIMD. Типичным представителем последней группы, в частности, является компьютер Connection Machine 2, имеющим на внешнем уровне топологию гиперкуба, каждый узел которого является кластером процессоров с полной связью.
1.7 Классификация ШнайдераВ 1988 году Л. Шнайдер предложил новый подход к описанию архитектур параллельных вычислительных систем, попадающих в класс SIMD систематики Флинна. Основная идея заключается в выделении этапов выборки и непосредственно исполнения в потоках команд и данных. Именно разделение потоков на адреса и их содержимое позволяет описать такие ранее "неудобные" для классификации архитектуры, как компьютеры с длинным командным словом, систолические массивы и целый ряд других.
Введем необходимые для дальнейшего изложения понятия и обозначения. Назовем потоком ссылок ( reference stream ) S некоторой вычислительной системы конечное множество бесконечных последовательностей пар:
S = { (a1t1) (a2t2)..., (b1u1) (b2u2)..., (c1v1)(c2v2)...},
где первый компонент каждой пары - это неотрицательное целое число, называемое адресом, второй компонент - это набор из n неотрицательных целых чисел, называемых значениями, причем n одинаково для всех наборов всех последовательностей. Например, пара (b2u2) определяет адрес b2 и значение u2. Если значения рассматривать как команды, то из потока ссылок получим поток команд I; если же значения интерпретировать как данные, то соответствующий поток - это поток данных D.
Интерпретация введенных понятий очень проста. Элементы каждой последовательности это адрес и его содержимое, выбираемое из (или записываемое в) память. Последовательность пар адрес-значение можно рассматривать как историю выполнения команд либо перемещения данных между процессором и памятью компьютера во время выполнения программы. Число инструкций, которое данный компьютер может выполнять одновременно, определяет число последовательностей в потоке команд. Аналогично, число различных данных, которое компьютер может обработать одновременно, определяет число последовательностей в потоке данных.
Пусть S произвольный поток ссылок. Последовательность адресов потока S, обозначаемая Sa, - это последовательность, чей i-й элемент - набор, сформированный из адресов i-х элементов каждой последовательности из S:
Sa = a1 b1 ...c1 ,a2 b2 ...c2 ,...
потока S, обозначаемая Sv, - это последовательность, чей i-й элемент - набор, образованный слиянием наборов значений i-х элементов каждой последовательности из S:
Sv = t1 u1 ...v1,t2 u2 ...v2 ,...
Если Sx - последовательность элементов, где каждый элемент - набор из n чисел, то для обозначения "ширины" последовательности будем пользоваться обозначением: w(Sx) = n.
Из определений Sa, Sv и w сразу следует утверждение: если S - это поток ссылок со значениями из n чисел, то
w(Sa) = S и w(Sv) = nS,
где S обозначает мощность множества S.
Каждую пару (I, D) с потоком команд I и потоком данных D будем называть вычислительным шаблоном, а все компьютеры будем разбивать на классы в зависимости от того, какой шаблон они могут исполнить. В самом деле, компьютер может исполнить шаблон (I, D), если он в состоянии:
- выдать w(Ia) адресов команд для одновременной выборки из памяти;
- декодировать и проинтерпретировать одновременно w(Iv) команд;
- выдать одновременно w(Da) адресов операндов и
- выполнить одновременно w(Dv) операций над различными данными.
Если все эти условия выполнены, то компьютер может быть описан следующим образом:
Iw(Ia)w(Iv)Dw(Da)w(Dv)
На основе указанных предикатов можно выделить следующие классы компьютеров:
- IssDss - фон-неймановские машины;
- IssDsc - фон-неймановские машины, в которых заложена возможность выбирать данные, расположенные с разным смещением относительно одного и того же адреса, над которыми будет выполнена одна и та же операция. Примером могут служить компьютеры, имеющие команды, типа одновременного выполнения двух операций сложения над данными в формате полуслова, расположенными по указанному адресу.
- IssDsm - SIMD компьютеры без возможности получения уникального адреса для данных в каждом процессорном элементе, включающие MPP, Connection Machine 1 так же, как и систолические массивы.
- IssDcc - многомерные SIMD машины - фон-неймановские машины, способные расщеплять поток данных на независимые потоки операндов;
- IssDmm - это SIMD компьютеры, имеющие возможность независимой модификации адресов операндов в каждом процессорном элементе, например, ILLIAC IV и Connection Machine 2.
- IscDcc - вычислительные системы, выбирающие и исполняющие одновременно несколько команд, для доступа к которым используется один адрес. Типичным примером являются компьютеры с длинным командным словом (VLIW).
