Общие вопросы решения "больших задач"
Параллельная обработка данных
Способы параллельной обработки данных, погрешность вычислений
Взаимодействие параллельных процессов, синхронизация процессов
Принципы построения многопроцессорных вычислительных систем
Распределение вычислений и данных в многопроцессорных вычислительных системах с распределенной памятью
Массивно-параллельные суперкомпьютеры серии CRY T3
Навигация
Способы параллельной обработки данных, погрешность вычислений
Массивно-параллельные суперкомпьютеры серии Cry T3 и кластерные системы класса BEOWULF
70495
знаков
0
таблиц
12
изображений
1.2.3 Способы параллельной обработки данных, погрешность вычислений
Возможны следующие режимы выполнения независимых частей программы:
· Параллельное выполнение – в один и тот же момент времени выполняется несколько команд обработки данных; этот режим вычислений может быть обеспечен не только наличием нескольких процессоров, но и с помощью конвейерных и векторных обрабатывающих устройств.
· Распределенные вычисления – этот термин обычно применяют для указания способа параллельной обработки данных, при которой используются несколько обрабатывающих устройств, достаточно удаленных друг от друга и в которых передача данных по линиям связи приводит к существенным временным задержкам.
При таком способе организации вычислений эффективна обработка данных только для параллельных алгоритмов с низкой интенсивностью потоков межпроцессорных передач данных; таким образом функционируют, например, многомашинные вычислительные комплексы, образуемые объединением нескольких отдельных электронно-вычислительных машин с помощью каналов связи локальных или глобальных информационных сетей.
Формально к этому списку может быть отнесен и многозадачный режим (режим разделения времени), при котором для выполнения процессов используется единственный процессор; в этом режиме удобно отлаживать параллельные приложения.
Существует два способа параллельной обработки данных: параллелизм и конвейерность.
Параллелизм предполагает наличие p одинаковых устройств для обработки данных и алгоритм, позволяющий производить на каждом независимую часть вычислений, в конце обработки частичные данные собираются вместе для получения окончательного результата. В этом случае получим ускорение процесса в p раз. Далеко не каждый алгоритм может быть успешно распараллелен таким способом (естественным условием распараллеливания является вычисление независимых частей выходных данных по одинаковым – или сходным – процедурам; итерационность или рекурсивность вызывают наибольшие проблемы при распараллеливании).
Идея конвейерной обработки заключается в выделении отдельных этапов выполнения общей операции, причем каждый этап после выполнения своей работы передает результат следующему, одновременно принимая новую порцию входных данных. Каждый этап обработки выполняется своей частью устройства обработки данных (ступенью конвейера), каждая ступень выполняет определенное действие (микрооперацию); общая обработка данных требует срабатывания этих частей последовательно.
Конвейерность при выполнении команд имитирует работу конвейера сборочного завода, на котором изделие последовательно проходит ряд рабочих мест; причем на каждом из них над изделием производится новая операция. Эффект ускорения достигается за счет одновременной обработки ряда изделий на разных рабочих местах.
Ускорение вычислений достигается за счет использования всех ступеней конвейера для потоковой обработки данных (данные потоком поступают на вход конвейера и последовательно обрабатываются на всех ступенях). Конвейеры могут быть скалярными или векторными устройствами (разница состоит лишь в том, что в последнем случае могут быть использованы обрабатывающие векторы команды). В случае длины конвейера l время обработки n независимых операций составит l+n−1 (каждая ступень срабатывает за единицу времени). При использовании такого устройства для обработки единственной порции входных данных потребуется время l×n и только для множества порций получим ускорение вычислений, близкое к l.
Из рисунка 2 видно, что производительность E конвейерного устройства асимптотически растет с увеличением длины n набора данных на его входе, стремясь к теоретическому максимуму производительности 1/τ
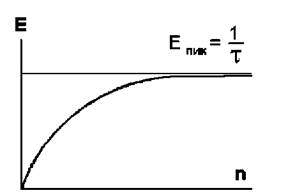
Рисунок 2. Производительность конвейерного устройства в функции длины входного набора данных
1.3 Понятие параллельного процесса и гранулы распараллеливания
Наиболее общая схема выполнения последовательных и параллельных вычислений приведена на рисунке 3 (моменты времени S и E – начало и конец задания соответственно).
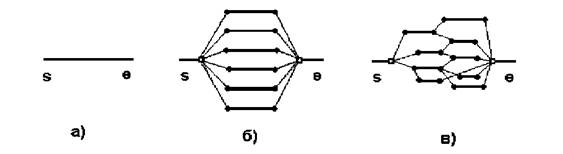
Рисунок 3. Диаграммы выполнения процессов при последовательном вычислении – а), при близком к идеальному распараллеливании – б) и в общем случае распараллеливания – в)
Процессом называют определенные последовательности команд, наравне с другими процессами претендующие для своего выполнения на использование процессора; команды (инструкции) внутри процесса выполняются последовательно, внутренний параллелизм при этом не учитывают.
На рисунке 3 тонкими линиями показаны действия по созданию процессов и обмена данными между ними, толстыми – непосредственно исполнение процессов (ось абсцисс – время). В случае последовательных вычислений создается единственный процесс (рисунок 3a), осуществляющий необходимые действия; при параллельном выполнении алгоритма необходимы несколько процессов (параллельных ветвей задания). В идеальном случае все процессы создаются одновременно и одновременно завершаются (рисунок 3б), в общем случае диаграмма процессов значительно сложнее и представляет собой некоторый граф (рисунок 3в).
Характерная длина последовательно выполняющейся группы команд в каждом из параллельных процессов называется размером гранулы (зерна). В любом случае целесообразно стремиться к "крупнозернистости" (идеал – диаграмма 3б). Обычно размер зерна (гранулы) составляет десятки-сотни тысяч машинных операций (что на порядки превышает типичный размер оператора языков Fortran или C/C++). В зависимости от размеров гранул говорят о мелкозернистом и крупнозернистом параллелизме.
На размер гранулы влияет и удобство программирования – в виде гранулы часто оформляют некий логически законченный фрагмент программы. Целесообразно стремиться к равномерной загрузке процессоров.
Разработка параллельных программ является непростой задачей в связи с трудностью выявления параллелизма (обычно скрытого) в программе (то есть выявления частей алгоритма, могущих выполняться независимо друг от друга).
Автоматизация выявления параллелизма в алгоритмах непроста и в полном объеме вряд ли может быть решена в ближайшее время. В то же время за десятилетия эксплуатации вычислительной техники разработано такое количество последовательных алгоритмов, что не может быть и речи об их ручном распараллеливании.
Даже простейшая модель параллельных вычислений позволяет выявить важное обстоятельство – время обмена данными должно быть как можно меньше времени выполнения последовательности команд, образующих гранулу.
Для реальных задач (традиционно) характерный размер зерна распараллеливания на несколько порядков превышает характерный размер оператора традиционного языка программирования (C/C++ или Fortran).
0 комментариев