Навигация
Параметричні критерії для перевірки гіпотези про відмінність (або схожість) між середніми значеннями
17194
знака
0
таблиц
1
изображение
2. Параметричні критерії для перевірки гіпотези про відмінність (або схожість) між середніми значеннями
Отже, якщо ваші вибірки мають нормальний розподіл, для перевірки статистичних гіпотез на їх основі можна користуватися параметричними критеріями. Найпоширенішим параметричним методом оцінки відмінностей між порівнюваними середніми значеннями незалежних вибірок є критерій Стьюдента, або t-критерий. Нульова гіпотеза полягає в рівності генеральних середніх М1 і М2, (М1 – М2) = 0 сукупностей, з яких були взяті вибірки, або, іншими словами, перевіряється нульова гіпотеза про приналежність двох порівнюваних вибірок однієї і тієї самої генеральної сукупності. T-критерій, що перевіряється, виражається у вигляді відношення різниці відповідних вибіркових середніх до помилки такої різниці, тобто
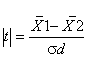 або
або 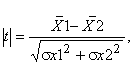
де σd – стандартна помилка різниці вибіркових середніх значень, σх1, σх2 – стандартні помилки середніх значень порівнюваних вибірок.
Треба звернути увагу, що дисперсія різниці (так само, як і дисперсія суми) двох середніх значень дорівнює сумі дисперсій цих середніх значень.
Для перевірки критерію знак різниці середніх значень не відіграє ролі, тому у формулі для розрахунку тестової статистики береться модуль різниці. Проте знак різниці важливий для інтерпретації результатів порівняння і висновку про перевагу одного з порівнюваних методів. Надалі при порівнянні параметрів у формулах для тестових статистик ми опускатимемо знак модуля.
Гіпотезу про рівність математичних очікувань відкидають, якщо фактично отримана величина t-критерію перевершить або виявиться рівною табличному значенню для прийнятого рівня значимості і числа ступенів свободи. При цьому робиться висновок про наявність статистично значимих відмінностей між середніми значеннями на відповідному рівні значимості.
Формули для розрахунку тестової статистики і числа ступенів свободи дещо розрізняються залежно від рівності або нерівності дисперсій порівнюваних сукупностей. Це питання вимагає уважного розгляду, особливо для вибірок малого об'єму (n < 20).
У разі рівності дисперсій або вибірок достатньо великого об'єму помилка різниці середніх σd визначається за такими формулами:
для нерівночисельних вибірок при n1≠n2
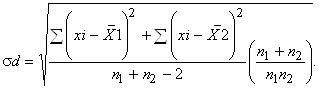
для рівночисельних вибірок при n1= n2 формула дещо спрощується:

Число ступенів свободи для випадку рівних дисперсій дорівнює ![]() . Якщо хоча б одна з порівнювальних вибірок мала, то спочатку слід перевірити гіпотезу про рівність дисперсій вибірок. Залежно від відповіді на це запитання подальше порівняння середніх арифметичних проводять двома різними способами.
. Якщо хоча б одна з порівнювальних вибірок мала, то спочатку слід перевірити гіпотезу про рівність дисперсій вибірок. Залежно від відповіді на це запитання подальше порівняння середніх арифметичних проводять двома різними способами.
Для перевірки гіпотези про рівність генеральних дисперсій користуються критерієм Фішера. При цьому обчислюють показник Фішера, що дорівнює відношенню більшої вибіркової дисперсії до меншої: 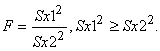 Показник Фішера завжди F> 1, а при рівності дисперсій F=1. Чим значніше нерівність, тим більше значення показника і навпаки. Функція F табульована і залежить від чисел ступенів свободи. Якщо обчислене значення F перевищить відповідне табличне значення і гіпотеза про рівність дисперсій буде знехтувана, то це означає, що вибірки були взяті з сукупностей з різними дисперсіями.
Показник Фішера завжди F> 1, а при рівності дисперсій F=1. Чим значніше нерівність, тим більше значення показника і навпаки. Функція F табульована і залежить від чисел ступенів свободи. Якщо обчислене значення F перевищить відповідне табличне значення і гіпотеза про рівність дисперсій буде знехтувана, то це означає, що вибірки були взяті з сукупностей з різними дисперсіями.
