Навигация
Определяется общее среднее (константа дискриминации) для дискриминантных функций
24301
знак
8
таблиц
7
изображений
9. Определяется общее среднее (константа дискриминации) для дискриминантных функций

10. Выполняется распределение (дискриминация) объектов подмножества М0 подлежащих дискриминации по обучающим выборкам М1 и М2. С этой целью рассчитанные и п. 7 по каждому i-му объекту значения дискриминантных функций
![]()
сравниваются с величиной ![]() общего среднего. На основе сравнения данный объект относят к одному из обучающих подмножеств.
общего среднего. На основе сравнения данный объект относят к одному из обучающих подмножеств.
Если ![]() , то i-й объект подмножества М0 относят к подмножеству М1, при
, то i-й объект подмножества М0 относят к подмножеству М1, при ![]() >0 и к подмножеству М2 при
>0 и к подмножеству М2 при ![]() <0. Если же
<0. Если же ![]() <
<![]() , то заданный объект относят к подмножеству М1, при
, то заданный объект относят к подмножеству М1, при ![]() < 0 и к подмножеству М2 в противном случае.
< 0 и к подмножеству М2 в противном случае.
11. Далее делается оценка качества распределения новых объектов, для чего оценивается вклад переменных в дискриминантную функцию.
Влияние признаков на значение дискриминантной функции и результаты классификации может оцениваться по дискриминантным множителям (коэффициентам дискриминации), по дискриминантным нагрузкам признаков или по дискриминантной матрице.
Дискриминантные множители зависят от масштабов единиц измерения признаков, поэтому они не всегда удобны для оценки.
Дискриминантные нагрузки более надежны в оценке признаков, они вычисляются как парные линейные коэффициенты корреляции между рассчитанными уровнями дискриминантной функции F и признаками, взятыми для ее построения.
Дискриминантная матрица характеризует меру соответствия результатов классификации фактическому распределению объектов по подмножествам и используется для оценки качества анализа. В этом случае дискриминантная функция F формируется по данным объектов (с измеренными p признаками) обучающих подмножеств, а затем проверяется качество этой функции путем сопоставления фактической классовой принадлежности объектов с той, что получена в результате формальной дискриминации.
3. ПРИМЕРЫ ДИСКРИМИНАНТНОГО АНАЛИЗА
3.1 Применение дискриминантного анализа при наличии двух обучающих выборок (q=2)
Имеются данные по двум группам промышленных предприятий отрасли: Х1 - среднегодовая стоимость основных производственных фондов, млн. д.ед.; Х2 — среднесписочная численность персонала, тыс. чел.; Х3 — балансовая прибыль млн. д.ед.
Исходные данные представлены в таблице 2.
Таблица 2
| Номер группы Mk (k =1, 2) | Номер предприятия, i (i = 1, 2, ..., nk) | Свойства (показатель), j (j = 1, 2, ..., p) | |||
| Х1 | Х2 | Х3 | |||
| Группа 1, M1 (k = 1) | 1 | 224,228 | 17,115 | 22,981 | |
| 2 | 151,827 | 14,904 | 21,481 | ||
| 3 | 147,313 | 13,627 | 28,669 | ||
| 4 | 152,253 | 10,545 | 10,199 | ||
| Группа 2, M2 (k = 2) | 1 | 46,757 | 4,428 | 11,124 | |
| 2 | 29,033 | 5,51 | 6,091 | ||
| 3 | 52,134 | 4,214 | 11,842 | ||
| 4 | 37,05 | 5,527 | 11,873 | ||
| 5 | 63,979 | 4,211 | 12,860 | ||
| Группа предприятий M0, подлежащих дискриминации | 1 | 55,451 | 9,592 | 12,840 | |
| 2 | 78,575 | 11,727 | 15,535 | ||
| 3 | 98,353 | 17,572 | 20,458 | ||
Необходимо провести классификацию (дискриминацию) трех новых предприятий, образующих группу М0 с известными значениями исходных переменных.
Решение:
1. Значения исходных переменных для обучающих подмножеств M1 и M2 (групп предприятий) записываются в виде матриц X(1) и X(2) :
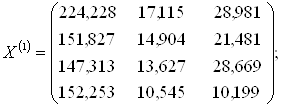
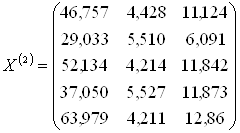
и для подмножества M0 группы предприятий, подлежащих классификации в виде матрицы X(0):
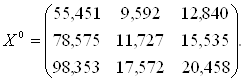
Общее количество предприятий, составляющих множество М, будет равно N = 3+4+5 = 12 ед.