- IccDcc - многомерные MIMD машины. Фон-неймановские машины, которые могут расщеплять свой цикл выборки/выполнения с целью обработки параллельно нескольких независимых команд.
- ImmDmm - к этому классу относятся все компьютеры типа MIMD.
Достаточно ясно, что не нужно рассматривать все возможные комбинации описателей 's', 'c' и 'm', так как архитектура реальных компьютеров накладывает ряд вполне разумных ограничений. Очевидно, что число адресов w(Sa) не должно превышать числа возвращенных значений w(Sv), которое компьютер может обработать. Отсюда следуют неравенства: w(Ia)<=w(Iv) и w(Da)<=w(Dv). Другим естественным предположением является тот факт, что число выполняемых команд не должно превышать числа обрабатываемых данных: w(Iv) <= w(Dv).
Подводя итог, можно отметить два положительных момента в классификации Шнайдера: более избирательная систематизация SIMD компьютеров и возможность описания нетрадиционных архитектур типа систолических массивов или компьютеров с длинным командным словом. Однако почти все вычислительные системы типа MIMD опять попали в один и тот же класс ImmDmm. Это и не удивительно, так как критерий классификации, основанный лишь на потоках команд и данных без учета распределенности памяти и топологии межпроцессорной связи, слишком слаб для подобных систем.
1.8 Классификация ДжонсонаЕ.Джонсон предложил проводить классификацию MIMD архитектур на основе структуры памяти и реализации механизма взаимодействия и синхронизации между процессорами.
По структуре оперативной памяти существующие вычислительные системы делятся на две большие группы: либо это системы с общей памятью, прямо адресуемой всеми процессорами, либо это системы с распределенной памятью, каждая часть которой доступна только одному процессору. Одновременно с этим, и для межпроцессорного взаимодействия существуют две альтернативы: через разделяемые переменные или с помощью механизма передачи сообщений. Исходя из таких предположений, можно получить четыре класса MIMD архитектур, уточняющих систематику Флинна:
- общая память - разделяемые переменные (GMSV);
- распределенная память - разделяемые переменные (DMSV);
- распределенная память - передача сообщений (DMMP);
- общая память - передача сообщений (GMMP).
Опираясь на такое деление, Джонсон вводит названия для некоторых классов. Так вычислительные системы, использующие общую разделяемую память для межпроцессорного взаимодействия и синхронизации, он называет системами с разделяемой памятью, например, CRAY Y-MP (по его классификации это класс 1). Системы, в которых память распределена по процессорам, а для взаимодействия и синхронизации используется механизм передачи сообщений он называет архитектурами с передачей сообщений, например NCube, (класс 3). Системы с распределенной памятью и синхронизацией через разделяемые переменные, как в BBN Butterfly, называются гибридными архитектурами (класс 2).
В качестве уточнения классификации автор отмечает возможность учитывать вид связи между процессорами: общая шина, переключатели, разнообразные сети и т.п.
1.9 Классификация БазуПо мнению А.Базу, любую параллельную вычислительную систему можно однозначно описать последовательностью решений, принятых на этапе ее проектирования, а сам процесс проектирования представить в виде дерева. В самом деле, корень дерева - это вычислительная система (рис. 1.13), а последующие ярусы дерева, фиксируя уровень параллелизма, метод реализации алгоритма, параллелизм инструкций и способ управления, последовательно дополняют друг друга, формируя описание системы.
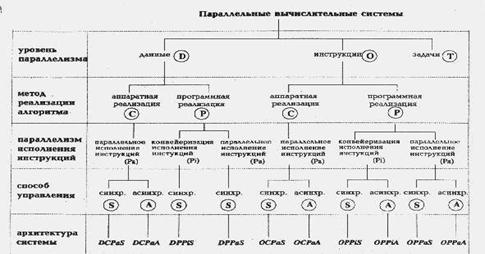
Рисунок 1.13 – Классификация Базу
На первом этапе мы определяем, какой уровень параллелизма используется в вычислительной системе. Одна и та же операция может одновременно выполняться над целым набором данных, определяя параллелизм на уровне данных (обозначается буквой D на рисунке). Способность выполнять более одной операции одновременно говорит о параллелизме на уровне команд (буква O на рисунке). Если же компьютер спроектирован так, что целые последовательности команд могут быть выполнены одновременно, то будем говорить о параллелизме на уровне задач (буква T).