Для порівняння двох залежних вибірок або вибірок з попарно пов'язаними варіантами перевіряють гіпотезу про рівність нулю середнього значення їх попарних різниць. Така задача виникає, коли є дані про зміну ознаки, що нас цікавить, у кожного пацієнта. Наприклад, якщо група пацієнтів одержувала метод лікування, що вивчається, і у кожного пацієнта вимірювалося значення ознаки до і після лікування. В даному випадку належить перевірити нульову гіпотезу про рівність нулю змін цієї ознаки в результаті отримання терапії.
3. Непараметричні критерії для перевірки гіпотези про відмінність (або схожість) між середніми значеннями
Для порівняння середніх значень може застосовуватися і цілий ряд непараметричних критеріїв, серед яких важливе місце займають так звані рангові критерії. Використання цих критеріїв було засновано на ранжируванні членів порівнювальних груп. При цьому порівнюються не самі члени ранжированого ряду, а їх порядкові номери або ранги. Під час розв’язання конкретної задачі дуже важливо правильно обрати критерій.
Наведемо U-критерий Уїлкоксона (Манна–Уітні) для перевірки гіпотези про приналежність порівнюваних незалежних вибірок до однієї і тієї самої генеральної сукупності. Гіпотезу перевіряють, розташувавши в узагальнений ряд значення порівнювальних вибірок у зростаючому порядку. Всім значенням отриманого узагальненого ряду привласнюються ранги від 1 до N=n1+n2. Для кожної вибірки знаходяться суми рангів R і розраховуються статистики: ![]() для
для ![]() та
та![]() - номер вибірки.
- номер вибірки.
Якщо нульова гіпотеза вірна і вибірки були взяті з однієї і тієї самої генеральної сукупності, ми не повинні очікувати переважання спостережень з однієї вибірки на одному з кінців з'єднаного варіаційного ряду, їх значення мають бути достатньо рівномірно розсіяні по всьому узагальненому ряду. Таким чином, дуже великі або дуже малі значення статистики R мають примусити нас засумніватися у справедливості нульової гіпотези. Як тестову статистику вибирають мінімальну величину U і порівнюють її з табличним значенням для прийнятого рівня значимості. Гіпотеза приймається, і відмінності вважаються недостовірними, якщо розраховане значення більше відповідного табличного.
Зазвичай у таблицях наводяться критичні значення даного критерію для об'єму вибірок 20 або 40. У разі вибірок більшого об'єму для перевірки даного критерію застосовується нормальна апроксимація. Тоді критичні значення для критерію U можна розрахувати за формулою:
![]()
де ![]() – критичні значення стандартного нормального розподілу, визначені за таблицями. Треба звернути увагу, що якщо є однакові варіанти, їм привласнюється середній ранг, проте значення останнього рангу має дорівнювати n1+n2. Це правило використовують для перевірки правильності ранжирування.
– критичні значення стандартного нормального розподілу, визначені за таблицями. Треба звернути увагу, що якщо є однакові варіанти, їм привласнюється середній ранг, проте значення останнього рангу має дорівнювати n1+n2. Це правило використовують для перевірки правильності ранжирування.
У разі попарно зв'язаних вибірок застосовується Т-критерій Уїлкоксона. При цьому попарні різниці – позитивні і негативні (окрім нульових) в один ряд так, щоб найменша абсолютна різниця (без урахування знака) отримала перший ранг, однаковим величинам привласнюють один ранг. Окремо обчислюють суму рангів позитивних (T+) і негативних різниць (Т-), меншу з двох таких сум без урахування знака вважають тестовою статистикою даного критерію. Нульову гіпотезу приймають на даному рівні значимості, якщо обчислена статистика перевершить табличне значення (число парних спостережень зменшують на число виключених нульових різниць). Таким чином, можна сказати, що якщо нульова гіпотеза вірна, статистики T+ і T – приблизно рівні, порівняно малі або великі значення T-статистик примусять нас відхилити нульову гіпотезу про відсутність відмінностей.
Приклад. Припустимо, в результаті проведення дослідження був обчислений ряд попарних різниць між показником ефекту в двох попарно пов'язаних групах (n1 = n2 = 10) (наприклад, так звана задача «до і після»): 0,2 -0,4 0,7 -0,9 1,3 1,5 -0,1 0,8 -1,0 1,1. Ранжируємо попарні різниці в один ряд, незалежно від знака різниці, одержуємо такий ранжирований ряд: -0,1 0,2 -0,4 0,7 0,8 -0,9 -1,0 1,1 1,3 1,5.