2. Определяются элементы векторов ![]() средних значений по j признакам для i-х объектов по каждой k-й выборке (k = 1, 2), которые представляются в виде двух векторов
средних значений по j признакам для i-х объектов по каждой k-й выборке (k = 1, 2), которые представляются в виде двух векторов ![]() (по количеству обучающих выборок):
(по количеству обучающих выборок):
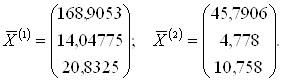
3. Для каждого обучающего подмножества M1 и M2 рассчитываются ковариационные матрицы Sk (размером р×р):
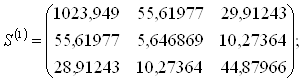
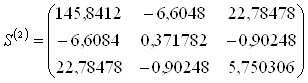
4. Рассчитывается объединенная ковариационная матрица:
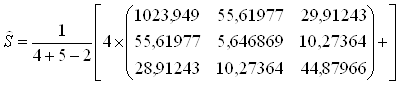
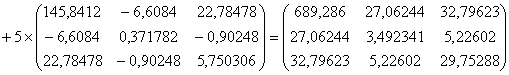
5. Рассчитывается матрица ![]() обратная к объединенной ковариационной матрице:
обратная к объединенной ковариационной матрице:
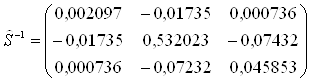
6. Рассчитываются дискриминантные множители (коэффициенты дискриминантной функции) по всем элементам обучающих подмножеств:
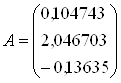
7. Для каждого i-го объекта k-го подмножества М определяется значение дискриминантной функции:
F1(1)=0,104743×224,228+2,046703×17,115+(-0,13635)×22,981=55,38211;
F2(1)=0,104743×151,827+2,046703×14,904+(-0,13635)×21,481=43,47791;
F3(1)=0,104743×147,313+2,046703×13,627+(-0,13635)×28,669=39,41138;
F4(2)=0,104743×152,253+2,046703×10,545+(-0,13635)×10,199=36,13924;
F1(2)=0,104743×46,757+2,046703×4,428+(-0,13635)×11,124=12,44351;
………………………………………………………………………………..
F5(2)=0,104743×63,979+2,046703×4,211+(-0,13635)×12,860=13,56655.
8. По совокупности найденных значений F(k) рассчитываются средние значения ![]() для каждого подмножества Mk:
для каждого подмножества Mk:
![]()
![]()
9. Определяется общее среднее (константа дискриминации) для дискриминантных функций:
![]()
10. Выполняется распределение объектов подмножества М0 по обучающим подмножествам М1 и М2, для чего по каждому объекту (i = 1, 2, 3) рассчитываются дискриминантные функции:
F1(0)=0,104743×55,451+2,046703×9,592+(-0,13635)×12,840=23,68661
F2(0)=0,104743×78,575+2,046703×11,727+(-0,13635)×15,535=30,11366
F3(0)=0,104743×98,353+2,046703×17,572+(-0,13635)×20,458=23,68661
Затем рассчитанные значения дискриминантных функций F(0) сравниваются с общей средней F=28,3556.
Поскольку ![]() , то i-й объект подмножества М0 относят к подмножеству М1 при
, то i-й объект подмножества М0 относят к подмножеству М1 при![]() > 0 и к подмножеству М2 при
> 0 и к подмножеству М2 при ![]() <0. С учетом этого в данном примере предприятия 2 и 3 подмножества М0 относятся к М1, а предприятие 1 относится к М2.
<0. С учетом этого в данном примере предприятия 2 и 3 подмножества М0 относятся к М1, а предприятие 1 относится к М2.
Если бы выполнялось условие ![]() , то объекты М0 относились к подмножеству М1, при
, то объекты М0 относились к подмножеству М1, при ![]() и к подмножеству М2 в противном случае.
и к подмножеству М2 в противном случае.
11. Оценку качества распределения новых объектов выполним путем сравнения с константой дискриминации F значений дискриминантных функций Fi(k)=обучающих подмножеств М1 и М2. Поскольку для всех найденных значений выполняются неравенства![]() , и
, и ![]() , то можно предположить о правильном распределении объектов и уже существующих двух классах и верно выполненной классификации объектов подмножества М0.
, то можно предположить о правильном распределении объектов и уже существующих двух классах и верно выполненной классификации объектов подмножества М0.
