ПРЕДПОСЫЛКИ МЕТОДА НАИМЕНЬШИХ КВАДРАТОВ И ИХ РЕАЛИЗАЦИЯ В STATISTICA
Небольшое изменение исходных данных (например, добавление новых наблюдений) приводит к существенному изменению оценок коэффициентов модели
Требования к остаткам
Проверка гипотезы о нормальности остатков в модуле Multiple Regression Statistica
СОЗДАНИЕ МАКРОСА ДЛЯ ПРОВЕРКИ ГИПОТЕЗЫ О НОРМАЛЬНОСТИ ОСТАТКОВ
Проверка гипотезы о нормальности остатков в модели вторичного рынка жилья в г. Минске
Навигация
Небольшое изменение исходных данных (например, добавление новых наблюдений) приводит к существенному изменению оценок коэффициентов модели
Создание макроса на языке Statistica Visual Basic для проверки гипотезы о нормальности остатков регрессии
48568
знаков
2
таблицы
25
изображений
1. Небольшое изменение исходных данных (например, добавление новых наблюдений) приводит к существенному изменению оценок коэффициентов модели.
2. Оценки имеют большие стандартные ошибки, малую значимость, в то время как модель в целом является значимой (высокое значение коэффициента детерминации R2 и соответствующей F-статистики).
3. Оценки коэффициентов имеют неправильные с точки зрения теории знаки или неоправданно большие значения.[Магнус 94]
Подходы к отбору факторов на основе показателей корреляции могут быть разные. Наиболее широкое применение получили следующие методы построения уравнения множественной регрессии:
• метод исключения;
• метод включения;
• шаговый регрессионный анализ.
Каждый из этих методов по-своему решает проблему отбора факторов, давая в целом близкие результаты - отсев факторов из полного его набора (метод исключения), дополнительное введение фактора (метод включения), исключение ранее введенного фактора (шаговый регрессионный анализ).
Как и в парной зависимости, возможны разные виды уравнений множественной регрессии: линейные и нелинейные. [Елисеева-100] Линейные модели регрессии могут быть описаны как линейные в двух отношениях: как линейные по переменным и как линейные по параметрам. Для линейного регрессионного анализа требуется линейность только по параметрам (![]() ), поскольку нелинейность по переменным (
), поскольку нелинейность по переменным (![]() ) может быть устранена с помощью изменения определений.[Доугерти 141]
) может быть устранена с помощью изменения определений.[Доугерти 141]
В линейной множественной регрессии параметры при х называются коэффициентами регрессии (![]() ). Они характеризуют среднее изменение результата (
). Они характеризуют среднее изменение результата (![]() ) с изменением соответствующего фактора (
) с изменением соответствующего фактора (![]() ) на единицу при неизмененном значении других факторов, закрепленных на среднем уровне. [Елисеева-100]
) на единицу при неизмененном значении других факторов, закрепленных на среднем уровне. [Елисеева-100]
Оценка значимости коэффициентов чистой регрессии может быть проведена по t-критерию Стьюдента. В этом случае, как и в парной регрессии, для каждого фактора используется формула:
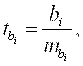
где ![]() - коэффициент чистой регрессии при факторе хi;
- коэффициент чистой регрессии при факторе хi;
![]() - средняя квадратическая ошибка коэффициента регрессии
- средняя квадратическая ошибка коэффициента регрессии ![]() .
.