Розрахуємо окремо суму рангів позитивних (Т+) і негативних (T-) різниць, у нашому випадку T+ = 2 + 4 + + 5 + 8 + 9+10 = 38, T- = 1 + 3 + 6 + 7= 17. Для перевірки двостороннього T-критерію використовуємо меншу статистику T – =17 і порівнюємо її з табличним значенням для числа попарних різниць n = 10 і рівня значимості 5%. Таке табличне критичне значення дорівнює 9. Розраховане мінімальне значення T статистики перевершує відповідне табличне значення, а, отже, нульова гіпотеза залишається в силі.
У разі аналізу результатів клінічних досліджень непараметричні критерії корисні не тільки для аналізу кількісних даних, а також при якісній або альтернативній формі представлення ознак.
Похожие работы
... , що наявні дані їй не суперечать. Не можна забувати, що, перевіряючи статистичну гіпотезу, ми маємо справу лише з обмеженою вибіркою з генеральної сукупності. Тому всі висновки, що робляться під час перевірки статистичних гіпотез, носять характер імовірності. От чому значення імовірності помилок I і II роду мають таке велике значення для цієї процедури. Для перевірки гіпотез у біометрії можливі ...
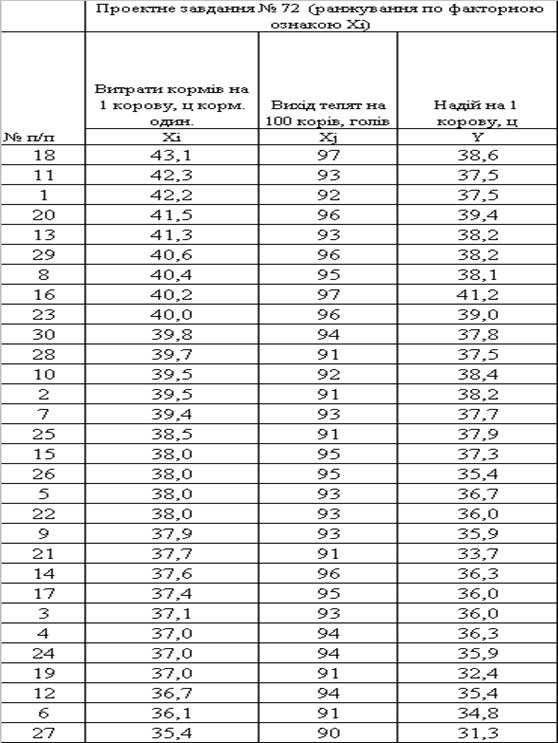
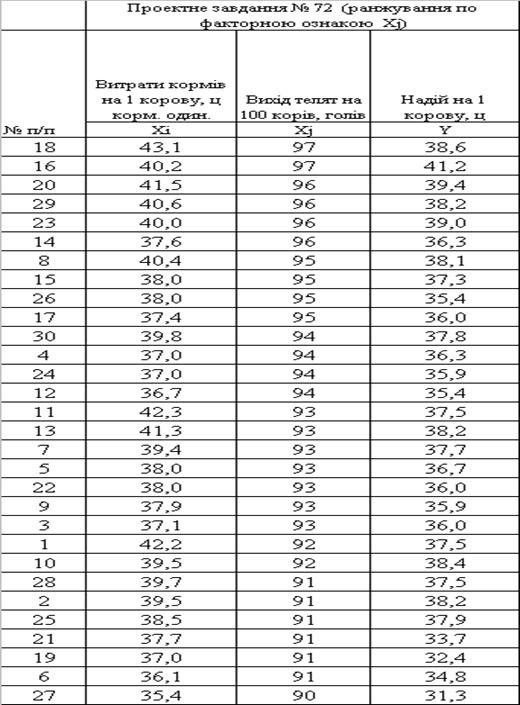
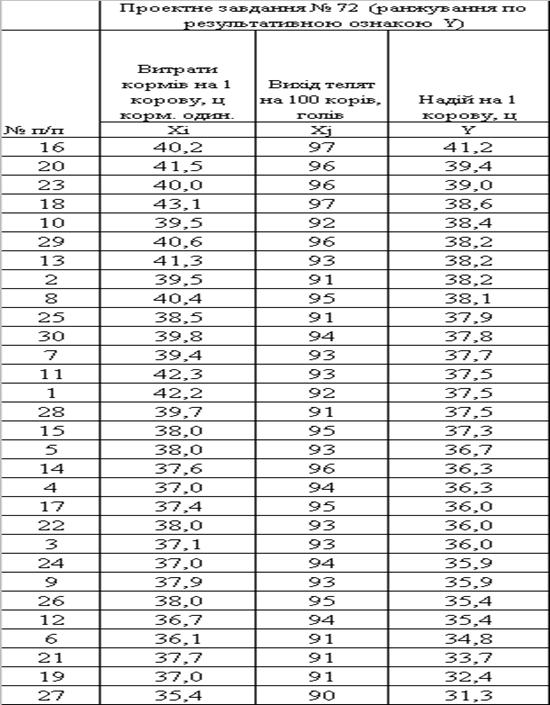
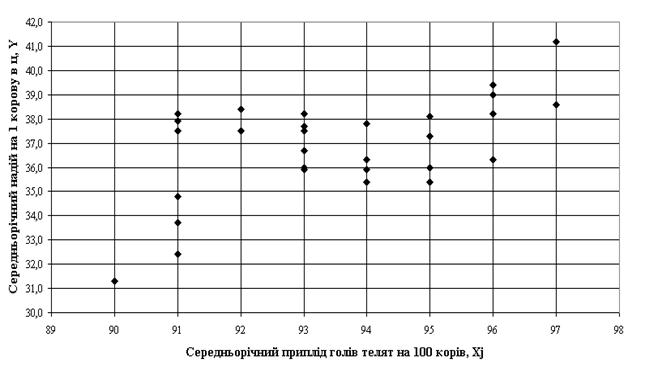
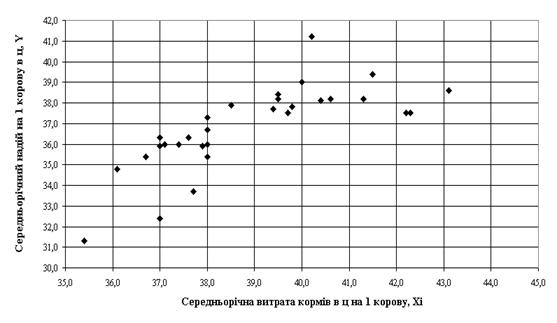
