Навигация
Иерархическая модель данных
41876
знаков
0
таблиц
12
изображений
1.1 Иерархическая модель данных
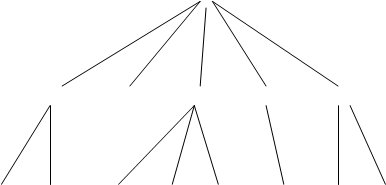
В иерархической модели связи между данными можно описать с помощью упорядоченного графа (или дерева). Упрощенно представление связей между данными в иерархической модели показано на рис.1. (см. Приложение рис.1.) Для описания структуры (схемы) иерархической БД на некотором языке программирования используется тип данных «дерево». Тип «дерево» схож с типами данных «структура» языков программирования ПЛ/1 и C и «запись» языка Паскаль. В них допускается вложенность типов, каждый из которых находится на некотором уровне. Тип «дерево» является составным. Он включает в себя подтипы («поддеревья»), каждый из которых, в свою очередь, является типом «дерево». Каждый из типов «дерево» состоит из одного «корневого» типа и упорядоченного набора (возможно, пустого) подчиненных типов. Каждый из элементарных типов, включённых в тип «дерево», является простым или составным типом «запись». Простая «запись» состоит из одного типа, например числового, а составная «запись» объединяет некоторую совокупность типов, например, целое, строку символов и указатель (ссылку). Пример типа «дерево» как совокупности типов показан на рис.2. (см. Приложение рис.2.)
Корневым называется тип, который имеет подчиненные типы и сам не является подтипом. Подчинённый тип (подтип) является потомком по отношению к типу, который выступает для него в роли предка (родителя). Потомки одного и того же типа являются близнецами по отношению друг к другу.
B целом тип «дерево» представляет собой иерархически организованный набор типов «запись».
Иерархическая БД, представляет собой упорядоченную совокупность экземпляров данных типа «дерево» (деревьев), содержащих экземпляры типа «запись» (записи). Часто отношения родства между типами переносят на отношения между самими записями. Поля записей хранят собственно числовые или символьные значения, составляющие основное содержание БД. Обход всех элементов иерархической БД обычно производится сверху вниз и слева направо.
В иерархических СУБД может использоваться терминология, отличающаяся от приведенной. Так, в системе IMS понятию «запись» соответствует термин «сегмент», а под «записью БД» понимается вся совокупность записей, относящаяся к одному экземпляру типа «дерево».
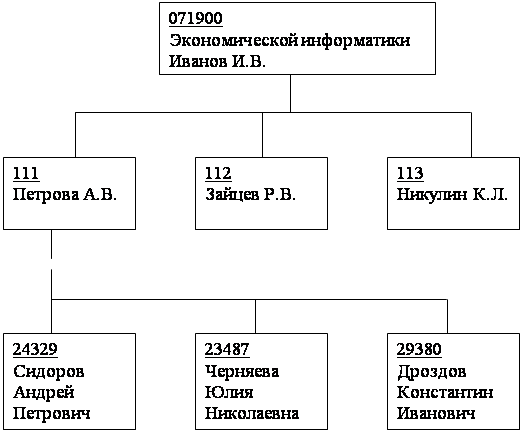
Данные в базе с приведенной схемой (рис.2.) могут выглядеть, например, как показано на рис.3. (см. Приложение рис. 3.)
Для организации физического размещения иерархических данных в памяти ЭВМ могут использоваться следующие группы методов:
1. представление линейным списком с последовательным распределением памяти (адресная арифметика, левосписковые структуры);
2. представление связными линейными списками (методы, использующие указатели и справочники).
К основным операциям манипулирования иерархически организованными данными относятся следующие:
1. поиск указанного экземпляра БД;
2. переход от одного дерева к другому;
3. переход от одной записи к другой внутри;
4. вставка новой записи в указанную позицию;
5. удаление текущей записи и т. д.
B соответствии с определением типа «дерево», можно заключить, что между предками и потомками автоматически поддерживается контроль целостности связей. Основное правило контроля целостности формулируется следующим образом: потомок не может существовать без родителя, а у некоторых родителей может не быть потомков. Механизмы поддержания целостности связей между записями различных деревьев отсутствуют.
K достоинствам иерархической модели данных относятся эффективное использование памяти ЭВМ и неплохие показатели времени выполнения основных операций над данными. Иерархическая модель данных удобна для работы с иерархически упорядоченной информацией. Недостатком иерархической модели является ее громоздкость для обработки информации с достаточно сложными логическими связями, а также сложность понимания для обычного пользователя. На иерархической модели данных основано сравнительно ограниченное количество СУБД, в числе которых можно назвать зарубежные системы IMS, PC/Focus, Теаm-Up и Data Еdgе, а также отечественные системы Ока, ИНЭС и МИРИС.