Для уравнения множественной регрессии ![]()
средняя квадратическая ошибка коэффициента регрессии ![]() может быть определена по следующей формуле:
может быть определена по следующей формуле:

где ![]() - среднее квадратическое отклонение для признака у;
- среднее квадратическое отклонение для признака у;
![]() - среднее квадратическое отклонение для признака
- среднее квадратическое отклонение для признака ![]() ;
;
![]() - коэффициент детерминации для уравнения множественной регрессии;
- коэффициент детерминации для уравнения множественной регрессии;
![]() - коэффициент детерминации для зависимости фактора
- коэффициент детерминации для зависимости фактора ![]() со всеми другими факторами уравнения множественной регрессии;
со всеми другими факторами уравнения множественной регрессии;
![]() - число степеней свободы для остаточной суммы квадратов отклонений. [Елисеева-136-137]
- число степеней свободы для остаточной суммы квадратов отклонений. [Елисеева-136-137]
Критический уровень t при любом уровне значимости зависит от числа степеней свободы, которое равно ![]() : число наблюдений минус число оцененных параметров. [Доугерти 154]
: число наблюдений минус число оцененных параметров. [Доугерти 154]
Практическая значимость уравнения множественной регрессии оценивается с помощью показателя множественной корреляции (![]() ) и его квадрата – коэффициента детерминации (
) и его квадрата – коэффициента детерминации (![]() ). [Елисеева-112]
). [Елисеева-112]
Показатель множественной корреляции может быть найден как индекс множественной корреляции:

где ![]() - общая дисперсия результативного признака;
- общая дисперсия результативного признака;
![]() - остаточная дисперсия для уравнения
- остаточная дисперсия для уравнения ![]()
Границы изменения индекса множественной корреляции: от 0 до 1. Чем ближе его значение к 1, тем теснее связь результативного признака со всем набором исследуемых факторов. [Елисеева-113]
Коэффициент детерминации ![]() определяет долю дисперсии
определяет долю дисперсии ![]() , объясненную регрессией. [Доугерти 159]
, объясненную регрессией. [Доугерти 159]
Значимость уравнения множественной регрессии в целом оценивается с помощью F-критерия Фишера:
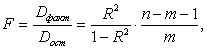
где ![]() - факторная сумма квадратов на одну степень свободы;
- факторная сумма квадратов на одну степень свободы;
![]() - остаточная сумма квадратов на одну степень свободы;
- остаточная сумма квадратов на одну степень свободы;
![]() - коэффициент (индекс) множественной детерминации;
- коэффициент (индекс) множественной детерминации;
![]() - число параметров при переменных
- число параметров при переменных ![]() (в линейной регрессии совпадает с числом включенных в модель факторов);
(в линейной регрессии совпадает с числом включенных в модель факторов);
![]() - число наблюдений. [Елисеева-129]
- число наблюдений. [Елисеева-129]
Смысл проверяемой гипотезы заключается в том, что все коэффициенты линейной регрессии, за исключением свободного параметра, равны нулю (случай отсутствия линейной функциональной связи).
![]()
Величина F имеет распределение Фишера с степенями свободы ![]() . Распределение Фишера - двухпараметрическое распределение неотрицательной случайной величины, являющейся в частном случае при m = 1 квадратом случайной величины, распределенной по Стьюденту. [Салманов 48]. В определенном смысле этот тест дополняет t-тесты, которые используются для проверки значимости вклада отдельных случайных переменных, когда проверяется каждая из гипотез
. Распределение Фишера - двухпараметрическое распределение неотрицательной случайной величины, являющейся в частном случае при m = 1 квадратом случайной величины, распределенной по Стьюденту. [Салманов 48]. В определенном смысле этот тест дополняет t-тесты, которые используются для проверки значимости вклада отдельных случайных переменных, когда проверяется каждая из гипотез ![]() .. [Доугерти 160]
.. [Доугерти 160]
Для проверки нулевой гипотезы при заданном уровне значимости по таблицам находится критическое значение Fкрит, и нулевая гипотеза отвергается, если ![]() .
.
Распределение Фишера может быть использовано не только для проверки гипотезы об одновременном равенстве нулю всех коэффициентов линейной регрессии, но и гипотезы о равенстве нулю части этих коэффициентов. Это особенно важно при развитии линейной регрессионной модели, так как позволяет оценить обоснованность исключения отдельных переменных или их групп из числа объясняющих переменных или, наоборот, включения их в это число. [Салманов 48].
0 комментариев