Навигация
Многомерный статистический анализ в системе SPSS
28596
знаков
12
таблиц
16
изображений
Оглавление
Введение
Глава 1. Множественный регрессионный анализ
Глава 2. Кластерный анализ
Глава 3. Факторный анализ
Глава 4. Дискриминантный анализ
Список используемой литературы
Введение
Исходная информация в социально-экономических исследованиях представляется чаще всего в виде набора объектов, каждый из которых характеризуется рядом признаков (показателей). Поскольку число таких объектов и признаков может достигать десятков и сотен, и визуальный анализ этих данных малоэффективен, то возникают задачи уменьшения, концентрации исходных данных, выявления структуры и взаимосвязи между ними на основе построения обобщенных характеристик множества признаков и множества объектов. Такие задачи могут решиться методами многомерного статистического анализа.
Многомерный статистический анализ - раздел математической статистики, посвященный математическим методам, направленным на выявление характера и структуры взаимосвязей между компонентами исследуемого многомерного признака и предназначенным для получения научных и практических выводов.
Основное внимание в многомерном статистическом анализе уделяется математическим методам построения оптимальных планов сбора, систематизации и обработки данных, направленным на выявление характера и структуры взаимосвязей между компонентами исследуемого многомерного признака и предназначенным для получения научных и практических выводов.
Исходным массивом многомерных данных для проведения многомерного анализа обычно служат результаты измерения компонент многомерного признака для каждого из объектов исследуемой совокупности, т.е. последовательность многомерных наблюдений. Многомерный признак чаще всего интерпретируется как величина случайная, а последовательность наблюдений как выборка из генеральной совокупности. В этом случае выбор метода обработки исходных статистических данных производится на основе тех или иных допущений относительно природы закона распределения изучаемого многомерного признака.
По содержанию многомерный статистический анализ может быть условно разбит на три основных подраздела:
1. Многомерный статистический анализ многомерных распределений и их основных характеристик охватывает ситуации, когда обрабатываемые наблюдения имеют вероятностную природу, т.е. интерпретируются как выборка из соответствующей генеральной совокупности. К основным задачам этого подраздела относятся: оценивание статистическое исследуемых многомерных распределений и их основных параметров; исследование свойств используемых статистических оценок; исследование распределений вероятностей для ряда статистик, с помощью которых строятся статистические критерии проверки различных гипотез о вероятностной природе анализируемых многомерных данных.
2. Многомерный статистический анализ характера и структуры взаимосвязей компонент исследуемого многомерного признака объединяет понятия и результаты, присущие таким методам и моделям, как регрессионный анализ, дисперсионный анализ, ковариационный анализ, факторный анализ и т.д. Методы, принадлежащие к этой группе, включают как алгоритмы, основанные на предположении о вероятностной природе данных, так и методы, не укладывающиеся в рамки какой-либо вероятностной модели (последние чаще относят к методам анализа данных).
3.Многомерный статистический анализ геометрической структуры исследуемой совокупности многомерных наблюдений объединяет понятия и результаты, свойственные таким моделям и методам, как дискриминантный анализ, кластерный анализ, многомерное шкалирование. Узловым для этих моделей является понятие расстояния, либо меры близости между анализируемыми элементами как точками некоторого пространства. При этом анализироваться могут как объекты (как точки, задаваемые в признаковом пространстве), так и признаки (как точки, задаваемые в объектном пространстве).
Прикладное значение многомерного статистического анализа состоит в основном в решении следующих трех задач:
· задача статистического исследования зависимостей между рассматриваемыми показателями;
· задача классификации элементов (объектов или признаков);
· задача снижения размерности рассматриваемого признакового пространства и отбора наиболее информативных признаков.
Множественный регрессионный анализ предназначен для построения модели, позволяющей по значениям независимых переменных получать оценки значений зависимой переменной.
Логистическая регрессия для решения задачи классификации. Это разновидность множественной регрессии, назначение которой состоит в анализе связи между несколькими независимыми переменными и зависимой переменной.
Факторный анализ занимается определением относительно небольшого числа скрытых (латентных) факторов, изменчивостью которых объясняется изменчивость всех наблюдаемых показателей. Факторный анализ направлен на снижение размерности рассматриваемой задачи.
Кластерный и дискриминантный анализ предназначены для разделения совокупностей объектов на классы, в каждый из которых должны входить объекты в определенном смысле однородные или близкие. При кластерном анализе заранее неизвестно, сколько получится групп объектов и какого они будут объема. Дискриминантный анализ разделяет объекты по уже существующим классам.
Глава 1. Множественный регрессионный анализ
Задание: Исследование рынка жилья в Орле (Советский и Северный районы).