Второй уровень в классификационном дереве фиксирует метод реализации алгоритма. С появлением сверхбольших интегральных схем (СБИС) стало возможным реализовывать аппаратно не только простые арифметические операции, но и алгоритмы целиком. Например, быстрое преобразование Фурье, произведение матриц и LU-разложение относятся к классу тех алгоритмов, которые могут быть эффективно реализованы в СБИС'ах. Данный уровень классификации разделяет системы с аппаратной реализацией алгоритмов (буква C на схеме) и системы, использующие традиционный способ программной реализации (буква P).
Третий уровень конкретизирует тип параллелизма, используемого для обработки инструкций машины: конвейеризация инструкций (Pi) или их независимое (параллельное) выполнение (Pa). В большей степени этот выбор относится к компьютерам с программной реализацией алгоритмов, так как аппаратная реализация всегда предполагает параллельное исполнение команд. Отметим, что в случае конвейерного исполнения имеется в виду лишь конвейеризация самих команд, разбивающая весь цикл обработки на выборку команды, дешифрацию, вычисление адресов и т.д., - возможная конвейеризация вычислений на данном уровне не принимается во внимание.
Последний уровень данной классификации определяет способ управления, принятый в вычислительной системе: синхронный (S) или асинхронный (A). Если выполнение команд происходит в строгом порядке, определяемом только сигналами таймера и счетчиком команд, то будем говорить о синхронном способе управления. Если же для инициации команды определяющими являются такие факторы, как, например, готовность данных, то попадаем в класс машин с асинхронным управлением. Наиболее характерными представителями систем с асинхронным управлением являются data-driven и demand-driven компьютеры
Описав основные принципы классификации, посмотрим, куда попадают различные типы параллельных вычислительных систем.
Изучение систолических массивов, имеющих, как правило, одномерную или двумерную структуру, показывает, что обозначения DCPaS и DCPaA могут быть использованы для их описания в зависимости от того, как происходит обмен данными: синхронно или асинхронно. Систолические деревья, введенные Кунгом для вычисления арифметических выражений могут быть описаны как OCPaS либо OCPaA по аналогичным соображениям. Конвейерные компьютеры, такие, как IBM 360/91, Amdahl 470/6 и многие современные RISC процессоры, разбивающие исполнение всех инструкций на несколько этапов, в данной классификации имеют обозначение OPPiS. Более естественное применение конвейеризации происходит в векторных машинах, в которых одна команда применяется к вектору независимых данных, и за счет непрерывного использования арифметического конвейера достигается значительное ускорение. К таким компьютерам подходит обозначение DPPiS. Матричные процессоры, в которых целое множество арифметических устройств работает одновременно в строго синхронном режиме, принадлежат к группе DPPaS. Если вычислительная система подобно CDC 6600 имеет процессор с отдельными функциональными устройствами, управляемыми централизованно, то ее описание выглядит так: OPPaS. Data-flow компьютеры, в зависимости от особенностей реализации, могут быть описаны либо как OPPiA, либо OPPaA.
Системы с несколькими процессорами, использующими параллелизм на уровне задач, не всегда можно корректно описать в рамках предложенного формализма. Если процессоры дополнительно не используют параллелизм на уровне операций или данных, то для описания можно использовать лишь букву T. В противном случае, Базу предлагает использовать знак '*' между символами, обозначающими уровни параллелизма, одновременно присутствующие в системе. Например, комбинация T*D означает, что некоторая система может одновременно исполнять несколько задач, причем каждая из них может использовать векторные команды.
Очень часто в реальных системах присутствуют особенности, характерные для компьютеров из разных групп данной классификации. В этом случае для корректного описания автор использует знак '+'. Например, практически все векторные компьютеры имеют скалярную и векторную части, что можно описать как OPPiS+DPPiS (пример - это TI ASC и CDC STAR-100). Если в системе есть возможность одновременного выполнения более одной векторной команды (как в CRAY-1) то для описания векторной части можно использовать запись O*DPPiS, а полное описание данного компьютера выглядит так: O*DPPiS+OPPiS. Действуя по такому же принципу, можно найти описание и для систем CRAY X-MP и CRAY Y-MP. В самом деле, данные системы объединяют несколько процессоров, имеющих схожую с CRAY-1 структуру, и потому их описание имеет вид: T*(O*DPPiS+OPPiS).
1.10 Классификация КришнамарфиЕ.Кришнамарфи для классификации параллельных вычислительных систем предлагает использовать четыре характеристики, очень похожие на характеристики классификации А.Базу:
- степень гранулярности;
- способ реализации параллелизма;
- топология и природа связи процессоров;
- способ управления процессорами.
