Навигация
Построим линейную модель регрессию со всеми факторами (кроме фиктивной переменной Х4)
28596
знаков
12
таблиц
16
изображений
4. Построим линейную модель регрессию со всеми факторами (кроме фиктивной переменной Х4)
По степени влияния на показатель «Цена» распределили:
Самый значимый фактор – общая площадь (F= 40,806)
Второй по значимости фактор- количество комнат (F= 29,313)
5. Включенные/исключенные переменные
| Модель | Включенные переменные | Исключенные переменные | Метод |
| 1 | Общая площадь | . | Включение (критерий: вероятность F-включения >= ,050) |
| 2 | Район | . | Включение (критерий: вероятность F-включения >= ,050) |
| 3 | Кол-во комнат | . | Включение (критерий: вероятность F-включения >= ,050) |
a Зависимая переменная: Цена
6. Построим линейную модель регрессии для наиболее влиятельных факторов с фиктивной переменной, в нашем случае она и является одним из влиятельных факторов.
Полученная модель:
У = 348,349 + 35,788 Х1 -217,075 Х4 +305,687 Х7
Оценка качества модели.
Коэффициент детерминации R2 = 0,807
Показывает долю вариации результативного признака под воздействием изучаемых факторов. Следовательно, около 89% вариации зависимой переменной учтено и обусловлено в модели влиянием включенных факторов.
Коэффициент множественной корреляции R = 0,898
Показывает тесноту связи между зависимой переменной У со всеми включенными в модель объясняющими факторами.
Стандартная ошибка = 126,477
Коэффициент Дарбина - Уотсона = 2,136
Проверка значимости уравнения регрессии
Значение критерия F-Фишера = 41,687
Уравнение регрессии следует признать адекватным, модель считается значимой.
Самый значимый фактор – количество комнат (F=41,687)
Второй по значимости фактор- общая площадь (F= 40,806)
Третий по значимости фактор- район (F= 32,288)
7. Фиктивная переменная Х4 является значимым фактором, поэтому целесообразно включить ее в уравнение.
Интервальные оценки параметров уравнения показывают результаты прогнозирования по модели регрессии.
С вероятностью 95% объем реализации в прогнозируемом месяце составит от 540,765 до 1080,147 млн. руб.
8. Определение стоимости квартиры в элитном районе
Для 1 комн У = 348,349 + 35,788 * 74, 5 - 217,075 * 3 + 305,687 * 1
Для 2 комн У = 348,349 + 35,788 * 74, 5 - 217,075 * 3 + 305,687 * 2
Для 3 комн У = 348,349 + 35,788 * 74, 5 - 217,075 * 3 + 305,687 * 3
в периферийном
Для 1 комн У = 348,349 + 35,788 * 74, 5 - 217,075 * 4 + 305,687 * 1
Для 2 комн У = 348,349 + 35,788 * 74, 5 - 217,075 * 4 + 305,687 * 2
Для 3 комн У = 348,349 + 35,788 * 74, 5 - 217,075 * 4 + 305,687 * 3
Глава 2. Кластерный анализ
Задание: Исследование структуры денежных расходов и сбережений населения.
В таблице представлена структура денежных расходов и сбережений населения по регионам Центрального федерального округа Российской федерации в 2003 г. Для следующих показателей:
· ПТиОУ – покупка товаров и оплата услуг;
· ОПиВ – обязательные платежи и взносы;
· ПН – приобретение недвижимости;
· ПФА – прирост финансовых активов;
· ДР – прирост (уменьшение) денег на руках у населения.
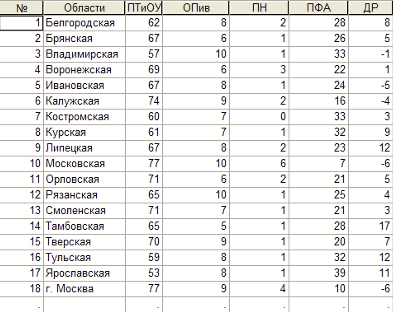
Рис. 8 Исходные данные
Требуется:
1) определить оптимальное количество кластеров для разбиения регионов на однородные группы по всем группировочным признакам одновременно;
2) провести классификацию областей иерархическим методом с алгоритмом межгрупповых связей и отобразить результаты в виде дендрограммы;
3) проанализировать основные приоритеты денежных расходов и сбережений в полученных кластерах;
4) сравнить полученную классификацию с результатами применения алгоритма внутригрупповых связей.
Выполнение:
1) Определить оптимальное количество кластеров для разбиения регионов на однородные группы по всем группировочным признакам одновременно;
Для определения оптимального количества кластеров нужно воспользоваться Иерархическим кластерным анализом и обратиться к таблице «Шаги агломерации» к столбцу «Коэффициенты».
Эти коэффициенты подразумевают расстояние между двумя кластерами, определенное на основании выбранной дистанционной меры (Евклидово расстояние). На том этапе, когда мера расстояния между двумя кластерами увеличивается скачкообразно, процесс объединения в новые кластеры необходимо остановить.
В итоге, оптимальным считается число кластеров, равное разности количества наблюдений (17) и номера шага (14),после которого коэффициент увеличивается скачкообразно. Таким образом, оптимальное количество кластеров равно 3. (Рис.9)
статистический математический анализ кластерный

