Навигация
Градація яркостей зображень
42785
знаков
3
таблицы
8
изображений
1.4 Градація яркостей зображень
Відзначений у п. 1 факт можна використати для градації зображень, коли необхідно більше «часто» градуювати ті області яркостей пикселей, розходження яких необхідно підкреслити. Наприклад, яскраві значення пикселей, а не темних, оскільки око більше чутливе до сприйняття світлих ділянок зображень. Для цього досить перейти до градуировке зображення з матрицею яскравості пикселей ![]() , рівного
, рівного ![]() , де
, де ![]() - матриця, всі значення якої дорівнюють максимальному значенню матриці вихідного зображення
- матриця, всі значення якої дорівнюють максимальному значенню матриці вихідного зображення ![]() . Для стислості такий метод градації назвемо «зворотним», на відміну від градації вихідного зображення, що ми назвемо «прямим».
. Для стислості такий метод градації назвемо «зворотним», на відміну від градації вихідного зображення, що ми назвемо «прямим».
На мал.1 представлені результати 4-х уровневой (2 біти) градації яркостей пикселей зображення «Роза». В інтересах зіставлення на всіх 4-х зображень (включаючи вихідне) сума яркостей пикселей однакова.
Як видно, при рівномірному, не оптимальному, розбивці спостерігаються нечисленні артефакти, «прямий» метод показав гарну чутливість до малих значень пикселей, «зворотній» - виділив всі яскраві ділянки вихідного зображення.
Таким чином, пропонований інформаційний критерій дозволяє одержати інформацію про структуру значень компонент елементів (рядків, стовпців) масиву аналізованих даних, що може бути використана для рішення різних завдань їхнього аналізу - класифікації, оцінки інформативності ознак й їхньої градації.
| 4-х рівневі градуйовані зображення | ||
| рівномірна розбивка | пропонований метод | |
| «прямий» | «зворотній» | |
|
|
|
|
| Вихідне зображення | Графіки зміни критерію інформативності | |
|
| «прямий» метод | «зворотній» метод |
|
|
| |





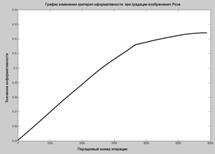
Рис.1 Результати градації зображення «Роза»
Тепер розглянемо методи, якими можна обробити зображення.
2.Застосування імовірнісних методів для підвищення ефективності ощадливого кодування відеоінформації
2.1 Загальна теорія
Відеоінформація являє собою досить специфічний тип інформації - вона двухмерна по своїй природі. У зв'язку з тим, що сучасні обчислювальні алгоритми є здебільшого алгоритмами послідовної обробки, їхнє застосування до інформації такого роду утруднено. При роботі з відеоданими за основу, як правило, вибирається деяка одномірна модель. Зображення розглядається як вибірка джерела послідовної дискретної інформації . Ця вибірка володіє рядом особливих властивостей, що відбивають реальну природу інформаційного джерела.
У даному розділі мова йтиме про застосування контекстно-контекстно-залежного імовірнісного моделювання в методах ощадливого кодування відеоінформації. У рамках контекстно-контекстно-залежного моделювання специфічні особливості відеоданих є основою для виробітку критеріїв формування факторних векторів і розбивки їхньої безлічі на підмножини. Визначальну роль тут грає просторове розташування елементів зображення і їхня близькість.
Вихідним дискретним поданням зображення є колірні компоненти в матричній формі. Проблема ощадливого кодування відеоінформації, таким чином, зводиться до проблеми одержання ефективних подань матриць натуральних чисел. Специфіка цих матриць полягає в наявності сильного імовірнісного взаємозв'язку між сусідніми значеннями матриці. Для обліку цього взаємозв'язку при кодуванні ідеально підходить двомірна контекстно-контекстно-залежна модель, у якій факторний вектор формується із уже закодованих значень двомірного контекстного оточення кодируемой позиції матриці.
Кодування значень матриці може здійснюватися послідовно, відповідно до деяким заздалегідь обраним порядкком обходу позицій. Формування факторного вектора прямо залежить від цього порядку. Якщо, приміром, матриця кодується построчно, потенційними складовими факторного вектора є вже закодовані значення кодируемой рядка, а також значення всіх раніше закодованих рядків, що перебувають при порядковому кодуванні над кодуємим рядком.
Існує альтернативний спосіб кодування. Він має на увазі многопроходную обробку інформації. При використанні многопроходного кодування під час чергового кодового проходу значення матриці кодуються не повністю (наприклад, кодуються окремі біти). Незакодована частина кодується під час наступних проходів. При такому способі організації кодування як складові факторного вектора можна брати тільки вже закодовані частини значень.
Одержання оцінок імовірностей появи символів при використанні описаного методу побудови контекстно-контекстно-залежної моделі нерідко утруднено наступною обставиною: кількість усіляких значень може виявитися настільки більшим, що збирає статистика, що, стане адекватної тільки після обробки значного обсягу інформаційної вибірки. Вихід з даної ситуації - застосування моделювання, при якому моделюються не конкретні значення, а групи або інтервали значень. Поява значень, що належать однієї й тій же групі (інтервалу), уважається равновероятным, тому вводити додаткові моделі для їхньої обробки не потрібно. Описаний прийом дозволяє підвищити ефективність кодування за рахунок підвищення адекватності імовірнісних оцінок (оцінка для групи (інтервалу) виявляється більше точної за рахунок більшого обсягу статистики). Для досягнення оптимального результату варто дуже ретельно підходити до підбору груп (інтервалів) значень. Приміром, що найбільше часто зустрічаються значення недоцільно поєднувати зі значеннями встречающимися значно рідше, тому що для останніх об'єктивність оцінки незрівнянно нижче, ніж для перших.
Похожие работы
... ональних інтересів та безпеку інформаційного простору. Підсумки: В цьому розділі ми з’ясували, які саме зміни всередині урядових організацій, в їх структурі, функціях і методах роботи ініціює запровадження електронного уряду. А саме: відбувається перенесення акцентів з вертикальних на горизонтальні зв’язки всередині уряду, між різними його підрозділами і гілками влади. За рахунок створення внутрі ...
... системи, вибираються тип моделі і математичні методи її опису в залежності від мети і роду інформації. Заключний етап складається в створенні моделі і порівнянні її із системою-об'єктом з метою ідентифікації. Структурне моделювання зорової системи Зоровий аналізатор являє собою складну функціональну систему, що містить багато рівнів для переробки зорової інформації, якість роботи якої багато в ...
... і організації, у якій її члени отримують стимул в усуненні перепон і досягненні максимальних результатів. У своїй роботі я хочу розглянути автоматизоване робоче місце менеджера як комплексне поняття, що включає в себе такий компонент як: - програмне забезпечення для більш ефективної роботи менеджера. Детальний розгляд цього компонента допомагає глибше розкрити і зрозуміти самий процес організац ...
... 15. Білецька В. Українські сорочки, їх типи, еволюція і орнаментація//Матеріали доетнографії та антропології. 1929. Т. 21—22. Ч. 1. С. 81. 16. Кравчук Л. Т. Вишивка // Нариси історії українського декоративно-прикладного мистецтва. Львів, 1969. С. 62. 17. Добрянська І. О„ Симоненко І. Ф, Типи та колорит західноукраїнської вишивки//Народна творчість та етнографія. 1959. № 2. С. 80. 18. ...
0 комментариев