Принцип построения классификации очень прост. Для каждой степени гранулярности будем рассматривать все возможные способы реализации параллелизма. Для каждого полученного таким образом варианта рассмотрим все комбинации топологии связи и способов управления процессорами. В результате получим дерево (pис. 1.14), в котором каждый ярус соответствует своей характеристике, каждый лист представляет отдельную группу компьютеров в данной классификации, а путь от вершины дерева однозначно определяет значения указанных выше характеристик. Разберем характеристики подробнее.
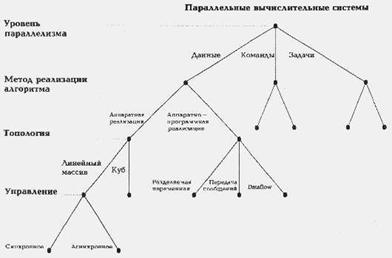
Рисунок 1.14 – Дерево классификации Кришнамарфи
Первые два уровня практически один к одному повторяют А.Базу. Третий уровень классификации, топология и природа связи процессоров, тесно связан со вторым. Если был выбран аппаратный способ реализации параллелизма, то надо рассмотреть топологию связи процессоров (матрица, линейный массив, тор, дерево, звезда и т.п.) и степень связности процессоров между собой (сильная, слабая или средняя), которая определяется относительной долей накладных расходов при организации взаимодействия процессоров. В случае комбинированной реализации параллелизма, помимо топологии и степени связности, надо дополнительно учесть механизм взаимодействия процессоров: передача сообщений, разделяемые переменные или принцип dataflow (по готовности операндов).
Наконец, последний, четвертый уровень - способ управления процессорами, определяет общий принцип функционирования всей совокупности процессоров вычислительной системы: синхронный, dataflow или асинхронный.
На основе выделенных четырех характеристик нетрудно определить место наиболее известных классов архитектур в данной систематике.
Векторно-конвейерные компьютеры:
- гранулярность - на уровне данных;
- реализация параллелизма - аппаратная;
- связь процессоров - простая топология со средней связностью;
- способ управления - синхронный.
Классические мультипроцессоры:
- гранулярность - на уровне задач
- реализация параллелизма - комбинированная;
- связь процессоров - простая топология со слабой связностью и использованием разделяемых переменных;
- способ управления - асинхронный.
Матрицы процессоров:
- гранулярность - на уровне данных;
- реализация параллелизма - аппаратная;
- связь процессоров - двумерные массивы с сильной связностью;
- способ управления - синхронный.
Систолические массивы:
- гранулярность - на уровне данных;
- реализация параллелизма - аппаратная;
- связь процессоров - сложная топология с сильной связностью;
- способ управления - синхронный.
Архитектура типа wavefront:
- гранулярность - на уровне данных;
- реализация параллелизма - аппаратная;
- связь процессоров - двумерная топология с сильной связностью;
- способ управления - dataflow.
Архитектура типа dataflow:
- гранулярность - на уровне команд;
- реализация параллелизма - комбинированная;
- связь процессоров - простая топология с сильной либо средней связностью и использованием принципа dataflow;
- способ управления - асинхронно-dataflow.
Несмотря на то, что классификация Е. Кришнамарфи построена лишь на четырех признаках, она позволяет выделить и описать такие "нетрадиционные" параллельные системы, как систолические массивы, машины типа dataflow и wavefront. Однако эта же простота является и основной причиной ее недостатков: некоторые архитектуры нельзя однозначно отнести к тому или иному классу, например, компьютеры с архитектурой гиперкуба и ассоциативные процессоры. Для более точного описания таких машин потребуется ввести еще целый ряд характеристик, таких, как размещение задач по процессорам, способ маршрутизации сообщений, возможность реконфигурации, аппаратная поддержка языков программирования и другие. Вместе с тем ясно, что эти признаки формализовать гораздо труднее, поэтому есть опасность вместо ясности внести в описание лишь дополнительные трудности.
1.11 Классификация СкилликорнаВ 1989 году была сделана очередная попытка расширить классификацию Флинна и, тем самым, преодолеть ее недостатки. Д.Скилликорн разработал подход, пригодный для описания свойств многопроцессорных систем и некоторых нетрадиционных архитектур, в частности dataflow и reduction machine.
Предлагается рассматривать архитектуру любого компьютера, как абстрактную структуру, состоящую из четырех компонент:
- процессор команд (IP - Instruction Processor) - функциональное устройство, работающее, как интерпретатор команд; в системе, вообще говоря, может отсутствовать;
- процессор данных (DP - Data Processor) - функциональное устройство, работающее как преобразователь данных, в соответствии с арифметическими операциями;
- иерархия памяти (IM - Instruction Memory, DM - Data Memory) - запоминающее устройство, в котором хранятся данные и команды, пересылаемые между процессорами;
- переключатель - абстрактное устройство, обеспечивающее связь между процессорами и памятью.