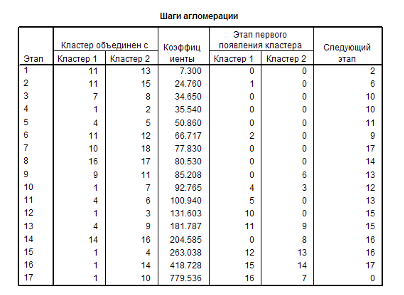
Рис. 9 Таблица «Шаги агломерации»
2) Провести классификацию областей иерархическим методом с алгоритмом межгрупповых связей и отобразить результаты в виде дендрограммы;
Теперь, используя оптимальное количество кластеров, проводим классификацию областей иерархическим методом. И в выходных данных обращаемся к таблице «Принадлежность к кластерам». (Рис.10)
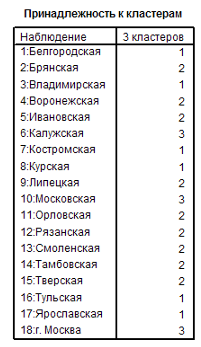
Рис. 10 Таблица «Принадлежность к кластерам»
На Рис. 10 отчетливо видно, что в 3 кластер попали 2 области (Калужская, Московская) и г. Москва, во 2 кластер две (Брянская, Воронежская, Ивановская, Липецкая, Орловская, Рязанская, Смоленская, Тамбовская, Тверская), в 1 кластер – Белгородская, Владимирская, Костромская, Курская, Тульская, Ярославская.

Рис. 11 Дендрограмма
3) проанализировать основные приоритеты денежных расходов и сбережений, в полученных кластерах;
Для анализа полученных кластеров нам нужно провести «Сравнение средних». В выходном окне выводится следующая таблица (Рис. 12)
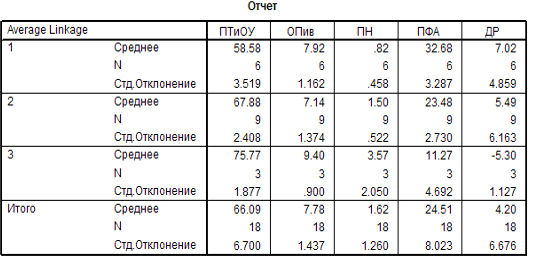
Рис. 12 Средние значения переменных
В таблице «Средних значений» мы можем проследить, каким структурам отдается наибольший приоритет в распределении денежных расходов и сбережений населения.
В первую очередь стоит отметить, что самый высокий приоритет во всех областях отдается покупке товаров и оплате услуг. Большее значение параметр принимает в 3 кластере.
Похожие работы


... практический характер. Результаты, полученные в работе, могут быть использованы в дальнейших исследованиях по управлению риском и могут быть применены в банках. Глава 1. Обзор моделей оценки кредитного риска 1.1. Понятие качества и прозрачности методик Проблема количественной оценки и анализа кредитных рисков и рейтингов заемщиков и создания резервов на случай дефолта является ...
... и т.д. Строятся доверительные интервалы для средних, дисперсий и коэффициентов корреляции, применяются подходящие критерии согласия. Используются методы дисперсионного, факторного и регрессионного анализа. При обобщении результатов исследования решается вопрос о репрезентативности выборки. Необходимо отметить, что эта последовательность действий, строго говоря, не является хронологической, за ...
... пятого кластера стали Санкт-Петербург, Свердловская область. А вот шестой кластер состоит лишь из одного региона России- Республики Ингушетии. Для создания качественного представления о социально-экономическом положении (различиях в имущественном обеспечении и неравенстве в доходах) очень полезно будет рассмотреть таблицу окончательных кластерных центров. Таблица 9 «Окончательные кластерные ...
... в странах Европы, школа по использованию математико-статистических методов и ЭВМ в исторических исследованиях под руководством И.Д. Ковальченко в СССР. Процесс комплексного применения количественных методов и информационных технологий при обработке исторических источников прошел в своем развитии два основных этапа. Первый этап охватил 1960-е – первую половину 1980-х гг., получив по определению ...
0 комментариев