В таблице приведены данные по цене квартир в Орле и по различным факторам, ее обусловливающим:
· цена;
· общая площадь;
· площадь кухни;
· жилая площадь;
· район;
· этаж;
· тип дома;
· количество комнат. (Рис.1)
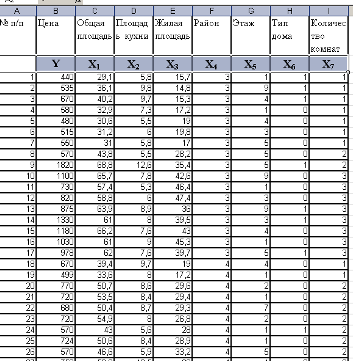
Рис. 1 Исходные данные
В графе «Район» использованы обозначения:
3 – Советский (элитный, относится к центральным районам);
4 – Северный.
В графе «Тип дома»:
1 – кирпичный;
0 – панельный.
Требуется:
1. Проанализировать связь всех факторов с показателем «Цена» и между собой. Отобрать факторы, наиболее подходящие для построения регрессионной модели;
2. Сконструировать фиктивную переменную, отображающую принадлежность квартиры к центральным и периферийным районам города;
3. Построить линейную модель регрессии для всех факторов, включив в нее фиктивную переменную. Пояснить экономический смысл параметров уравнения. Оценить качество модели, статистическую значимость уравнения и его параметров;
4. Распределить факторы (кроме фиктивной переменной) по степени влияния на показатель «Цена»;
5. Построить линейную модель регрессии для наиболее влиятельных факторов, оставив в уравнении фиктивную переменную. Оценить качество и статистическую значимость уравнения и его параметров;
6. Обосновать целесообразность или нецелесообразность включения в уравнение п. 3 и 5 фиктивной переменной;
7. Оценить интервальные оценки параметров уравнения с вероятностью 95%;
8. Определить, сколько будет стоить квартира общей площадью 74,5 м² в элитном (периферийном) районе.
Выполнение:
1. Проанализировав связь всех факторов с показателем «Цена» и между собой, были отобраны факторы, наиболее подходящие для построения регрессионной модели, используя метод включения «Forward»:
А) общая площадь;
Б) район;
В) количество комнат.
Включенные/исключенные переменные(a)
| Модель | Включенные переменные | Исключенные переменные | Метод |
| 1 | Общая площадь | . | Включение (критерий: вероятность F-включения >= ,050) |
| 2 | Район | . | Включение (критерий: вероятность F-включения >= ,050) |
| 3 | Кол-во комнат | . | Включение (критерий: вероятность F-включения >= ,050) |
a Зависимая переменная: Цена
2. Переменная Х4 «Район» является фиктивной переменной, так как имеет 2 значения: 3-принадлежность к центральному району «Советский», 4- к периферийному району «Северный».
3. Построим линейную модель регрессии для всех факторов (включая фиктивную переменную Х4).
Полученная модель:
У = 348,349 + 35,788 Х1 -217,075 Х4 +305,687 Х7
Оценка качества модели.
Коэффициент детерминации R2 = 0,807
Показывает долю вариации результативного признака под воздействием изучаемых факторов. Следовательно, около 89% вариации зависимой переменной учтено и обусловлено в модели влиянием включенных факторов.
Коэффициент множественной корреляции R = 0,898
Показывает тесноту связи между зависимой переменной У со всеми включенными в модель объясняющими факторами.
Стандартная ошибка = 126,477
Коэффициент Дарбина - Уотсона = 2,136
Проверка значимости уравнения регрессии
Значение критерия F-Фишера = 41,687
Уравнение регрессии следует признать адекватным, модель считается значимой.
Самый значимый фактор – количество комнат (F=41,687)
Второй по значимости фактор- общая площадь (F= 40,806)
Третий по значимости фактор- район (F= 32,288)
Похожие работы


... практический характер. Результаты, полученные в работе, могут быть использованы в дальнейших исследованиях по управлению риском и могут быть применены в банках. Глава 1. Обзор моделей оценки кредитного риска 1.1. Понятие качества и прозрачности методик Проблема количественной оценки и анализа кредитных рисков и рейтингов заемщиков и создания резервов на случай дефолта является ...
... и т.д. Строятся доверительные интервалы для средних, дисперсий и коэффициентов корреляции, применяются подходящие критерии согласия. Используются методы дисперсионного, факторного и регрессионного анализа. При обобщении результатов исследования решается вопрос о репрезентативности выборки. Необходимо отметить, что эта последовательность действий, строго говоря, не является хронологической, за ...
... пятого кластера стали Санкт-Петербург, Свердловская область. А вот шестой кластер состоит лишь из одного региона России- Республики Ингушетии. Для создания качественного представления о социально-экономическом положении (различиях в имущественном обеспечении и неравенстве в доходах) очень полезно будет рассмотреть таблицу окончательных кластерных центров. Таблица 9 «Окончательные кластерные ...
... в странах Европы, школа по использованию математико-статистических методов и ЭВМ в исторических исследованиях под руководством И.Д. Ковальченко в СССР. Процесс комплексного применения количественных методов и информационных технологий при обработке исторических источников прошел в своем развитии два основных этапа. Первый этап охватил 1960-е – первую половину 1980-х гг., получив по определению ...
0 комментариев