Функции процессора команд во многом схожи с функциями устройств управления последовательных машин и, согласно Д.Скилликорну, сводятся к следующим:
- на основе своего состояния и полученной от DP информации IP определяет адрес команды, которая будет выполняться следующей;
- осуществляет доступ к IM для выборки команды;
- получает и декодирует выбранную команду;
- сообщает DP команду, которую надо выполнить;
- определяет адреса операндов и посылает их в DP;
- получает от DP информацию о результате выполнения команды.
Функции процессора данных делают его , во многом, похожим на арифметическое устройство традиционных процессоров:
- DP получает от IP команду, которую надо выполнить;
- получает от IP адреса операндов;
- выбирает операнды из DM;
- выполняет команду;
- запоминает результат в DM;
- возвращает в IP информацию о состоянии после выполнения команды.
В терминах таким образом определенных основных частей компьютера структуру традиционной фон-неймановской архитектуры можно представить в следующем виде:
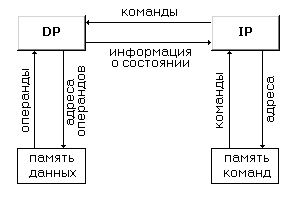
Рисунок 1.15 – Структура фон-неймановской архитектуры
Это один из самых простых видов архитектуры, не содержащих переключателей. Для описания параллельных вычислительных систем автор зафиксировал четыре типа переключателей, без какой-либо явной связи с типом устройств, которые они соединяют:
- 1-1 - переключатель такого типа связывает пару функциональных устройств;
- n-n - переключатель связывает i-е устройство из одного множества устройств с i-м устройством из другого множества, т.е. фиксирует попарную связь;
- 1-n - переключатель соединяет одно выделенное устройство со всеми функциональными устройствами из некоторого набора;
- nxn - каждое функциональное устройство одного множества может быть связано с любым устройством другого множества, и наоборот.
Примеров подобных переключателей можно привести очень много. Так, все матричные процессоры имеют переключатель типа 1-n для связи единственного процессора команд со всеми процессорами данных. В компьютерах семейства Connection Machine каждый процессор данных имеет свою локальную память, следовательно, связь будет описываться как n-n. В тоже время, каждый процессор команд может связаться с любым другим процессором, поэтому данная связь будет описана как nxn.
Классификация Д.Скилликорна состоит из двух уровней. На первом уровне она проводится на основе восьми характеристик:
- количество процессоров команд (IP);
- число запоминающих устройств (модулей памяти) команд (IM);
- тип переключателя между IP и IM;
- количество процессоров данных (DP);
- число запоминающих устройств (модулей памяти) данных (DM);
- тип переключателя между DP и DM;
- тип переключателя между IP и DP;
- тип переключателя между DP и DP.
Рассмотрим упомянутый выше компьютер Connection Machine 2. В терминах данных характеристик его можно описать: (1, 1, 1-1, n, n, n-n, 1-n, nxn),
Для сильно связанных мультипроцессоров (BBN Butterfly, C.mmp) ситуация иная. Такие системы состоят из множества процессоров, соединенных с модулями памяти с помощью динамического переключателя. Задержка при доступе любого процессора к любому модулю памяти примерно одинакова. Связь и синхронизация между процессорами осуществляется через общие (разделяемые) переменные. Описание таких машин в рамках данной классификации выглядит так: (n, n, n-n, n, n, nxn, n-n, нет),
Используя введенные характеристики и предполагая, что рассмотрение количественных характеристик можно ограничить только тремя возможными вариантами значений: 0, 1 и n (т.е. больше одного), можно получить 28 классов архитектур.
В классах 1-5 находятся компьютеры типа dataflow и reduction, не имеющие процессоров команд в обычном понимании этого слова. Класс 6 это классическая фон-неймановская последовательная машина. Все разновидности матричных процессоров содержатся в классах 7-10. Классы 11 и 12 отвечают компьютерам типа MISD классификации Флинна и на настоящий момент, по мнению автора, пусты. Классы с 13-го по 28-й занимают всесозможные варианты мультипроцессоров, причем в 13-20 классах находятся машины с достаточно привычной архитектурой, в то время, как архитектура классов 21-28 пока выглядит экзотично.
На втором уровне классификации Д.Скилликорн просто уточняет описание, сделанное на первом уровне, добавляя возможность конвейерной обработки в процессорах команд и данных.