Похожие работы
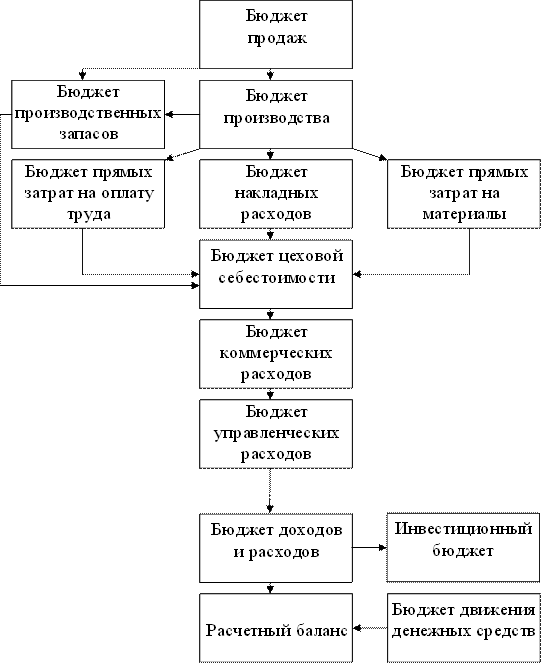
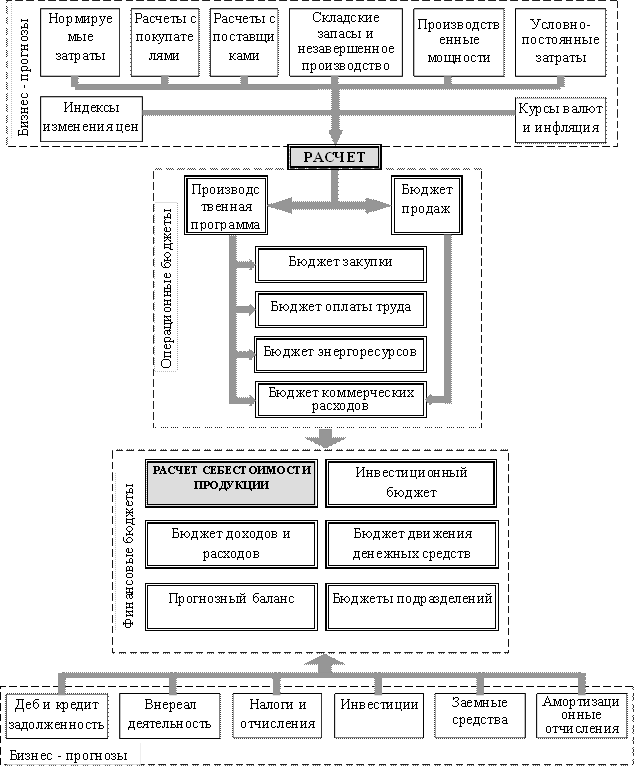
... период подготовки планов. Еще одна категория систем, используемых для бюджетирования - корпоративные системы управления (ERP-системы). ERP (Enterprise Resource Planning) - автоматизация и оптимизация внутренних бизнес-процессов, планирование как материальных, так и финансовых ресурсов в масштабе предприятия; - используется для описания компонентов "производство", "логистика", "финансы". ERP- ...
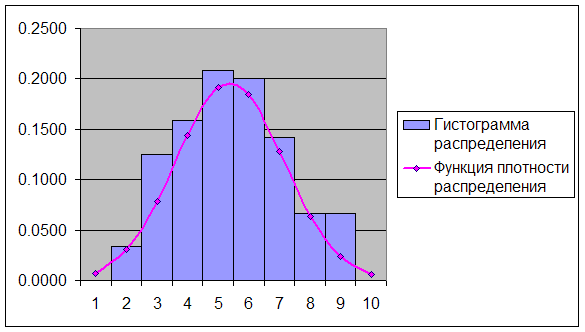
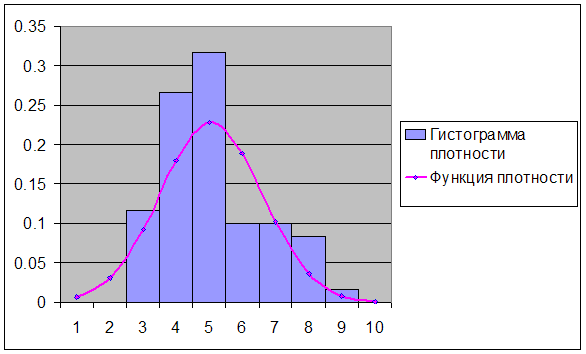
... критических точек распределения ([1], стр. 465), по уровню значимости =0,05 и числу степеней свободы 8-3=5 находим Т.к. , экспериментальные данные не противоречат гипотезе и о нормальном распределении случайной величины . Для случайной величины : Используя предполагаемый закон распределения, вычислим теоретические частоты по формуле , где - объем выборки, - шаг (разность между ...
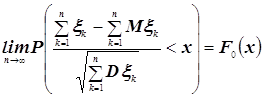
... проверить знания студента из первой части курса, которая излагается в первых четырёх модулях. Во вторых вопросах билета проверяются знания классической предельной проблемы теории вероятностей и математической статистики, которые излагаются в следующих пяти модулях. 1. Вероятностная модель с не более чем счётным числом элементарных исходов. Пример: испытания с равновозможными исходами. 2. ...
... взаимосвязи и взаимодействие подразделений с аналогичными функциями на разных уровнях единой организационной и управленческой структуры. Такая структура создает упорядоченность и организованность системы таможенных органов при выполнении возложенных на них функций. Рассмотрим современную организационную структуру таможенных органов. ГТК России имеет дифференцированную и разветвленную структуру. ...
0 комментариев