... , як умови продовження періодичного процесу лактації молока у ВРХ. 1. Система показників статистики тваринництва 1.1 Методологія розрахунку основних показників статистики тваринництва в сегменті великої рогатої худоби (ВРХ) Продукція тваринництва поділяється на дві групи: 1) продукція нормальної життєдіяльності тварин, реалізація якої для вживання за межами тваринництва не пов'язана з ...
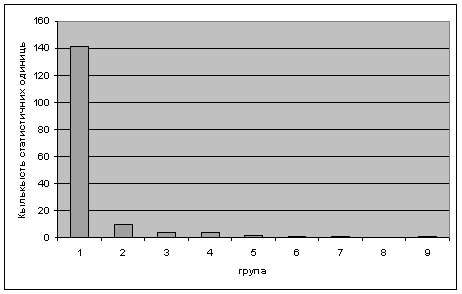
... ідних груп банків з метою забезпечення достовірності подальших статистичних досліджень. Розділ 2 2.1 Оцінка однорідності статистичної сокупності комерційних банків за допомогою показників їх діяльності Перевіримо однорідність досліджуваної сукупності за допомогою розрахунків показників варіації: Вибіркове середнє визначаємо за формулою середньої арифметичної зваженої: Дисперс ...
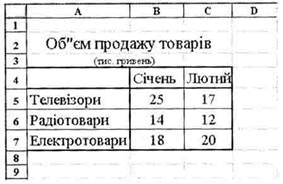
... та знизу ( нижній колонтитул ) у межах одного розділу або всього документа. Правильний вибір цієї інформації дає змогу читачеві краще орієнтуватися в документі. 5.4 Уведення інформації Інформаційна система маркетингу – це сукупність інформації, апаратно-програмних і технологічних засобів, засобів телекомунікацій, баз і банків даних, методів і процедур, персоналу управління, які реалізують ...
0 комментариев