В конце данного описания имеет смысл привести сформулированные автором три цели, которым должна служить хорошо построенная классификация:
- облегчать понимание того, что достигнуто на сегодняшний день в области архитектур вычислительных систем, и какие архитектуры имеют лучшие перспективы в будущем;
- подсказывать новые пути организации архитектур - речь идет о тех классах, которые в настоящее время по разным причинам пусты;
- показывать, за счет каких структурных особенностей достигается увеличение производительности различных вычислительных систем; с этой точки зрения, классификация может служить моделью для анализа производительности.
1.12 Классификация Дазгупты
Одним из последних исследований по классификации архитектур, по-видимому, является работа С. Дазгупты, вышедшая в 1990 году. Автор использовал позитивные идеи работы Скилликорна, которая была рассмотрена ранее в данном обзоре. Пытаясь расширить описательные возможности классификации, он разработал иерархическую систему для классификации архитектур. Изложим ее основные идеи.
Предлагаемая система построена на основе семи элементарных понятий - базовых элементов архитектуры.
Базовые элементы архитектуры:
- iM - память с расслоением - память, из которой можно выбрать несколько единиц информации за один цикл памяти;
- sM - простая память - память, из которой можно выбрать единицу информации за цикл памяти;
- C - программируемая или непрограммируемая кэш-память. Буферные регистры, подобные регистрам CRAY-1, также описываются, как кэш-память;
- sI - простой (неконвейерный) процессор для подготовки команды к исполнению;
- pI - конвейерный процессор для подготовки команды к исполнению;
- sX - простой процессор для исполнения команды;
- pX - конвейерный процессор для исполнения команды.
Заметим, что функции процессора для подготовки команды к исполнению (I) эквивалентны тем, которые выполняет процессор команд (IP) по классификации Скилликорна, с дополнительной возможностью обращения к кэш-памяти. Аналогично, функции процессора для исполнения команд (X) совпадают с функциями процессора данных (DP) у Скилликорна, включая дополнительно работу с кэш-памятью.
Если архитектура содержит N элементов типа A, которые могут работать в системе параллельно и независимо (обозначим эту возможность AN), то AN будем называть сложным элементом типа A. Считается, что составляющие сложного элемента не имеют между собой физической связи. Например:
sM3 - три блока простой памяти, к которым можно обращаться параллельно и независимо;
sI4 - четыре неконвейерных процессора, которые могут параллельно и независимо подготовить к исполнению команды из четырех потоков команд.
Назовем кэш-процессором CP объединение C-элемента с I, X или другими CP.
Например, C.sI, C.(C2.pI)2
Обозначение Ä1.A2" подразумевает последовательное соединение элемента A1 с элементом A2.
Например, процессор команд с кэш-памятью: C.sI C - sI
Назовем кэш-процессором с памятью MCP объединение M-элемента с I, X, CP или другими MCP.
Например, iM.(C.sI2)k, sM.iM.C.pIn
Процессором для подготовки команд I" назовем MCP, который представляет собой законченную подсистему подготовки команды к исполнению.
Процессором для исполнения команд X" назовем MCP, который представляет собой законченную подсистему для выполнения команды.
Процессоры, как и базовые элементы, могут быть сложными элементами архитектуры в смысле определения данного выше.
Полным описанием архитектуры может служить одиночная или повторяющаяся последовательность, составленная из I" и X" процессоров.
Символьную строку, описывающую некоторый базовый элемент, сложный элемент, процессор или всю архитектуру, будем называть формулой архитектуры.
Каждая формула служит описанием некоторой структуры. Введем два оператора, устанавливающих соответствие между формулой и структурой:
1) Пусть R - формула. Тогда оператор Rep(R) описывает следующую структуру:
![]()
Другими словами, если R = AN, то структура описывается оператором Rep(R);
2) Пусть R = R1.R2. ... .Rn - формула, где Ri может быть базовым или сложным элементом, простым или сложным процессором. Обозначим head(R) = R1 - самую левую составляющую в формуле; tail(R) = Rn - самую правую составляющую в формуле.
Введем второй оператор Link. Пусть R1 и R2 - формулы. Тогда Link(R1, R2):
а) если tail(R1) и head(R2) - простые составляющие, то
![]()
б) если tail(R1) простая, а head(R2) - сложная составляющая вида Zn, то
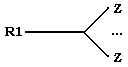
в) если tail(R1) - сложная составляющая вида Wn, а head(R2) - простая, то
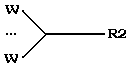
г) если tail(R1) - сложная составляющая вида Wn, а head(R2) - сложная составляющая вида Zm, то
Легко понять, что оператор Link явно описывает связи между элементами архитектуры. В классификации Скилликорна этим целям служили переключатели четырех типов (см. классификацию Д.Скилликорна ).