1.2 Сетевая модель данных
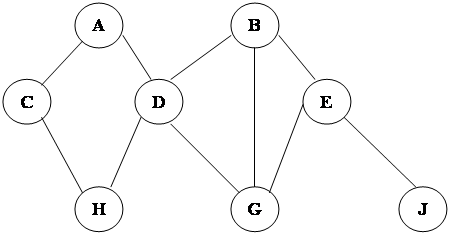
Сетевая модель данных позволяет отображать разнообразные взаимосвязи элементов данных в виде произвольного графа, обобщая тем самым иерархическую модель данных (рис. 4.). Наиболее полно концепция сетевых БД впервые была изложена в Предложениях группы КОДАСИЛ (KODASYL). (см. Приложение рис.4.) Для описания схемы сетевой БД используется две группы типов: «запись» и «связь». Тип «связь» определяется для двух типов «запись»: предка и потомка. Переменная типа «связь» являются экземплярами связей. Сетевая БД состоит из набора записей и набора соответствующих связей. На формирование связи особых ограничений не накладывается. Если в иерархических структурах запись-потомок могла иметь только одну запись-предка, то в сетевой модели данных запись-потомок может иметь произвольное число записей-предков (сводных родителей). Пример схемы простейшей сетевой БД показан на рис.5. Типы связей здесь обозначены надписями на соединяющих типы записей линиях. (см. Приложение рис.5.) B различных СУБД сетевого типа для обозначения одинаковых по сути понятий зачастую используются различные термины. Например, такие как элементы и агрегаты данных, записи, наборы, области и т. д.
Физическое размещение данных в базах сетевого типа может быть организовано практически теми же методами, что и в иерархических базах данных.
K числу важнейших операций манипулирования данными баз сетевого типа можно отнести следующие:
· поиск записи в БД;
· переход от предка к первому потомку;
· переход от потомка к предку;
· создание новой записи;
· удаление текущей записи;
· обновление текущей записи;
· включение записи в связь;
· исключение записи из связи;
· изменение связей и т. д.
Достоинством сетевой модели данных является возможность эффективной реализации по показателям затрат памяти и оперативности. B сравнении с иерархической моделью сетевая модель предоставляет большие возможности в смысле допустимости образования произвольных связей.
Недостатком сетевой модели данных является высокая сложность и жесткость схемы БД, построенной на ее основе, а также сложность для понимания и выполнения обработки информации в БД обычным пользователем. Кроме того, в сетевой модели данных ослаблен контроль целостности связей вследствие допустимости установления произвольных связен между записями.
Системы на основе сетевой модели не получили широкого распространения на практике. Наиболее известными сетевыми СУБД являются следующие: IDMS, db_VistaIII, СЕТЬ, СЕТОР и КОМПАС.
Похожие работы

... став вторичного ключа, не может принимать значение NULL. Перекрывающиеся ключи — сложные ключи, которые имеют один или несколько общих столбцов. Связанные отношения В реляционной модели данные представляются в виде совокупности взаимосвязанных таблиц. Подобное взаимоотношение между таблицами называется связью (rilationship). Таким образом, еще одним важным понятием реляционной модели является ...
... на них повысилась. В этом и заключалось преимущество Shell перед конкурентами в эпоху доминирования ОПЕК. Помимо сценариев, Shell продолжает экспериментировать с различными инструментами управления интеллектуальными моделями. Сюда входят инструменты системного мышления (см. главы 4—8), компьютерное моделирование (см. главу 17), "микромиры" и другие "мягкие системы", получившие такое название ...
... были установлены, происходит на основе логических обобщений и, как правило, опирается на ряд интуитивных соображений. При этом формулируются общие физические и математические модели. Понятие модели в естественных науках подразумевает совокупность представлений, понятий или выводов, которые в нашем сознании связываются с рассматриваемым явлением и позволяет не только объяснить наблюдаемые факты, ...
... , креативщики изо всех сил пытаются что-то как-то "позиционировать", но большинство попыток - "мимо кассы". Продукт обычно выигрывает только за счет дистрибуции и мерчендайзинга. При рассматрении же ситуативных моделей возможности для создания уникальных продуктов, которые будут востребованы потребителем, - как на ладони. Взгляд со стороны ситуативных моделей (то есть обобщенных ситуаций, которые ...
0 комментариев