Используя систему понятий и обозначений, введенных выше, автор строит следующую систему классификации.
Назовем классом классификационной схемы именованную группу объектов, которые по некоторым специально выделенным свойствам отличаются от объектов других классов. Множество классов образует категорию.
Множество свойств, которые являются определяющими при отнесении объекта к какому-либо классу, назовем классификационными характеристиками (TC - taxonomic characters). В нашем случае введенные выше базовые элементы архитектуры определяют эти классификационные характеристики.
В сложных системах классификации может быть несколько категорий, образующих иерархию. Каждый объект может появляться только в одном классе в некоторой категории.
С. Дазгупта предлагает для систематизации архитектур классификацию с тремя уровнями (категориями) иерархии. Он считает, что иерархические системы обладают рядом привлекательных свойств. В частности, подобные системы позволяют не только легче сравнивать объекты, но также дают возможность определять, по каким параметрам и в какой степени объекты одного уровня иерархии сходны или различны.
Иерархия категорий строится таким образом, что объекты более низкого уровня обладают всеми свойствами объектов выше расположенного уровня и некоторыми дополнительными свойствами. Таким образом, степень детализации описания архитектуры будет уменьшаться при переходе к категориям более высокого уровня иерархии.
Итак, автор предлагает следующую иерархию категорий:
1) Самый низкий уровень - категория КЭШ-процессора с памятью MCP (memory-cache processor).
Классами этой категории являются всевозможные различные архитектуры. Соответствующую архитектуре формулу можно рассматривать как имя класса.
2) Более высокий уровень - категория КЭШ-процессора (СP). Множество классов этой категории получается путем удаления из классов категории CP составляющих, описывающих память.
3) Самый высокий уровень - категория процессора (P). Классы получают удалением кэш-составляющих из классов категории CP.
На каждом уровне описание архитектуры задается формулой, отображающей те свойства архитектуры, которые являются существенными для данной категории.
Наиболее низкий уровень иерархии содержит в виде формулы самое подробное описание архитектуры в терминах различных типов памяти и процессоров, с возможностью количественного отображения различных элементов архитектуры и указания природы связей между ними.
Две архитектуры принадлежат к одному классу в CP категории, если совпадают их описания процессоров и кэш-памяти. Если две архитектуры сходны только по описанию процессоров команд, то они попадают в один класс процессорной категории.
В заключении отметим, что те уровни иерархии, которые выделены Дазгуптой, не являются единственно возможными. Могут появиться другие варианты в зависимости от целей систематизации архитектур ( например, не всегда нас интересует конкретное число процессоров в системе или тип используемой памяти).
1.13 Классификация Дункана
В работе Р.Дункан излагает свой взгляд на проблему классификации архитектур параллельных вычислительных систем, причем сразу определяет тот набор требований, на который, с его точки зрения, может опираться искомая классификация:
1) Из класса параллельных машин должны быть исключены те, в которых параллелизм заложен лишь на самом низком уровне, включая:
- конвейеризацию на этапе подготовки и выполнения команды (instruction pipelining), т.е. частичное перекрытие таких этапов, как дешифрация команды, вычисление адресов операндов, выборка операндов, выполнение команды и сохранение результата;
- наличие в архитектуре нескольких функциональных устройств, работающих независимо, в частности, возможность параллельного выполнения логических и арифметических операций;
- наличие отдельных процессоров ввода/вывода, работающих независимо и параллельно с основными процессорами.
Причины исключения перечисленных выше особенностей автор объясняет следующим образом. Если рассматривать компьютеры, использующие только параллелизм низкого уровня, наравне со всеми остальными, то, во-первых, практически все существующие системы будут классифицированны как "параллельные" (что заведомо не будет позитивным фактором для классификации), и, во-вторых, такие машины будут плохо вписываться в любую модель или концепцию, отражающую параллелизм высокого уровня.
2) Классификация должна быть согласованной с классификацией Флинна, показавшей правильность выбора идеи потоков команд и данных.
3) Классификация должна описывать архитектуры, которые однозначно не укладываются в систематику Флинна, но, тем не менее, относятся к параллельным архитектурам (например, векторно-конвейерные).
Учитывая вышеизложенные требования, Дункан дает неформальное определение параллельной архитектуры, причем именно неформальность дала ему возможность включить в данный класс компьютеры, которые ранее не вписывались в систематику Флинна. Итак, параллельная архитектура - это такой способ организации вычислительной системы, при котором допускается, чтобы множество процессоров (простых или сложных) могло бы работать одновременно, взаимодействуя по мере надобности друг с другом. Следуя этому определению, все разнообразие параллельных архитектур Дункан систематизирует так, как показано на рис. 1.16:
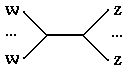
Риснунок 1.16 – Классификация параллельных архитектур по Дункану
По существу систематика очень простая: процессоры системы работают либо синхронно, либо независимо друг от друга, либо в архитектуру системы заложена та или иная модификация идеи MIMD. На следующем уровне происходит детализация в рамках каждого из этих трех классов. Дадим небольшое пояснение лишь к тем из них, которые на сегодняшний день не столь широко известны.
Систолические архитектуры (их чаще называют систолическими массивами) представляют собой множество процессоров, объединенных регулярным образом (например, система WARP). Обращение к памяти может осуществляться только через определенные процессоры на границе массива. Выборка операндов из памяти и передача данных по массиву осуществляется в одном и том же темпе. Направление передачи данных между процессорами фиксировано. Каждый процессор за интервал времени выполняет небольшую инвариантную последовательность действий.
Гибридные MIMD/SIMD архитектуры, dataflow, reduction и wavefront вычислительные системы осуществляют параллельную обработку информации на основе асинхронного управления, как и MIMD системы. Но они выделены в отдельную группу, поскольку все имеют ряд специфических особенностей, которыми не обладают системы, традиционно относящиеся к MIMD.
MIMD/SIMD - типично гибридная архитектура. Она предполагает, что в MIMD системе можно выделить группу процессоров, представляющую собой подсистему, работающую в режиме SIMD (PASM, Non-Von). Такие системы отличаются относительной гибкостью, поскольку допускают реконфигурацию в соответствии с особенностями решаемой прикладной задачи.
Остальные три вида архитектур используют нетрадиционные модели вычислений. Dataflow используют модель, в которой команда может выполнятся сразу же, как только вычислены необходимые операнды. Таким образом, последовательность выполнения команд определяется зависимостью по данным, которая может быть выражена, например, в форме графа.
Модель вычислений, применяемая в reduction машинах иная и состоит в следующем: команда становится доступной для выполнения тогда и только тогда, когда результат ее работы требуется другой, доступной для выполнения, команде в качестве операнда.
Wavefront array архитектура объединяет в себе идею систолической обработки данных и модель вычислений, используемой в dataflow. В данной архитектуре процессоры объединяются в модули и фиксируются связи, по которым процессоры могут взаимодействовать друг с другом. Однако, в противоположность ритмичной работе систолических массивов, данная архитектура использует асинхронный механизм связи с подтверждением (handshaking), из-за чего "фронт волны" вычислений может менять свою форму по мере прохождения по всему множеству процессоров.
Похожие работы

... программе, однако аппаратура обнаружения и устранения конфликтов между логически связанными командами обеспечивает получение результатов в соответствии с заданной программой. Соответствующая организация коммутирующих магистралей, обеспечивающая засылку результата операции непосредственно в буфер, хранящий логически зависимую команду, задержанную из-за конфликта, или непосредственно ...
... элементов, глобальное пространство имен, а также лавинообразную первоначальную загрузку сети. Таким образом ОСРВ SPOX имеет необходимые механизмы для создания отказоустойчивой распределенной операционной системы реального времени, концепция построения которой описана в главе 2. 4.3 Аппаратно-зависимые компоненты ОСРВ Модули маршрутизации, реконфигурации, голосования реализованы как аппаратно- ...
... ? 8. Какими программами можно воспользоваться для устранения проблем и ошибок, обнаруженных программой Sandra? Раздел 3. Автономная и комплексная проверка функционирования и диагностика СВТ, АПС и АПК Некоторые из достаточно интеллектуальных средств вычислительной техники, такие как принтеры, плоттеры, могут иметь режимы автономного тестировании. Так, автономный тест принтера запускается без ...
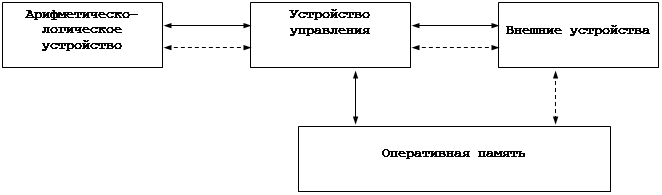
... оснащать их дополнительными устройствами сотен различных производителей. Итак, после начала широкого внедрения персональных компьютеров в повседневную жизнь, продолжилось быстрое развитие вычислительной техники. Остановимся на наиболее важном элементе: микропроцессор – это эффективный с технологической и экономической точки зрения инструмент для переработки возрастающих потоков информации. Новое ...
0 комментариев